从分歧到修复:大模型面对多块补丁的挑战

从分歧到修复:大模型面对多块补丁的挑战

CreateAMind
发布于 2026-03-11 17:21:59
发布于 2026-03-11 17:21:59
Characterizing Multi-Hunk Patches: Divergence,Proximity, and LLM Repair Challenges
从分歧到修复:大模型面对多块补丁的挑战
https://www.arxiv.org/pdf/2506.04418


摘要
在实际中,多段缺陷(multi-hunk bugs)——即修复涉及代码中多个不连续区域——十分常见,但在自动修复领域却未受到足够重视。现有的技术和基准测试主要针对单段修复场景,忽视了在代码库中协调语义相关变更所带来的额外复杂性。在本研究中,我们对HUNK4J进行了特征分析,该数据集包含来自372个真实缺陷的多段补丁。我们提出了“段间差异度”(hunk divergence)这一指标,通过捕捉编辑在词法、结构和文件层级上的差异,并结合补丁中涉及的代码段数量,来量化补丁内各编辑之间的差异程度。此外,我们定义了“空间邻近性”(spatial proximity),用于对代码段在程序层次结构中的空间分布情况进行分类建模。我们对六种大语言模型(LLM)进行的实证研究表明,随着差异度和空间分散程度的增加,模型的成功率显著下降。值得注意的是,当仅使用大语言模型时,没有任何模型能够在空间分布最分散的“碎片类”(Fragment class)缺陷上成功修复。这些发现揭示了当前大语言模型能力的关键短板,并推动了面向差异度感知的修复策略的发展。
第一部分 引言
自动程序修复(Automated Program Repair, APR)已受到研究社区的广泛关注 [1]–[18]。APR 技术已从基于启发式的方法 [19]–[22] 发展到深度学习方法,后者通过从大规模代码库中学习修复模式 [10], [15]–[18],在单段缺陷(single-hunk bugs)上取得了令人鼓舞的成果 [4], [5], [10], [16]–[18], [23]–[27]。尽管近年来取得了进展,大多数 APR 研究仍集中于单段场景 [10], [16]–[18], [24],忽视了多段缺陷——即需要在代码中多个不连续区域进行修改的缺陷。这类缺陷在实践中十分常见 [28],且由于其语义上的相互依赖性,修复难度更大。尽管该问题已被意识到 [28],但仅有少数研究直接应对这一挑战 [28]–[33],且其有效性有限。
近年来大语言模型(Large Language Models, LLMs)的进步在包括程序修复在内的多项软件工程任务中展现出巨大潜力 [34]。这些模型在包含代码和自然语言的海量数据集上进行训练,如 GPT-4 和 LLaMA,已展现出理解和生成代码的能力 [34]–[37]。尽管这些模型已在单段缺陷修复中取得显著成功,但其在处理多段代码修复方面的潜力仍探索不足。
早期基于大语言模型的多段修复研究包括 AlphaRepair [35]、RepairAgent [38] 以及微调策略 [39], [40]。尽管这些方法表明大语言模型可以超越单段修复场景,但关于在代码库中分布的语义相互依赖的编辑进行推理的挑战仍未得到解决。
我们识别出限制该领域进展的四个挑战。第一,数据集差异影响一致性:先前研究在不同的数据集上进行评估,例如合成基准 LMDefects [41]、算法生成的任务(EvalRepair-C++/Java)[40] 以及真实世界数据集如 Defects4J [42],且常基于不同的假设、输入格式和测试环境,导致结果难以比较。第二,缺陷类型模糊性影响评估:多段缺陷涵盖广泛的情形,从单个函数内非连续区域的修改,到跨多个文件的相互依赖变更。然而,先前工作并未系统性地刻画这种异质性,常常将多行、多函数和多文件等不同类型的多位置修复混为一谈。第三,报告方式不一致阻碍了有效归因:现有方法通常报告包含单段和多段结果的综合指标 [38], [40],难以单独评估其在多段修复上的有效性。第四,现有评估缺乏能够量化补丁内各代码段差异的、感知补丁复杂度的指标。
为应对这些挑战,我们:(1)提出“段间差异度”(hunk divergence),该指标通过测量多段补丁中各段之间的词法、结构和文件级距离,并结合段的数量及在文件间的分布情况,量化补丁内部的变异程度;(2)定义“空间邻近性”(spatial proximity)作为分类体系,将每个补丁划分为五类之一——核(Nucleus)、簇(Cluster)、轨道(Orbit)、蔓延(Sprawl)或碎片(Fragment),反映其在程序层次结构(包括方法、文件和包)中分布的离散程度;(3)利用这些抽象对多段补丁进行特征分析,研究其段间差异度和段间关系;(4)开发 BIRCH,一个用于标准化评估基于大语言模型的多段修复的平台,支持在不同模型和配置之间进行可复现的比较;(5)开展大规模实证研究,考察在不同差异度和分散度下,检索策略、上下文粒度以及反馈机制对修复成功率和成本的影响。
本研究的主要贡献如下:
- 我们提出了“段间差异度”指标,用于量化补丁内部在词法、结构和文件级距离上的变异程度;同时提出“空间邻近性”分类体系,根据多段补丁在代码库中的空间布局进行分类。
- 我们引入 HUNK4J,一个包含 372 个真实世界多段缺陷的基准数据集。同时,我们首次系统性地刻画了多段缺陷的特征,重点关注其段的多样性与空间邻近性。
- 我们提出 BIRCH,一个用于评估大语言模型在多段缺陷修复能力的平台。我们的实证研究涵盖 6 种大语言模型、2 种代码表示模式以及 3 种检索策略,并考察上下文范围和编译错误、测试失败反馈的作用。
- 我们的实证结果表明,随着段间差异度增加和空间邻近性降低,模型的修复准确率显著下降。所有未经增强的模型均未能修复“碎片类”(Fragment class)中任何缺陷,凸显了高度分散的代码段带来的严峻挑战。
第二部分 多段补丁的特征分析
尽管多段补丁已被研究 [28], [33], [38],但其结构与空间特性,以及这些特性如何影响自动修复,仍缺乏深入理解。
定义1(代码段,Hunk):一个代码段是一组应用于源代码特定区域的连续修改。我们将每个代码段 hi定义为一个元组:


我们的观察是,多段补丁在多个维度上可能存在显著差异。在某些情况下,各代码段几乎完全相同,例如重复的重命名操作或模板式修改;而在另一些情况下,它们涉及语义上不同的变更,在词法和结构上均存在差异。此外,这些编辑在空间位置上也各不相同,从位于同一方法内的代码段,到分散在多个文件中的代码段均有分布。这一观察促使我们提出问题:一个补丁内的代码段在多大程度上存在差异?这种差异是否可以被有意义地量化?
