【存储100问】从GFS出发,比较理解:全局命名、DASE

【存储100问】从GFS出发,比较理解:全局命名、DASE

数据存储前沿技术
发布于 2026-03-09 18:03:54
发布于 2026-03-09 18:03:54
问题意识
现代企业面临着一个日益严峻的挑战:数据以前所未有的速度增长,并分散在本地网络附加存储(NAS)、公有云对象存储和边缘设备等不同的专有存储孤岛中 1。这种数据碎片化现象造成了严重的“数据引力”问题,不仅扼杀了人工智能(AI)和图形处理器(GPU)计算流程的效率,也极大地限制了企业的业务敏捷性 1。问题的根源在于,传统IT基础设施是以存储为中心构建的,而非以数据为中心,这导致数据被锁定在物理硬件中,难以自由流动和访问 4。
阅读收获
- 理解现代企业数据碎片化和“数据引力”问题的根源,以及传统存储架构的局限性。
- 掌握应对数据复杂性的两种核心战略:以 Hammerspace 为代表的“数据编排覆盖层”和以 VAST Data 为代表的“一体化数据平台”。
- 明确 Hammerspace 如何通过“数据就地同化”技术,在不中断业务的情况下统一管理现有异构存储,并实现数据跨地域、跨平台的无缝流动。
- 了解 VAST Data 的 DASE 架构如何通过软硬件一体化设计,提供高性能、可独立扩展的单一存储层,旨在通过替换简化基础设施。
以数据为中心:Hammerspace、VAST Data 与 AI 工作负载的未来

执行摘要
现代企业面临着一个日益严峻的挑战:数据以前所未有的速度增长,并分散在本地网络附加存储(NAS)、公有云对象存储和边缘设备等不同的专有存储孤岛中 1。这种数据碎片化现象造成了严重的“数据引力”问题,不仅扼杀了人工智能(AI)和图形处理器(GPU)计算流程的效率,也极大地限制了企业的业务敏捷性 1。问题的根源在于,传统IT基础设施是以存储为中心构建的,而非以数据为中心,这导致数据被锁定在物理硬件中,难以自由流动和访问 4。
为了应对这一挑战,业界涌现出两种截然不同的解决思路,本报告将对这两种思路的代表性厂商进行深入剖析。第一种思路以 Hammerspace 为代表,它提供了一个软件定义的数据编排覆盖层。其核心理念是通过一个高性能的并行全局文件系统,将企业现有的、异构的存储资源统一起来,创建一个虚拟化的数据云 1。Hammerspace 的目标是让数据“无处不在,却无需复制”,通过抽象化底层硬件,实现数据的完全可见性和无缝访问 1。
第二种思路以 VAST Data 为代表,它提供了一个专门构建的、软硬件一体化的数据平台。该平台基于其创新的“分离式共享一切”(Disaggregated Shared Everything, DASE)架构,旨在用一个可大规模扩展的高性能全闪存系统,彻底取代传统复杂的多层级存储体系 7。VAST Data 的哲学不是管理现有的复杂性,而是通过替换来消除复杂性。
本报告将提供对这两种解决方案的深度架构分析,并进行详细比较,最终为企业在不同场景下的战略决策提供指导。分析表明,Hammerspace 在拥有大量现有存储投资的“棕地”环境中表现卓越,提供了无与伦比的数据移动性和编排能力。而 VAST Data 则为希望从零开始构建全新高性能基础设施的“绿地”项目提供了一个强大而简化的解决方案。最终的选择不仅是技术路线的抉择,更是企业如何应对数据复杂性(是通过编排管理还是通过整合替换)的战略定位。
1. Hammerspace 全局数据平台:架构深度剖析
本节将解构 Hammerspace 平台的层次化、软件定义的架构,阐明其如何实现统一的数据管理和高性能访问。
1.1 核心原则:解耦的、元数据驱动的控制平面
Hammerspace 架构的基石在于其将文件系统从基础设施层中“提升”出来,创建了一个与底层物理存储完全分离的、统一的元数据驱动的控制平面 6。其“秘诀”在于将所有文件的元数据(如文件名、路径、权限、时间戳等)从各个独立的存储系统中剥离出来,汇集到一个全局共享、可随时随地访问的通用元数据层中 5。
这一架构决策是 Hammerspace 全部价值主张的核心。通过实现元数据与数据块的解耦,Hammerspace 真正做到了硬件无关(hardware-agnostic)1。无论实际数据存放在 NetApp 的文件管理器、Dell PowerScale 集群、AWS S3 存储桶还是 Azure Blob 中,其元数据都在 Hammerspace 的统一视图下管理。这使得 Hammerspace 能够向用户和应用程序呈现一个单一、连贯的全局文件系统,屏蔽了底层存储的异构性和复杂性 1。
这种设计带来了两个层面的战略转变。首先,它将企业的 IT 运营范式从传统的存储管理转变为真正的数据管理。在传统架构中,一个文件的“存在”与其所在的存储系统紧密绑定,数据被认为是该存储系统“渲染”出的幻象 5。移动数据就意味着创建了一个全新的、独立的副本。Hammerspace 彻底颠覆了这一模式。通过元数据的集中化,
数据本身成为了持久的、权威的实体,而其物理存储位置则变成了一个可根据策略动态调整的、暂时的属性 5。这使得企业能够将数据视为一种全局性的、可流动的资产进行管理,直接满足了用户对“以数据为中心”的解决方案的需求。
