券商头部都用的金融时序数据库DolphinDB
原创
券商头部都用的金融时序数据库DolphinDB
原创
薛晓刚-
发布于 2026-03-12 10:04:04
发布于 2026-03-12 10:04:04
去年我才听到这个数据库,估计熟悉他们产品的人不多
- 但是第一时间我得到了一个数据,券商头部都是用他们的产品
- 且都是用户主动找上门的
- 金融领域的做的很出名
瞬间觉得是自己孤陋寡闻了。
- 后来经过一系列了解发现他们非常低调,宣传不是太多。主打产品实力强。
- 今年我也尝试了一下。说说自己的感受。
为了快速体验,使用了容器安装
- 容器安装只能单实例。没有体验分布式架构。(金融场景必须要求高可用)
image.png
- 启动容器以后可以有web页面进入管理
- 这就像数据库工具的客户端一样。不少数据库只提供了命令行模式没有图形化界面。或者需要安装exe的客户端工具。用web当客户端工具的不多。当然他也有命令行模式(上图)
image.png
- 经过一系列的建表和初始化,最后界面是:
image.png
通过简单学习的结论
- DolphinDB是一款为海量时序数据场景而生的高性能分布式数据库。目前最成功的是在金融时序场景,其他场景比如电力、烟草、新能源等工业场景…他们也已经有了很多案例。它不仅在架构设计上兼顾了扩展性与稳定性,更通过独创的存储引擎技术,实现了真正的HTAP能力,能够同时高效处理高并发的实时事务与复杂的分析查询。在我简单的学习中能初步了解他们的时序和分析的设计好在哪里?
- LSM——Tree这种就是天生应对大量写入的,而时序场景第一个要面对的就是写的压力。而至于读不是LSM-Tree的强项,DolphinDB是用列存去支持的。
- 其实对于AP系统场景如何使用索引也是一个学问,但是这不是技术壁垒点。大家都是用索引那么SQL效率也应该差不多,至少不是数量级的差异。
- 真正有差异的地方是金融工程函数多 开箱即用 有流计算引擎 比如订单簿引擎 可以直接在实际场景中落地。也就是说更加懂金融业务做了很多定制化的函数这才是护城河。
- 例如看到这个我第一反应是懵的(贝塔分布)
- cdfBeta(alpha, beta, X) 返回 Beta 分布的累计密度函数的值。
- cdfBeta(2.31, 0.627, [0.001, 0.5, 0.999]); // output [0, 0.116056, 0.976416]
- 借助AI得到如下分析
- 在 x = 0.001 处,累积概率几乎为 0(说明该分布几乎不包含小于 0.001 的概率质量)。
- 在 x = 0.5 处,累积概率约为 0.116,即只有约 11.6% 的概率落在 0.5 以下。
- 在 x = 0.999 处,累积概率约为 0.976,即 97.6% 的概率落在 0.999 以下,仍有约 2.4% 的概率超过 0.999(因为 β 小,分布尾部延伸到 1)。
- 以上可能通过其他方式也能去做,但是这里直接提供现场的函数。这就像做证明题你可能需要去做很多证明,而你的同学知道有一个定理,直接用了。这样少了很多步骤。
- 这说的只是冰山一角。这些自定义的金融场景的工程化函数还有很多。
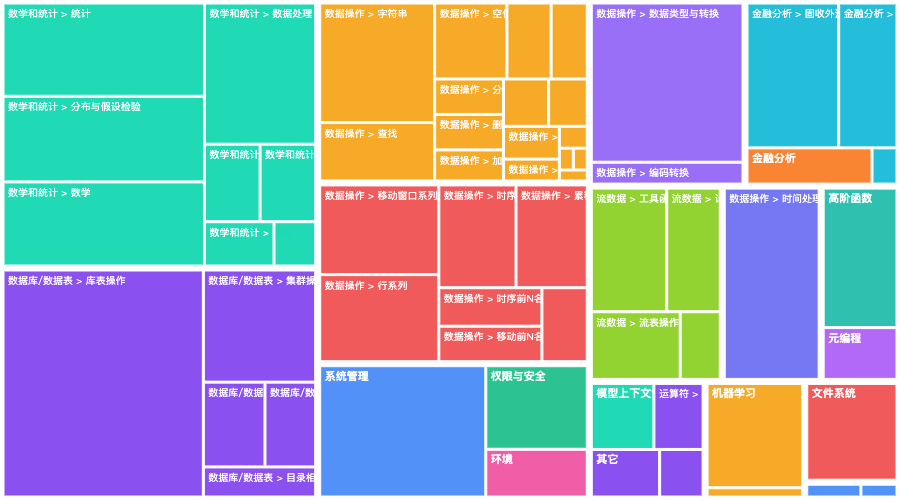
34810491f67c9a9ad3758c7bb5dadeea.png
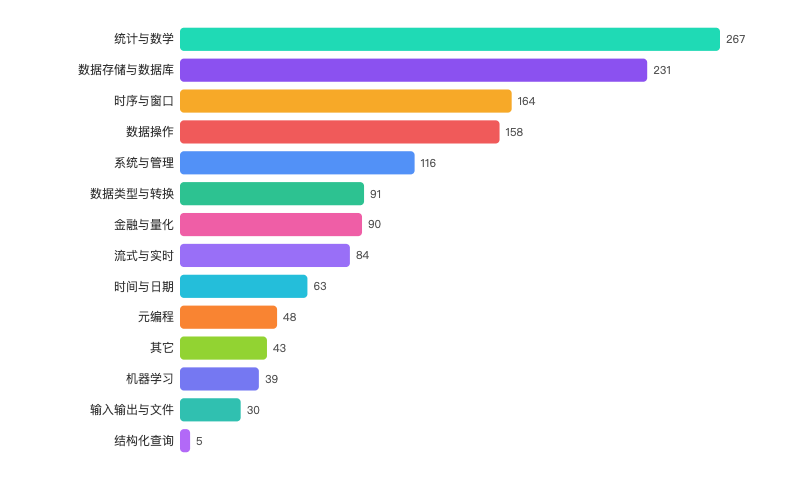
a38ab0195f49fe7d46358c3dc0e0e4f3.png
- 上面这些图是 AI 从官网文档上抓的从这里可以看出,发力的重点和规模化了吧。这些创造能力极大简化了用户的使用。都是深入贴合和金融业务的定制化。
