Intel:IPU存储新引擎,提升数据运力

Intel:IPU存储新引擎,提升数据运力

数据存储前沿技术
发布于 2026-03-09 16:51:45
发布于 2026-03-09 16:51:45
全文概览
随着虚拟化、容器和云计算的普及,基础设施管理任务(如网络处理、存储访问、安全加密)占用了主机 CPU 大量资源,挤占了本应服务于核心业务应用的空间。这不仅降低了计算效率,也带来了性能瓶颈和隔离性问题。
为了解决这一困境,基础设施处理单元(IPU)应运而生。IPU 是一种新型的专用处理器,旨在将基础设施层从主计算层中彻底解耦,通过专用硬件和软件栈加速这些任务。本文将深入探讨 IPU 的核心功能、它与智能网卡的演进关系,并重点解析 IPU 如何通过卸载和加速 NVMe 存储访问,显著提升数据中心的存储性能和整体效率,为构建下一代安全、可编程的基础设施奠定基础。
阅读收获
- 理解 IPU 如何通过硬件加速和功能卸载,解决传统数据中心基础设施任务对主机 CPU 的资源占用问题。
- 掌握 IPU 与 SmartNIC 的关键区别,认识到 IPU 在数据中心架构演进中的重要地位。
- 了解 IPU 如何将 NVMe-oF 发起端功能从主机完全迁移,从而大幅提升存储访问性能和效率。
- 认识到 IPU 虽然不改变应用层接口,但通过优化底层数据路径和处理方式,间接提升了整体系统性能和资源利用率。
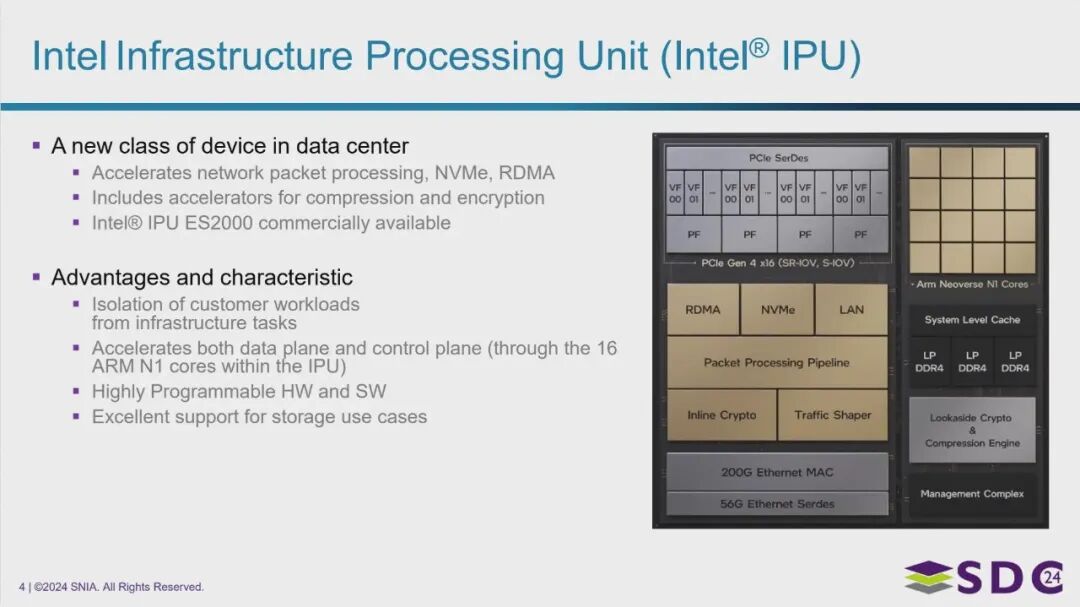
英特尔基础设施处理单元 (Intel® IPU)
英特尔基础设施处理单元 (Intel® IPU)
右侧是 IPU 模块示意图,Intel® IPU ES2000 型号已进入商业市场。
主要功能:
- 加速能力: 专门用于加速基础设施任务,包括:
- 网络数据包处理
- NVMe 存储访问
- RDMA (远程直接内存访问)
- 数据压缩和加密
- 工作负载隔离: 旨在将客户应用程序/工作负载与底层基础设施管理任务隔离开来。
核心特性和优势:
- 性能提升: 通过专用硬件和处理管线显著提升特定基础设施操作的性能。
- 双平面加速: 利用内置的 16 个 ARM Neoverse N1 核心,可同时加速数据平面和控制平面任务。
- 灵活性: 硬件和软件具有高度可编程性,适应不同的应用场景。
- 存储优化: 对各种存储用例提供强大支持。
如何理解 IPU 和现阶段智能网卡,两者的区别和演进关系?
