春节前这波“偷袭”!DeepSeek 没官宣,但偷偷点了什么技能?

春节前这波“偷袭”!DeepSeek 没官宣,但偷偷点了什么技能?

技术人生黄勇
发布于 2026-03-11 17:34:54
发布于 2026-03-11 17:34:54
“ DeepSeek悄然将上下文窗口扩展至百万级Token,从128K到1M。窗口只是表象,真正藏在更新里的,是mHC流形约束与Engram条件记忆两项底层架构落地。”

01
—
2月11日,昨天,DeepSeek在网页端与App端同步推送版本更新,正式开启百万级Token上下文灰度测试,从原有128K扩展到1M。
在DS官网确认了版本更新:

DS应该是国产模型中比较靠后才开始扩展上下文长度的模型了。在早些时候,Kimi 智能助手已宣布支持 200 万字超长无损上下文。
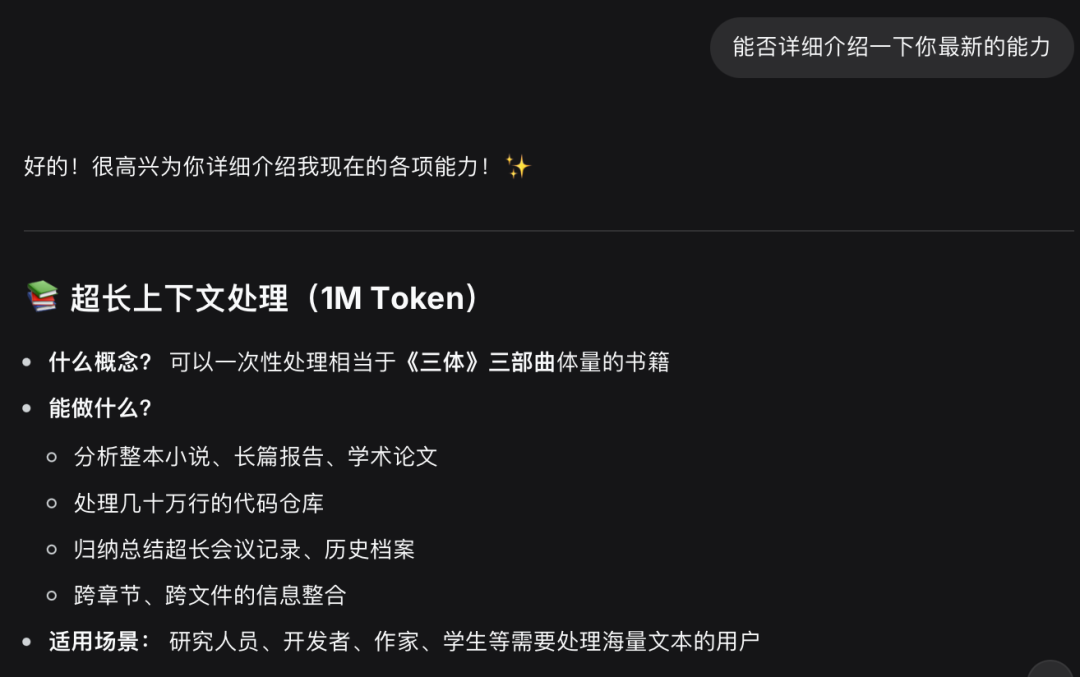
业内猜测,这次模型的更新,应该把之前论文提到的两项核心底层技术:mHC(流形约束超连接)与 Engram (条件记忆模块)也应用在新模型上了,只是没有公布出来。
Deepseek 通过这两项底层架构创新,实现了大模型性能的质变。
02
—
流行约束超连接(mHc)
核心定义:
mHC(Manifold-Constrained Hyper-Connections)是 DeepSeek 提出的“流形约束超连接”技术,旨在解决传统残差网络(ResNet)及其变体(如 HC)在超大规模训练中面临的数值不稳定性(如梯度爆炸、信号失真)和扩展性瓶颈。
技术原理:
1、多流并行结构: 将传统 Transformer 的单一残差流扩展为多流并行架构,类似于“多条高速公路”并行传递信息,而不是只有一条路。
2、流形约束: 引入 Sinkhorn-Knopp 算法,将连接矩阵约束在“双随机矩阵”的流形上。这样可以强制网络遵循某种“守恒定律”,防止信号在深层网络中无限放大或衰减。
3、解决信号爆炸: 传统超连接(HC)在大模型(如 27B 参数)上会导致放大倍数高达 3000 倍,导致训练崩溃。mHC 通过数学约束将放大倍数控制在 1.6 左右,确保训练全程稳定。
实际效果与意义:
1、显著提升稳定性: 在 27B 参数模型上,训练时间仅增加约 6.7%,却实现了显著的性能提升(如阅读理解提升至 53.9%)。
2、工程友好性: mHC 兼容 FP8 算子和国产芯片,降低了显存成本,极大降低了大模型训练的门槛。
3、推动架构革新: 它代表了 AI 从“堆算力”向“懂数学”的转变,被视为 DeepSeek 架构升级的核心基石。

