AAAI 2026 | 基于 LLM 对齐的地理实体token化:快手LGSID框架优化本地生活服务推荐

AAAI 2026 | 基于 LLM 对齐的地理实体token化:快手LGSID框架优化本地生活服务推荐

时空探索之旅
发布于 2026-03-10 14:48:44
发布于 2026-03-10 14:48:44
论文标题:LLM-Aligned Geographic Item Tokenization for Local-Life Recommendation
作者:Hao Jiang, Guoquan Wang, Donglin Zhou, Sheng Yu, Yang Zeng, Wencong Zeng, Kun Gai(盖坤), Guorui Zhou(周国睿)
机构:快手科技
论文链接:https://arxiv.org/abs/2511.14221
代码:https://github.com/JiangHaoPG11/LGSID
Cool Paper:https://papers.cool/arxiv/2511.14221
TL;DR:LGSID 是快手面向本地生活推荐的 LLM 对齐地理语义token框架,聚焦解决现有模型 “重语义、轻地理” 的痛点。通过 RL-based 地理 LLM 对齐(G-DPO 算法注入空间与协同信号)和分层token化(主token + 残差token),让语义 ID 具备地理感知,在判别式与生成式推荐中均超越 SOTA,显著提升地理适配性与推荐性能。
关键词:LLM,tokenization,强化学习,本地生活推荐

摘要