为此,我们首次对多段补丁进行了深入的特征分析,提出了两个新指标:(a)段间差异度(hunk divergence),用于量化各代码段之间在词法、结构和文件层级上的差异性;(b)空间邻近性(spatial proximity),用于对代码段在整个代码层次结构中的空间分布模式进行分类。
A. 段间差异度(Hunk Divergence)
我们提出“段间差异度”这一新指标,用于捕捉一个补丁中各代码段之间的词法、结构和文件层级上的差异。
定义3(成对段间差异度,Pairwise Hunk Divergence):我们通过词法距离、结构距离和文件级分离距离的组合,定义补丁 P中两个代码段
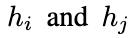
之间的成对段间差异度:
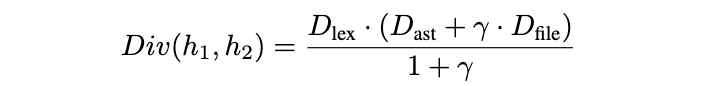

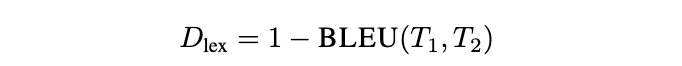

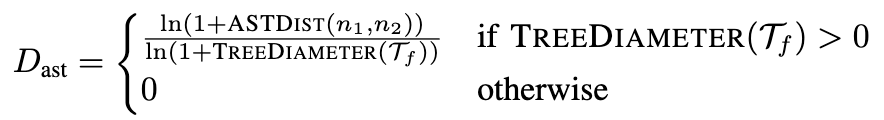

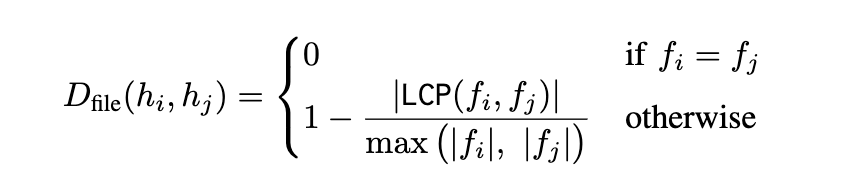



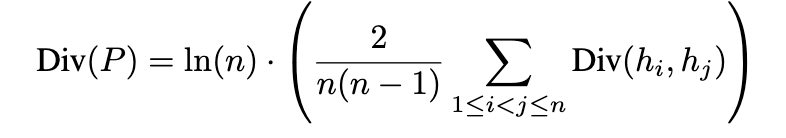

B. 空间邻近性(Spatial Proximity)
空间邻近性将每个多段补丁划分为五类之一:核(Nucleus)、簇(Cluster)、轨道(Orbit)、蔓延(Sprawl)或碎片(Fragment),代表代码段在方法、文件和包等层次结构中空间分布的离散程度逐渐增加。与段间差异度不同——后者基于代码段的不相似性给出连续的量化分数——该分类通过基于规则的方式,提供对代码段空间分布模式的直观洞察。
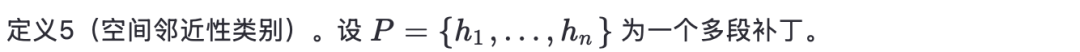

这里,λ 是一个用于区分结构上分散(SPRAWL)与广泛离散(FRAGMENT)补丁的目录深度阈值。这一区分基于如下直觉:当修改发生在共享层次结构极少的目录路径中时,开发人员所需进行的协调工作量会显著增加。
C. HUNK4J:一个多段缺陷数据集
为了实现系统性的评估,我们提出了 HUNK4J,这是一个从 DEFECTS4J [51] 中整理提取的多段缺陷数据集。DEFECTS4J 包含来自多个不同领域开源 Java 项目的、可复现且有测试套件支持的缺陷。我们分析了 DEFECTS4J 中全部 835 个缺陷,识别出其中开发者编写的补丁包含多段修复(定义2)的缺陷。结果发现,835 个缺陷中有 372 个(44.6%)属于多段缺陷。这 372 个多段缺陷构成了我们 HUNK4J 数据集的基础,用于后续分析。
除了提取补丁级别的特征外,我们还为 HUNK4J 增加了每个缺陷的自然语言上下文信息。具体而言,我们从官方项目仓库和问题跟踪系统(包括 Apache JIRA、GitHub Issues 和 SourceForge)中收集了缺陷报告、标题和摘要。这些丰富的元数据有助于为基于大语言模型的程序修复构建提示(prompt),并支持检索增强型策略。
通过结合经测试套件验证的补丁和详细的代码段信息(定义1、定义2),HUNK4J 能够对多段缺陷在词法、结构、文件级差异以及空间分布等方面的异质性进行深入分析。
D. 代码段特征分析
为了分析多段缺陷的复杂性,我们对 HUNK4J 中的每个补丁进行了检查。所有分析均基于开发者编写的真实补丁(ground truth patch)进行。首先,我们通过定位以 diff --git 开头的行来识别被修改的文件集合,这些行标记了补丁中包含的文件。接着,我们通过检测以 @@ 开头的行来提取每个文件内的独立代码段(hunks),这些行表示代码段的边界。对于单文件的多段补丁,我们进一步通过统计以 -(删除)或 +(新增)开头的行数,来量化修改的行数。如果一个删除操作后紧跟一个新增操作,我们将其视为一次单行替换,而非两个独立的修改。这些步骤有助于对代码段进行精确分类。
