AAAI 2026 Oral | 零样本、高精度、低开销:高效利用视觉语言模型检测时序异常

AAAI 2026 Oral | 零样本、高精度、低开销:高效利用视觉语言模型检测时序异常

时空探索之旅
发布于 2026-03-10 15:52:03
发布于 2026-03-10 15:52:03
时间序列异常检测,长期依赖数值建模,却难以捕捉人类专家一眼识别的“上下文异常”。随着多模态大模型的发展,研究者开始探索将时间序列渲染为图像,并借助视觉语言模型(VLM)进行异常判断。然而,直接调用 VLM 往往陷入两难:用长窗口保留上下文却丢失定位精度,用短窗口精确定位又带来爆炸性 token 开销,难以兼顾准确性、效率与语义理解。
为此,来自宾夕法尼亚州立大学、麻省理工大学与亚马逊的研究者提出VLM4TS,一个高效、零样本,基于VLM的诗序异常检测框架。它将检测任务拆解为“视觉初筛 + 多模态精修”两阶段,既精准定位异常,又理解全局时序语义。这项被 AAAI 2026 选为 Oral 的工作,首次让 VLM 真正在时序异常检测中“看得准、想得清、用得起”。

论文标题: Harnessing Vision-Language Models for Time Series Anomaly Detection
论文会议: AAAI 2026(Oral Presentation)
论文地址: https://arxiv.org/abs/2506.06836
论文源码:https://github.com/ZLHe0/VLM4TS
(持续迭代优化,欢迎反馈和交流!)
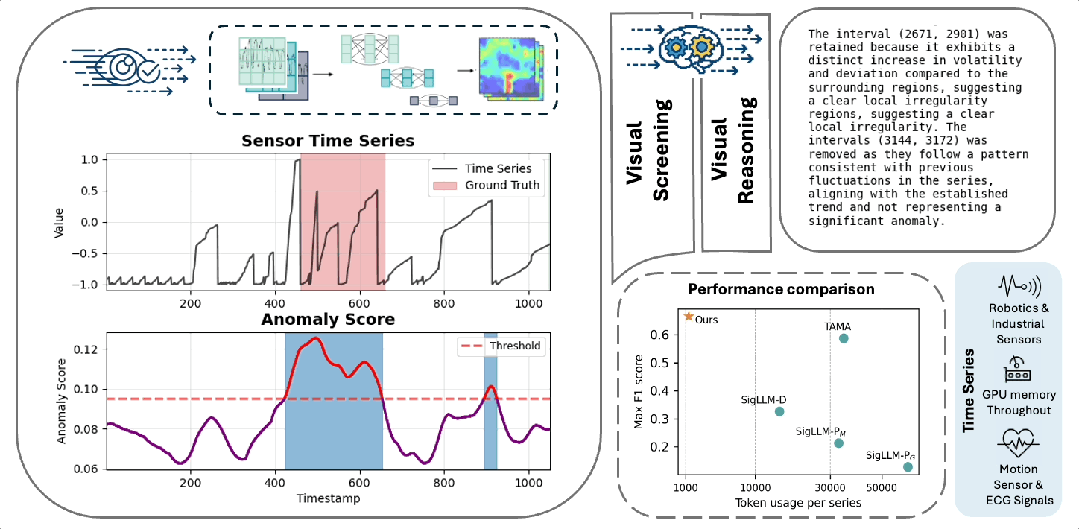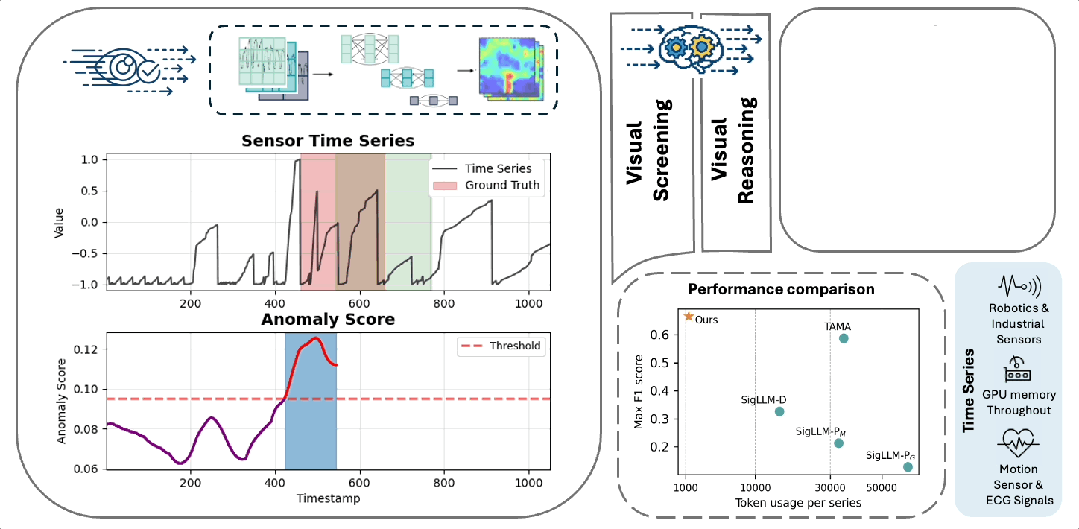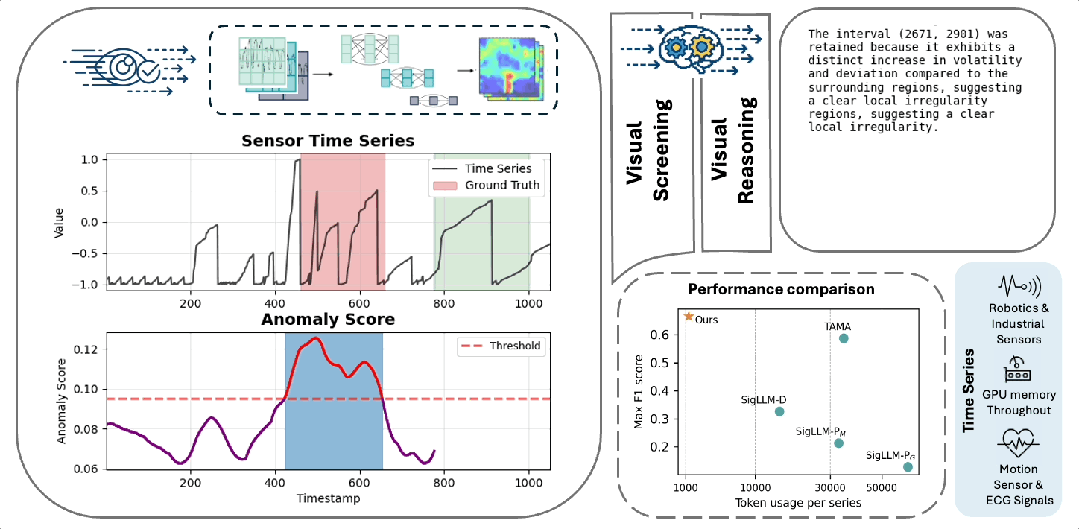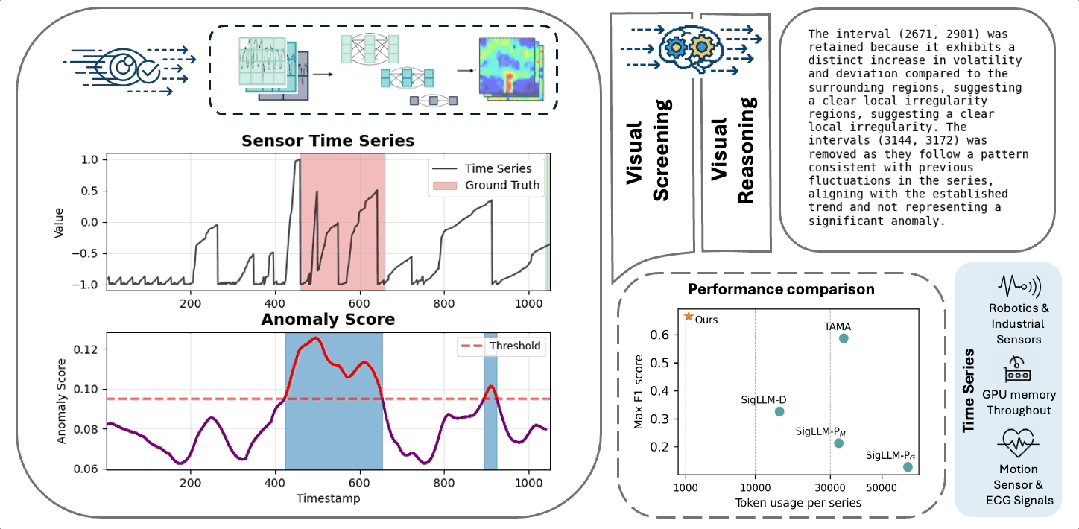
VLM4TS概览图
VLM4TS概览图
论文背景
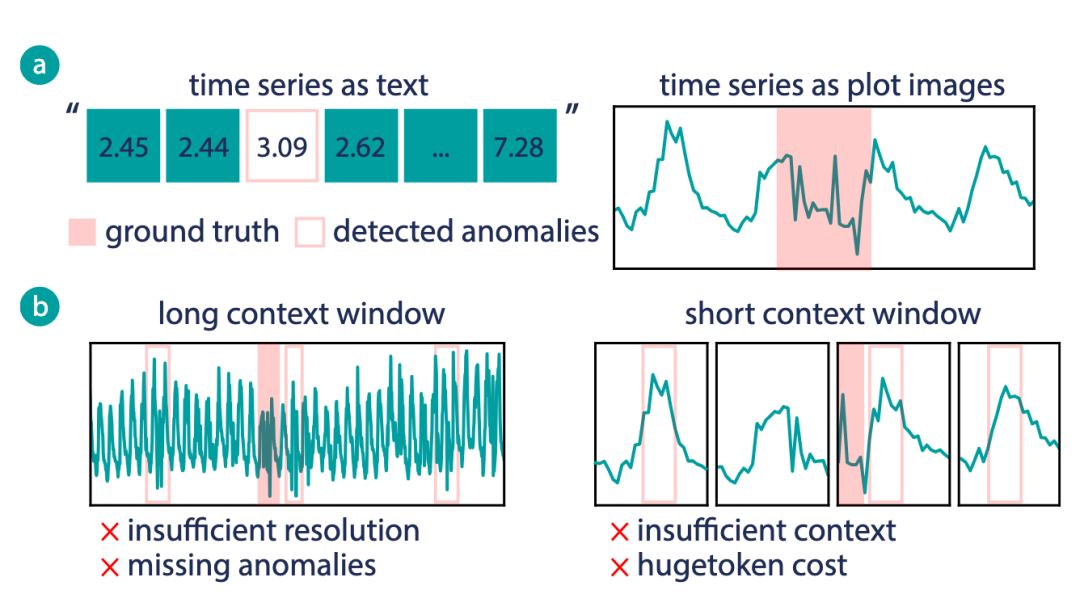
(a)时间序列的视觉表达比文本表达更适合检测任务. (b) 基于VLM异常检测的精度-上下文困境
(a)时间序列的视觉表达比文本表达更适合检测任务. (b) 基于VLM异常检测的精度-上下文困境