其次,Hammerspace 的“纯软件”模式具有深远的战略意义。Hammerspace 不销售存储硬件,其产品以软件形式提供,可部署在商用服务器或云环境中 1。这种模式使用户避免了在硬件层面的供应商锁定,并允许企业充分利用和延长现有存储资产的投资回报周期 4。这催生了一种强大的“落地与扩展”(land-and-expand)的商业模式:企业部署的初始门槛极低,因为不需要进行任何“推倒重来”式的替换。一旦 Hammerspace 平台建立起来,它就自然而然地成为企业所有未来存储采购的战略控制中心,从而将底层的存储硬件转变为可按需采购的商品。
1.2 性能引擎:基于标准的并行全局文件系统
为了满足 AI 和 HPC 等高性能工作负载对数据吞吐量的苛刻要求,Hammerspace 实现了一个高性能的并行全局文件系统,并将其命名为“Hyperscale NAS” 2。该系统的核心是基于行业标准的并行网络文件系统(Parallel NFS, pNFS)v4.2 协议 9。
与许多需要安装专有客户端软件的并行文件系统(如 Lustre 或 GPFS/Spectrum Scale)不同,Hammerspace 采用标准的 pNFS 协议,使得任何标准的 Linux 客户端都可以在无需安装代理(agent)的情况下并行访问数据 1。其工作流程是:客户端首先与 Hammerspace 的元数据服务器通信,获取一个描述数据块在后端存储中分布情况的“布局图”(layout map)。随后,客户端可以根据这张图,绕过元数据服务器,直接与多个后端存储系统(无论是 NAS 还是对象存储)并行地进行数据读写操作。这种设计极大地提高了 I/O 并发性,能够同时从多个存储阵列中检索数据,从而最大化数据吞吐量,为大规模 AI 训练提供充足的数据供给 1。
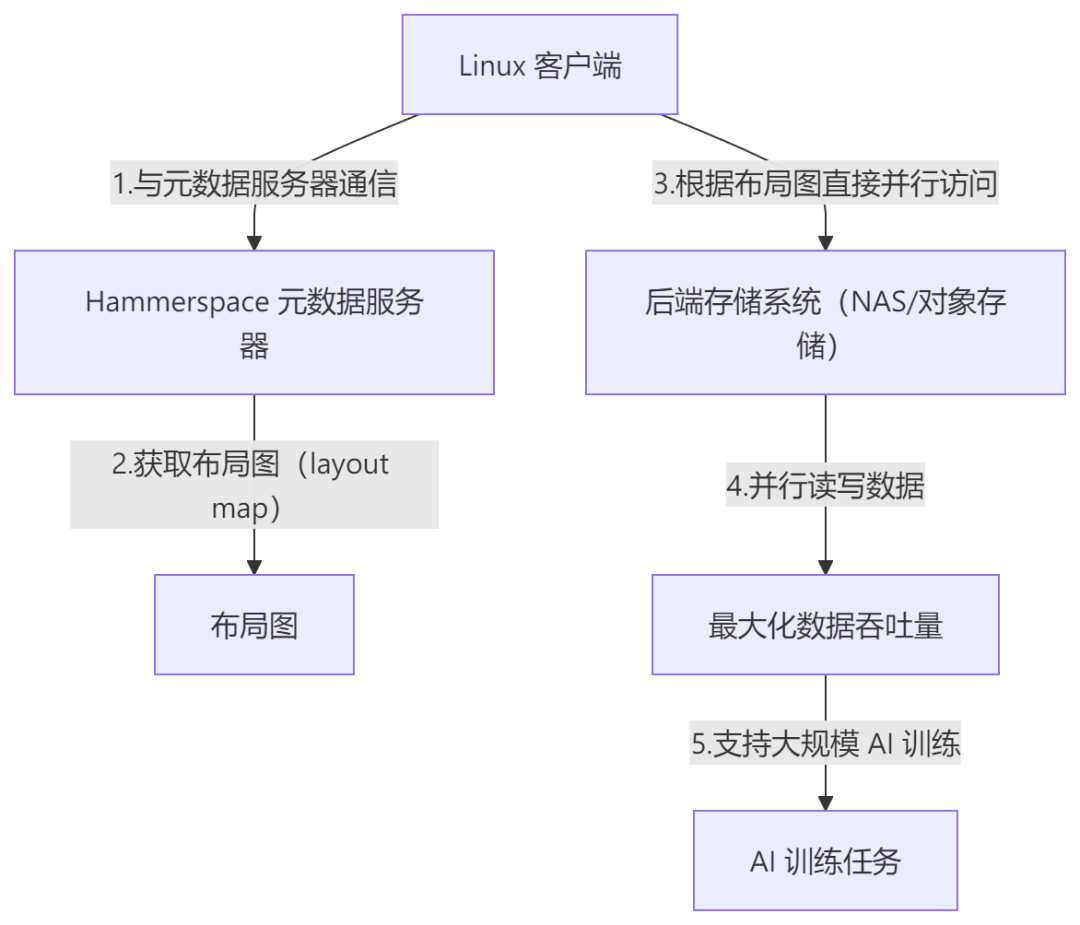
此外,Hammerspace 平台提供了广泛的协议兼容性,支持企业中常见的 NFS(v3, v4.2)、SMB(v2, v3)和 S3 等标准协议 9。这种多协议支持能力对于企业级应用至关重要,它意味着 Hammerspace 可以将一个对象存储桶中的数据以文件形式呈现给应用,或者将 NAS 文件管理器中的数据通过 S3 接口提供服务,所有这些都在同一个全局命名空间下无缝进行。同时,平台还支持 GPUDirect 和 RDMA 等性能加速技术 11。其中,对 GPUDirect 的支持对于 AI 工作负载尤为关键,它允许 GPU 直接从存储中拉取数据,绕过 CPU 和系统内存,从而消除了传统 I/O 路径中的性能瓶颈,确保昂贵的 GPU 资源得到充分利用 11。
1.3 统一视图:单一全局命名空间
解耦的元数据与并行文件系统架构相结合,最终为用户和应用程序呈现出一个单一全局命名空间(Single Global Namespace) 1。在这个命名空间下,所有数据——无论其物理位置(本地数据中心、公有云、边缘站点)或其底层存储类型(文件、对象、块)——都表现为一个统一的、看似本地的数据池 1。
这彻底解决了企业长期面临的数据蔓延(data sprawl)问题。用户和数据科学家不再需要为了访问不同位置的数据而去管理和记忆多个不同的挂载点、盘符或连接字符串。它提供了真正的位置透明性 20。例如,一个位于伦敦办公室的用户可以像访问本地文件一样,无缝地访问存放在东京数据中心云存储上的数据。Hammerspace 的智能缓存和数据移动机制会在后台自动运行,根据访问模式将需要的数据或文件的实例移动到离计算资源更近的位置,从而在提供全局视图的同时优化访问性能 1。
2. 通过“数据就地同化”实现无中断集成
本节将详细阐述 Hammerspace 如何在不进行破坏性数据迁移的前提下,将现有存储系统中的数据整合到其全局数据平台中。
2.1 同化机制:采集元数据,而非数据
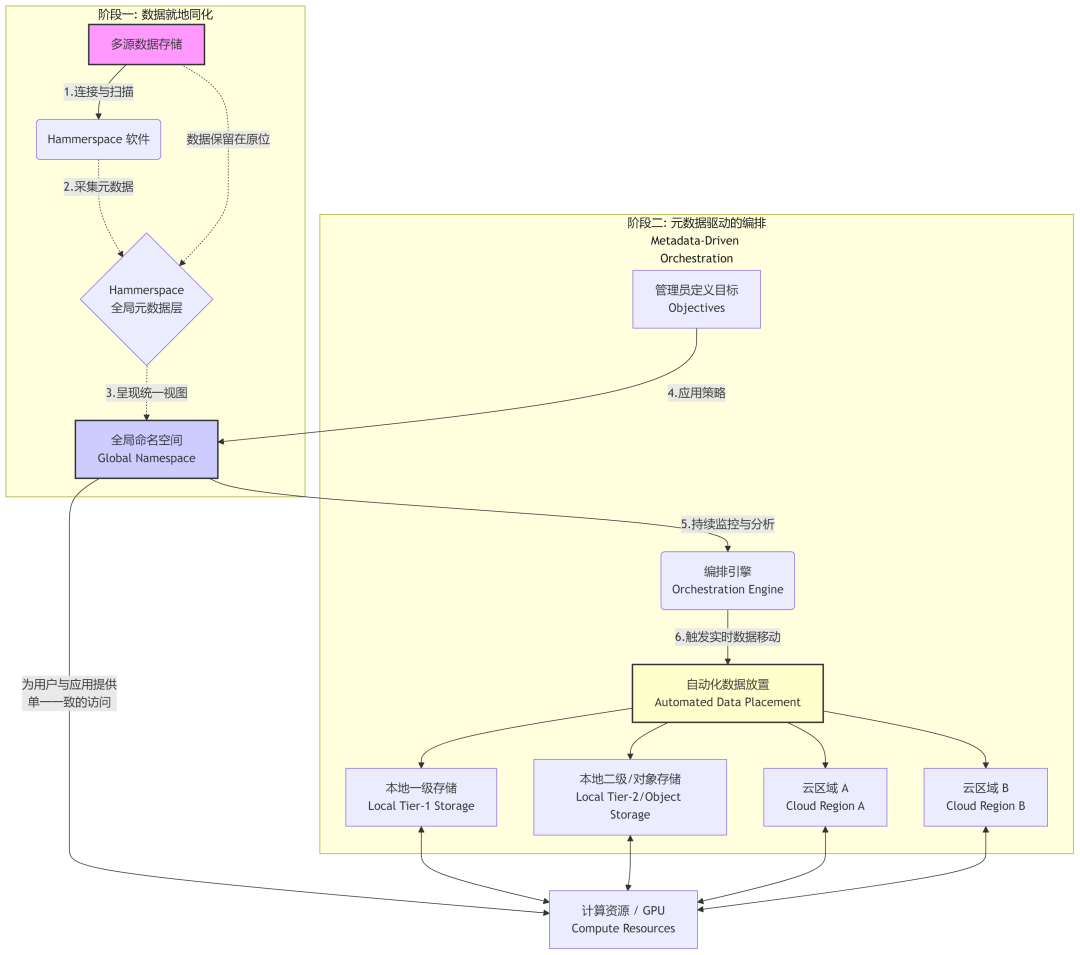
Hammerspace 的核心集成技术被称为 “数据就地同化”(Data-in-Place Assimilation)。该过程的核心思想是,在整合第三方存储系统时,只吸纳其元数据,而将实际的数据块保留在原有的存储位置 3。
这是一个完全无中断的过程。当 Hammerspace 部署后,管理员可以将其连接到现有的 NAS 共享(例如,来自 NetApp 或 Dell 的存储)或云存储桶。Hammerspace 会扫描目标文件系统,并将所有元数据(包括文件名、目录结构、权限、时间戳等)“采集”到自己的全局元数据层中 15。由于元数据相对于数据本身来说体量极小,这个采集过程非常迅速。即使是 PB 级别的大型存储环境,其元数据也能在数分钟内被吸纳,并立即在 Hammerspace 的全局命名空间中变得可见和可访问 4。
数据就地同化 与 OTF 开放数据格式的比较
Hammerspace 的数据就地同化与开放数据格式(Open Table Format, OTF,如 Iceberg, Delta Lake, Hudi)以及数据目录(Data Catalog)在某些方面有相似之处,即它们都旨在管理和组织数据。然而,它们在目标、作用层面和实现机制上存在显著差异:
特性 | Hammerspace 数据就地同化 | 开放数据格式(OTF,如 Iceberg, Delta Lake, Hudi)/数据目录 |
|---|---|---|
主要目标 | 统一管理和编排非结构化数据(文件、对象),打破存储孤岛,实现数据跨异构存储的自由流动和全局访问。 | 主要针对结构化/半结构化数据,解决数据湖中数据质量、事务一致性、模式演进、版本管理等问题,并提供优化的查询性能。数据目录则侧重于元数据发现、管理和治理。 |
作用层面 | 存储层和文件系统层之上的“数据编排覆盖层”。它不改变底层数据存储格式,而是通过统一的元数据视图来管理跨异构存储的数据。 | 数据文件之上的一层元数据管理,定义数据如何被组织、存储和访问(通常是基于 Parquet 或 ORC 文件)。它改变了数据湖中数据被“理解”和“操作”的方式。数据目录则更偏向于数据治理和发现的工具。 |
实现机制 | 采集现有存储的元数据,将其提升到一个独立的全局元数据层,并提供一个统一的全局文件系统访问接口(pNFS, SMB, S3)。数据本身留在原地。 | 在数据湖中生成和管理额外的元数据文件(如 manifest files, transaction logs),这些文件描述了数据文件的组织方式、版本和模式信息。它通常与特定的计算引擎(如 Spark)集成。数据目录则通过扫描和集成不同数据源来收集元数据。 |
数据类型 | 主要针对非结构化数据(文件、视频、图片、日志等)。 | 主要针对结构化和半结构化数据(表格数据)。 |
核心关注点 | 数据移动性、位置透明性、性能优化(通过并行访问和缓存)和跨云/跨站点数据编排。 | 数据可靠性、事务 ACID 特性、模式演进、数据版本控制、性能优化(通过谓词下推、数据跳过)。数据目录关注数据发现、血缘、治理。 |
典型用例 | AI/ML 数据流水线、HPC、媒体和娱乐、生命科学、多站点/混合云数据同步和访问。 | 数据湖、数据仓库现代化、ETL/ELT 流程、BI 和分析、数据治理。 |
简而言之,Hammerspace 旨在解决“数据在哪里”和“如何高效访问和管理分布在各处的数据”的问题,它是一个数据编排和访问平台。而开放数据格式和数据目录则更侧重于解决“数据如何被正确地组织、理解和使用”的问题,它们是数据湖管理和治理工具。尽管都涉及元数据管理,但其目的和方法论截然不同。
“数据就地同化”技术为企业IT现代化提供了一条巧妙的、低风险的路径。传统上,引入新型存储技术最大的障碍是数据迁移所带来的高昂成本、漫长时间窗口和业务中断风险。“数据就地同化”完美地规避了这一难题。企业可以部署 Hammerspace,将其现有的所有存储资源“同化”进来,从而在不移动任何生产数据字节的情况下,立即获得全局命名空间、数据统一视图和智能编排等现代化能力。
一旦数据被同化,其管理权就转移到了 Hammerspace 的控制之下。接下来,企业可以利用 Hammerspace 强大的策略引擎,在后台无缝地、透明地、在线地将数据从旧存储迁移到新的、更具成本效益或性能更高的存储上,而整个过程对前端的用户和应用程序完全无感知 4。旧存储系统可以在数据迁移完成后安全退役。这种方式将过去高风险的、需要“一刀切”(flag day)的迁移项目,转变为一个低风险的、自动化的、可在后台持续进行的运维任务。
2.2 载入与编排工作流
Hammerspace 的数据管理流程主要分为两个阶段:1) 通过“数据就地同化”整合数据;2) 使用称为“目标”(Objectives)的策略来编排数据 22。
在数据同化完成之后,管理员不再需要编写复杂的脚本来管理数据,而是通过定义简单、声明式的“目标”来描述他们期望的数据状态。这些目标可以用接近自然语言的业务规则来表达,例如:“将所有带有‘render’元数据标签的数据放置到计算成本最低的云区域进行处理”,或者“确保‘legal’目录下的所有文件都在第二个数据中心保留一份副本” 10。
定义好目标后,Hammerspace 的编排引擎会持续监控全局数据平台中所有数据的当前状态,并与预设的目标进行比较。一旦发现偏差,引擎会自动触发数据移动操作,以满足策略要求。这种数据移动是文件实例级别的、实时的,并且可以在数据被实时读写的同时进行(Live Data Mobility),对用户和应用完全透明 21。
以下流程图展示了从数据载入到编排的完整工作流:
3. 现代数据架构的比较框架
本节将直接回应用户的第三个、也是最复杂的问题。首先,本节将清晰定义相关术语,然后对 Hammerspace 和 VAST Data 进行深入的、并行的比较分析。
3.1 术语定义:GFS、UNS 与 DASE
在数据存储领域,“全局文件系统”(Global File System, GFS)和“统一命名空间”(Unified Namespace, UNS)这两个术语经常被混用,导致概念模糊。而 DASE 则是一个特定的、专有的架构。为了进行严谨的比较,首先必须对这些概念进行清晰的界定。
下表对这三个核心架构概念进行了定义和区分,为后续的详细比较奠定了基础。
表 1: 架构概念定义
概念 | 定义 | 核心功能 | 实现方式 | 是否在数据路径中? | 示例 |
|---|---|---|---|---|---|
