LLM 的自然语言偏好获取函数的贝叶斯优化

LLM 的自然语言偏好获取函数的贝叶斯优化

CreateAMind
发布于 2026-03-11 17:25:35
发布于 2026-03-11 17:25:35
Bayesian Optimization with LLM-Based Acquisition Functions for Natural Language Preference Elicitation 基于 LLM 的自然语言偏好获取函数的贝叶斯优化
https://arxiv.org/pdf/2405.00981


摘要 在冷启动环境下,设计能够快速确定用户最偏爱物品的偏好获取(PE)方法,是构建高效且个性化对话式推荐(ConvRec)系统的关键挑战。尽管大语言模型(LLM)能够实现完全自然语言(NL)的偏好获取对话,但我们假设,单一的LLM自然语言偏好获取(NL-PE)方法缺乏多轮、基于决策理论的推理能力,难以在对任意物品集合的偏好探索与利用之间有效平衡。相比之下,传统的贝叶斯优化(BO)偏好获取方法定义了理论上最优的PE策略,但无法生成任意的自然语言查询,也无法对自然语言描述的物品内容进行推理——因此要求用户通过评分或比较不熟悉的物品来表达偏好。为了克服上述两种方法的局限性,我们将自然语言偏好获取(NL-PE)建模为一个贝叶斯优化(BO)框架,旨在主动获取自然语言反馈以识别最佳推荐物品。将贝叶斯优化推广至处理自然语言反馈所面临的关键挑战包括:(a)如何利用大语言模型将自然语言偏好反馈的似然性建模为物品效用的函数;以及(b)如何为自然语言贝叶斯优化设计一种采集函数,以在无限的语言空间中主动获取偏好信息。我们在一个新颖的NL-PE算法PEBOL中展示了该框架,该算法使用:1)用户偏好语句与自然语言物品描述之间的自然语言推理(NLI)来维护贝叶斯偏好信念;2)贝叶斯优化策略(如汤普森采样TS和置信上限UCB)来指导大语言模型生成查询语句。我们在受控仿真实验中对所提方法进行了数值评估,结果表明,在经过10轮对话后,PEBOL的MRR@10最高可达0.27,优于最佳单一LLM基线方法的0.17,尽管PEBOL所依赖的是更早版本且规模更小的大语言模型。
CS概念• 信息系统 → 推荐系统;个性化;语言模型。
关键词 对话式推荐,偏好获取,贝叶斯优化,在线推荐,查询生成
1 引言 个性化的对话式推荐(ConvRec)系统需要高效的自然语言(NL)偏好获取(PE)策略,能够在冷启动场景下快速学习用户最偏好的物品,理想情况下仅需一组任意的自然语言物品描述即可实现。尽管大语言模型(LLMs)的出现为实现自然语言偏好获取(NL-PE)对话提供了技术支持 [14, 23],但我们推测,单一的LLM在针对任意物品集合进行主动、多轮的NL-PE对话方面能力有限。具体而言,我们假设LLMs缺乏多轮决策理论层面的推理能力,无法交互式地生成既能避免对用户-物品偏好过度利用(over-exploitation)又能避免过度探索(over-exploration)的查询,从而可能导致系统过度聚焦于已揭示的偏好,或在低价值物品上浪费性地进行探索。此外,单一LLM的NL-PE方法还面临其他挑战:需要同时对大量可能未曾见过的物品描述进行联合推理,以及即使经过提示工程(prompt engineering)或微调后,系统行为仍缺乏可控性和可解释性 [28]。
相比之下,传统的偏好获取算法 [21, 22, 27, 39, 40],包括贝叶斯优化方法 [2, 5, 12, 32, 36],建立了形式化的决策理论策略,例如汤普森采样(Thompson Sampling, TS)和置信上界(Upper Confidence Bound, UCB)[16],以平衡探索与利用,目标是快速识别出用户最偏爱的物品。然而,这些技术通常假设用户可以通过直接评分或比较物品来表达偏好——当用户对大多数物品不熟悉时,这一假设并不现实 [1]。尽管近期的研究已将贝叶斯偏好获取扩展到基于预定义关键词的固定模板化查询 [36],但目前尚无研究将贝叶斯方法扩展至在通用自然语言物品描述集合上的生成式自然语言偏好获取(NL-PE)。
本文的主要贡献如下: • 我们首次提出了针对任意自然语言对话、在通用自然语言物品描述集合上的自然语言偏好获取(NL-PE)的贝叶斯优化形式化框架——为利用决策理论推理来引导大语言模型的研究建立了新范式。 • 我们提出了PEBOL(基于贝叶斯优化增强的大语言模型进行偏好获取),一种新颖的NL-PE算法,该算法:1)通过对话语句与物品描述之间的自然语言推理(Natural Language Inference, NLI)[37] 来推理物品偏好,从而维护贝叶斯偏好信念;2)引入基于大语言模型的采集函数(acquisition functions),利用TS和UCB等决策理论策略,基于偏好信念来指导自然语言查询的生成。 • 我们在多个自然语言物品数据集和不同用户噪声水平下,通过受控的NL-PE对话实验,将PEBOL与单一的GPT-3.5和Gemini-Pro NL-PE方法进行了数值评估。 • 实验结果表明,在经过10轮对话后,PEBOL的平均MRR@10最高可达0.27,优于最佳单一LLM基线方法的0.17,尽管PEBOL所依赖的是更早且规模更小的LLM。
2 背景与相关工作 2.1 贝叶斯优化

