LLM 中贝叶斯推断的几何尺度 ——贝叶斯注意力三部曲之Paper III

LLM 中贝叶斯推断的几何尺度 ——贝叶斯注意力三部曲之Paper III

CreateAMind
发布于 2026-03-11 16:13:09
发布于 2026-03-11 16:13:09
《大语言模型中贝叶斯推理的几何缩放》——贝叶斯注意力三部曲之Paper III https://arxiv.org/pdf/2512.23752


近期研究表明,在受控的“风洞”(wind-tunnel)环境中训练的小型 Transformer 模型能够实现精确的贝叶斯推理,其训练动态会产生一种几何基底(geometric substrate)——即低维的值流形(value manifolds)和逐步正交化的键(progressively orthogonal keys)——用以编码后验结构。我们探究这种几何特征是否在工业级语言模型中依然存在。在 Pythia、Phi-2、Llama-3 和 Mistral 等模型系列中,我们发现:最后一层的值(value)表征沿着单一主导轴组织,该轴的位置与预测熵高度相关;而当使用领域受限的提示(domain-restricted prompts)时,这种结构会坍缩为在合成环境中观察到的相同低维流形。
为了探查这种几何结构的作用,我们在上下文学习(in-context learning)过程中对 Pythia-410M 模型中与熵对齐的轴进行了定向干预。移除或扰动该轴会特异性地破坏局部不确定性几何结构,而对匹配的随机轴进行同等干预则不会产生此类影响。然而,这些单层操作并未导致贝叶斯式行为出现成比例的、特异性的退化,这表明该几何结构是不确定性的一种特权读出(privileged readout),而非唯一的计算瓶颈。综上所述,我们的结果表明,现代语言模型保留了在“风洞”中实现贝叶斯推理所需的几何基底,并沿着这一基底组织其近似的贝叶斯更新。
1 引言 大语言模型在自然语言、编程、数学和推理任务中取得了显著的性能表现 [6, 7, 14]。然而,其内部计算机制仍仅部分被理解。一个核心问题是:Transformer 模型仅仅是通过大规模数据近似统计关联,还是实现了更为原则性的概率推理形式?
风洞结果:近期工作(本三部曲的第一篇论文 [1])证明,在受控的“贝叶斯风洞”中训练的小型 Transformer 模型能够在双射学习(bijection-learning)和隐马尔可夫模型(HMM)滤波任务上执行精确的贝叶斯推理:其后验熵、KL 散度和预测分布与解析解的误差在 0.1 比特以内。第二篇论文进一步表明,这些行为源于梯度动力学所生成的特定几何机制:按熵排序的值流形、定义假设方向的正交键帧(orthogonal key frames),以及逐层注意力锐化(layerwise attention sharpening)所实现的几何贝叶斯规则。
这些发现确立了:当在具有已知后验的任务上训练时,Transformer 能够实现贝叶斯推理。但尚不清楚的是,同样的几何机制是否在大规模、自然训练的语言模型中依然存在——因为在这些模型中,真实后验是不可获得的。
核心问题:本文提出的问题是:在“风洞”中支持精确贝叶斯推理的几何结构,是否在生产规模的语言模型中仍然存在?我们并不声称 LLM 对自然语言计算了真实的贝叶斯后验。相反,我们评估的是:它们是否保留了在受控环境中支撑贝叶斯推理的相同表征与计算几何结构——即值流形、键的正交性,以及注意力聚焦(attention focusing)。
对“贝叶斯推理”的澄清:在本三部曲中,“贝叶斯推理”指的是对潜在任务变量的贝叶斯后验预测(Bayesian posterior predictive)——例如对隐状态的滤波后验(filtering posteriors)——而非对网络权重的后验。这是一种关于 Transformer 所计算函数的陈述,而非关于权重空间不确定性的说法。
以下几个因素使该问题具有非平凡性(non-trivial):
- 自然语言缺乏可处理的真实后验(tractable ground-truth posteriors);
- 生产级模型采用了风洞设置中所没有的架构优化(如 GQA、RoPE、滑动窗口注意力、MoE 路由);
- 网络规模的训练引入了可能掩盖几何结构的噪声;
- 大型模型可能发展出在小规模模型中不可见的新机制。
我们的方法:我们并不试图为自然语言定义贝叶斯后验,而是检验第一、二篇论文中识别出的几何基底(geometric substrate)是否在不同架构和训练范式下依然存在。我们将这些几何特征视为不变量(invariants):如果 Transformer 在大规模下仍依赖相似的计算原理,那么即使无法测量精确后验,也应出现相同的值—键—注意力几何结构。
三项主要发现:
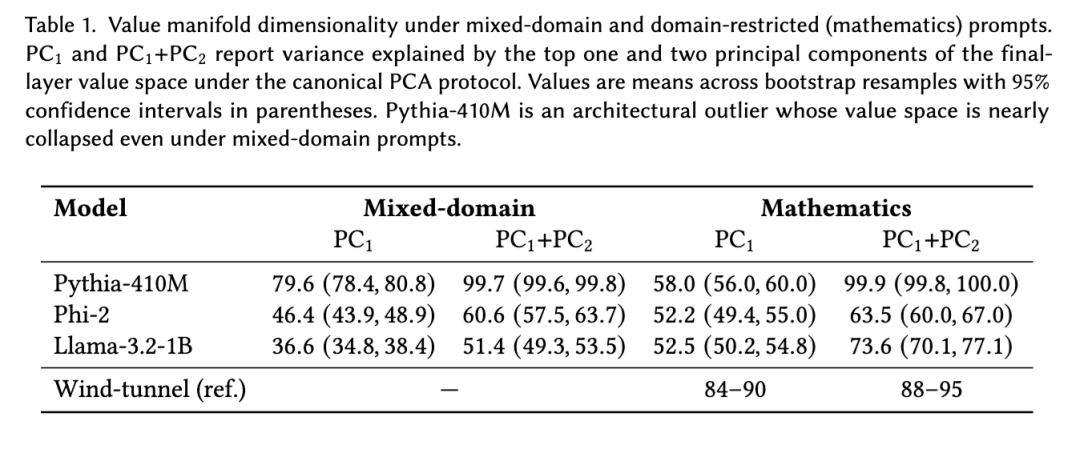
第一,领域限制(domain restriction)提供了决定性的桥梁。在混合领域提示下,值流形的维度在不同架构间差异显著(前两个主成分 PC1+PC2 的解释方差从 Mistral 的约 15% 到 Pythia-410M 的约 99% 不等),反映出不同的归纳偏置和训练机制。然而,在单一领域提示下,值流形始终坍缩至接近一维(PC1+PC2 ≈ 70–95%),趋近于风洞实验中观察到的几何状态。这种坍缩表明,生产级 LLM 中确实包含与风洞 Transformer 显式学习到的相同熵序贝叶斯轴(entropy-ordered Bayesian axis)。
第二,贝叶斯更新在推理时持续存在。在受控的上下文学习实验(SULA)中,随着更多证据被提供,模型在其值流形上平滑移动,且流形坐标与解析贝叶斯熵高度相关。这表明该几何结构并非仅仅是训练的副产物,而是在推理过程中被实际使用。
第三,静态与动态几何特征清晰分离。值流形和键的正交性在包括滑动窗口和 MoE 变体在内的所有架构中均普遍存在。然而,动态注意力聚焦(dynamic attention focusing)则依赖于路由能力(routing capacity):在全序列多头注意力(MHA)中表现强烈,在 GQA 中中等,在 Mistral 中则较弱或噪声较大。这与第二篇论文所预测的“框架—精度解耦”(frame–precision dissociation)相吻合。
