AIIData数据中台!实时开发平台(StreamPark) Spark SQL可视化实操流程
原创
AIIData数据中台!实时开发平台(StreamPark) Spark SQL可视化实操流程
原创
奥零数据科技
修改于 2026-03-11 11:40:09
修改于 2026-03-11 11:40:09
AllData数据中台作为可定义数据中台,具备全链路数据集成、治理能力,负责数据的统一汇聚与资产化管理;Streampark作为Apache顶级开源实时计算平台,支持Spark、Flink双引擎,提供低代码开发与一站式运维能力。
🔥 核心亮点
无需复杂配置,一键打通AllData数据中台与开源项目Streampark,用Spark SQL实现实时数据处理,新手也能快速上手,企业级实时数仓搭建效率直接翻倍!
在数字化转型的下半场,“实时数据”早已不是加分项,而是企业抢占市场的核心竞争力。但很多企业在搭建实时数据体系时,都会陷入两大困境:要么数据中台与实时开发平台割裂,数据流转卡顿;要么Spark SQL开发门槛高,运维成本居高不下。
🔥 破局方案
本文通过可视化操作+极简配置,让Spark SQL实时开发从配置Spark SQL版本、作业参数配置,到作业发布、启动运行,再到实时查看运行日志、完成作业闭环。

- 安装路径为服务器Spark的绝对路径
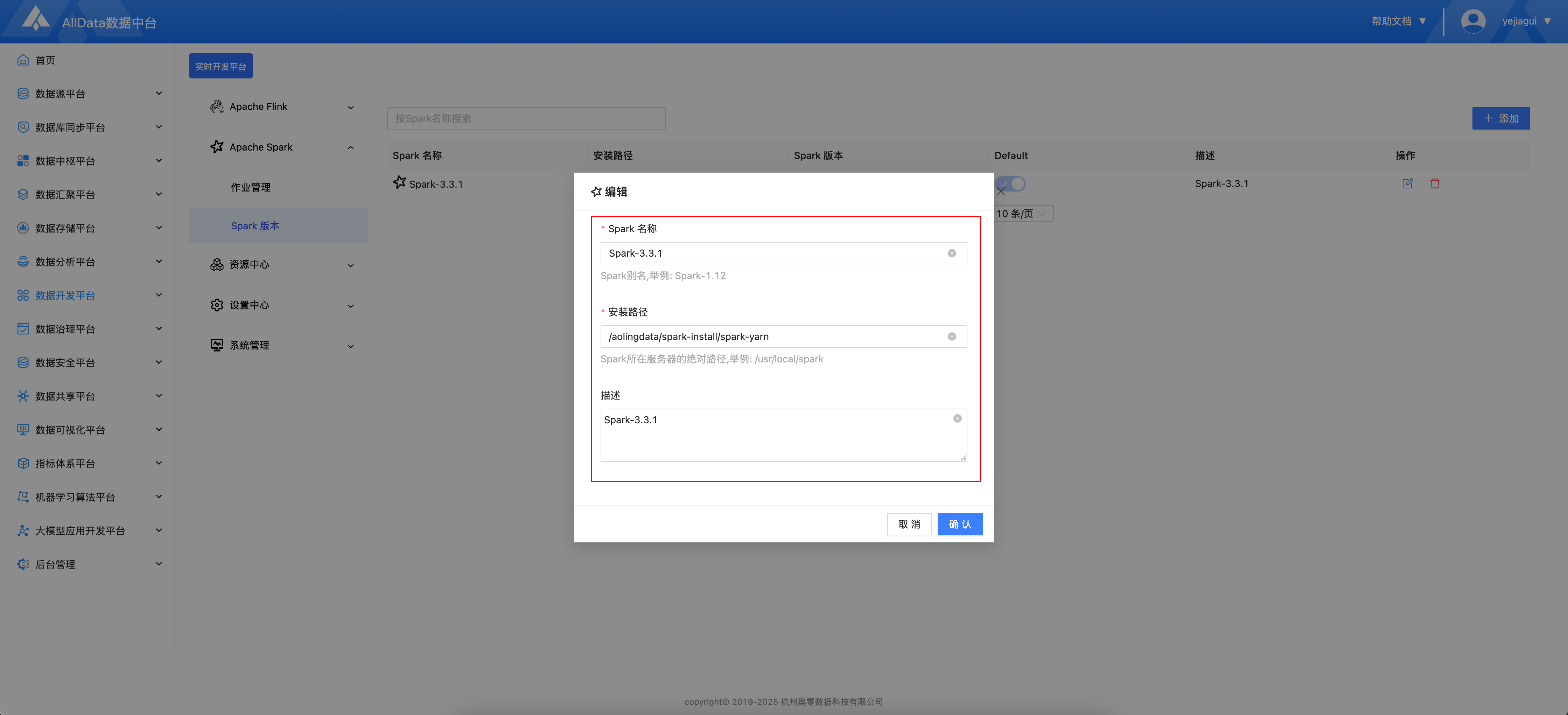