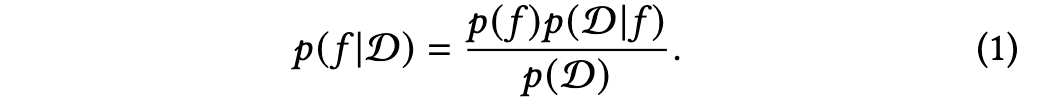

2.2 偏好获取
偏好获取(PE)已历经数十年的研究,涵盖基于贝叶斯优化的方法(例如 [3, 8, 11, 13, 18])、多臂老虎机(Bandits)方法(例如 [5, 24, 25, 40])、约束优化方法 [29] 以及部分可观测马尔可夫决策过程(POMDPs)[2]。在标准的偏好获取设定中,假设用户对一组包含 N个物品的集合 I拥有某种隐藏的效用值 u=[u1,...,uN],当且仅当 ui>uj时,物品 i比物品 j更受用户偏爱。偏好获取的目标通常是在尽可能少的偏好获取查询次数内,找到一个物品 i∗∈argmaxiui,使其效用值最大化。这些查询大多数要求用户通过物品评分(例如 [3, 5, 24, 25, 40])或对物品对或物品集合进行相对偏好比较(例如 [2, 8, 11, 12, 14, 32])来表达偏好。
另一种形式的偏好获取则要求用户对预定义的物品特征表达偏好,同样是通过评分或比较类的查询实现 [22, 27, 39]。上述各类偏好获取方法的核心在于查询选择策略,这些策略需要平衡对用户偏好的探索与利用,其中汤普森采样(TS)和置信上界(UCB)算法(参见第4.2节)通常表现出较强的性能 [5, 27, 36, 39, 40]。然而,这些方法均无法通过自然语言对话与用户交互,也无法对自然语言描述的物品内容进行推理。
2.3 基于语言的偏好获取
Yang 等人 [36] 提出了使用汤普森采样(TS)和置信上界(UCB)的贝叶斯偏好获取策略,用于关键词评分查询。该方法首先从自然语言物品评论中挖掘关键词,然后将这些关键词与用户-物品偏好共同嵌入到推荐系统中。Handa 等人 [14] 提出使用大语言模型(LLM)与传统的贝叶斯偏好获取系统进行交互,建议通过预处理步骤从自然语言描述中提取特征,并通过语言生成步骤流畅地表达物品对之间的比较查询。Li 等人 [23] 利用提示(prompt)让大语言模型生成针对特定领域(例如新闻内容、道德观念)的偏好获取查询,观察用户的回应,并对单个物品的LLM相关性预测进行评估。尽管这些研究在自然语言偏好获取(NL-PE)方面取得了进展,但它们并未探讨LLM如何在物品或类别反馈之外,战略性地通过查询生成探索用户对任意物品集合的偏好。
2.4 对话式推荐
近期关于对话式推荐(ConvRec)的研究利用语言模型³ 来支持自然语言对话,同时结合调用推荐模块,该模块基于用户-物品交互历史生成推荐结果 [4, 26, 33, 35]。He 等人 [15] 报告称,在常见数据集上,零样本的 GPT-3.5/4 表现优于这些 ConvRec 方法,因为后者通常使用较旧的语言模型,且其推荐模块需要依赖用户-物品交互历史。
2.5 自然语言推理
二元自然语言推理(Natural Language Inference, NLI)[37] 模型用于预测一个称为“前提”(premise)的文本片段是否蕴含另一个称为“假设”(hypothesis)的文本片段(即,能否从前者推出后者)。例如,一个有效的NLI模型应能高概率判断前提“我想看《钢铁侠》”蕴含假设“我想看一部超级英雄电影”。如本例所示,通常“假设”在语义上要比“前提”更宽泛。NLI模型通过对编码器-only的大语言模型在NLI数据集上进行微调来训练 [6, 31, 34],这些数据集通常由较短的前提和假设文本片段组成,因此即使使用参数量相对较少的大语言模型,也能在类似任务上实现较高效的性能。
3 问题定义
我们现在提出自然语言偏好获取(NL-PE)的贝叶斯优化形式化定义。NL-PE的目标是通过自然语言对话,高效地识别出用户在一组 N个物品中最偏爱的物品。

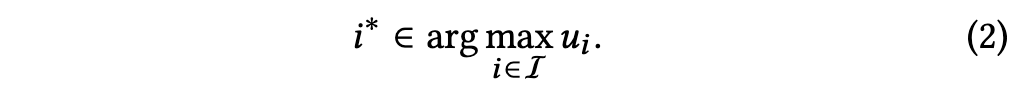


这允许在任何回合中根据预期效用推荐前k个项目。 我们的贝叶斯优化NL-PE范式让我们能够形式化几个关键问题,包括:

这些问题揭示了在第7节中进一步讨论的许多新颖研究方向。在本文中,我们提出了PEBOL,这是一种基于上述贝叶斯优化NL-PE形式化的NL-PE算法,并通过控制的、模拟的自然语言对话对其进行了数值评估(参见第6节)。
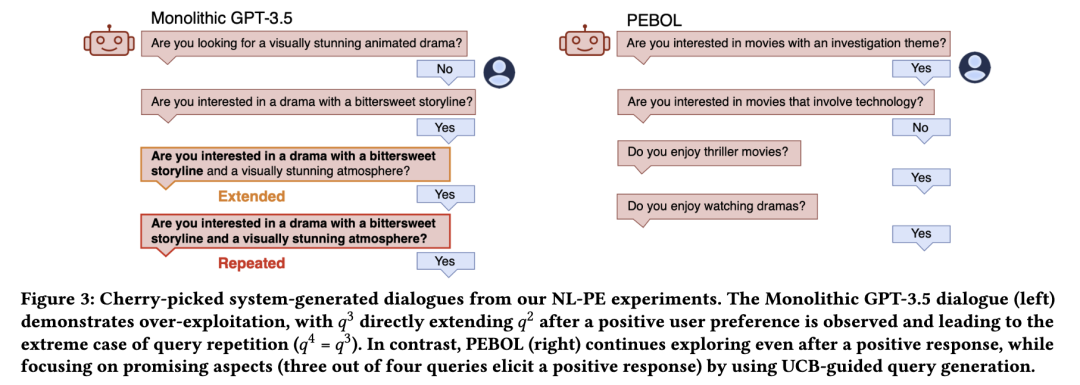
4方法论
单一LLM提示方法的局限性。一种显而易见的自然语言偏好获取(NL-PE)方法(将在第5.1节中进一步描述为基线方法)是:在每一轮对话中,将所有物品描述 x、对话历史 Hₜ 以及生成新查询的指令一并输入给一个单一的大语言模型(LLM)进行提示。然而,将所有物品描述 [x₁, ..., xₙ] 放入LLM的上下文窗口中,除了在物品集合极小的情况下,计算开销都非常高。虽然可以通过微调使LLM内化物品知识,但每次物品更新都意味着需要重新训练整个系统。更重要的是,除了通过提示工程或进一步微调外,无法对LLM的偏好获取行为进行有效控制,而这两种方法都无法保证系统行为具有可预测性或可解释性,也无法确保在用户偏好探索与利用之间实现良好平衡。
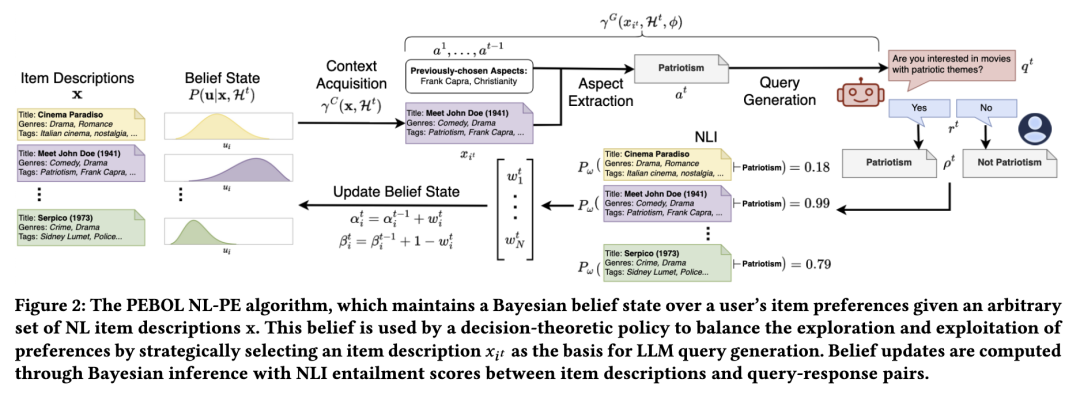
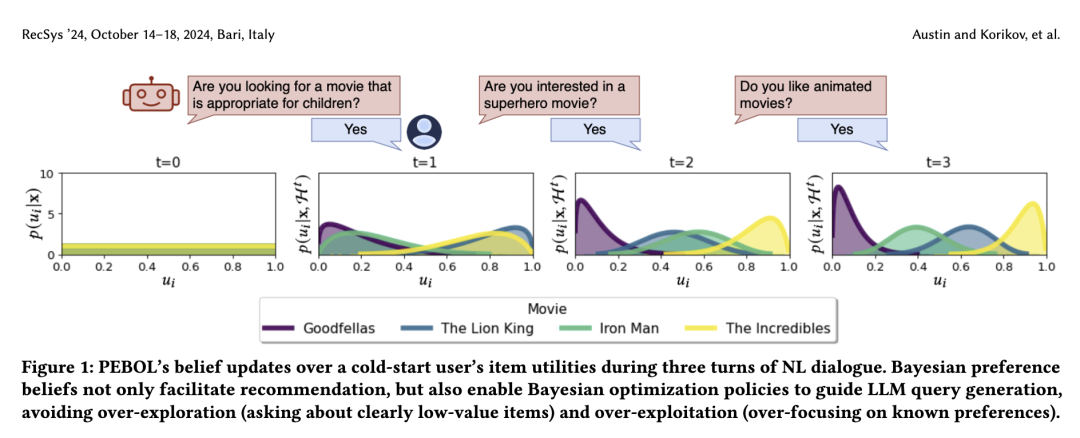
PEBOL概述。我们提出了一种新算法PEBOL(如图2所示),通过将大语言模型推理与贝叶斯优化过程相结合,以解决上述局限性。在每一轮对话 t,我们的算法维护一个关于用户偏好的概率性信念状态,即Beta信念状态(详见第4.1节)。该信念状态指导一个基于LLM的采集函数,生成能够显式平衡探索与利用的自然语言查询,以快速发现用户最偏好的物品(详见第4.2节)。此外,我们的采集函数将每轮提示LLM所需的上下文信息从全部 N 个物品描述 x减少到仅一个经过策略性选择的物品描述 xᵢₜ。随后,PEBOL利用自然语言推理(NLI)对获取到的自然语言偏好和物品描述进行分析,将对话中的语句映射为数值化的观测结果(详见第4.3节)。
4.1 效用信念
4.1.1 先验信念。在任何对话开始之前,PEBOL 会为用户-物品效用建立一个无信息的先验信念 p(u)。我们假设各个物品的效用是相互独立的,因此有:



4.2 基于大语言模型(LLM)的采集函数



4.3 自然语言物品偏好蕴含

4.4 完整的PEBOL系统
至此,PEBOL系统的完整定义已完成——从先验效用信念出发,经过基于大语言模型(LLM)的采集函数生成查询,再到后验效用更新的整个流程如图2所示。
5 实验方法
我们通过在多个数据集和不同响应噪声水平下进行受控的自然语言偏好获取(NL-PE)对话实验,对PEBOL的不同变体进行了数值评估,并与两种单一的大语言模型(MonoLLM)基线方法进行了比较。具体而言,这些基线方法直接将 GPT-3.5-turbo-0613(GPT MonoLLM)或 Gemini-Pro(Gemini MonoLLM)用作NL-PE系统,如第5.1节所述。我们没有与现有的对话式推荐(ConvRec)方法 [4, 26, 33, 35] 进行比较,因为这些方法并非冷启动系统,其推荐模块依赖于已观测到的用户-物品交互数据。我们也没有基于 ReDIAL [26] 等ConvRec数据集开展实验,因为这些数据集由预先录制的对话历史组成,无法用于评估主动式的冷启动NL-PE系统。
5.1 单一LLM基线方法(MonoLLM Baseline)
将单一LLM用于NL-PE的一个主要挑战是:物品描述 x 要么需要通过训练内化到模型中,要么必须放入上下文窗口中(参见第4节)。由于我们关注的是完全冷启动场景,因此我们测试后者作为基线方法。在每一轮对话中,给定完整的对话历史 Hₜ 和所有物品描述 x,我们提示单一LLM生成一个新的查询以获取用户偏好——所有提示模板均见于补充材料。为了评估推荐性能,我们在每一轮之后使用另一个提示,要求LLM根据当前对话历史 Hₜ 从 x 中推荐十个物品名称。
由于上下文窗口长度的限制,这种单一LLM方法仅适用于物品数量较少且描述较短的集合;因此,为了与单一LLM基线进行公平比较,我们必须将物品集合大小 |I| 限制为100。
5.2 仿真细节
我们通过与大语言模型模拟用户之间的NL-PE对话来测试PEBOL和单一LLM方法,其中模拟用户的物品偏好对系统是隐藏的。我们在10轮对话过程中评估推荐性能。

