Iceberg:数据湖仓核心技术与AI赋能

Iceberg:数据湖仓核心技术与AI赋能

数据存储前沿技术
发布于 2026-03-09 18:06:28
发布于 2026-03-09 18:06:28
问题意识
在当今数据驱动的世界里,海量数据已成为企业宝贵的资产。然而,传统的数据湖架构,如基于Hive的系统,在面对ACID事务、并发控制、Schema演进以及大规模查询性能等挑战时,常常力不从心,甚至可能让数据资产沦为难以利用的“数据沼泽”。你是否也曾为数据一致性、小文件问题或复杂的元数据管理而头疼不已?
Apache Iceberg的出现,正是为了解决这些长期困扰数据工程师和分析师的痛点。它不仅仅是一种新的表格式,更是一种革命性的架构范式,旨在将数据湖提升为具备数据库级别可靠性和智能的“数据湖仓”(Lakehouse)。Iceberg通过其独特的三层架构——数据层、元数据层和目录层——彻底解耦了逻辑表定义与物理文件布局,从而实现了ACID事务、乐观并发控制、灵活的Schema演进、隐藏分区以及强大的时间旅行能力。
那么,Iceberg究竟是如何在对象存储之上构建起如此强大的数据管理能力的?它又将如何赋能未来的AI/ML工作流,并帮助我们从“数据负债”走向“数据资产”?本文将深入剖析Iceberg的核心机制、迁移策略及其在AI领域的巨大潜力,带你一探数据湖仓的未来。
阅读收获
- 理解Iceberg核心架构与优势: 掌握Iceberg三层架构(数据、元数据、目录)如何解决传统数据湖痛点,实现ACID事务、并发控制、Schema演进等数据库级能力。
- 掌握Iceberg迁移与集成策略: 了解从传统Hive数据湖向Iceberg湖仓迁移的实际路径(原地迁移、增量迁移、CDC影子迁移),以及与MinIO、Spark等生态组件的集成方法。
- 洞察Iceberg在AI/ML领域的应用: 认识Iceberg如何通过时间旅行、数据完整性、灵活特征管理和高效查询优化,为MLOps提供坚实基础,加速大规模模型训练。
- 把握Iceberg未来趋势与实施建议: 了解Iceberg V3新特性(删除向量、行级血缘等)对实时处理的推动,以及在组织中实施Iceberg的实用建议。

2025-07-31-Fig-2.png
第一部分:架构范式转变:对象存储上的Iceberg
本节将阐述Apache Iceberg的根本性架构创新,并解释其如何直接解决构建于对象存储之上的传统、类Hive数据湖所面临的长期挑战。
1.1 奠定基础的三层架构
Iceberg引入了一种结构化的三层架构,从逻辑上定义了一张表,并将其与底层的物理文件布局完全解耦 1。正是这一核心创新,使其所有其他高级功能成为可能。
- 数据层 (Data Layer):由实际的数据文件构成,通常采用Parquet、ORC或Avro等开放式列存格式,存储在MinIO或AWS S3等对象存储系统上。该层还包含用于支持行级别操作的“删除文件” (delete files) 1。
- 元数据层 (Metadata Layer):一个由文件构成的分层树状结构,用于追踪表的完整状态。它包含:
- 清单文件 (Manifest Files):这类元数据文件列出了一部分数据文件的信息,其中包含对查询规划至关重要的信息,如文件路径、分区数据、行数以及列级别的统计信息(例如最小值/最大值)1。
- 清单列表 (Manifest Lists):一个单独的文件,指向属于某个特定表“快照” (snapshot) 的所有清单文件。列表中的每个条目都包含关于对应清单文件的元数据,如其存储位置和分区边界 1。
- 表元数据文件 (Table Metadata Files):作为元数据树的根节点,这是一个JSON格式的文件,包含了表的当前Schema、分区规范、当前清单列表(即快照)的位置,以及所有历史快照的记录 1。
- 目录层 (Catalog Layer):所有操作的入口。目录的核心作用是将表名映射到其当前表元数据文件的位置。这个原子性的指针是实现事务保障的关键 4。目录可以通过多种服务实现,如REST Catalog、Hive Metastore或AWS Glue 2。
下图表清晰地展示了Iceberg的表架构:
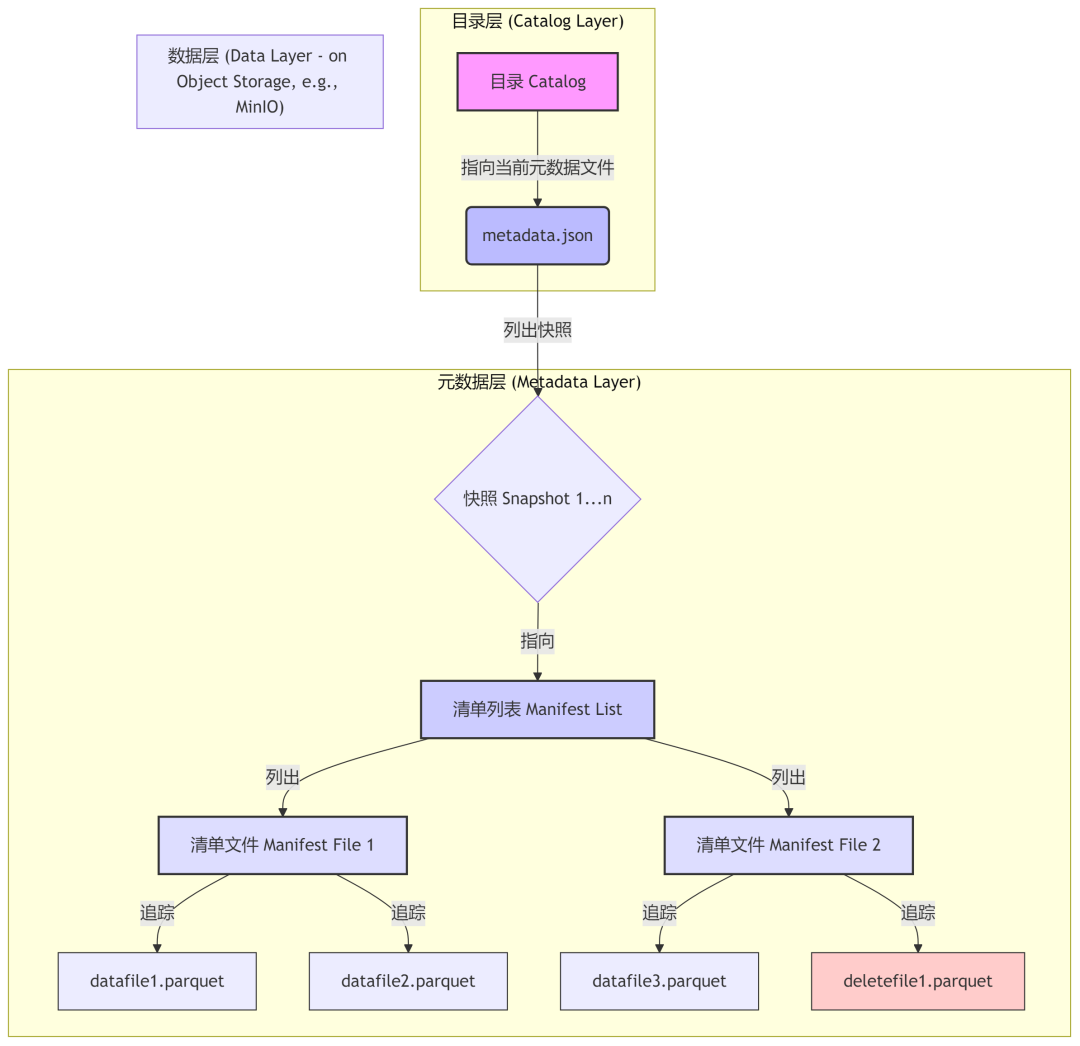
2025-07-31-Fig.png
1.2 解决核心数据湖挑战
传统的类Hive数据湖存在系统性问题:缺乏ACID事务、并发性能差、数据治理不一致以及随着规模扩大性能急剧下降,最终往往导致数据资产变成无法使用的“数据沼泽” 8。Iceberg的设计初衷就是为数据湖带来数据库级别的可靠性和智能,从而将其转变为“数据湖仓” (Lakehouse)。
Iceberg 之前的数仓实践
在 Iceberg 出现之前,数据湖的数仓能力主要通过以下几种方式实现,尽管它们在可靠性、性能和管理性方面存在局限:
1. 基于 Hadoop 和文件系统的原始存储