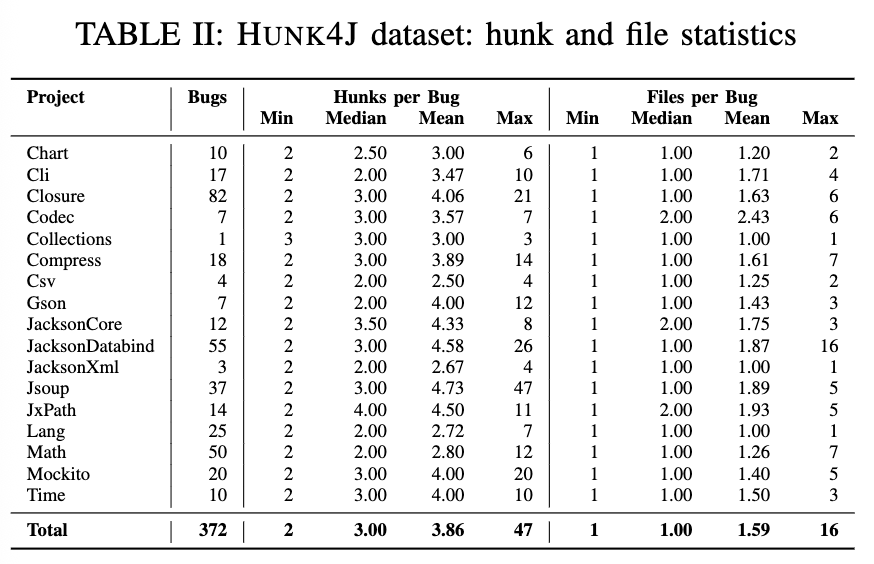
我们从两个维度对多段缺陷进行分类:修改区域的数量(代码段数) 和 涉及的文件数量,如表 I 所示。单文件的多段缺陷占主导地位,共 244 例,即所有修改都局限在单个文件内——其中包括 140 个包含两个代码段的缺陷、55 个包含三个代码段的缺陷,以及 49 个包含四个或更多代码段的缺陷。这类缺陷属于文件内部的修复场景,通常只需局部推理即可解决。相比之下,有 128 个缺陷跨越多个文件,代表更碎片化、分布更广的修复任务。值得注意的是,其中 68 个缺陷涉及四个或更多代码段,表明其在代码库中的分布程度较高。例如,JSOUP 56 [52] 的多段补丁 P 涉及 5 个文件中的 10 个代码段。

为补充前述分类,表 II 展示了各项目的具体统计信息,揭示了多段缺陷在不同代码库中的表现情况。在 17 个项目中的 15 个中,每个缺陷的代码段中位数最多为 3,表明大多数缺陷涉及相对局部的修改。然而也存在例外,例如 Jsoup 87 [53] 的补丁包含多达 47 个代码段。相比之下,Chart 4 [54] 的多段修复仅包含两个代码段,且均位于同一方法内,因此更容易推理。在所有 17 个项目中,每个缺陷修改的文件数中位数不超过 2;尽管如此,仍存在显著例外。例如,JacksonDatabind 103 [55] 的补丁跨越 16 个文件中的 26 个代码段,在整个代码库中修改了异常处理逻辑。相反,Lang、Collections 和 JacksonXml 等项目则未包含任何跨文件的多段缺陷。

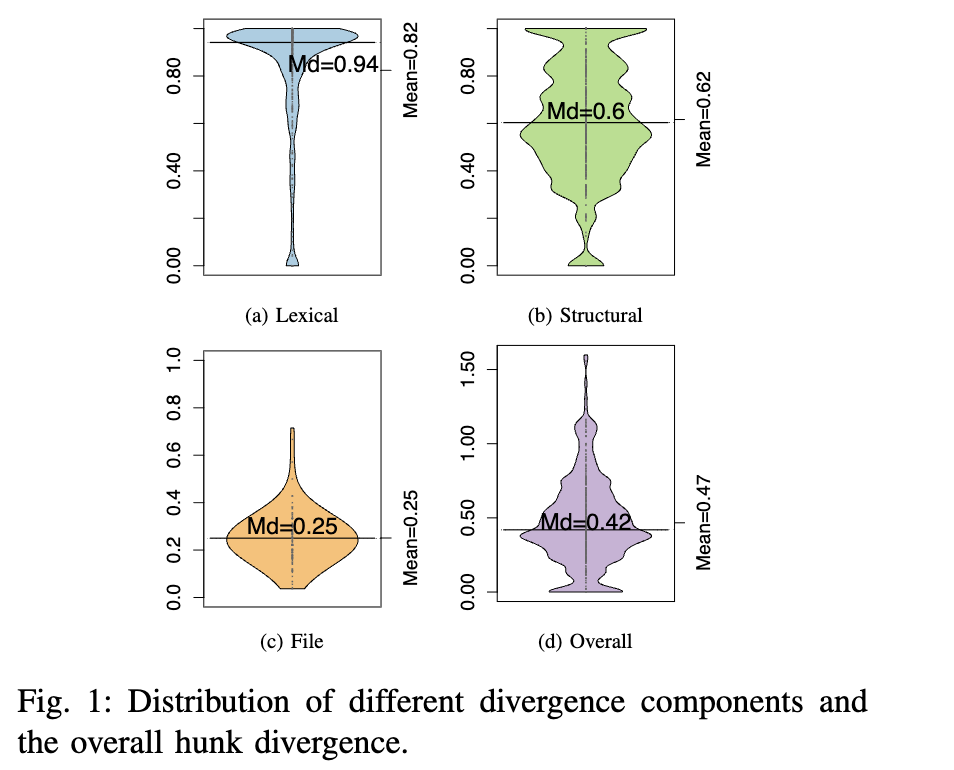
HUNK4J 中整体的段间差异度(hunk divergence)范围从最小值 0.00 到最大值 1.60,中位数为 0.42,均值为 0.47。值得注意的是,25% 的多段补丁其差异度值超过 0.624。该分布反映了在词法内容、代码结构和文件层级分离上的显著异质性。重要的是,这种差异度分布远非简单或均匀,否定了任何关于多段补丁具有同质性的假设。
我们还根据提出的空间邻近性分类体系(定义5)对多段补丁进行了特征刻画。我们基于 HUNK4J 中包路径深度的经验分布来设定邻近性阈值 λ。所有缺陷文件的包路径深度中位数为 6;我们设 λ=3,即该中位数的一半,以保守地区分松散聚集的修改与在代码库中结构上广泛分散的修改。
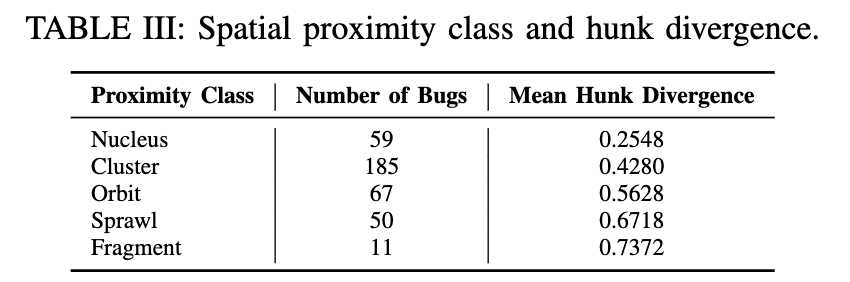
表 III 根据空间邻近性对多段补丁进行了分类,揭示出明显的偏向于局部化修复的分布趋势。其中,“簇”类(Cluster)包含 185 个缺陷,是最常见的类别,其补丁特征为多个代码段出现在同一文件内的不同方法中。其次是“轨道”类(Orbit),共 67 个缺陷,表示代码段跨越同一包内的多个文件;以及“核”类(Nucleus),共 59 个缺陷,所有代码段均局限于单个方法内。例如,来自“簇”类的 Mockito 6 [56] 包含 20 个代码段,全部位于同一个文件中,但分布在多个方法之间,显示出尽管在方法层级上分散,但在文件层级上仍具有较高的内聚性。
相比之下,“蔓延”类(Sprawl)包含 50 个缺陷,“碎片”类(Fragment)包含 11 个缺陷,代表了空间分布越来越分散的补丁。“碎片”类由那些代码段散布在互不相关的包中的补丁组成。例如“碎片”类中的 Closure 144 [57],其代码段分散在多个无关的包中,显示出极低的空间局部性。
随着空间分散程度的增加,平均段间差异度(hunk divergence)呈现单调上升趋势。尽管“碎片”类补丁较为罕见,但其差异度最高(0.7372),突显了此类修复任务的复杂性。
第三部分 实证评估
本研究旨在回答以下研究问题:
- RQ1:大语言模型(LLMs)在多段修复任务中的表现如何?
