FPGA 上的脉冲神经网络:方法论和最新进展综述

FPGA 上的脉冲神经网络:方法论和最新进展综述

CreateAMind
发布于 2026-03-11 17:46:22
发布于 2026-03-11 17:46:22
Spiking neural networks on FPGA: A survey of methodologies and recent advancements FPGA 上的脉冲神经网络:方法论和最新进展综述
https://www.researchgate.net/publication/389054889_Spiking_neural_networks_on_FPGA_A_survey_of_methodologies_and_recent_advancements
本文综述了脉冲神经网络(SNNs)在FPGA上的实现方法,聚焦输入编码、神经元模型、学习规则和网络架构。介绍近期进展,如CORDIC加速、Vivado HLS优化及Transformer集成,展示SNN在图像识别、机器人控制等领域的低功耗优势。分析挑战,如资源限制和通信延迟,提出未来方向:深度学习结合、分布式FPGA及AI辅助设计。适合研究者了解SNN-FPGA的最新技术和应用。


摘要:
在信息处理中对生物大脑结构的模拟,使脉冲神经网络(SNNs)相比传统系统展现出显著降低的功耗。因此,近年来这些网络获得了越来越多的关注,并激发了大量研究工作,提出了各种结构以实现低功耗、高速度和更高的识别能力。然而,研究人员在开发更高效、更接近生物大脑的神经网络方面仍处于初级阶段。此类开发与研究需要具备适当能力的硬件平台来执行,而现场可编程门阵列(FPGA)相比现有的中央处理器(CPU)和图形处理器(GPU)等硬件,是一个极具潜力的候选方案。FPGA具备与大脑类似的并行处理能力、更低的延迟和功耗,以及更高的吞吐量,因此是协助脉冲神经网络开发的理想硬件。本综述旨在通过收集和分析近期相关研究成果,以及阻碍这些网络在FPGA上实现的挑战,为研究人员进一步推进该领域的发展提供便利。
- 引言 随着人工智能(AI)在各个领域的迅速普及,针对模型的能耗和延迟进行优化变得愈发重要。尽管已有多种方法用于提升深度学习的效率,但神经形态计算(neuromorphic computing)采取了一种独特的思路:借鉴支撑大脑卓越能效的原理。脉冲神经网络(Spiking Neural Networks, SNNs)通过将数据编码和处理为电脉冲(即“脉冲”或“spikes”)来模拟大脑,有望通过稀疏激活和事件触发计算减少数据瓶颈,并通过降低位宽简化计算,从而显著降低神经网络的能耗(Liang 等,2021;Eshraghian 等,2023;Maass,1997)。在事件触发计算中,仅在生成脉冲(事件)时才进行处理,从而最大限度地减少不必要的操作并节省能量(Shahsavari 等,2023)。与传统人工神经网络(ANNs)相比,SNNs 在处理序列数据时具有更高的潜在效率(Lemaire 等,2020;Ottati 等,2023;Azghadi 等,2020)。鉴于便携式、资源受限设备日益普及,降低嵌入式AI的功耗至关重要(He 等,2021)。
脉冲神经元通过发放脉冲来传输数据。在空间上分布的脉冲可并行处理,而在不同时间触发的脉冲则可串行处理。在没有脉冲活动时,所需的内存访问更少,尽管基于脉冲的工作负载仍可从并行处理中获益。CPU 的并行化能力有限,而 GPU 拥有大量核心,可适配高度并行化的工作负载。深度学习社区已充分利用这一特性,在层间进行张量的批处理。张量是一种多维数组,常以矩阵或更高阶形式表示数据,能够高效处理深度学习中的大规模计算任务。基于脉冲的激活具有稀疏性,导致张量中大量子块处于非活跃状态,而 GPU 并未针对稀疏性进行有效优化,也无法通过重新编程来解决这一问题(Y. Liu 等,2022)。此外,CPU 和 GPU 普遍采用的冯·诺依曼架构虽支持通用计算,却因频繁在内存与处理单元之间传输数据而造成高功耗(He 等,2021;Dabbagh 等,2025)。将内存与处理器集成可在牺牲通用工作负载处理能力的前提下加速计算并降低功耗,但随着深度学习处理需求的持续增长,这种权衡通常是必要的(S. Yang, Gao 等,2021;Eshraghian, Wang & Lu,2022)。
将内存与处理器集成被视为遵循“神经形态”计算范式,因为大脑并不将内存与计算分离。相反,其计算单元(神经元)与存储单元(突触)相互交织、紧密集成。图1展示了冯·诺依曼架构(图1(a))与神经形态处理的一般概念(图1(b))(An 等,2017)。鉴于大脑是世界上最高效的计算系统,借鉴其工作机制有望显著降低认知计算的功耗。这需要定制硬件,其架构需类似大脑,而神经形态工程的一个共同主题正是通过专用集成电路(ASICs)或现场可编程门阵列(FPGAs)来实现这一点(Shahsavari 等,2019, 2015)。
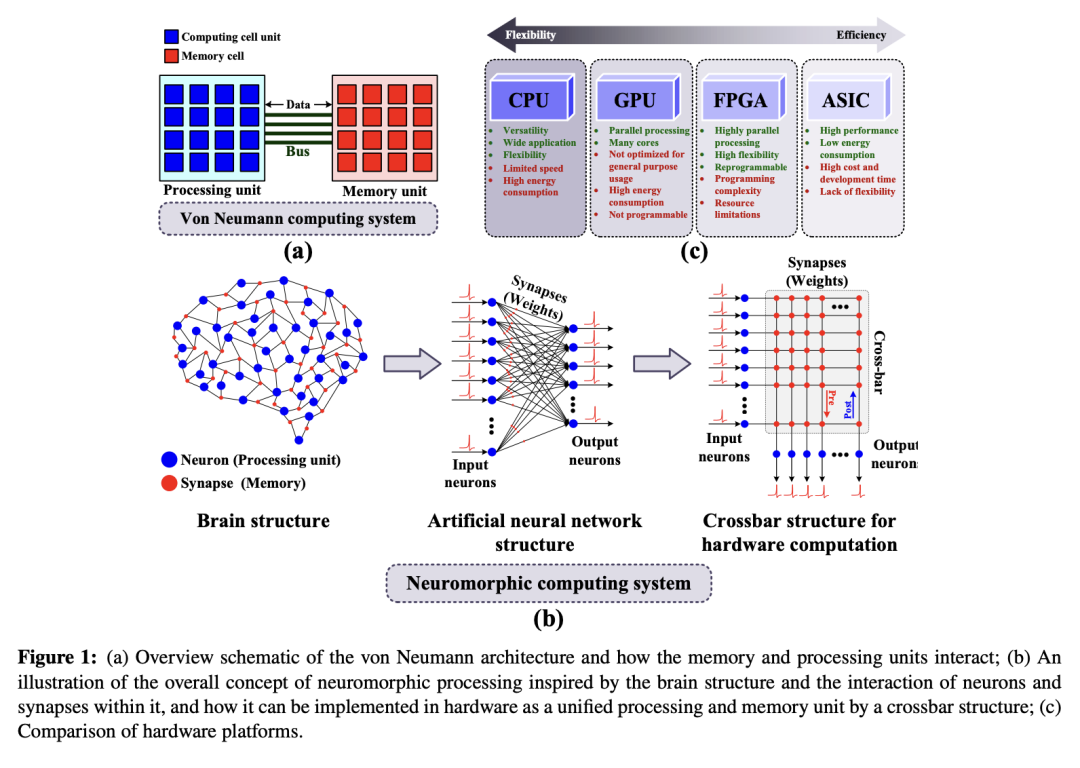
与 CPU 和 GPU 相比,FPGA 因其高度灵活性、可编程性、并行处理能力以及低功耗特性,在快速测试和迭代定制 SNN 加速器方面极具价值(Gupta 等,2020;K. Wang 等,2023)。图1(c) 提供了不同平台的总体比较(Capra 等,2020)。FPGA 还可用于测试新颖或新兴的脉冲架构,并通过软硬件协同设计方法更准确地评估所能获得的能效提升。然而,FPGA 实现带来的挑战比软件编程(如 Python)更为复杂。因此,本文综述了 SNN 在 FPGA 上的实现,涵盖执行方法、当前研究重点、挑战、具体应用以及未来需解决的研究空白。本综述可帮助需要轻量级硬件解决方案的深度学习从业者更好地理解其模型将运行的硬件平台,同时也可协助 FPGA 工程师了解未来需加速的模型类型。
1.1 关于 SNN 的元综述 我们对一系列与本综述互补的综述文章进行了元综述,详见表1。从计算栈底层开始,J.-Q. Yang 等(2020)重点综述了基于新兴器件的 SNN;Basu 等(2022)全面回顾了关键的基于脉冲的定制集成电路(ICs);Bouvier 等(2019)则上升到 SNN 的硬件架构层面。Javanshir 等(2022)和 Nguyen 等(2021)考察了 SNN 在各类硬件平台上的最新实现进展。从软件视角出发,Pietrzak 等(2023)聚焦于适用于硬件执行的学习算法及其复杂性,而 Huynh 等(2022)则探讨了涵盖平台化设计与软硬件协同设计的软件框架。最后,Frenkel 等(2023)深入研究了面向 SNN 定制 ASIC 实现的自上而下与自下而上设计方法的融合,特别强调协同设计;Roy 等(2019)则对基于脉冲的计算进行了高层次综述。就 FPGA 相关工作而言,Pham 等(2021)对多种在 FPGA 上部署 SNN 的研究进行了高层次概述,并提供了应用层面的综述;S. Yang 与 Chen(2024)则提供了近期关于神经形态智能系统的综合性资源之一。尽管该著作主要强调神经科学和学习理论层面,并探讨了不同架构,但并未深入覆盖 FPGA 实现。我们的目标是提供一个更近期的、聚焦于 FPGA 上学习与推理的综述,并深入剖析和综合这些设计高效有效的关键因素。

鉴于算法快速演进与 ASIC 设计周期漫长之间的矛盾,迫切需要基于 FPGA 的探索以推动软硬件协同设计。本综述旨在深入探讨实现细节、SNN 各组成部分的执行方式、不同架构之间的权衡,以及 FPGA 特有的技术,以帮助 SNN 开发者更好地利用 FPGA 所支持的快速设计迭代优势。
1.2 方法与结构安排 在本综述中,我们的重点聚焦于那些在SNN的FPGA实现中已被广泛使用、反复采用并普遍接受的成熟技术和方法。我们首先介绍理解SNN所需的基础概念,然后通过分析以往各类工作中对SNN各组成部分的实现方式,深入探讨其在FPGA上的具体实现。
本文将SNN的FPGA实现划分为四个主要方面,这些方面在大多数设计中均需予以考虑,包括: 1)将不同类型输入数据编码为脉冲; 2)各类脉冲神经元的实现; 3)学习规则,即突触权重如何更新; 4)网络架构与系统设计,涵盖SNN在FPGA上的整体设计与执行,并依赖于前述三个类别。
此外,本节还将讨论稀疏性——SNN的关键特性之一——以及如何在FPGA上有效利用这一特性。在涵盖上述四点之后,我们将进一步深入探讨已实现特定应用的技术方法,并基于这些文献识别当前领域中存在的研究空白,同时展望未来工作的可能方向。
本文的结构安排如下: 第2节首先考察SNN的基本概念; 第3节探讨其在FPGA上的实现; 第4节讨论SNN在现实世界中的具体应用及其实施方式; 第5节将阐述SNN/FPGA领域所面临的挑战与研究空白,并指出未来工作中应给予更多关注的方向; 最后,第6节对全文进行总结。
- 预备知识 本节将深入探讨以脉冲神经网络(SNN)为核心的主题,包括:突触可塑性、各类神经元模型、学习原理以及数据编码。
2.1 突触可塑性
突触为神经元之间传递信息提供了通路,在生物有机体神经系统的信息处理中起着关键作用(L. Abbott & Regehr, 2004)。大量实证研究表明,突触在神经活动过程中表现出依赖于活动的特性,而突触可塑性——即突触根据其活动水平的增强或减弱而随时间加强或削弱的能力——被广泛认为是生物系统中学习与记忆的基础(Sjöström 等, 2008)。神经元之间突触连接的强度受突触前与突触后活动在不同时间尺度上时序关系的影响(Bi & Poo, 1998)。突触可塑性大致可分为两类:1)长时程可塑性(long-term plasticity),指持续数小时或更长时间的突触变化;2)短时程可塑性(short-term plasticity),指在数十毫秒至数分钟时间尺度上表现出的某些依赖于活动的特性(Lynch 等, 1977;J.-Q. Yang 等, 2020)。
长时程可塑性可进一步分为长时程增强(Long-Term Potentiation, LTP)和长时程抑制(Long-Term Depression, LTD)。LTP 是指两个神经元之间的信号传递因受到高强度刺激而产生的持久性增强。相反,LTD 则表现出与 LTP 相反的效果,即连接被削弱或“抑制”(Bear & Malenka, 1994;J.-Q. Yang 等, 2020)。
短时程可塑性在神经系统计算中至关重要。与长时程可塑性类似,短时程可塑性也可根据突触强度的变化分为两类:短时程增强(Short-Term Potentiation, STP)和短时程抑制(Short-Term Depression, STD)。
脉冲时序依赖可塑性(Spike-Timing-Dependent Plasticity, STDP)认为,突触前和突触后神经元的活动时序将决定突触连接强度如何通过 LTP 和 LTD 进行调整。STDP 通常被认为在神经系统执行时序依赖的计算任务中发挥关键作用,至少对更高层次的时序依赖学习有所贡献。接下来的小节将深入探讨 STDP 模型。尽管 STDP 是最常被引用的可塑性机制之一,但突触计算和神经信号处理还需要其他类型的可塑性,包括突触重分布(synaptic redistribution)、脉冲频率依赖可塑性(Spike-Rate-Dependent Plasticity, SRDP)、联想学习(associative learning)、非联想学习(non-associative learning)以及突触缩放(synaptic scaling)(Brenowitz & Regehr, 2005;Citri & Malenka, 2008;L. F. Abbott & Nelson, 2000;J.-Q. Yang 等, 2020)。值得注意的是,要理解生物神经系统的工作机制,必须认识到突触可塑性的核心作用。STDP 是模拟和实现生物神经系统时最常被引用的可塑性形式之一。为了更好地理解 STDP,有必要阐明其源于赫布定律(Hebb’s law)的背景。
2.1.1 赫布规则(Hebb’s Rule)
在过去五十多年(甚至更久)中,大量科学实验致力于研究突触可塑性的底层机制。其中大多数研究都基于赫布规则。该规则指出,对于一对神经元(称为神经元 A 和神经元 B),其连接应按如下方式调整(Hebb, 2005):
“当细胞 A 的轴突足够靠近细胞 B 并反复或持续地参与激发 B 时,A 和 B 中的一个或两个细胞会发生某种生长过程或代谢变化,使得 A 作为激发 B 的细胞之一,其效率得到提升。”
Shatz(1992)在其关于视觉系统的研究中对此进行了更简洁的总结:“一起放电的细胞会连接在一起”("cells that fire together wire together")。简而言之,赫布定律指出:当两个神经元在物理上彼此靠近,且突触前神经元引发突触后神经元放电时,它们之间的连接会增强;反之,如果突触后神经元先于突触前神经元放电,则它们的连接会减弱。后一种情况表明这两个神经元之间缺乏因果关系,突触后神经元很可能是被其他神经元而非该突触前神经元所激发。这一原理启发了研究人员尝试以之为模型,复制大脑机制,并设计功能类似的硬件。为实现这一目标,已提出多种模型,其中最流行的一种便是 STDP。
2.1.2 脉冲时序依赖可塑性(STDP)
STDP 因实验上验证了赫布规则而获得广泛关注,其完全依赖于突触前与突触后神经元之间的时序关系,如图2所示(Shouval 等, 2010)。因此,STDP 可被视为赫布更一般性规则的一种具体实现形式。STDP 表明:若突触前神经元在突触后神经元之前以较小的时间差放电,则它们之间的连接会增强,这对应于 LTP 活动;随着该时间差增大,连接强度的变化呈指数衰减。这为赫布定律提供了定量支持——即神经元之间较小的时间差意味着它们在空间上距离较近,且突触前神经元很可能负责激发了突触后神经元。
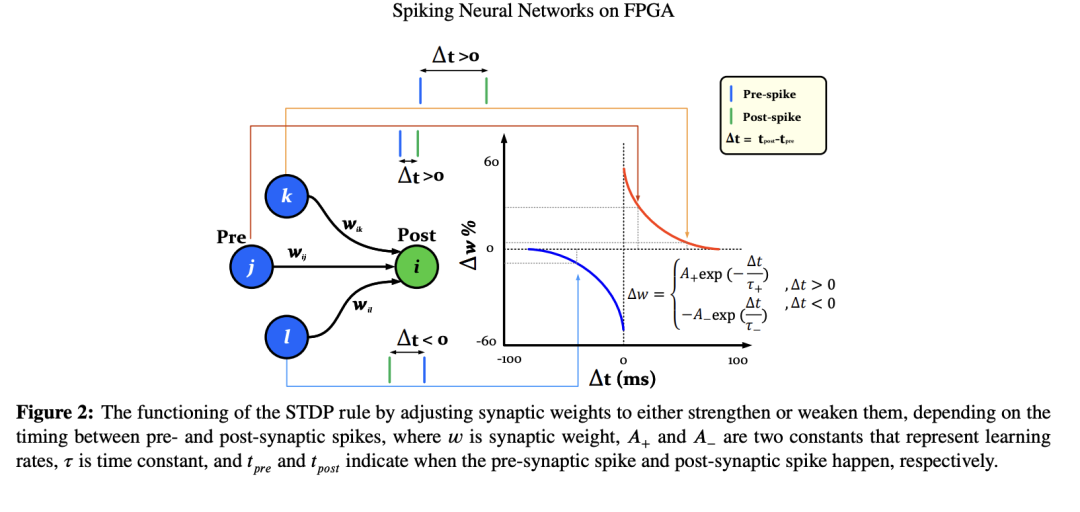
相反,若突触后神经元先于突触前神经元放电,则连接强度应减弱,从而导致 LTD。时间差越小,连接强度的减弱程度越大。计算时间差并确定连接强度变化幅度的公式如图2所示(Bi & Poo, 1998)。在神经网络的语境下,这种连接强度的变化对应于模型的权重更新。
2.2 脉冲神经元模型
神经元之间的可塑性依赖于神经元如何激活并相互“交流”,因此所采用的神经元模型将决定网络随时间演化的具体方式。目前已开发出大量神经元模型,其中一些追求生物真实性,另一些则侧重于计算简洁性。选择合适的模型取决于对精度或计算效率的需求。以下小节将讨论最常用的几种模型。
2.2.1 霍奇金–赫胥黎模型(Hodgkin–Huxley Model)
霍奇金与赫胥黎(Hodgkin & Huxley, 1952)提出的 HH 模型是保留离子通道丰富动力学行为的最常见模型之一,其源自对大型鱿鱼神经元的实验。在 HH 模型的方程组中,包含两种类型的 Na⁺ 和 K⁺ 离子通道,用于生成神经元的输出电流和动作电位:
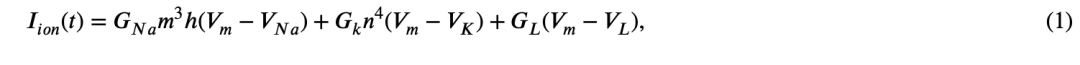