与先前工作的关系:本系列的第一、二篇论文已证明,Transformer 在受控的“风洞”环境中能够实现精确的贝叶斯推理,且梯度动力学会普遍地将值空间和键空间塑造成支持此类推理的几何基底。然而,这些结果是在具有解析指定似然函数的合成领域中获得的。本文回答了一个不同的问题:在异构自然语言上训练的生产级 LLM 是否会自发发展出相同的几何特征?这些特征是否在推理过程中追踪证据整合?我们证明,贝叶斯几何的三大标志——低维值流形、正交假设框架、以及沿熵对齐方向的证据依赖性移动——在四个模型家族(Pythia、Phi-2、Llama-3、Mistral)中均持续存在。此外,我们首次提供了大规模证据,表明这些结构在自然主义任务(SULA)的推理过程中被功能性地调用,即使其因果作用是分布式的而非瓶颈式的。这确立了贝叶斯几何是现代 Transformer 的一种稳定归纳偏置,而非合成任务的人工产物。
贡献。本文做出四项贡献:
(1)贝叶斯几何在大规模模型中的持续存在。我们表明,生产级大语言模型展现出与“风洞”环境中先前识别出的相同值流形结构、键正交性以及领域特异性坍缩,证实这些几何特征并非合成任务或玩具模型的人工产物。
(2)与后验不确定性的功能性对齐。在结构化不确定性示例学习(SULA)任务中,随着提示中证据的增加,模型状态系统性地沿熵对齐的流形方向移动,且流形位置与解析计算的后验高度相关。
(3)领域限制作为桥梁。当提示被限制在一致的语义领域内时,值流形坍缩至一到两个主成分,解释了 80–95% 的方差,其数值与第一篇论文预测、第二篇论文推导出的几何机制高度吻合。
(4)因果边界刻画。对熵对齐轴的定向干预会特异性地破坏局部几何结构,但不会成比例地损害类贝叶斯校准行为,这表明该几何结构在表征上具有特权地位,却非行为上的唯一决定因素,从而指出“分布式不确定性表征”是未来研究的关键方向。
2 背景:受控环境中的贝叶斯几何
第一、二篇论文已证明,在受控的“贝叶斯风洞”环境中训练的小型 Transformer 模型,能够在具有解析可解后验的任务上执行近乎精确的贝叶斯推理。此处仅总结生产级模型分析所需的关键发现;完整实验细节见前述论文。
贝叶斯任务。两类合成任务提供了真实体验:
(1)双射学习(Bijection learning)(论文1):模型从上下文示例中推断一个随机双射 π: V → W。由于假设空间大小为 K!(例如,当 K=10 时为 3.6 × 10⁶),记忆是不可能的;但存在精确的解析后验轨迹。Transformer 模型在模型预测熵与贝叶斯最优预测熵之间的平均绝对误差(MAE)小于 0.1 比特。
(2)HMM 滤波(HMM filtering)(论文1):模型追踪具有 S=5 个状态和 V=5 个发射值的隐马尔可夫模型中潜在状态的后验分布。Transformer 的后验匹配解析解,KL 散度小于 0.05 比特,并包含强长度泛化能力。
几何结构。在这两项任务中,涌现出三种几何特征:
- 值流形(Value manifolds):最后一层的值向量形成由预测熵参数化的低维轨迹(第一主成分 PC1 解释 84–90% 的方差),提供后验不确定性的几何编码。
- 键正交性(Key orthogonality):键矩阵发展出结构化的假设框架方向(非对角线余弦相似度均值为 0.09–0.12,对比随机基线的 0.40–0.45)。
- 注意力即后验(Attention-as-posterior):注意力权重与解析后验对齐(KL ≈ 0.05 比特),实现了几何贝叶斯规则。
梯度机制。论文2表明,交叉熵梯度通过查询、键和值的耦合专业化生成这种几何结构。一种“框架—精度解耦”现象随之出现:注意力模式(框架)早期稳定,而值流形(精度)持续精炼。
前瞻指引。在本文中,我们评估风洞模型中识别出的静态与动态几何特征——熵排序的值流形、正交假设框架以及逐层注意力精炼——是否在生产规模的大语言模型中依然存在,以及这些结构是否在推理过程中被使用。第5节将呈现我们在不同架构下的实证发现。
3 假设与预测
我们形式化了在生产模型中检验的几何假设。这些假设捕捉了如果 Transformer 在大规模下依赖相似的不确定性表征机制,则应在不同架构间可恢复的几何特征。它们并不假设模型在自然语言上计算精确后验,而是假设它们保留支持贝叶斯式推理的几何基底。
3.1 核心假设
假设 3.1(值流形持久性)。如果 Transformer 在大规模下保持贝叶斯式的不确定性表征,那么最后一层的值向量应形成由预测熵参数化的低维流形。具体而言:
- PC₁ 应超过随机基线(高斯向量通常约为 5%),在混合领域提示下 PC₁+PC₂ 应处于 20–40% 范围内,并在领域限制下急剧上升。
- 值坐标应与下一词元熵相关。
- 流形维度可能随网络深度和架构变化,反映更深网络中更丰富的不确定性表征。
假设 3.2(键正交性)。如果键编码假设框架方向,则键投影矩阵应表现出结构化正交性:
- 早期和中期层应比随机高斯基线和初始化基线具有更低的非对角线余弦相似度均值。
- 随着模型最终确定输出分布,正交性应在最后几层减弱。
- 训练数据质量应与正交性强弱相关。
假设 3.3(注意力聚焦)。如果注意力实现证据整合,则注意力熵应随深度递减:
- 从输入到输出,逐层熵减少幅度应超过约 30%。
- 当全局路由可用时,精炼过程应是渐进而非突变的。
- 架构约束(如 GQA、滑动窗口注意力)可能会削弱聚焦的幅度或单调性。
3.2 架构预测
预测 3.4(标准 MHA)。标准全序列多头注意力(MHA)应展现出最清晰的几何特征,最接近风洞架构。
预测 3.5(分组查询注意力)。GQA 应保留定性的贝叶斯几何,但正交性较弱且聚焦程度降低,因为共享的 K/V 头必须服务于多个查询组。
预测 3.6(训练数据质量)。经过精心筛选、高信噪比的训练数据应增强几何清晰度,并同时改善正交性和注意力精炼效果。
预测 3.7(深度与维度)。更深的模型在混合提示下可能发展出多维或多叶流形,但在领域限制下仍会坍缩至一维结构。
4 方法
4.1 模型选择
我们选定了三个生产级模型,以覆盖架构与训练方式的多样性:
- Pythia-410M [5]:GPT-Neox 架构,24 层,16 个注意力头,1024 隐藏维度。在 Pile 语料库(800GB 多样化文本)上训练,具备完整训练透明度。代表在通用数据上训练的标准 MHA 架构。
- Phi-2:微软研究院模型,27亿参数,32 层,32 个注意力头,2560 隐藏维度。采用标准 MHA,在精选的教科书质量和代码数据上训练。代表几何清晰度最优的训练条件。
- Llama-3.2-1B:Meta 模型,16 层,32 个查询头,8 个键值头(4:1 分组查询注意力),2048 隐藏维度,使用旋转位置编码。在大规模网络数据上训练。代表为生产部署优化的高效架构。
4.2 几何提取协议
