拆解 Clawdbot(OpenClaw):深入核心看多代理AI如何协调工作

拆解 Clawdbot(OpenClaw):深入核心看多代理AI如何协调工作

技术人生黄勇
发布于 2026-03-11 17:38:07
发布于 2026-03-11 17:38:07
“ Clawdbot(又名Moltbot)的项目正引发技术圈的热议。它如何在本地环境中协调多代理执行、实现工具调用与浏览器交互?本文将从系统架构角度深入解析其核心模块——从网关服务器的请求调度,到代理运行器的智能决策,再到内存管理与安全执行机制。”
上次在云平台快速部署了Clawdbot之后,我在云端搭了个“贾维斯”:Moltbot(Clawdbot)云端部署与初体验,我对这个开源工具的工作原理很好奇。特别是它如何处理代理(Agent)执行、工具调用和浏览器交互等核心功能。对于AI工程师来说,这里有不少值得借鉴的设计思路。
01
—
核心架构
了解Clawdbot的底层机制,不仅能更好地理解这个系统,更重要的是,能看清它的优势与局限。
Clawdbot是一个用TypeScript编写的命令行(CLI)应用程序。注意,它不是Python程序,也不是Next.js或一般的Web应用。它是在你电脑上运行的一个进程,主要提供以下功能:
- 作为网关服务器,负责连接飞书、QQ、企业微信、Telegram、WhatsApp、Slack等各种通讯渠道。
- 调用各类大语言模型(LLM)的API,包括Anthropic、OpenAI以及本地模型。
- 在本地执行各种工具。
- 它能在你的电脑上执行被允许的任何操作。
核心架构:一次请求的旅程
为了更好地解释其架构,下面通过具体案例来看看:当你给Clawdbot发送一条消息,直到收到回复,这期间发生了什么?
以下是Clawdbot在处理来自通讯应用的消息时的步骤:
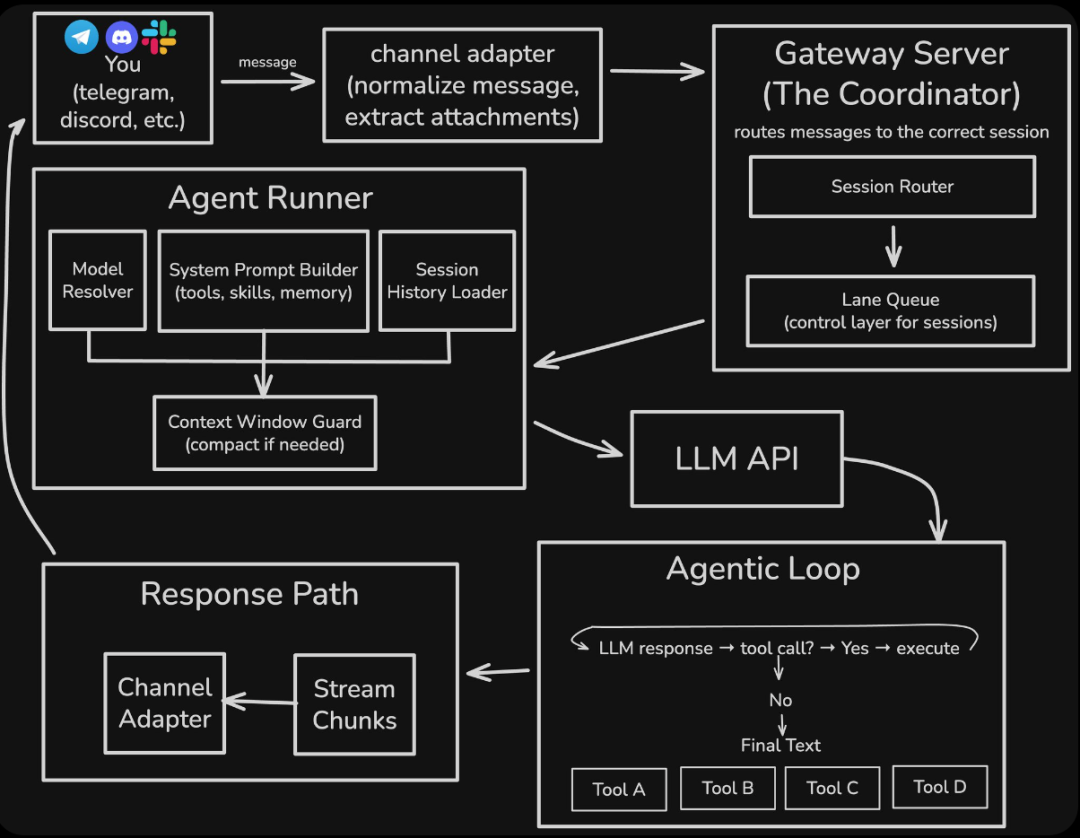
1. 渠道(Channel)适配器
适配器首先接收你的消息,并进行预处理(如标准化格式、提取附件)。不同的通讯平台都有其专用的适配器。
(注:这部分用于对接各种通讯渠道,例如飞书、WhatsApp,便于用户操作命令bot。)
2. 网关服务器
网关服务器是整个系统的核心,扮演着任务协调员的角色。它接收消息,并将其路由到正确的会话中处理。Clawdbot能够同时处理多个重叠的请求。
为了保证操作有序,Clawdbot采用了基于“通道”的命令队列设计。每个会话有自己专用的通道,确保任务串行处理。而一些低风险、可并行的任务(例如定时任务)则可以在独立的并行通道中运行。
这种设计避免了因过度使用异步编程而可能导致的代码混乱和可靠性问题。其核心理念是:默认采用串行处理,只有在明确需要时才启用并行。
这借鉴了业内关于代理(agent)系统设计的经验——避免构建过于复杂、难以调试的多代理系统。
“通道”是对队列的一种抽象,它将串行化作为默认的架构基础,而非事后补救。开发者只需关注哪些操作可以安全地并行化,而无需担心复杂的锁和竞态条件问题。
3. 代理(Agent)执行器
这是AI真正开始思考的环节。执行器会决定使用哪个模型、选择相应的API密钥(如果某个配置失效,会将其暂时“冷却”并尝试下一个),并在主模型失败时自动回退到备用模型。