通过求解上述方程组,该模型能够模拟脉冲产生过程中膜电位的行为。尽管该模型具有较高的生物真实性,但其计算开销较大,在实现大规模网络时会消耗大量资源(Yamazaki 等,2022),尤其是在资源受限的 FPGA 实现中尤为明显。此外,根据 Paugam-Moisy 与 Bohte(2012)的说法,HH 模型在每毫秒的仿真中大约需要 1,200 次浮点运算(FLOPS)。
2.2.2 伊热凯维奇模型(Izhikevich Model)
受 HH 方法启发,并旨在对其进行简化,Izhikevich(2003)提出了一种计算量更少且精度令人满意的模型。该模型将 HH 神经元模型中的众多参数简化为以下所示的二维常微分方程组:
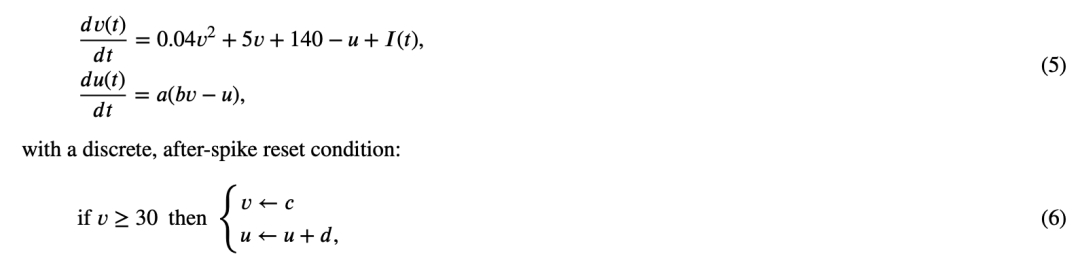
其中,𝑣 表示膜电位,𝑢 表示 K⁺ 通道的激活和 Na⁺ 通道的失活,负责神经元膜电位的恢复过程,𝐼 为突触输入电流,在神经元处进行积分。 一旦膜电位达到 +30,恢复变量和膜电位将根据公式(6)进行重置。参数 𝑎 决定恢复速度,通常设为 0.02;参数 𝑏 通常取值为 0.2,表示恢复变量 𝑢 对膜电位阈下振荡的敏感程度。脉冲发放后膜电位 𝑣 和恢复变量 𝑢 的值由参数 𝑐 和 𝑑 决定,通常分别设为 -65 和 2。 Izhikevich 神经元模型的一个优势在于,通过调整参数 𝑎、𝑏、𝑐 和 𝑑 的取值,可以模拟和再现神经元的多种动态行为。由于其计算简化且具备适当的生物真实性,该模型适用于构建大规模脉冲神经网络,且每毫秒仿真仅需 13 次浮点运算(FLOPS)(Paugam-Moisy & Bohte, 2012)。
2.2.3 漏电积分-发放模型(Leaky Integrate-and-Fire, LIF) 将脉冲神经元模型简化至最基本的形式(即一个一维微分方程),便得到积分-发放(Integrate-and-Fire, IF)神经元模型。该模型的核心原理是:神经元对输入脉冲产生的电压进行积分,当膜电位达到某一阈值时,便产生一个脉冲,随后神经元恢复至静息状态(Gerstner 等,2014)。由于其结构简单,该模型在数字电路中较为常用(Nitzsche 等,2021)。
漏电积分-发放(Leaky Integrate-and-Fire, LIF)模型是对 IF 模型的轻微扩展,在神经元膜电位中引入了一个“漏电”项。该模型的行为由以下方程描述:

鉴于公式(9)具有非线性且可微,因此可用于训练深度网络,并能对脉冲神经元提供合理的近似(Hunsberger & Eliasmith, 2016)。LIF 模型因其计算开销低、仿真速度快,且能够捕捉生物神经元最基本的时序动态特性而被广泛使用,且在毫秒级精度下进行仿真仅需 5 次浮点运算(FLOPS)。
2.2.4 自适应指数积分-发放模型(Adaptive Exponential Integrate-and-Fire, AdEx)
2005 年,Brette 与 Gerstner(2005)提出了一种二维的积分-发放模型,称为自适应指数积分-发放(AdEx)模型。该模型结合了指数积分-发放模型(Exponential Integrate-and-Fire, EIF)(Fourcaud-Trocmé 等,2003)与一个适应性方程。AdEx 模型融合了 EIF 模型的特性以及 Izhikevich 模型中的二维状态变量结构。描述 AdEx 神经元行为的方程如下:
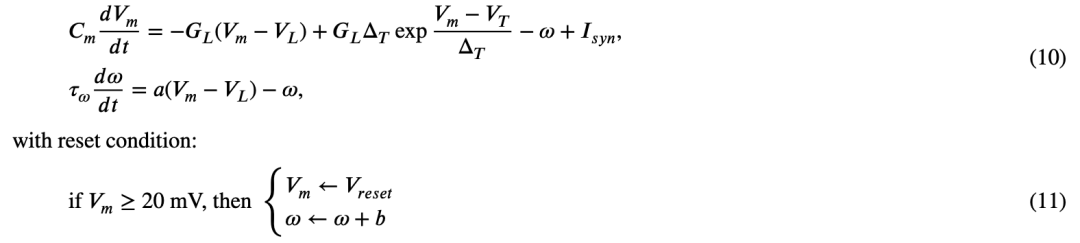
其中,ω 是适应变量,ΔT 是斜率因子,VT 是阈值电位,a 是阈下适应水平,b 是脉冲触发的适应。在 AdEx 模型中,若将 ΔT 设为 0 并移除 ω 项,则模型简化为 LIF 模型。该模型的计算开销低于 Izhikevich 模型,仿真仅需 10 次浮点运算(FLOPS)。
表2 对本节讨论的各类神经元模型进行了比较,从定性和定量两个角度进行评估,以帮助理解。在该表中,神经元模型根据计算复杂度、生物准确性、生物合理性、方程动力学特性以及参数数量等标准进行对比。动态参数是指那些随时间变化以模拟神经元行为的参数,例如 AdEx 模型中的 Vm 和 ω 值;相比之下,固定参数则是可调整以控制神经元输出的参数,如 Izhikevich 模型中的 a、b、c 和 d 值。此外,表中还列出了这些模型与硬件实现的兼容性——这也是本文的核心关注点,尽管更详细的解释将在后续章节中提供。
2.3 脉冲神经网络中的学习规则 将前述原理转化为图论视角,神经元可被视为节点,而它们之间相互连接的突触则为带权重的边。这一视角与深度学习中的人工神经网络(ANNs)相呼应,但同时引入了动态行为。优化 ANN 通常需要一种学习规则,最常见的是通过误差反向传播(backpropagation)实现的梯度下降法。然而,由于反向传播在生物学上的合理性有限,神经科学界提出了其他学习理论。这些理论大致可分为监督学习和无监督学习,但需注意的是,在自监督学习(Shwartz-Ziv & LeCun, 2024)和弱监督学习(Zhou, 2018;Gunasekaran 等,无日期;Y. Yang 等,2022)领域中,这两者之间的界限已变得极为模糊。
2.3.1 无监督学习 STDP 可被解释为一种无监督学习规则,因为它默认不依赖于监督信号或误差信号。它也是一种局部学习(local learning)形式,因为突触可塑性的计算仅依赖于突触自身上的局部变量。采用局部学习机制,有机会将存储单元与计算单元更紧密地结合:存储单元承担突触权重的存储功能,而计算则在神经元内部完成。这种无需长距离数据通信即可实现突触可塑性的特性,非常适合实现高能效的片上学习(on-chip learning)。最早成功展示 SNN 无监督学习的案例之一是 Diehl 与 Cook(2015)的工作,其在 MNIST 数据集(LeCun 等,1998)上取得了与深度学习方法相当的准确率。然而,SNN 的局部学习面临可扩展性挑战:随着网络层数增加,深层神经元产生脉冲的概率会降低,这一现象被称为“前向脉冲传播消失”(vanishing forward-spike propagation)(Kheradpisheh 等,2018)。总体而言,STDP 具有正向强化的特性——较强的连接通常会被进一步加强。这种强化机制提高了神经元在再次遇到相同模式时发放脉冲的可能性。此外,作为一类无监督学习算法,STDP 能够支持类似生物大脑的终身学习(lifelong learning),并已被用于微调预训练模型(S. Hu 等,2021;Bianchi 等,2020)。
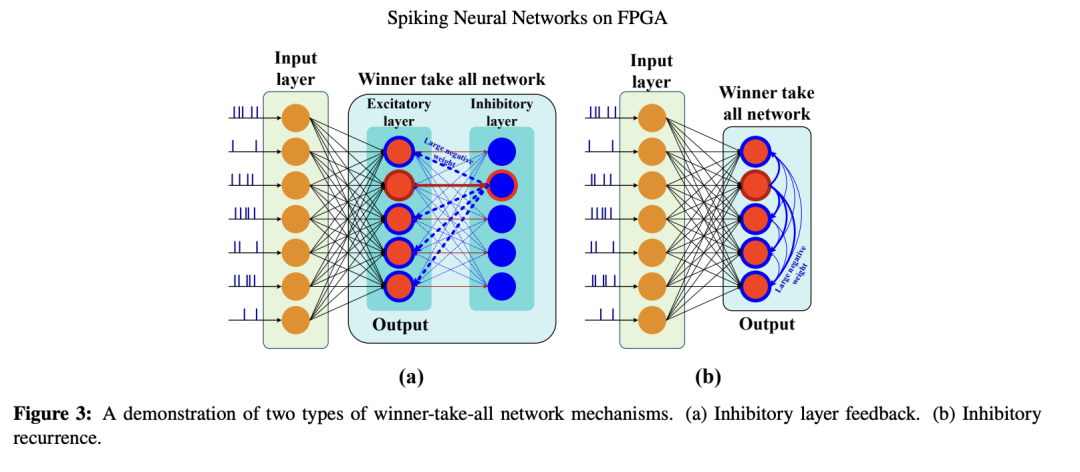
鉴于 STDP 的正向强化特性,大脑中必然存在稳态机制(homeostatic mechanisms)以防止神经活动的雪崩式爆发。一般来说,稳态机制是指维持生物系统内部平衡与稳定的过程。在神经系统中,这些机制保持一种平衡状态,确保神经活动在长时间内保持稳定,避免出现剧烈波动(S. Davies 等,2024)。其中一种用于平衡网络活动的方法是侧向抑制机制(lateral inhibitory mechanisms):即一个神经元的兴奋会抑制其他神经元,旨在模拟大脑中的竞争机制。在此方法中,某一层中一个神经元的发放会抑制同层其他神经元的活动。具体而言,每一层中“获胜”的神经元会抑制其邻近神经元,这被称为“胜者通吃”(winner-takes-all)方法(Masquelier 等,2009)。实现胜者通吃的方案有多种,图3展示了其中两种较常见的方法。在图3(a)中,兴奋性层与抑制性层之间的连接权重被设定为固定值,其中红线表示正权重,蓝线表示负权重。这意味着兴奋性层中某个神经元的“胜利”会激活抑制性层中对应的神经元,并通过较大的负权重抑制其所有邻近神经元。在图3(b)中,获胜神经元自身通过循环连接(recurrent connections)直接向邻近神经元发送负权重信号。
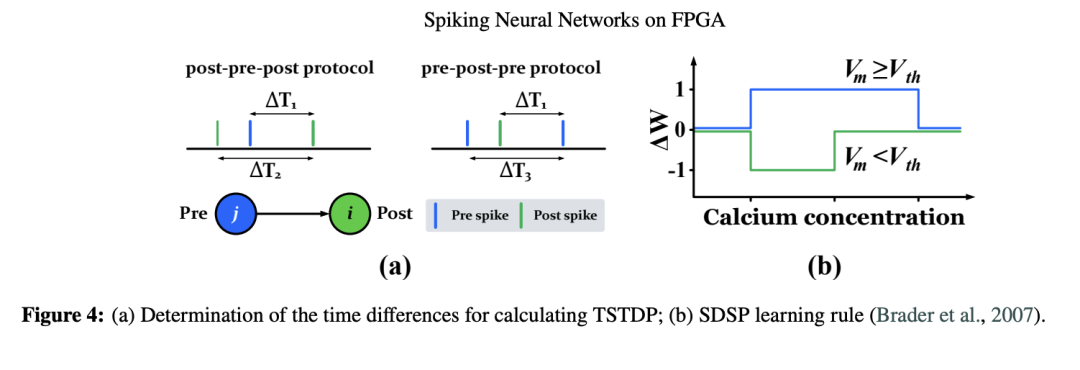
经典的 STDP 模型也被称为基于脉冲对的 STDP(pair-based STDP, PSTDP),因其依赖于成对脉冲的时间关系。然而,该模型被认为在生物学可解释性方面存在局限(Lammie 等,2018)。因此,Pfister 与 Gerstner(2006)于 2006 年提出了基于脉冲三元组的 STDP 模型(triplet-based STDP, T-STDP),该模型能够更准确地再现生物行为。该模型考虑三元组脉冲:即两个突触前脉冲和一个突触后脉冲,或一个突触前脉冲和两个突触后脉冲。T-STDP 是一种通过考虑三个连续脉冲的时序来调整突触权重的机制,其数学描述如下列方程所示:

其中,Δ𝑤⁺ 和 Δ𝑤⁻ 分别代表突触增强(potentiation)和减弱(depression)。𝐴⁺₂、𝐴⁺₃、𝐴⁻₂ 和 𝐴⁻₃ 是增强与减弱的强度参数;𝜏⁺、𝜏⁻、𝜏ₓ 和 𝜏ᵧ 是时间常数,用于控制 STDP 曲线的时间窗口宽度。各种 Δ𝑡ᵢ 如图4(a)所示。研究表明,基于脉冲频率的 Bienenstock-Cooper-Munro(BCM)突触可塑性法则所固有的行为,可以从 T-STDP 规则中自然衍生出来(Azghadi 等,2013;Lammie 等,2018)。
BCM 理论描述了一种突触可塑性机制:其增强或削弱突触的阈值是动态变化的,并根据神经元活动水平进行调整。这使得突触能够依据脉冲频率表现出长时程增强或抑制,因此成为理解活动依赖型突触变化的关键模型。
需要指出的是,除上述模型外,还提出了多种基于 STDP 的扩展方法,如自组织映射-STDP(SOM-STDP)(Rumbell 等,2013)、奖励调制-STDP(R-STDP)、奖励调制自组织映射-STDP(R-SOM-STDP)(H. Wang 等,2022),以及 BCM-STDP(BSTDP)(J. Liu 等,2018),这些方法均以 STDP 为基础构建。
Brader 等人(2007)提出了一种替代性的学习规则:突触强度的变化取决于突触前脉冲发生时突触后神经元的内部状态,而非依赖于精确的时间差。该方法被称为“脉冲驱动突触可塑性”(Spike-Driven Synaptic Plasticity, SDSP),其核心机制是:当突触前脉冲发生时,若突触后神经元的内部状态(𝑉ₘ)高于某一阈值(𝑉ₜₕ),则突触强度增加一个单位;反之,若内部状态低于特定阈值,则突触强度减少一个单位。该方法通过避免精确计时计算,有效降低了计算负载与硬件复杂度,同时支持兼具时序与空间特性的学习。它契合脉冲神经网络异步、事件驱动的本质,因而非常适合高效硬件实现与实时处理。Frenkel 等人(2019, 2018)已在 65nm 和 28nm CMOS 工艺上采用此方法实现硬件部署,其运行机制如图4(b)所示。
2.3.2 监督学习
在监督学习中,网络通过一个全局信号进行训练,该信号可来自数据的标签或损失/误差信号。这是深度学习时代性能最强的方法。因此,早在2002年,SpikeProp 被提出用于 SNN 的监督学习,其思路类似于传统的误差反向传播(Bohte 等,2002)。该算法展示了 SNN 如何学习非线性任务,例如 XOR 分类。在 SpikeProp 提出之后,出现了更多改进版本,以推广单脉冲学习,例如 Multi-SpikeProp(Ghosh-Dastidar & Adeli,2009)。
2018年,Zenke 与 Ganguli(2018)提出了 SuperSpike,用于训练由漏电积分-发放(LIF)神经元构成的多层 SNN,以完成时空脉冲模式转换任务。该方法采用替代梯度(surrogate gradient)策略来克服离散脉冲不可微的问题,从而推导出一种基于电压的非线性三因子学习规则。这种将梯度下降法适配到 LIF 神经元计算图展开(unrolling)的方法,已成为训练 SNN 最主流的方式,因其性能最优,并直接借鉴了深度学习领域的全部进展(Eshraghian 等,2023;Shrestha & Orchard,2018;Y. Wu, Deng, Li & Shi,2018)。该方法已使 SNN 能够在大规模任务上与现代深度学习方法相竞争(Zhu 等,2023;Bal & Sengupta,2024)。
在基于替代梯度下降的技术普及之前,训练 SNN 的主流方法是先训练一个 ANN,再通过权重重缩放和归一化等方法将其转换为 SNN,将 ANN 中的连续非线性值转化为 SNN 所需的漏电时间常数、不应期、膜电位阈值等参数(A. Sengupta 等,2019)。在基于转换的方法中,无需使用随时间反向传播(Backpropagation Through Time, BPTT),而 BPTT 的内存复杂度会随着序列步长增加而上升。然而,这种转换需要近似处理,因为 ANN 的性能本质上为转换后的 SNN 设定了性能上限。传统上,从 ANN 转换而来的 SNN 通常需要极长的推理时间,导致延迟增加、能效降低,并且仅在静态(非时序)数据集上表现良好,这常被认为违背了 SNN 的初衷(Roy 等,2019;Ottati 等,2023)。关于从深度学习衍生出的 SNN 训练技术的详细综述,可参见文献(Eshraghian 等,2023)。
然而,这些源自深度学习的训练方法在生物合理性(bio-plausibility)方面面临诸多挑战,也偏离了开发 SNN 的最初目标之一:高效学习。为此,研究者提出了远程监督方法(Remote Supervised Method, ReSuMe),用于使 SNN 实现期望的输入-输出特性,其中 STDP 与反-STDP 机制(anti-STDP)(Rumsey & Abbott,2004)结合来自目标传递函数或期望输出的全局指导信号协同工作(Kasinski & Ponulak,2005)。Tempotron 是一种广为人知的算法,神经系统利用它有效解码隐藏在时空脉冲模式中的信息(Gütig & Sompolinsky,2006)。ReSuMe 和 Tempotron 采用 STDP 的监督变体进行分类,使 STDP 能够实现仅靠局部可塑性无法达到的性能。
此外,还有一些方法更明确地定义了全局或奖励调制形式的 STDP,旨在通过弱监督信号提升无监督方法的性能。这催生了 R-STDP 规则(Shahsavari 等,2021)。在该方法中,通过建模多巴胺(dopamine)引入强化学习的外部奖励信号,使 STDP 能更有效地训练网络(He 等,2021;Bing 等,2019, 2018)。在 R-STDP 中,训练的目标是获得最大奖励。因此,当任务成功时,释放的多巴胺会强化学习过程(Quintana 等,2022)。在 R-STDP 中,突触权重(𝑊)通过两个指标进行更新:资格迹(eligibility trace, 𝐸ₜ)和奖励信号(𝑅)。首先,突触的资格迹用于记录 STDP 所引起的修改。突触的资格迹定义如下:

