复刻一个java版的Langgraph落地Agent

复刻一个java版的Langgraph落地Agent

春哥大魔王
发布于 2026-03-11 20:39:14
发布于 2026-03-11 20:39:14
继续Agent落地第三篇。
第一篇:Workflow就够用了为了Agent而Agent?
第二篇:谁说Agent必须Chatbot形式Agent必须Chatbot?
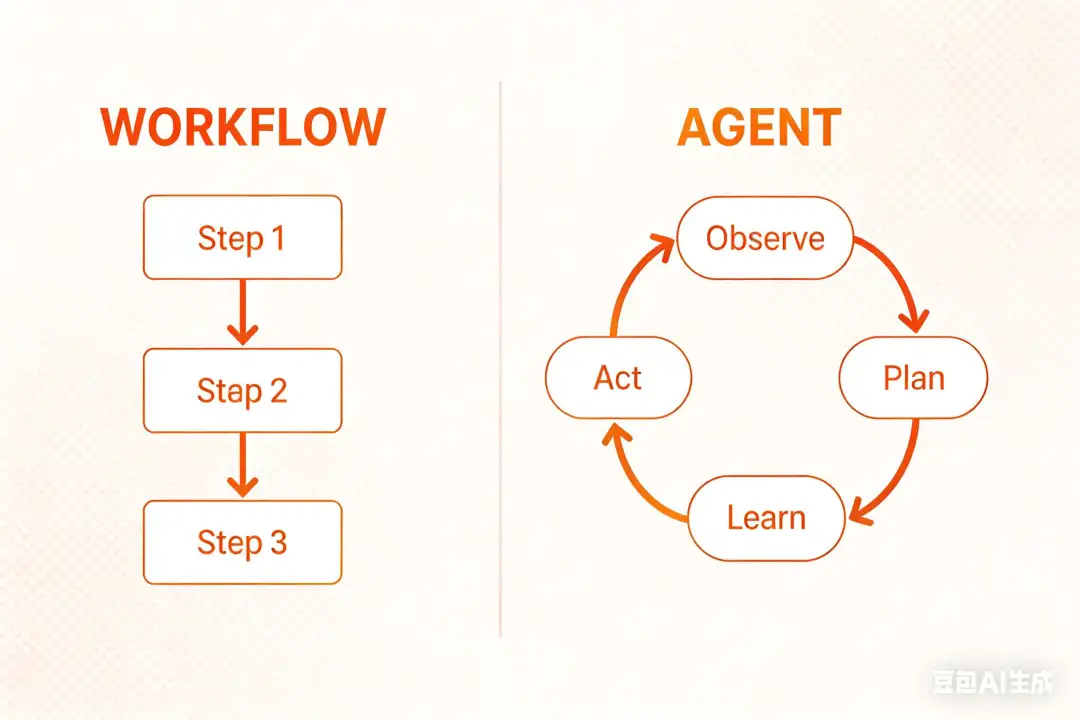
很多人区分Workflow和Agent架构,主要看有没有plan和observe。
我觉得两者没啥本质区别。
图片
其实你好好想一下两者是对等的。
Workflow是一个个step节点串联起来的,同样Agent也是一个个的节点串起来的,只不过有的节点负责plan,有的节点负责observe,有的节点负责act,所以没啥区别,都是Workflow的形式。
为了实现这种节点编排,业界的最佳实践是Langgraph。
它背后的逻辑是将工作流抽象为一个图,通过节点和边定义任务流程(其实也是Workflow),因为有节点和边的抽象,可以注入一些逻辑规则,实现逻辑控制。
Langgraph中有三个关键概念:
1、节点:node,定义了一个的逻辑单元,比如可以是llmNode、codeNode、classifierNode、reflectionNode、human-in-the-loopNode等,来解决一个具体的特定问题;
2、边:edge,连接了两个节点,定义了Graph的走向,边可以是简单边,也可以是条件边,条件边可以注入一些路由规则,将下一个逻辑路由到对应节点;
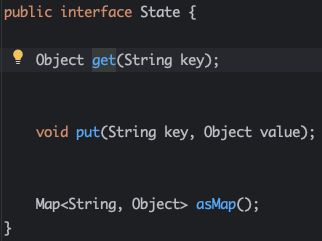
3、状态:state,全局状态存储,用于节点和边共享数据和进行数据交换;
除此之外,还提供了Graph的状态存储,用于执行过程的状态记录及崩溃恢复,还可以用于复杂任务的历史回放。
以上是我问豆包搜Langgraph的基本信息,我又简单看了下Langgraph的源码,虽然没有全看,但已经知道了它大概怎么做,以及怎么解决问题了。
其实代码写多了,你见过很多框架设计,光知道理念,复刻一个框架基本没啥难度。
借助AI Coding,基本上可以逆向出一个java版的Langgraph了。
有人问,为啥要复刻呢?不可以使用Langgraph或者Langgraph4j吗?