- RQ2:增强型提示技术(如RAG、上下文扩充、反馈机制)在多大程度上提升了修复准确率?
- RQ3:代码段的特征(如差异度和空间邻近性)如何影响基于大语言模型的修复技术的成功率?
- RQ4:某些特定类型的差异度或空间邻近性是否更能预示大语言模型修复中的困难?
A. 基准测试框架:BIRCH
为了实现在不同大语言模型(LLMs)之间的可复现评估,我们提出了 BIRCH,一个面向多段程序修复的基准测试框架。该框架提供了一个从输入准备到补丁验证的端到端评估流程。评估过程首先从 HUNK4J 中检出程序的缺陷版本,并设置工作空间。针对每个缺陷,BIRCH 提取缺陷代码、相关测试用例以及关联的元数据。随后,框架构建一个输入提示(prompt),其中包含缺陷代码、精确的缺陷位置、问题的自然语言描述,以及失败的测试用例及其对应的错误信息。提示构建完成后,提交给选定的大语言模型。模型生成的补丁被解析并应用到缺陷代码上,随后使用测试套件对代码进行编译和测试。编译错误和测试失败信息会被记录下来。
模式(Modes)。BIRCH 支持对原始大语言模型(vanilla LLMs)的评估,同时也提供多种可选模式以增强模型能力。
- 基于检索的示例选择模式:支持稀疏检索(如 BM25)和稠密检索(dense retrieval)技术。
- 上下文范围选择模式:可提取不同粒度的上下文信息,包括方法级、类级和文件级上下文。
- 反馈循环模式:支持补丁的迭代优化:如果生成的补丁无法通过编译,则将相应的编译错误信息追加到下一轮提示中;如果补丁能通过编译但未能通过测试套件,则将详细的测试失败信息纳入提示,以指导后续的修复尝试。如果补丁成功通过编译且所有测试均通过,则标记为修复成功。
所有评估过程中的产物,包括提示内容、生成的代码、差异(diff)、测试日志等,均被持久化保存,以便后续检查与分析。
实现细节。BIRCH 使用 Python 实现,并通过 Ollama [58] 支持专有模型和开源模型。我们使用 litellm [59] 与不同提供商的大语言模型 API 进行对接。提示模板采用 TOML 格式,便于集成新的提示变体。我们采用 JavaParser 解析抽象语法树(AST),用于计算代码段之间节点级的距离、获取树的直径,以及提取方法、类等外围作用域信息。对于稀疏检索,使用 BM25 算法;对于稠密检索,采用 text-embedding-ada-002 或 Mini-LM 模型生成嵌入向量,并将其存储在 FAISS [60] 索引中,以支持最近邻查找。
B. 模型
本研究对六种模型进行了对比评估,所选模型代表了具有不同架构特征的专有模型和开源模型。专有模型包括:谷歌的 GEMINI-2.5-FLASH(上下文窗口为100万token),通过官方Gemini API以非推理模式进行评估;亚马逊的 NOVA-PRO(30万token)。来自OpenAI的模型包括:具备推理能力的 O4-MINI(20万token),以及不具备推理能力的变体 GPT-4.1(100万token),均通过 OpenAI API 直接调用。专有模型的参数量未公开。开源模型包括:Mistral AI 的 MISTRAL-LARGE-2407(12.8万token,1230亿参数)和 Meta 的 LLAMA3.3(12.8万token,700亿参数)。除来自 OpenAI 和谷歌的模型外,其余所有模型均通过 Amazon Bedrock [61] 的全参数推理端点进行评估。我们的目标并非进行全面的模型基准测试,而是旨在评估研究结论在不同架构的大语言模型之间的普适性。
C. 评估指标
我们根据生成代码是否能够正确解析、成功编译并通过基准测试套件中的所有测试来评估补丁的正确性。沿用先前研究 [62] 的做法,我们报告 Plausible@1 指标,其定义为:在所有缺陷中,生成的首个(top-1)看似合理(plausible)的补丁能够通过完整测试套件的缺陷所占的比例:
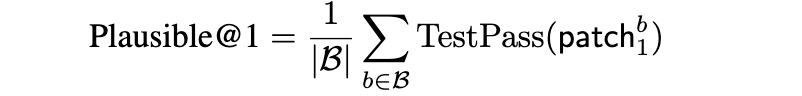
其中,B是缺陷集合,

表示针对缺陷 b生成的第一个补丁。如果一个补丁能够成功编译并通过所有测试用例(包括最初失败的测试用例),则被视为“看似合理”(plausible)。
除 O4-MINI 外,所有模型均使用标准解码设置(例如温度 temperature = 0.0)为每个缺陷生成一个补丁。O4-MINI 的 API 固定使用温度为 1.0。尽管 API 层面的解码被配置为确定性模式,但由于底层系统因素(如线程调度、内存布局和后端随机性)的影响,实际生成结果仍具有非确定性 [63]。
D. 大语言模型在多段修复中的有效性(RQ1)