时间序列异常检测(TSAD)在医疗监护、金融风控、工业物联网等关键场景中扮演着“安全哨兵”的角色。然而,现有方法大多依赖于在纯数值数据上训练的领域专用模型,缺乏人类专家所具备的视觉-时序综合理解和推理能力。
近年来,视觉-语言大模型(VLMs)在图像理解、跨模态推理等任务中展现出接近人类的感知能力。研究者自然想到:能否将时间序列“绘制成图”,让 VLM 像人类专家一样“看图识异常”?然而,直接将整条时间序列渲染为一张图交给 VLM,会陷入精度-上下文困境(Resolution–Context Dilemma):
- 若用长窗口全局图,虽保留长期依赖,但细节被压缩,x 轴刻度拥挤,模型难以精确定位异常边界;
- 若用短窗口滑动图,虽分辨率高,但上下文断裂、需处理海量图像,带来高昂的 token 消耗与推理延迟。
这一困境使得现有 VLM-based TSAD 方法在精度与上下文之间难以兼顾,限制了其在真实大规模监控系统中的落地。
核心问题
如何在不进行任何时间序列领域微调的情景下,高效且精准地利用视觉-语言大模型(VLM)实现时间序列异常检测? 关键挑战在于:
- 如何在保留全局上下文的同时实现高精度异常定位?
- 如何避免滑动窗口带来的爆炸性 token 开销?