- 两者的区别
特性 | 智能网卡 (SmartNIC) | 基础设施处理单元 (IPU) |
|---|---|---|
核心焦点 | 网络处理卸载和加速,可能包含部分存储/安全 | 基础设施层任务的全面处理、卸载和隔离 |
功能范围 | 主要聚焦于网络功能,扩展到部分存储和安全卸载 | 涵盖网络、存储、安全、管理、隔离等更广泛的基础设施任务 |
处理能力 | 通常是嵌入式 CPU、NPU 或 FPGA,处理能力相对受限 | 通常包含功能更强大的 CPU 核心(如 ARM)和更多样的专用加速器 |
可编程性 | 不同型号差异大,可能通过固件、eBPF 或有限的 SDK | 强调更高的可编程性,支持在上面运行完整的操作系统或复杂软件栈 |
隔离级别 | 在一定程度上隔离网络处理与主 CPU | 旨在实现彻底隔离租户工作负载与基础设施管理层 |
市场定位 | 作为网卡的增强,提升网络性能、支持部分卸载 | 作为独立的基础设施处理器,构建下一代安全、可编程的数据中心基础架构 |
- 演进关系
智能网卡是 IPU 的一个重要前身和演进阶段。
- 传统网卡: 只负责最基本的数据传输,所有高级功能都由主 CPU 完成。
- SmartNIC 阶段: 为了减轻主 CPU 负担,网卡开始集成硬件逻辑或处理器,卸载一些特定的网络任务。这个阶段的功能是逐步增加和扩展的。
- IPU 阶段: 随着数据中心复杂度的提高、虚拟化和容器技术的普及以及对安全隔离的更高要求,SmartNIC 的功能和处理能力已经不足以应对所有基础设施任务。IPU 应运而生,它将 SmartNIC 的概念推向极致,不再仅仅是“智能”的网卡,而是成为一个独立、强大的“基础设施处理器”。它将基础设施层从主计算层中完全解耦,形成一种新的计算架构。

英特尔® IPU 在存储工作负载中的硬件加速能力
英特尔® IPU 在存储工作负载中的硬件加速能力
关键硬件加速引擎:
- NVMe 处理引擎
- 将 NVMe 发起端(Initiator)的功能从主 CPU 卸载到 IPU 上,减轻主 CPU 负担。
- 使得连接到 IPU 后端的 PCIe NVMe 存储设备能够直接、高效地与主机处理器通信。
- 主要功能: 负责处理 NVMe 协议相关的任务。
- 带来的好处:
- 旁路加密与压缩引擎 (Lookaside Crypto & Compression Engine, LCE)
- 设备级别的加密