全局文件系统 (GFS) | 一种分布式文件系统,能够跨越多个物理位置和存储系统,提供单一、一致的文件视图 20。 | 提供位置透明的数据访问。同时管理数据和元数据的访问请求。 | 可分为以存储为中心(厂商绑定,如 Dell PowerScale)或以元数据为中心(覆盖层,如 Hammerspace)20。 | 是。客户端直接挂载 GFS,所有 I/O 请求都通过它进行处理 20。 | Hammerspace, Dell PowerScale, Qumulo, Nasuni, Panzura。 |
统一命名空间 (UNS) | 一种架构原则或策略,旨在为组织内的所有数据创建一个单一、逻辑上的事实来源(single source of truth)28。 | 提供数据的分层、逻辑化组织,将数据生产者与消费者解耦。 | 在工业物联网(IIoT)中常通过消息总线(如 MQTT)实现;在存储领域,通常由全局文件系统(GFS)来实现 28。 | 不一定。UNS 是逻辑结构;而实现它的 GFS 则处于数据路径中。 | GFS 创建的逻辑视图;IIoT 中的 MQTT 主题层级。 |
分离式共享一切 (DASE) | 由 VAST Data 首创的一种特定的、专有的存储架构,通过高速网络将无状态的计算节点与有状态的、共享的存储介质分离开来 7。 | 在单一集成系统内,实现性能(计算)和容量(存储)的独立扩展。 | 由 VAST 服务器(CNodes)负责计算逻辑,高可用机柜(DBoxes)负责 NVMe 存储,两者通过 NVMe-oF 网络连接 7。 | 是。VAST 集群作为一个整体,为其管理的数据提供服务,处于数据路径中。 | VAST Data 平台。 |
3.2 VAST Data 的分离式共享一切(DASE)架构
VAST Data 的 DASE 架构是一种革命性的设计,它将无状态的 VAST 服务器(称为 CNodes 或计算节点)与包含持久化存储介质(NVMe SSD)的有状态高可用机柜(称为 DBoxes 或数据机柜)彻底分离开来 31。所有的 DBoxes 都是共享的,集群中任何一个 CNode 都可以通过低延迟的 NVMe-oF(NVMe over Fabrics)网络直接访问任何一个 DBox 中的数据 32。
这是一种真正的“共享一切”(shared-everything)模型,与传统的每个节点只管理自身存储的“无共享”(shared-nothing)架构形成鲜明对比。DASE 架构的关键创新在于,它消除了节点之间为了 I/O 操作而产生的“东西向”网络流量。VAST 声称,这种设计使得系统能够实现近乎无限的、线性的性能和容量扩展 7。当需要提升性能时,只需增加 CNodes;当需要扩大容量时,只需增加 DBoxes,两者可以独立进行,互不影响 7。
Dave's point
DASE 的 分离式共享一切 个全局文件系统还是有显著差异的,前者是为提高数据访问效率、降低延迟而设计的:通过将元数据复制到每个节点,从而避免元数据节点的瓶颈,提高数据访问效率;而全局文件系统,强调的是构建多地域、多存储系统的统一数据管理视角,其出发点是数据管理,而并非DASE的数据IO性能,但不排除随着元数据规模增加,元数据进一步解耦到多个节点,这时候就接近 DASE的架构设计了。
VAST Data 的核心理念是构建一个更好、更高效、一体化的数据平台。它提供的是一个集成的软硬件系统,旨在通过一个单一的全闪存存储层,取代传统存储中用于主存储和归档存储的复杂层级 7。因此,VAST 的目标是通过替换来整合和简化基础设施,而不是像 Hammerspace 那样去编排现有的异构系统。虽然 VAST 也在发展其全局命名空间能力,但这些能力目前主要集中在连接 VAST 生态系统内部的多个集群,而非整合第三方存储 34。
3.3 正面比较:Hammerspace vs. VAST Data
Hammerspace 和 VAST Data 代表了解决现代数据挑战的两种根本不同的哲学:编排与替换。Hammerspace 的核心价值来源于异构环境。它能统一的存储孤岛越多、种类越丰富,其价值就越大 1。它天生就是为了解决“棕地”(brownfield)环境的复杂性而设计的。相比之下,VAST Data 的核心价值来源于其高度优化、深度集成的技术栈。它旨在用一个单一、卓越的平台来取代异构环境 7。它更适合“绿地”(greenfield)项目或全面的基础设施更新。
这种根本性的差异决定了它们在市场上的定位是相互对立的。选择 Hammerspace 的客户,是决定通过一个智能的控制平面来管理现有的复杂性;而选择 VAST Data 的客户,是决定通过替换来彻底消除这种复杂性。对于潜在的购买者而言,理解这一战略层面的区别至关重要。
以下表格从架构、运营和应用场景等多个维度对两者进行了详细的比较。
表 2: 架构与运营对比:Hammerspace vs. VAST Data
特性 | Hammerspace 全局数据平台 | VAST Data 平台 |
|---|---|---|
核心架构 | 软件定义的数据编排覆盖层。以元数据为中心的并行全局文件系统(基于 pNFS)1。 | 软硬件一体化的数据平台。分离式共享一切(DASE)架构 7。 |