除了上述方法外,Chronotron 还提出了其他不依赖深度学习、适用于采用信息时序编码的脉冲神经元的学习规则:一种具有高记忆容量(E-learning),另一种则具有更高的生物合理性(I-learning)(Florian, 2012)。本文对 SNN 学习规则的综述并非全面覆盖,而是聚焦于那些已在硬件中普遍实现的子集。关于脑启发学习机制更严谨的论述,读者可参考文献(Schmidgall 等,2024)。
2.4 数据编码
大多数 SNN 硬件需要基于脉冲的输入,因此通常必须将传感数据也编码为脉冲。数据编码方式会直接影响网络的性能、速度、准确率和能效。然而,由于大多数输入数据是以“连续”变量形式记录的,将其转换为脉冲通常意味着某种形式的有损压缩。通常更明智的做法是处理那些原生即以脉冲(或事件)形式捕获的数据;除此之外,在 SNN 与深度学习领域中,大多数编码策略主要通过两种方式实现。
第一种观点基于神经元发放的频率进行编码,称为频率编码(rate coding)(Y. Kim 等,2022)。另一种观点认为,信息编码于脉冲之间的精确时序(或单个脉冲的发放时刻)中,这被称为时序编码(temporal coding)(Ghosh-Dastidar & Adeli,2009)。在频率编码方法中,受到高强度刺激的神经元比受到低强度刺激的神经元产生更高频率的脉冲发放。滑动窗口(Sliding Window, SW)算法(Webb 等,2011)和 Ben 的脉冲生成算法(Ben’s Spiker Algorithm, BSA)(Schrauwen & Van Campenhout,2003)是两种常用的、基于频率编码在脉冲域与非脉冲域之间转换的算法(K. Wang 等,2023)。为避免有损压缩,通常需要较长的脉冲序列,但这会导致活动量增加、功耗上升和延迟增大。因此,Z. Wang 等(2022)提出了基数编码(radix-encoded)方法,该方法不仅显著缩短了脉冲序列长度,还提升了所配合模型的准确率,相比当前最先进的基于频率编码的模型,实现了 25 倍的速度提升和 1.7 倍的准确率提升。
第二种主流的数据编码方法是使用时序编码,其中信息被编码到发放时刻中:受到高强度刺激的神经元比低强度刺激的神经元更早发放脉冲(Saha 等,2013)。该方法比频率编码更具能效,因为它用更少的脉冲编码信息。常见的时序编码方法包括:前进步(Step-Forward, SF)编码、移动窗口(Moving-Window, MW)编码(N. K. Kasabov,2014)、基于脉冲宽度调制的算法(Pulse Width Modulated-Based, PWMB)(Arriandiaga 等,2019)、排序编码(Rank-Order Encoding)(Van Rullen & Thorpe,2001)、GA-gamma 编码(N. Sengupta 等,2015)、小波编码(Wavelet Encoding)(Z. Wang 等,2016)等。在各类时序编码方法中,相位编码算法(phase coding algorithms)(Cattani 等,2015)能更充分地利用神经元的时序信息,近年来得到了更广泛的应用(K. Wang 等,2023)。需要指出的是,现有编码策略种类繁多,本文远未穷尽所有编码方法。
- 基于 FPGA 的脉冲神经网络(SNNs) 神经形态硬件可分为三类:模拟型、数字型和混合模式型。尽管神经形态计算最初旨在模拟神经处理的模拟特性,但 SNN 的数字实现更易于扩展为大规模系统。
迄今为止,研究人员和企业已提出了多款采用全定制数字设计的 ASIC 芯片,以摆脱冯·诺依曼架构,迈向神经形态系统。这些芯片专为类脑处理而设计。在众多已提出的架构中,有几款尤为突出:
- SpiNNaker(Furber 等,2014)由曼彻斯特大学开发,采用分布式冯·诺依曼架构,每颗芯片集成 18 个 ARM 核心,基于 130 nm 工艺制造。该芯片专为大规模 SNN 仿真设计,具有高度灵活性。其新一代硬件
SpiNNaker 2(Gonzalez 等,2024)采用 ARM Cortex-M4F 核心,进一步优化,可在单芯片上模拟更多神经元。
- IBM TrueNorth (Akopyan 等,2015)基于全局异步、局部同步(GALS)架构,单芯片包含 100 万个神经元和 2.56 亿个非可塑性突触,采用 28 nm 工艺制造,集成 54 亿个晶体管。该芯片定制的 Izhikevich 神经元可模拟 11 种不同神经元行为,通过组合三个神经元甚至可生成多达 20 种行为。
- Intel Loihi (M. Davies 等,2018)同样采用全异步设计,单芯片最多支持 18 万个神经元和 11.4 万至 100 万个突触。得益于其片上学习能力和异步架构,该芯片在实时神经处理方面效率极高。它采用 STDP 模型进行神经学习,并基于英特尔 14 nm FinFET 工艺制造。
尽管这些硬件平台代表了神经形态系统发展的重要里程碑,但它们仍面临一些挑战,例如可编程性有限甚至不可编程,以及对大多数研究人员而言可及性受限。
相比之下,FPGA 提供了一个易于获取、高效且低成本的平台,能够快速实现探索性算法与模型,并具备高度可编程性。通过有效优化,FPGA 在特定任务负载上可超越 CPU 和 GPU(Mohaidat & Khalil,2024)。SNN 尤其受益于 FPGA 实现,因其具备并行处理能力、分布式本地存储,并能适应具有分支结构的动态工作负载——而这正是 GPU 不再具备优势的场景(Javanshir 等,2022)。例如:
- Ju 等(2020)提出了一种基于 FPGA 的 SNN,证明其实现的网络比 CPU 快 41 倍,比 GPU 能效高 22 倍。
- Guo 等(2021)表明,其在 FPGA 上实现的 SNN 在训练速度上比基于 PyTorch 的 CPU 仿真快 180 倍,推理速度快 20 倍。
- Han 等(2020)在 Xilinx ZC706 评估板上进行实验,与在 Tesla P100 GPU 上运行的 PyTorch 软件仿真相比,FPGA 每瓦可处理 337.6 帧/秒,而 GPU 仅为 42.2 帧/秒。
- Fang 等(2019)指出,其 FPGA 实现比 GPU 执行能效高 196 倍,速度快 10.1 倍。
- Cheslet 等(2024)在 AMD Kria KR260 开发板(属于 Zynq UltraScale+ MPSoC 系列)上实现了实时 SNN 任务,其执行速度约为普通个人电脑(PC)的 28 倍。
这些实例凸显了 FPGA 相较于其他平台的优越性,尤其在执行 SNN 任务方面,进一步证明了选择 FPGA 作为 SNN 硬件平台的合理性。
鉴于对能效的关注,资源约束通常迫使设计者采用多种近似方法。在 FPGA 上实现算法和模型时,软件实现与硬件实现之间往往存在不可避免的差异。这是因为若不进行简化(例如量化,或将超越函数实现为查找表),直接部署可能因硬件资源需求过大而不可行(Venkatesh 等,2024;Eshraghian, Lammie 等,2022)。
在过去几年中,已有大量研究尝试在 FPGA 上实现 SNN。这些尝试通常可分为四大类:数据编码方法、学习规则、神经元模型和网络架构(Pham 等,2021)。在以下小节中,我们将更详细地审视和综述每个领域已开展的工作。
3.1 数据编码 深度 SNN 需要更多的内存,不可避免地会达到一个临界点:片上内存不足以容纳所需数据,设计者不得不使用片外内存,而这会显著增加功耗。有效的输入数据编码方法,结合合理的架构选择,能够大幅减少网络参数和内存需求(Javanshir 等,2022)。因此,大量研究工作投入到优化数据编码策略中。这与许多基于软件的 SNN 研究形成鲜明对比——在后者中,输入通常仅被简单地视为连续电流注入,而未经过专门的编码处理。
泊松分布脉冲编码(Poisson distributed spike coding)(Cao 等,2015;Diehl 等,2015)是一种在 FPGA 上常用的编码技术,它根据输入数据的强度对信息进行编码。其数学表达如下:

其中,𝑟𝑎𝑛𝑑() 是从 0 到 1 之间的均匀概率分布中采样的一个随机数,𝑐 是控制发放率的因子,𝑥 表示归一化后的输入。生成伪随机数的一种常用方法是使用线性反馈移位寄存器(Linear-Feedback Shift Register, LFSR)(Linares-Barranco 等,2007)。同样,泊松编码方法也可以基于两个脉冲之间的时间间隔(即脉冲间间隔,Inter-Spike Interval, ISI)来实现(Heeger 等,2000),其表达式如下:

其中,ℐ 表示前一个脉冲与当前脉冲之间的时间间隔,𝜂 为发放率。
时序编码方法在生物学上可能更具真实性,也更适合处理动态输入数据。然而,对于静态数据(如图像),频率编码方法可能更为有效。因此,Carpegna 等人(2022)在实现泊松编码时,为所有输入设定一个固定的时间窗口 Δ𝑡,在此期间将输入编码为一定数量的脉冲。随后,将 Δ𝑡 划分为若干个时间步长 𝑑𝑡,每个时间步长最多包含一个脉冲。通过将输入值(即发放率 𝑟𝑎𝑡𝑒)乘以 𝑑𝑡,即可计算出平均脉冲数(𝐴𝑆𝑃𝑆 = 总脉冲数 / 总步数 = 𝑟𝑎𝑡𝑒 ⋅ 𝑑𝑡)。由于 𝐴𝑆𝑃𝑆 的取值范围在 0 到 1 之间,因此在每个时间步长中,通过生成一个随机数并与之比较,即可判断是否应在此步长内产生脉冲。该随机数同样采用 LFSR 技术生成,与前述方法类似,但不同之处在于:所有输入共享同一个生成的随机数。这种方法在对准确率影响极小的前提下,显著降低了硬件复杂度和资源消耗。
在基于泊松的脉冲序列中,由于随机性,给定时间窗口内实际生成的脉冲数量可能与预期值不完全一致,从而导致脉冲数量不可预测。因此,Y. Xu 等人(2017)提出了一种名为固定均匀脉冲序列生成算法(Fixed Uniform Spike Train Generation Algorithm, FUSTGA)的编码方法,能够更精确地将输入转换为脉冲序列。该算法的执行过程如算法1所示,其中 𝑇 为期望的时间窗口,𝐼 为归一化到 [0, 1] 区间内的输入向量中的每个元素。根据该算法,脉冲数量(𝑁𝑓𝑖𝑟𝑒)及其发放时刻(𝐹𝑖𝑟𝑒𝑡𝑖𝑚𝑒𝑠)会根据 𝐼 和 𝑇 进行调整。
Ju 等人(2020)在其基于 FPGA 的网络中实现了三种编码方法:泊松-ISI、泊松-rand 和 FUSTGA,并对它们的准确率进行了比较。在 MNIST 数据集上,三种方法分别取得了 84.15%、98.82% 和 98.94% 的准确率。结果表明,FUSTGA 方法的准确率优于另外两种泊松编码方法。鉴于 MNIST 被视为一个简单、玩具级的数据集,这一结果可能表明泊松-ISI 方法在静态数据上的实用性有限。

G. Zhang 等人(2020)采用了一种基于群体编码(population coding)的时序方法对输入数据进行编码。群体编码利用一组均值不同但方差恒定的高斯曲线,通过概率分布模型来表示输入数据(G. Tang 等,2021;G. Zhang 等,2020;P.-S. V. Sun 等,2024)。因此,该模型将输入信息映射为脉冲发放时刻,可表示如下:

其中,𝐴 为最大脉冲发放时间,𝑚 为高斯感受域的数量,𝛾 为控制参数。
鉴于输入编码方式的选择对网络性能和效率具有重要影响,K. Wang 等人(2023)在 FPGA 上实现了四种常用算法,并从准确率、速度、计算量、硬件资源消耗以及抗噪声能力等方面对它们进行了评估。他们研究了两种用于频率编码的算法——滑动窗口(SW)算法(Webb 等,2011)和 Ben 脉冲生成算法(BSA)(Schrauwen & Van Campenhout,2003),以及两种用于时序编码的算法——基于脉冲宽度调制(PWMB)和前进步(SF)算法(N. Kasabov 等,2016)。这四种算法与 FPGA 更兼容,能够更高效地在 FPGA 上实现。据他们所述,GA-gamma(N. Sengupta 等,2015)和小波编码(Z. Wang 等,2016)这两种算法复杂度过高,不太适合在 FPGA 上执行。此外,SW 算法仅用于从脉冲信号中重构原始信号。
- BSA:BSA 算法的基础是一个 FIR 滤波器。为了生成脉冲,需要计算原始信号与其滤波后信号之差的累积和。当该差值大于当前时刻原始信号的累积值时,便生成一个脉冲,并将原始信号减去滤波器的输出值。
- SF:SF 算法采用一个移动阈值。当信号超过阈值时,生成一个正脉冲;当信号低于阈值时,生成一个负脉冲,并更新阈值。
- PWMB:在 PWMB 方法中,原始信号与一个参考值进行比较。根据原始信号的幅值生成不同宽度的脉冲,并在所生成脉冲的上升沿处产生一个脉冲事件。
表 3 展示了 K. Wang 等人(2023)在 FPGA 上实现并比较的这四种方法的性能对比结果。
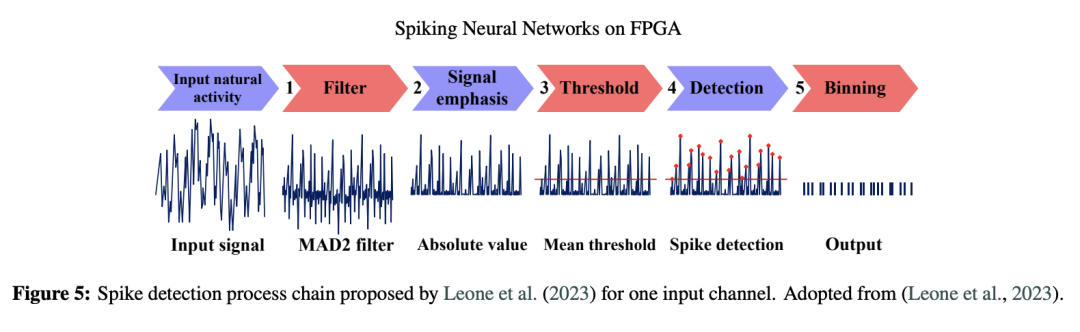
对脑电图(EEG)、心电图(ECG)等传感器数据进行连续、实时的信号处理是 SNN 的典型应用场景(Xiaoxue 等,2023;Azghadi 等,2020;Y. Yang 等,2023)。因此,将此类信号转换为脉冲以进行实时处理至关重要(N. K. Kasabov,2014)。考虑到 FPGA 的资源限制,Leone 等人(Leone et al., 2023)提出了一种新方法,以降低能耗和运算次数。该方法的脉冲检测过程包含以下五个阶段,从原始数据开始依次进行:
- 滤波 :通过二阶移动平均差分(Moving Average Difference, MAD)滤波器,从输入信号中去除低频成分;
- 脉冲增强 :对信号取绝对值,消除负值,以提高信号检测的可靠性;
- 阈值设定 :阈值由信号在 0.82 毫秒时间窗内的均值确定,因此该阈值每 0.82 毫秒更新一次;
- 检测器 :识别出超过阈值的峰值;
- 脉冲分箱(Spike binning):将检测到的峰值在相同的时间间隔内以分组脉冲的形式输出。
其脉冲检测流程如图 5 简要所示。该方法使用两只猕猴的电生理记录数据进行了测试(Brochier 等,2018),并采用了 Z. Zhang 与 Constandinou(2021)提出的 MAD 滤波器,其表达式如下:

其中,𝑥 为输入的连续信号,𝑁 为滤波器的阶数。通过将 𝑁 选择为 2 的幂,该滤波器仅需执行 𝑁 + 1 次加法和一次右移操作,从而无需使用乘法器。本文中取 𝑁 = 2。 Chu 等人(2022)使用电平穿越型模数转换器(Level-Crossing Analog-to-Digital Converter, LC-ADC)将连续的 ECG 输入数据转换为脉冲,并将其作为网络输入。LC 是一种采样方法,当信号穿越预设的阈值电平时即生成一个脉冲事件(Z. Wang 等,2020)。在该研究中,LC-ADC 产生的事件仅用单比特表示,从而简化了 ADC 的量化过程,并同时实现了原生的时序编码。
另一种可直接在 FPGA 上实现数据编码的方法是直接使用 IF(积分-发放)或 LIF(漏电积分-发放)神经元。这些神经元根据输入信号强度和膜电位变化被激发,并依据输入幅值以不同频率产生脉冲。该方法可使用单个神经元或一组神经元实现(Fang 等,2020)。此外,直接利用神经元进行编码在信号处理应用中已展现出良好效果(Rathi & Roy,2020;Y. Wu 等,2019)。脉冲神经元通常被视为 Δ-Σ(delta-sigma)模数转换器。
3.2 学习规则 如第 2.3 节所述,已有大量方法被提出用于训练 SNN。然而,将这些方法部署到硬件(包括 FPGA)上需要额外的考量。本节将探讨近期在 FPGA 上实现的一些训练方法及其所采用的技术。
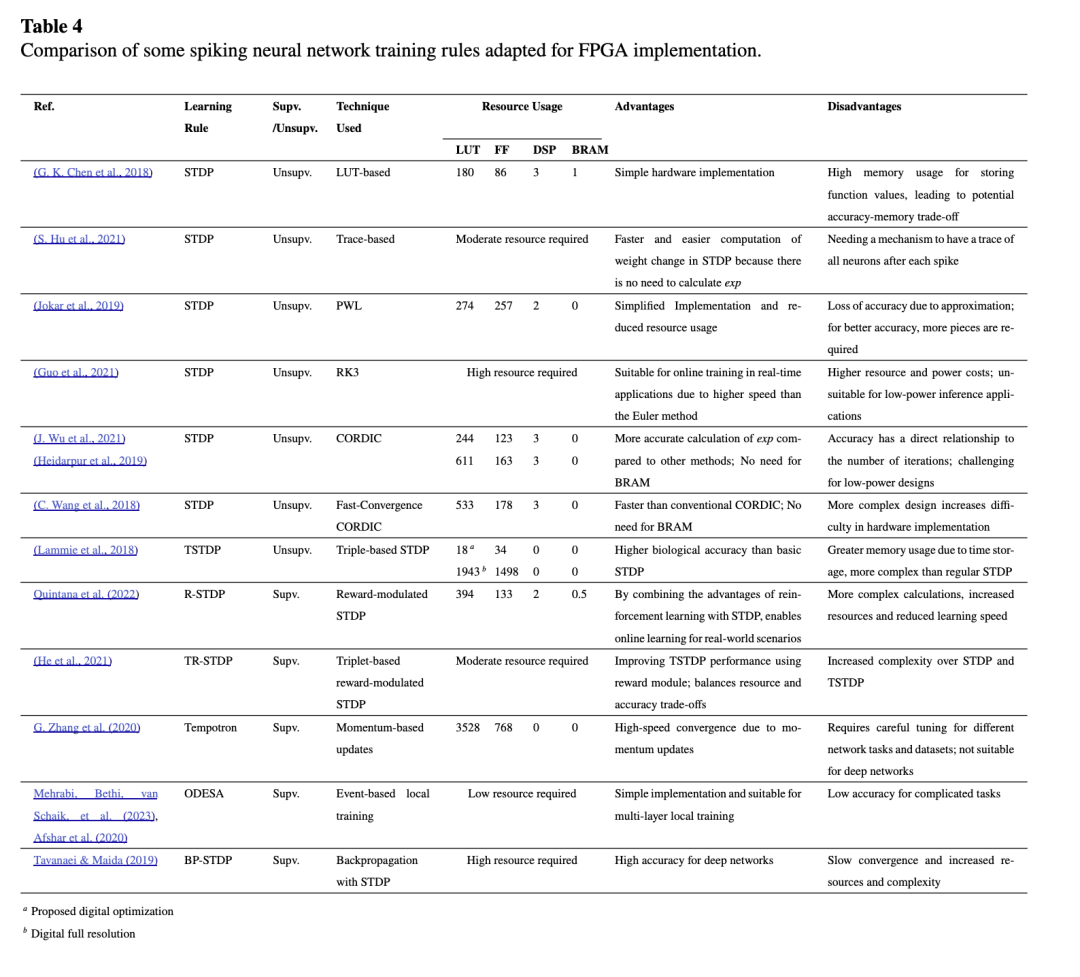
3.2.1 无监督学习规则 在 FPGA 上实现 STDP 等学习规则的主要挑战之一在于其包含指数项、乘法运算以及微分项的求解(J. Wu 等,2021;Bahrami & Nazari,2024)。为解决这些问题,研究人员提出了多种技术,例如:使用查找表(LUT)实现(G. K. Chen 等,2018)、三角形近似(A. S. Cassidy 等,2013)、坐标旋转数字计算(CORDIC)算法(Volder,1959)、分段线性(PWL)近似、基于 2 的幂次近似(Gomar & Ahmadi,2018)以及数值求解器等。
在这些方法中,Guo 等人(2021)成功在 FPGA 上实现了三元组 STDP(triplet STDP)模型,采用了两种数值计算方法:欧拉法(Euler)和三阶龙格-库塔法(RK3)。其中,RK3 方法虽然消耗更多硬件资源,但显著提升了训练和推理速度。
由于乘法运算在硬件实现中会消耗大量资源,S. Yang、Wang、Deng 等人(2021)采用欧拉近似对 STDP 规则进行了简化,并使用移位逻辑乘法器(Shift Logic Multiplier, SLM)模块替代传统乘法器,以避免过度消耗资源和功耗。本文在 FPGA 上实现所采用的 STDP 方程如下:

针对 STDP 计算中需处理所有脉冲对时序的问题——这一任务计算开销大,尤其在 FPGA 上会消耗大量硬件资源——一种解决方案是采用基于迹(trace-based)的 STDP 规则。研究表明,该方法在保持与经典方法相同准确率的同时,效率显著更高(S. Hu 等,2021)。在基于迹的 STDP 规则中,“迹”(trace)指一个时间变量,用于记录神经元近期的脉冲活动历史。它本质上追踪神经元过去脉冲的衰减过程,反映其近期所经历的激活水平。每次脉冲发生时,迹值都会更新,并随时间呈指数衰减。由于迹本身呈指数衰减,因此在计算权重更新时,可用它替代原始 STDP 方程中的指数函数(Gebhardt & Ororbia,2024)。
为便于理解,图 6 展示了突触权重如何根据突触前和突触后神经元近期脉冲所留下的“迹”而变化。当突触前或突触后神经元产生脉冲时,突触权重会根据另一侧神经元所留迹值的大小(由其脉冲时序决定)进行增强或削弱。在 S. Hu 等人(2021)的研究中,若突触前神经元发生脉冲事件,则突触强度会根据突触后迹(postsynaptic trace)的值进行削弱;反之,若突触后神经元发生脉冲事件,则连接权重会根据突触前迹(presynaptic trace)的值进行增强。这意味着:在第一种情况下,当突触前脉冲发生时,若此前已发生过突触后脉冲,则符合传统 STDP 的概念,权重应减小;相反,在突触后脉冲发生时,若此前已发生过突触前脉冲,则权重应增大。公式(22)表达了这一机制,需注意的是,𝑡𝑟𝑎𝑐𝑒ₚᵣₑ 和 𝑡𝑟𝑎𝑐𝑒ₚₒₛₜ 在每次脉冲发生后均会呈指数衰减。
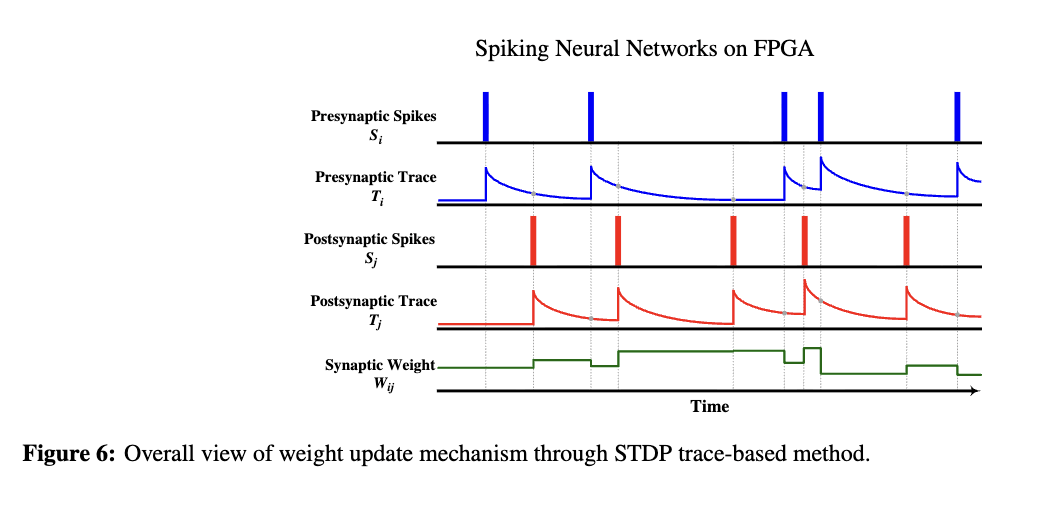

换句话说,权重更新过程仅在突触前或突触后脉冲发生时进行,无需存储所有脉冲的时间戳。这显著提升了效率并减少了硬件资源消耗(S. Hu 等,2021;He 等,2021)。
如前所述,针对 FPGA 中指数函数难以实现的问题,一种建议的解决方案是采用 CORDIC 方法(Bahrami & Nazari,2024)。CORDIC 是一种迭代算法,可用于计算多种复杂函数,如指数函数、双曲函数和三角函数。它仅使用简单的移位和加法操作,因此在 FPGA 上实现起来简单且高效(Meher 等,2009)。因此,在类脑计算方法中,指数函数常被用于描述神经元和突触的动力学行为,而 CORDIC 方法在此类场景下能够显著提升实现的精度与效率(J. Wu 等,2021)。Heidarpur 等人(2019)对传统 CORDIC 算法进行了简化,并将其用于 STDP 规则的实现。有关该算法的更多细节可参见文献(Heidarpur 等,2019;Heidarpour 等,2016)。
J. Wu 等人(2021)在 FPGA 上实现了多种不同的 STDP 实现方案并进行了比较。这些方法包括:Heidarpur 等人(2019)提出的简化方法、传统的 CORDIC 方法、C. Wang 等人(2018)提出的快速收敛 CORDIC 方法,以及 G. K. Chen 等人(2018)提出的基于查找表(LUT)的方法。他们证明,CORDIC 方法相比基于 LUT 的方法功耗和能耗更低;尽管 CORDIC 方法占用更多逻辑资源,但无需使用块存储器(BRAM)。在各类 CORDIC 方法中,快速收敛技术在迭代次数约为其他两种方法一半的情况下,实现了最低的能耗。
Bahrami 与 Nazari(2024)提出了一种改进 CORDIC 算法收敛速度的方法,并将其用于实现指数运算符(Exp CORDIC)、自然对数运算符(Ln CORDIC)以及任意幂函数(Pow CORDIC)。最终,他们利用 Pow CORDIC 实现了 Spatial-Pow-STDP 学习算法。与传统 CORDIC 相比,所提出的方法在仅需 9 次迭代的情况下,以更少的参数和误差实现了更高的精度。
为克服突触可塑性和神经元模型中非线性项实现的复杂性,Jokar 等人(2019)提出了一种基于均匀分段线性分割(uniform piecewise linear segmentation)的新方法(Soleimani 等,2012)。他们将该方法应用于钙依赖型突触可塑性模型(Graupner & Brunel,2012),该模型能够生成 STDP 曲线。
Lammie 等人(2018)首次在 FPGA 上实现了 T-STDP 算法(Pfister & Gerstner,2006)。他们用低分辨率的无符号移位-加法乘法器替代了浮点乘法器,并将突触系数(即公式 12 中的 𝐴 和 𝜏)替换为 2^𝑁 形式的值(其中 𝑁 ∈ ℤ),从而缓解了乘法运算对硬件资源的高消耗问题。
在 S. Yang、Wang、Pang、Jin 与 Linares-Barranco(2024)发表的文章中,提出了一种四元组 STDP(Quadruplet STDP, Q-STDP)学习算法,作为适用于 FPGA 实现的高效方法。在该算法的实现中,复杂的指数函数被线性微分方程所替代,从而能够在数字硬件上直接且低成本地部署。该算法中的突触权重更新方程定义如下:
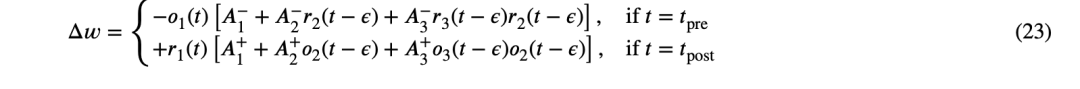
其中,𝜖 表示用于考虑突触前与突触后脉冲之间时间对齐的时间延迟,𝑟₁、𝑟₂、𝑟₃、𝑜₁、𝑜₂ 和 𝑜₃ 是表示增强(potentiation)与抑制(depression)电位的变量。这些变量通过如下所示的线性微分方程进行建模:
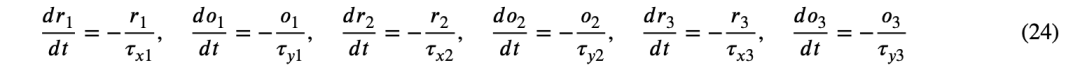
其中,𝜏ₓ₁、𝜏ₓ₂、𝜏ₓ₃ 分别为增强电位 𝑟₁、𝑟₂、𝑟₃ 的时间常数,𝜏ᵧ₁、𝜏ᵧ₂、𝜏ᵧ₃ 分别为抑制电位 𝑜₁、𝑜₂、𝑜₃ 的时间常数。本文的实验结果表明,Q-STDP 相较于 T-STDP 和传统 STDP 算法具有更高的学习准确率,并且具备更强的容错能力。
3.2.2 监督学习规则监督学习是现代深度学习的核心组成部分,尽管与无监督方法相比,它通常需要消耗更多的计算资源。G. Zhang 等人(2020)的工作将 Tempotron 的监督学习方法进行了推广,其灵感来源于惯性的物理定律。在计算当前权重更新值时,保留一部分先前权重更新值,从而确定最终权重更新的方向。权重更新的幅度计算公式为:Δ𝑊ᵢ = 𝜆 ∑{𝑡ᵢ < 𝑡ₘₐₓ} 𝐾(𝑡ₘₐₓ − 𝑡ᵢ),其中,𝜆 为学习率,决定突触权重更新的最大幅度;𝑡ᵢ 表示第 𝑖 个传入神经元的脉冲发放时间;𝑡ₘₐₓ 表示突触后膜电位达到最大值的时刻;𝐾 表示归一化的突触后电位核函数。关于 Tempotron 学习的更多细节可参见文献(Gütig & Sompolinsky, 2006)。
G. Zhang 等人(2020)的研究通过引入动量(momentum)项对原始方法进行了改进,其权重更新规则如下:

Bethi 等人(2022)提出了优化的深度事件驱动脉冲神经网络架构(Optimized Deep Event-driven Spiking Neural Network Architecture, ODESA)方法,用于监督式网络训练。在该方法中,网络在基于事件的数据上进行局部训练。具体而言,下一层的活动被用作前一层的监督信号,突触权重仅根据每一层自身的活动进行调整,而无需依赖其他层的权重信息。本质上,该方法利用了两种信号:局部注意信号(Local Attention Signals, LAS)和全局注意信号(Global Attention Signals, GAS)。LAS 由隐藏层生成,而 GAS 由输出层产生。这些信号在训练过程中用于对神经元施加奖励或惩罚:每当某一层产生脉冲时,LAS 会作用于前一层,奖励那些对当前脉冲活动有贡献的神经元;GAS 则由输出层生成并作用于网络中的所有层——当输入被正确分类时,活跃神经元获得奖励;若分类错误或输出层无活动,则对其施加惩罚。ODESA 的设计灵感来源于 Afshar 等人(2020)提出的基于自适应选择阈值的特征提取(Feature Extraction using Adaptive Selection Thresholds, FEAST)方法。
Mehrabi、Bethi、van Schaik 等人(2023)成功在 FPGA 上实现了 ODESA 算法。该工作包含一个多层网络,每层均配备独立的训练模块,从而支持无需反向传播的在线监督训练。在此架构中,他们采用局部自适应选择阈值,对每一层施加“胜者通吃”(Winner-Takes-All, WTA)约束,并使用了一种更适用于硬件实现的改进型权重调整规则。该论文展示了 ODESA 算法与硬件的良好兼容性及其在在线训练中的适用性。此外,Mehrabi、Bethi、van Schaik 与 Afshar(2023)进一步优化了其硬件实现,将硬件神经元中计算成本较高的点积运算替换为低成本的移位寄存器。通过这一策略,显著降低了 FPGA 层面的资源消耗,使得更复杂的 SNN 网络得以实现。
Quintana 等人(2022)成功在 FPGA 上实现了奖励调制脉冲时序依赖可塑性(Reward-modulated STDP, R-STDP)的学习机制。如图 7 所示,R-STDP 的计算首先需要在每个时间步并行计算每个输入突触群体的 STDP 迹(trace)。然而,为减少突触前和突触后计算所需的硬件组件,该设计采用了时分复用(time multiplexing)技术。当输入脉冲发生时,𝑤𝑒𝑖𝑔ℎ𝑡𝑝𝑙𝑢𝑠 的值增加一个用户设定的常量;𝑒𝑡𝑟𝑎𝑐𝑒 寄存器则累积 𝑤𝑒𝑖𝑔ℎ𝑡𝑚𝑖𝑛𝑢𝑠 的值。当突触后脉冲发生时,𝑤𝑒𝑖𝑔ℎ𝑡𝑚𝑖𝑛𝑢𝑠 增加,而 𝑒𝑡𝑟𝑎𝑐𝑒 则累积 𝑤𝑒𝑖𝑔ℎ𝑡𝑝𝑙𝑢𝑠 的值。在每个时间步,所有寄存器均根据公式(22)采用欧拉法进行更新。在计算出资格迹(eligibility trace)后,将其值与全局多巴胺水平相乘,以确定突触权重的变化量。
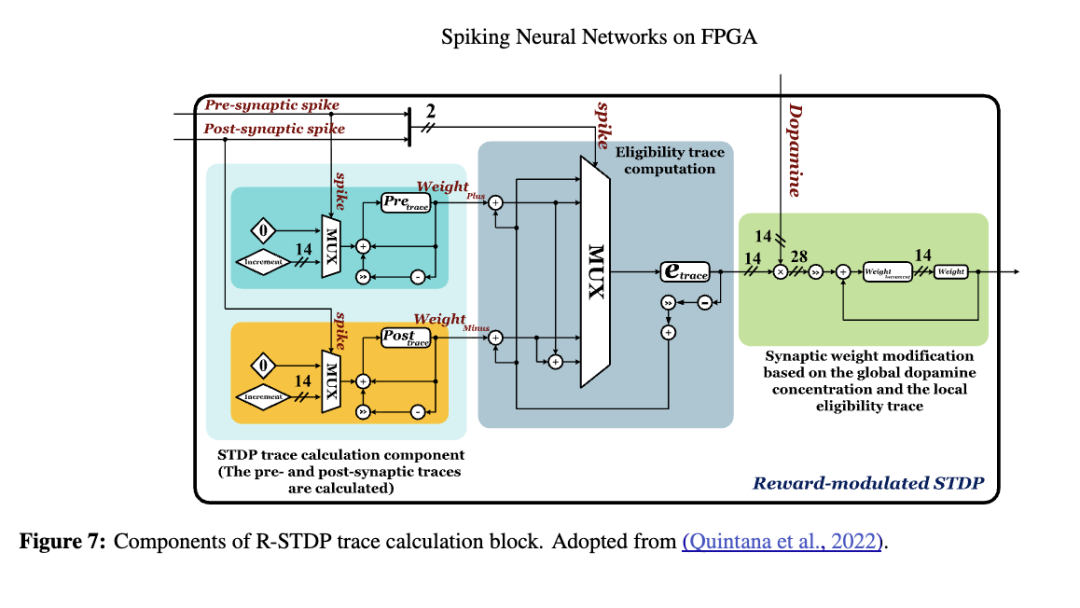
为在不显著增加资源消耗的前提下提升准确率,He 等人(2021)将迹辅助(trace-assisting)、三元组 STDP(triplet-based STDP)和 R-STDP 方法相结合用于网络训练。该工作利用迹辅助技术避免大量时间戳的存储,并借助 R-STDP 提高准确率。输入层的权重被随机初始化并保持固定,仅隐藏层与输出层之间的权重根据上述方法进行训练和更新。
如前所述,提出一种监督学习方法,使其既能适应现实认知应用、符合生物最优性原则,又能支持在线学习,是极具价值且必要的。大多数基于梯度下降的方法通常需离线执行,这可能对系统的最终准确率产生不利影响。因此,Tavanaei 与 Maida(2019)将 STDP 与反向传播相结合,提出了 BP-STDP 方法。该方法不仅基于类脑启发原则,还执行监督式的反向传播操作以实现更高准确率。在该算法中,首先更新隐藏层与输出层之间的权重(Δ𝑤ₕ,ₒ),随后按如下方式更新输入层与隐藏层之间的权重(Δ𝑤ᵢ,ₕ):

输出神经元的误差可近似表示为 εₒ,它代表目标类别神经元与脉冲神经元之间的差异,并可作为梯度下降的一种变体应用,如公式26所示。J. Zhang等人(2021)使用BP-STDP方法在FPGA上训练了他们的网络。他们没有采用速率编码,而是提出了加权神经元模型,其中每个脉冲的幅度与输入成正比。因此,公式27和26中过去四个时间步内神经元的脉冲计数
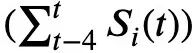
可被替换为 W Sᵢ。
先前的研究表明,可以通过传递有关信用分配的神经信息的反馈信号,在隐藏层中计算局部误差信号,从而实现在线学习(Lillicrap等人,2016)。然而,这些模型在模拟真实大脑性能方面面临挑战,因为它们需要独立的反馈通路来传输神经信息以确定局部误差信号。这种方法由于需要将每个隐藏层神经元与相应的反馈误差信号配对,因而与真实大脑不兼容。因此,S. Yang、Wang、Pang、Azghadi 和 Linares-Barranco(2024)提出了面向树突的学习系统(NADOL)的神经形态架构,其设计灵感源自人脑中的生物学习机制。该架构将反馈和前馈信号整合到不同的树突区室(包括顶树突和基树突段)中,从而增强信用分配和基于脉冲的学习。通过利用树突区室的独特特性,NADOL 模拟了大脑分别处理感觉信号和反馈信号的能力。这种分离使得无需依赖反向传播等低效方法即可精确计算误差,从而提高了与生物过程的兼容性。半监督的 NADOL 训练算法已在基于 FPGA 的 BiCoSS 平台上实现(S. Yang, Wang, Hao 等人,2021),并利用了时分复用、PWL 和欧拉技术进行数字优化。
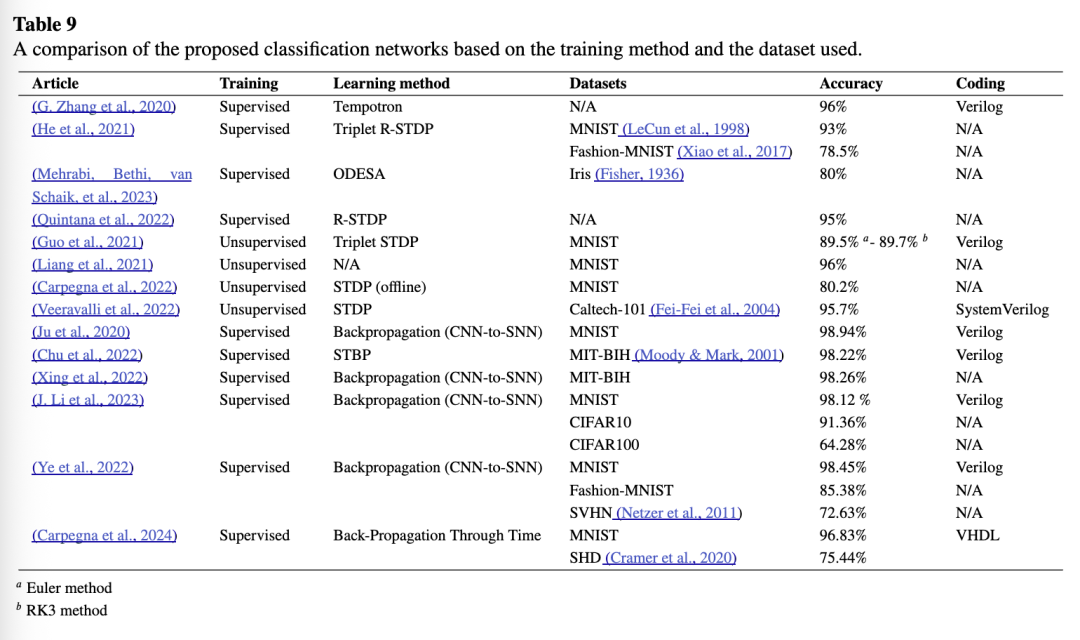
为了更好地理解本节讨论的方法,表4提供了针对FPGA实现所适配的一些规则的简明比较。在该表中,根据所采用的规则和实现技术,汇总了每项研究消耗的资源。此外,还以概括方式列出了每项研究的优势与劣势。值得注意的是,所介绍的学习规则的主要影响在于整体网络性能和所达到的精度,这些内容将在第3.4节(表9)中呈现并加以比较。同时,也提供了使用这些方法所实现的网络精度。
3.3 神经元模型 神经元是脉冲神经网络的核心构建单元,其能力对网络的功耗、精度和性能具有显著影响。如第2.2节所述,已有多种类型的脉冲神经元被提出,它们在生物合理性与计算复杂度方面各不相同。考虑到轻量级FPGA上的资源限制,神经元模型的计算开销成为一个关键考量因素。大量先前的研究致力于通过引入各种技术来降低硬件资源消耗,同时保持足够的生物准确性,从而减少计算需求。在本节中,我们将重点介绍近期工作中提出的若干神经元模型,并分析它们在FPGA上的实现方法。
前一节中公式5所示的Izhikevich模型呈现的是该方程的连续形式,若要在FPGA等数字系统中使用,则必须对其进行离散化。因此,最简单的离散化方法之一是采用欧拉法,正如Humaidi等人(2020)所推导出的近似解如下所示:

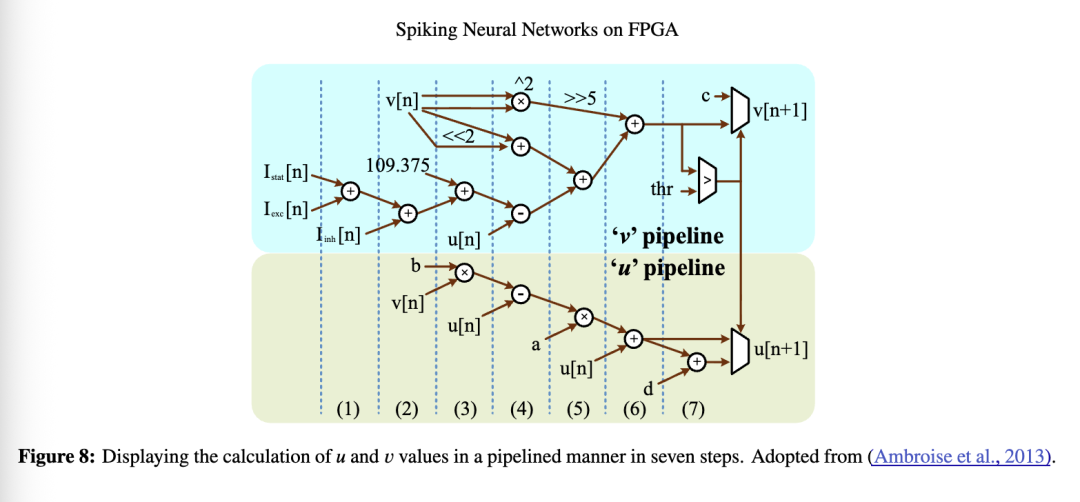
由于在FPGA中进行有符号浮点数运算代价高昂,因此神经元的数值采用定点数表示,其范围为[−1, 1]。为此,需将𝑢和𝑣缩小100倍,以使其适配算术系统所需的数值范围。此外,若将时间步长(timestep)设为2的幂次,则积分运算可简化为一次右移操作。因此,在(Humaidi 等人,2020)中,该时间步长取值为1∕16。而在(Quintana 等人,2022)中,该时间步长被设为1∕8,并基于上述缩放操作,Izhikevich方程被转换如下:

在该方程中,与原始Izhikevich方程(公式5)相比,1/32取代了小数0.04,从而用五次右移操作替代了乘法运算。此外,数值5被替换为4,以将其转化为两次左移操作(A. Cassidy & Andreou, 2008)。这种Izhikevich神经元的实现如图8所示。更新𝑣和𝑢的过程采用流水线方式完成,在不同步骤中仅使用一个乘法器。在经过六个阶段计算出𝑣和𝑢之后,最后一个阶段将𝑣的值与阈值进行比较,以确定脉冲生成条件及后续的𝑣和𝑢值。这些数值假定为18位,其中10位用于整数部分,8位用于小数部分。因此,本实现中使用了18×18位的乘法器。由突触连接产生的兴奋性电流𝐼ₑₓc和抑制性电流𝐼ᵢₙₕ,需要1毫秒时间来增加其电流值;然而,它们表现出不同的漏电行为,时间常数分别为3毫秒和10毫秒。因此,在公式31中,它们被分别写出并嵌入方程。
迄今为止,已有大量文章致力于Izhikevich神经元的数学建模,例如(Ghanbarpour等人,2023;Heidarpur等人,2024;Lin等人,2020;Pi & Lin,2022)。其中,Leigh等人(2020)提出了一种称为“面向硬件的改进型Izhikevich神经元”(HOMIN)的方法。在数字系统中,通过简单的移位操作即可实现将数字乘以2ˣ(其中𝑥 ∈ ℤ)。因此,他们将近似Izhikevich模型中的常数参数替换为其最接近的2ˣ值,以减少对乘法单元的需求。以下提供了HOMIN模型的简化方程,该方程使用欧拉法离散化,其中𝑑𝑡 = 2⁻⁵ = 0.03125:


其中,𝑣ᵢ(𝑡) 表示第 𝑖 个神经元在时刻 𝑡 的膜电位,𝑠ᵢ(𝑡) 是第 𝑖 个神经元的发放信号,𝜃 是阈值。在该模型中,由于每个周期仅生成一个脉冲,因此从内存读取数据的速率和脉冲发放频率均会降低,从而减少功耗。此外,膜电位的累积过程仅涉及加法器,无需使用乘法器。
Jokar 等人(2019)采用均匀分段线性分割方法,处理 Izhikevich 和 FitzHugh–Nagumo(FHN)神经元模型(FitzHugh, 1961),以及更复杂的 Hindmarsh–Rose(HR)神经元三维模型(Rose & Hindmarsh, 1989),以简化其在 FPGA 上的实现。
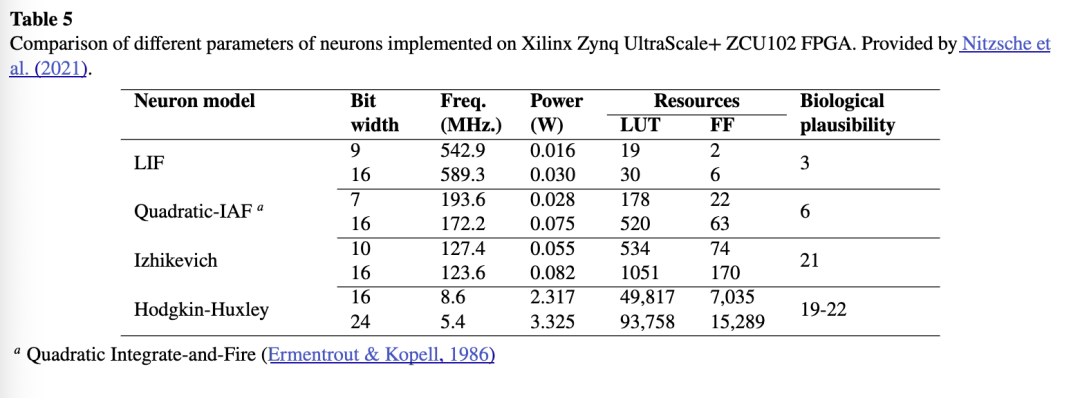
Nitzsche 等人(2021)在 Xilinx Zynq UltraScale+ ZCU102 FPGA 开发板上实现了多种神经元模型,并进行了比较分析。他们采用定点数表示数值,并根据误差水平确定每种模型的最佳位宽和小数点位置。他们未使用 DSP 单元,以便所有模型能公平比较,并全部使用逻辑单元完成运算。此外,在实现每种模型时,他们尽可能利用 2 的幂次特性,以消除对乘法器的需求。这种比较尤为重要,因为不同的 DSP 单元针对不同运算进行优化。表5 提供了每种神经元在相同 FPGA 模型下的位宽、可实现频率、功耗及资源利用率。同时,也标注了各模型的生物合理性,以提供更全面的比较。
对于一种极其高效的 LIF 神经元,Ye 等人(2022)提出了一种扩展预测校正(EPC)方法,取代常用的欧拉法。他们采用了二阶 EPC 方法,在获得参数后,通过移位操作执行计算。他们声称,使用 EPC 方法不仅消除了微分计算,还降低了硬件需求并提高了神经元对抗误差的稳定性。他们提出的 LIF 神经元结构包含 18 个触发器(FF)和 86 个查找表(LUT)。此外,他们利用遗传算法(Lambora 等人,2019)优化神经元阈值。这与超参数搜索过程中优化阈值的方法并无太大区别,因为此类搜索通常采用基于进化策略的方法。
通常,在 FPGA 实现中使用两种更新神经元状态的方法:时间驱动和事件驱动更新方法。在时间驱动算法中,每个时间步都必须检查所有神经元的状态,以确定是否产生脉冲。以下给出了时间驱动更新方程,其中假设采用简化的 LIF 神经元类型 𝑉ₜ₊₁ = 𝑉ₜ × exp(−Δ𝑡/𝜏):

其中,𝑉ₜ₊₁ 是第 𝑗 个突触后神经元在时间步 𝑡+1 的膜电位,𝑆ᵢ(𝑡) ∈ {0, 1} 是第 𝑖 个突触前神经元在时刻 𝑡 的状态,𝑊ᵢ,ⱼ 是第 𝑖 个与第 𝑗 个神经元之间的连接权重,𝑛 是神经元总数,𝜏 是漏电时间常数。该方法通常较为浪费,因为没有必要更新那些未接收到任何输入脉冲的神经元(Y. Liu 等人,2022),尽管它可能在发放活动较高的网络中,或在需要确定性执行的程序化工作负载中带来益处。
另一方面,在事件驱动算法中,神经元仅在事件发生时才被更新。如果某个事件发生并由一个神经元触发脉冲,则这些事件将被排队,下游神经元随之被更新。此方法可比时间驱动方法高效得多,但事件排序会增加硬件复杂度。然而,这一过程也可并行执行,类似于生物系统(Han 等人,2020)。事件驱动更新基于以下原则进行:

在(Carpegna 等人,2022)中,采用了一种时钟驱动(clock-driven)的方法来更新神经元的膜电位。这意味着在每个时钟周期内,都会根据LIF神经元的指数关系对膜电位进行评估。然而,输入仅在脉冲出现时才被检查。该方法虽然增加了功耗,但占用的硬件资源更少。
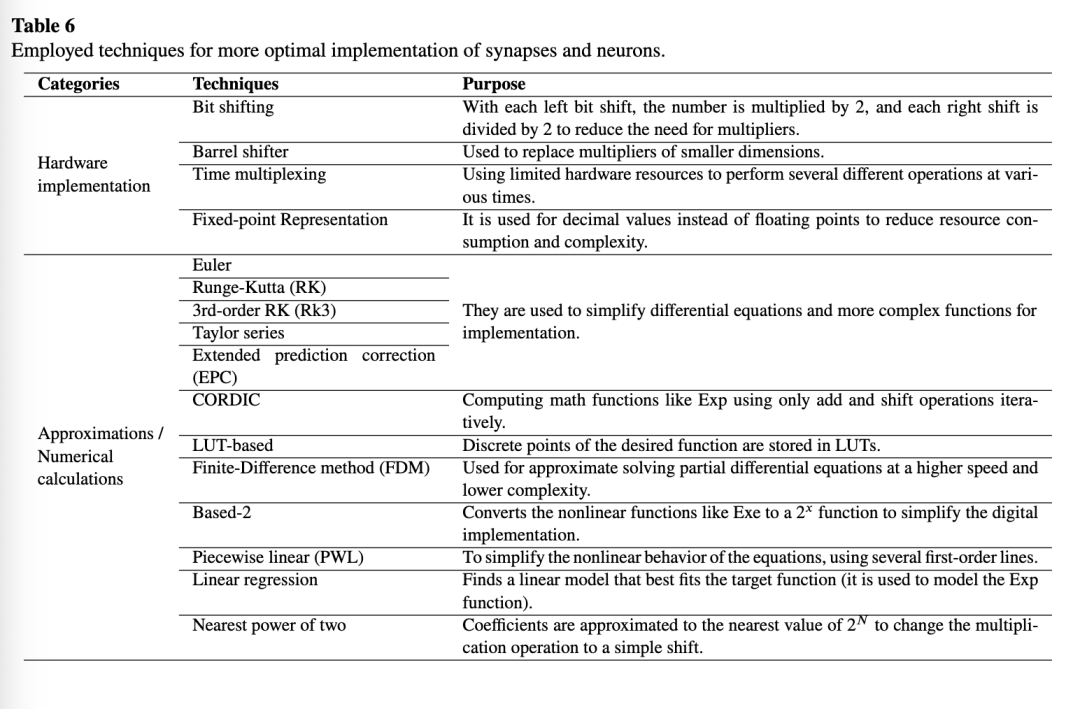
在FPGA上以类似于软件仿真那样精确的方式实现神经元和学习规则十分复杂,因此需要引入简化方法和技术以降低这种复杂性。在数据驱动任务的背景下,许多此类近似是可以接受的。因此,表6简要总结了所综述文献中使用的技术及其目标。
3.3.1 评估指标 鉴于所采用的近似方法数量众多,我们提供三种常用的主评估标准:

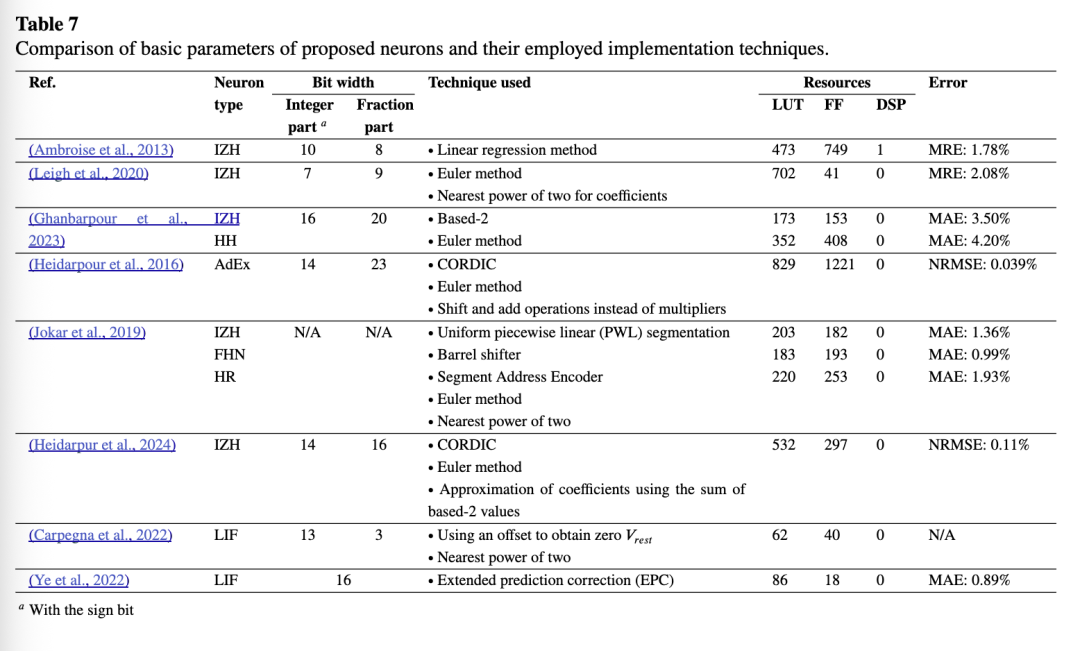
可使用多种参数来评估所提出的神经元模型并确定其最优性。除上述误差指标外,所使用的硬件资源等因素也至关重要。表7总结了数据可获取的各类神经元,包括所提出的神经元类型、位数、采用的简化与实现技术,以及相对于全精度实现所达到的准确率。最大可实现工作频率和执行时间也应被考虑,但由于其依赖于FPGA器件的具体型号,本文未将其列入。另一方面,表中所列数值代表各文献在不同执行条件下所能达到的最佳性能。需注意的是,神经元的生物合理性是选择和设计神经元的重要标准,它表明该模型能再现真实神经元的多少种生物学特征。在表7中,可根据生物合理性对IH、HR、IZH、FHN、AdEx和LIF神经元进行优先排序,尽管设计者也可能关注与基于梯度或局部学习规则兼容的神经元模型,这同样会影响特定应用下哪种模型更优。
3.4 网络架构与系统设计
即使各个模块设计精良且经过优化,网络的整体架构通常仍对整体性能起决定性作用。本节回顾了几种近期的FPGA系统实现方案,并研究了完整网络的设计方法及其组件与子模块间的交互方式。我们发现,为实现FPGA上不同子系统间更有效的交互,必须采用某些技术及附加组件——这些在软件框架中可能并不明显。
Han等人(2020)结合事件驱动与时间驱动方法实现网络,利用多个标记有时间戳Qₙ的事件队列(其中n的取值范围为0到D−1,D表示最大延迟)。因此,同时发生的事件被放入同一队列,无需排序。在每个时间步,活动队列为Q₀,此时执行事件处理并更新神经元状态。若某神经元发放脉冲,则一个新事件将带延迟被置入事件队列。当前步骤直至Q₀清空才结束。一旦事件队列变空,标签值减一,Q₀以循环方式重用,即变为Q_{D−1}。通过实施这种混合更新算法,消除了排序过程,从而降低了系统运行时的延迟。该结构包含四个主要组件,每个组件均配备一个控制器。
事件队列子模块负责事件队列的硬件实现,而事件控制器子模块负责管理这些队列。此外,还设有权重、状态和延迟存储器子模块,分别用于保存神经元的权重与状态以及各类事件的延迟。该结构的核心部分是状态更新器,它检查神经元的状态,在激活时将其值设为预设值,并定义新事件。状态更新器可并行执行,同时检查多个神经元的状态。
受Han等人(2020)启发,Y. Liu等人(2022)提出了一种具有时间-事件混合算法的新结构。该结构设计分为三部分:神经元计算架构、驱动算法设计、平台构建与测试。在神经元设计部分,该结构支持IZH和LIF两种神经元。在驱动算法设计部分,其实施采用了泊松脉冲算法、地址事件表示(AER)总线和环形先进先出(FIFO)结构。最终,通过整合所有部分,加速器平台得以完成。AER地址总线用于脉冲的最优传输(Boahen, 2000)。环形FIFO阵列用于缓冲输入脉冲事件和内部脉冲事件。只要FIFO非空,神经元更新将持续进行。
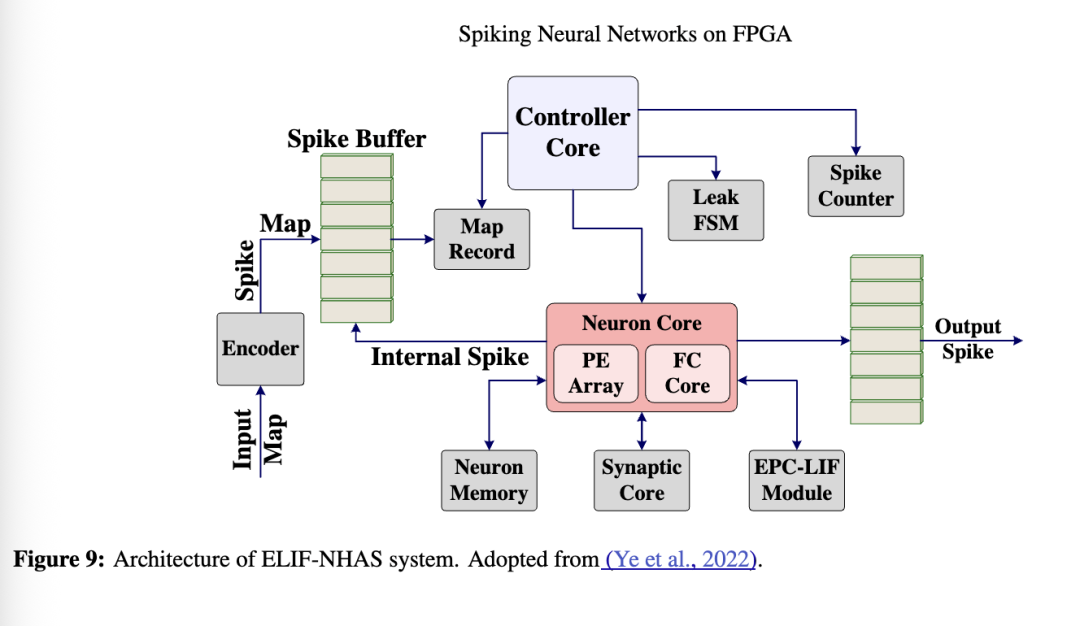
在Ye等人(2022)的文章中,作者提出了一种名为ELIF-NHAS的优化架构,能够基于收缩阵列架构(R. Xu等人,2023)执行多层感知机(MLP)和卷积运算。该架构的总体视图如图9所示。为确保系统功能正常,需要设计并排布各种组件与模块。本文中的网络输入为图像数据,首先送入编码器单元,通过泊松速率编码转换为脉冲,然后存入脉冲缓冲区。Map Record模块根据网络类型和需求重新排列数据。神经元核心由用于全连接计算的FC Core和用于卷积计算的PE Array组成。计算过程基于(Y. Liu等人,2022)以流水线和并行方式执行。神经元位于EPC-LIF模块内,其详细信息见第3.3节。膜电位和神经元状态在每一步更新后存储于神经元存储器中。当系统执行更新时,通过突触核心收集对应地址的权重。Leak FSM模块负责控制不同神经元漏电的同步。脉冲计数器统计神经元发出的脉冲数量,作为确定最终输出的基础。最后,控制器核心负责协调所有不同的系统模块。此外,该模块包含一个存储网络拓扑所有参数的内存,可通过UART总线配置,便于轻松修改网络拓扑。
在(Mitchell等人,2020)中,提出了名为μCaspian的架构及相应的PCB开发板设计。该设计提供了一种成本效益高、尺寸小、重量轻、功耗优化的神经形态硬件平台。本文的主要目标是为研究人员提供一种经济实惠的硬件选项和开源FPGA工作流。这是因为流行的硬件选项(如IBM的TrueNorth(Akopyan等人,2015)和Intel的Loihi(M. Davies等人,2018))公众难以获取,导致在实际应用中部署或评估它们具有挑战性甚至不可能。Xia等人(2020)利用以太网接口实现了其网络与其他FPGA通信的能力,从而能够构建大规模网络。
C. Tang & Han(2023)提出了一种权值二值化的脉冲神经网络(WB-SNN),旨在减少内存占用和硬件资源。在此网络中,脉冲被视为0和1,分别代表无脉冲和有脉冲;权重则被限制为-1和1。此外,为避免考虑符号位,-1被表示为0,仅需一位内存即可同时表示权重和脉冲。先前研究表明,SNN对权值二值化高度容忍,因为它们将信息投射到神经元状态和时间维度上(Eshraghian & Lu, 2022)。在该架构中,采用优先级编码器(PE)用于层间通信,其编码最高优先级的活动比特索引。编码后的比特指示内存地址位置,从而使比特宽度从N个输入通道降至log₂N。当PE完成对最高优先级比特的编码后,优先级解析电路(PRI)清除该比特,使PE继续编码次高优先级比特。此外,还使用了一个计数器来实现IF神经元的最简单、最节省资源的实现。
权值二值化和量化是一种常见的降低内存消耗的技术。然而,应注意的是,该技术应在训练过程中应用,正如Qiao等人(2020)所证明的那样,训练后应用该技术会导致网络准确率显著下降。类似地,S. Hu等人(2021)使用基于STDP的量化和二值化权值训练其网络。他们证明,使用4位量化权值的网络在MNIST数据集上达到了93.8%的准确率,而使用32位权值的网络准确率为94.1%。这表明,与显著减少的内存使用相比,准确率的下降可以忽略不计。此外,二值网络达到了92.9%的准确率,显著减少了内存使用并将输入-权值乘法过程转化为简单的AND操作。
在Chu等人(2022)的文章中,采用了一种基于(Yan等人,2021;Corradi等人,2019)的循环网络用于隐藏层,该网络具有循环和稀疏连接,被称为“液态池”。如图10所示,输入脉冲连接至液态池,从而处理时间特征并提高分类准确率。最后两层负责分类任务。液态池输出连接至分类器,以及输入层到液态池的连接,均采用稀疏连接以减少处理时间和成本。密集连接仅存在于输出层,以降低计算需求。此外,该网络中的所有权重均使用时空反向传播(STBP)算法进行训练(有关STBP更多信息,请参见Y. Wu, Deng, Li, Zhu, & Shi, 2018)。
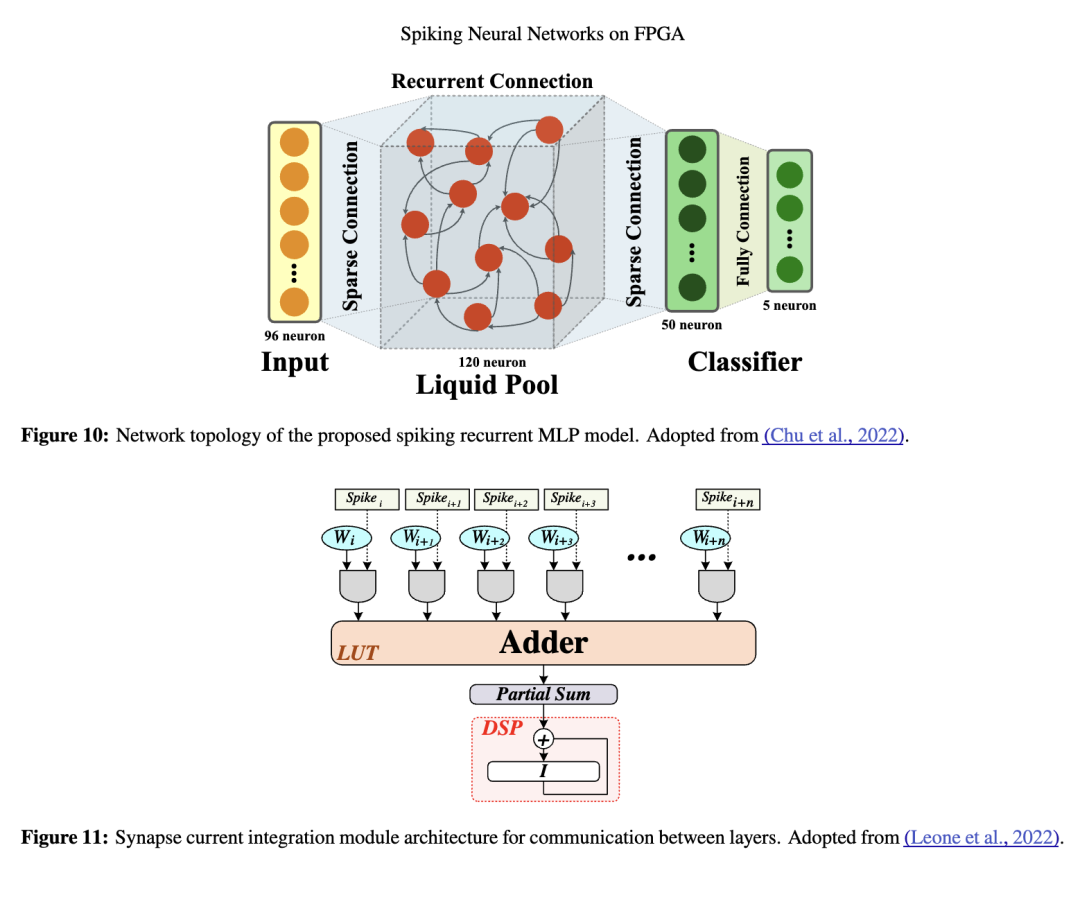
为了构建大规模网络,Leone等人(2022)提出了一种使用片外双倍数据速率(DDR)存储器的全连接网络,因为他们证明数据传输带宽足以避免系统中断。他们将突触权重存储在DDR内存中,通过高级可扩展接口(AXI)高性能端口与FPGA通信。然而,他们将Izhikevich神经元的参数和突触电流存储在块RAM(BRAM)中。由于Izhikevich神经元的输入必须是电流,他们根据图11所示方式进行层间通信。权重以64位值形式从DDR内存中提取,直接使用而无需缓冲。由于权重为8位,因此8位权重比特同时作为输入传入AND门,如图11所示。当脉冲通过每个神经元时,其权重通过使用LUT实现的加法器累加,然后使用DSP进行累积。
如前所述,各种个人和公司已推出了以数字为主的神经形态硬件平台,每个平台都具有独特的优缺点。S. Yang、Wang、Hao 等人(2021)提出了一种受生物启发的认知超级计算系统(BiCoSS)平台,该平台使用了35块 Cyclone IV FPGA,每块 FPGA 连接两个同步动态随机存取存储器(SDRAM)以及额外的组件和外围电路。借助异构多核架构,该平台能够实时支持超过四百万个脉冲神经元。他们的主要目标之一是开发一个具备多粒度能力的平台——这一特性在几乎所有先前的平台中都未能完全实现。此外,他们还旨在弥合神经科学与神经形态架构之间的鸿沟。本研究中的多粒度神经形态架构被划分为六个部分:从神经元形态角度看,该架构同时包含点神经元模型和区室神经元模型(S. Yang, Deng 等人,2019;Y. Sun 等人,2023);在生物合理性方面,支持多种神经元模型,如 LIF、IZ、HH 等;在网络拓扑层面,涵盖前馈网络和循环网络;在突触层面,包含电突触和化学突触;在学习规则层面,支持多种学习规则。
3.4.1 卷积脉冲神经网络 大多数基于 FPGA 的脉冲神经网络(SNN)研究集中于多层感知机(MLP)的探索与实现,而卷积神经网络(CNN)在计算机视觉任务中通常占据运算量的主导地位(Aung 等人,2021;Lemaire 等人,2020)。这种更强的特征提取能力是以增加运算量为代价的。因此,CNN 能从激活稀疏性中显著受益,因为激活稀疏性可大幅减少所需的总运算次数(Veeravalli 等人,2022;Tapiador-Morales 等人,2018)。
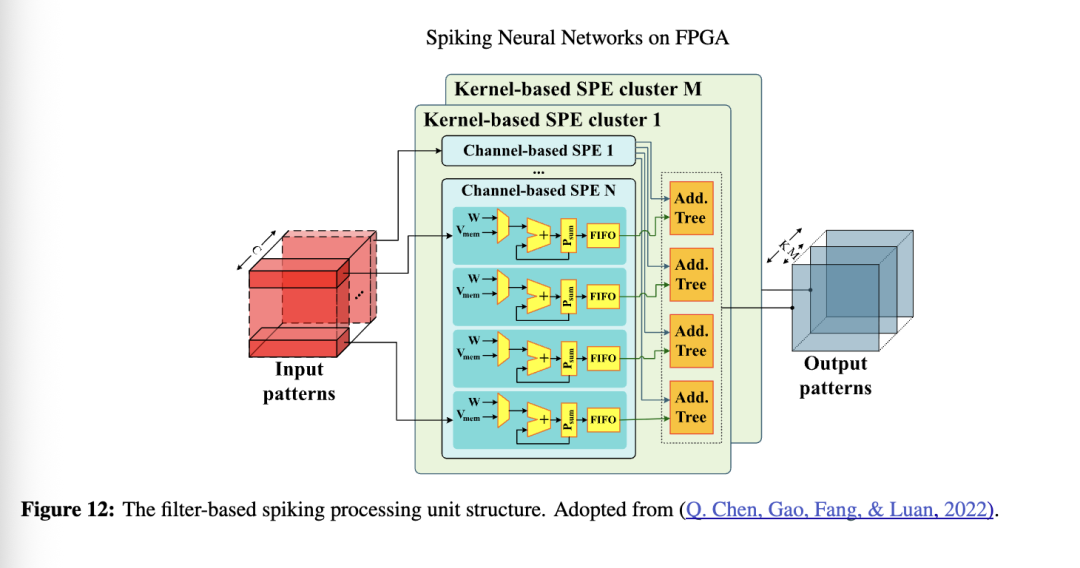
Q. Chen、Gao、Fang 和 Luan(2022)提出了一种卷积 SNN,其中处理单元由多个基于滤波器的脉冲处理单元(SPE)簇构成,如图12所示。显然,每个簇包含若干个基于通道的 SPE 和加法树。每个基于通道的 SPE 接收一个滤波器内部分卷积核,并计算部分膜电位之和,其中每个部分被划分为4个数据流。每个数据流产生的部分和由加法树进行汇总,最终计算出该簇中特定通道的输出膜电位。每个 SPE 簇连接一个存储权重的存储体。他们指出,由于输入通道的稀疏性各不相同,包含更多零值的 SPE 运算更快,而包含非零值的 SPE 造成最大延迟,从而导致负载不平衡。为解决事件驱动工作负载不平衡的问题,该论文提出了通道均衡工作负载调度(CBWS)方法,将输入通道划分为 N 个近似工作负载相等的组,并由 N 个 SPE 分别处理。文中通过近似比例关系构建(APRC)方法获得近似相对工作负载,并将其用于 CBWS。在应用这两种方法后,负载均衡比率从79.63%提升至94.14%。
Aung 等人(2021)提出了一种高性能的 RTL IP 核,通过将 IF 脉冲神经元集成到 CNN 中,以加速卷积 SNN 的推理。该神经元架构基于(Pani 等人,2017)进行配置,并采用三级加法树来整合权重与输入。加法树的第一级使用 DSP 实现,其余两级则通过可配置逻辑块(CLB)执行。此外,网络训练采用标准反向传播算法完成。
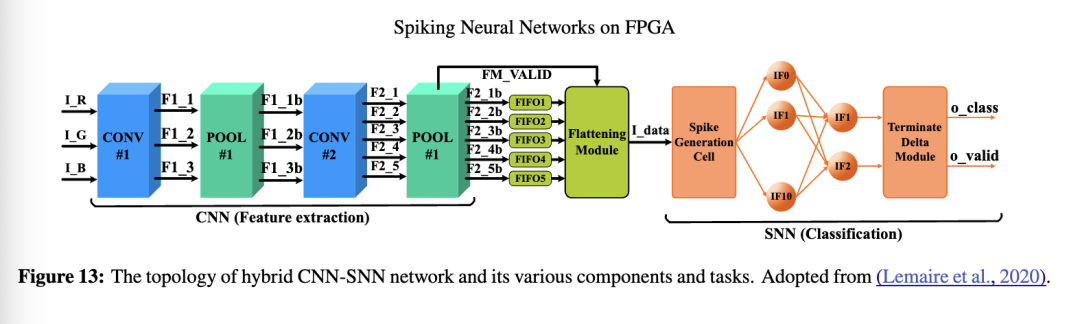
为实现更优的特征提取,Lemaire 等人(2020)首先利用 CNN 对输入图像进行处理,随后使用 SNN 进行优化分类。网络结构如图13所示。如图所示,RGB 图像作为输入送入尺寸为 28×28 的 CNN 网络。随后,卷积层和最大池化层提取出尺寸为 4×4×5 的潜在特征(Hamdan,2018)。这些特征被展平并通过脉冲发生器转换为脉冲序列。这些脉冲依次通过两层采用 IF 神经元的 SNN,最终层的输出由“终止 Delta 模块”(Terminate Delta Module)用于确定输出类别并完成分类。
Ju 等人(2020)实现了一个深度 SNN,该网络通过 ANN-SNN 转换方法进行训练(Rueckauer 等人,2017)。最大池化有助于减少网络参数数量(Scherer 等人,2010)。然而,其硬件实现面临挑战,因为在每个时间步都必须考虑神经元的发放率。受 Y. Hu 与 Pfeiffer(2016)的启发,发放率根据所提出的公式41进行计算。在该公式中,𝑥ᵢ(𝑡) 表示神经元 𝑖 在时刻 𝑡 是否发放脉冲,𝑇 为一次输入呈现的时间窗口长度。