早期的数据湖通常构建在 HDFS 或云存储(如 S3)之上,数据以开放格式(如 Parquet、ORC、Avro)存储。用户通过批处理引擎(如 MapReduce、Spark)读取和处理这些文件,实现类似数仓的 ETL 和分析功能。
- 优点:成本低、扩展性强、支持半结构化和非结构化数据。
- 缺点:缺乏事务支持、元数据管理弱、难以保证数据一致性。
2. Hive Metastore + 文件命名约定
Apache Hive 被广泛用于为数据湖提供元数据管理。通过 Hive Metastore,用户可以定义数据库、表、分区等,使得数据湖具备一定的“表”语义。
- 实现方式:将底层文件路径映射为逻辑表,通过分区字段(如
dt=2023-01-01)组织数据。 - 局限性:
- 不支持 ACID 事务(早期版本)。
- “小文件问题”严重。
- 更新、删除操作困难,通常只能追加或覆盖整个分区。
3. Compaction 与分区管理(手动或脚本)
为了提升查询性能,用户通过定期合并小文件(compaction)和优化分区策略来模拟数仓的性能优化机制。
- 常见做法:使用 Spark 或 Hive 脚本定期重写分区数据为更大、更高效的文件。
- 问题:流程复杂、易出错、缺乏自动化。
4. 上层计算引擎的增强(如 Spark SQL)
Spark SQL 等引擎提供了强大的 SQL 接口,允许用户在数据湖上执行复杂的分析查询,模拟传统数仓的查询能力。
- 支持:SQL 查询、视图、UDF、Catalyst 优化器。
- 局限:仍依赖底层文件系统的“最终一致性”,无法保证写入时的原子性和隔离性。
5. Delta Lake 和 Hudi 的早期探索(Iceberg 前期的改进方案)
在 Iceberg 之前,Delta Lake(Databricks)和 Apache Hudi 已开始尝试为数据湖引入事务、UPSERT、时间旅行等能力。
- Hudi:支持记录级更新、增量拉取(incremental pull)。
- Delta Lake:基于 Parquet + 事务日志(Delta Log),实现 ACID。
- 这些系统为“湖仓一体”奠定了基础,但各有生态绑定问题(如 Delta Lake 与 Databricks 深度绑定)。
在 Iceberg 出现前,数据湖虽能存储海量数据并支持分析,但缺乏:
- 可靠的事务支持
- 高效的元数据管理
- 表级别的原子操作
- 多引擎兼容性(Spark、Flink、Presto 等)
Iceberg 的设计初衷就是为数据湖带来数据库级别的可靠性和智能,从而将其转变为“数据湖仓” (Lakehouse) —— 它通过标准化的表格式、ACID 事务、模式演进、隐藏分区、快照隔离等特性,弥补了传统数据湖在数仓能力上的短板,实现了真正的“湖仓一体”。 3。
下表对不同数据湖架构进行了直接的功能特性对比,清晰地展示了从Hive到Iceberg的范式转变。这种对比方式综合了多个来源的信息 8,为决策者提供了一个简洁明了的视图,直接回答了Iceberg解决了哪些根本性问题。
特性 | 传统类Hive数据湖 | 基于Iceberg的数据湖仓 |
|---|---|---|
事务支持 | 无原生ACID支持。操作非原子性,在并发写入或作业失败时易导致数据损坏和状态不一致 8。 | 完全符合ACID。写入操作是原子、一致、隔离且持久的。变更在单次操作中提交,防止部分写入,确保读取者看到一致的视图 3。 |
并发控制 | 并发能力有限,常依赖分区或表级别的悲观锁,这会阻塞其他读写操作 8。 | 乐观并发控制 (OCC)。允许多个写入者同时操作。仅在提交时通过一次原子性的目录操作检查冲突,从而最大化吞吐量 6。 |
查询性能 | 性能随表大小和分区数量增加而下降。查询规划需要对对象存储目录进行缓慢且昂贵的list操作($O(n)$复杂度)10。 | 高且稳定的性能。查询规划是$O(1)$复杂度的元数据操作,与表大小无关。通过读取包含文件列表和丰富统计信息的清单文件进行剪枝,完全避免了目录列表操作 6。 |
Schema演进 | 脆弱且高风险。添加或重命名列可能损坏数据或需要重写整个表。变更缺乏中央跟踪机制 9。 | 安全且灵活。列通过唯一ID而非名称进行跟踪。添加、删除、重命名、重排序和类型提升等操作是快速的元数据变更,无需重写数据 3。 |
分区演进 | 不重写整个表就无法实现。物理目录结构定义了分区方案,使其僵化且永久 10。 | 支持。分区方案可随时间推移而改变,无需重写旧数据。Iceberg在元数据中跟踪分区规范,允许具有不同布局的新旧数据在同一张表中并存 11。 |
数据版本控制 | 无原生支持。需要复杂的自定义解决方案来追踪历史数据状态 8。 | 完全支持时间旅行 (Time Travel) 和回滚 (Rollback)。每次变更都会创建一个新的、不可变的表快照,允许用户查询历史数据并轻松恢复到之前的已知良好状态 4。 |