- 存储系统层面的加密
- 磁盘上的数据保护
- 主要功能: 提供高性能的硬件级数据加密和压缩能力。
- 技术支持: 内建多种高级加密和压缩算法。
- 针对存储应用: 尤其适用于处理“静止数据”(Data at Rest)的场景,可以提供:
- 高级特性: 支持将多个操作串联执行,例如在将数据写入存储前,先进行硬件压缩,然后立即进行硬件加密。
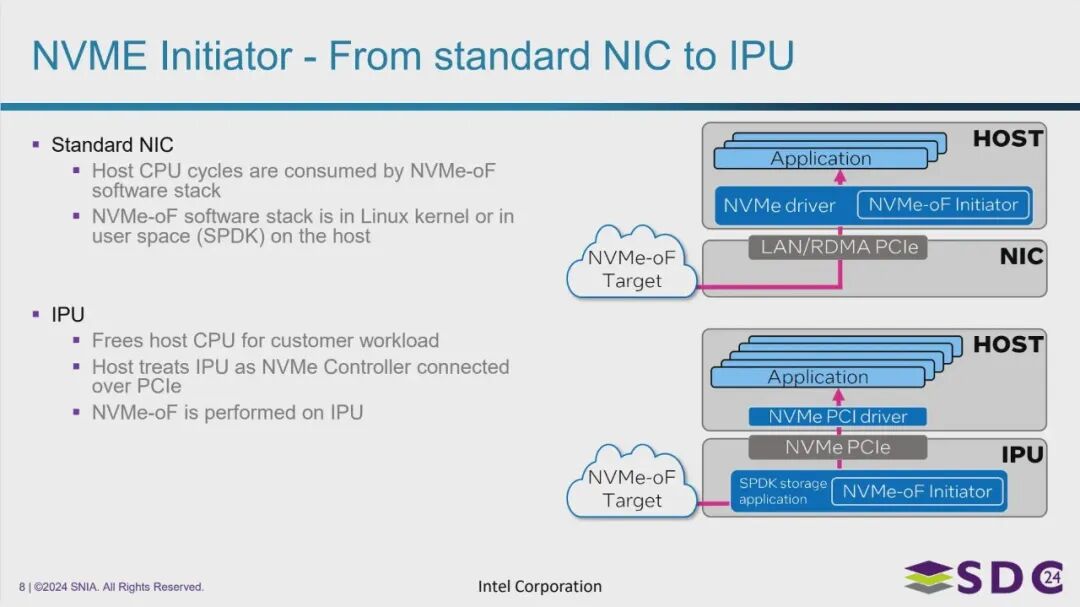
NVMe 发起端功能从主机 CPU 到 IPU 的卸载与演进
NVMe 发起端功能从主机 CPU 到 IPU 的卸载与演进
对比分析:
- 标准网卡模式下的 NVMe 发起端:
- 处理位置: NVMe-oF 发起端的功能主要由主机 (Host) 的 CPU 来执行,运行在主机操作系统(Linux 内核)中的驱动或用户空间的软件栈(如 SPDK)中。
- 资源消耗: 执行 NVMe-oF 协议栈会消耗大量主机 CPU 周期,挤占了用于运行客户应用程序的计算资源。
- 数据路径: 应用程序通过主机上的软件栈生成存储请求,这些请求通过 LAN/RDMA 协议,经由 PCIe 发送给标准网卡,再由网卡传输到 NVMe-oF 存储目标。
- IPU 模式下的 NVMe 发起端:
- 处理位置: NVMe-oF 发起端的功能完全迁移到 IPU 上执行,通常在 IPU 自身运行的操作系统或存储软件栈(如基于 SPDK 的应用)中完成。
- 资源效益: 将 NVMe-oF 处理任务从主机 CPU 卸载,彻底释放主机 CPU 资源,使其能更高效地专注于运行客户应用程序。
- 主机视角: 从主机的角度看,IPU 不再仅仅是一个网卡,而是被视为一个通过 PCIe 直接连接的高性能 NVMe 控制器。
- 数据路径: 应用程序直接通过标准的 NVMe PCI 驱动和 PCIe 接口与 IPU 通信。IPU 接收到请求后,在自身处理 NVMe-oF 协议,并将数据发送到 NVMe-oF 存储目标。
核心价值:
- IPU 通过将 NVMe 发起端等存储协议处理功能从主机 CPU 上剥离并卸载到专用硬件上,显著提高了存储访问的效率和性能,同时降低了主机 CPU 的负载,提升了整个系统的资源利用率和成本效益。
Cite
应用层数据交互 通常涉及到tcp/ip 协议栈,NVMe + IPU的出现,是否会改变应用层数据的访问方式,又会带来哪些新的变化?