大型语言模型(LLMs)的最新进展通过为传统的基于ID的方法赋予语义泛化能力,增强了基于文本的推荐效果。基于文本的方法通常通过提示词设计对物品的文本信息进行编码,并通过物品分词生成离散的语义ID。然而,在本地生活服务等特定领域任务中,仅仅将位置信息注入提示词无法捕捉物品间细粒度的空间特征和真实世界的距离感知。为解决这一问题,本文提出了LGSID,一种用于本地生活推荐的、与LLM对齐的地理物品分词框架。该框架包含两个关键组件:(1)基于强化学习(RL)的地理LLM对齐;(2)分层地理物品分词。在基于强化学习的对齐模块中,我们首先训练一个列表式奖励模型来捕捉物品间真实世界的空间关系。然后,我们引入一种新颖的G-DPO算法,该算法利用预训练的奖励模型将泛化的空间知识和协同信号注入LLMs,同时保留其语义理解能力。此外,我们提出了一种分层地理物品分词策略,其中主token源自离散的空间和内容属性,而残差token则利用对齐后的LLM的地理表示向量进行优化。在真实的快手行业数据集上进行的大量实验表明,LGSID在性能上持续优于最先进的判别式和生成式推荐模型。消融研究、可视化和案例研究进一步验证了其有效性。
Q: 这篇论文试图解决什么问题?
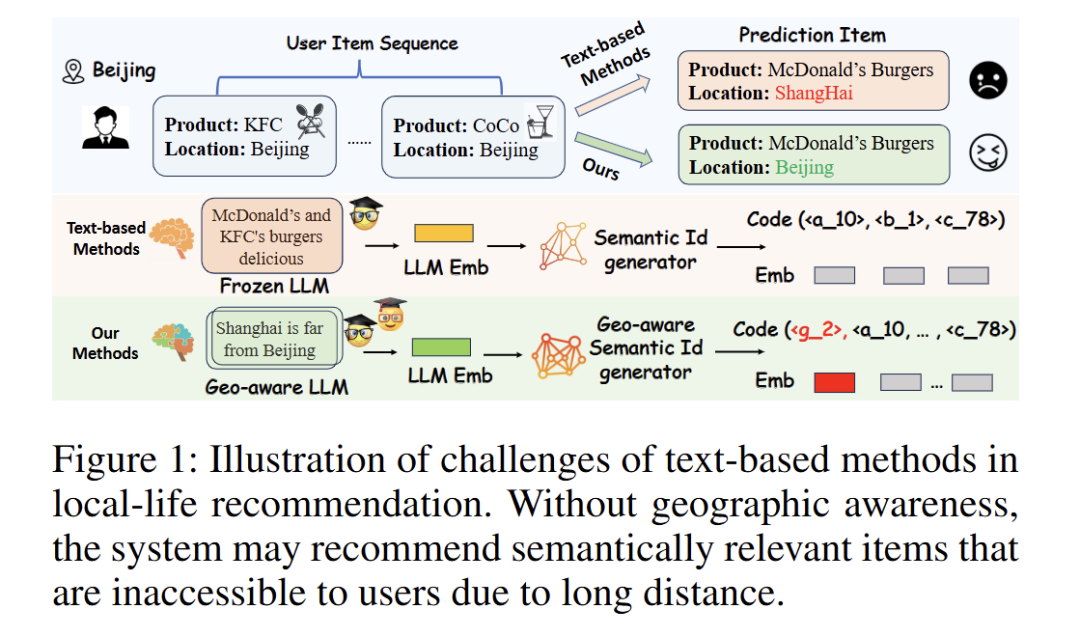
A: 论文针对本地生活(local-life)推荐场景下,现有文本驱动、基于大语言模型(LLM)的条目向量化(item tokenization)方法缺乏细粒度空间感知与真实地理距离意识的缺陷,提出 LGSID 框架,旨在:
- 让 LLM 同时具备语义理解与地理空间知识,避免“把上海餐厅推给北京用户”这类不可达推荐;
- 在tokenization阶段显式注入地理约束,使生成的语义 ID 天然携带“就近可达”属性;
- 缓解本地生活场景中因地理半径限制导致的交互稀疏、曝光不公平问题,提升推荐系统整体效率与用户体验。
Q: 有哪些相关研究?
A:
- Item Tokenization
- RQ-VAE / VQ-VAE 系列:TIGER、QARM、LETTER、EAGER、UTGRec、SC、UnifiedSID、ETEGRec 等