5.3 数据集
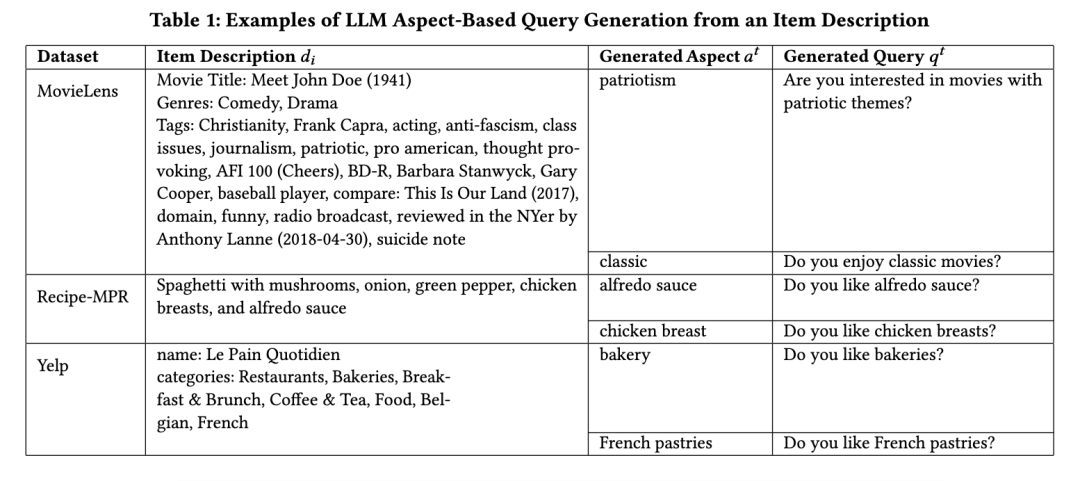
我们从三个真实世界的数据集中获取物品描述:MovieLens25M⁷、Yelp⁸ 和 Recipe-MPR [38](每个数据集的示例物品描述见补充材料中的表1)。在对Yelp和MovieLens进行以下过滤步骤后,我们随机采样100个物品来构建物品集合 x。对于Yelp数据集,我们筛选餐厅描述,要求其来自北美某一个主要城市(费城),且至少有50条评论以及五个或更多的类别标签。对于MovieLens数据集⁹,我们筛选出评分数量排名前10%的电影,并且每部电影至少包含20个标签;电影描述由标题、类型标签以及用户赋予的20个最常见标签组成。
5.4 研究问题