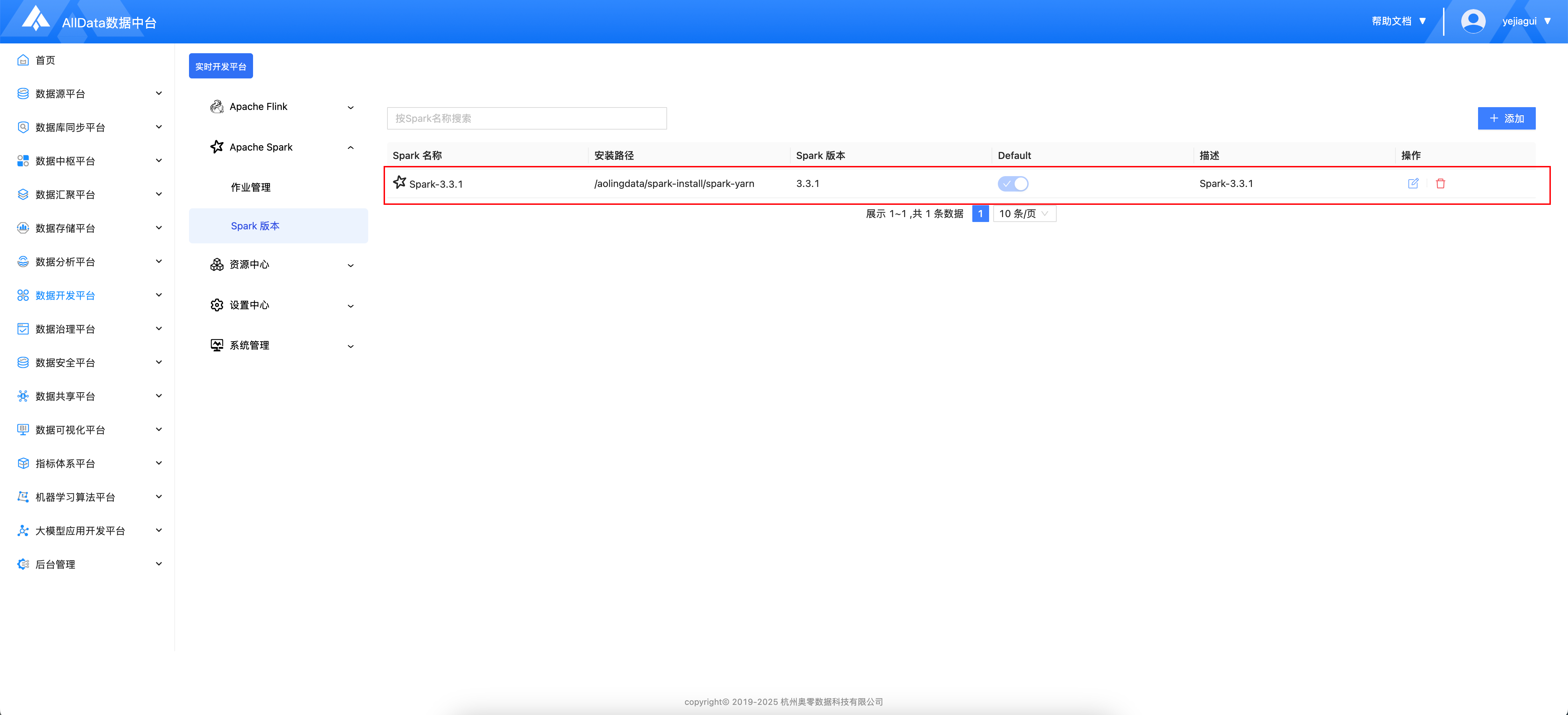
- 添加完成

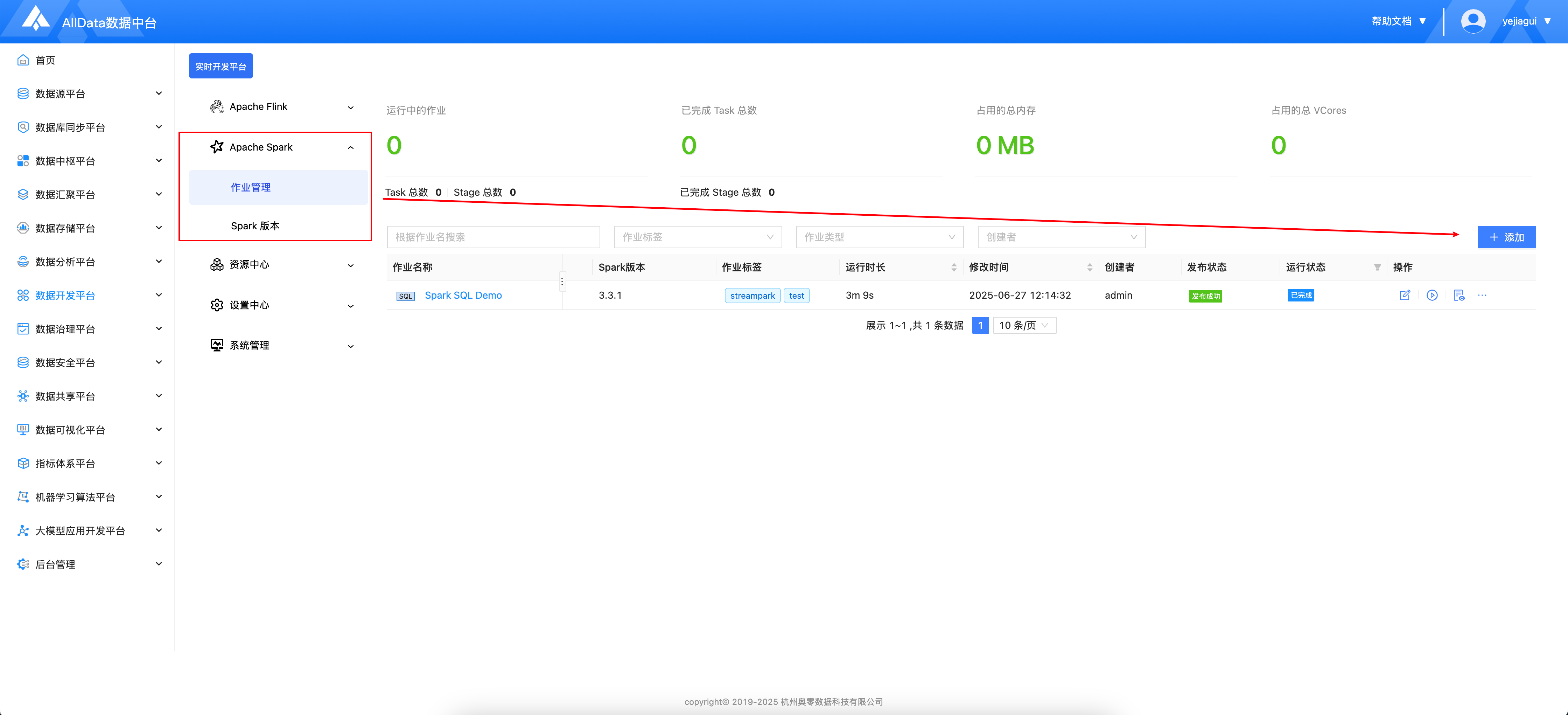
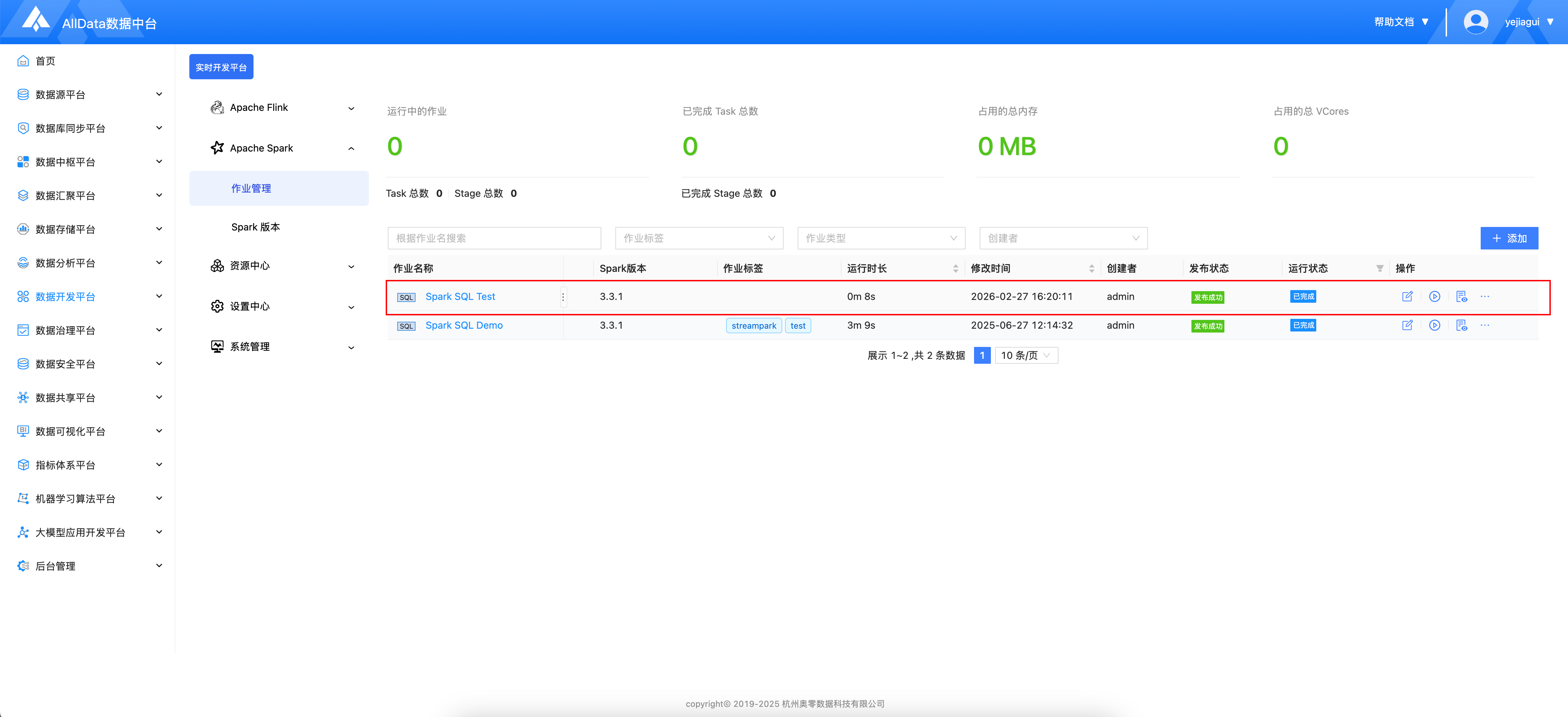
- 进入作业管理,点击添加
- 选择部署模式以及版本
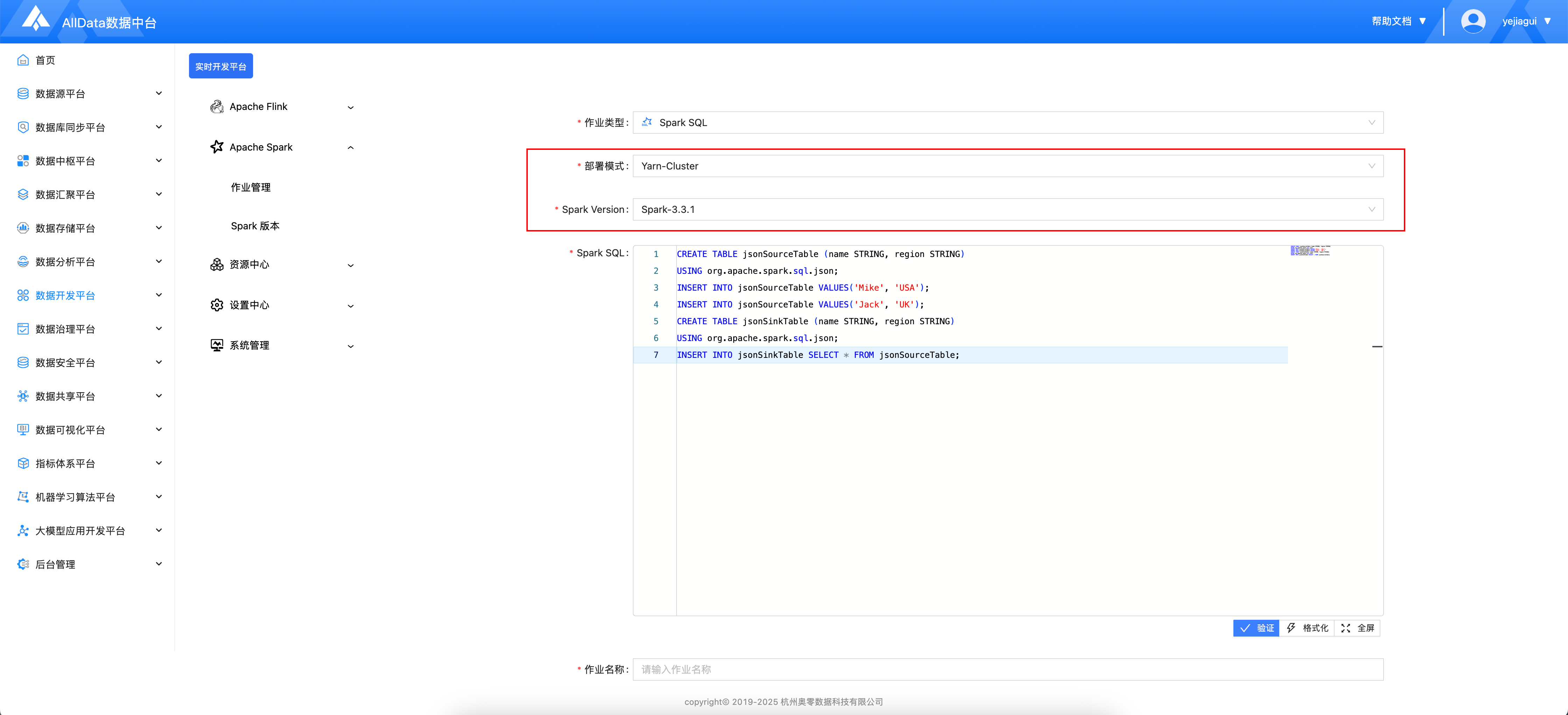
