TIME: 突破时序基础模型评估瓶颈, 下一代任务驱动时序预测Benchmark

TIME: 突破时序基础模型评估瓶颈, 下一代任务驱动时序预测Benchmark

时空探索之旅
发布于 2026-03-10 16:20:59
发布于 2026-03-10 16:20:59
论文题目: It's TIME: Towards the Next Generation of Time Series Forecasting Benchmarks
作者: Zhongzheng Qiao(乔忠正), Sheng Pan(潘胜), Anni Wang (王安妮), Viktoriya Zhukova , Yong Liu(刘雍)Xudong Jiang(蒋旭东) Qingsong Wen(文青松), Mingsheng Long (龙明盛)Ming Jin(金明)Chenghao Liu(刘成昊)
论文链接: https://arxiv.org/abs/2602.12147
代码:https://github.com/zqiao11/TIME
榜单:https://huggingface.co/spaces/Real-TSF/TIME-leaderboard

背景
随着时间序列基础模型(TSFMs)的爆发,时序预测(TSF)的评估范式正在经历一场深刻的变革:从传统的“以数据集为中心”的单一数据集内训练和测试,转向“以任务为中心”的多任务零样本(zero-shot)泛化评估。然而,近年来领域内开始对现有的基准测试(Benchmarks)进行深刻反思,不仅发现了其中广泛存在却长期被忽视的底层问题,也越发意识到构建契合基础模型时代的全新 Benchmark 的迫切性与重要性。尽管近期领域内涌现了不少新的 Benchmark 尝试应对这些挑战,但如何从底层的数据来源、质量把控、任务设定以及评估视角进行系统性的重构,依然是当前亟待解决的难题。
为了打破这些僵局,作者们正式推出了 TIME——一个为 TSFMs 打造的下一代“以任务为中心”的时序预测基准。在基准构建层面,TIME 引入了 50 个全新的、鲜被现有Benchmark使用的“纯净”数据集,从源头上杜绝了数据泄露;同时,引入了“LLM辅助+人类决策”的严格数据清洗流程,并结合真实场景需求量身定制了 98 个极具现实意义的预测任务。在评估视角层面,TIME创新性地提出了“基于时序模式(Pattern-level)分析”方法。TIME不再局限于死板的领域或频率划分,而是通过提取时序变量的内在结构特征,将表现出相同模式的变量跨领域聚合。这不仅为模型的泛化能力提供了更具诊断性的洞察,也让 TIME 成为了一个真正能指导时序基础模型落地应用的强力工具。
引言:当前 TSF Benchmark的瓶颈
如图1所示,总结了当前时间序列预测Benchmark面临的一些共性瓶颈或挑战。

纵观TSF Benchmark的发展时间线(图2),现有Benchmark在数据构成上往往需要复用过往的经典数据集(legacy datasets)。这种数据集的持续复用,一方面使得模型在经典 Benchmark 上的性能提升逐渐趋缓(如在 Gift-Eval 上的表现趋于平稳);另一方面,这也无形中增加了测试集泄露(Test Leakage)的潜在风险,给零样本(Zero-shot)评估的客观性带来了挑战。

