OpenClaw的架构逻辑与企业级技术特性


OpenClaw的设计哲学强调“数据主权”与“执行自主”。在企业环境中,这种架构解决了云端模型无法直接触达本地文件系统和敏感业务接口的痛点。其五组件架构——网关(Gateway)、大脑(Brain)、记忆(Memory)、技能(Skills)以及执行节点(Nodes)——共同构成了一个能够感知环境并做出反馈的动态系统。
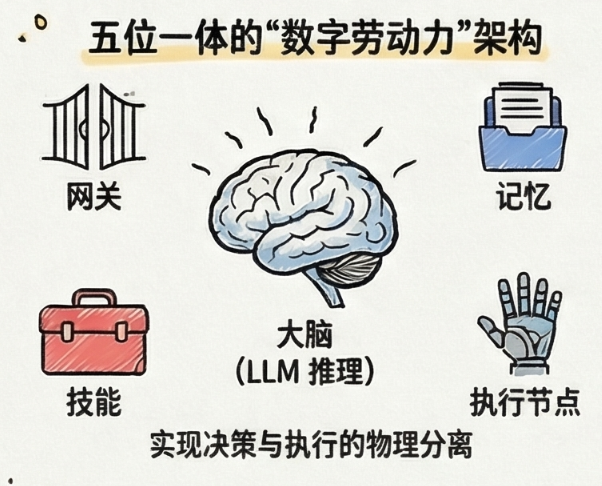
核心组件的运行机制与解耦优势
OpenClaw网关作为系统的中枢神经,采用了长连接WebSocket协议,默认监听18789端口。这种设计允许智能体从50多个消息和业务通道(如飞书、Slack、WhatsApp、Gmail等)接收指令,而推理逻辑则被隔离在“大脑”组件中 。网关本身不进行任何逻辑运算,仅负责消息路由,这种高度的模块化确保了即使某个通讯渠道发生故障,核心智能体的运行状态也不会受到干扰。
架构组件 | 核心功能 | 企业级技术考量 |
|---|---|---|
网关 (Gateway) | 接收多渠道输入,进行消息路由与身份验证。 | 支持OAuth 2.0、API密钥及硬件令牌,确保控制面安全 。 |
大脑 (Brain) | 编排LLM调用,运行ReAct(推理-行动)循环。 | 模型无关性允许企业根据任务复杂度在Claude、GPT-4与本地开源模型间切换 。 |
记忆 (Memory) | 基于本地Markdown文件的长短期记忆管理。 | 数据留存本地,符合GDPR等隐私合规要求,无需维护复杂的向量数据库。 |
技能 (Skills) | 定义智能体能力的YAML/Markdown描述文件。 | 允许企业根据专有SOP(标准作业程序)快速扩展特定业务能力。 |
执行节点 (Nodes) | 在具体终端(macOS/iOS/Android/Linux)执行底层操作。 | 支持摄像头访问、屏幕录制及系统级指令执行。 |
这种架构的核心洞察在于,它将“决策”与“执行”进行了地理上的分离:决策可以由高性能的云端大模型完成,而执行则发生在企业受控的本地节点上 。
自主学习与RLHF的工程化落地
OpenClaw-RL框架的引入,使得智能体具备了从日常对话反馈中持续进化的能力。通过异步强化学习(RL)框架,企业能够将员工对智能体输出的自然语言评价转化为策略优化的训练信号。

R(s,a)=PRM(conversation_history)+Feedback_Signal公式中体现了过程奖励模型(PRM)如何对智能体的每一轮推理行为进行评分。OpenClaw-RL不仅支持传统的Binary RL(二元奖励),还支持更为先进的在策略蒸馏(OPD)。在OPD范式下,当人类给出“你应该先检查文件,而不是直接删除”的反馈时,法官模型(Judge Model)会提取事后暗示(Hindsight Hint),并以此增强教师模型的输出,进而通过Token级别的概率差距引导学生模型修正其推理路径。这种闭环反馈机制是企业培养领域专家型智能体的关键。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-03-06,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号