6 实验结果
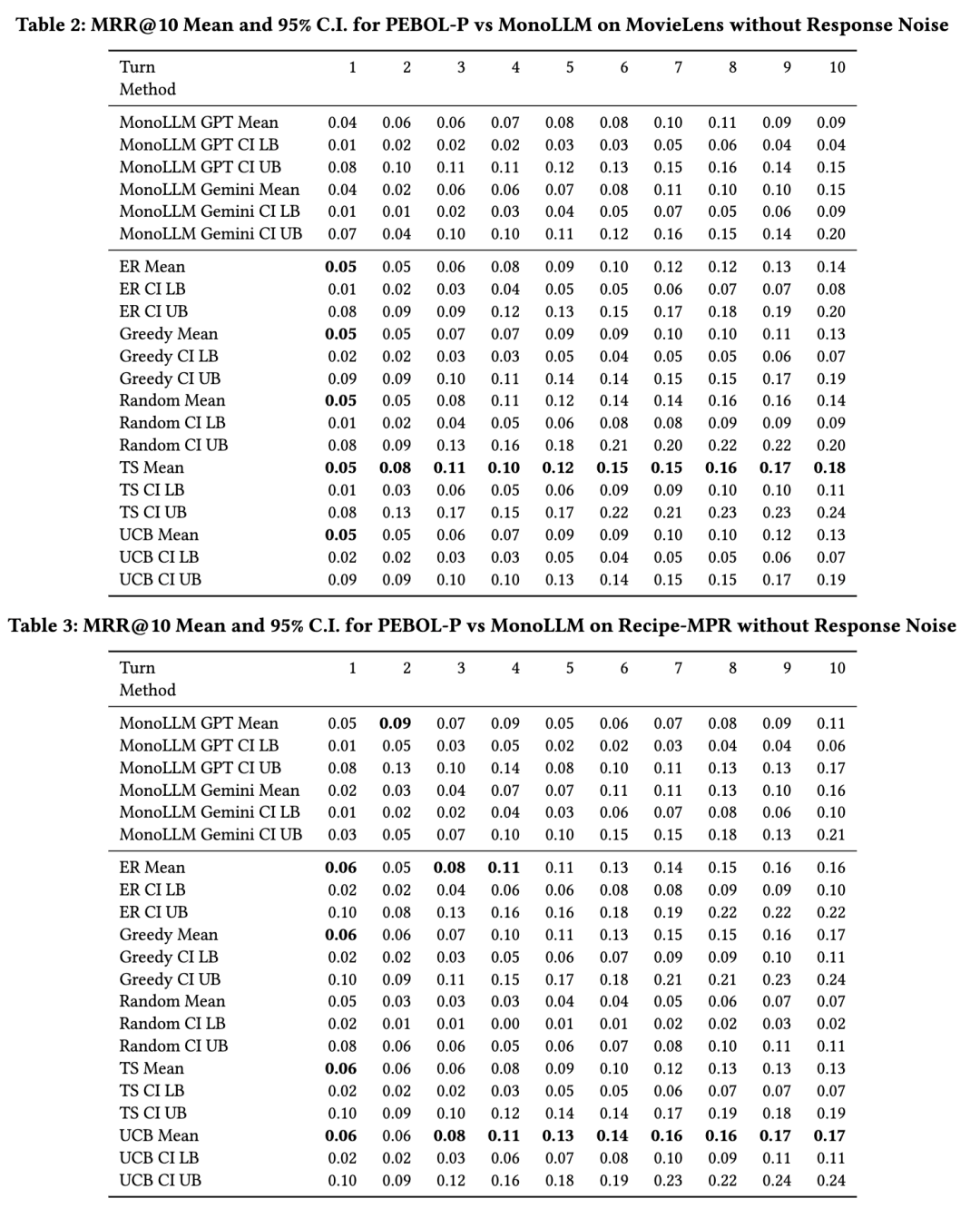
6.1 RQ1 - PEBOL 与 MonoLLM 对比
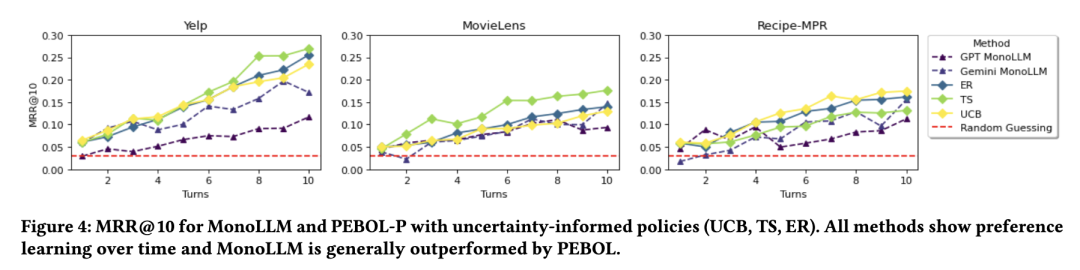
图4展示了在10轮对话中,单一LLM(MonoLLM)和PEBOL(采用UCB、TS、ER策略)的MRR@10表现,第10轮的95%置信区间(CIs)如图8所示(所有轮次和实验的置信区间详见补充材料)。所有方法在初始阶段都接近随机猜测水平,反映出冷启动场景的特点,并随着时间推移表现出明显的偏好学习能力。
6.2 RQ2 - 二元响应与概率性响应的对比
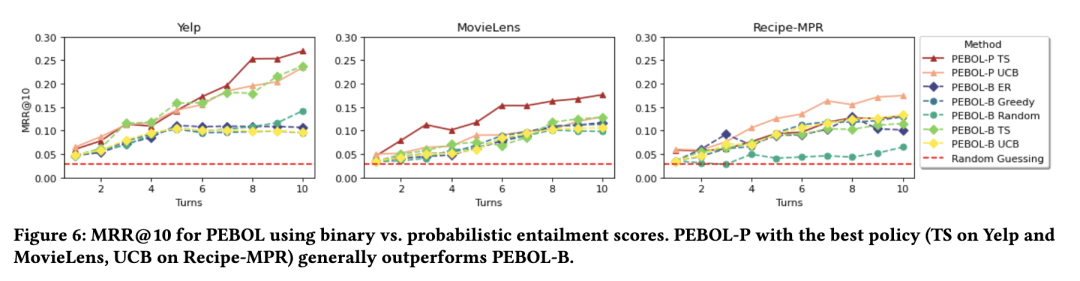
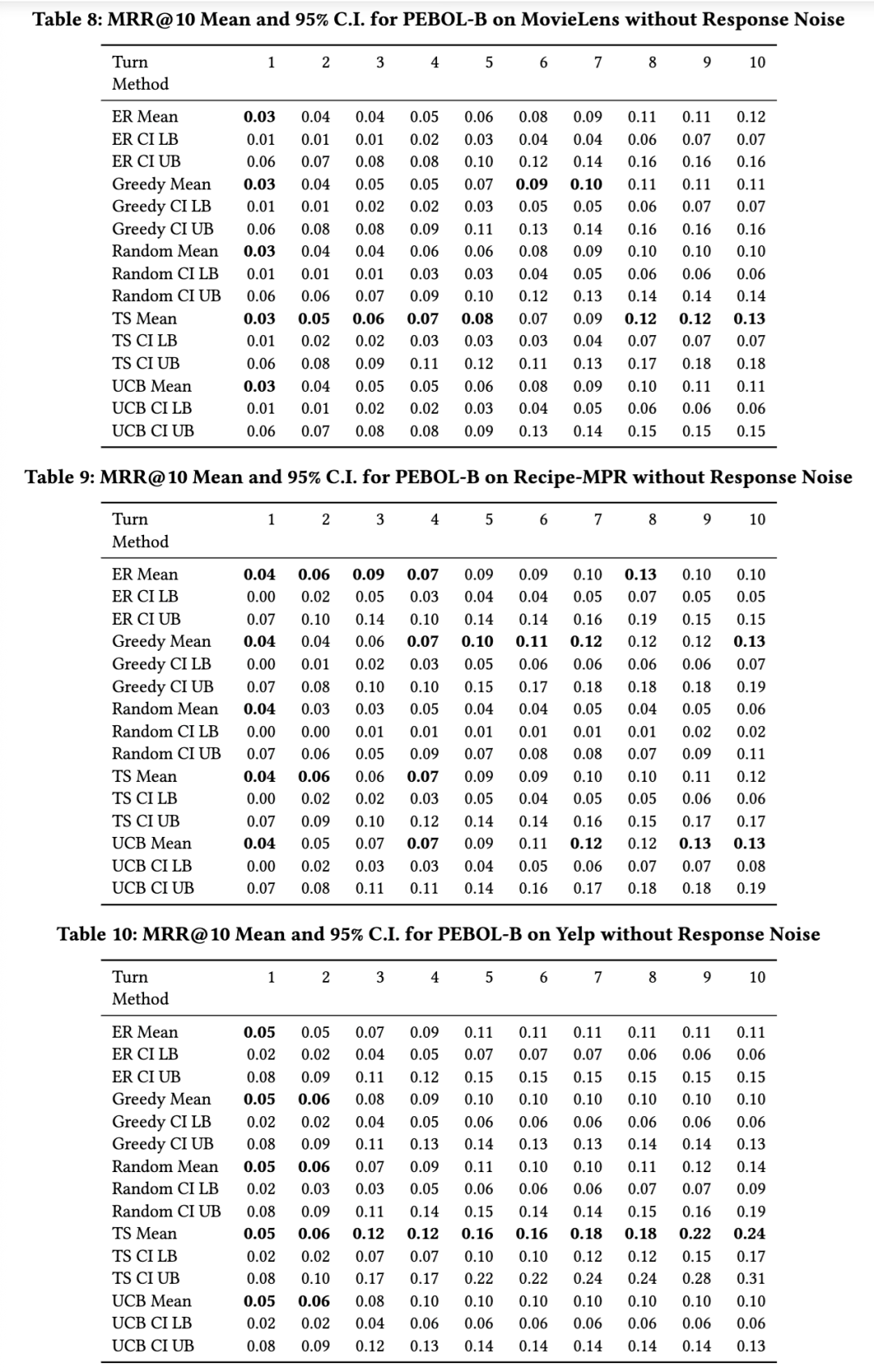
图6比较了使用二元反馈(PEBOL-B)和连续反馈(PEBOL-P)时PEBOL的性能表现。结果显示,通常情况下使用连续反馈(即概率性响应)时性能更优——这表明二元反馈模型会丢弃来自蕴含概率中的有价值信息。
6.3 RQ3 - 用户响应噪声的影响
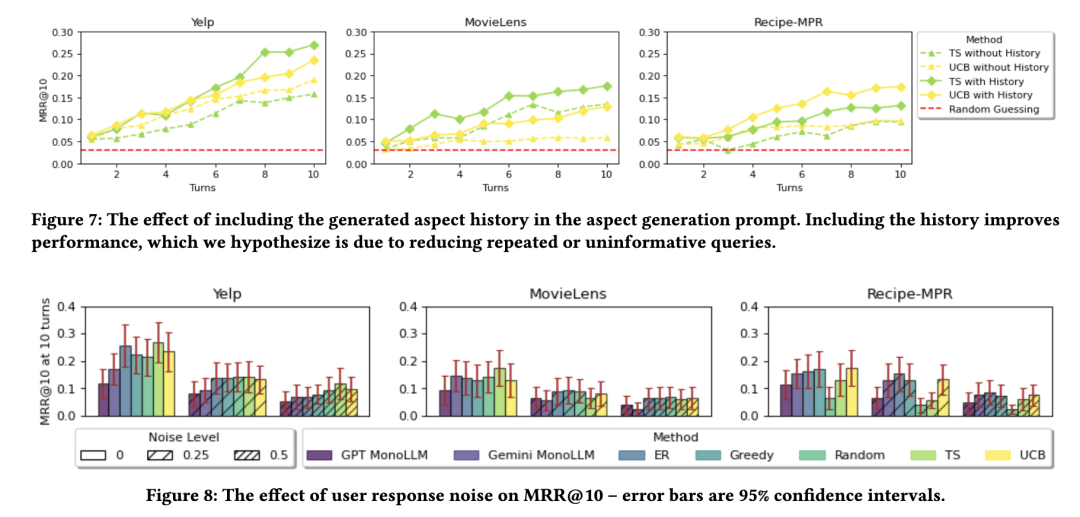
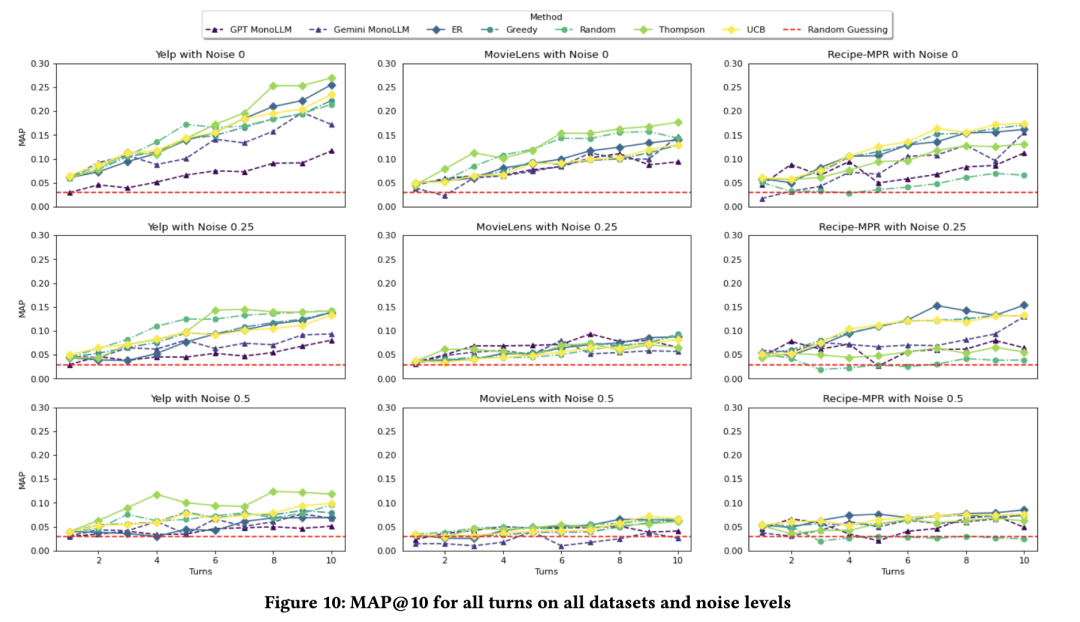
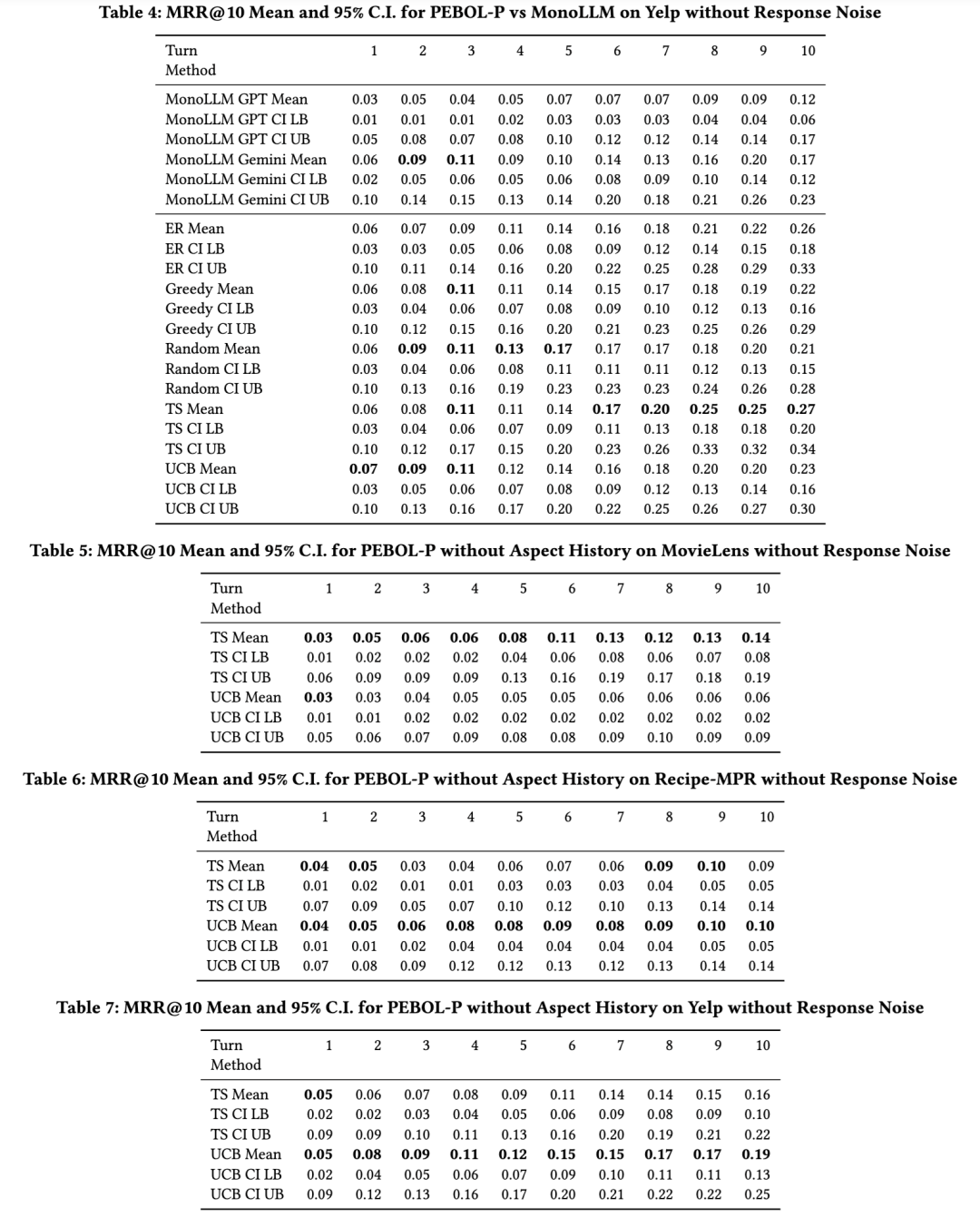
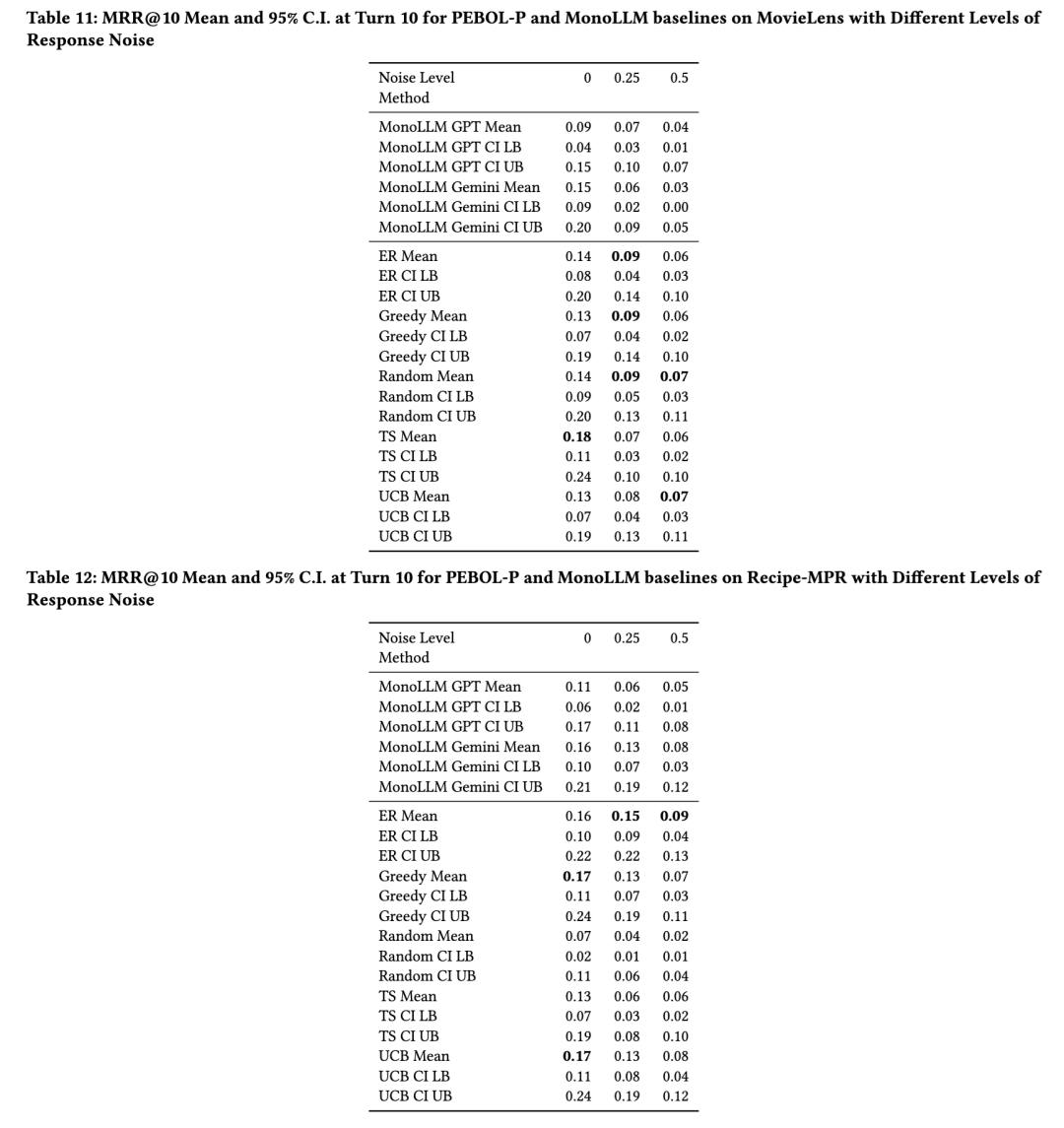
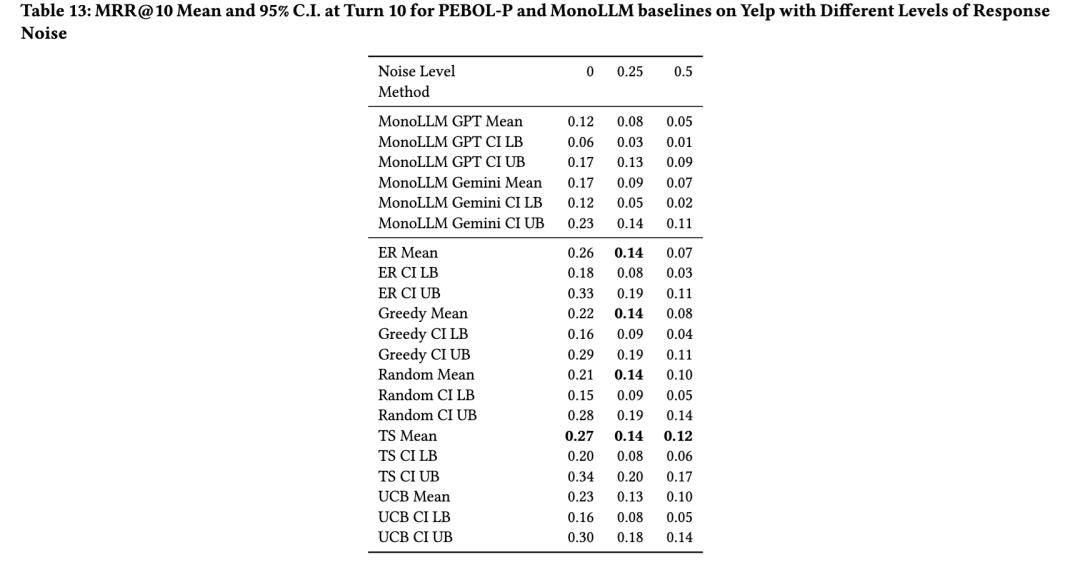