为评估大语言模型在多段缺陷修复中的表现,我们将全部 372 个缺陷提交给六个模型进行测试。表 IV 总结了实验结果,包括完全修复的缺陷数量(Pass)、测试失败数、编译失败数、看似合理补丁率(Plausible@1)以及每次运行的预估成本。总体来看,表现最佳的模型是 O4-MINI,成功修复了 372 个缺陷中的 100 个(26.88%),其次是 GPT-4.1,成功修复 82 个(22.04%)。在开源模型中,LLAMA3.3 准确率最高,修复了 46 个缺陷(12.37%),MISTRAL-2407 紧随其后,修复了 45 个缺陷(12.10%)。
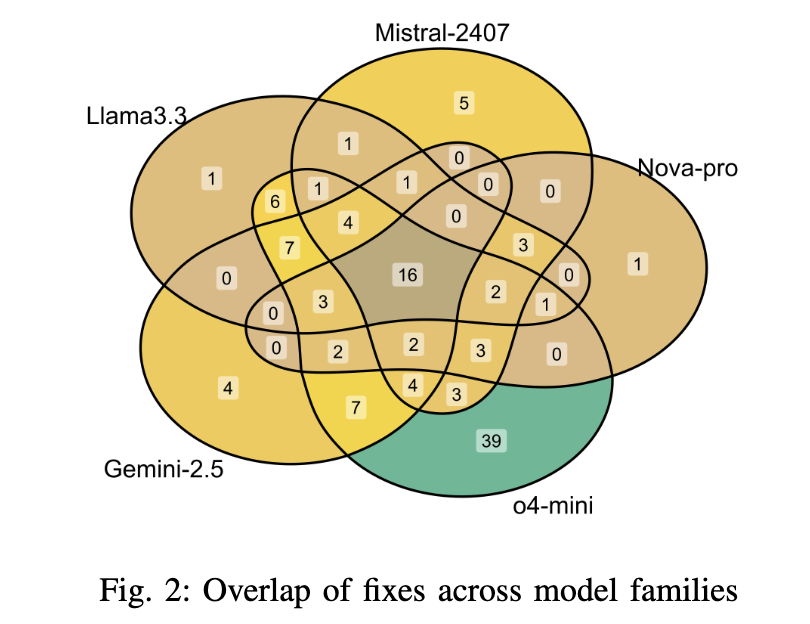
在六个大语言模型中,共成功修复了 127 个不同的缺陷。在两个 OpenAI 模型中,我们选择准确率更高的 O4-MINI 进行后续分析。接着,我们评估个体模型的有效性以及模型组合的覆盖能力,选用以下五个模型进行分析:O4-MINI、GEMINI-2.5-FLASH、NOVA-PRO、MISTRAL-2407 和 LLAMA3.3。具体而言,我们对每个模型成功修复的缺陷集合进行交集分析。这五个模型共同为 116 个不同的缺陷生成了看似合理的补丁。这一结果表明,通过精心选择的模型组合,可以在多段缺陷修复中实现较高的覆盖范围。图 2 展示了所选模型之间 Plausible@1 补丁的重叠情况的维恩图(Venn diagram)。尽管所有五个模型共同修复了 16 个缺陷,但每个模型都贡献了额外的独立修复,其中 O4-MINI 最为突出,独立修复了 39 个缺陷。
从成本角度来看,模型的准确率相对于推理开销存在显著差异。GEMINI-2.5-FLASH 以仅 0.37 美元的总成本实现了 13.44% 的 Plausible@1,是所有模型中成本最低的。相比之下,开源模型 MISTRAL-LARGE-2407 的成本高达 4.08 美元,但其 Plausible@1 仅为 12.10%,与前者相当。这一差距表明,更高的推理成本并不一定带来更高的修复准确率。
总体而言,尽管近年来取得了进展,大语言模型在多段缺陷修复任务上仍面临显著挑战:即使是表现最好的模型,仍有超过 70% 的缺陷未能修复。O4-MINI 的更高准确率凸显了使用具备推理能力、在测试时拥有更多计算资源的模型相比非推理模型的优势。然而,即使是最佳模型的有限修复准确率也表明,仅靠增加测试时的计算量可能不足以应对复杂的修复任务 [64]。
E. 增强型提示的影响(RQ2)
为评估不同提示增强策略对基于大语言模型的程序修复的影响,我们考察了三个方面:(a)基于检索的示例选择,(b)上下文粒度,(c)基于反馈的迭代优化。鉴于在所有提示增强策略上进行大规模评估的推理成本较高,本分析仅限于两个代表性模型:O4-MINI(表现最佳的专有模型)和 LLAMA3.3(我们评估中效果最好的开源模型)。
我们通过比较不同方式表示和检索相似修复示例,来评估基于检索的提示(retrieval-augmented prompting)的有效性。每个缺陷示例分别以代码标记(code tokens)或抽象语法树元素(AST elements)进行编码,分别捕捉词法和结构层面的信息。对于每种表示方式,我们应用一种稀疏检索方法和两种基于稠密嵌入的检索方法,以识别语义上相似的历史补丁作为示例。通过将两种代码表示与三种检索技术组合,我们构建了六种示例选择策略,每种策略在提示中包含检索出的最相似的前5个补丁。在基于检索的提示中使用的示例补丁,是从 HUNK4J 数据集中早于目标缺陷被修复的多段补丁中选取的(排除目标缺陷本身),其选择依据是与目标缺陷在标记或AST表示上的相似性,具体取决于检索配置。
表 V 报告了不同提示增强策略在 O4-MINI 和 LLAMA3.3 上的准确率、失败结果和推理成本。结果表明,基于标记的表示结合稠密检索的策略,优于基于AST的表示和稀疏检索(BM25)方法。对于 O4-MINI,最佳配置“token+text-embed”实现了 31.18% 的 Plausible@1,比“AST+text-embed”变体(23.66%)高出 7.52 个百分点。在所有检索策略中,“text-embed”在标记和AST输入下均持续优于 MiniLM 和 BM25。LLAMA3.3 也表现出类似趋势:“token+text-embed”达到 20.16% 的 Plausible@1,而“AST+text-embed”为 11.02%,“token+BM25”为 17.20%。这种提升可归因于稠密检索的工作机制:与依赖词项重叠和词频的稀疏检索(BM25)不同,稠密检索(text-embed)使用神经嵌入模型将查询和候选补丁编码为稠密向量。该嵌入模型是在标记序列上训练的,而非结构化的AST。因此,当查询和候选均以标记序列表示时,相似性搜索更为准确。
