智谱Glyph:把信息,压缩成图片


昨天,DeepSeek 发了 OCR 用图片来理解信息,缩减上下文

低清无码,不影响识别《通过视觉,确实可以压缩信息》
刚刚的,智谱发了 Glyph 把信息压缩成图片,缩减上下文
Git:https://github.com/thu-coai/Glyph
公众号后台回复:Glyph,获取报告论文 pdf
两个团队,同一时间 把目光投到了「用视觉方式,表达信息」 领域一致,路径互补
Karpathy 今天也发推了
Karpathy 前两天录了个很棒的播客:Andrej Karpathy 2小时访谈:未来十年,没有 AGI,只有 Agent |附:中文版音频
Glyph 在做什么
Glyph 的新思路 把信息渲染成图像,然后用模型处理 对于纯文本输入 通过搜索的方式,找到效率最高的渲染方式
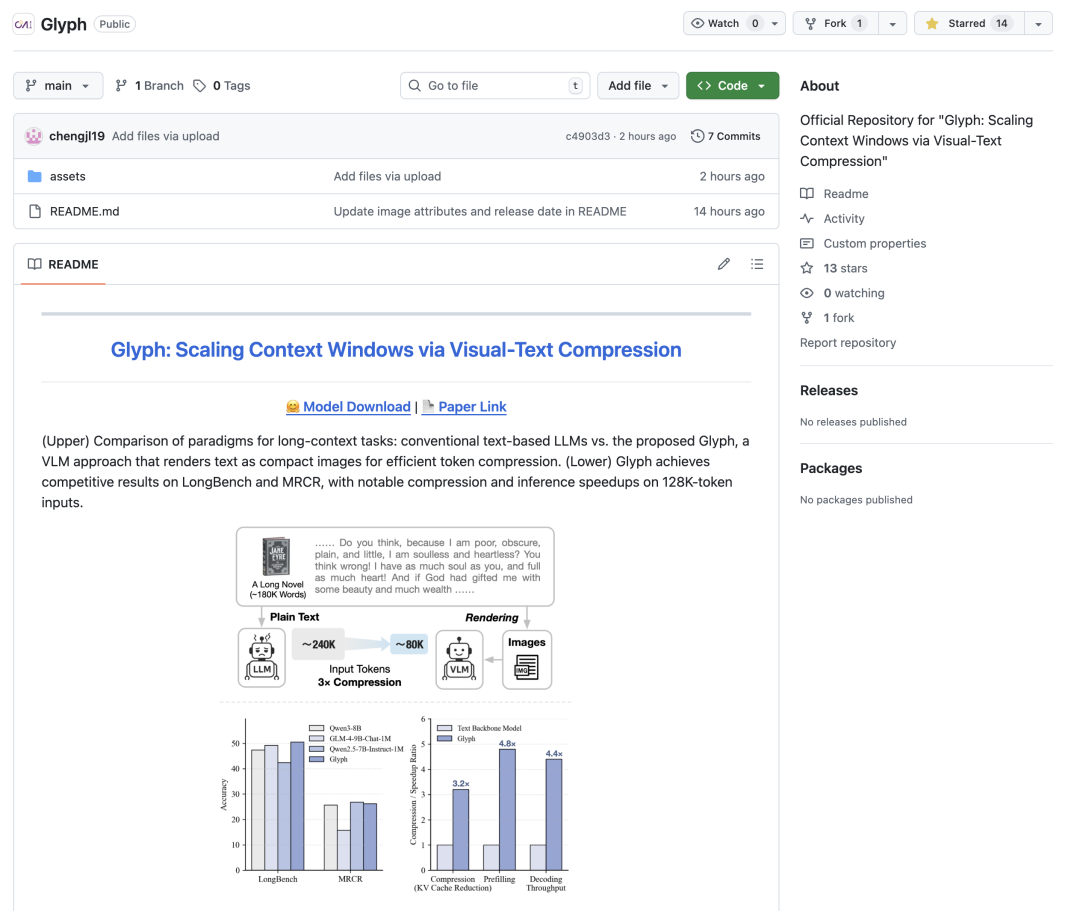
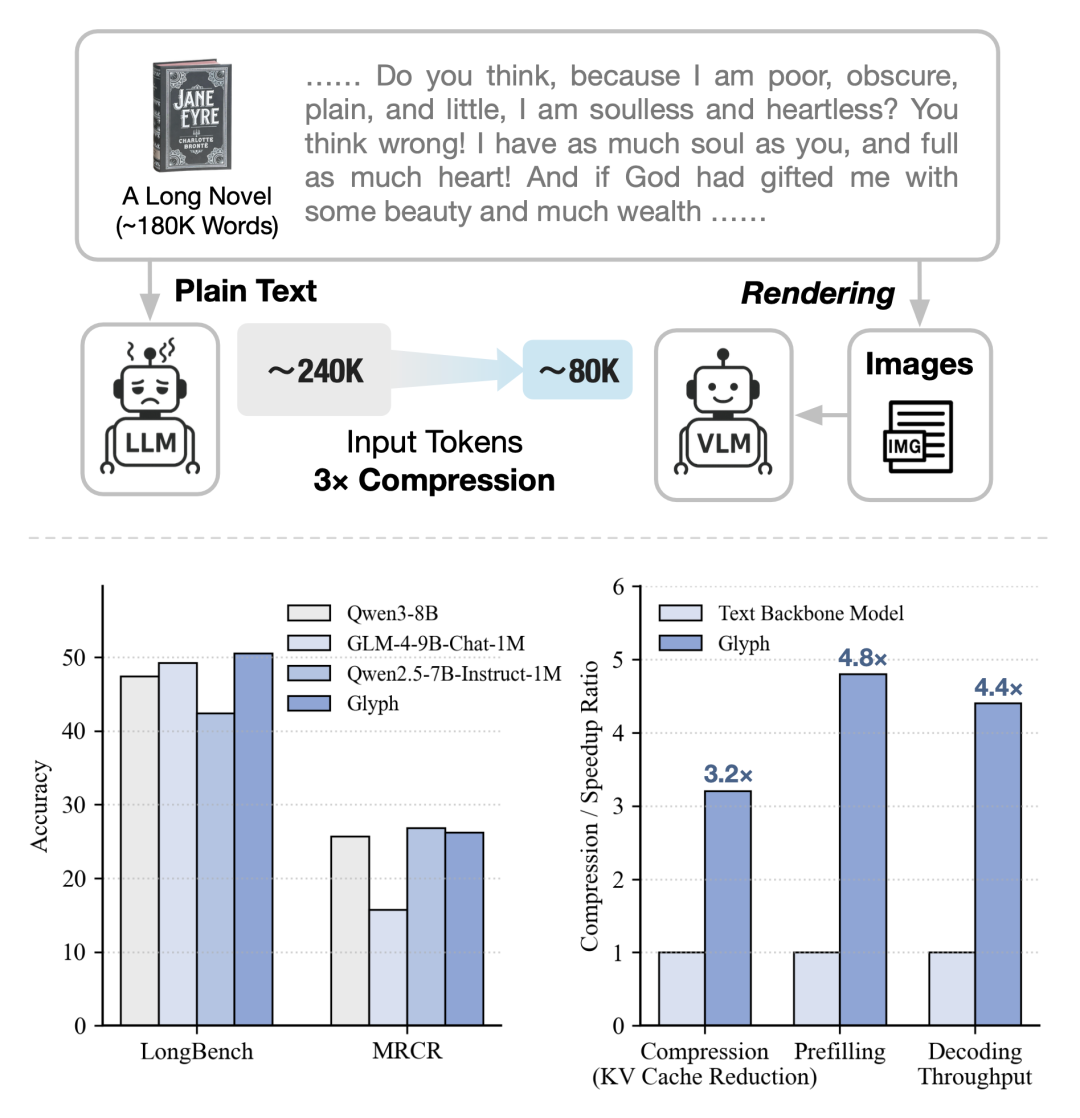
比如处理一本小说《简爱》 约 240K tokens 128K 窗口装不下,必须截断
Glyph 把整本小说渲染成图像 大概 80K 视觉 tokens 128K 窗口就能装下了 这样模型能看到完整上下文 回答问题时不会因为截断丢信息
方法分三个阶段:
持续预训练 把大规模长文本渲染成各种视觉风格 教 VLM 理解渲染后的文本 用了 document_style、web_style、dark_mode、code_style 等多种风格