关键创新
针对上述挑战,作者提出 VLM4TS,一个两阶段基于视觉的时序异常检测框架,巧妙解耦“定位”与“验证”任务,兼顾精度与效率:
● 亮点一:分阶段检测范式(Localization + Verification)
受人类专家“先粗筛、再细判”工作流启发,VLM4TS 将 TSAD 拆解为两个阶段:
- ViT4TS(视觉筛查阶段):将时间序列切分为滑动窗口图像,使用VLM的轻量级纯图像预训练的 Vision Encoder(无任何 TS 微调),通过视觉模式匹配快速定位候选异常区间;
- VLM4TS(语言-视觉验证阶段):将 ViT4TS 提出的候选区间与完整长序列全局图一同输入 VLM,利用其跨模态推理能力,结合长期上下文对候选异常进行语义级验证与筛选。
相比现有的时序异常检测方法实现了高精度(F1-max 提升 24.6%)。
● 亮点二:极致 token 效率**
通过“轻量筛查 + 聚焦验证”机制,VLM4TS 仅对可疑区域调用高成本 VLM,避免全序列高分辨率渲染,为大规模实时监控提供了可行性。
相比现有基于LLM和VLM的 TSAD 方法,实现了低开销 (平均 token 消耗降低 36 倍),
● 亮点三:零样本跨域泛化能力
整个框架无需在目标时间序列数据上进行任何训练或微调:
- ViT4TS 直接使用 ImageNet 预训练权重;
- VLM4TS 依赖 VLM 原生的图文对齐能力,通过文本引导其理解“异常”语义。
实验表明,该方法在多个领域(服务器日志、航天遥测等)均取得 SOTA 性能,展现出极强的通用性与可迁移性。
论文方法
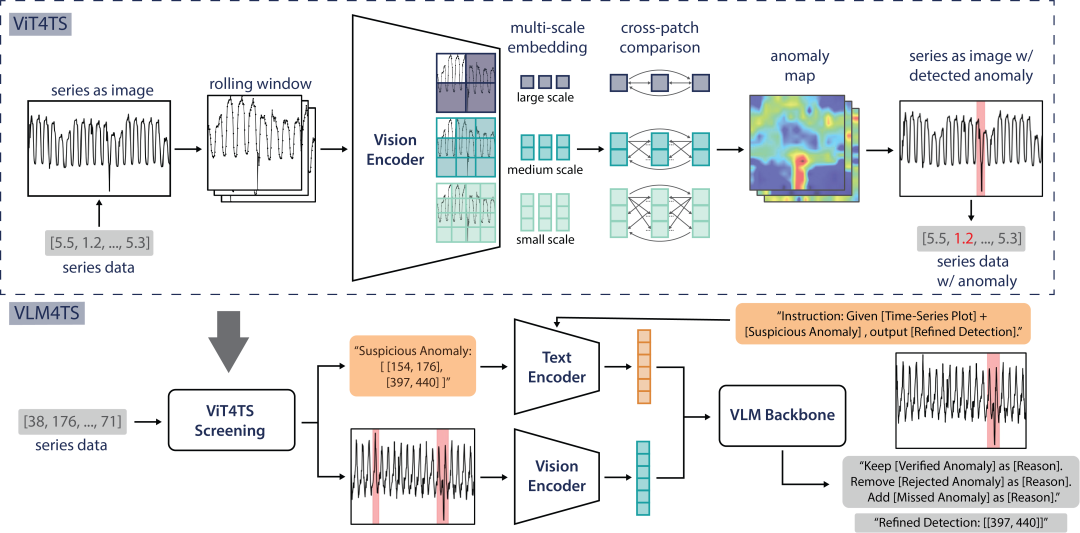
方法总览图:ViT4TS 将时序切片为图像,通过多尺度 patch 对比定位候选异常;VLM4TS 则结合全局对候选进行语义级精修
方法总览图:ViT4TS 将时序切片为图像,通过多尺度 patch 对比定位候选异常;VLM4TS 则结合全局对候选进行语义级精修
01 ViT4TS:轻量级视觉初筛,多尺度“看图识异”