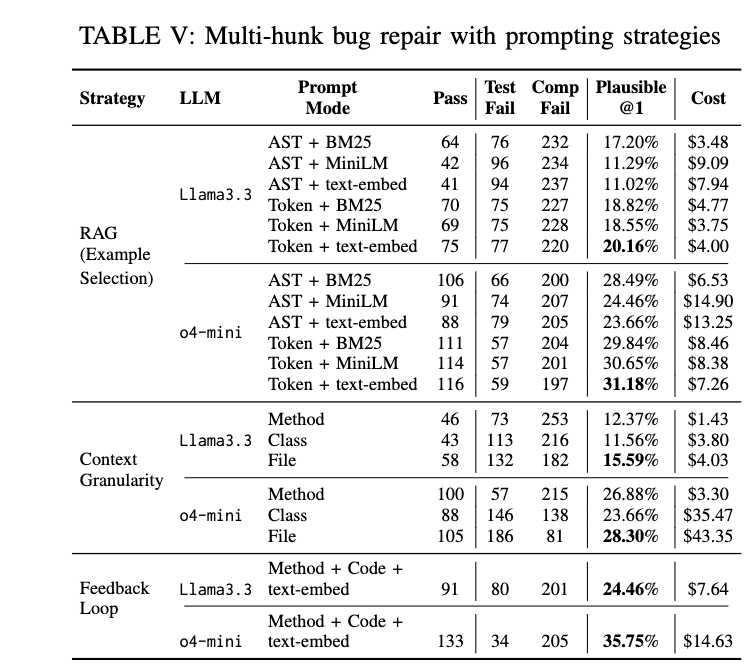
除了示例选择,我们还研究了上下文粒度对修复效果的影响,通过在提示中包含不同范围的代码上下文进行比较。我们考察了三种包围上下文层级:方法级、类级和文件级。结果显示,更广的上下文通常有助于提升修复成功率。对于 O4-MINI,Plausible@1 从方法级的 26.88% 提升到文件级的 28.30%,但在类级出现下降(23.66%),因为类级提示常导致代码生成不完整。类级上下文效果较差的原因在于,大语言模型可能将类片段视为不完整的代码片段,倾向于仅修补单个方法或更底层的结构。相比之下,文件级提示包含导入语句和顶层注释,提供了更清晰的语义线索,促使模型生成完整的代码。LLAMA3.3 也呈现类似趋势:文件级提示达到 15.59%,高于方法级(12.37%)和类级(11.56%)。然而,这种提升伴随着显著的成本增加:O4-MINI 的文件级提示成本为 43.35 美元,是方法级(3.30 美元)的13倍,而后者已接近同等准确率。
我们进一步评估了基于反馈的迭代优化,即在提示中加入由编译失败或测试失败动态生成的执行信息,遵循先前研究 [65]–[67] 的做法。为控制成本,反馈提示采用方法级上下文和最佳检索配置(token+text-embed)。尽管设计保守,反馈机制在所有设置中仍取得了最高准确率:O4-MINI 达到 35.75% 的 Plausible@1,LLAMA3.3 达到 24.46%,均超过各自静态提示的基线水平。值得注意的是,使用反馈的 O4-MINI 准确率超过了使用文件级上下文的静态提示(28.30%),而成本不到其一半(14.63 美元 vs. 43.35 美元)。这些结果表明,由测试失败或执行轨迹提供的运行时信息,能够比单纯扩展提示上下文更有效地引导模型。此外,反馈机制通过引入动态执行轨迹,弥补了窄上下文的局限性,提供了静态提示所缺乏的具体且针对失败的指导。
尽管反馈和检索等提示增强策略相比原始大语言模型提升了修复准确率,但即使在最佳配置下,仍有 64% 的多段缺陷未能被修复。
F. 基于段间差异度和空间邻近性的修复结果分析(RQ3)
为探究基于大语言模型的程序修复在何种条件下最为有效,我们统计了成功与失败修复案例的段间差异度(hunk divergence)的描述性统计量,并计算了各空间邻近性类别下的修复准确率。这些指标基于 RQ1 中选出的五个代表不同模型家族的模型所生成的补丁得出。
表 VI 报告了在成功修复与未修复缺陷上的段间差异度的集中趋势,同时列出了各空间邻近性类别中被正确修复的缺陷比例。
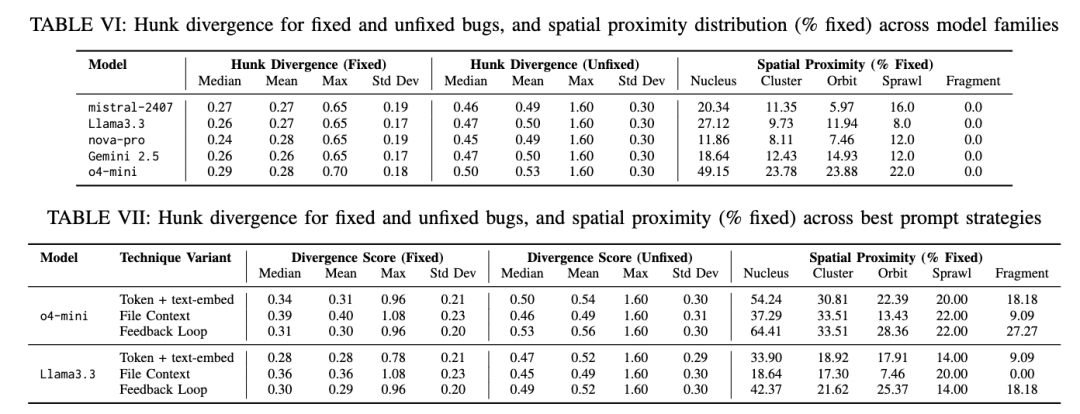
成功修复的缺陷在所有五个模型中均表现出较低的差异度(均值 ≈ 0.26–0.28;中位数 ≈ 0.24–0.29),且方差较小(标准差 < 0.20),表明生成的补丁在语义上高度一致。相比之下,未修复的缺陷表现出显著更高的段间差异度(均值:0.49–0.53;中位数:0.45–0.53),且方差更大、最大值更高(最高达 1.60)。这些结果反映出大语言模型在协调跨分散代码区域的复杂、语义多样的修改时面临显著困难。
表 VII 报告了在表现最佳的提示配置下的分析结果,即:(1)标记 + text-embed 检索,(2)文件级上下文,(3)反馈循环,应用于 O4-MINI 和 LLAMA3.3。在所有策略下,被修复的缺陷始终表现出比未修复缺陷更低的差异度。已修复缺陷的平均差异度范围为 0.28–0.40(中位数:0.28–0.39),而未修复缺陷的得分显著更高(均值:0.49–0.56;中位数:0.45–0.53),表明代码段内部异质性越高,越容易导致修复失败。在所有评估策略中,反馈循环在两个模型上对已修复缺陷实现了最低的差异度(均值:0.29–0.30;中位数:0.30–0.31),并在“核”(NUCLEUS)和“簇”(CLUSTER)类别中实现了最高的修复比例。这一模式表明,该策略在涉及空间局部化修改的缺陷上效果更佳。这些结果表明,提示策略显著影响了成功补丁的语义一致性与空间局部性。值得注意的是,反馈循环在高邻近性上下文中实现了最低差异度的修复,从而促进了更精确、更协调的多段程序修复。
空间邻近性与修复成功率之间的关联首先体现在表 VI 中。修复成功率在“核”(NUCLEUS)和“簇”(CLUSTER)类别中最高,因为这些类别的代码段空间位置更接近;而在“蔓延”(SPRAWL)和“碎片”(FRAGMENT)类别中修复率显著降低,其中“碎片”类甚至没有任何成功修复案例。这一趋势在表 VII 的不同提示变体中依然存在。在所有评估策略中,反馈循环在空间邻近性高的类别中始终表现出更优的准确性。例如,使用反馈循环的 O4-MINI 在“核”类中修复了 64.41% 的缺陷,在“簇”类中修复了 33.51%,而在“蔓延”和“碎片”类中分别仅修复了 22.00% 和 27.27%。LLAMA3.3 也表现出类似模式。