- N-gram / Cosine 语义 ID:Lin et al. 2025、Singh et al. 2024、Zheng et al. 2025b
- LLM Alignment for Recommendation
- 任务提示型:LGHRec、GNPR-SID、SIIT
- 监督微调型:NoteLLM / NoteLLM-2、AlignRec、LLMEmb、LARM、Lu et al. 2024
- 本地生活 / 空间感知推荐
- 连续 POI 推荐:Ma et al. 2024、Zhao et al. 2025
- 基于图或距离的 CF:Wu et al. 2021、Zhang et al. 2024c
- RL 与 DPO 优化
- 直接偏好优化 DPO:Rafailov et al. 2023
- 列表式排序与负采样:传统 Learning-to-Rank、密度感知采样策略
Q: 论文如何解决这个问题?
论文通过提出 LGSID 框架(LLM-Aligned Geographic Item Tokenization),从 “LLM 地理对齐” 和 “分层token化” 两个核心维度解决本地生活推荐的地理感知缺失问题,核心结论是:通过 RL-based 方法注入地理知识与协同信号,再结合分层量化策略,实现语义理解与地理邻近性的平衡。
LGSID
LGSID
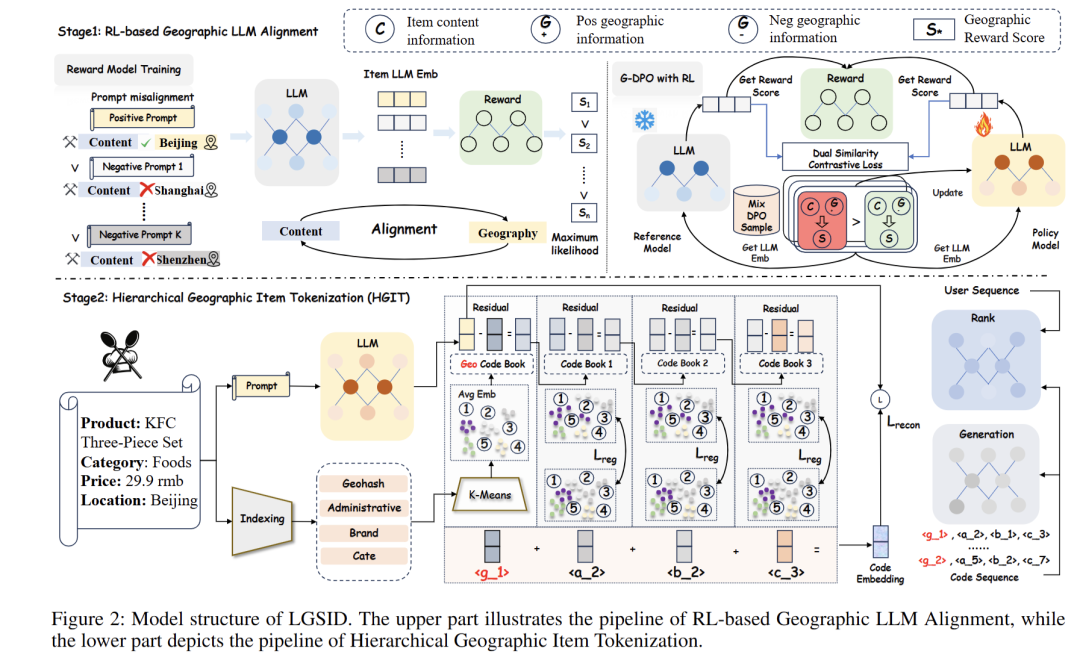
一、核心解决方案:LGSID 框架的两大模块
1. 模块一:RL-based 地理 LLM 对齐(注入地理与协同信号)
- 训练列表式地理奖励模型:基于经纬度计算哈夫辛距离(Haversine),采用密度感知硬负采样构建 “文本固定 + 地理位置替换” 的提示词序列,通过 MLP 预测 “物品内容 - 地理位置” 的相关性得分,让模型学习近距离优先的空间知识。