- 编辑Spark SQL
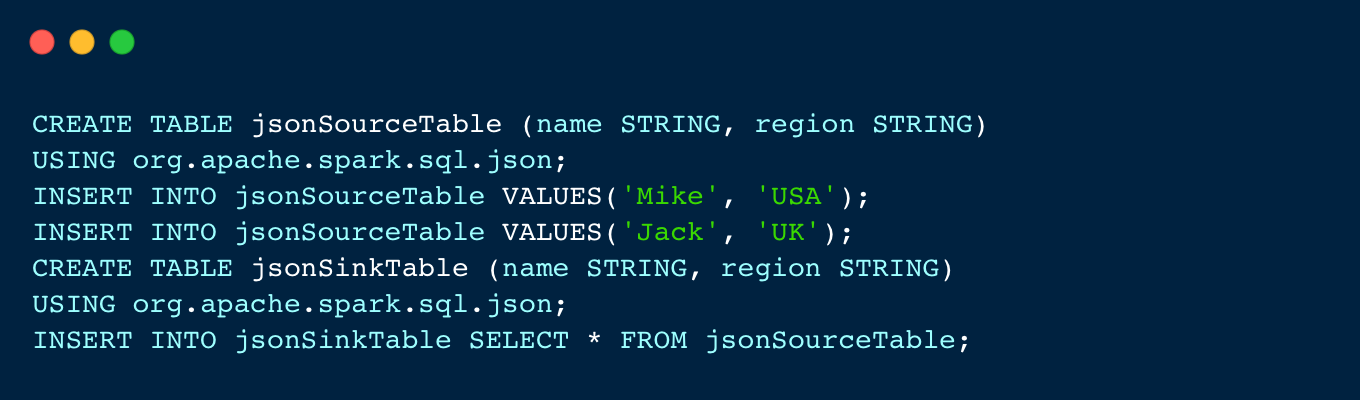
- 输入作业名称
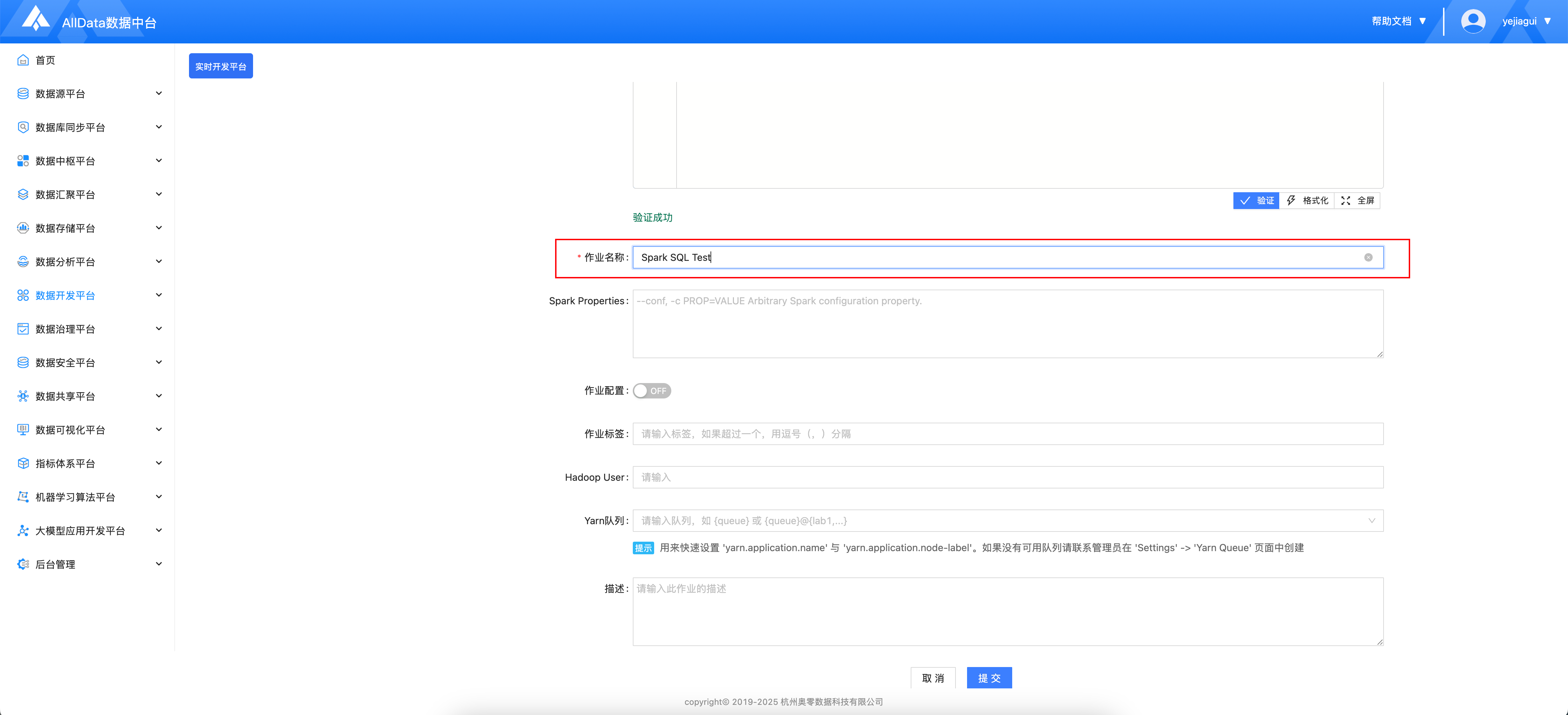
- 提交
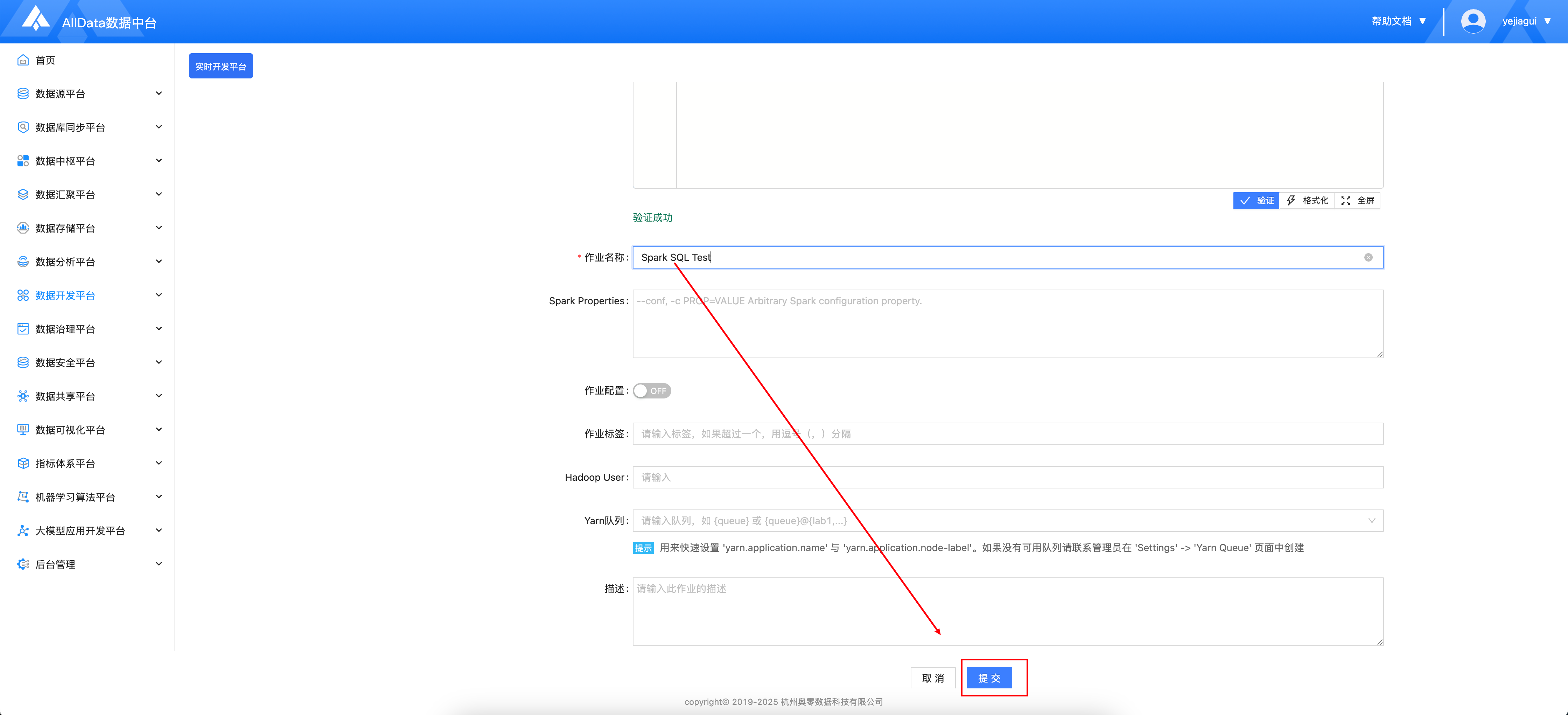

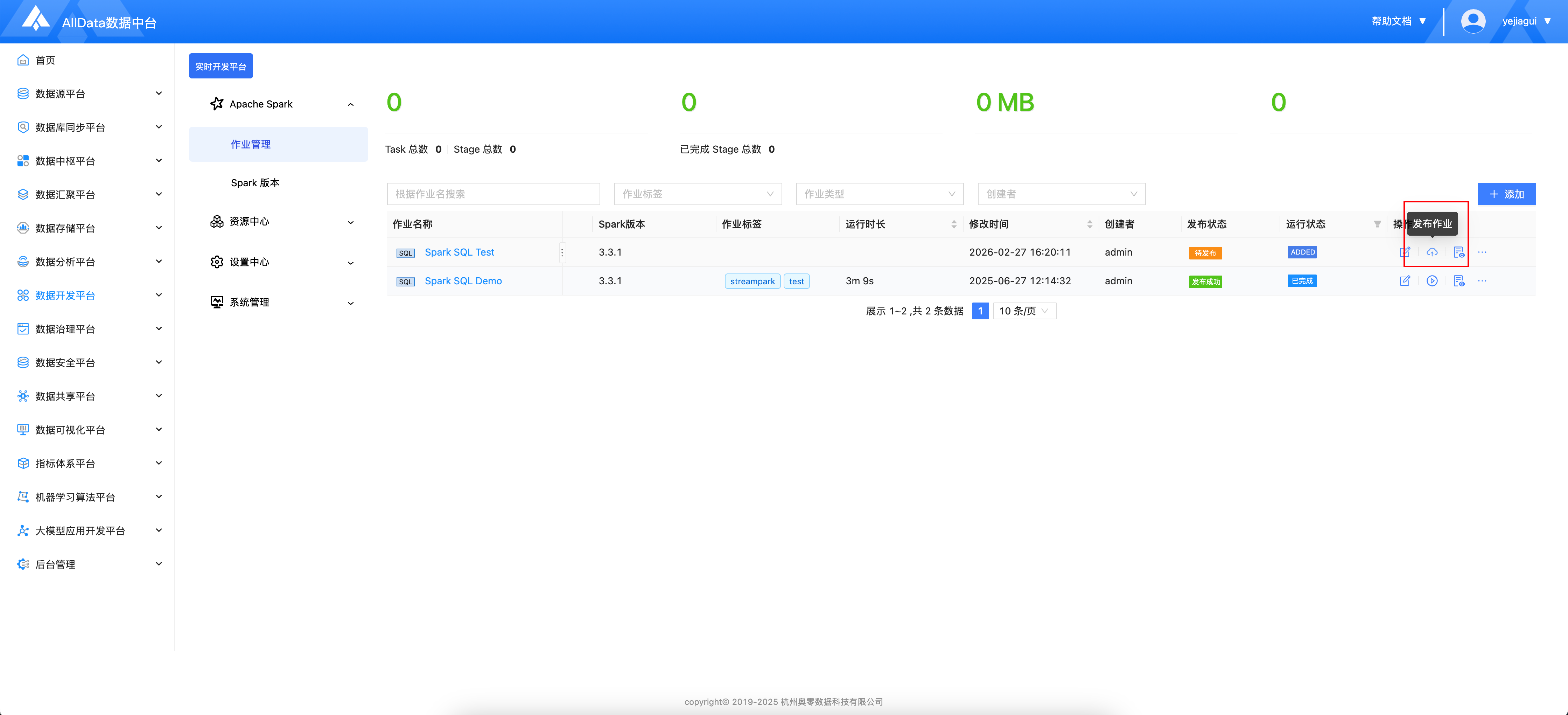