1.3 可靠性机制:原子提交与目录的角色
Iceberg的可靠性关键在于其提交过程。一次写入操作涉及创建新的数据文件、追踪这些文件的新清单文件、为新快照创建新的清单列表,最后生成一个新的顶级元数据文件。
整个操作的原子性通过最后一步实现:在目录中执行一次原子的“比较并交换” (Compare-And-Swap, CAS) 操作,将指向旧元数据文件的指针更新为指向新文件 2。如果CAS操作失败(例如,由于并发写入),整个事务将被中止并重试,确保任何部分写入的状态都永远不会对外部可见。
这种设计揭示了一个深刻的转变:目录不再仅仅是一个服务发现机制,它已成为整个数据湖的事务协调器。通过将最终的提交步骤集中于一次单一的、原子性的指针交换,Iceberg成功地将一个成熟的数据库模式应用于分布式文件系统,从而在对象存储之上实现了可串行化的隔离级别。这意味着目录实现(如Hive Metastore、Nessie或AWS Glue)的选择是一项至关重要的架构决策。目录能否可靠地执行原子CAS操作,是Iceberg所有一致性和并发性保证的基石。一个实现不佳或非事务性的目录将破坏整个模型的可靠性,这使得目录从一个简单的组件上升为数据湖仓可靠性的核心。
第二部分:集成与迁移:从遗留数据湖到现代数据湖仓
本节将详细介绍采用Iceberg的实际步骤和架构考量,重点解决从传统的基于Parquet/Hive的设置过渡的问题。
2.1 采用Iceberg的基础性变革
采用Iceberg不仅仅是更换一个库,它要求思维方式的转变——从管理目录转向通过目录管理表。
- 目录设置:第一步是选择并配置一个Iceberg目录。选项包括利用现有的Hive Metastore (type=hive)、使用AWS Glue等云原生服务,或部署像Nessie这样的专用REST目录 7。选择取决于现有生态系统和期望的功能(例如,Nessie提供类Git的数据版本控制)。
- 计算引擎配置:像Spark或Trino这样的查询引擎必须配置为使用Iceberg目录及其针对底层存储的特定FileIO实现(例如,为MinIO/S3配置S3FileIO)19。这涉及到添加正确的Iceberg运行时JAR包并设置SQL目录属性。
- 存储配置:像MinIO这样的对象存储是Iceberg的理想搭档,因为它提供了Iceberg设计之初所依赖的可扩展、持久且兼容S3的后端。MinIO本身无需特殊配置,因为Iceberg的S3FileIO会处理所有交互 20。
2.2 战略性迁移路径
迁移PB级的Hive表需要一个谨慎、分阶段的策略,以最大限度地减少停机时间和风险 18。
- 原地迁移 (migrate过程):对于一次性转换,可以使用Spark的migrate过程。它读取Hive表的元数据并创建一个新的Iceberg表,将现有的数据文件集成到Iceberg的元数据结构中,而无需重写数据本身 18。
- 增量迁移 (add_files过程):对于仍在被活跃写入的表,add_files过程允许增量地将Hive表中的新文件或分区添加到相应的Iceberg表中 18。
- 零停机“影子”迁移 (CDC):一种非常稳健的方法是创建一个“影子”Iceberg表,并使用变更数据捕获 (Change Data Capture, CDC) 管道使其与活动的Hive表保持同步。正如Natural Intelligence的迁移案例所述,来自Hive Metastore的事件(如UpdatePartition)可以触发一个流程,将更新后的分区数据复制到Iceberg表中。这使得在切换消费者之前可以进行彻底的验证 24。
下图表展示了基于CDC的Hive到Iceberg迁移流程:
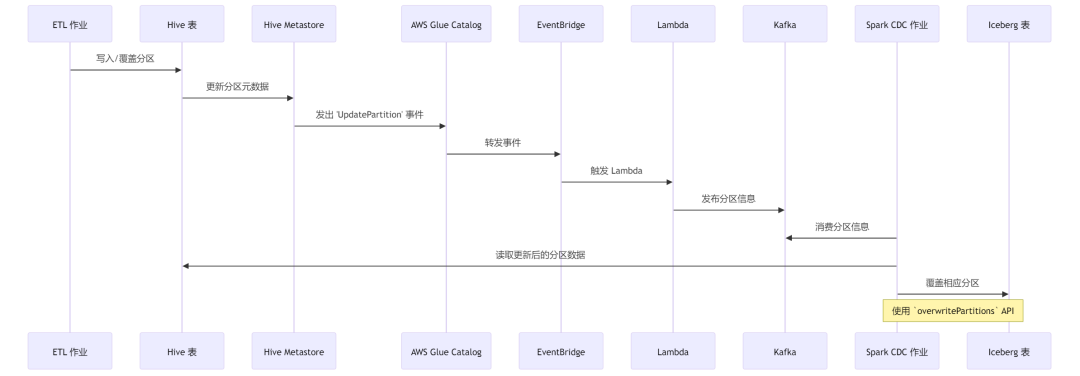
2025-07-31-Fig-1.png
2.3 参考架构:Iceberg与MinIO和Spark的结合
该架构展示了一个解耦的、开放的数据湖仓。
- MinIO (存储层):作为所有与表相关工件的单一、统一的存储库。这包括原始数据文件(如Parquet),但关键是,也包括所有的Iceberg元数据:metadata.json文件、*.avro格式的清单列表和清单文件,以及任何关联的puffin或删除文件。MinIO的S3 API兼容性、高性能和可扩展性使其成为理想的基础 20。
- Spark (计算层):用于读写的处理引擎。Spark不存储任何表的状态。当提交查询时,Spark连接到目录以定位表在MinIO上的当前元数据文件。然后,它从MinIO读取元数据树(清单等)来规划查询,最后仅从MinIO读取必要的原始数据文件来执行查询 19。
- Iceberg目录 (协调层):作为“事实之源”,指向存储在MinIO中的正确版本的表元数据。它确保所有Spark应用程序(以及Trino等其他引擎)都能看到一致的数据视图 22。