- 提出G-DPO 算法:融合领域协同对(用户高频共现物品对)和地理约束对(远距离负样本对),用预训练奖励模型指导 LLM 对齐,同时加入批内对比正则化损失,平衡语义准确性与地理感知,避免 LLM 优先语义而忽略距离。
2. 模块二:分层地理项token化(生成地理感知语义 ID)
- 主token生成:将地理编码(经纬度)、行政编码(省市县 ID)、品类 / 品牌编码加权拼接,通过 MiniBatch K-Means 聚类生成粗粒度地理token,确保基础地理约束。
- 残差token优化:基于对齐 LLM 的地理表征向量,用可学习聚类中心和欧氏距离分配细粒度token,叠加重构损失和熵正则化,避免聚类塌陷,同时保留语义细节。
二、关键辅助设计
- 提示词设计:将物品文本属性(名称、品类、价格)与地理属性(省市县)融合,为 LLM 提供统一的地理 - 文本输入。
- 多范式适配:同时支持判别式推荐(如 DIN、DIEN)和生成式推荐(如 TIGER、OneRec),通过语义 ID 适配不同推荐 pipeline。
Q: 论文做了哪些实验?
论文在快手本地生活真实工业数据集(5 000 万样本、232 万商品、1 908 万用户)上系统回答了 4 个研究问题,实验设计如下:
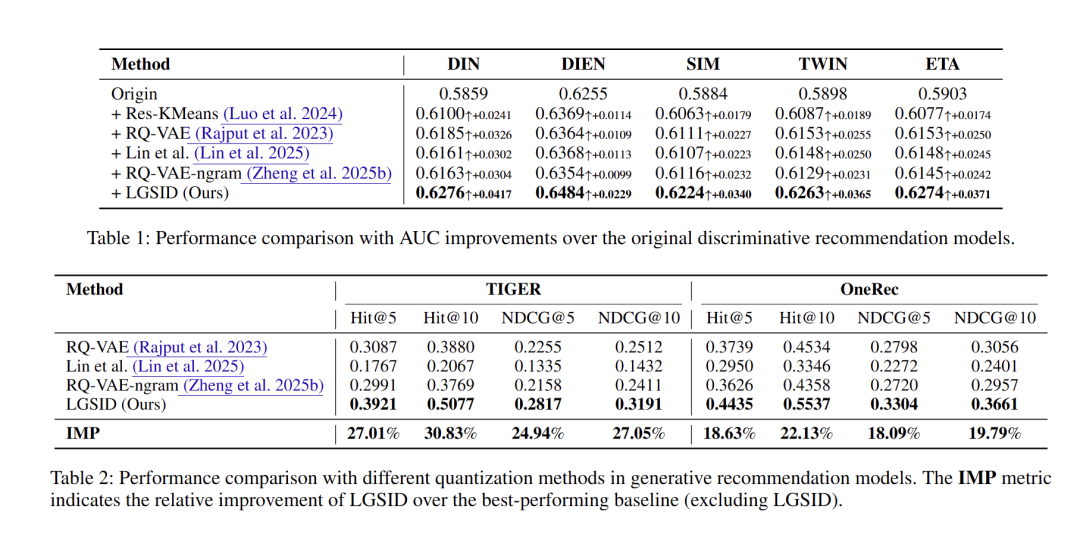
- RQ1 整体效果
- 判别式:将 LGSID 语义 ID 嵌入 DIN/DIEN/SIM/TWIN/ETA,对比原始模型与 Res-KMeans、RQ-VAE、RQ-VAE-ngram、Lin et al. 等量化方案,指标 AUC
- 生成式:替换 TIGER 与 OneRec 的量化器,指标 Hit@5/10、NDCG@5/10