接着,代理执行器会动态组合系统提示,其中包含可用的工具、技能和记忆,并添加上下文历史记录(这些记录通常保存在一个`.jsonl`文件中)。
然后,整个上下文会经过一道“容量检查”。如果上下文窗口即将被填满,系统会尝试压缩会话(例如生成摘要),或者选择优雅地失败,而不是强行截断。
4. LLM API 调用
这一层负责调用大语言模型。它对不同的模型提供商进行了抽象化处理,可以适配各种响应流格式。如果模型支持,它还会请求模型进行更详细的“思考”(扩展推理)。
(注:现在的项目,都在大模型之上,做了一层封装,做到可以底层随意更换模型)
5. 代理循环
如果LLM返回的是一个“工具调用”指令(比如运行某个命令),Clawdbot会在本地执行这个指令,并将执行结果添加回对话中。这个过程会循环进行,直到LLM返回最终的文本答案,或者达到预设的最大循环次数(默认约为20轮)。
正是在这个循环中,Clawdbot实现了与计算机的深度交互。
6. 响应与持久化
最后的步骤比较标准:大模型的回复和工具调用执行结果,会通过相应的渠道发送给你。同时,整个会话会以基本的“jsonl”格式保存下来,每一行都记录着用户消息、工具调用、结果、AI响应等。
这就是Clawdbot实现“记忆”的基础。
02
—
关键组件
以上是基本架构,接下来我们看看几个更关键的组件。
Clawdbot 如何实现“记忆”
没有记忆的AI助手,其智能就像金鱼一样短暂。Clawdbot通过两个系统来解决这个问题:
1. 会话记录:如前所述,使用"jsonl"文件记录每次对话的完整交互。
2. 文件记忆:将重要的信息以Markdown格式保存在 "MEMORY.md" 文件或 `memory/` 文件夹中。
在需要搜索记忆时,Clawdbot结合了两种方式:
- 向量搜索:用于语义匹配(例如,搜索“authentication bug”也能找到提到“auth issues”的文档)。
- 关键词搜索:用于精确匹配短语。
向量搜索基于SQLite实现,关键词搜索则使用了SQLite的FTS5扩展。嵌入模型是可以配置的。
此外,系统还具备智能同步功能。当文件监视器检测到记忆文件被更改时,会自动触发更新。
这些Markdown记忆文件,本身就是由代理通过普通的“写文件”工具生成的。没有特殊的内存写入API,代理只是将内容写入"memory/*.md"。
当新的对话开始时,系统会获取之前的对话记录,并用Markdown格式生成摘要。
Clawdbot的记忆系统出人意料地简洁,其设计理念更倾向于可解释的简单性,而非复杂的结构。记忆会永久保存,旧记忆和新记忆的权重基本相同,可以说它没有“遗忘曲线”。
(注:使用者可以在此基础上,用 Supermemory 扩展 bot 的记忆:
https://supermemory.ai/docs/integrations/clawdbot)
Clawdbot 的“利器”:使用你的电脑
这是Clawdbot的一个核心能力:你给它电脑权限,它就能使用。
Clawdbot授予代理很高的计算机访问权限,但风险需要用户自担。它主要通过一个“执行”工具来运行shell命令,并支持三种模式:
- 沙盒模式(默认):命令在Docker容器中运行。
- 主机模式:命令直接在宿主机上运行。
- 远程模式:命令在远程设备上运行。
除此之外,它还提供:
- 文件系统工具(读、写、编辑文件)。
- 基于Playwright的浏览器工具(带有“语义快照”功能)。
- 进程管理工具(用于运行长期后台命令、终止进程等)。
安全性如何?
与Claude Code类似,Clawdbot为用户希望批准的命令设置了白名单机制(可选择“允许一次”、“始终允许”、“提示用户”或“拒绝”)。配置文件示例如下:
~/.clawdbot/exec-approvals.json
{
"agents": {
"main": {
"白名单": [
{ "模式": "/usr/bin/npm", "最后使用时间": 1706644800 },
{ "pattern": "/opt/homebrew/bin/git", "lastUsedAt": 1706644900 }
]
}
}
}一些安全的命令(如`jq`、`grep`、`cut`、`sort`等)已经预置为批准状态。
同时,默认会阻止危险的shell构造,例如命令替换、敏感文件重定向、使用`||`的命令链、子shell执行等,在执行前就会被拒绝。
其安全理念与Claude Code类似:在提供强大功能的同时,尽可能将控制权交给用户。
浏览器工具:语义快照
Clawdbot的浏览器工具主要不依赖截图,而是使用“语义快照”。这是一种基于文本的页面表示方式,来源于页面的可访问性树(ARIA)。
因此,浏览器Agent “看到”的页面是这样的:
- “登录”按钮[ref=1]
- 文本框“电子邮件”[ref=2]
- 文本框“密码”[ref=3]
- 链接“忘记密码?”[ref=4]
- 标题“欢迎回来”
- 列表
- 列表项 "仪表板"
- 列表项 "设置"这种方式有如下优点:
- 浏览网页不一定需要视觉信息。
- 与可能高达5MB的截图相比,语义快照通常小于50KB,将其转换为文本提示(token)的成本也远低于处理图像。
03
—
OpenClaw 的 Skill 库
在部署完成后,虽然内置了一些文件操作、浏览器的功能,但是 Clawdbot 它仅仅还是个陪聊的机器人。
下面推荐的这个仓库收集了几百种 Skill,能在里面找到各种现成的脚本和配置,专门用来给它扩充能力,让bot学会操作浏览器抓数据、管理本地文件、自动发邮件,甚至是写代码和部署服务。
图片
无论你是想用 AI 来处理日常杂事,还是想搞点复杂的开发工作流,去这里淘一淘现成的轮子绝对比自己从头造要快得多。
对于正在折腾 OpenClaw 的玩家来说,这基本上是一个必看的资源站。
开源地址:https://github.com/VoltAgent/awesome-openclaw-skills
架构部分的原文:
https://x.com/Hesamation/article/2017038553058857413
往期热门文章推荐:
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-02-07,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号