原因一:费曼说过:凡事我不能创造的,我都不能理解,学习最好的方式就是创造。
我过去的习惯都是准备在大规模应用之前,先复刻一版,哪怕是lite版本,这样可以更清晰的理解这个框架可以解决什么问题,以及如何用好它。
原因二:Langgraph需要python,Langgraph4j需要springboot3.x+JDK21.
LangChain和Langgraph被诟病的一点是过度封装多了一些,它毕竟是个底层框架,做好了各种可能性抽象和封装这是可以理解的。
但我们系统应用中,如果直接引入会带来一些不必要的复杂度,而且复刻的框架在做加法过程中可以更好的贴近现有系统做扩展,将自己的一些想法加进去。
原因三:成本也不高。
很多人担心所谓重复造轮子,无外乎是ROI是否合理,如果成本不高不是啥问题。
而且有了AI Coding,写代码效率会高很多,所以ROI问题不存在了,多去几次厕所基本写完了。
周末正好翻到了书架上几本书,原来Langgraph和当年设计severless框架思想是一样的,所以会有种似曾相识的感觉。

以下是我画的一个简化的Serverless框架图:
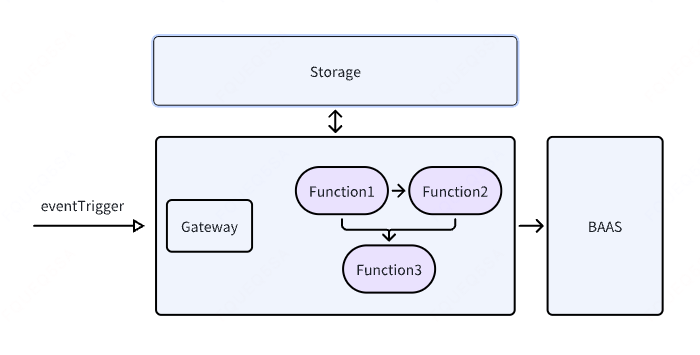
你会发现它和Langgraph的逻辑极其相似,Node节点类比为Function,Function也可以被编排起来形成Workflow和Graph,而且Function是无状态的,所以共享数据一般都是通过共享storage的方式,这和Langgraph通过state共享数据是一样的。
既然设计思路一脉相承,我就不需要继续看Langgraph源码了,按照自己的审美逻辑逆向吧。
以下是我想到的一个Graph的架构图(不确定哪些是和Langgraph一致,哪些有区别),希望对Langgraph更熟悉的同学可以提出更好的解决方案。