这种架构体现了计算的无状态性和 “数据即代码” 的范式。参考架构清晰地展示了关注点的分离:MinIO持有状态(数据+元数据),目录持有指针,而Spark是执行逻辑的、短暂的无状态引擎。这与传统系统中引擎常与存储布局紧密耦合的情况形成了鲜明对比。其深层含义是,表的整个状态和历史记录都自包含并版本化于对象存储中。这种方式将数据资产视为类似于Git仓库中的源代码。计算引擎就像编译器,可以被替换、升级或独立扩展,而不会影响“源代码”(即数据)。正是这种架构的纯粹性,才使得多引擎互操作性 26 和操作灵活性成为可能,这些都是Iceberg生态系统的标志性特征。
第三部分:AI创新的催化剂:Iceberg的优势
本节将探讨Iceberg的特定功能如何为现代人工智能和机器学习工作流奠定卓越的基础,以应对关键的MLOps挑战。
3.1 MLOps的坚实基础
AI/ML工作流对规模、多样性和速度的要求,是传统数据实践难以满足的。Iceberg为此提供了必要的基础 28。
- 通过时间旅行实现可复现性:MLOps的一个关键要求是能够复现实验。Iceberg的不可变快照和时间旅行功能允许数据科学家查询数据集在特定时间点或特定快照ID时的确切状态。这消除了数据相关的可变性,确保模型训练运行是一致且可比较的 4。
- 数据完整性与一致性:ACID事务确保训练数据永远不会处于部分或损坏的状态。并发的特征工程管道可以向同一个特征表写入数据而不会引发数据完整性问题,从而为模型训练提供可靠、一致的数据 4。
Iceberg的出现,将数据从ML流程中的一个易变、不可靠的负债,转变为一个版本可控的资产。在传统模式下,ML实验失败和不可复现的一个主要根源是数据的可变性。一个今天在s3://bucket/features/上训练的模型,其行为会与明天训练的模型不同,因为数据已经改变。Iceberg从根本上改变了数据的身份。数据不再是某个路径下的一个无定形、可变的二进制大对象,而是一个有版本的、不可变的快照(例如table@snapshot_id)。这使得ML团队能够以管理代码和模型的纪律来管理数据。这种转变将数据湖从一个混乱的数据源提升为MLOps生命周期中的一等、版本可控的工件,直接赋能了以数据为中心的AI开发。
3.2 构建高性能特征存储
Iceberg是实现特征存储 (Feature Store) 的理想技术,后者是MLOps中用于管理和提供ML特征的核心组件 17。
- 灵活的特征管理:Schema演进功能允许数据科学团队添加、更新或删除特征,而无需重写数据或破坏下游管道。这种敏捷性在特征工程的迭代过程中至关重要 28。
- 时间点准确性:时间旅行对于提供历史准确的特征至关重要,可以防止将未来的数据泄露到训练集中。一个针对特定事件日期进行训练的模型,可以查询该日期的特征存储 (AS OF that date) 以获取正确的特征值 28。
- 高效的更新:SQL的MERGE操作提供了一种富有表现力的、声明式的方式来更新或插入(upsert)新的特征值到存储中,从而简化了特征注入管道的逻辑 17。
3.3 加速大规模模型训练
高效地访问和处理PB级训练数据是一个主要瓶颈。Iceberg的性能特性直接解决了这个问题。
- 智能文件剪枝:Iceberg的清单文件为每个数据文件存储了丰富的列级别统计信息(如最小值/最大值、空值计数)。查询引擎利用这些元数据来剪除那些不包含查询所需数据的整个文件和分区,从而极大地减少I/O并加速数据访问 4。
- 隐藏分区:此功能将物理数据布局从用户面前抽象出来。数据工程师可以演进分区方案以优化不断变化的查询模式,而无需数据科学家修改他们的查询。引擎会自动使用最优的分区布局进行剪枝 3。
- 使用Puffin进行高级统计:为了实现更复杂的查询优化,Iceberg支持Puffin文件。这些文件存储高级统计信息,如通过Theta Sketch算法计算的唯一值数量 (Number of Distinct Values, NDV),这些信息因体积过大而无法存放在清单文件中。Trino和Athena等引擎中的成本优化器 (Cost-Based Optimizer, CBO) 会利用这些NDV统计信息来做出更优的连接顺序和执行计划决策,进一步提升复杂训练数据查询的性能 1。
第四部分:未来轨迹与战略建议
本节将基于V3规范分析Iceberg的未来发展方向,并为考虑采用的组织提供可操作的建议。
4.1 新前沿:Iceberg V3与迈向实时之路
最近被批准的Iceberg V3规范引入了强大的新功能,扩展了其应用场景 33。
- 删除向量 (Deletion Vectors):一种更高效的行级删除格式,显著提升了读时合并 (Merge-on-Read, MOR) 策略的性能。这减少了写放大,使Iceberg更适用于流式处理和高频更新的工作负载 33。