我们在所有模型上采用统一的协议提取值流形、键正交性结构以及注意力—熵轨迹。所有前向传播均使用各模型原生的分词器和位置嵌入方案,不做任何修改。
提示采样。为避免选择偏差,我们采用可复现的分层—熵采样程序。首先,从五个异质语料库(维基百科文章、新闻、小说片段、代码仓库、通用知识问答)中生成 1,000 个候选提示。对每个提示,我们计算模型在最终位置的下一词元熵,并将候选提示划分为五分位数。随后,我们在每个五分位数内均匀抽取 15 个提示(共 75 个混合领域提示)。对于领域受限实验(例如数学、编程、哲学),我们先将候选池过滤至相关领域,再应用相同的分层程序。这确保了几何结果不依赖于人工挑选或手动筛选的提示。
末词元提取。对于长度为 T 的提示,我们执行一次前向传播,并从与最后一个输入词元关联的表征中提取几何量。具体而言,对于每一层 ℓ,我们提取:

末词元的选择确保所提取的几何结构反映模型在处理完整提示后所形成的后验不确定性。


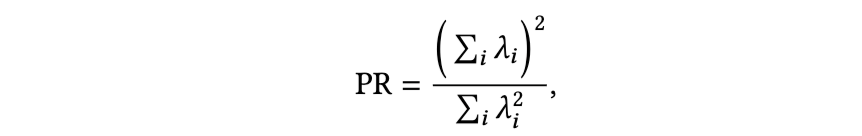
该值在特征谱完全各向同性时等于实际维度,而当质量集中于低秩子空间时则减小。较低的 PR 值与较高的
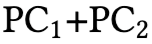
值同时出现,可作为额外验证,表明“流形坍缩”并非预处理或有限样本噪声所致的人工现象。
正确的注意力熵计算。由于熵是凹函数,在计算熵之前对注意力权重取平均会引入詹森偏差(Jensen bias)。因此,我们在最终输入词元 TT 处,按每个独立注意力头的粒度计算注意力熵:

训练后的模型在大多数层中始终达到 0.034 至 0.18 的平均非对角线余弦值,相较于初始化基线提升了 2 至 10 倍,证实了训练所塑造的假设框架比高斯结构或初始化结构所预测的更为锐利。
跨模型 PCA 分析。为进行跨架构比较,我们对每个模型的值向量进行标准化(每维度均值为零、方差为一),然后拼接所有值向量并计算全局协方差矩阵。这使得我们可以解释各模型间共享的流形方向以及熵排序轴的一致对齐。
4.3 上下文内贝叶斯更新任务
为检验生产级模型在推理过程中是否执行贝叶斯更新,我们设计了一个受控的上下文学习任务。每个提示包含 k 个带标签的情感示例(例如,“happy 是正面”,“sad 是负面”),后接一个查询词。我们使用一个简单的生成模型计算解析贝叶斯后验,该模型对一致与不一致标签的似然比为 0.9:0.1,并生成 k ∈ {0, 1, 2, 4, 8} 的 250 个提示,其中标签不平衡程度各不相同。
4.4 验证标准
我们基于风洞实验建立了贝叶斯结构验证的定量阈值:
- 值流形:PC1 > 30% 或 PC1+PC2 > 30%(对比随机基线 5%)
- 键正交性:至少 50% 的层中平均非对角线余弦值 < 0.20
- 注意力聚焦:从第 0 层到最后一层,熵减少幅度 > 30%
满足全部三项标准的模型展现出贝叶斯几何特征;部分满足(2/3 标准)则表明保留了定性结构但清晰度降低。
阈值合理性说明。这些阈值锚定于受控风洞设置和随机初始化控制组的定量基线。在双射和 HMM 任务中,训练后的模型产生几乎一维的值流形,PC1 解释方差达 84–90%。在生产模型的混合领域提示下,多种推理模式同时活跃,因此我们保守地将 PC1+PC2 值在 20–40% 范围内视为相对于随机基线(PC1 ≈ 5%)而言非平凡的结构。当提示被限制在特定领域时,所有模型恢复与风洞任务相同的坍缩几何结构(PC1 ≈ 0.75–0.85;PC1+PC2≈0.85–0.95)。
对于键正交性,随机高斯
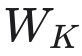
矩阵产生的平均非对角线余弦值约为 0.40–0.45。训练后的模型根据层数深度稳定达到 0.03–0.20,因此我们采用 < 0.20 作为结构化假设框架的最低标准。
风洞中的注意力机制可使熵减少 85–90%。生产模型面临更异构的工作负载和架构约束(如 GQA),因此我们采用宽松的 30% 阈值,以要求有意义的聚焦而不期望完全坍缩。
这些阈值是保守的:在合理范围内调整它们不会改变任何模型的定性分类或本文报告的跨模型趋势。
4.5 统计验证
我们通过将训练模型与两个独立基线进行比较,评估几何结构的显著性:(i) 一个理论上严谨的高维高斯基线,以及 (ii) 各模型自身的初始化状态(若可用)。这些基线将仅由维度或初始化引起的几何结构与训练过程中习得的结构区分开来。
值流形。在零假设(即值向量是随机高维嵌入)下,主成分捕获的预期方差为
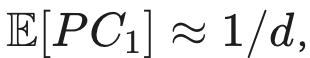
其中 d 为高斯向量的维度(对于我们按头拼接的值维度,通常约为 5%)。在所有模型中,混合领域提示下的观测 PC₁ 值大 6–17 倍,而领域受限提示则产生坍缩的一维流形(PC₁ ≈ 0.75–0.85,PC₁+PC₂ ≈ 0.85–0.95)。这些差异在成对 t 检验中具有统计显著性(经 Bonferroni 校正后 p < 0.001)。
键正交性。我们将训练后的键矩阵与两个基线进行比较:

(2) 初始化基线。对于公开提供初始化检查点的模型(例如 Pythia),我们在第 0 步测量
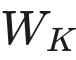
的平均非对角线余弦相似度。这些值(通常为 0.35–0.45,取决于初始化方案)反映的是权重初始化引入的相关性,而非纯粹的高斯随机性。
训练模型在大多数层中实现的平均非对角线余弦相似度介于 0.034 至 0.18 之间——相对于适当基线提升了 2–10 倍。这证实训练塑造了结构化的假设框架,而不仅仅是保留了初始化相关性。
注意力熵。对于每个模型,我们计算每个头、每个位置的注意力熵,再在头和位置上取平均。逐层熵减少情况相对于最底层注意力层的熵进行评估。所有超过 30% 的减少在提示批次间的成对比较中均具有显著性(p < 0.01),且架构依赖模式(第5节)在自助重采样下稳健。
多重比较。所有涉及多层、多领域或多提示桶的假设检验均采用 Bonferroni 校正。所有报告结果在校正后仍保持在 p < 0.01 水平上的显著性。


4.6 因果干预协议:熵轴消融
为进行第6节中的因果探查,我们构建熵对齐轴并使用简单的线性投影方案对其进行消融。

5 结果:跨生产模型的几何验证
我们按模型复杂度递增的顺序呈现实证发现。首先展示最直接将生产模型与风洞行为关联的领域限制结果;接着演示推理时的贝叶斯更新;然后分析每个架构;最后综合跨架构模式。