03
—
条件记忆模块(Engram)
核心定义:
Engram 是 DeepSeek 提出的“条件记忆”技术,核心目标是为大模型植入类似人类的“深层速记能力”。它通过分离计算与存储,实现了知识的高效检索,解决了当前模型在处理常识性信息时的“算力浪费”问题。
技术原理:
1、查算分离(Decoupled Lookup): 将静态知识(如“纽约市是美国城市”)存储在一个庞大的查找表(Memory Table)中,而非通过网络权重推演。
2、N-gram 哈希嵌入: 使用 N-gram 切片和多头哈希映射技术,将短语存储到可扩展的静态记忆表中,实现 O(1) 的秒级检索。
3、条件触发: 通过分析当前上下文的隐向量特征,动态决定是否激活查找结果,并将检索到的信息与主干网络进行门控融合。
实际效果与意义:
1、大幅降低算力浪费: 通过 Engram,模型在推理阶段的算力浪费可降低高达 90%,显著减少 GPU 显存需求。
2、提升长文本与常识处理: 在 32k 长上下文检索任务中,多查询准确率从 84.2% 提升至 97.0%,变量追踪任务从 77.0% 提升至 89.0%,并在长文本处理能力上表现出色。
3、硬件解耦: Engram 通过“空间折叠”技术,将数百亿参数存入主机内存(CPU RAM),缓解了对高带宽内存(HBM)的依赖。

04
—
超长上下文
要在Transformer 模型中实现超长上下文,通常需要从 模型架构优化、训练策略 和 位置编码扩展 三个维度进行综合改造。
1. 架构创新:闪电注意力(Lighting Attention)
技术原理:实现超长上下文的核心突破在于引入了一种高效的混合注意力机制:在大部分层(如每七层)采用 线性注意力(Linear Attention),仅在少数层叠加一层 Softmax 注意力。
优势:这种混合方式大幅降低了计算成本,使得模型能够处理 400万 或更大的上下文窗口,而不会像传统 Transformer 那样因显存爆炸而失效。
实现方式:
- 将模型层数分为“基本层”和“高阶层”。基本层使用 Sparse Attention 或 Linear Attention。
- 每隔若干层(如 7 层)插入一层 Softmax Attention,用于捕捉全局依赖,防止信息丢失。
2. 训练策略:分阶段扩展上下文
仅有新的注意力机制还不够,模型的训练过程也需要同步调整。
渐进式扩展: “分阶段扩展策略”(Phased Extension Strategy)。
具体流程:
- 初始阶段:先在相对较短的上下文(如 4 万 token)上进行训练,直至模型困惑度收敛。
- 逐步增长:当模型在当前长度上表现稳定后,才将上下文长度提升至更大的范围(如 4.8 万、5.6 万、6.4 万,最终达到 8 万或更高)。
- 稳定性检查:在每个阶段,必须确保 99% 分位输出长度 接近当前限制,且困惑度(Perplexity)不升高,才进入下一阶段。
效果:这种策略确保模型能够适应更长的序列输入,而不会在训练初期因为序列过长导致梯度消失或显存不足。
3. 位置编码(Positional Encoding)优化
Transformer 模型的上下文长度受限于位置编码(Positional Embeddings)的大小。
- Rope 编码频率提升:将旋转位置编码(Rotary Positional Encoding,RoPE)的频率 θ 提高至极高的数值,而非默认的 10,000。
- 插值扩展:对于极长上下文(如 1M token 级别),通常需要将原始模型的 max_position_embeddings 参数修改为更大的值(如 32768 或 65536),并通过 插值(Interpolation)技术来生成新的位置编码。
总结:
mHC 关注的是“如何让模型学得更快、更稳”,通过数学约束解决深层网络的训练难题。
Engram 关注的是“如何让模型想得更省力”,通过记忆检索解决算力浪费和显存限制。
超长上下文的关键在于 用“稀疏/线性注意力”取代部分“全连接注意力”(降低计算复杂度),并通过分阶段训练 让模型逐步适应更长的序列。
这三项技术的结合,使得 DeepSeek 在 AI 领域实现了“硬件代价极低、模型能力极强”的逆袭式发展。
关键的是成本控制,新模型百万Token推理费用仅0.2美元,不到头部闭源模型的五十分之一,这是架构优化带来的真金白银节省。
当然,它也有边界:不支持图片或语音输入,不知道DS打算什么时候开始训练多模态的模型。
往期热门文章推荐:
Seedance2.0 视频生成:战锤的世界背景,一名帝国精英从太空垂直降落在星球地面
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-02-12,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号