- 行级血缘 (Row Lineage):引入了系统列(_row_id, _last_updated_sequence_number),明确追踪行随时间的变化。这为变更数据捕获 (CDC) 工作流提供了内置支持,简化了下游复制和物化视图的维护 33。
- 扩展的数据类型:增加了对半结构化 (variant) 和地理空间 (geometry, geography) 数据的支持,使Iceberg成为一个更通用的格式,能适应更广泛的现代应用 33。
Iceberg的发展轨迹清晰地展示了其从一个批处理分析格式向一个统一的事务性格式的演进。 V1版本专注于解决大规模批处理分析的问题 34。 V2版本引入了行级删除,为事务性用例打开了大门。 而V3版本中的特性——特别是删除向量和行级血缘——明确指向了对实时和流处理能力的战略性推动 33。删除向量优化了流式摄入中常见的频繁、小批量更新;行级血缘则是CDC的规范定义。这表明Iceberg不再仅仅是一个“更好的Hive”,它正在演变成一个能够在一个数据副本上统一批处理、交互式查询、流处理和CDC工作负载的通用格式。这一发展轨迹将Iceberg定位为真正统一的数据湖仓的核心表格式,打破了分析系统和操作型数据系统之间的最后壁垒。
4.2 行业采纳与生态系统成熟度
Iceberg并非一项实验性技术;它经过了实战检验,并被领先的科技公司大规模使用,包括其创建者Netflix以及苹果、Adobe和Expedia等主要采纳者 12。
这种广泛的采纳催生了一个丰富而开放的生态系统。Iceberg已成为主流查询引擎(Spark、Trino、Flink)和数据平台(Snowflake、Dremio、Starburst、AWS、Google Cloud)中的一等公民,确保了广泛的兼容性并避免了供应商锁定 14。
可操作的实施建议
- 从试点项目开始:选择一个非关键但具有代表性的工作负载开始,以积累经验和建立内部专业知识。迁移几个关键的Hive表是一个常见的起点 6。
- 制定目录策略:作为事务处理的关键,目录的选择至关重要。根据您当前的基础设施(例如,对于现有的Hadoop/Spark生态系统,可使用Hive Metastore)和未来需求(例如,考虑使用Nessie以获得类Git的数据版本控制)来评估选项。
- 拥抱声明式数据工程:充分利用Iceberg的声明式特性。使用SQL MERGE构建幂等的数据管道,并设置表属性来控制写入顺序和文件大小,让引擎处理实现细节。这能让工程师专注于更高价值的数据建模和治理任务 29。
- 规划优化:虽然Iceberg提供了显著的开箱即用性能,但仍需规划持续的优化。实施自动化的压缩作业来管理小文件,并考虑为关键查询工作负载生成Puffin高级统计信息,以最大化性能和成本效益。
参考资料
- Apache Iceberg: The Definitive Guide - Dremio, accessed on July 31, 2025, https://www.dremio.com/wp-content/uploads/2023/02/apache-iceberg-TDG_ER1.pdf
- Apache Iceberg Architecture: 3 Core Components to Understand - Atlan, accessed on July 31, 2025, https://atlan.com/know/iceberg/apache-iceberg-architecture/
- Apache Iceberg Tutorial: The Ultimate Guide for Beginners | Estuary, accessed on July 31, 2025, https://estuary.dev/blog/apache-iceberg-tutorial-guide/
- What is Apache Iceberg? Benefits and use cases | Google Cloud, accessed on July 31, 2025, https://cloud.google.com/discover/what-is-apache-iceberg
- Apache Iceberg Series: Part 1 — Iceberg Architecture | by Jaime Andres Salas, accessed on July 31, 2025, https://blog.infostrux.com/apache-iceberg-the-unofficial-review-part-1-iceberg-architecture-7bfabed461de
- How Apache Iceberg Actually Works | by Thomas F McGeehan V | Medium, accessed on July 31, 2025, https://medium.com/@tfmv/how-apache-iceberg-actually-works-64f97fb13c45