LLM 驱动的渲染搜索 用遗传算法 + LLM 自动找最优渲染配置 DPI、字体、字号、行高这些参数 LLM 来指导怎么组合 找到压缩和性能的最佳平衡
后训练 用找到的最优配置做 SFT 和强化学习 同时加入 OCR 对齐任务 增强识别能力
和 DeepSeek 的异同
很多人可能会疑问 这和 DeepSeek-OCR 有什么差别么
DeepSeek-OCR vs Glyph
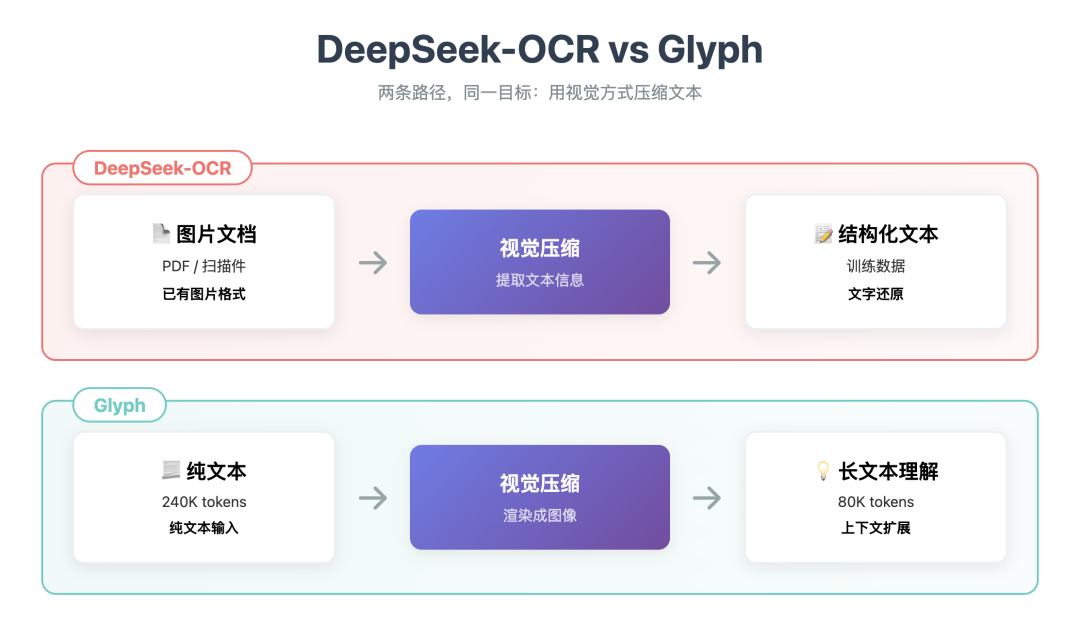
切入点不同:
DeepSeek-OCR: 从图像中提取信息
针对的是已经是图片格式的文档 更像是一个思想实验,验证了视觉压缩的可行性 同时 imply 了一个可能性: 在纯文本任务中,也能做视觉压缩 而不只是 OCR
Glyph: 把信息渲染成图像
这里,针对的是纯文本输入 真正验证了这个可能性 把视觉压缩应用到通用长文本任务
只从事情上来说 两个团队解决的问题不一样 无法进行「好或者坏」的比较
应用场景不同:
DeepSeek-OCR 用来做 OCR、处理 PDF、生产训练数据 聚焦于真实文档 OCR 任务 验证的是视觉压缩下的文字还原能力
Glyph 用来扩展长上下文、处理超长文本 应用到更广泛的通用长文本任务 真正验证了利用视觉模型实现上下文扩展的可行性
但底层逻辑一致: 用视觉方式表达文本,效率更高 两者都从「视觉压缩」出发 利用视觉 token 承载更多的文本信息
LLM 驱动的搜索
先看个 Glyph 的数据:
在极限压缩下(8× 压缩)
- • 128K 窗口处理 1M tokens 的文本
- • 某些任务上性能会有影响
平衡配置(3-4× 压缩)