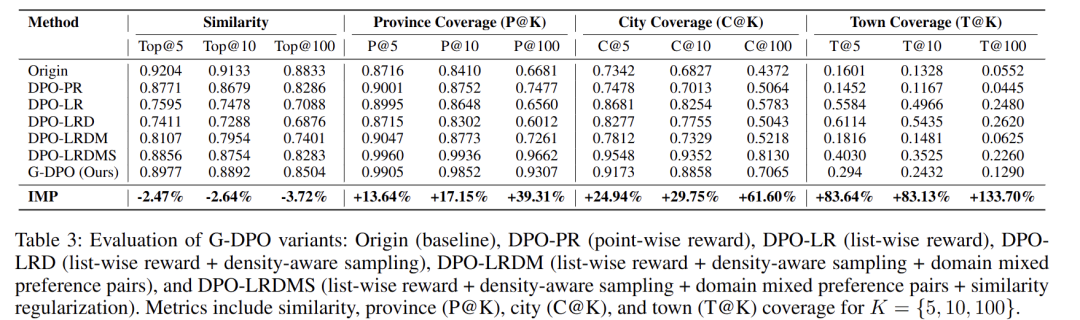
- RQ2 对齐消融逐步叠加“列表式奖励→密度感知采样→域混合偏好→相似性正则”,观测
- 语义保持:Top-K 余弦相似度
- 地理感知:省/市/区覆盖率 P@K、C@K、T@K
- RQ3 表示可视化
- t-SNE:对比 G-DPO 前后商品嵌入的省市区聚类,量化 NMI
- 雷达图:统计三级token在各分位点的覆盖量,验证层次量化对长尾的压缩能力

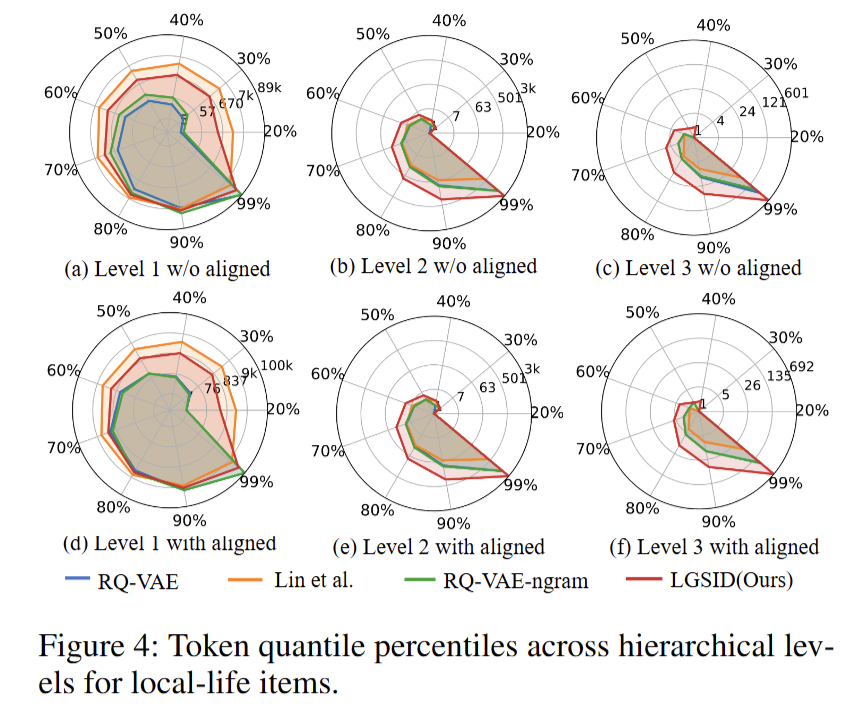
- RQ4 案例与稳健性
- 层次token分布:展示 BBQ、本地菜等品类在不同层级是否被“单根”聚合
- 6 随机种子:报告均值±SD、95% CI、IQR,Wilcoxon 检验显著性
- 超参敏感:调节相似性正则权重,展示语义-地理权衡曲线
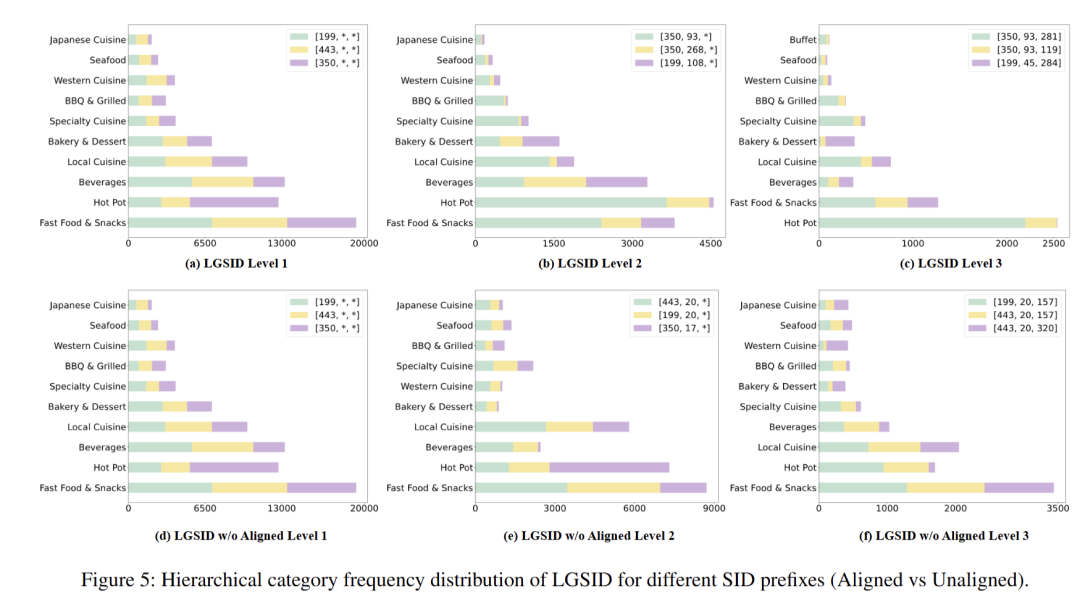

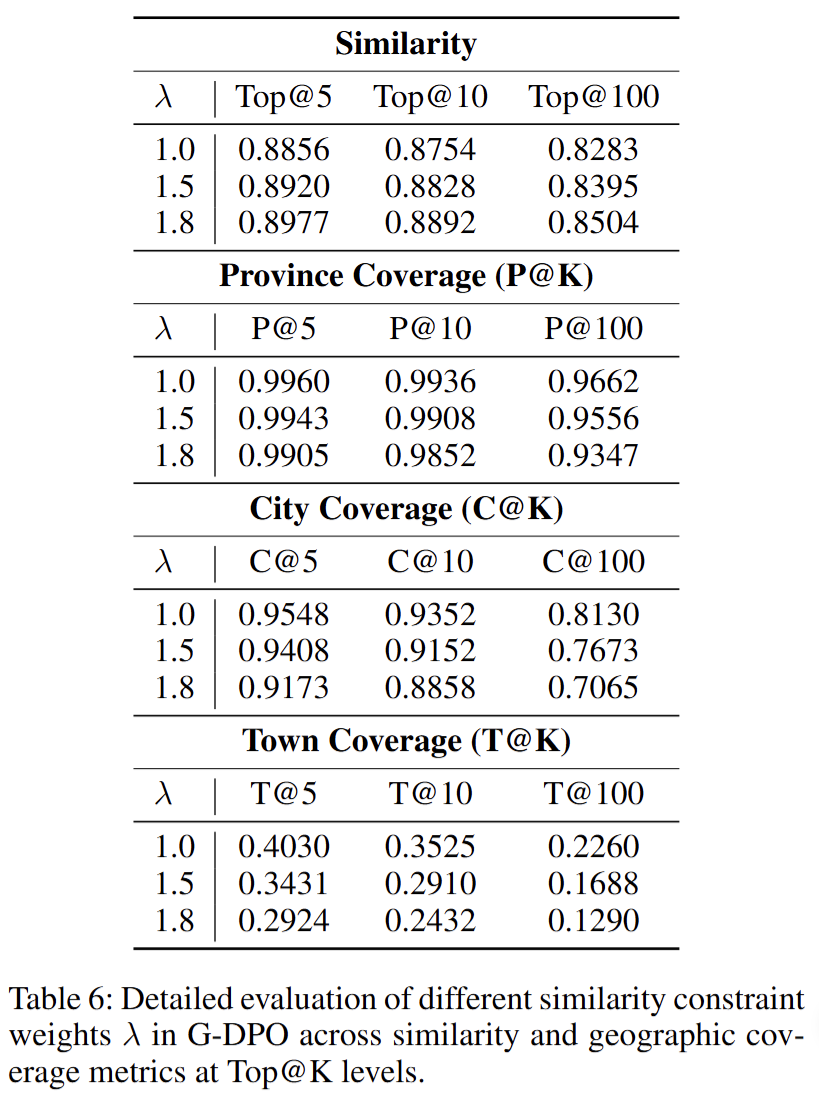
LGSID与OneLoc的区别与联系
论文标题:OneLoc: Geo-Aware Generative Recommender Systems for Local Life Service
作者:Zhipeng Wei, Kuo Cai, Junda She, Jie Chen, Minghao Chen, Yang Zeng, Qiang Luo, Wencong Zeng, Ruiming Tang(唐睿明), Kun Gai(盖坤), Guorui Zhou(周国睿)
论文链接:https://arxiv.org/abs/2508.14646
州懂学习笔记:快手OneLoc:本地生活场景的OneModel推荐