- A deep dive into the concept and world of Apache Iceberg Catalogs - DEV Community, accessed on July 31, 2025, https://dev.to/alexmercedcoder/a-deep-dive-into-the-concept-and-world-of-apache-iceberg-catalogs-2dl2
- Data Lake vs Data Lakehouse: The Evolution of Data Storage - Airbyte, accessed on July 31, 2025, https://airbyte.com/data-engineering-resources/data-lake-vs-data-lakehouse
- Explaining Data Lakes, Lakehouses, Table Formats and Catalogs - Estuary.dev, accessed on July 31, 2025, https://estuary.dev/blog/explaining-data-lakes-lakehouses-catalogs/
- Hive Metastore's Dilemma: Performance Limits - lakeFS, accessed on July 31, 2025, https://lakefs.io/blog/hive-metastore-it-didnt-age-well/
- Apache Iceberg | What is it? Why Use It? - Starburst, accessed on July 31, 2025, https://www.starburst.io/blog/apache-iceberg/
- Apache Hudi vs. Apache Iceberg: 2025 Evaluation Guide - Atlan, accessed on July 31, 2025, https://atlan.com/know/iceberg/apache-hudi-vs-iceberg/
- Spec - Apache Iceberg™, accessed on July 31, 2025, https://iceberg.apache.org/spec/
- The Apache Iceberg Avalanche: How the Open Table Format Changes the Face of Data Lakes - Snowflake, accessed on July 31, 2025, https://www.snowflake.com/en/blog/apache-iceberg-data-lakehouse-architecture/
- My Adventure with Apache Iceberg: Migrating a Local Hive Data Warehouse (POC) | by Stefentaime | Medium, accessed on July 31, 2025, https://medium.com/@stefentaime_10958/my-adventure-with-apache-iceberg-migrating-a-local-hive-data-warehouse-poc-b494a50a04b5
- What Is Apache Iceberg? Features & Benefits - Dremio, accessed on July 31, 2025, https://www.dremio.com/resources/guides/apache-iceberg/
- Apache Iceberg Intro— Day 65 of 100 Days of Data Engineering, AI and Azure Challenge, accessed on July 31, 2025, https://medium.com/@krthiak/apache-iceberg-intro-day-65-of-100-days-of-data-engineering-ai-and-azure-challenge-4512297837c3
- Migration Guide for Apache Iceberg Lakehouses - Dremio, accessed on July 31, 2025, https://www.dremio.com/blog/migration-guide-for-apache-iceberg-lakehouses/