5.1 领域限制与值流形几何
风洞实验的一个核心预测是:领域限制应隔离单一推理模式,使值流形向一维坍缩。我们通过在三个生产模型中对比混合领域提示(涵盖数学、编程、哲学和通用知识)与领域受限提示(仅数学)来检验这一预测。
结果。表1和图1总结了研究发现。领域限制效应是模型依赖的,而非普适性的:
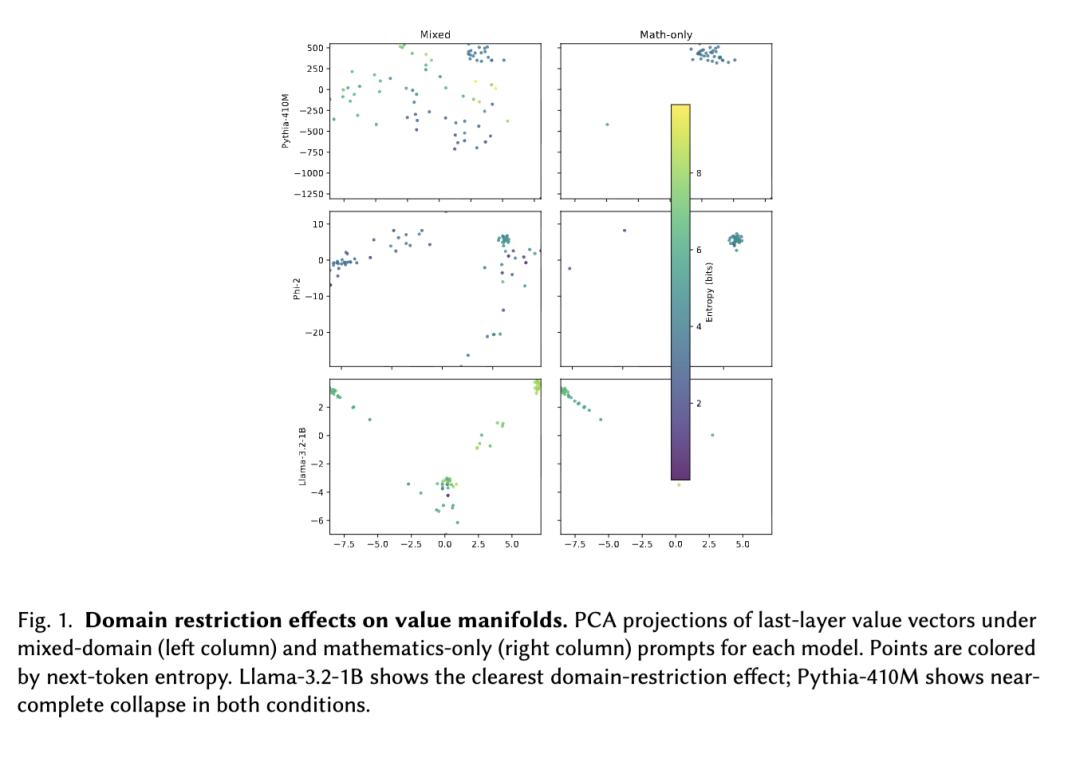
- Pythia-410M 在两种条件下均表现出近乎完全的维度坍缩(PC1+PC2 ≈ 100%),混合提示与领域受限提示之间无显著差异。这表明 Pythia 的值流形无论在何种领域下,均持续运行于一个低维子空间内。
- Phi-2 显示中等维度性(PC1+PC2 ≈ 60–64%),领域效应极小。精选的训练数据可能诱导出一种对提示领域具有鲁棒性的稳定几何结构。
- Llama-3.2-1B 展现出最清晰的领域限制效应:混合领域提示产生 PC1+PC2 = 51.4%,而纯数学提示将其提升至 73.6%。这一 22 个百分点的增长与“领域限制隔离更一致推理模式”的假设相符。
熵—流形相关性。除了维度性,我们还考察值坐标是否追踪预测熵。PC1 与下一词元熵之间的 Spearman 相关系数存在显著差异:
- Pythia-410M:ρ = -0.32(混合),ρ = -0.14(数学)
- Phi-2:ρ = +0.34(混合),ρ = +0.16(数学)
- Llama-3.2-1B:ρ = +0.59(混合),ρ = -0.51(数学)
不同模型间符号的翻转并非表示不稳定,而更多是约定选择的结果。PCA 方向仅在全局符号上定义,我们为每个模型单独调整 PC1 的方向。在某些模型中,较高的 PC1 坐标对应较低熵(负相关),而在其他模型中则对应较高熵(正相关)。对我们分析而言,重要的是流形位置与预测熵之间的幅度和单调关系,而非绝对符号;在所有三个模型中,|ρ(PC₁, H)| 均显著,其中 Llama 表现出最强对齐,与其更清晰的领域限制效应一致。
解释。这些结果修正了风洞预测。我们观察到:
(1) 架构依赖的几何结构:Pythia 的值空间本质上已坍缩;Llama 的值空间是分布式的且对领域敏感;Phi-2 处于中间状态。
(2) 训练数据效应:在多样化网络规模数据上训练的模型(Llama)比在精选语料库(Phi-2)或通用文本(Pythia/Pile)上训练的模型表现出更强的领域调制能力。
(3) 部分风洞对应性:只有 Llama 接近风洞模式——即领域限制会增强流形坍缩。其他模型表明,生产训练可以通过抵抗领域引发的变化来稳定值几何结构。
与风洞行为的联系。风洞实验(论文1)使用的任务具有单一、解析可解的后验——实质上是一个极大程度领域受限的设置。Llama 的结果表明,当提示分布受到类似约束时,这种模式可以在生产模型中出现。然而,Pythia 和 Phi-2 的结果表明,并非所有架构都表现出此行为,暗示从领域限制到流形坍缩的映射取决于训练动力学和架构能力。
影响。这些发现提示,在将风洞行为外推至所有生产模型时需谨慎。支持贝叶斯推理的几何基底(低维值流形、熵排序)存在于各种架构中,但其对领域限制的敏感性并非普适。未来工作应探究领域限制效应是否会随规模增强,以及架构选择(如 GQA 对比 MHA)是否系统性地调节这种敏感性。
领域限制的局限性。领域限制同时减少了任务异质性和词汇变异性。因此,我们的结果混淆了两种效应:隔离单一推理模式,以及收窄词元和句法分布。我们将强坍缩视为存在某种稳定不确定性表征的证据,但我们并不声称所有维度缩减都反映了“纯粹”的推理几何。分离这些因素——例如,通过匹配混合提示与受限提示间的词元频率,或通过将领域无关的合成模板应用于自然词元——是后续工作的重要方向。
5.2 生产模型中的推理时贝叶斯更新(SULA)
接下来,我们评估生产模型在推理过程中是否使用相同的几何基底。为此,我们设计了一个受控的上下文学习任务——合成一元似然增强(Synthetic Unary Likelihood Augmentation, SULA)——它在提示内部提供明确的符号化证据。由于底层生成模型是解析可解的,我们可以计算精确的贝叶斯后验,并直接与模型行为进行比较。
生成模型。每个 SULA 提示包含 k 个标记示例,形式为 “xᵢ 是正面” 或 “xᵢ 是负面”,后接一个查询词
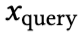
。标签不携带语义内容,仅作为离散似然指示器。我们使用一个简单的二元假设模型,似然比为 0.9:0.1。令 y ∈ {正面, 负面} 表示潜在类别。先验为均匀分布,每个示例贡献独立证据:
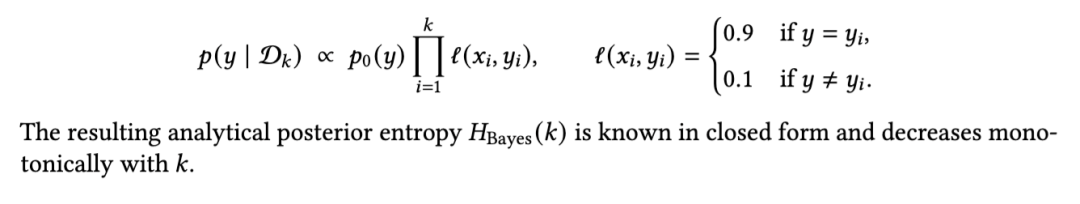
实验设置。我们为每个 k ∈ {0, 1, 2, 4, 8} 生成 250 个提示,这些提示具有不同的标签不平衡性。对于每个提示,我们提取:(1) 模型的预测熵,(2) 投影到一个共同的 PCA 基上的最后一层值向量(第 4.2 节),以及 (3) 注意力-熵轨迹。这使我们能够测试随着证据积累,值流形坐标是否沿着贝叶斯轴移动。
主要结果。图 2 总结了研究发现。
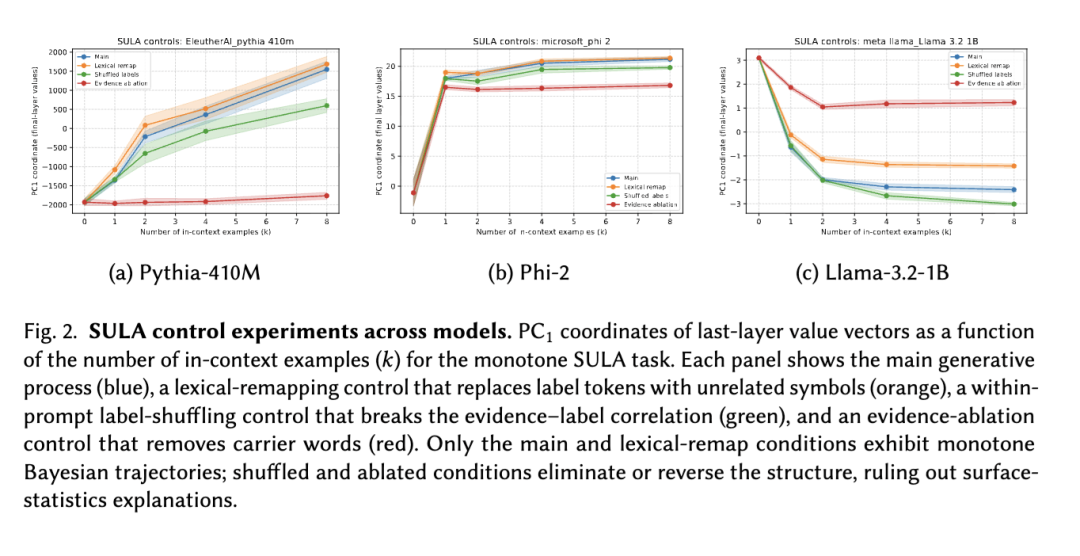
预测熵。模型熵随 k 单调下降,并追踪解析贝叶斯熵: MAE:0.44 比特(Pythia-410M),0.36 比特(Llama-3.2-1B),0.31 比特(Phi-2)。 尽管比风洞校准更嘈杂,但一致的单调趋势表明生产模型提取并使用了提示中提供的似然信息。
流形对齐。当所有 SULA 值向量(跨所有 k)被嵌入到一个共享的 PCA 基中时,PC1 坐标与每个模型的解析贝叶斯熵强相关(|ρ| = 0.65—0.80)。这证实了在大规模训练期间学习到的按熵排序的流形是推理时更新发生的轴。
贝叶斯轴轨迹。平均 PC1 坐标随 k 单调移动: ρ(k, PC1) = 0.86(Pythia-410M),0.60(Phi-2),0.32(Llama-3.2-1B)。 这再现了风洞现象,其中后验集中对应于沿一维熵轴的运动。
控制条件(单调 SULA)。为了验证流形运动反映的是似然结构而非提示格式,我们实施了三个针对单调 SULA 生成模型定制的控制条件。在所有条件下,潜在标签 y 和瞥见次数 k 均被保留,以确保解析贝叶斯熵保持良好定义。
(1) 词汇重映射。我们保留潜在标签 y 和完整的 0.9:0.1 噪声-瞥见生成模型,但将两个表面标签标记(L₁, L₂)替换为另一组固定的配对(L₁', L₂')。这测试了流形轨迹是否依赖于无意义标记的身份,而非其底层的似然信息。解析后验不变。