应用层通常通过文件系统接口(如 POSIX API)或块设备接口来访问数据,这些接口在底层往往依赖于 TCP/IP 协议栈(例如,通过 NFS、SMB 等网络文件系统,或 iSCSI 等网络块存储协议)或直接与本地存储硬件交互。
NVMe + IPU 的出现,不会直接改变应用层调用文件读写或块设备访问的 API(比如 read()、write()、open() 等 POSIX 函数)。应用开发者通常仍然使用这些熟悉的接口。然而,它会显著改变数据在底层流动的路径和处理方式,进而间接影响应用层的性能、效率和可能的架构选择。
以下是 NVMe + IPU 会带来的变化:
- 存储协议处理的卸载与加速:
- 传统的 NVMe-oF(例如 over TCP 或 over RDMA)发起端软件栈运行在主机 CPU 上,会消耗大量 CPU 资源。
- IPU 将整个 NVMe-oF 发起端软件栈以及相关的网络或 RDMA 协议处理(如果 NVMe-oF 运行在这些协议之上)卸载到 IPU 自身的处理器和加速器上。
- 这意味着原本由主机 CPU 完成的繁重协议解析、数据校验、队列管理等任务现在由 IPU 完成,极大地释放了主机 CPU,让其能更专注于运行核心业务应用。
- IPU 上的专用硬件加速器(如之前提到的 NVMe 处理引擎、加解密/压缩引擎)能以比通用 CPU 更高的效率和更低的延迟处理存储任务。
- 数据路径的优化:
- 在 IPU 模式下,主机应用程序发出的存储请求通过 PCIe 直接发送到 IPU,而不是经过主机自身的网络协议栈。
- IPU 在处理完 NVMe-oF 协议后,再将请求通过其网络接口发送到远程 NVMe-oF 目标存储。
- 这种绕过主机网络栈的数据路径更短、更直接,降低了访问延迟。
- 网络协议栈的角色变化:
- 如果 NVMe-oF 是通过 TCP/IP 传输的(NVMe-oF/TCP),那么 TCP/IP 协议栈的处理将从主机 CPU 转移到 IPU 上。IPU 需要具备高性能的 TCP/IP 处理能力。
- 如果 NVMe-oF 是通过 RDMA 传输的(NVMe-oF/RoCE 或 NVMe-oF/iWARP),那么 RDMA 协议的处理也将在 IPU 上完成。IPU 需要支持 RDMA 功能。
- 关键在于,这些底层网络/传输协议的处理不再是主机 CPU 的负担。
- 更高的数据中心效率和隔离性:
- 通过将基础设施(包括存储访问)与应用彻底分离,IPU 提供更好的性能隔离。一个租户的存储访问活动不会因为消耗大量主机 CPU 资源而影响到同一主机上的其他租户或应用。
- 这为构建更高效、更安全、更易于管理的云基础设施提供了可能。
- 促进新的存储架构:
- IPU 强大的存储卸载和处理能力,使得构建高性能、分布式的软件定义存储(SDS)方案变得更加容易和高效。例如,可以将存储目标端(NVMe-oF Target)的一部分甚至全部功能也集成到 IPU 上,实现更紧密的计算与存储融合或解耦架构。
- 可以更容易地在 IPU 上实现高级存储服务,如数据加密、压缩、去重、RAID 等,而无需消耗主机资源。
NVMe + IPU 并没有改变应用层使用标准 API 访问数据的基本模式。它的核心变革发生在基础设施层:通过将 NVMe-oF 协议栈的处理以及底层网络/传输协议的处理从主机 CPU 卸载到 IPU 上,极大地提升了存储访问性能和效率,降低了主机 CPU 负载,优化了数据路径,增强了隔离性,并为未来更先进的数据中心和存储架构奠定了基础。
可以这样理解:应用层仍然“说”同样的语言(文件/块设备 API),但数据从应用到达存储的“高速公路”和“交通管理局”(IPU)变得更加高效和专业化了,而不再需要“拥挤”的主机 CPU 来充当“交警”和“导航员”。
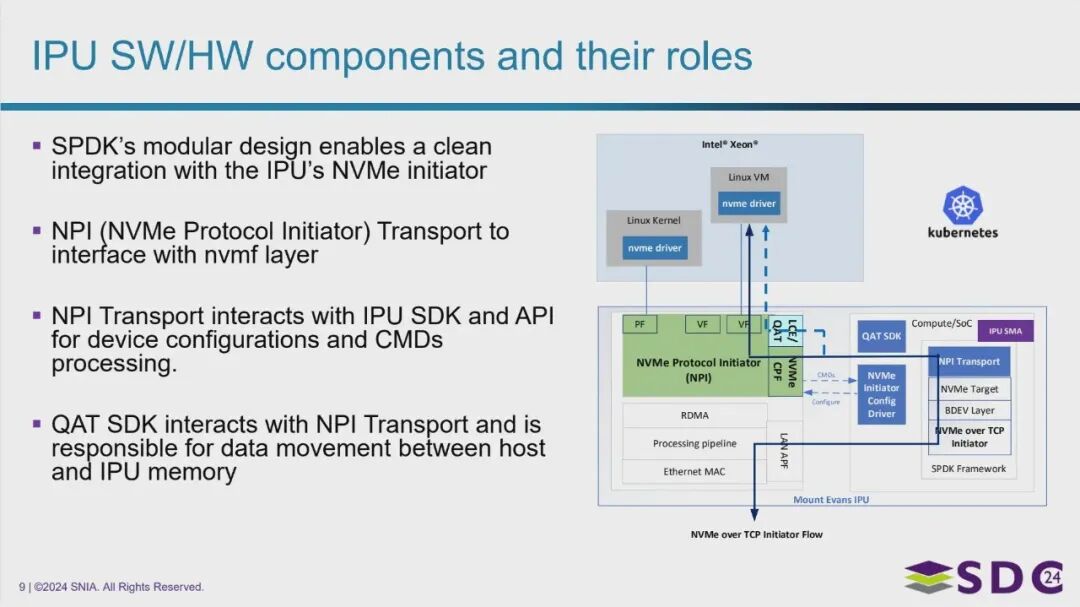