- Turning Data into Insight: Flexible Lakehouse with MinIO, Iceberg, Airflow, DBT, Spark, Pandera & Superset | by Bayu Setiawan | Towards Dev - Medium, accessed on July 31, 2025, https://medium.com/towardsdev/turning-data-into-insight-flexible-lakehouse-with-minio-iceberg-airflow-dbt-spark-pandera-409d036e5542
- The Definitive Guide to Lakehouse Architecture with Iceberg and MinIO, accessed on July 31, 2025, https://blog.min.io/lakehouse-architecture-iceberg-minio/
- Learning Apache Iceberg — storing the data to Minio S3 | by Marin Aglić | Medium, accessed on July 31, 2025, https://medium.com/@MarinAgli1/learning-apache-iceberg-storing-the-data-to-minio-s3-56670cef199d
- A Developer's Introduction to Apache Iceberg using MinIO, accessed on July 31, 2025, https://blog.min.io/a-developers-introduction-to-apache-iceberg-using-minio/
- Apache Iceberg: Things to know before migrating your data lake | Decube, accessed on July 31, 2025, https://www.decube.io/post/apache-iceberg-migrate-data-lake
- Melting the ice — How Natural Intelligence simplified a data lake migration to Apache Iceberg | AWS Big Data Blog, accessed on July 31, 2025, https://aws.amazon.com/blogs/big-data/melting-the-ice-how-natural-intelligence-simplified-a-data-lake-migration-to-apache-iceberg/
- Hands-on with Apache Iceberg on Your Laptop: Deep Dive with Apache Spark, Nessie, Minio, Dremio, Polars and Seaborn - DEV Community, accessed on July 31, 2025, https://dev.to/alexmercedcoder/hands-on-with-apache-iceberg-on-your-laptop-deep-dive-with-apache-spark-nessie-minio-dremio-polars-and-seaborn-2hgk
- ivrore/apache-iceberg-minio-spark - GitHub, accessed on July 31, 2025, https://github.com/ivrore/apache-iceberg-minio-spark
- What Is Apache Iceberg? How It Works, Benefits, & Use Cases - Monte Carlo Data, accessed on July 31, 2025, https://www.montecarlodata.com/blog-are-apache-iceberg-tables-right-for-your-data-lake-6-reasons-why/
- Building an AI/ML Data Lake With Apache Iceberg - DZone, accessed on July 31, 2025, https://dzone.com/articles/building-an-aiml-data-lake-with-apache-iceberg