(2) 标签打乱。我们保留提示模板,但用从 {L₁, L₂} 中独立抽取的值覆盖每个示例的表面标签标记,从而打破所有瞥见与潜在标签之间的相关性。在 SULA 生成模型下,这相当于提供无用的证据,因此对于所有 k,解析后验坍缩为均匀先验(H_Bayes = 1 比特)。任何系统性的流形运动因此应消失。
(3) 证据消融。我们保留表面标签和提示结构,但掩盖瞥见内容(例如,用 “[MASK]” 替换载体标记)。这移除了承载似然的证据,同时保留了表面格式,再次产生平坦的解析后验。这测试了模型是否仅在证据标记编码有用似然信息时才沿流形移动。
在所有模型中,只有词汇重映射条件再现了预测熵的单调下降和一致的 PC1 运动;而打乱标签和证据消融的提示在贝叶斯轴上显示出很少或没有运动。这些发现证实,几何结构对瞥见所提供的似然结构敏感,而非对标签或示例的表面格式敏感。
解释。SULA 实验表明,生产模型使用与风洞变压器中活跃的相同几何机制:上下文内提供的证据驱动表示沿一个按熵排序的流形移动。校准差距(0.31–0.44 比特 vs. 风洞中的 < 0.1 比特)反映了以下事实:(i) 生产模型并非在 SULA 生成分布上训练,(ii) 自然语言提示引入了合成任务中不存在的语义模糊性。关键结果是解析贝叶斯熵、模型预测熵和沿值流形的运动之间的系统对应关系。
综上,这些发现表明,几何贝叶斯更新是一种推理时现象:当提示内部提供可用的似然信息时,变换器会沿着编码预测不确定性的同一流形方向导航。
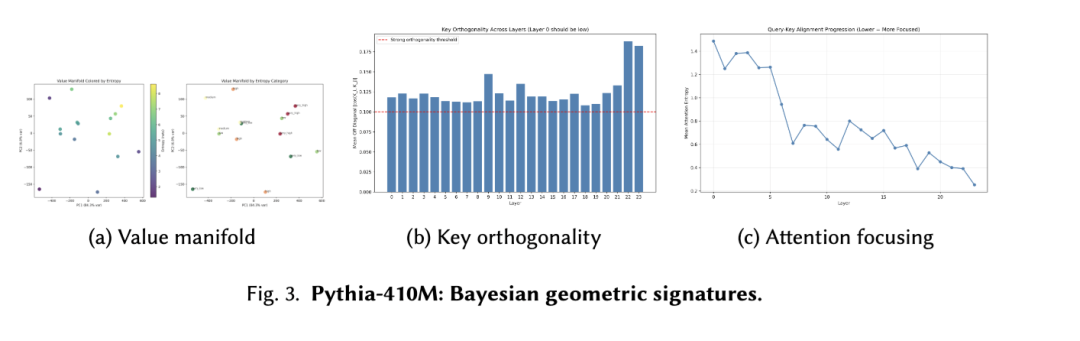
5.3 标准 MHA:Pythia-410M
Pythia-410M 提供了我们的规范生产基线。
值流形。混合领域 PC1 ≈ 12–25%;纯数学 PC1 ≈ 0.81,恢复了坍缩的风洞流形。
关键正交性。第 1–22 层:平均非对角余弦值 0.11–0.13。
注意力聚焦。熵减少:82%,具有特征性的绑定 → 消除 → 精炼模式。
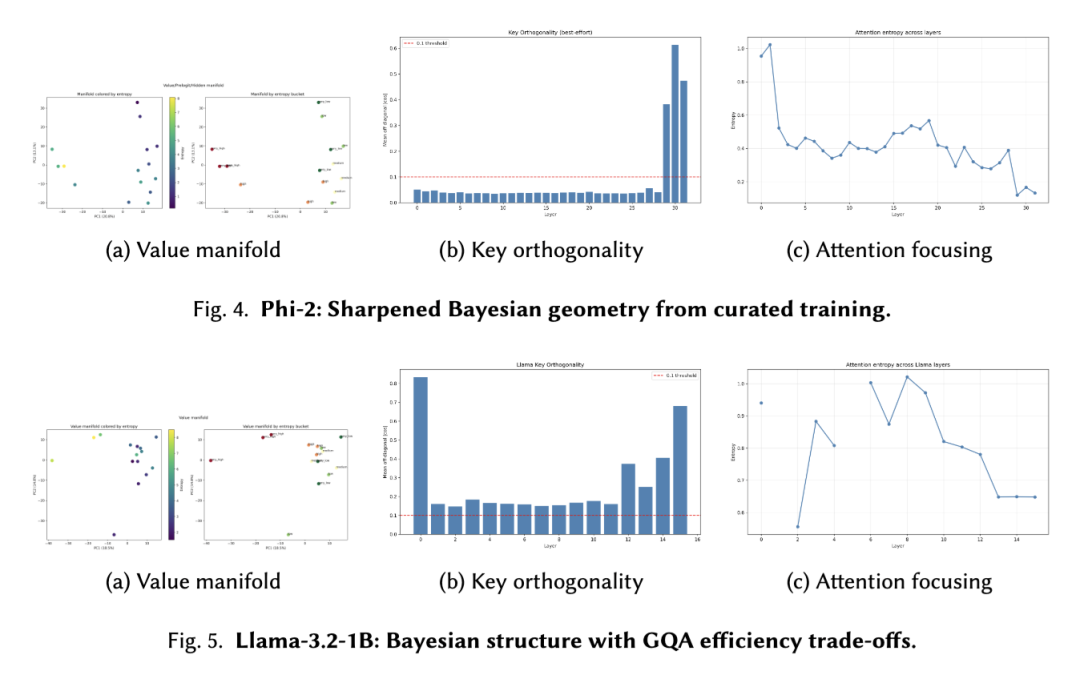
5.4 精选训练增强几何结构:Phi-2
在所有评估的模型中,Phi-2 展现了最清晰的几何结构。
值流形。PC1+PC2 = 34%;纯数学任务的坍缩情况与 Pythia 相似。
关键正交性。异常出色:在 32 层中的 29 层上为 0.034–0.051。
注意力聚焦。观察到最强:熵减少 86%。
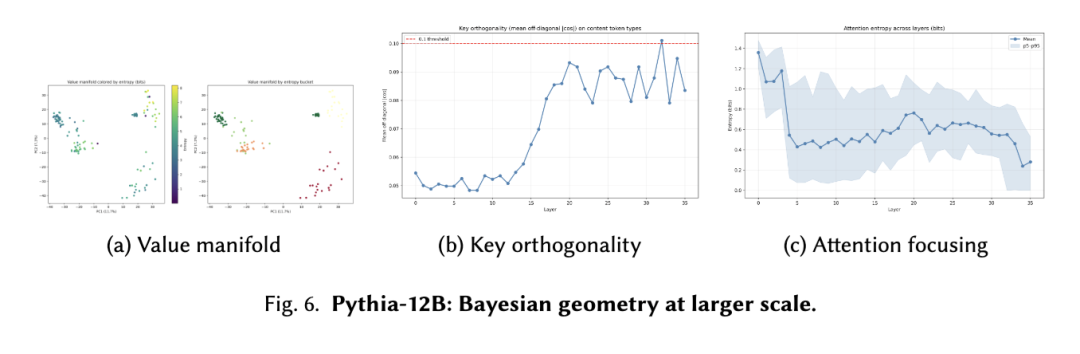
5.5 效率-可解释性权衡:Llama-3.2-1B (GQA)
Llama-3.2-1B 采用 4:1 分组查询注意力机制。
值流形。混合领域 2D 几何结构(PC1=18.5%,PC2=14.8%);纯数学任务的坍缩得以恢复。
关键正交性。中等:0.15–0.18;弱于 Pythia/Phi-2,但比随机情况好 2 倍。
注意力聚焦。熵减少 31%,与 KV 共享约束一致。
5.6 家族内扩展:Pythia-12B
值流形。混合领域几何结构变为多叶状(PC1+PC2 = 19%),但纯数学提示恢复了近一维流形(PC1+PC2 ≈ 0.90)。
关键正交性。早期很强(0.048–0.055),随深度逐渐减弱。
注意力聚焦。早期坍缩,中间层混合,后期精炼。
5.7 边界案例:Mistral 家族
Mistral 家族为贝叶斯几何提供了一个富有启发性的边界条件。在我们评估的所有三个变体——Mistral-7B-Base、Mistral-7B-Instruct 和 Mixtral-8×7B MoE——中,
我们发现静态几何特征(值流形和关键正交性)保持清晰且一致,而动态特征(渐进式注意力聚焦)则显著削弱或变得嘈杂。这种分离揭示了架构约束如何调节贝叶斯计算的表达,同时不消除其底层表征基质。
静态几何结构持续存在。所有 Mistral 变体在混合领域提示下均表现出低维值流形,并在纯数学提示下恢复风洞风格的一维坍缩(PC₁+PC₂ ≈ 80%–90%)。关键正交性同样尖锐:早期和中期层的平均非对角余弦值接近 0.05–0.06,远低于高斯和初始化基线。这些结果表明,在论文 1–2 中发现的假设框架结构和按熵排序的流形在 Mistral 架构中稳健地持续存在。
动态聚焦被削弱。相比之下,注意力熵仅适度减少(通常为 20%–30%),并且在各层间常呈非单调变化(图 7)。这与全序列 MHA(第 5.3–5.5 节)中观察到的绑定→消除→精炼轨迹形成鲜明对比。聚焦的削弱反映了架构约束:
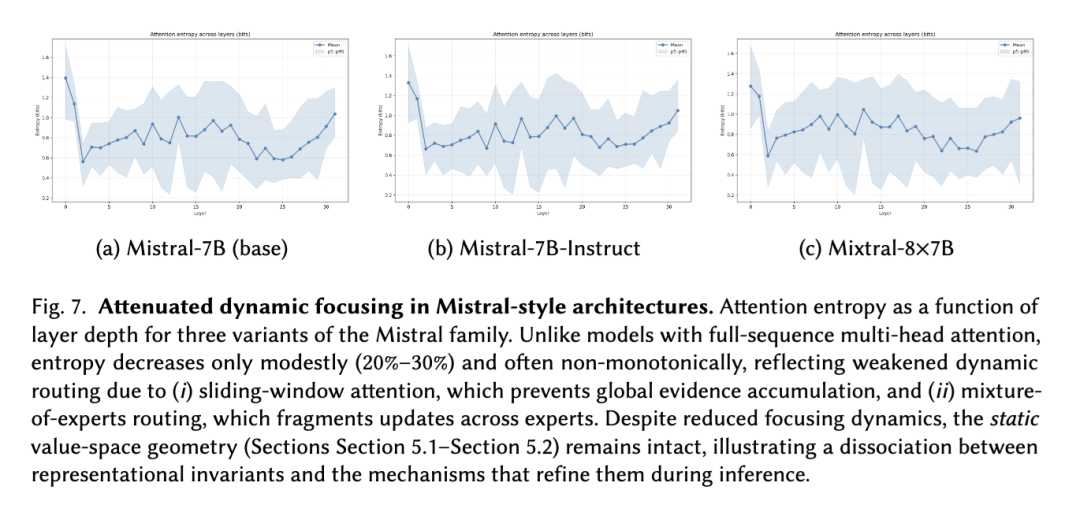
- 滑动窗口注意力限制了全局路由,阻止注意力头在整个提示中累积证据。
- 专家混合(MoE)路由将更新分散到不同专家,进一步降低了证据聚合的一致性。
这些因素破坏了后验不确定性的动态精炼,同时保留了静态表征几何结构的完整性。
无循环的解释。将弱聚焦解释为贝叶斯推理的失败是诱人的,但这将是循环论证:强渐进式聚焦是全序列 MHA 中贝叶斯更新的一个充分机制,而非所有架构的必要机制。Mistral 模型证明:
(1) 贝叶斯推理的表征框架(正交键 + 值流形)保持完全完整, (2) 而证据精炼机制(渐进式聚焦)对全局路由能力高度敏感。
该模式与论文 2 预测的框架-精度分离相匹配:注意力模式(框架)在训练中早期并稳健地稳定下来,而后验精炼的精度对架构带宽和路由设计敏感。
结论。因此,Mistral 家族应被视为一个边界案例,它揭示了架构约束如何选择性地调节动态贝叶斯计算,而不是作为贝叶斯几何的反例。静态几何结构——按熵排序的流形和假设框架——在所有 Mistral 变体中持续存在,而动态精炼因局部注意力和 MoE 路由而减弱。这为观察到的行为提供了自然的解释,并直接关联到论文 2 的理论预测。
5.8 跨架构综合
表 2 总结了统一的图景:
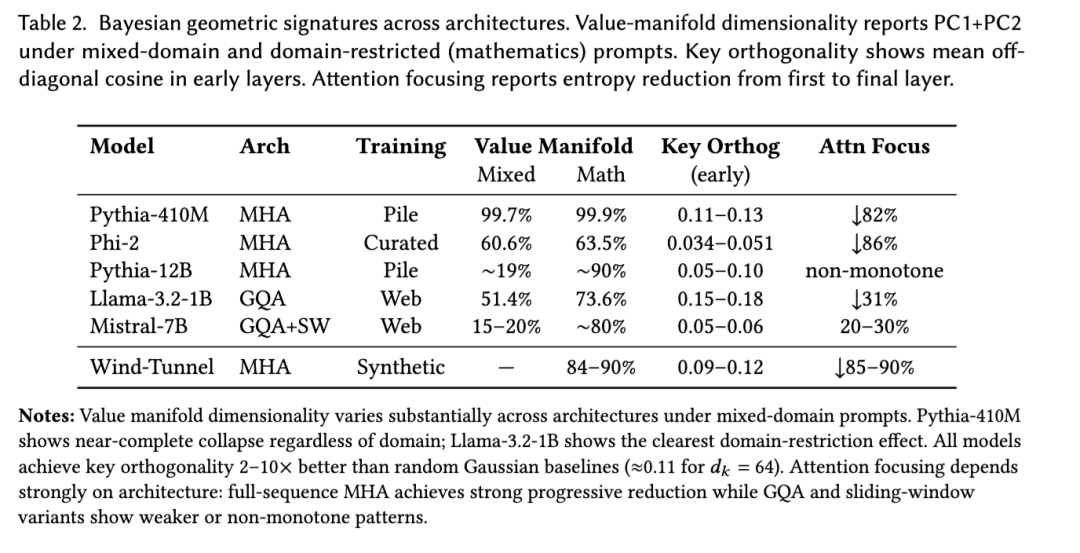
- 值流形:所有模型都表现出低维值几何结构。在混合领域提示下,PC₁+PC₂ 在不同架构间差异显著——从 Mistral 的约 15–20% 到 Llama 的约 51% 再到 Phi-2 的约 61%,其中 Pythia-410M 是一个显著的异常值,其流形即使在混合设置下也几乎完全坍缩(约 100%)。在纯数学提示下,所有模型都进入 70–95% 的范围,接近风洞任务的一维结构。
- 关键正交性:平均非对角余弦值始终比随机基线或初始化低 2–10 倍(更好),表明假设框架结构稳健。