稳健灵活的分布式基石(由于体验的是单机,分布式这段是从白皮书上概括的)
- DolphinDB采用经典的Shared-Nothing集群架构,各节点职责清晰、相互独立。其中,控制节点作为集群的“大脑”,统一管理元数据、协调事务并监控全局状态。数据节点负责数据的存储与本地计算,而计算节点则专司计算密集型任务,实现了计算与存储的分离。这种设计让系统在高并发查询下更加稳定,计算资源可以独立弹性扩展,且单个节点故障不会影响整体服务。
- 在数据组织上,它支持灵活的多维分区策略,可以将数据表按时间、设备ID等多个维度进行千万级的细粒度切分。分区信息与物理存储位置解耦,使得数据能够均匀分布,并在查询时智能地跳过无关分区,极大提升了检索效率。
- 对于跨分区的数据操作,DolphinDB通过两阶段提交协议和多版本并发控制来保证严格的ACID事务。其写入流程也经过深度优化:数据先写入内存缓存并持久化日志,再批量异步刷盘。这种机制不仅确保了崩溃恢复的安全性,还将大量随机小写合并为顺序大写,显著提升了写入吞吐和磁盘IO效率。同时,基于快照的读写隔离机制,让读写操作互不阻塞,保障了高并发场景下的性能。
双引擎驱动的HTAP核心
- DolphinDB的HTAP能力并非通过单一的“万 能”引擎实现,而是通过为不同工作负载量身定制的双存储引擎来达成的。
- TSDB引擎:为时序与点查优化,是类似TP场景的解决方案
- 这个引擎的核心是基于LSM-Tree模型的深度定制。它创新性地引入了排序列的概念,用户可以将时间戳、设备ID等关键字段指定为排序列,数据在分区内即按此排序。这本质上构建了一个高效的排序键索引,使得基于这些字段的等值或范围查询速度极快,非常适合监控、金融等场景下的高频点查。
- 在存储结构上,它采用了PAX行列混合存储格式。数据文件内部先按排序键分组,组内再按列独立压缩存储。这种设计巧妙地结合了行存利于键值检索和列存利于压缩扫描的双重优势。配合LSM的多层合并与去重策略,它能很好地处理时序数据常见的乱序写入和更新操作。
- OLAP引擎:为分析扫描而生,是纯AP场景的解决方案
- 这是一个纯粹的列式存储引擎。每个数据列都被单独存储和压缩。当进行统计分析时,系统只需读取查询涉及的列,避免了读取整行数据的IO浪费,特别适合进行大规模的历史数据扫描、聚合和关联分析。写入时同样经过缓存和日志缓冲,以追加方式落到列文件,保证了写入性能。
- 用户可以根据业务表的特点灵活选择引擎:需要高频更新和点查的表选用TSDB引擎;用于复杂报表和深度分析的宽表则选用OLAP引擎。在同一套数据库内混合使用这两种引擎,正是DolphinDB实现HTAP的秘诀。
深度优化的LSM:不止于通用模型
- 很多使用LSM——tree的产品都对它做了改造。以至于很多数据库中他的层数都不一样。
- DolphinDB的LSM实现并非简单套用开源方案,而是针对时序数据也做了改造。
- DolphinDB通过在写入时即建立强有序的排序键,为点查提供了确定性的高效路径。
- 其次,其磁盘文件采用的PAX行列混存格式,在LSM体系中颇为独特。它既保留了LSM顺序写入的优势,又通过列式存储提升了压缩率和分析查询的扫描效率。 此外,它的合并压缩策略专门考虑了时序数据的特性,如对乱序数据的去重和排序,使得整个存储结构更加贴合物联网、金融行情等真实业务的数据流。
目前还是初级了解,详细的还需要再多学习一下。有些可能理解上还有不对的地方,需要去问问原厂。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号