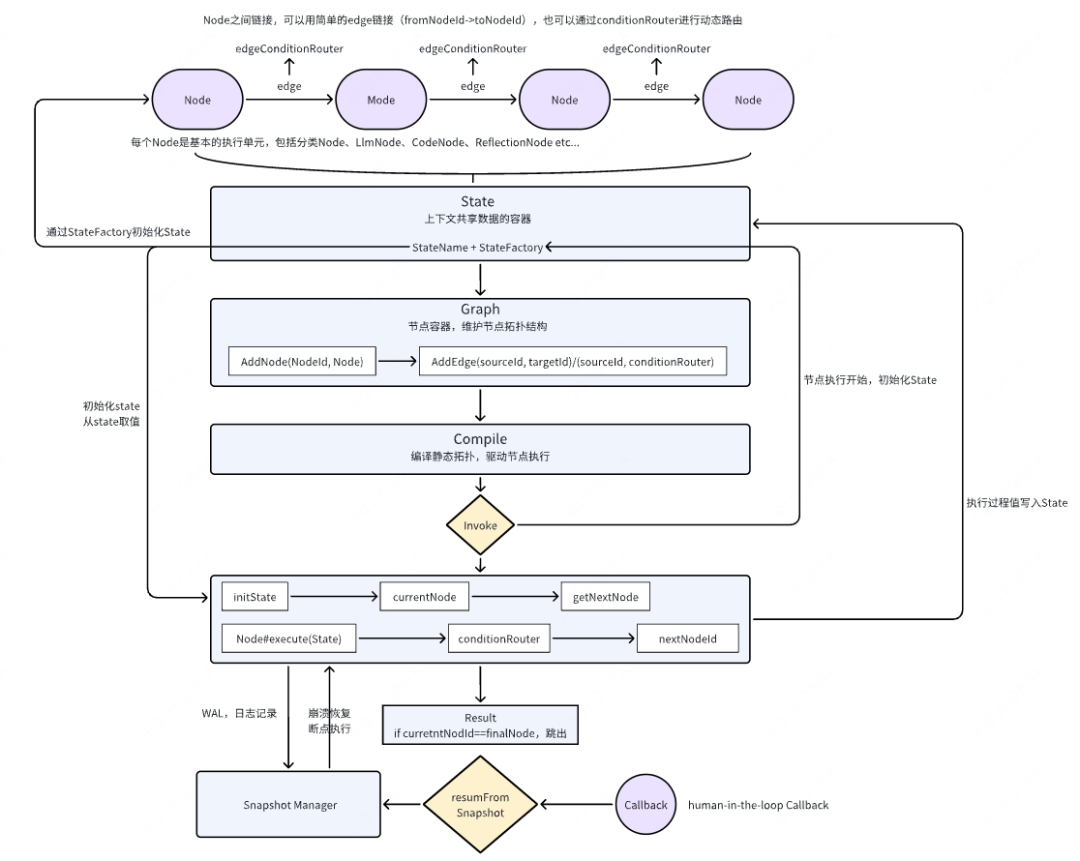
简单介绍下:
1、Node:每个Node都是基本的执行单元,比如分类Node用于意图分类、LlmNode用于封装模型调用、CodeNode用于执行本地热加载代码、ReflectionNode用于对推理结果进行反思检查;
2、Edge:Node之间的连接,可以是SimpleEdge,也可以是ConditionEdge注入逻辑控制;
3、State:上下文共享数据的容器,用于Node和Edge共享和交换数据;
4、StateFactory:state的工厂模式封装,目的是对state更好的管理;
5、Graph:Node通过Edge编排之后形成的图,代表了一整套业务逻辑,运行时会在这个图中找到下一个Node和下一个Edge;
6、Invoke方法:图出发执行的入口方法;
7、resumeFromSnapshot方法:崩溃恢复的回调入口,可以在human-in-the-loop节点之后回调恢复图执行;
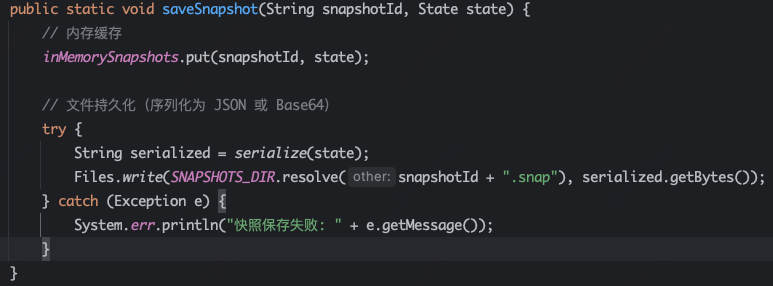
8、SnapshotManage:图执行过程的快照记录,可以通过内存+持久化方式将执行路径记录下来,用于事后的流量回放检查;
看一些关键源码,更好的理解。
首先是Node节点,每个Node节点都有自己在图中唯一的id,execute是核心方法,isAsync可以将这个节点变成异步节点,不阻塞主线程。
public interface Node { String getId(); State execute(State state); boolean isAsync(); // 是否异步执行 // 默认同步执行 default Node async() { return new AsyncNodeWrapper(this); } }