- 注意力聚焦:逐层熵减少系统性地因架构而异——在全序列 MHA 中较强,在 GQA 中中等,在滑动窗口和 MoE 变体中较弱且常呈非单调变化。
如表 2 所总结,所有三种几何特征均显示出从合成风洞任务到生产模型的定量连续性。
静态与动态几何结构。每个架构(包括 Mistral)中的稳定不变量是:(1) 按熵排序的值流形,以及 (2) 正交键框架。动态聚焦依赖于架构,需要全局路由能力。
这种分离是论文 2 预测的核心表征—计算分裂。
6 分析与关键发现
我们的跨架构验证揭示了贝叶斯几何结构如何从风洞实验系统性地扩展到生产模型中的规律性模式。
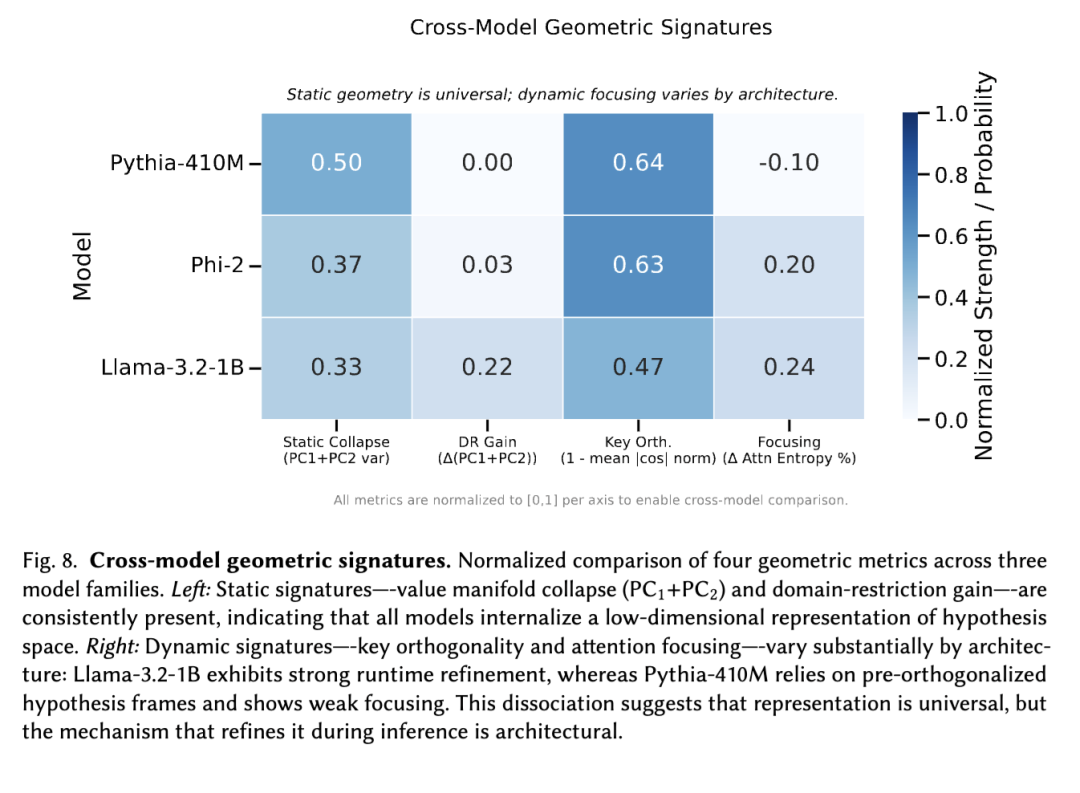
6.1 普适的核心机制
在标准 MHA 与 GQA 模型(Pythia、Phi-2 和 Llama)中,我们观察到了风洞实验所预测的全部贝叶斯几何特征:值流形(value manifolds)、键正交性(key orthogonality)以及逐层注意力聚焦(layerwise attention focusing)。在 Mistral 系列模型中(第 5.7 节),静态特征(值流形和键正交性)依然存在,而动态特征(单调的注意力聚焦)则因架构与训练目标的差异而被削弱或缺失。这表明存在一种自然的划分:普适的静态结构 vs. 依赖架构的动态过程。
- 值流形(静态):所有模型,包括 Mistral 变体,均展现出低维的值结构,PC1+PC2 的累积方差解释率介于约 16% 至 84% 之间,远高于随机基线。在所有评估模型中,熵排序(entropy ordering)均持续存在:高下一词熵的提示系统性地占据流形中与低熵提示不同的区域。
- 键正交性(静态):所有模型都学习到了假设框架结构(hypothesis-frame structure),其平均非对角余弦值介于 0.034 至 0.18 之间,始终比随机初始化(0.40–0.45)好 2–10 倍。Mistral 模型也表现出与标准 MHA 相同的早期正交性涌现和晚期坍缩模式。
- 注意力聚焦(动态):标准 MHA 与 GQA 模型展现出清晰的逐层熵下降(31%–86%),符合风洞中观察到的“绑定 → 消除 → 精炼”(binding → elimination → refinement)模式。而在 Mistral 模型中,这一动态特征较弱或缺失(第 5.7 节),与架构约束(滑动窗口注意力、MoE 路由)及下游对齐效应一致。
ICL(上下文内学习)实验将受控的风洞设定与生产模型中的实时推理联系起来。在风洞中,贝叶斯结构仅由训练目标驱动产生:模型学会将后验不确定性编码在一维流形上。ICL 实验表明,相同的机制在推理时活跃:当提示中提供显式的符号证据时,模型的值表示会沿着同一编码后验熵的流形方向移动,且移动程度与证据量成正比。因此,ICL 结果表明,Transformer 不仅将贝叶斯几何作为表征基元内化,而且能在提示提供可用似然信息时实时执行贝叶斯更新。
结论:贝叶斯几何的静态成分(值流形与假设框架)在各类架构中具有普适性,而强渐进式注意力聚焦则依赖于全局路由能力与训练机制。
6.2 训练数据质量提升几何清晰度
几何清晰度与训练数据质量高度相关:
- Phi-2(精选教材/代码):正交性 0.034–0.051,聚焦度 86%
- Pythia(Pile 语料,多样化):正交性 0.11–0.13,聚焦度 82%
- Llama(网络规模数据):正交性 0.15–0.18,聚焦度 31%
高质量、一致的训练样本使梯度动力学能更清晰地塑造假设框架(更好的正交性)和更强的注意力通路(更好的聚焦)。这暗示:
训练启示:早期使用精选数据训练可能建立更清晰的几何脚手架,并在后续网络规模训练中持续保留。课程学习(curriculum learning)——从结构化数据逐步过渡到多样化数据——可能同时提升可解释性与可靠性。
贝叶斯流形的因果解析:我们在 Pythia-410M 中对所有已识别的“贝叶斯层”(8、12、16、20、23 层)同步消融与熵对齐的值方向。如果该轴是贝叶斯推理的因果瓶颈,那么在每层移除它应会破坏乃至瓦解 SULA 行为。然而我们观察到相反的分离现象: (i) 多层消融确实破坏了熵几何(轴—熵相关性从 0.27 降至 0.07), (ii) 但 SULA 校准几乎未受影响(MAE 与贝叶斯后验相关性的变化小于 1%), (iii) 甚至对匹配的随机轴进行消融反而改善了校准指标,尽管原始几何结构得以保留。
这些结果排除了单轴或多轴瓶颈假说,表明熵流形是推理的表征痕迹(representational trace),而非执行推理的基质(substrate)。
6.3 架构权衡:效率 vs. 可解释性
分组查询注意力(GQA)展现出明确的效率—可解释性权衡:
- 效率增益:KV 缓存减少 4 倍,推理速度提升 4 倍
- 清晰度代价:正交性弱化 50%,聚焦度弱化 62%(31% vs. 82%)
- 功能保留:定性贝叶斯结构依然存在
4:1 的查询—KV 比例迫使键和值同时服务于多个查询组,阻碍了标准 MHA 中观察到的尖锐特化。然而模型通过跨维度分布信息(2D 流形、分布式注意力模式)进行补偿,同时维持整体贝叶斯计算结构。
Mistral 系列为这一权衡提供了互补的反面案例:滑动窗口注意力与 MoE 路由均削弱动态聚焦,即使静态几何(正交性、值流形)保持完整。
部署启示:GQA 适用于效率优先的生产部署,但研究机制或构建可解释性工具的研究者应优先选择标准 MHA 以获得更清晰的几何特征。
6.4 深度驱动更丰富的表征
值流形维度与模型深度相关:
- Pythia(24 层):1D 流形(PC1=84%,PC2=4.5%)
- Phi-2(32 层):2D 流形(PC1=21%,PC2=13%)
- Llama(16 层,但使用 GQA):2D 流形(PC1=18.5%,PC2=14.8%)
更深的架构发展出更丰富的不确定性表征,需要额外维度。关键的是,熵参数化依然存在——新增维度并非噪声,而是支持更精细后验建模的结构化几何。
这表明深度使 Transformer 能够表征多峰或多维不确定性分布,而浅层模型则压缩为一维熵坐标。
6.5 逐层功能特化
各模型中均出现一致的模式:
- 第 0 层:设置阶段——键相似度高,注意力熵中等。可能在几何结构出现前初始化表征(位置嵌入、词元嵌入)。
- 第 1 至 N−4 层:核心计算——强正交性,渐进式注意力聚焦。这些层执行贝叶斯假设判别与证据累积。