图8展示了用户响应噪声对第10轮MRR@10的影响。在存在用户响应噪声的情况下,PEBOL整体上仍能持续优于单一LLM基线方法。具体而言,在所有噪声水平下,两种单一LLM基线方法在Yelp数据集上均被所有PEBOL-P变体超越;在MovieLens和Recipe-MPR数据集上,则至少被一种PEBOL-P变体超越。
6.4 RQ4 - 上下文采集策略的比较
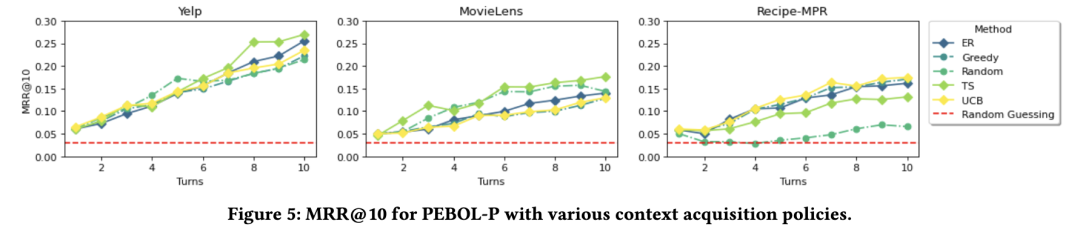
图5比较了不同PEBOL上下文采集策略的性能。除在Recipe-MPR数据集上随机选择物品外,所有策略均表现出活跃的偏好学习能力。各方法之间存在较大重叠,但总体来看,TS策略在Yelp和MovieLens数据集上表现良好,而在Recipe-MPR上则被贪婪(Greedy)、熵减(ER)和UCB策略超越。由于采样过程的随机性,TS的表现与随机选择策略相关性较强;而UCB策略的表现与贪婪策略非常相似。
6.5 RQ5 - 查询生成中属性历史的影响
如图7所示,我们在属性生成提示中加入之前已生成的属性列表后,观察到PEBOL性能有所提升。例如,在10轮对话结束后,包含与不包含查询历史的TS策略在平均MRR@10上的差异分别为:Yelp数据集为0.27 vs 0.16;MovieLens为0.18 vs 0.14;Recipe-MPR为0.13 vs 0.09。实际上,将属性生成历史纳入提示还有助于避免重复提问,而重复提问无法提供新信息,可能使用户感到沮丧。
7 结论与未来工作