以一个分类器节点说明,图的入口往往从一个意图分类节点开始的,借助关键词、规则、模型识别进行意图识别,将识别出的意图放到State中,供后续流程使用。
public class ClassifierNode implements Node {
private final static String id = "classifier_node";
@Override
public State execute(State state) {
// 分类器,基于用户输入进行分类
String category = classificationService.classify(state);
state.put(StateConstValue.CATEGORY_RESULT, category);
return state;
}再说一个常见的LlmNode,这个节点里面对模型调用进行了封装,比如封装了PromptTemplate或tools调用,从State中获取Input,模型调用结果放到last_output。
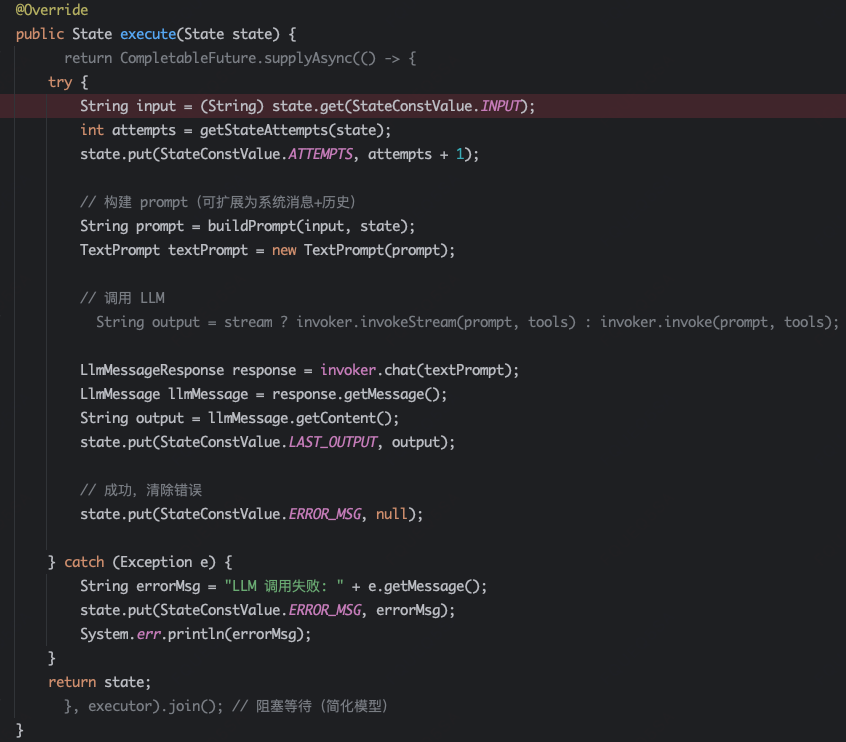
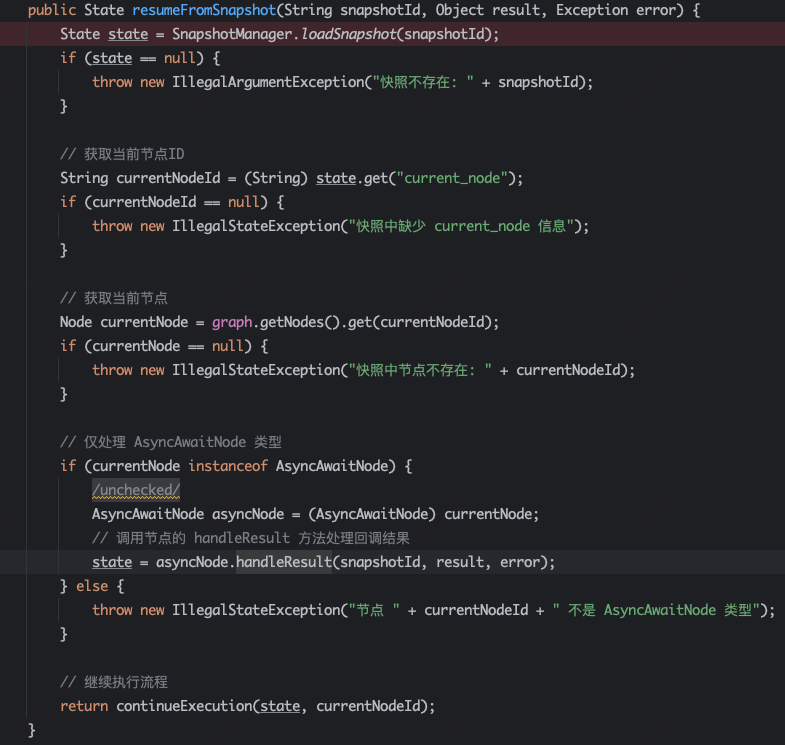
再看一个AwaitNode节点,这是一个较为特殊的节点,服务于human-in-the-loop人工介入,比如需要人审批,那么先跳出主流程,人工审批完成之后,再通过持久化记录跳回主流程(Callback->resumeFromSnapshot)。
public class ApprovalNode extends AsyncAwaitNode { private static final String id = "approval_node";
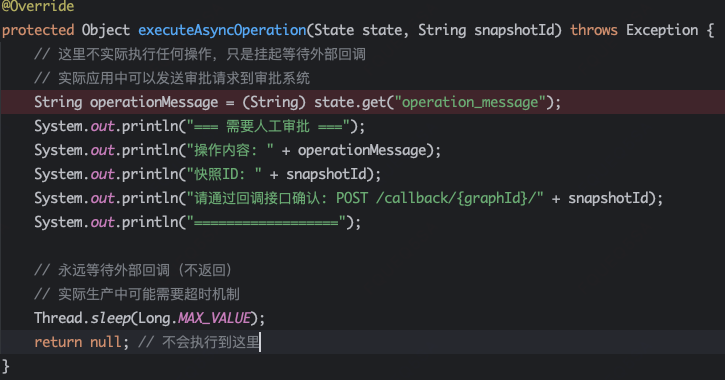
我们再看看边的定义,主要包括边的其实节点sourceNodeId和边的目标节点targetNodeId。