- 发布成功
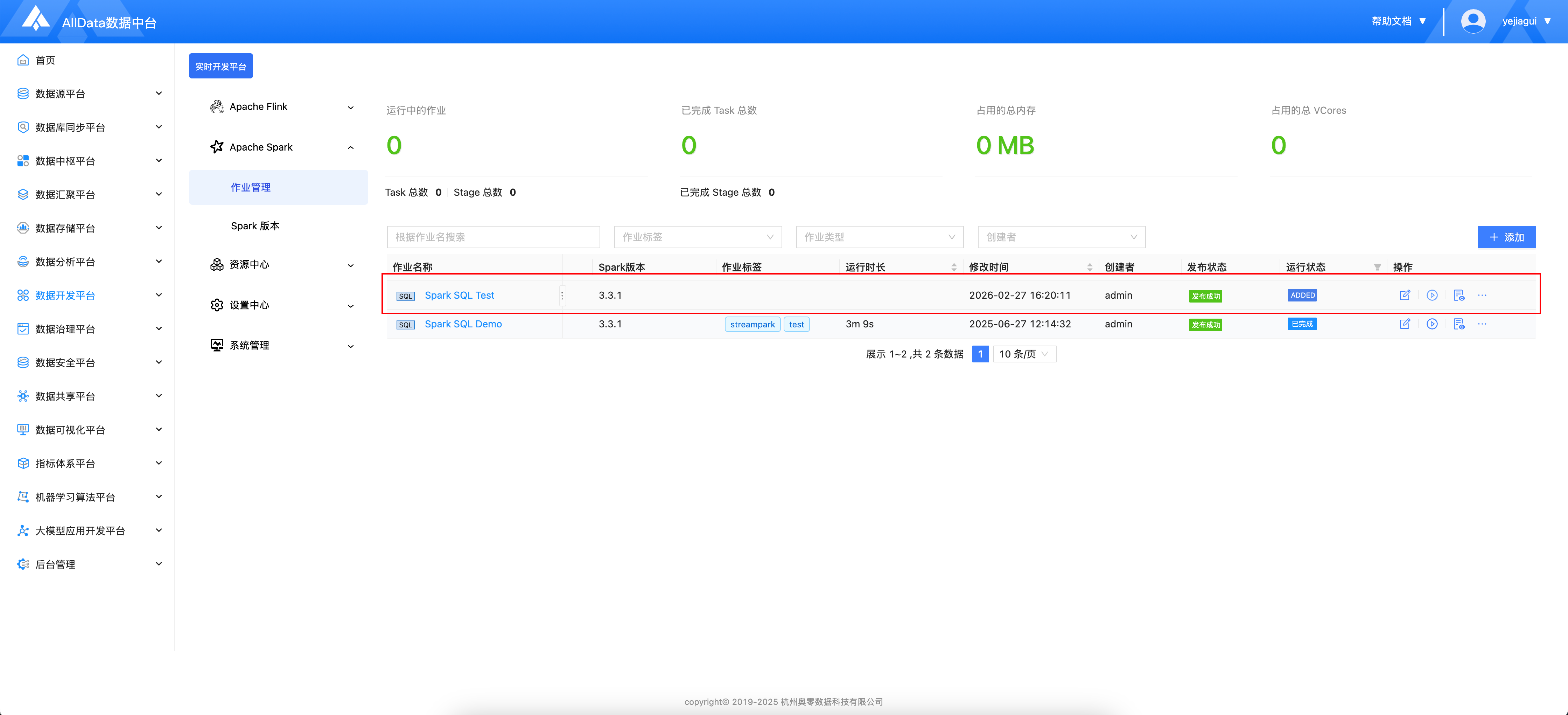

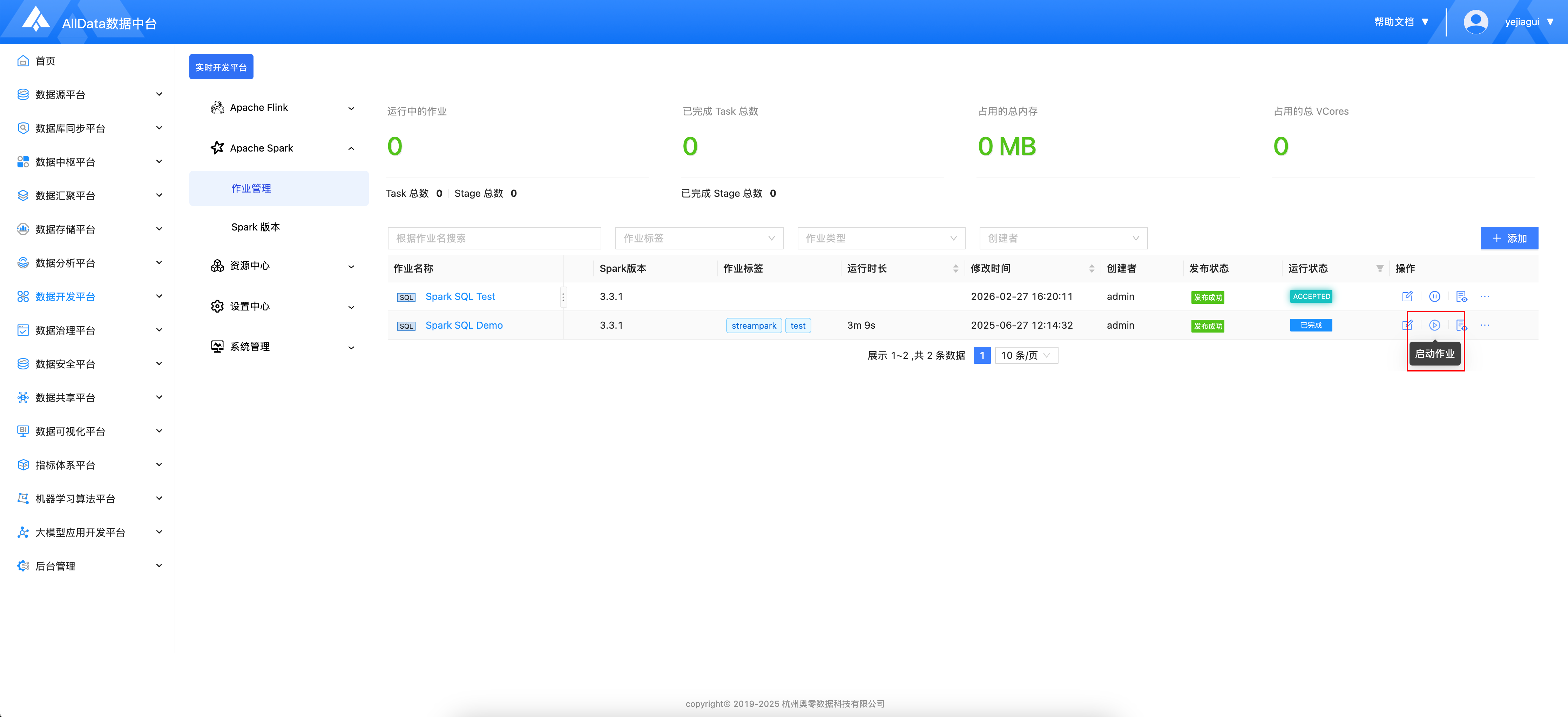
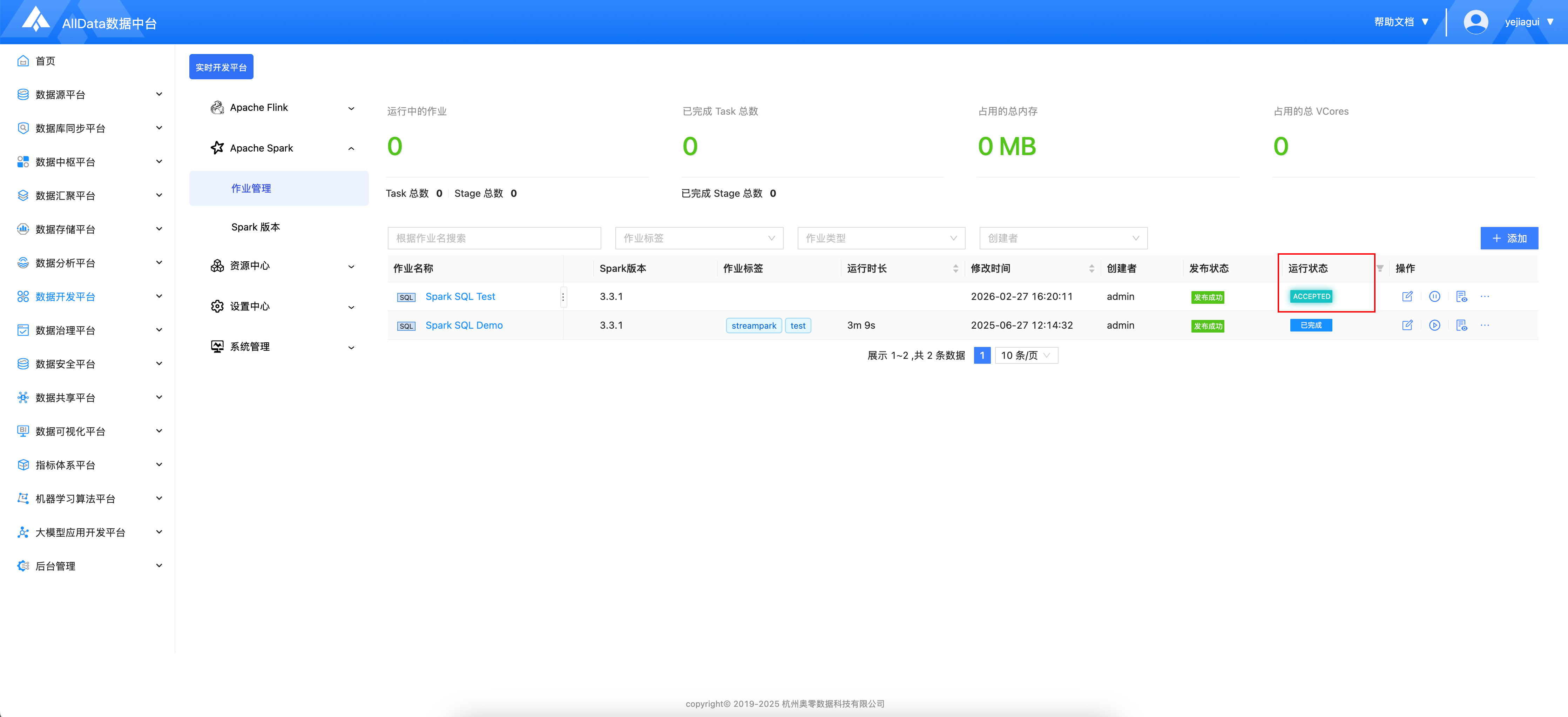
- 启动中

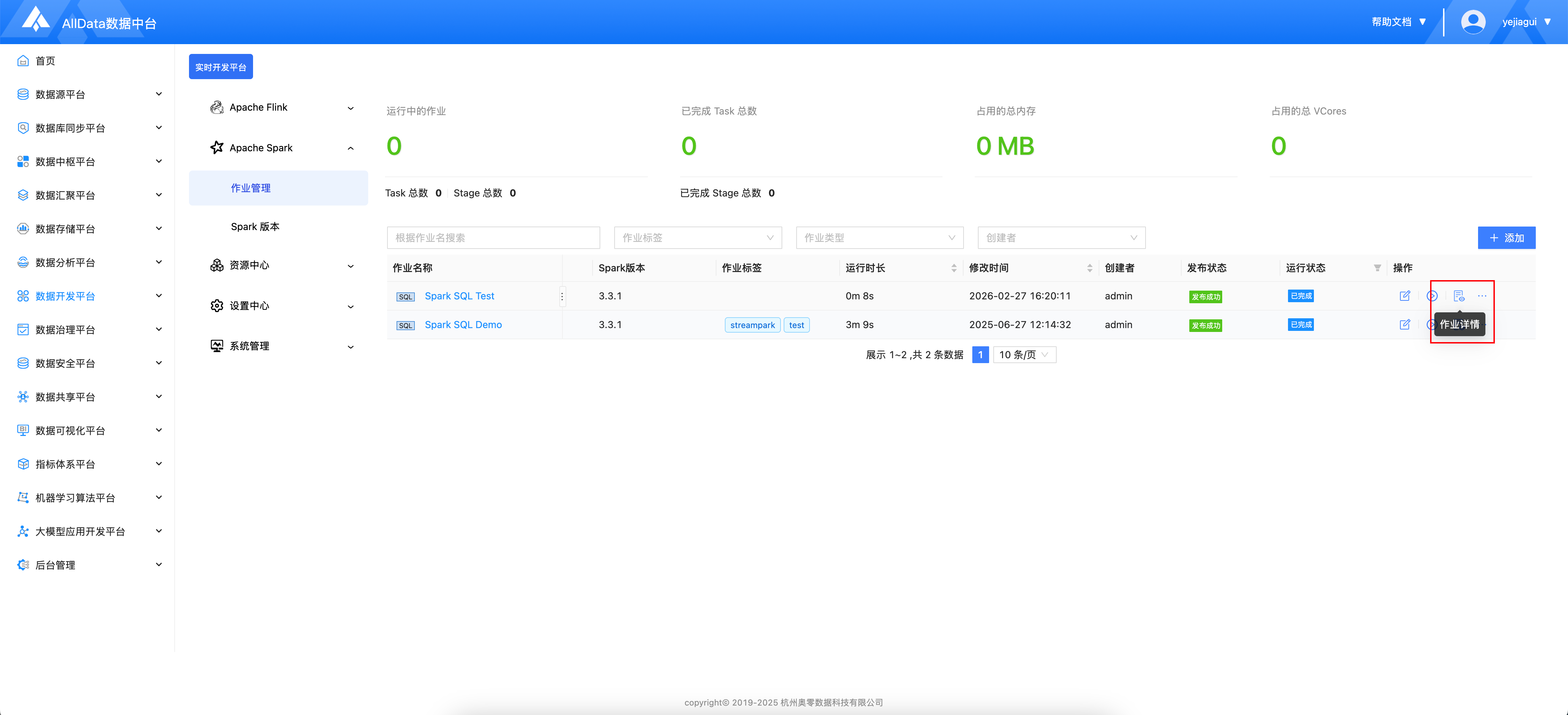
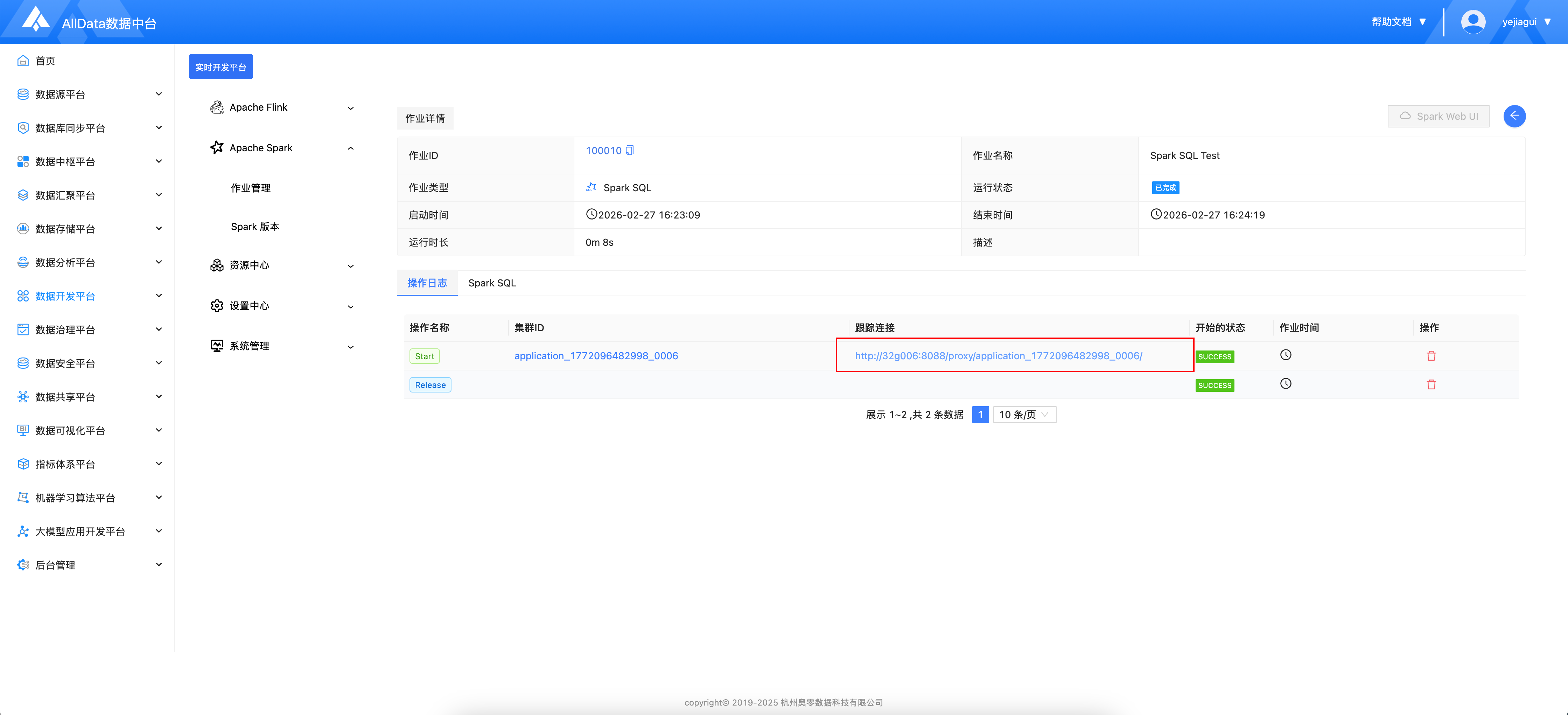