本文提出了一种针对任意自然语言(NL)物品描述的自然语言偏好获取(NL-PE)的新型贝叶斯优化形式化框架,并提出和评估了一种名为PEBOL的算法——即基于贝叶斯优化增强的大语言模型进行自然语言偏好获取的算法。如下所述,本研究也为未来的研究提供了诸多方向,包括解决PEBOL算法及实验设置中存在的一些局限性。
用户研究。首先,我们的实验受限于对大语言模型(LLM)模拟用户的依赖。尽管对话模拟结果显示了合理的行为,例如初始推荐性能接近随机猜测、随时间推移学习用户偏好、以及日志中显示的连贯用户响应(如图7所示),但未来的研究将从真实人类用户参与的用户实验中受益。
多物品信念更新。虽然假设物品效用可以独立更新,使得我们可以为每个物品使用简单且可解释的贝塔-伯努利(Beta-Bernoulli)更新模型,但这也要求对每个物品分别进行一次自然语言推理(NLI)计算,这在计算上较为昂贵。因此,一个关键的未来方向是探索替代的信念状态形式,以支持通过单次NLI计算实现对所有物品信念的联合更新。
协作式信念更新。由于PEBOL未利用与其他用户的任何历史交互信息,一个重要的未来方向是研究能够利用协作式、多用户数据的NL-PE方法。一种可能的方法是基于其他用户的交互历史来初始化冷启动用户的先验信念。另一个方向是将基于协同过滤的信念更新方法(例如在基于物品反馈的偏好获取技术中使用的方法 [5])适配到NL-PE场景中。
多样化的查询形式。尽管PEBOL采用逐点查询生成策略,每次选择一个物品描述作为LLM的上下文,但未来工作可以探索基于成对或集合式上下文选择的LLM采集函数。这种多物品上下文选择方式将支持对比性查询生成,从而更有效地区分不同物品之间的偏好。