为进一步探究代码段的空间邻近性是否影响基于大语言模型的修复成功率,我们分析了被五个不同大语言模型家族中至少一个高性能模型成功修复的缺陷子集。在 HUNK4J 的 372 个多段缺陷中,共有 116 个被至少一个模型成功修复。图 3 采用 UpSet 风格的可视化方式展示这 116 个已修复缺陷,按空间邻近性类别以及生成成功补丁的模型组合进行分组。横轴上的每一条柱状图代表一种唯一的模型组合(由下方矩阵中的实心圆圈表示),柱状图从左到右按修复缺陷数量由少到多排列。每根柱子内部按空间邻近性类别进行颜色编码:“核”类(深蓝)、“簇”类(浅蓝)、“轨道”类(橙)、“蔓延”类(桃红)、“碎片”类(绿色),各段标注其所代表的确切缺陷数量。每种模型交集的总修复数量标注在对应柱子上方。下方面板为一个由实心圆点和垂直连接线组成的矩阵:每行代表五个模型之一(从上到下依次为:MISTRAL-2407、LLAMA3.3、GEMINI-2.5-FLASH、NOVA-PRO、O4-MINI),每列对应上方生成柱状图的相同模型组合。实心圆点表示该模型参与了该组合,连接线表示参与的模型。
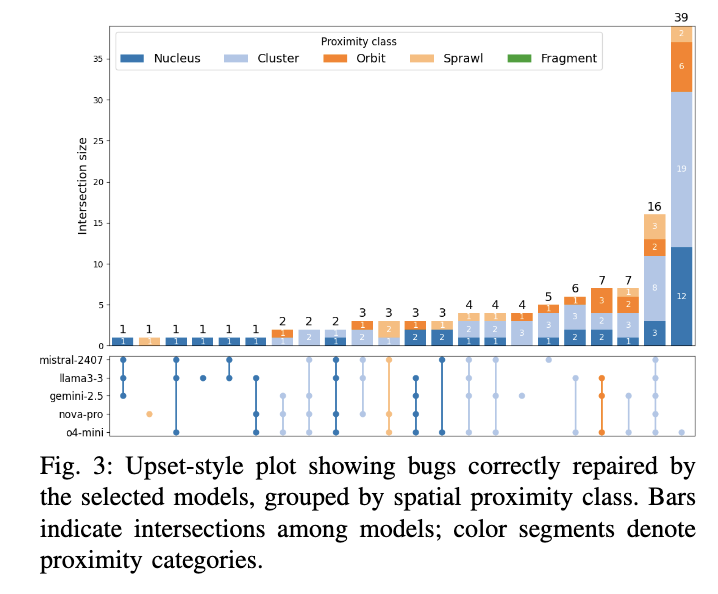
两个趋势明显可见:第一,大多数成功修复集中在“核”和“簇”类别,这些类别中相关代码元素高度聚集,且在共享和模型特有的交集中均占主导地位。第二,“轨道”和“蔓延”类别中相关上下文更分散,修复频率较低。大语言模型未能修复任何“碎片”类缺陷,这反映了该类中相关上下文极度分散或不连通(见表 VI)。最大的修复集合(39 个缺陷)仅由 O4-MINI 独立完成,第二大的集合(16 个缺陷)被所有五个模型共同修复。较小的交集揭示了模型特有的能力或差异,特别是在处理空间邻近性较低的上下文方面。
综上所述,这些发现表明,基于大语言模型的多段缺陷修复若要成功,通常具备两个特征:(1)语义上一致、段间差异度低的修改;(2)空间上局部化、邻近性高的依赖关系。
G. 差异度、邻近性与修复难度(RQ4)
我们现在探讨段间差异度(hunk divergence)和空间邻近性(spatial proximity)是否可作为大语言模型(LLM)修复难度的预测指标,即模型无法生成正确补丁的可能性。该分析考虑了多段补丁的两个维度:补丁内部的变异程度(段间差异度)和在程序层次结构中空间分布的离散程度(空间邻近性)。
为进行评估,我们首先将五个最佳大语言模型(Top5 LLMs)的数据划分为两个独立样本:已修复缺陷和未修复缺陷,并对其差异度得分应用双样本 Wilcoxon 秩和检验(two-sample Wilcoxon rank-sum test)。在所有五个表现最佳的模型中,已修复与未修复缺陷的差异度分布均存在显著差异。所有 Wilcoxon 检验的 p 值均低于 10⁻⁴,其中三个模型的 p < 10⁻⁷,最大 p 值为 2.6 × 10⁻⁵。这些结果证实,更高的段间差异度与无法生成正确补丁之间存在强关联。
我们还计算了 Cliff’s Delta 以评估效应量(effect size)。在仅使用大语言模型和采用反馈循环提示的配置下,O4-MINI 的 Delta 值分别为 0.533 和 0.554。这两个值均超过 0.474 的阈值,表明效应量大,即成功修复与未成功修复的缺陷在段间差异度上存在显著差异。在所有模型中观察到的一致显著性表明,段间差异度可能作为补丁复杂性和基于大语言模型修复有效性的有意义指标。
我们在比较增强型提示配置时也观察到了类似趋势(见表 VII)。在六种提示变体中,四种的 p 值低于 10⁻⁷,一种为 p = 3.8 × 10⁻³,所有 p 值均低于传统显著性阈值 0.05。这表明,基于差异度区分已修复与未修复缺陷的模式在不同提示策略下均成立,进一步验证了其预测价值。
图 4 展示了分面小提琴图(faceted violin plots),呈现了每个模型在不同结果(修复成功/失败)下的平均段间差异度得分分布。每个小提琴图表示差异度值的密度分布,其中嵌入的箱线图显示中位数和四分位距(IQR),覆盖数据的中间 50%。在所有模型中,已修复缺陷始终与较低的差异度得分相关联。这一清晰且一致的模式表明,段间差异度是判断多段缺陷复杂性和大语言模型修复成败的有效判别信号。
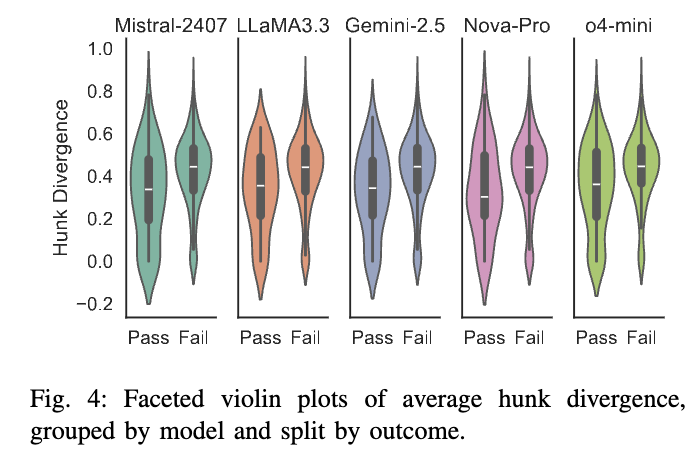