- Data engineering with Apache Iceberg - Tabular, accessed on July 31, 2025, https://www.tabular.io/apache-iceberg-cookbook/data-engineering-background/
- Puffin Spec - Apache Iceberg™, accessed on July 31, 2025, https://iceberg.apache.org/puffin-spec/
- Accelerating Query Performance with Iceberg Puffin - Yeedu, accessed on July 31, 2025, https://www.yeedu.io/posts/accelerating-query-performance-with-iceberg-puffin-0g8k7
- Apache Iceberg Table Stats with Puffin - Dremio, accessed on July 31, 2025, https://www.dremio.com/blog/puffins-and-icebergs-additional-stats-for-apache-iceberg-tables/
- Apache Iceberg v3 Table Spec: Celebrating the OSS Community's Shared Success, accessed on July 31, 2025, https://www.snowflake.com/en/blog/apache-iceberg-v3-table-spec-oss-shared-success/
- What's New in Apache Iceberg Format Version 3? - Dremio, accessed on July 31, 2025, https://www.dremio.com/blog/apache-iceberg-v3/
- Apache Iceberg™ v3: Moving the Ecosystem Towards Unification | Databricks Blog, accessed on July 31, 2025, https://www.databricks.com/blog/apache-icebergtm-v3-moving-ecosystem-towards-unification
- Beyond the Surface: Part II— Building a Future-Proof Data Foundation for the AI-Driven Enterprise with Apache Iceberg — An AI Practitioner's Guide | by Adnan Masood, PhD. - Medium, accessed on July 31, 2025, https://medium.com/@adnanmasood/beyond-the-surface-part-ii-building-a-future-proof-data-foundation-for-the-ai-driven-enterprise-794b07dadd89
- Why Iceberg + Python is the Future of Open Data Lakes - dltHub, accessed on July 31, 2025, https://dlthub.com/blog/iceberg-open-data-lakes
- Netflix's Apache Iceberg Data Lake Migration - AWS, accessed on July 31, 2025, https://aws.amazon.com/awstv/watch/3db41488539/
- Apache Paimon vs. Apache Iceberg - A Detailed Comparison - OLake, accessed on July 31, 2025, https://olake.io/iceberg/paimon-vs-iceberg
Notice:Human's prompt, Datasets by Gemini-2.5-Pro-DeepResearch #大数据治理 #数据湖仓架构
---【本文完】---
👇阅读原文,查看历史文章(更新到 7.31)。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-07-31,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号