IPU 软硬件组件及其作用
IPU 软硬件组件及其作用
图片展示了 IPU 如何通过一个精心设计的软硬件协同架构来实现高性能的 NVMe 发起端功能。它依赖于 SPDK 这样的框架,通过 NPI、QAT SDK 等关键软件组件,并结合底层的专用硬件加速器,将复杂的 NVMe-oF 处理任务从主机 CPU 转移到 IPU 上,从而实现更高效、更隔离的存储访问。
核心软件栈与框架:
- SPDK (Storage Performance Development Kit) 框架: 作为构建 IPU 高性能存储软件栈的基础,其模块化特性便于集成 NVMe 发起端功能。
- NPI (NVMe Protocol Initiator) 传输层:
- 是 IPU 上 NVMe 发起端的核心软件组件。
- 负责与底层的 NVMe over Fabrics (nvmf) 层进行接口和数据传输。
- 通过与 IPU 的 SDK 和 API 交互,处理 NVMe 设备的配置和具体的命令(如读、写请求)。
- QAT SDK (QuickAssist Technology Software Development Kit):
- 负责管理和利用 IPU 内建的 QAT 硬件加速器。
- 与 NPI 传输层协同工作,关键作用在于加速主机内存与 IPU 内存之间的数据移动,这对于高性能存储访问至关重要(尤其是在数据需要经过加解密或压缩时)。
- NVMe Initiator Config Driver 和 NVMe over TCP Initiator: 负责具体的 NVMe 发起端功能实现,例如设备配置和基于 TCP 网络的 NVMe-oF 协议处理。
- BOEV 层 (Block Offload Engine Virtio Layer): 暗示 IPU 支持通过 Virtio 等机制,将块设备相关的处理任务卸载并呈现给虚拟机或其他环境。
主机 (Host) 与 IPU 的协作模式:
- 主机上运行标准的应用程序和 nvme 驱动。
- 主机应用程序通过标准的存储接口(如块设备接口)发出请求。
- 主机上的 nvme 驱动通过 PCIe 总线与 IPU 进行通信。
- IPU 上的 NVMe 发起端软件栈(包括 NPI、SPDK 等)接收请求,并在 IPU 硬件加速器的协助下处理 NVMe-oF 协议,最终将请求发送到远程 NVMe-oF 存储目标。
IPU 内部硬件支撑:
- 图示及之前内容表明,IPU 包含专门的硬件组件(如 NVMe 模块、RDMA 模块、QAT 硬件、处理管线、高速以太网接口等),这些硬件为上述软件组件的高效运行提供了基础和加速能力。
延伸思考
这次分享的内容就到这里了,或许以下几个问题,能够启发你更多的思考,欢迎留言,说说你的想法~
- IPU 在彻底解耦基础设施层后,将如何影响未来软件定义存储 (SDS) 和超融合基础设施 (HCI) 的架构设计?
- 除了存储和网络,IPU 未来还可能卸载和加速哪些其他类型的基础设施任务,以进一步提升数据中心效率?
- IPU 的普及将如何改变数据中心运维和管理的模式,对现有的技能要求和工具链带来哪些挑战和机遇?
#智能网卡演进 #数据中心运力提升
原文标题:Leveraging SPDK Acceleration Framework for Optimal IPU/DPU Storage Workflows
Notice:Human's prompt, Datasets by Gemini-2.5-flash-thinking
---【本文完】---
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-05-12,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号