J. Li 等人(2023)提出了若干解决方案,以应对 FPGA 中的数学计算挑战和内存限制。他们在 Xilinx Ultrascale FPGA 上实现了一种脉冲卷积神经网络(SCNN)。他们将突触进行打包,并将其送入 DSP48E2 单元,然后利用脉冲信号动态启用或禁用这些 DSP,从而以更少的硬件资源构建出高速交叉开关(crossbar)。对于一个 16×4 的交叉开关,仅需 8 个 DSP,且无需使用 LUT 和 FF。此外,他们通过一种分层的数据传输机制,在片外内存带宽与片上内存对权重和神经元状态的消耗之间取得平衡,从而实现了更高的内存效率。
为加速从深度神经网络(DNN)到脉冲神经网络(SNN)的转换推理过程,S.-Q. Wang 等人(2020)提出了一种名为 SIES(SNN 推理引擎)的架构。他们将所有计算单元集成到一个统一的脉动阵列(systolic array)中,以加速膜电位的计算。他们还增加了一个可选的最大池化模块,以减少不必要的数据移动,并开发了一种硬件机制,用于更快地准备输入脉冲。他们所提出的架构显著提升了数据处理效率,并增强了 SNN 的硬件并行化能力。
为了在利用 CNN 强大能力的同时避免其超参数繁多的问题,从而在 FPGA 上实现高效执行,Y. Chen 等人(2023)提出了一种采用参数融合与量化技术的网络,以减少资源占用。他们提出的网络能够执行标准卷积和残差卷积。此外,一些文献(如 Q. Chen、Gao 与 Fu,2022;Khodamoradi 等人,2021;Gerlinghoff 等人,2022;Sommer 等人,2022;Irmak 等人,2021)也聚焦于在 FPGA 上实现卷积型 SNN,这些工作可为进一步理解与开发提供参考。
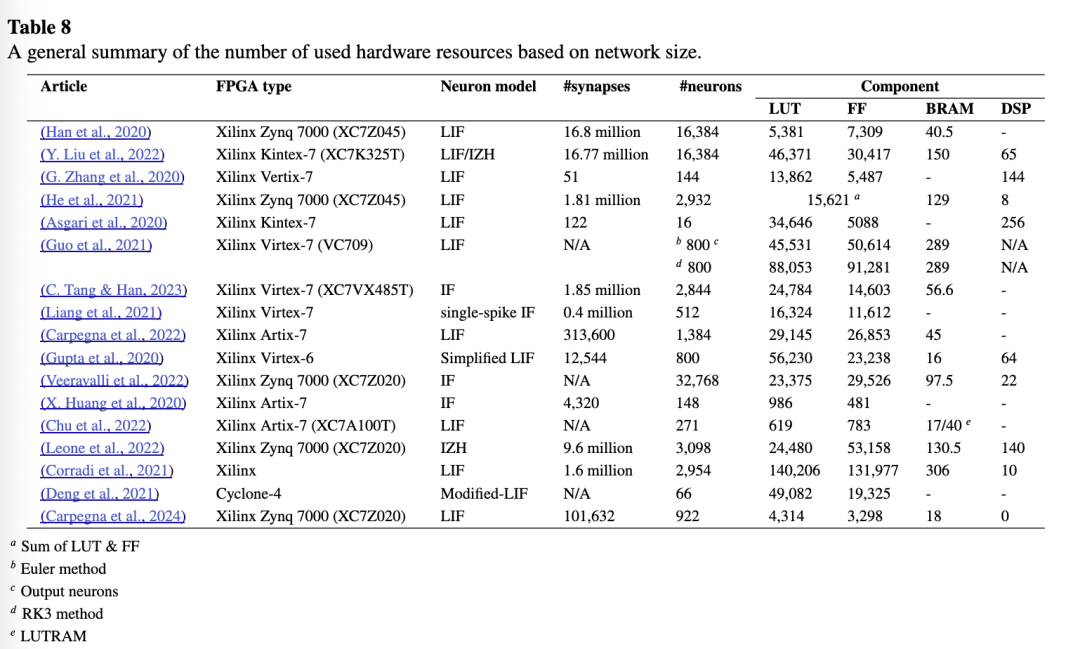
为便于对“网络架构与系统设计”一节中各项研究在 FPGA 上实现和执行 SNN 的情况进行总体比较和深入理解,表 8 汇总了提供相关信息的文献。这些研究根据所使用的 FPGA 类型,以及按突触和神经元数量所消耗的硬件资源进行了梳理。此外,表 9 汇总了所综述文献中与分类任务相关的信息,包括训练类型、学习方法、网络准确率以及所使用的硬件描述语言。同时,文中也列出了用于分类任务的数据集,并提供了相应引用,以向研究人员介绍此类任务中常用的数据集。我们注意到,所有这些研究均使用静态时间数据集(time-static datasets),未能充分发挥基于脉冲的时间计算潜力。因此,我们鼓励研究社区在时变数据(time-varying data)上测试其实现方案,因为传统 ANN 能够直接处理图像而无需将其映射到时间维度,通常具有更低的延迟(Ottati 等人,2023)。
另一方面,近期研究开始关注新兴且更复杂的网络结构,例如基于 Transformer 的网络,并已在 FPGA 上实现(如 Udeji 与 Margala,2024;Vishwamith 等人,2024)。这些努力为未来的发展带来了希望。因此,我们也鼓励研究人员超越简单网络的实现,迈向更复杂任务的处理,并应对在硬件和 FPGA 上实现此类网络所带来的挑战。
3.5 FPGA 上对稀疏性的利用 尽管 FPGA 本质上是为同步处理而设计的,这给典型稀疏神经网络中常见的异步计算带来了挑战,但通过策略性的设计选择可以缓解这些限制(Shahsavari 等人,2020)。当用于利用稀疏性的额外电路开销(例如电源门控和时钟门控、在无数据输入时停用后续处理的多路复用器(针对稀疏激活),以及用于编码稀疏数据格式的硬件)小于执行全部计算和内存访问所带来的开销时,实现针对稀疏工作负载的加速技术就是合理的(Y. Chen 等人,2024)。电源门控和时钟门控技术可在功能单元未处理活跃神经元时将其关闭,从而在不破坏 FPGA 同步运行的前提下有效降低动态功耗(Leone 等人,2024)。
通过将 FPGA 架构划分为若干区域,并根据工作负载独立地对各区域进行时钟门控,设计者可以构建一种更节能的实现方案,充分利用稀疏激活所具有的非规则计算模式(Blott 等人,2018)。此外,在以同步设计为主的系统中引入异步 FIFO 缓冲区和握手协议,有助于管理由稀疏性引起的数据流。
在神经网络中利用稀疏激活为优化 FPGA 上的内存访问模式和计算效率提供了重要机遇(T. Li 等人,2024)。稀疏激活——即大量神经元输出为零值——在使用 ReLU 等激活函数的网络中很常见,尤其在脉冲神经网络(SNN)中更为显著。利用这种稀疏性可以降低内存带宽需求和计算负载,这对于片上内存有限、并行处理能力受限的 FPGA 尤为有利(H. Liu 等人,2024)。根据具体神经网络的规模和需求,采用不同的稀疏性利用方法将带来不同的收益。
- 减少内存访问:对于可完全放入 FPGA 片上内存的小规模模型,可采用诸如“跳零”(zero-skipping)等技术,以最小化 SRAM 访问和计算操作。通过设计能够检测零值激活的定制化处理单元,FPGA 可跳过与这些零值相关的不必要计算及内存读/写操作(Jiang 等人,2024)。这种选择性计算减少了运算次数,并通过避免逻辑门和存储单元的翻转来节省功耗。在计算方面,稀疏矩阵-向量乘法(SpMV)优化也可有效用于非零元素密度较低的全连接层(Y. Liu 等人,2024)。具体实现可超越仅以 RTL 朴素描述 SpMV 的方式,而将此类操作表达为包含跳零机制的架构(Ma 等人,2017)。在这些设计中,处理单元配备控制逻辑以检测零值输入和输出,从而使阵列能够跳过不必要的计算和数据移动。
- 降低内存占用:基于 SNN 的加速技术可借鉴 FPGA 上深度剪枝神经网络的思路。剪枝通过移除网络中重要性较低的权重和神经元,生成更稀疏的模型,从而减少计算资源需求。细粒度剪枝可显著缩小模型规模并降低计算需求,使整个模型无需访问外部 DRAM 即可完全存入片上内存。例如,FINN(Fast, Scalable Quantized Neural Network Inference)同时利用了极端量化和权重稀疏性(Blott 等人,2018)。然而,除非权重稀疏到可以将非零权重的地址以压缩形式编码并存入片上 SRAM,否则权重稀疏性仍可能需要一次内存访问来判断权重是否存在,之后才能跳过下游操作。
对于因规模庞大而必须使用外部 DRAM 的大型模型,利用激活稀疏性变得更加关键。压缩稀疏格式(如压缩稀疏行格式 CSR 或坐标格式 COO)可通过仅存储非零元素及其索引来高效表示激活矩阵和权重矩阵,从而显著减少 FPGA 与 DRAM 之间的数据传输量(T. Li 等人,2024)。
专用内存控制器和数据流架构可处理这些稀疏数据格式。通过仅获取和处理非零元素,系统降低了对 DRAM 带宽的需求,并减少了与内存事务相关的能耗。内存分块(tiling)和阻塞(blocking)等技术进一步优化了内存访问模式,确保从 DRAM 获取的数据在被替换前得到充分利用。
- 电源门控策略:电源门控策略在 FPGA 上实现 SNN 时尤为有效。通过在脉冲发生前关闭空闲的神经元或突触,网络可在非活跃期间显著降低功耗。该方法契合 SNN 的事件驱动特性,并利用 FPGA 的同步操作实现能效优化。然而需注意,由于 FPGA 具有固定结构,应用电源门控技术比在电路级实现中更具挑战性,且方法有所不同。这类技术在 ASIC 设计中通常更为有效(Jahanirad,2023)。
- 脉冲神经网络(SNN)的应用 随着 SNN 的进一步发展及其在更高级任务中能力的提升,研究重点已不仅限于网络扩展和组件设计,而是延伸至现实世界的应用。本节将考察近年来在 FPGA 上实现的部分代表性 SNN 应用。
便携式医疗健康设备是 SNN 极具前景的应用领域之一,因其相较于人工神经网络(ANN)具有更高的能效和更低的功耗,使其非常适合用于患者的持续监测、控制与自适应调节(Chu 等人,2022;Corradi 等人,2019)。然而,目前在硬件上实现的浅层网络尚未在生物医学信号处理中得到充分挖掘。在此背景下,Xing 等人(2022)利用 SNN 在 FPGA 上实现了心电图(ECG)分类的实时便携式处理。为解决先前 SNN 研究准确率较低的问题(Amirshahi & Hashemi,2019),他们引入了通道注意力模块(CAM),从 ECG 通道中提取关键信息,并将其融入信号的形态学特征中。通过这种方式,显著特征更加突出,有助于更优、更准确地检测 ECG 心律失常。该文采用 ANN 到 SNN 的转换方法。此外,Chu 等人(2022)也尝试在 FPGA 上实现用于连续健康监测的 ECG 分类。他们使用 LC-ADC 将输入 ECG 信号转换为脉冲,并采用 STBP 学习算法训练其轻量级 SNN 模型,在 MIT-BIH 数据集上实现了 98.22% 的癫痫发作检测准确率(Moody & Mark,2001)。
除生物医学信号分析外,SNN 在机器人领域也备受关注,因为该领域可用的计算资源通常极为受限。例如,Walravens 等人(2020)提出在 FPGA 上结合强化学习使用 SNN 实现机器人的避障功能。Hao 等人(2019)和 K. Wang 等人(2023)通过在 FPGA 上对小脑进行建模,实现了对机械臂的实时控制。此外,Canas-Moreno 等人(2023)将一种基于脉冲的 PID(比例-积分-微分)控制器应用于具有 6 自由度的 Scorbot ER-VII 机械臂。该控制器采用脉冲频率调制(而非传统的脉冲宽度调制)驱动电机,使其行为模拟运动神经元对肌肉的控制方式。该控制器在 Xilinx Spartan 和 Zynq MPSoC 两种 FPGA 上实现并进行了测试。Gutierrez-Galan 等人(2020)提出了 NeuroPod——一种用于机器人应用的实时神经形态脉冲中枢模式发生器(CPG)。受昆虫等生物实例启发,该研究旨在推动机器人超越重复性任务,迈向更复杂的行为。其六足机器人系统由 SpiNNaker(Furber 等人,2014)和 FPGA 板共同组成并控制。实时测量结果验证了仿真效果,证明该机器人能够无缝执行步态,无失衡或延迟现象。
听觉系统是人脑的核心组成部分之一,能够通过耳朵接收并理解声音。声音识别是一项高度依赖时间信息的任务,因此 Deng 等人(2021)提出了一种利用 SNN 时间特性的听觉系统,并在 FPGA 上实现。他们基于声音的强度和频率,使用泊松编码将声学输入波形转换为脉冲,并通过一个受 Khatami 与 Escabí(2020)启发的网络进行分类。该网络由 6 层、每层 11 个改进型 LIF 神经元组成,并采用贝叶斯推断进行分类。其分层结构使其在噪声环境下仍能实现可接受的准确率。他们在后续工作(Deng 等人,2023)中进一步扩展,构建了一个由 10 块 FPGA 组成的更大规模网络,并优化了各组件,性能较之前显著提升。在含噪声环境下,其在 TIMIT 数据集(Garofolo,1993)上的语音检测准确率达到 85.75%。
Asgari 等人(2020)提出了一种用于上下文相关任务的 SNN,其中采用了强化学习。该文将 LIF 神经元简化为仅需两次求和运算,并使用基于查找表(LUT)的近似方法实现 STDP,从而降低了硬件成本和功耗。S. Yang、Wang、Deng 等人(2021)也在 FPGA 上实现了其神经形态系统,目标是实现上下文相关学习与容错能力。
Lemaire 等人(2020)针对空间应用中卫星图像分类对低功耗嵌入式网络和高准确率的需求,提出将 CNN 用于特征提取、SNN 用于高效分类的混合架构(更多细节见第 3.4.1 节)。Lent 在(2020, 2021)中提出了一种认知网络控制器(CNC),利用 SNN 在 FPGA 加速下于复杂场景中做出自适应路由决策。George 等人(2021)则探索了利用 SNN 进行对称性感知,借助 SNN 的“巧合检测”(coincidence detection)特性来识别镜像对称。他们在地理空间卫星图像上测试了所提出的系统,并通过包括 FPGA 在内的多种硬件平台,展示了其自动区分人造结构与植被的能力。该能力在图像渲染、机器人、脑机接口以及弥合传感器输入与高层语义解释之间的鸿沟方面具有广阔前景。
X. Huang 等人(2020)利用 SNN 的事件驱动特性,在 FPGA 上实现了放射性同位素的检测。他们首先在 SpiNNaker(Furber 等人,2014)上将 ANN 结果转换为 SNN 以提升执行速度,随后将整体方案部署到 FPGA 上。此外,在(X. Huang 等人,2021)中,他们提出了另一种结构以执行该任务,并改进了先前的设计。
结构健康监测(SHM)用于评估影响结构可靠性的损伤。为检测由负载和日常使用引起的损伤,现代 SHM 系统需要持续监测。Javed 等人(2021)提出了一种基于 SNN 的 FPGA 实现的 SHM 损伤分类模型。该模型具有低成本、高能效的特点,并在对一栋 7 层混凝土建筑的地震损伤分类中达到了 99.46% 的高准确率。