- 点击作业详情
- 点击跟踪链接
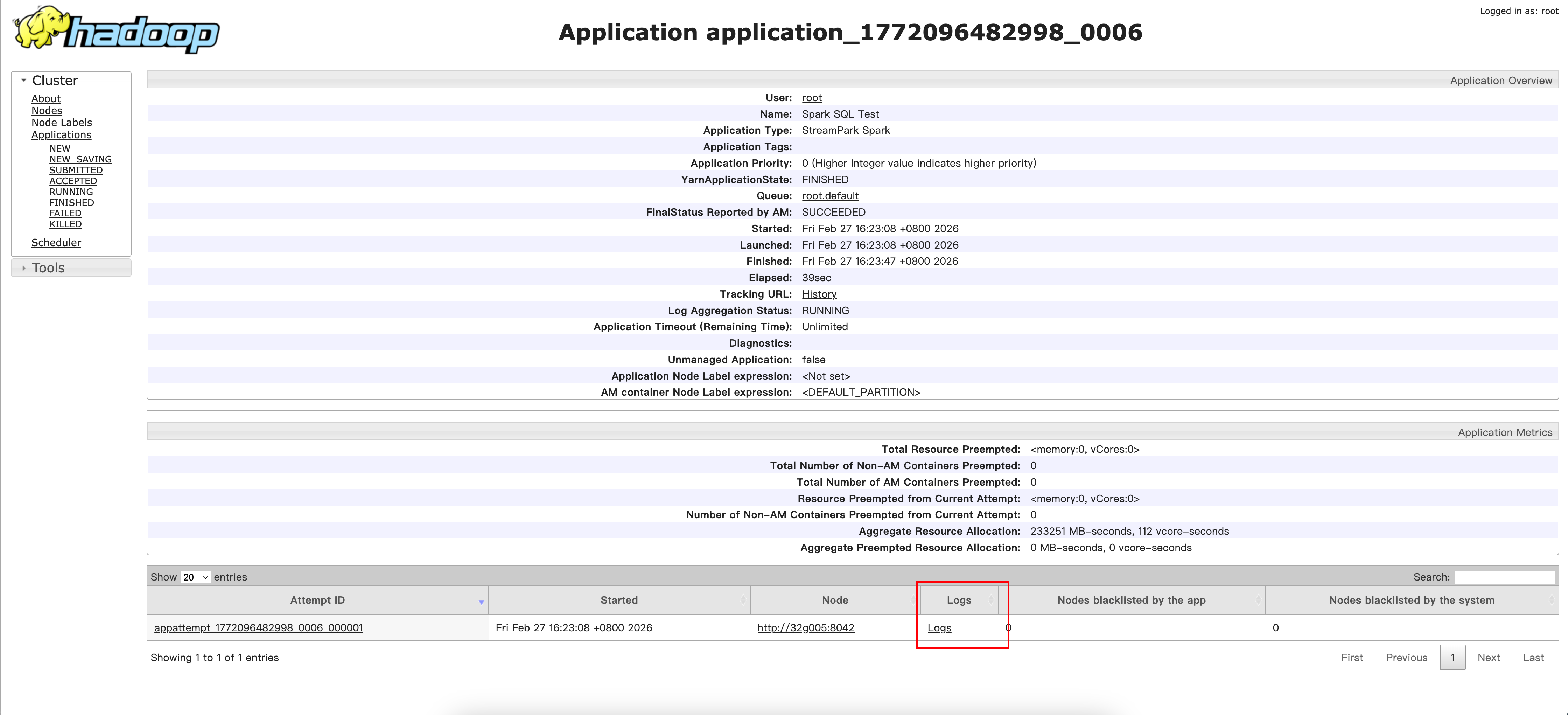
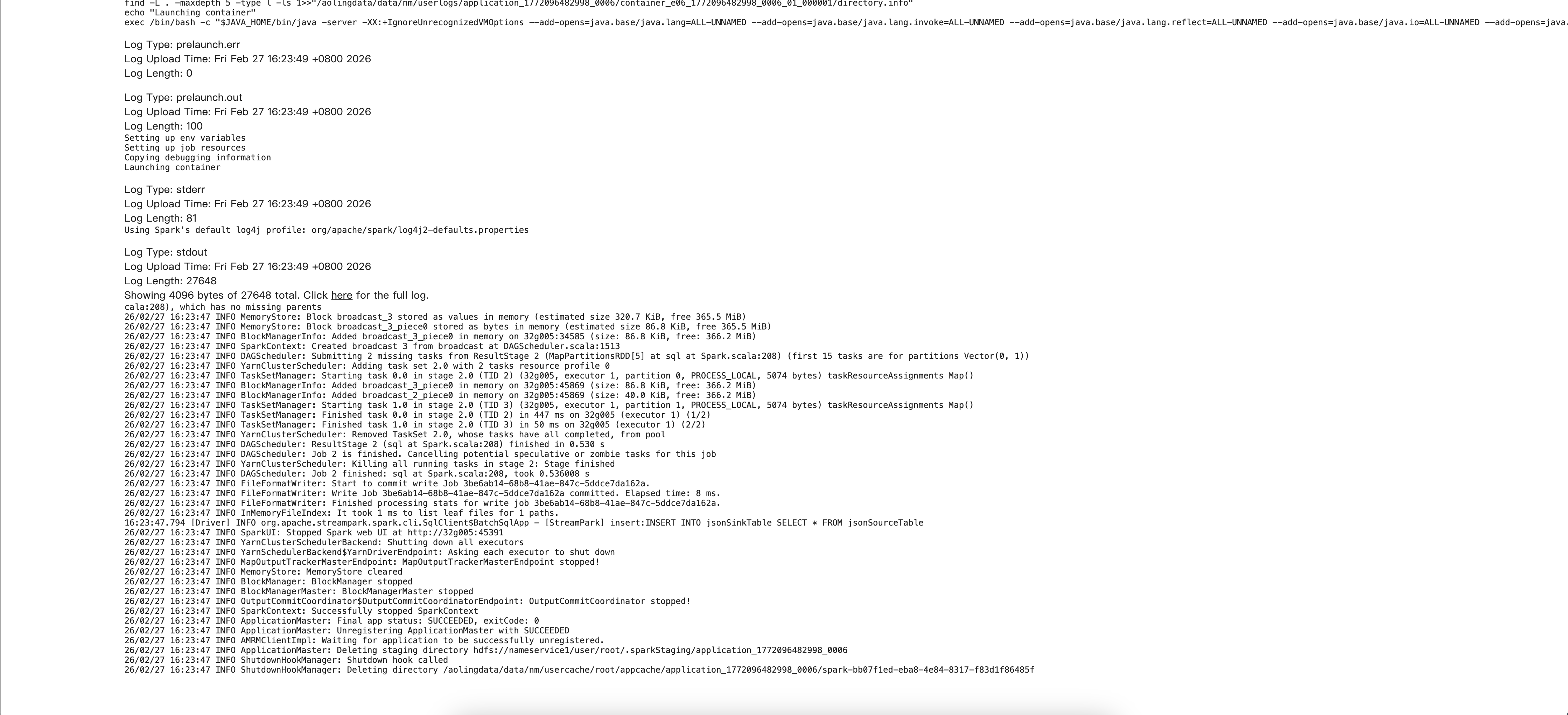
- 点击Logs

避坑指南:新手必看的3个注意事项
1. 版本兼容是关键:AllData、Streampark、Spark的版本需严格匹配(本文推荐的版本组合经过实测,无兼容问题),避免出现集成失败、作业运行报错;
2. Kafka数据源配置:需确保Kafka主题权限开放,AllData与Streampark能正常访问,否则会出现数据读取失败;
3. 并行度设置:根据数据量合理设置,小数据量无需过高并行度(避免资源浪费),大数据量可适当提升,同时预留一定的集群资源。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号