打工人必备!Openclaw实践之采集+发布小红书自动化方案,每天省下3小时!
原创
打工人必备!Openclaw实践之采集+发布小红书自动化方案,每天省下3小时!
原创
LucianaiB
修改于 2026-03-08 15:43:58
修改于 2026-03-08 15:43:58
前言
我是热爱探索AI前沿技术的LucianaiB。
这次想带你用 2 小时左右,搭建一条「从采集到发布」基本全自动的小红书内容流水线。
之前那篇 Openclaw 保姆级教程反响不错,很多同学在后台问:能不能一键实现“小红书自动采集 + 自动写文案 + 自动发布”?所以带来本文Openclaw实践之采集+发布小红书自动化方案,温馨提示,本文预计部署需要预计2小时左右,所以谨慎开始!!!!
效果预览
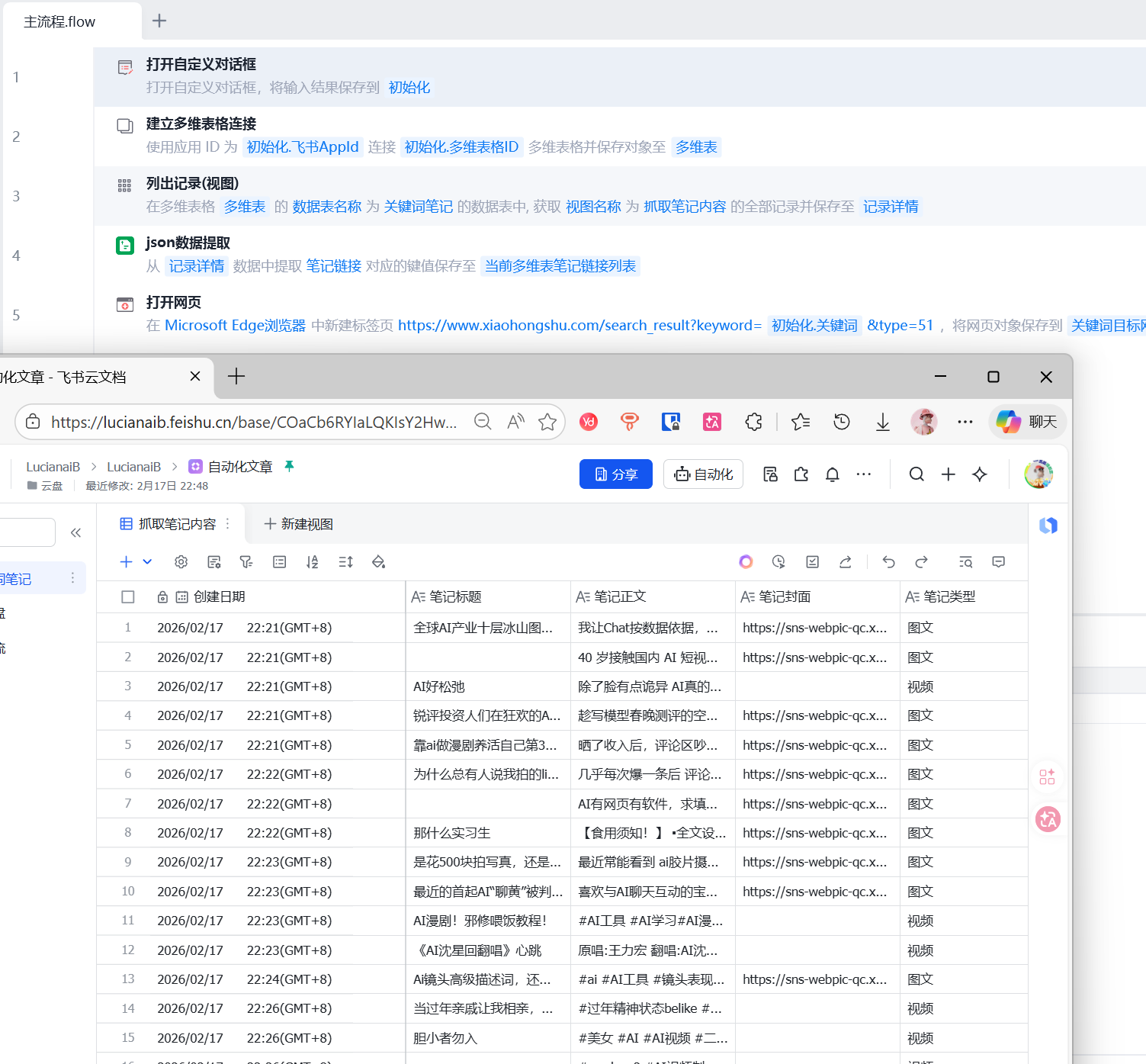
影刀 + 多维表效果
每天影刀定时爬取指定话题的热门小红书笔记,结构化存入飞书多维表,等于给自己搭了一个“小红书素材私库”。
img
小红书生成skill+openclaw进行整理效果
Openclaw 自动读取多维表数据,结合自制小红书 skill,批量生成符合算法规则的爆款文案(标题 + 正文 + 标签 + 互动 + CTA)。
img