无人机(UAV)通过与多种传感器交互,从周围环境中采集物理数据,通常利用深度神经网络(DNN)进行识别。Corradi 等人(2021)通过采用脉冲神经网络(SNN)替代 DNN,提升了能源受限无人机的能效。他们利用光学-雷达双时相数据集对农业产品进行像素级分类。S. Yang 等人(2023)开发了一种基于车联网(IoV)的智能导航系统,并在由六块 Altera Stratix III FPGA 芯片组成的 LaCSNN 系统上实现了容错边缘计算(S. Yang, Wang 等人,2019)。该系统采用受生物启发的计算方法,能够在复杂环境中实现精准导航与避障。
本研究的关键创新在于:开发了一种用于脉冲信息传输的容错路由算法,并设计了一个面向智能边缘计算系统的框架。实验结果表明,该系统提高了资源利用效率,降低了处理延迟,并增强了实时处理任务的容错能力。所提出的模型可作为智能交通中自动驾驶车辆智能导航与避障系统的基础,利用生物启发方法推动智慧交通的发展。
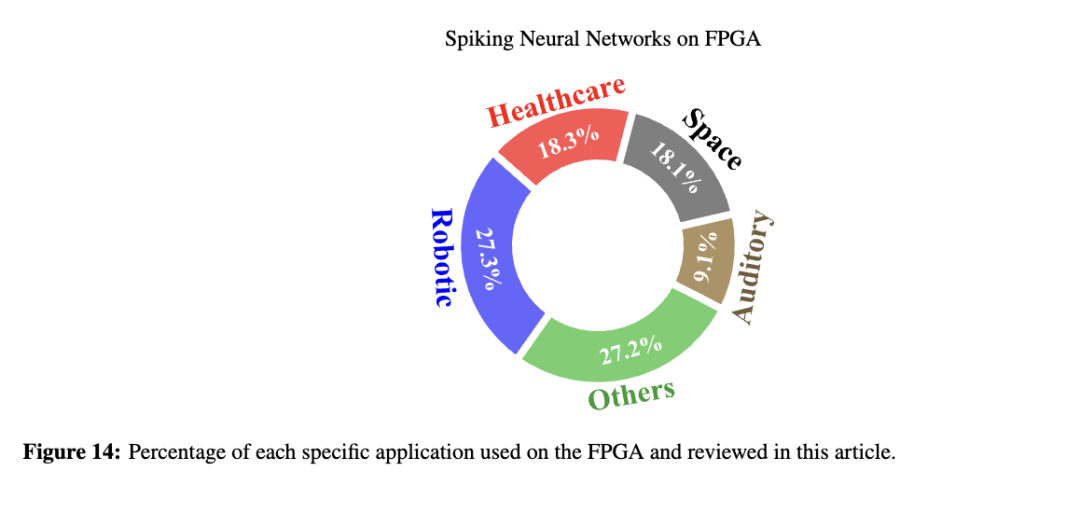
图14展示了本节所讨论的各类应用在 FPGA 上的资源利用率百分比,以便更清晰地理解。需要注意的是,此前各章节中的大多数研究工作集中于图像分类任务(如 MNIST 数据集),属于图像处理范畴;而本节则更侧重于超越玩具数据集(toy datasets)的真实世界应用任务。
- 未来工作、差距与机遇
在本节中,我们探讨了在 FPGA 上开发脉冲神经网络(SNN)所面临的挑战。这些挑战基于近期文献中已识别的问题与空白,强调未来研究需给予更多关注并付出努力以解决这些问题。
• 受脑启发的多层监督学习:SNN 的训练仍是一个开放的研究课题,目前尚未有效开发出能与误差反向传播具有同等效能的局部训练算法(Mehrabi, Bethi, van Schaik 等人,2023)。代理梯度下降法已扩展至大型架构,以克服脉冲不可微分的问题,但此类工作负载通常在片外执行(Neftci 等人,2019)。ReckOn 芯片提出采用实时循环学习(RTRL)的近似方法,以避免增加内存复杂性,但附加的近似使得将 RTRL 基础的学习规则扩展到大规模架构面临挑战(Frenkel & Indiveri,2022)。最近该实现已被移植到 FPGA 上,显示出替代反向传播的学习规则仍可保持相当高效性的有前景路径(Linares-Barranco 等人,2024)。
尽管基于 RTRL 的技术通过时间维度解决了反向传播中的时间局部性问题,它们仍存在空间局部性不足、更新锁定以及需要对称反向路径等缺陷。而具备更强空间局部性的技术,如 ReSuMe(Ponulak & Kasiński,2010)、Chronotron(Florian,2012)、Tempotron(Gütig & Sompolinsky,2006)和 SpikeProp(Bohte 等人,2000),利用各种损失函数,成功将反向传播算法适配于单层监督训练网络。值得指出的是,这些方法在计算输出误差和更新各层时需要大量运算,通常在 GPU 上执行,并在 FPGA 上占用显著资源。
考虑到上述因素,开发一种更贴近大脑生物学原理、支持多层训练的适当监督方法,对于提升计算性能与能效至关重要。这一目标不仅能提高硬件效率、降低功耗,还能增强系统与 FPGA 等硬件的兼容性。此外,它还提供了改进的解决方案,以应对受脑启发算法在监督学习中存在的缺陷,从而显著降低训练复杂度。
• 硬件可用性:阻碍神经形态工程进展的一个主要障碍是硬件资源的有限可用性。尽管在推进神经形态硬件及研发 IBM TrueNorth 和 Intel Loihi 等神经形态芯片方面已有大量研究,但获取和使用这些硬件对神经形态及非神经形态研究人员而言仍然困难(Mitchell 等人,2020)。已有颇具前景的努力致力于使学术界广泛访问定制硬件,例如 SpiNNaker 2(Gonzalez 等人,2024)和 Loihi,但为了继续推动新且有效的学习规则探索,仍需可重构硬件解决方案——因为将其集成到 ASIC 中过程过于缓慢。一项有前景的努力是 DeepSouth 大规模 FPGA 系统(ICNS,2024),预计将于 2025 年公开提供。
• 内存瓶颈:在 FPGA 上开发 SNN 的主要关注点之一源于内存限制所造成的瓶颈。随着网络规模扩大,此瓶颈限制了进一步的性能提升。参数数量的增长给硬件设计带来挑战,特别是在高效访问分布式内存方面。这种低效已成为在硬件受限平台上(尤其是资源有限的 FPGA)实施 SNN 的主要制约因素(C. Tang & Han,2023)。因此,提供诸如简化网络与组件等方法,在不显著牺牲网络精度的前提下减少内存与资源需求,将是极为高效且至关重要的。
其中一个解决方案是使用片外存储器(如 DDR)。然而,使用片外存储器也存在高功耗和带宽限制等缺点,尤其当网络进一步并行化时。因此,应开发适当的方法用于访问片外存储器、片上数据缓冲以及对其进行合理管理(J. Li 等人,2023)。
• 安全问题:鉴于 SNN 巨大的潜力及其日益增长的应用与发展,预计它们将在未来的网络物理系统(尤其是物联网 IoT)中受到更多关注。因此,必须严肃考虑安全问题,并评估新颖方法以缓解侧信道攻击。Garaffa 等人(2021)证明,通过在 FPGA 上实现 Izhikevich 神经元,信息泄露可能通过系统的时序和功耗发生,并可通过逆向工程攻击提取系统内部信息和神经元权重。
• 容错能力:人们普遍认为,由于 SNN 与生物大脑相似,因此对制造过程中可能出现的硬件故障具有鲁棒性。然而,近期研究表明,这一假设并不总是成立。这些网络仍可能因辐射、老化及其他因素导致故障(Putra 等人,2021;Spyrou 等人,2021)。此外,传统计算中常用的标准化容错技术(如三模冗余 TMR 和纠错码 ECC)对硬件加速器通常无效(Spyrou 等人,2022)。因此,针对成本效益高的容错设计,需进一步评估性能-错误场景,并推荐适用于实际部署的硬件友好型容错技术。另一方面,在设计大规模神经形态系统时,应考虑两个重要特性:1)系统应具备在线学习能力;2)系统应具备容错能力(S. Yang, Wang, Deng 等人,2021)。系统同时支持这两种能力对于适应易出错环境至关重要。
• 强化学习:SNN 的一个核心且关键应用是在线学习及其在现实场景中的应用。强化学习是这些网络的关键特征,要求它们通过与环境交互进行在线学习。这一特性在机器人、自动驾驶和自然语言处理等相关应用中尤为突出(Lagani 等人,2023)。尽管在线实施强化学习具有一定优势,但由于多种原因,其成本较高。首先,该过程耗时,因为学习所需的事件并发性很少出现。其次,错误成本高昂,因为错误可能导致系统损坏(Walravens 等人,2020)。因此,通过仿真获取知识再应用于系统,是缓解这些挑战的一种可能方案。然而,仿真与现实之间的差异本身也是一个导致故障的因素。一种解决方案是迁移学习(Ghaffari 等人,2023),但开发最小化上述挑战的在线学习系统至关重要。这种在线学习功能使 SNN 区别于传统神经网络,使其成为在不可预测和动态变化场景中快速决策的强大工具。
• 医疗便携设备:便携式设备的功耗至关重要,而在健康监测设备中,这一问题更为关键,因为这些设备需要持续监控个体或患者的健康状况(Zompanti 等人,2021)。SNN 在患者自适应和疾病检测与预测方面潜力巨大,例如通过持续监测 EEG 和 ECG 信号(Amirshahi & Hashemi,2019;Luo 等人,2020)。SNN 有望在需要连续健康监测的情境下提供更低能耗的疾病检测与预测。然而,迄今为止大部分工作因采用浅层网络而面临准确率方面的挑战(Xing 等人,2022)。随着 FPGA 技术的进步,更大规模嵌入式 SNN 将成为可能,从而使这些模型的效率提升至满足真实世界便携式部署所需的标准。
• 编译器框架:在 FPGA 上实现神经网络是一项更为繁琐的任务,因为 TensorFlow、Caffe 和 PyTorch 等框架不涵盖 FPGA 实现,且在 CPU 和 GPU 上运行时更容易操作(Javanshir 等人,2022)。然而,近年来引入的 BindsNET(Hazan 等人,2018)可与 FPGA 和 ASIC 等硬件接口运行,但仍需进一步发展。另一方面,FPGA 开发公司已推出高级综合(HLS)工具,旨在通过软件编码简化与硬件的协作,但相比硬件描述语言(HDL),它们仍缺乏用户对所有设计组件的精确控制(Gerlinghoff 等人,2021;Cong 等人,2022)。
FPGA 编译器框架对于加速器的广泛应用至关重要。它们使不熟悉硬件工程的研究人员和开发者能够更轻松地在 FPGA 上实现 SNN(T. Chen 等人,2018)。另一方面,硬件实现的 SNN 在执行更复杂操作时落后于软件仿真,但在执行较简单任务时表现良好。原因之一是缺乏更先进的 FPGA SNN 执行框架,以及硬件描述语言带来的灵活性与挑战。尽管如此,像 Gerlinghoff 等人(2021)、Gillet 等人(2022)等文章已努力开发通过 PyTorch 在 FPGA 上实现的简化软件框架,以及结合 PYNQ 板卡(Stornaiuolo 等人,2018;H. Li 等人,2024),可以通过 Python 语言对 FPGA 进行编程。尽管成果令人鼓舞,但差距依然明显,亟需进一步开发。一个有前景的方向是开发神经形态中间表示(NIR),作为通用 SNN 库之间交叉兼容的交换格式(Pedersen 等人,2023)。
• 商用 FPGA 的局限性与进步:商用 FPGA 尽管提供无与伦比的灵活性和可重构性,但其固有的局限性会显著影响 SNN 的设计与实现。SNN,特别是那些具有复杂动力学特性的网络,往往需要大量的资源进行实时处理。然而,有限数量的可用逻辑单元(如 FFs、LUTs 和 DSPs)和内部存储器(BRAM)会限制神经网络架构的复杂性,尤其是在考虑深层或生物准确性更高的模型时。此外,外部存储器带宽和输入/输出能力的限制也会阻碍处理单元与内存之间的通信速度,从而可能损害大规模 SNN 的性能并削弱其并行化能力(C. Tang & Han,2023)。
尽管面临这些挑战,近期 FPGA 技术的进步已解决或缓解了其中许多限制。超大规模架构(如 Xilinx UltraScale+ 和 Intel Stratix 10)的出现,显著增强了逻辑资源、更易访问的 BRAM 以及更高效的 DSP 片段。这些改进促进了越来越复杂的深层 SNN 的部署。当代 SoC FPGA,如 Xilinx Zynq 系列,集成了 ARM 处理器,提供了一种结合硬件加速与软件灵活性的混合平台。这种异构架构支持更高效的任务划分,从而降低延迟并提高 SNN 的能效。
近期的技术突破还引入了自适应计算加速平台(ACAP),如 Xilinx Versal,巧妙地将 FPGA 逻辑与集成 CPU 和专用 AI 处理引擎相结合(B.-Y. Huang 等人,2024)。此外,在前沿 FPGA 加速器(如 Xilinx Alveo)中集成高带宽内存(HBM),大幅提升了内存访问速度——这是神经计算中的关键因素(K. Kim & Park,2024)。
这些技术进步为 SNN 实现开辟了新的视野,使创建更复杂、更高效的类脑人工神经网络成为可能。结果是,它们正在推动类脑计算的边界,为从机器人与自主系统到高级模式识别与认知计算等领域的突破性应用铺平道路。
- 结论 脉冲神经网络(SNN)作为第三代神经网络,因其采用受大脑启发的计算模式,在低功耗和高速计算方面引发了高度期待与希望。模仿人脑以实现更高效的计算需要并行处理能力,而传统处理器难以胜任这一任务,且功耗较高。FPGA 凭借其独特的能力,包括对并行处理的支持、快速的设计迭代周期,在 SNN 加速、原型设计和迭代测试方面具有重要价值。
本文致力于系统梳理大量关于在 FPGA 上实现 SNN 加速与建模的文献。我们识别出 SNN 应用中存在的一系列挑战,并通过推动若干具体应用场景加以说明,最后讨论了未来值得进一步深入研究的新兴挑战。
原文链接:https://www.researchgate.net/publication/389054889_Spiking_neural_networks_on_FPGA_A_survey_of_methodologies_and_recent_advancements
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-09-28,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号