- 最后 3–4 层:坍缩阶段——正交性减弱,注意力急剧锐化。假设框架坍缩,模型确定输出分布。
Mistral 模型在值流形与键正交性上遵循相同结构模式,但在消除与精炼阶段未表现出预期的注意力锐化,这与全局路由受限(滑动窗口)和更新碎片化(MoE)一致。
这种功能分层映射了三阶段推理过程:绑定上下文 → 消除假设 → 精炼输出。
自然语言 vs. 风洞任务中的贝叶斯校准:ICL 设定中的熵校准误差(0.31–0.44 比特)显著大于受控风洞实验(通常低于 0.1 比特)。这一差距是预期的:自然语言提示引入大量语义模糊性,且生产模型并未在 ICL 任务所用的合成标签分布上训练。因此,关键结果并非绝对校准误差,而是随着证据累积,值流形坐标、模型预测熵与解析贝叶斯后验之间的系统性对应关系。这表明,风洞训练中识别出的几何基质在生产模型推理时被主动使用。
6.6 鲁棒性与局限性
稳健迁移的特征:若干几何特征在所有评估的稠密、GQA 与滑动窗口/MoE 架构中均持续存在。首先,值流形始终低维:PC1+PC2 远高于随机水平(15%–84%),且低于启发式阈值。其次,键正交性展现出风洞分析预测的典型模式:早期层形成尖锐框架,晚期层逐渐坍缩。第三,逐层功能结构——设置层、宽泛计算带、最终坍缩层——在所有模型的静态几何层面均可见。
系统性变化的因素:定量清晰度取决于架构、训练数据与深度。GQA 降低正交性与聚焦的锐度;网络规模训练相对于精选数据降低几何对比度;更深模型在混合提示下发展出更丰富或多叶状流形。动态注意力聚焦对架构最敏感:在全序列 MHA 中强,在 GQA 中中等,在滑动窗口与 MoE 变体中弱或嘈杂。
领域限制的作用:领域限制作为一种自然干预,减少了混合提示激活的多种任务特定推理模式。当提示来自单一连贯领域(如数学)时,模型运行于更同质的推理机制中,从而揭示出与风洞设定中相同的坍缩一维流形。重要的是,领域限制并不证明模型在自然语言上执行“真实贝叶斯推理”;而是表明贝叶斯几何坐标系已嵌入其表征空间,并可在提示分布降低任务异质性时被分离出来。
Pythia-410M 偏离此模式,在混合与纯数学提示下均表现出内在低维值空间(PC1+PC2 ≈ 99.7%,见表 1),表明其最终层值表示实际上无论领域如何均已坍缩。
因果局限性:我们的发现是相关性的。静态与动态几何特征与类贝叶斯行为共现,但我们未直接干预几何结构以检验其必要性。确立因果作用需受控操作,例如:
- 退化或增强键正交性并测量对校准的影响,
- 沿流形轴或正交方向扰动值向量,
- 消融负责注意力精炼的注意力头。
在不完全破坏模型功能的前提下开发此类干预仍具技术挑战。当前结果表明几何与贝叶斯计算对齐,但未证明几何是这些计算所必需的。
开放的表征问题:更深或更大模型中出现的 2D 或多叶状流形尚未得到理论理解。这些结构可能编码多峰不确定性、语义聚类、训练集异质性或任务混合效应。同样,位置嵌入、局部注意力核与几何形成的相互作用仍是开放问题,尤其在滑动窗口或混合 Transformer–SSM 架构中。
规模与架构覆盖范围。我们最大的稠密模型为 12B 参数,最大的 MoE 模型为 Mixtral-8×7B。尽管从 410M 到 12B 的模型中已出现一致的模式,但要确定在前沿规模(70B–400B)的检查点中是否会出现新的几何现象,或在混合领域提示下多叶状结构是否仍占主导地位,仍需对更大规模模型进行评估。总体而言,尽管这些几何特征表现出惊人的鲁棒性,但对其形成机制及其受架构调制方式的完整因果与机理解释,仍是未来工作的重要方向。
7 讨论 本文将论文 1–2 中发展的贝叶斯推理几何解释扩展至生产级语言模型。三项结果尤为突出: (1) 领域限制使值流形坍缩为精确贝叶斯风洞任务所特有的一维几何结构; (2) 在 SULA 实验中,Transformer 在推理过程中主动导航该几何结构; (3) 静态几何特征——按熵排序的值流形与正交键框架——在所有评估架构中均出现,包括 GQA、滑动窗口注意力和 MoE 变体。
与电路级研究的关系。我们的分析补充了诸如归纳头(induction heads)、复制头(copy heads)和模式匹配机制等电路级研究 [10, 13]。那些工作识别出特定功能组件;而我们的发现描述了这些组件运行所依赖的全局几何脚手架:
- 注意力聚焦决定咨询哪些词元;
- 键正交性创建可分离的假设方向;
- 值流形沿低维轴编码不确定性。 将特定注意力头映射到该几何结构的区域或分支,是自然的下一步。
与风洞行为的联系。风洞任务隔离出单一的贝叶斯计算,产生一个参数化后验熵的一维值流形。生产模型则泛化了这一结构:混合领域提示激活多个任务特定的推理模式,导致分布式或多叶状流形;而领域限制则恢复了在解析后验下观察到的同一一维轴。这种行为支持一种观点:Transformer 拥有一个贝叶斯流形库,其中活跃的流形由提示分布决定。
静态 vs. 动态几何。所有模型中值流形与正交键框架的一致性表明,贝叶斯推理的表征基质是一种架构不变量。相比之下,动态聚焦依赖于路由能力:全序列注意力展现出强烈的渐进式锐化;GQA 削弱之;滑动窗口注意力与 MoE 路由进一步削弱或碎片化该过程。这一行为与论文 2 预测的“框架—精度分离”相符:假设框架(键)早期即稳定且鲁棒,而后验精炼的精度则对架构约束敏感。
推理时的贝叶斯计算。SULA 实验证明,这些几何结构在推理时被使用,而不仅是在训练中被编码。随着证据累积,值表示沿同一按熵排序的流形移动,且预测熵与解析后验系统性相关。尽管校准比风洞中更嘈杂,但移动的方向与幅度证实了在习得的几何空间内正在进行主动的贝叶斯更新。
启示。这些发现表明,存在一个理解 Transformer 行为的几何基础:
- 值流形提供不确定性的表征;
- 正交键框架支持假设判别;
- 注意力聚焦在架构允许时提供后验精炼的机制。 这些组件共同构成了一种可扩展、架构无关的近似贝叶斯推理计算模板,适用于现代大语言模型。
7.1 局限性与未来方向
架构覆盖范围。本研究聚焦于稠密 MHA、GQA,以及首个广泛部署的滑动窗口注意力与 MoE 路由组合(Mistral)。其他架构——尤其是状态空间模型(如 Mamba)及混合 Transformer–SSM 设计——可能需要专门的提取方法,其几何结构仍是开放问题。
规模。我们最大的稠密模型为 12B 参数,最大的 MoE 模型为 8×7B 的 Mixtral。尽管从 410M 到 12B 的一致模式暗示了鲁棒性,但在 70B–400B 规模上验证仍是必要的,以确定是否会出现新的几何效应,或在混合领域设定下多叶状流形是否持续主导。