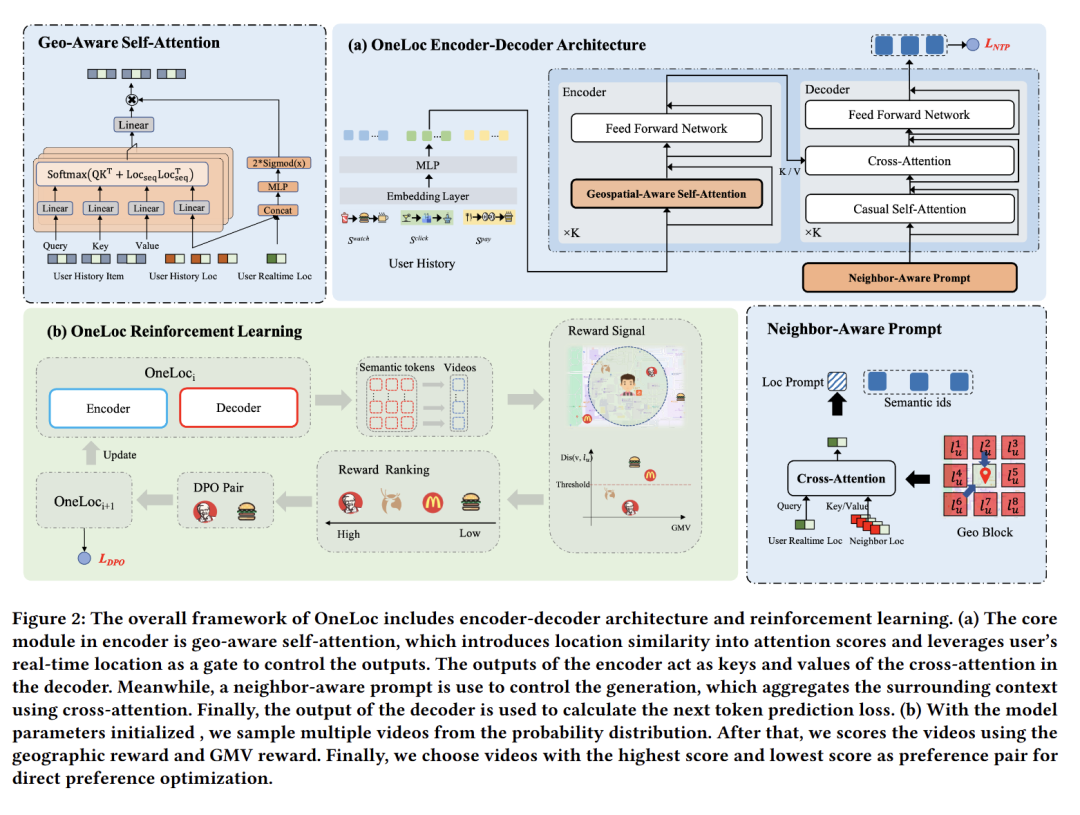
快手在今年8月份也挂出来一篇One系列的本地生活推荐的paper——OneLoc,这里也借助AI大模型梳理一下二者的异同。
两者均聚焦 “地理感知 + LLM 赋能”,但 LGSID 是通用的地理项token化框架,OneLoc 是端到端生成推荐系统,前者侧重 “token化优化”,后者侧重 “全流程落地”。
一、核心相同点
- 应用场景与核心痛点一致:均面向快手本地生活服务推荐,解决 “重语义、轻地理” 的核心问题,避免远距离无效推荐,需平衡用户兴趣与地理邻近性。
- 技术底座相通:都以 LLM 为基础,通过生成语义 ID(SID)融合地理信息与协同信号,采用强化学习(DPO 相关算法)优化模型对齐,依赖快手真实工业数据集验证。
- 核心设计思路重合:均重视地理信息的深度利用,通过多维度注入地理知识(表征层、模型层),兼顾用户兴趣与业务目标,支持判别式或生成式推荐场景。
二、核心差异点
1. 核心定位与技术重心
- LGSID:通用地理项token化框架,核心是优化 “语义 ID 的生成过程”,让 SID 本身具备地理感知,可作为组件嵌入各类推荐模型,通用性强。
- OneLoc:端到端生成推荐系统,核心是构建完整的生成式推荐流水线,直接输出推荐结果,侧重工业级部署与多业务目标平衡。
2. 地理信息融合方式
- LGSID:两阶段融合,先通过 RL+G-DPO 将地理知识注入 LLM,再通过分层token化(主token + 残差token)生成地理感知 SID,聚焦 “token化环节”。
- OneLoc:三维度融合,贯穿生成全流程 —— 地理感知 SID(表征层)、地理感知自注意力(编码器层)、邻居感知提示词(解码器层),覆盖 “生成全链路”。
3. 强化学习的作用与目标