在对话式推荐架构中的NL-PE应用。另一个未来研究方向是将诸如PEBOL这样的NL-PE方法集成到对话式推荐(ConvRec)系统架构中(例如 [7, 9, 17, 20]),这些系统需要平衡推荐、解释和个性化问答等多种任务。因此,与PEBOL所使用的逐点查询和“是/否”用户响应不同,在ConvRec系统中使用偏好获取意味着未来的算法需要基于任意的自然语言系统-用户语句对来获取偏好。在这些潜在的扩展中,可以通过使用LLM从语句中提取属性,来实现基于属性的NLI。



后一项表示一个贝塔分布的混合模型,其处理难度较大,因为每次进行后验更新都会导致该混合模型中的成分数量随着查询观测次数 m呈指数级增长,从而带来巨大的计算和内存开销。
为解决这一问题,已有多种方法被提出,用于近似后验分布,以实现可计算的推断。在本研究中,我们采用假设密度滤波(Assumed Density Filtering, ADF)方法。ADF是一种广泛应用于贝叶斯滤波与追踪问题中的技术,其核心思想是将复杂的后验分布投影到一个假设的、更简单的分布形式上(通常与先验分布形式相同,以保持闭式解的可传递性)。在我们的场景中,我们将贝塔混合后验投影为单个贝塔分布,从而维持一个与公式(20)中贝塔先验形式一致的闭式贝塔近似后验更新。
为应用ADF,我们假设后验分布为一个参数为 α′和 β′的贝塔分布,并通过匹配其一阶矩(即均值)来用该单一贝塔分布近似原始的贝塔混合分布:



原文链接:https://arxiv.org/pdf/2405.00981
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-08-25,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号