VLM4TS 的第一步是让一个轻量级视觉编码器对时间序列进行快速筛查。这一步的核心思想是:把时间序列当图像看,用预训练的视觉模型“扫一遍”,找出所有可疑区域。
我们考虑的是像 LLaVA 这类主流 VLM 所使用的视觉编码器(如 CLIP-ViT),它无需在时序数据上微调,仅凭其在海量自然图像上学到的视觉感知能力,就能完成这项任务。
具体流程如下:
- 将原始时间序列切成重叠滑动窗口;
- 每个窗口渲染成一张干净的折线图(无坐标轴、无图例);
- 输入视觉编码器,提取每个窗口的多尺度特征图: 首先,从视觉编码器中提取基础 patch 特征图 ,其中 是 patch 数量, 是特征维度。然后,对 分别应用不同大小的平均池化核 ,小 保留细节,大 聚合上下文,生成多个尺度的特征图 :
📌 为什么需要多尺度?因为异常形态千差万别:有的是瞬时尖峰(需高分辨率定位),有的是长期漂移(需全局上下文)。单一尺度无法兼顾。
- 获得多尺度特征后进行跨窗口对比(cross-patch comparison)。由于没有正常样本作为参考,我们利用“异常是稀有的”这一特性,让每个窗口内的 patch 去和所有其他窗口的 patch 做相似性匹配。为了效率,我们采用中位数参考法:
- 先计算所有窗口在某尺度下的 patch 特征中位数,形成一个“正常模式”的参考向量 ;
- 再计算当前窗口每个 patch 与该参考向量的余弦距离:
其中 是第 个窗口在尺度 下第 个 patch 的特征。距离越大,越可能是异常。最后,将不同尺度的异常分数通过调和平均融合,得到一张高分辨率的“异常热力图”,并据此提取出初步的候选异常区间。
02 VLM4TS:重型 VLM 验证,全局推理精修
ViT4TS 完成了快速的初筛,但它的弱点也很明显:缺乏对整条序列的宏观理解。比如,一个看似突兀的波动,如果在整个历史中反复出现,那它其实是正常的。因此,我们引入重型 VLM Backbone(如 GPT-4o)。它的任务不是从头开始“看图找异常”,而是基于 ViT4TS 提供的“可疑名单”,结合整条序列的全局视图,进行深度语义推理与修正。
整个验证过程分为三步:
- 输入一:全局图像: 将整条时间序列渲染为带坐标轴的折线图,让 VLM 能一眼看清趋势、周期与漂移;