除了差异度,空间邻近性也表现出强分类预测能力。如图 3 所示,修复成功率从“核”(NUCLEUS)类到“蔓延”(SPRAWL)类持续下降,而“碎片”类(FRAGMENT)在所有模型下均无任何成功修复。这一趋势表明,当与缺陷相关的上下文越分散,大语言模型越难以合成正确的补丁。“碎片”类完全无法修复的现象,揭示了当前模型在处理非局部、高度分散的依赖关系时存在能力上的硬性边界。
我们的分析表明,随着段间差异度的增加和空间邻近性的降低,大语言模型的修复准确率显著下降。那些在补丁内部变异度高,或代码段分散在不同方法、文件或包中的缺陷,绝大多数仍未被修复。这些发现凸显了开发能够显式应对多段补丁中词法和结构分散性的模型与提示策略的迫切需求。
五、有效性的威胁
HUNK4J 数据集完全来源于 Java 项目,这可能限制其向其他编程语言的推广。尽管这些缺陷来自真实场景且具有多样性,但其分布反映了 Java 项目的设计和测试理念,可能对修复任务的挑战范围带来一定偏差。
我们采用 Plausible@1 指标以降低推理成本,但这可能低估模型在迭代场景下的实际准确率。为了保证公平性,所有模型使用固定的解码参数和提示模板,这可能对某些架构更有利。然而,我们的目标是在统一条件下进行比较分析,而非针对特定模型优化。
我们的评估假设缺陷定位是完美的,这遵循了先前基于大语言模型的修复研究做法,以隔离补丁生成质量的影响 [10], [17], [18], [33]–[35], [38], [41]。虽然这为准确率设定了上限,但现实场景中通常存在定位不准确或不完整的问题。值得注意的是,即使在完美定位的前提下,大语言模型在多段修复上仍表现不佳,例如对“碎片”类(Fragment-class)缺陷全部修复失败(见表 VI),这突显了语义协调能力的不足,而不仅仅是定位问题。
大语言模型通过第三方 API 访问,其执行结果可能因后端更新或系统级非确定性而产生变化。尽管我们将解码设置为确定性模式(temperature = 0),仍可能出现微小波动。我们通过记录所有输入、输出和执行元数据来缓解这一问题,以确保可复现性。
我们的实现使用 JavaParser 提取抽象语法树(AST)并计算诸如节点级距离和树直径等差异度指标。使用其他解析器(如 javalang)可能因 AST 构建方式的差异而产生轻微变化,但所有模型均在统一标准下进行评估。
为支持可复现性,我们公开了 BIRCH 框架、所有脚本、提示模板以及 HUNK4J 数据集 [68]。
五、相关工作
大多数自动程序修复(APR)基准对多段缺陷的支持有限。虽然 Defects4J [51]、Bugs.jar [69]、BugsInPy [70] 和 LMDefects [41] 包含多段缺陷,但其他基准覆盖有限 [71]–[73] 或专注于单段修复 [74]–[76]。现有的基于大语言模型的多段修复研究依赖于合成数据 [41]、函数级 [42] 或算法生成的基准 [40],其通用性受限。我们提出 HUNK4J,这是一个源自 Defects4J 的真实世界多段缺陷基准,补充了差异度指标,用于评估基于大语言模型的修复方法。
先前研究已将变更度量用于缺陷预测。Graves 等人 [77] 使用了文件数和修改次数等粗粒度指标;D’Ambros 等人 [78] 强调了变更耦合与分散性的预测能力;Ferzund 等人 [79] 提出了代码段级别的度量。相比之下,我们量化了多段补丁中的语义和结构异质性,以评估基于大语言模型的修复效果。
关于大语言模型在多段修复中的先前研究 [35], [38]–[42], [80],在数据集、提示策略和评估协议上存在广泛差异,常报告综合结果而未单独分析多段修复的准确率。尽管已有研究探讨了补丁属性(如代码段可分性)[80],但未考虑空间分散性或补丁内部异质性。我们通过提出“段间差异度”(Hunk Divergence)和“空间邻近性”(Spatial Proximity)两个新指标,弥补了这一不足,这两个指标捕捉了代码段之间的词法、结构和层次关系,从而支持对复杂度敏感的分析。
六、结论
我们首次从补丁内部差异度的视角对多段缺陷进行了系统性刻画。我们提出的“段间差异度”指标量化了代码段之间在词法、结构和文件分离上的不相似性,而“空间邻近性”则对代码段在代码库中的分布进行分类。研究发现,多段缺陷在差异度上表现出显著变异性,没有任何单一模型能在整个谱系上保持高准确率。这些贡献共同为开发能够应对多段缺陷独特挑战的“差异度感知”技术奠定了基础。在未来工作中,我们计划开发一种基于差异度感知的模型选择器,根据预测的修复复杂度,将缺陷路由到最具能力且成本效益最高的大语言模型。
原文链接:https://www.arxiv.org/pdf/2506.04418
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-08-17,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号