主要目标 | 统一并编排现有的和新增的异构存储系统,将其整合成一个单一的逻辑资源 2。 | 替换传统的多层级存储,提供一个高度优化的、单一的全闪存数据平台 8。 |
硬件依赖性 | 硬件无关。可在商用服务器上运行,支持任何供应商的存储(NetApp, Dell, Pure, AWS, Azure 等)1。 | 集成系统。需要 VAST 认证的硬件(CNodes 和 DBoxes),或作为特定云市场上的软件实例运行 7。 |
数据载入方式 | “数据就地同化”。无中断地吸纳现有存储的元数据,无需移动实际数据 3。 | 数据迁移。数据必须被迁移到 VAST 平台之上才能被其管理。 |
命名空间范围 | 真正的全局与异构。可在单一命名空间内跨越多个供应商、站点和云 6。 | 主要为同构。全局命名空间能力正在发展,但主要用于连接 VAST 集群 34。 |
关键技术 | 通用元数据控制平面、基于策略的编排(“目标”)、并行 NFS 10。 | DASE 架构、基于相似性的数据缩减、写时重定向(Write-in-Free-Space)、全局一致性 7。 |
客户端访问 | 基于标准。无需专有客户端。支持标准 NFS/SMB/S3 客户端 11。 | 基于标准。支持标准 NFS/SMB/S3 客户端。 |
理想环境 | 棕地(Brownfield)。拥有大量、多样化的现有存储投资,需要统一管理和数据流动性的组织。 | 绿地(Greenfield)或全面更新。正在构建全新的 AI 基础设施或希望完全替换旧系统的组织。 |
商业模式 | 软件许可。将底层存储商品化。 | 集成平台销售(软件运行于认证硬件上)或云服务。 |
Gartner Peer Insights 评价 | 在“服务与支持”和“集成与部署的便捷性”方面评分低于 VAST 37。 | 在“服务与支持”和“集成与部署的便捷性”方面评分高于 Hammerspace 37。 |
4. 战略意义与建议
本节将综合以上分析,为用户提供可操作的、基于场景的战略指导。
4.1 基于场景的架构选型指南
场景 A: 对大型、异构的“棕地”环境进行现代化改造与统一
- 建议: 在此场景下,Hammerspace 是架构上更优越的选择。
- 理由: 该场景的核心挑战是已存在的数据引力问题和多样化的基础设施。Hammerspace 的“数据就地同化”技术提供了一条无中断的现代化路径。它使组织能够立即获得对所有数据资产的控制权和统一视图,充分利用现有投资,并根据策略将数据智能地编排到最合适的计算或存储层(包括云端)。相比之下,采用 VAST Data 进行“推倒重来”式的替换将是一个规模巨大、风险极高的数据迁移工程。
场景 B: 构建一个全新的、“绿地”的 AI/HPC 数据中心
- 建议: 在此场景下,VAST Data 提供了一个极具吸引力的、简化的解决方案。
- 理由: 由于没有历史遗留基础设施的束缚,此场景的重点是为新建设施寻求最高的性能、最简化的管理和最优的总体拥有成本(TCO)。VAST Data 的一体化平台,凭借其先进的数据缩减技术和全闪存的高性能,提供了强大的、类似一体机的部署和使用体验。由于不存在编排第三方系统的需求,Hammerspace 的核心价值主张在此场景中变得不那么关键。Gartner Peer Insights 中关于 VAST Data 在部署便捷性方面更高的评分也支持了这一结论 37。
场景 C: 混合模式——分阶段的现代化
- 建议: 一种分阶段的策略可以同时利用两者的优势。
- 理由: 组织可以首先部署 Hammerspace 来统一其现有的、复杂的遗留环境(如场景 A)。一旦全局数据平台建立,就可以利用 Hammerspace 的编排能力,在后台无缝地将对性能要求最苛刻的工作负载,透明地迁移到一个新建的 VAST Data 集群上。在这种模型中,VAST Data 成为一个由 Hammerspace 管理的高性能存储“层”,而 Hammerspace 继续作为全局的控制平面。这种策略充分发挥了两个平台的长处:Hammerspace 负责全局编排和数据流动,VAST Data 负责提供极致的性能执行。
4.2 结论:数据中心主义的必然崛起
总而言之,Hammerspace 和 VAST Data 尽管采用了截然不同的方法,但它们都清晰地指明了行业的一个关键转变:AI 数据基础设施的未来,必然是数据与底层硬件解耦的未来。
Hammerspace 通过一个纯粹的软件抽象层来实现这一目标,为组织在异构世界中提供了极致的灵活性和控制力。它让企业能够驾驭复杂性,将数据从存储的枷锁中解放出来。
VAST Data 则通过创建一个性能卓越、效率极高的平台来实现这一目标,其目标是让存储层级的异构性本身变得过时和没有必要。它试图通过整合来消除复杂性。
因此,企业在两者之间的选择,不仅仅是两个产品之间的技术权衡,更是一个关于组织希望如何管理其数据复杂性的战略决策:是通过编排来驾驭,还是通过整合来消除。正确的答案完全取决于组织的现状、战略目标以及对变革的接受程度。
===
参考资料