- 输入二:候选列表: 将 ViT4TS 输出的候选区间以文本形式提供给 VLM;
- 指令引导: 通过精心设计的 prompt,要求 VLM 执行三项操作:
- 保留真正偏离全局模式的区间;
- 删除与整体行为一致的“假阳性”;
- 补充 ViT4TS 可能遗漏的宏观异常。
最终,VLM 会返回一个“精修版检测结果”,包含推理、最终区间、置信度评分。我们只保留置信度 ≥2 的结果作为最终输出。
实验结果分析
01 核心性能对比:超越时序模型与语言模型基线
在 11 个广泛使用的工业异常检测基准数据集上(涵盖传感器、网络流量、社交媒体等多领域),VLM4TS 在 F1-max 平均得分上显著优于现有方法,在 9/11 个数据集上取得第一,平均性能比第二名基线(LSTM-DT)提升 **24.6%**。
- 与从零训练的时序模型对比:
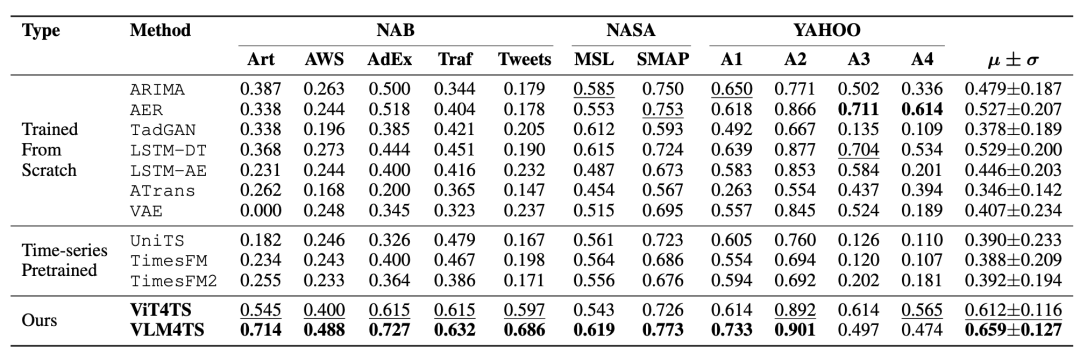
与传统时序模型基线效果对比
与传统时序模型基线效果对比
- VLM4TS 不仅全面超越了传统统计模型(ARIMA)、深度学习模型(LSTM-AE, TadGAN, ATrans)和变分重建模型(VAE),也超越了当前主流的预训练时序基础模型(UniTS, TimesFM)。
- 值得注意的是,其第一阶段模块 ViT4TS 本身即表现优异,在 6 个数据集上排名前二,证明了纯视觉筛查在无监督 TSAD 中的有效性。
- 这表明,将时间序列转化为图像并利用预训练视觉模型进行模式匹配,是一种强大且可扩展的范式,无需针对特定任务进行微调。
- 与基于大语言模型(LLM)的方法对比:

与LLM/VLM基线效果对比
与LLM/VLM基线效果对比
- VLM4TS 在所有数据集上的 F1-max 均显著优于 LLM 基线(如 SigLLM-D, SigLLM-P_G/M),平均领先 **13.3%**。
- 尤其在依赖长程上下文的数据集(如 NAB 系列)中,VLM4TS 的优势更为突出(最高达 26.5%),这验证了其“局部定位 + 全局验证”设计的有效性。