- • 在各类任务上不会掉点太多
- • 性能和 Qwen3-8B 相当
- • 4.8× 更快的 prefilling
- • 4.4× 更快的 decoding
在这里有个挺聪明的设计 Glyph 让 LLM 作为评委 分析当前配置的效果 DPI、页面大小、字体、字号、行高、对齐方式...
从而搜索最高效的视觉渲染方案
效果: 随机配置:40.91 分 人工配置:43.62 分 LLM 搜索配置:45.60 分
效果如何
在 LongBench 和 MRCR 上 Glyph 的表现和 Qwen3-8B、GLM-4-9B-Chat-1M 相当
性能对比图
LongBench 平均压缩比 3.3× MRCR 平均压缩比 3.0× 随着输入长度增长,Glyph 的优势越来越明显
还有个意外发现 虽然训练数据主要是渲染的纯文本 但在真实多模态文档任务上也有提升 MMLongBench-Doc 总体准确率 从 29.18% 提升到 45.57%
最后
在这个时间节点上 大家都开始了视觉压缩的探索 用视觉方式表达信息,效率更高 毕竟:低清无码,不影响识别
DeepSeek 从图像提取信息 针对已经是图片格式的文档 验证视觉压缩下的文字还原能力
智谱把文本变成图像 针对纯文本输入 验证利用视觉模型实现上下文扩展的可行性
领域一致,路径互补 江山代有才人出,各领风骚好几天
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-10-21,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号