- An Inside Look at Hammerspace's HPC-Grade Architecture - theCUBE Research, accessed on June 29, 2025, https://thecuberesearch.com/an-inside-look-at-hammerspaces-hpc-grade-architecture/
- Global Data Platform - Hammerspace, accessed on June 29, 2025, https://hammerspace.com/software/
- One Data View to Rule Them All: Simplifying Access for Distributed AI with a Global Namespace for Your AI Data Storage - Hammerspace, accessed on June 29, 2025, https://hammerspace.com/one-data-view-to-rule-them-all-simplifying-access-for-distributed-ai-with-a-global-namespace-for-your-ai-data-storage/
- Hammerspace Software: Building a Global Data Environment, accessed on June 29, 2025, https://www.titandatasolutions.com/ae/wp-content/uploads/sites/2/2022/10/Hammerspace-Data-Sheet-Oct-2022-v2.1.pdf
- Object Storage a 'Total Cop Out,' Hammerspace CEO Says. 'You All Got Duped' - HPCwire, accessed on June 29, 2025, https://www.hpcwire.com/2023/11/02/object-storage-a-total-cop-out-hammerspace-ceo-says-you-all-got-duped/
- Hammerspace Global Data Environment, accessed on June 29, 2025, https://hammerspace.com/hammerspace-global-data-environment/
- The VAST Data Platform, accessed on June 29, 2025, https://www.vastdata.com/whitepaper.pdf
- VAST Data Expands Platform to Unify Structured and Unstructured Data - HPCwire, accessed on June 29, 2025, https://www.hpcwire.com/off-the-wire/vast-data-expands-platform-to-unify-structured-and-unstructured-data/
- Mainline Viewpoint: Hammerspace - Unlocking Your Unstructured Data, accessed on June 29, 2025, https://mainline.com/mainline-viewpoint-hammerspace-unlocking-your-unstructured-data/
- How To Create a Global Namespace With Hammerspace ..., accessed on June 29, 2025, https://medium.com/@hammerspace/how-to-create-a-global-namespace-with-hammerspace-a40618de4d45
- Hammerspace claims fastest file system for AI training - Blocks and Files, accessed on June 29, 2025, https://blocksandfiles.com/2024/02/22/hammerspace-claims-fastest-file-system-for-ai/
- Hammerspace Expands Support for Commodity Hardware in the Global Data Environment, accessed on June 29, 2025, https://hammerspace.com/hammerspace-expands-support-for-commodity-hardware-in-the-global-data-environment/