- 相比之下,直接将时间序列文本化的 LLM 方法(如 SigLLM-P)在 token 消耗和推理延迟上表现极差,而 VLM4TS 通过两阶段设计实现了精度与效率的双重突破。
02 效率评估:Token 消耗降低 30 倍,推理速度媲美轻量模型
除了精度,VLM4TS 的另一大贡献在于大幅降低计算开销:
- Token 效率:相比需要对每个滑动窗口单独编码的 LLM/VLM 方法(如 TAMA, SigLLM),VLM4TS 仅对 ViT4TS 提出的少量候选区间调用 VLM,平均 token 消耗降低 30 倍以上(Table 2)。
- 推理速度:在标准硬件(NVIDIA V100)上,单条长序列(数千时间点)的完整检测可在数秒内完成,其中 ViT4TS 阶段可在 CPU 上运行,整体效率与轻量级时序模型相当。
- 部署可行性:对于大规模监控系统(如数千传感器),VLM4TS 的低 token 成本和快速推理使其具备实时落地潜力。
消融实验:核心组件的有效性验证
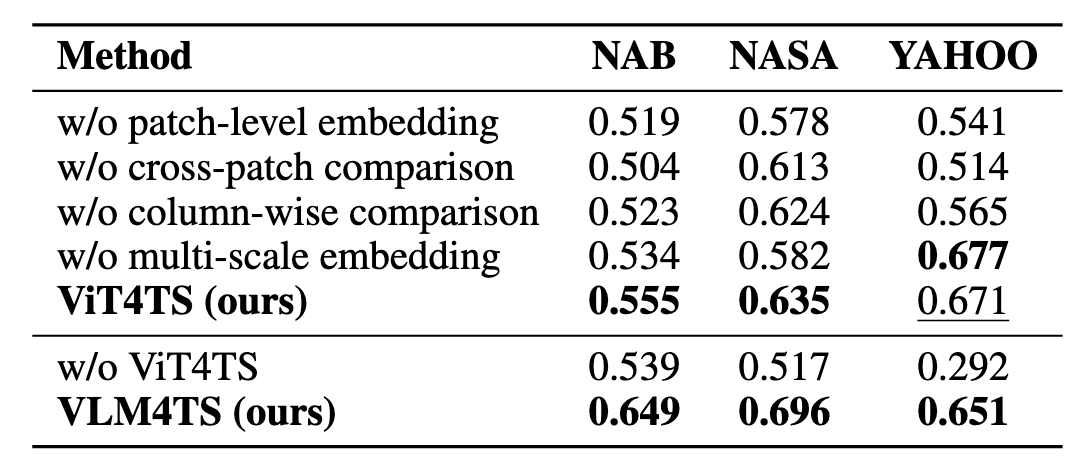
消融实验:核心组件的有效性验证
消融实验:核心组件的有效性验证
为了验证 ViT4TS 各模块的设计价值,作者在不同数据集上进行了系统性的消融研究,结果表明 ViT4TS 各组件对整体性能具有不可替代的作用:移除 patch-level 表示、cross-patch 匹配或多尺度嵌入均导致显著性能下降,分别验证了细粒度定位、跨窗口模式比对和多尺度上下文建模的必要性。尤为关键的是,若跳过 ViT4TS 直接调用 VLM 处理全序列图像,F1-max 在 Yahoo 等高密度异常数据集上大幅下滑,充分说明 ViT4TS 作为高召回率的视觉筛查器,为 VLM 提供了精准的候选区间,没有这一“粗筛”阶段,VLM 难以在复杂时序背景中可靠分离多个异常。
主干可扩展性:精度与效率的平衡
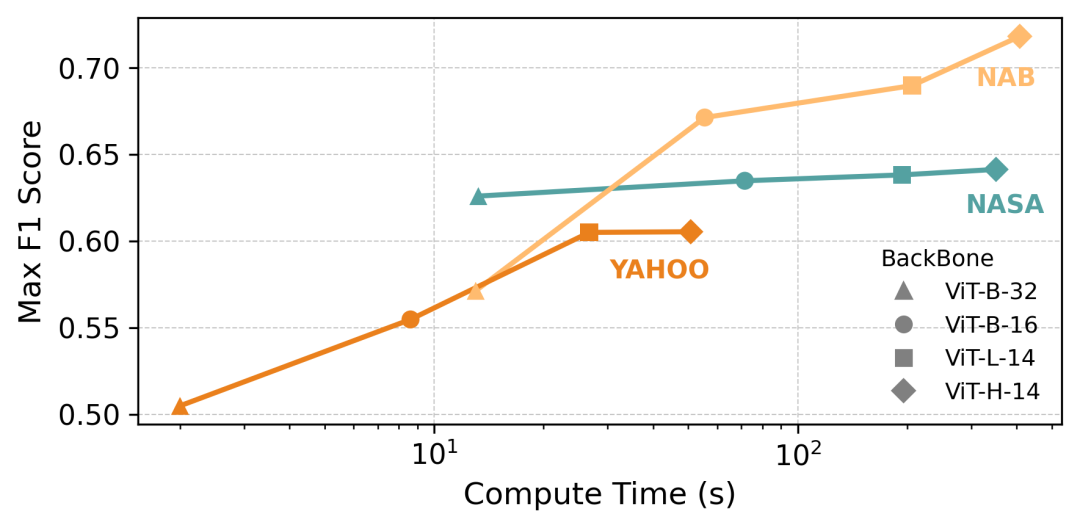
主干可扩展性:精度与效率的平衡
主干可扩展性:精度与效率的平衡