- LGSID:RL 用于 LLM 地理对齐,奖励函数聚焦地理距离相关性,目标是提升 SID 的地理感知精度,间接优化推荐效果。
- OneLoc:RL 用于多目标平衡,设计双奖励函数(地理奖励 + GMV 奖励),直接对齐商业指标(GMV、订单量),目标是提升业务价值。
4. 模型结构与适配场景
- LGSID:无固定模型结构,输出的地理感知 SID 可适配判别式(DIN、DIEN)和生成式(TIGER)模型,适配性广。
- OneLoc:固定 encoder-decoder 生成式结构,整合多行为序列(观看、点击、购买),专门适配生成式推荐,端到端输出结果。
5. 实验与落地重点
- LGSID:侧重离线性能泛化,核心指标是 AUC、Recall、NDCG,强调在不同模型上的通用提升效果。
- OneLoc:侧重线上落地价值,核心指标是 GMV(+21.016%)、订单量(+17.891%),已全量部署服务 4 亿日活用户,商业落地属性更强。
三、总结
两者是快手在本地生活推荐领域的 “互补性探索”:LGSID 是 “通用技术组件”,解决语义 ID 的地理感知痛点,可赋能各类推荐模型;OneLoc 是 “完整系统方案”,基于生成式范式构建端到端系统,直接承接业务落地。技术路线相通,但 LGSID 偏学术通用框架,OneLoc 偏工业级业务落地。
推荐阅读
AI论文速读 | 2024[SIGIR] LLM4POI:基于大语言模型的下一个兴趣点(POI)推荐
此公众号的文章皆系本人原创,辛苦码字不易!如需转载,引用请注明出处。如商用联系作者。
如果觉得有帮助还请分享,在看,点赞
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-12-07,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号