- Hammerspace challenges object storage norms for AI - Blocks and Files, accessed on June 29, 2025, https://blocksandfiles.com/2025/02/07/hammerspace-file-vs-object-ai-training/
- Category: White Paper - Hammerspace, accessed on June 29, 2025, https://hammerspace.com/category/white-paper/
- Top 5 Reasons to Consider Hammerspace for Your Global File System, accessed on June 29, 2025, https://hammerspace.com/top-5-reasons-to-consider-hammerspace-for-your-global-file-system/
- Category: Technical Brief - Hammerspace, accessed on June 29, 2025, https://hammerspace.com/category/technical-brief/
- Hammerspace Adds S3 Interface to Global Data Platform, Enhancing Data Orchestration, accessed on June 29, 2025, https://www.hpcwire.com/off-the-wire/hammerspace-adds-s3-interface-to-global-data-platform-enhancing-data-orchestration/
- Hammerspace Unveils GPU Data Orchestration for S3 Applications: Accelerating AI and GPU Workloads - @VMblog, accessed on June 29, 2025, https://vmblog.com/archive/2024/06/24/hammerspace-unveils-gpu-data-orchestration-for-s3-applications-accelerating-ai-and-gpu-workloads.aspx
- What is a Global File System - Hammerspace, accessed on June 29, 2025, https://hammerspace.com/what-is-a-global-file-system/
- What's Global File System | Unified Data Access & Management - Komprise, accessed on June 29, 2025, https://www.komprise.com/glossary_terms/global-file-system/
- Data Orchestration Services - Hammerspace, accessed on June 29, 2025, https://hammerspace.com/data-orchestration/
- Eliminate Data Silos by Consolidating, then Orchestrating, Distributed Unstructured Data, accessed on June 29, 2025, https://hammerspace.com/eliminate-data-silos-by-consolidating-then-orchestrating-distributed-unstructured-data/
- Public Sector - Hammerspace, accessed on June 29, 2025, https://hammerspace.com/public-sector/
- Automating Data Management with Hammerspace Data Orchestration, accessed on June 29, 2025, https://hammerspace.com/automating-data-management-with-hammerspace-data-orchestration/
- Taming Unstructured Data Orchestration with Hammerspace - YouTube, accessed on June 29, 2025, https://www.youtube.com/watch?v=YkC8mQSzGyQ
- Global file system - Wikipedia, accessed on June 29, 2025, https://en.wikipedia.org/wiki/Global_file_system