在主干可扩展性方面,实验显示 ViT 编码器的容量与检测精度呈正相关:更大模型(如 ViT-H/14)表现更优,但推理耗时显著增加。相比之下,默认的 ViT-B/16 在精度与效率之间取得良好平衡,既能维持高定位准确性,又满足工业部署对低延迟的要求,因此是实际应用中的推荐配置。
案例分析:遥测信号中的异常定位
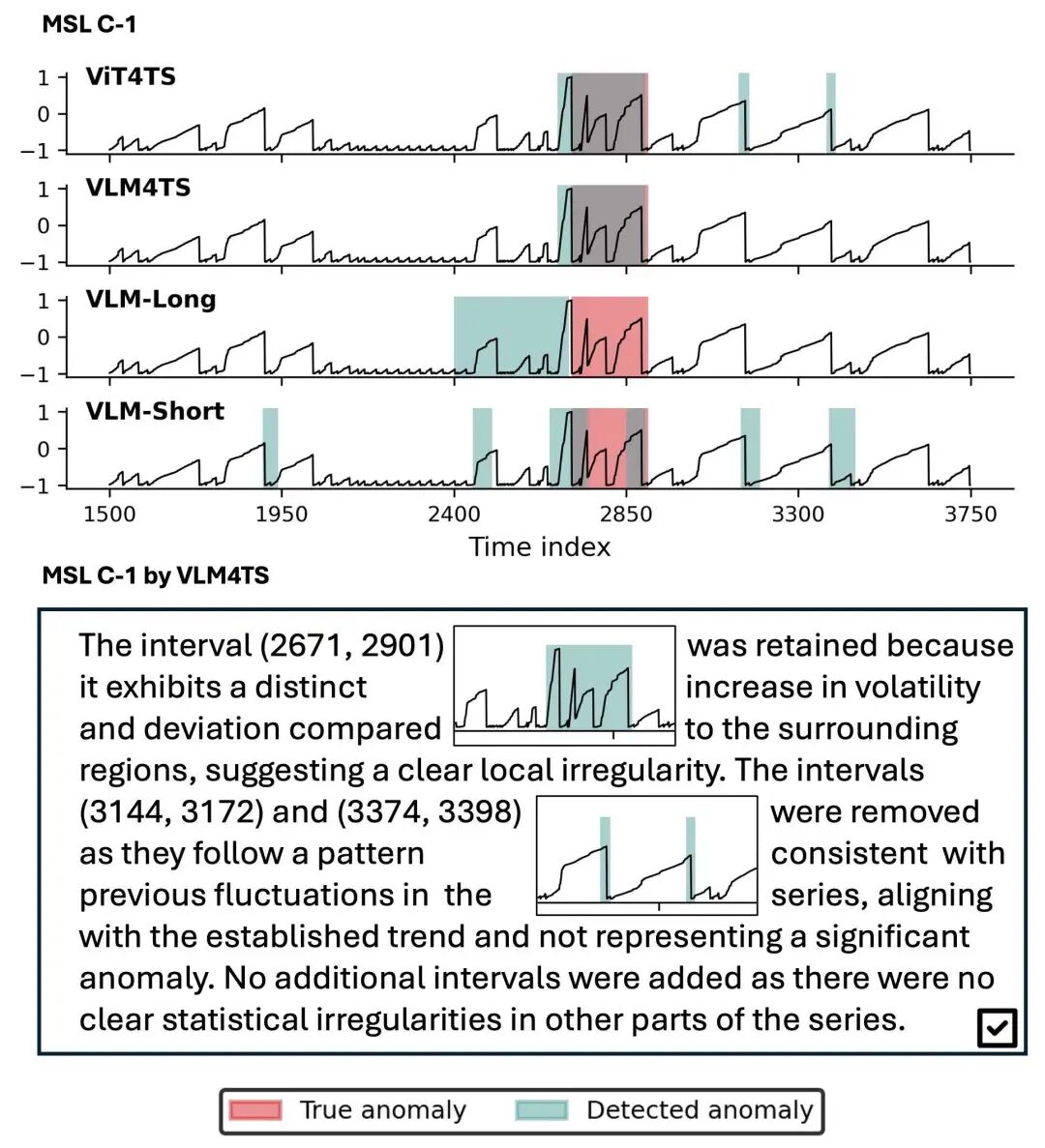
案例分析:遥测信号中的异常定位
案例分析:遥测信号中的异常定位
为直观展示 VLM4TS 的工作机理,作者选取了 NASA 数据集中的 MSL C-1 信号进行可视化分析(如图 Case Study 所示)。该信号包含多个复杂波动,其中真正的异常表现为局部形态畸变而非极端值。其中
- ViT4TS:作为第一阶段,成功捕捉到多个潜在异常区域(高召回),但包含误报,体现了其“广撒网”的筛查策略。
- VLM-Long:直接处理整条序列图像,虽能感知全局趋势,但因缺乏局部聚焦,导致检测边界模糊、定位不准。
- VLM-Short:对每个滑动窗口单独提问,受限于短时视野,易将正常波动误判为异常,产生大量假阳性。
- VLM4TS:通过“ViT4TS初筛 + VLM全局验证”,精准保留真实异常、剔除误报,实现高精度与高置信度的最终检测。
除上述内容外,论文还进行了多项补充实验以全面验证方法的鲁棒性与通用性,包括模型泛化性,超参敏感性,模块消融, 可视化, 多变量扩展等。为便于社区复现与应用,完整代码库已开源(GitHub),只需提供包含 timestamp 与 value 两列的 CSV 文件,即可一键运行 ViT4TS 筛选与 VLM4TS 验证全流程!
推荐阅读
IJCAI 2025 | 视觉模型如何颠覆时序分析?从成像到建模的完整路线图
NeurIPS 2025 | DMMV: 利用多模态的视角来解决视觉模型处理时间序列的偏置问题
如果觉得有帮助还请分享,在看,点赞
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-01-21,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号