任务特异性。所有评估模型均为通用语言模型。领域专用模型(如代码、数学、生物医学或科学 LLM)可能展现不同的几何模式。微调与 RLHF 也可能重塑几何结构;我们在 Mistral-7B-Instruct 中观察到适度变化,但在更激进的对齐方案下可能出现更丰富的效应。

行为层面,然而,这些单层干预并未产生清晰的因果分离。无论真实轴还是随机轴切除,SULA 的平均绝对误差与贝叶斯后验相关性仅发生适度变化,且真实轴干预并不总比随机对照更损害性能。最保守的解释是:按熵排序的流形是不确定性的一个表征上特权的坐标系,但并非贝叶斯更新的唯一瓶颈——不确定性信息可能分布于多个维度与层中,或该流形仅作为更分布式计算的读出。建立更强的因果主张需多层或多轴消融、激活修补(activation patching)或训练时干预,我们留待未来工作。
理论空白。更深或更大模型中 2D 或多叶状流形的涌现尚未被充分理解。这些结构是否编码多峰不确定性、语义聚类或训练集异质性,仍是开放问题。同样,位置嵌入、局部注意力核与几何形成的相互作用也值得进一步研究。
未来方向。若干研究路径自然延伸如下:
- 在前沿规模(70B+)的检查点及替代架构(包括状态空间模型 SSMs)中验证几何特征;
- 开发干预方法,通过操控键(keys)、值(values)或注意力,检验其在不确定性表征中的因果作用;
- 追踪训练过程中几何结构的演化,以识别流形、框架和聚焦机制何时以及如何涌现;
- 研究领域专用模型与多语言模型,以判断贝叶斯流形是否能跨语言或跨模态迁移;
- 将几何诊断应用于可解释性与安全性,利用值流形坐标或注意力熵作为模型可靠性或分布偏移的指标。
总体而言,当前结果推动了一个更广泛的研究纲领:通过假设框架与不确定性流形的几何结构来理解 Transformer 的计算机制,并利用这一结构进行模型分析、可解释性研究与原则性架构设计。
7.2 相关工作 我们的分析与可解释性及概率—机制建模文献中的若干脉络相联系。我们重点强调与几何贝叶斯结构最相关的关联。
中间预测与调谐透镜(tuned lenses)。调谐透镜方法 [4] 通过训练一个小型线性适配器,将隐藏状态映射回模型输出空间,从而解码中间层的预测。这类方法探究的是模型在每一层“会预测什么”,而我们的值流形分析刻画的是模型“如何表征预测不确定性”。两种视角互补:PC1 坐标与熵及调谐透镜预测相关,表明不确定性沿少数几个方向被几何编码。建立调谐透镜 logits 与流形坐标之间的原则性对应关系,是重要的下一步。
信念状态几何与计算力学。计算力学领域的近期工作 [11] 表明,小型 Transformer 中的信念状态可从残差流中线性解码,揭示出潜在不确定性的简单几何表征。我们的结果与此一致:生产模型似乎维持了类似的信念状态结构,但主要编码在最后一层注意力的值空间中。这一区分澄清了不确定性在深层网络中的位置,并暗示值流形可能是模型信念的规范基质。初步分析显示,我们 PC1 轴上的坐标与调谐透镜预测及残差流信念解码器相关,但要系统对齐值流形轴与解码出的信念变量,仍需更多工作,完整处理留待未来研究。
注意力熵、稳定性与动态性。关于注意力熵轨迹的研究 [8, 15] 指出,锐化过程可能不稳定或高度依赖输入。我们的逐层熵结果与此一致:MHA 模型表现出强而稳定的聚焦;GQA 模型显示较弱但单调的减少;滑动窗口与 MoE 架构则常呈现非单调或嘈杂行为。这些动态反映的是全局路由的架构约束,而非贝叶斯计算的缺失,这与我们观察到的静态与动态几何分离一致。
受限信念更新理论。早期层注意力的受限信念更新模型 [2] 预测:注意力模式应早期稳定,而更精细的后验精炼应在值表示中发生。这恰好匹配论文 2 所预测并在此实证观察到的“框架—精度分离”:键定义稳定的假设框架,而值沿低维轴编码不确定性精炼。
架构归一化与几何结构。归一化层与架构组件影响几何清晰度。近期分析 [3] 表明,层归一化、RoPE 嵌入和 GQA 会在残差流中诱导出特征性的各向异性与维度模式。我们的结果对此图景进行了细化:此类架构选择主要调制动态特征(尤其是注意力熵的减少),而静态贝叶斯几何(值流形与正交键框架)基本保持不变。
与电路级可解释性的关系。电路级分析 [9, 12] 识别出特定机制,如归纳头、模式匹配器和复制电路。我们的工作在互补尺度上展开:我们提供了这些电路运行所依赖的全局表征基质的几何描述。注意力机制决定咨询哪些证据;键框架定义可分离的假设方向;值流形沿低维坐标编码不确定性。将特定电路映射到这些全局几何结构,是未来工作的有前景方向。
总体而言,本系列研究所发展的贝叶斯几何视角,通过识别一个跨架构稳定的不确定性表征基质,并揭示后验精炼如何依赖于架构路由,补充了既有的可解释性方法。这一视角有助于在单一几何框架内统一可解释性、概率推理与模型分析中的多样观察。
8 结论
在严格受控环境中训练的 Transformer 能够实现精确的贝叶斯推理,其梯度动力学会生成一个低维几何基质,用以表达后验结构。在本研究中,我们追问:当接触真实语言、大规模参数以及异质化训练语料时,这种几何机制是否依然存续?我们对四个模型家族的分析表明,答案是肯定的:大语言模型将其值向量沿一个主导轴组织,该轴追踪预测熵;键保持接近正交框架;而领域限制能可靠地将值流形坍缩为合成风洞实验中观察到的同一种低秩形式。
这些发现表明,生产模型中的类贝叶斯证据整合并非抽样或提示设计的巧合,而是由一种持久的几何不变量所支撑——这是一种涌现的坐标系,不确定性在其上表达并随着上下文内证据的累积而演化。该不变量跨越不同架构与训练机制普遍存在,揭示出一种结构性归纳偏置:即使在没有任何显式贝叶斯目标的情况下,模型也倾向于以几何方式表征推理过程。
最后,我们的因果探针进一步细化了这一机制图景。移除或扰动与熵对齐的轴的干预会选择性地破坏局部不确定性几何,而匹配的随机干预则不会。然而,这些操作并未按比例削弱类贝叶斯行为,这意味着没有任何单一方向单独承担整个计算。该几何流形充当的是分布式推理过程的稳定读出(readout),而非脆弱的因果电路。
理解这一分布式机制如何产生,以及它是否可以被塑造、压缩或加速,代表了理论与工程领域的一个重要前沿。
大语言模型通过分布式机制执行贝叶斯更新,并将结果铭刻于一个低维、与熵对齐的流形之上——这是一种表征性读出,而非因果瓶颈。
原文链接:https://arxiv.org/pdf/2512.23752
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-01-25,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号