public interface Edge { String getSourceNodeId(); String getTargetNodeId(State state); default String getLabel() { return ""; } // 可选标签,用于可视化 }
边主要有两类,SimpleEdge和ConditionEdge。
public class SimpleEdge implements Edge { private final String source; private final String target; public SimpleEdge(String source, String target) { this.source = source; this.target = target; }
public class ConditionalEdge implements Edge { private final String source; private final ConditionRouter router; private final String label; // 可选标签 private final Set<String> possibleTargets; // 所有可能的目标节点(用于可视化)
@Override public String getTargetNodeId(State state) { return router.route(state); // 运行时使用 }
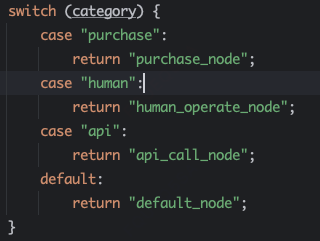
条件边主要通过继承条件边的实现类实现具体router逻辑,实现将targetNodeId路由到指定节点。
@FunctionalInterface public interface ConditionRouter { String route(State state); }
比如分类router:
public class ClassificationRouter implements ConditionRouter
State主要用于数据共享与交换,它是一个Map数据结构,以key-value形式存取数据。
SnapshotManage通过内存和文件方式存储和加载数据。
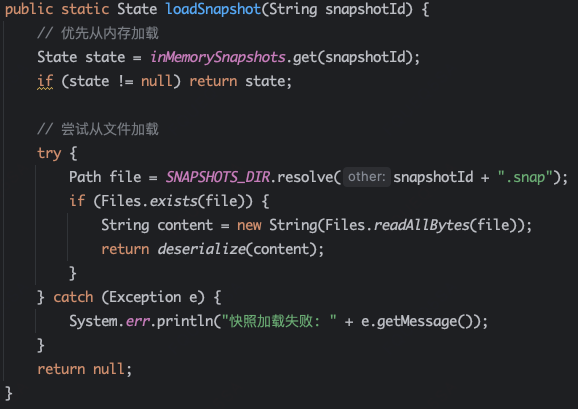
接下来看下Invoke核心方法,基本逻辑是从__start__节点开始,不断从图容器中找到下一个节点执行,执行完成之后通过边找到下一个节点,继续执行。

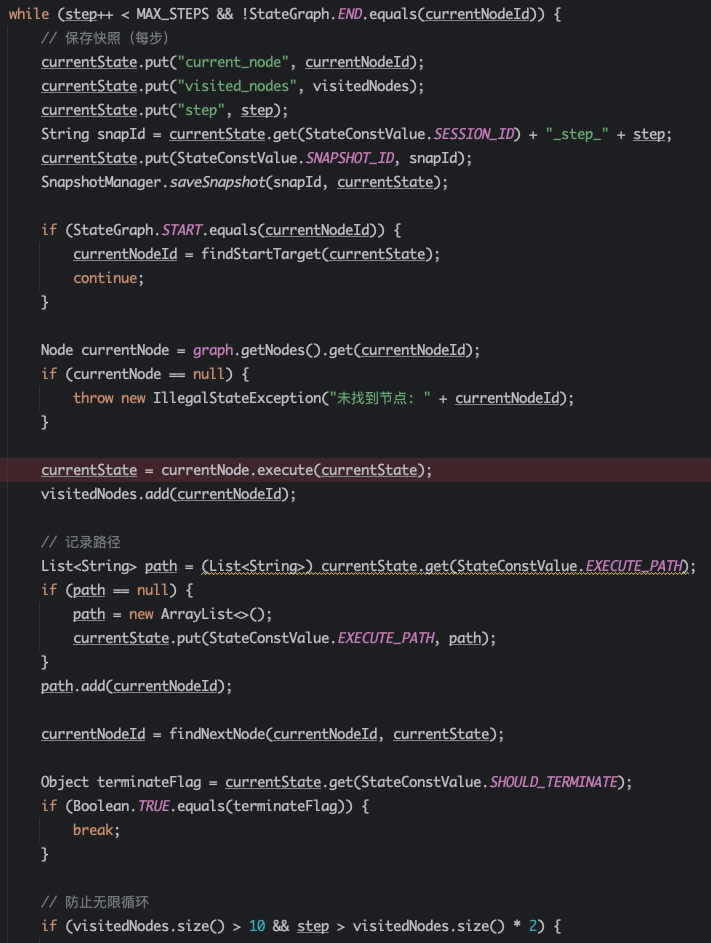
resumeFromSnapshot方法,用于崩溃恢复或者human-in-the-loop的回调,先从存储拿到快照,恢复执行,逻辑同Invoke类似。
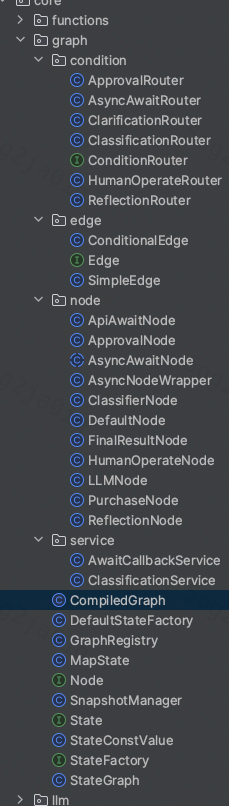
整体代码结构如下。
接下来用简单示例看下怎么用。
先看一个简单示例:
"如果我以每小时 60 英里的速度开车 2 小时,这段距离相当于多少公里?";这里面涉及到一个反思逻辑,就是需要将英里单位转换成公里。
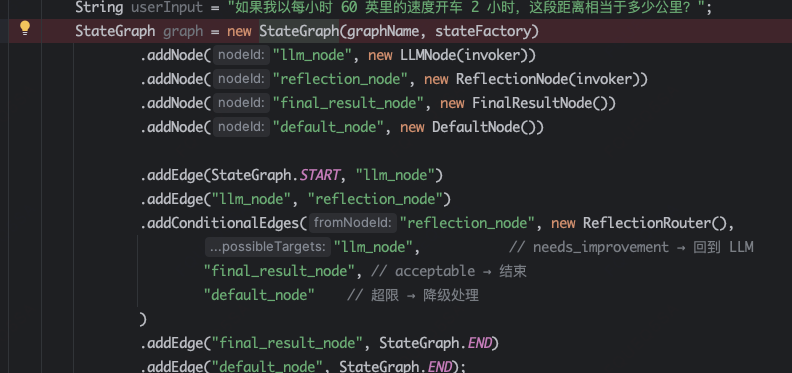
先用llmNode分析,如果Llm不够智能,得到的结果是2x60英里,就直接输出了。
此时有了一个ReflectionNode,可以进行反思。
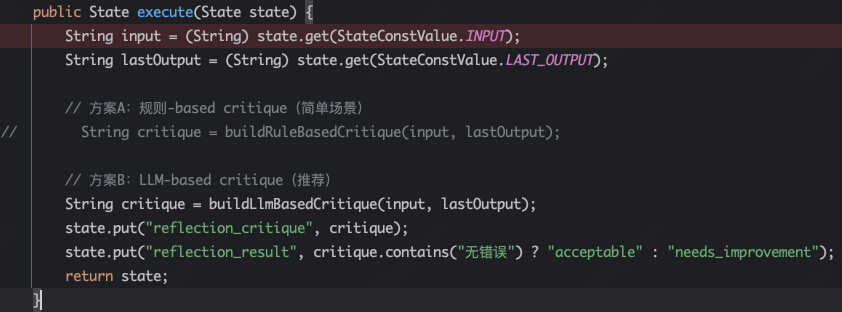

将用户原始问题,和模型推理的内容一起交给一个更智能的模型,这个模型会发现存在单位转换问题,于是生成错误分析结果:
未进行英里到公里的单位转换...此时将用户原始问题,第一轮模型推理结论,以及反思模型检查结果,重新组成上下文,再推给第一轮的模型,这样模型可以生成正确的结果。
直到推理模型认为无错误,才继续后续流程,也就是生成finalResult。
我们再看一个相对复杂的示例。
用户说:我下周去北京,帮我把行程改一下——航班改签、旧酒店取消、换一家离新会议地点近的、再加个租车。这个任务,涉及到多意图识别、任务规划、工具调用、结果生成。
图编排如下:
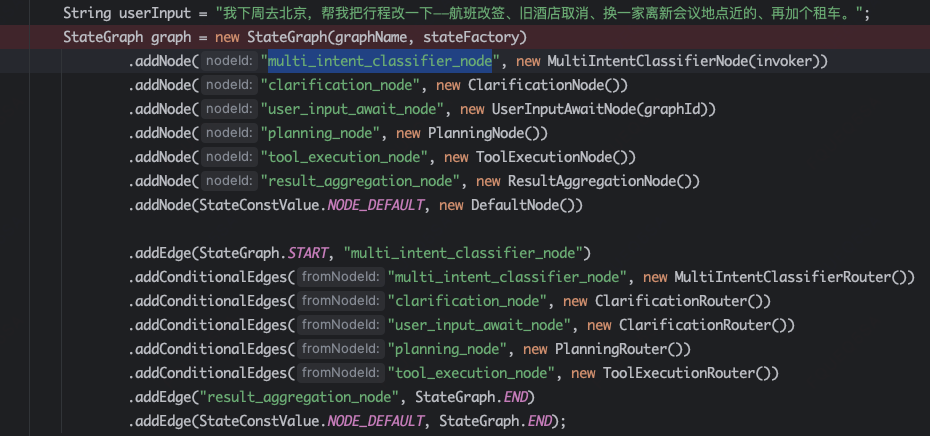
1、首先进行多意图分类:multi_intent_classifier_node
2、模型推理之后发现信息缺失,需要用户补齐澄清:clarification_node
3、此时触发human-in-the-loop节点,获取用户输入(如通过websocket im获得输入):user_input_await_node
4、用户输入内容之后,带着新输入和历史上下文重新回到多意图分类节点:multi_intent_classifier_node
5、模型不断进行推理验证,确认没有需要进一步澄清信息之后,进入规划节点:planning_node
6、规划节点基于意图,创建多个任务执行,如工具调用:tool_execution_node
7、所有任务执行完成之后,生成结果合并输出:result_aggregation_node
多次澄清节点循环示意图如下:

至此,通过复刻的Langgraph框架,实现了一个具有反思、推理、澄清、意图分类的Agent了。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-12-29,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号