其次,数据的质量把控也是一个重要环节。许多开源数据集在构建时缺乏严格的质量把控,例如包含了一些显著的异常值和存在极高的缺失率。同时,当前的预测任务设置往往脱离实际业务场景,目前常见的预测任务设置往往更侧重于学术范式,习惯采用统一的历史观测窗口和预测长度。这种标准化的设定有时难以完全贴合复杂多变的实际业务场景,导致排行榜上的量化分数,不一定能直接转化为指导实际决策的有效行动。
最后,目前的评估视角和方法仍有进一步拓展的空间,且定性分析(如可视化检验)的维度相对欠缺。现有的 Benchmark 通常习惯按“领域”(domain)或“频率”(frequency)来划分数据集并汇总指标,忽略了跨领域的时间序列之间可能共享的底层时序模式或特征。此外,与 NLP 或 CV 领域不同——在那些领域,像“准确率”这样的指标通常具备直观的操作意义,甚至可以直接对标人类的表现——时间序列的常用误差指标(如 MAE、MASE)在孤立状态下往往显得较为抽象。仅仅是基准测试上标量数值的提升,很难直接说明模型的预测在实际部署中是否真正可靠或具备鲁棒性。如果仅依赖量化的榜单指标来指导业务选型,可能会在实际应用落地中遇到预期之外的偏差。
TIME Benchmark 的构建
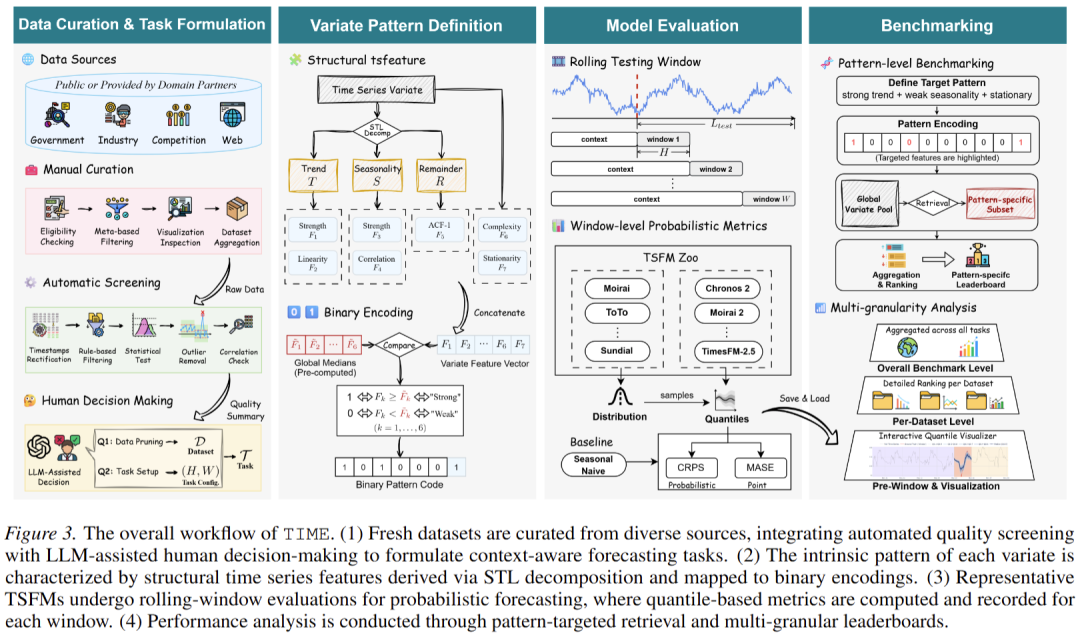
为了解决上述问题,作者重新设计了Benchmark的整个生命周期,提出了 TIME 的核心工作流(如图3所示)。整个过程主要包含四个紧密相连的环节:
- 在数据源头,从政府、业界合作和真实比赛等渠道收集了全新的数据集,从根本上杜绝了“测试集泄露”。
- 面对参差不齐的原始数据,设计了一套“自动化筛查+大模型辅助人类专家”的严密清洗机制,精准剔除极端异常值并保留真实的业务复杂性,确保了留存数据的高质量。
- 在任务设置上,摒弃了传统的固定预测长度。将任务定义交还给实际场景,深度结合领域知识和数据本身的时间频率,为每个数据集量身定制了最符合真实业务决策需求的预测窗口。
- 提出了一种基于时序特征的全新分析方法。通过STL结构化分解,先将原始时间序列变量剥离为趋势、季节性和残差等独立分量。在此基础上,针对每个分量分别计算其对应的结构化且极具可解释性的量化特征(如趋势强度、季节规律性、整体复杂性等),从而为每一条时间序列变量刻画出其内在的特征画像。最后,基于这些特征画像,将连续的特征指标转化为极简的“二进制编码”。这一设计让我们得以跨越的数据集或者领域的壁垒,将具有相同时序底层规律的数据跨界聚合在一起进行针对性测试。这种全新的“模式驱动”评估策略,不仅能直观地揭示出各大模型究竟最擅长捕捉哪种特定的时间动态,更为实际业务中复杂场景下的模型选型提供了精准的指导。
评估结果
在评估环节,作者对12个具有代表性的TSFMs进行了全面测评,并引入Seasonal Naïve 作为基线对比。整体的评估结果与当前模型的发展趋势所吻合,其中 Chronos-2 和 TimesFM-2.5 展现出了当前最优的综合性能。为了打破传统量化指标过于抽象的局限,作者还专门开发了一个交互式的Leaderboard,不仅支持多尺度的宏观分析,还能直接可视化每个模型在各个测试窗口的具体预测曲线,让定性分析变得一目了然。
榜单:https://huggingface.co/spaces/Real-TSF/TIME-leaderboard


此外,得益于特有的“模式驱动”策略,作者们还从时序特征的维度对模型能力进行了深度剖析。结果清晰地表明,在面对具备不同底层特征(如强趋势或高波动)的时间序列时,各大模型的排名和表现会发生的变化。这种细分维度的洞察,不仅直观地揭示了不同时序模式对具体模型性能的影响,也进一步为复杂业务场景下的精准模型选型提供了有力的依据。

开源代码与榜单提交
为了方便用户快速测试与复现,GitHub仓库开源了全流程代码,并提供了轻量易用、无复杂依赖的 Dataset 类以及完整的实验运行脚本。同时,非常欢迎研究者们在 TIME 上测评自己的模型,并将结果提交至官方榜单,详细的提交流程与指南敬请参阅作者们的 GitHub Repo。
代码:https://github.com/zqiao11/TIME
推荐阅读
VLDB2024 |TFB: 全面且公平的时间序列预测方法评测基准
如果觉得有帮助还请分享,在看,点赞
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-03-07,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号