龙虾之父亲推榜单揭露残酷真相:大模型正被“执行力”打脸,国产双雄赢了跑分却输了油钱
原创
龙虾之父亲推榜单揭露残酷真相:大模型正被“执行力”打脸,国产双雄赢了跑分却输了油钱
原创
用户12049556
发布于 2026-03-10 10:05:39
发布于 2026-03-10 10:05:39

fNaaZWzcG.jpeg
当全球几十万人正疯狂往自己的电脑上安装 OpenClaw(小龙虾)时,一个致命的现实问题挡在了所有狂热者面前:这只“虾”到底该装什么“脑子”?
选错模型,要么变成只会说废话的智障,要么变成一夜掏空信用卡的吞金兽。就在大众陷入“选型焦虑”之际,OpenClaw 之父出面背书了一份名为 PinchBench 的实时榜单。然而,这份专为智能体(Agent)量身定制的测试榜单,不仅狠狠撕下了传统大模型的遮羞布,更揭示了中国 AI 力量一个极其尴尬的反常识现状。
一、 传统评测的丧钟:会做奥数题,不代表会打工
与动辄考察大模型“懂不懂量子力学”或“会不会解微积分”的传统 Benchmark 不同,由 Kilo AI 团队推出的 PinchBench 只关心一件事:它能不能把活干完。
PinchBench 抛弃了传统的知识问答,直接将大模型扔进 23 个极其粗暴的真实工作流中:去查资料、去写邮件、去调 API、去生成报告。在这套包含“自动化脚本检查+大模型裁判(LLM Judge)”的严苛评价体系下,一个令人大跌眼镜的现象出现了——越大的模型,反而摔得越惨。
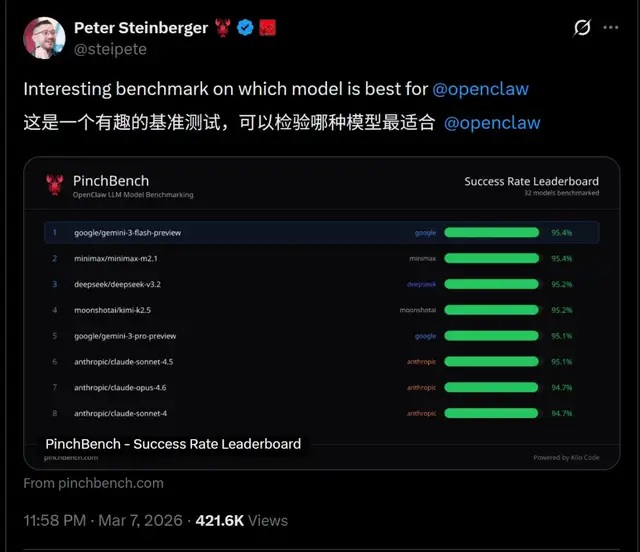
cf84485eeb3b994c23e01784a071ad50.jpg
榜单显示,那些拥有庞大参数量的主流“巨无霸”模型,在真实任务执行力上,往往被参数更小、专门针对 Agent 路径优化过的轻量级模型按在地上摩擦。
【笔者观点】 这是一个极具颠覆性的行业拐点信号。过去三年,整个科技界都在陷入“参数崇拜”,以为只要模型足够聪明(能写诗、能做题),就自然能成为优秀的助理。但这完全是个伪命题!Agent 时代需要的不是只会纸上谈兵的“哲学家”,而是能精准调用工具、不乱发散、指哪打哪的“数字蓝领”。PinchBench 的爆火,正式宣告了“大屏跑分时代”的终结,大模型厂商如果还沉浸在秀智商的幻觉里,必将在接下来的执行力战场上被迅速绞杀。
二、 国产模型的反常识突围:碾压了智商,却输给了账单
仔细看这份榜单,最让国人兴奋的,莫过于中国模型的强势霸榜。
在最核心的“成功率”(Success Rate)指标上,除了谷歌的 Gemini 3 Flash 以 95.1% 占据榜首,第二名和第三名均被中国企业包揽——MiniMax M2.1(93.6%)与 Kimi K2.5(93.4%)。而在“速度”(Speed)这个直接决定用户爽感的指标上,MiniMax 春节刚发布的 M2.5 模型更是直接登顶,将 Claude Opus 4.6 远远甩在身后。
但这真的是一场完美的胜利吗?榜单的第三个维度“价格”(Cost),给这场狂欢泼了一盆刺骨的冷水。
专为轻量级场景设计的 GPT-5-nano,输入和输出价格分别低至 0.05 美元和 0.40 美元/百万 tokens。相比之下,即使是国产模型中最便宜的 MiniMax M2.1,其综合使用成本也几乎是前者的 3 倍。
【笔者观点】 这正是当前国产大模型最痛的隐疾——我们造出了跑得最快的跑车,但用户却加不起油。在 OpenClaw 这种内置了“心跳机制”、需要 24 小时高频自唤醒的 Agent 生态中,Token 消耗量是指数级的。能力再强,如果商业成本无法做到“白菜价”,它就永远只能是少数极客的昂贵玩具,而无法成为普罗大众的基础设施。中国大模型在能力上确实跨越了鸿沟,但在极致的工程化压缩和算力成本控制上,我们依然被 OpenAI 牢牢卡着脖子。
三、 寻找“黄金分割点”:为什么选模型变成了走钢丝?
面对这份榜单,OpenClaw 的用户们陷入了深深的纠结:选谷歌,合规和网络是个大坑;选国产双雄,成功率极高但钱包在滴血;选便宜的 GPT-5-nano,在处理复杂连续动作时又可能掉链子。
PinchBench 给出的“最优解”,是那张横跨成功率与价格二维坐标系的散点图。在左上角的“高性价比黄金圈”内,一共圈出了 8 个模型,其中中国模型占据了半壁江山。这意味着,虽然我们在绝对低价上拼不过 OpenAI 的极限阉割版,但在“以相对合理的价格提供极高执行力”这个象限里,国产模型已经站稳了脚跟。
【笔者观点】 OpenClaw 带来的这场“全民养虾”运动,本质上是一次对全球 AI 算力供应链的极限压力测试。对于开发者和用户而言,闭眼选最贵、最大的模型已经成为最愚蠢的策略;未来的核心竞争力,在于如何根据具体的工作流(是高频简单的邮件,还是低频复杂的代码生成),在 PinchBench 这样的真实榜单中,精准找到那个“刚刚好”的套利空间。而对于中国的大模型创业者来说,紧迫感已经拉满:留给你们沾沾自喜“跑分第一”的时间不多了,2026 年下半场的生死战,不拼智商,只拼谁能把算力成本打到地板价。
👇 欢迎关注我的公众号
在 AI 爆发的深水区,我们一起探索真正能穿越周期的技术价值。
欢迎关注【睿见新世界】
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号