- Global Namespace vs Global File System - Komprise, accessed on June 29, 2025, https://www.komprise.com/wp-content/uploads/Namespace_Global_File_System_Komprise.pdf
- What Is Unified Namespace (UNS) and Its Role in Industry 4.0 | Cedalo, accessed on June 29, 2025, https://cedalo.com/blog/unified-namespace-uns/
- Unified Namespace in Manufacturing: The Digital Backbone of Industry 4.0 - Medium, accessed on June 29, 2025, https://medium.com/@hopeful_rajah_koala_193/unified-namespace-0464e3ccceeb
- Global namespace - hybrid cloud global file system – Panzura, accessed on June 29, 2025, https://panzura.com/technology/global-namespace/
- Disaggregated Shared-Everything Architecture (DASE) - VAST Data, accessed on June 29, 2025, https://www.vastdata.com/disaggregated-shared-everything-architecture-dase
- Meet VAST Data's DASE Architecture, accessed on June 29, 2025, https://www.vastdata.com/platform/how-it-works
- Why Does DASE™ Architecture Matter? - YouTube, accessed on June 29, 2025, https://www.youtube.com/watch?v=EvRMCqAGkQw
- Hammerspace: Other vendors are trying to copy us - Blocks and Files, accessed on June 29, 2025, https://blocksandfiles.com/2023/02/23/hammerspace-other-vendors-are-trying-to-copy-us/
- Unify Data Silos & Automated, Non-Disruptive Data Migration - Hammerspace, accessed on June 29, 2025, https://hammerspace.com/unify-data-silos-automated-non-disruptive-data-migration/
- Hammerspace For High Performance Computing, accessed on June 29, 2025, https://hammerspace.com/hammerspace-for-high-performance-computing/
- Top VAST Data Platform Competitors & Alternatives 2025 | Gartner Peer Insights, accessed on June 29, 2025, https://www.gartner.com/reviews/market/file-and-object-storage-platforms/vendor/vast-data/product/vast-data-platform/alternatives
延伸思考
- 考虑到您所在组织的现有数据基础设施现状,您认为采用“编排管理”还是“整合替换”的战略路径更适合应对未来的 AI 工作负载需求?为什么?
- 文章探讨了数据与底层硬件解耦的趋势,除了 Hammerspace 和 VAST Data,您还观察到哪些技术或架构正在推动这一转变?它们各自的优势和挑战是什么?
- 如果将 Hammerspace 的数据编排能力与 VAST Data 的高性能平台结合,您认为在实际部署中可能面临哪些技术或管理上的挑战?又如何最大化这种组合的价值?
Notice:Human's prompt, Datasets by Gemini-2.5-Pro-DeepResearch
#智能数据平台演进 #全局命名空间
---【本文完】---
👇阅读原文,查看历史文章(更新到 6.30)。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-06-29,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号