img

img
小红书MCP发布效果
只需要在 Openclaw 里发一句指令,就能触发 xiaohongshu‑mcp 完成登录检查、内容投放,真正做到“想好了就发”,彻底告别手动几十分钟的机械操作。

img
本文技术栈介绍
影刀爬取数据 + 多维表存储数据 + 自制小红书skill + openclaw进行整理 + 小红书MCP发布
本文内容概览
1.技术栈使用说明
2.影刀爬取数据并且多维表存储数据
3.自制小红书skill
4.openclaw进行整理
5.小红书MCP发布
💡 开始前建议:点个关注不迷路~
建议你在有连续 2 小时空档时再开始动手,中途尽量不要打断,这样一口气搭完,后面只需要“喂关键词 + 看结果”,自动化的成就感会非常强。
1.技术栈使用说明
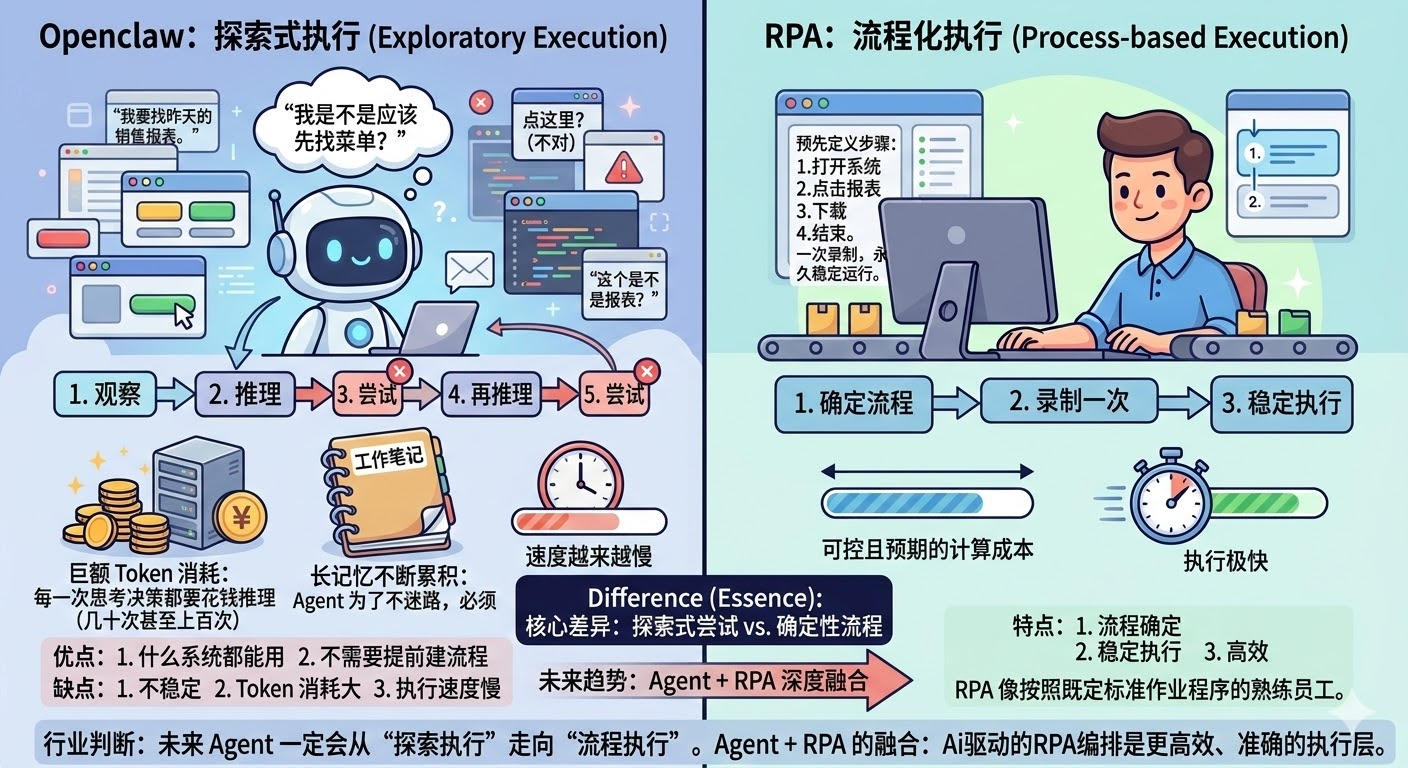
为什么不用 Openclaw 全流程获取,而是 RPA ?
Openclaw 好比研究生,他的使用需要消耗大量的钱(Token),后果就是Token 消耗巨大+长记忆不断累积+不停探索目标,而RPA就是实习生,他只需要部署好流程,就可以开始干活,优点是:一次录制+稳定执行。要有Token的话,但我没说。
未来趋势:Agent+RPA的融合
img
2.影刀爬取数据并且多维表存储数据
2.1 影刀前置准备
注册影刀RPA账号
通过专属链接注册,可得1个月创业版权限:https://www.winrobot360.com/share/activity?inviteUserUuid=748770993651355650
下载影刀RPA
下载应用:https://www.yingdao.com/client-download/
img
安装插件
首页点击头像,选择工具,选择自动化插件。
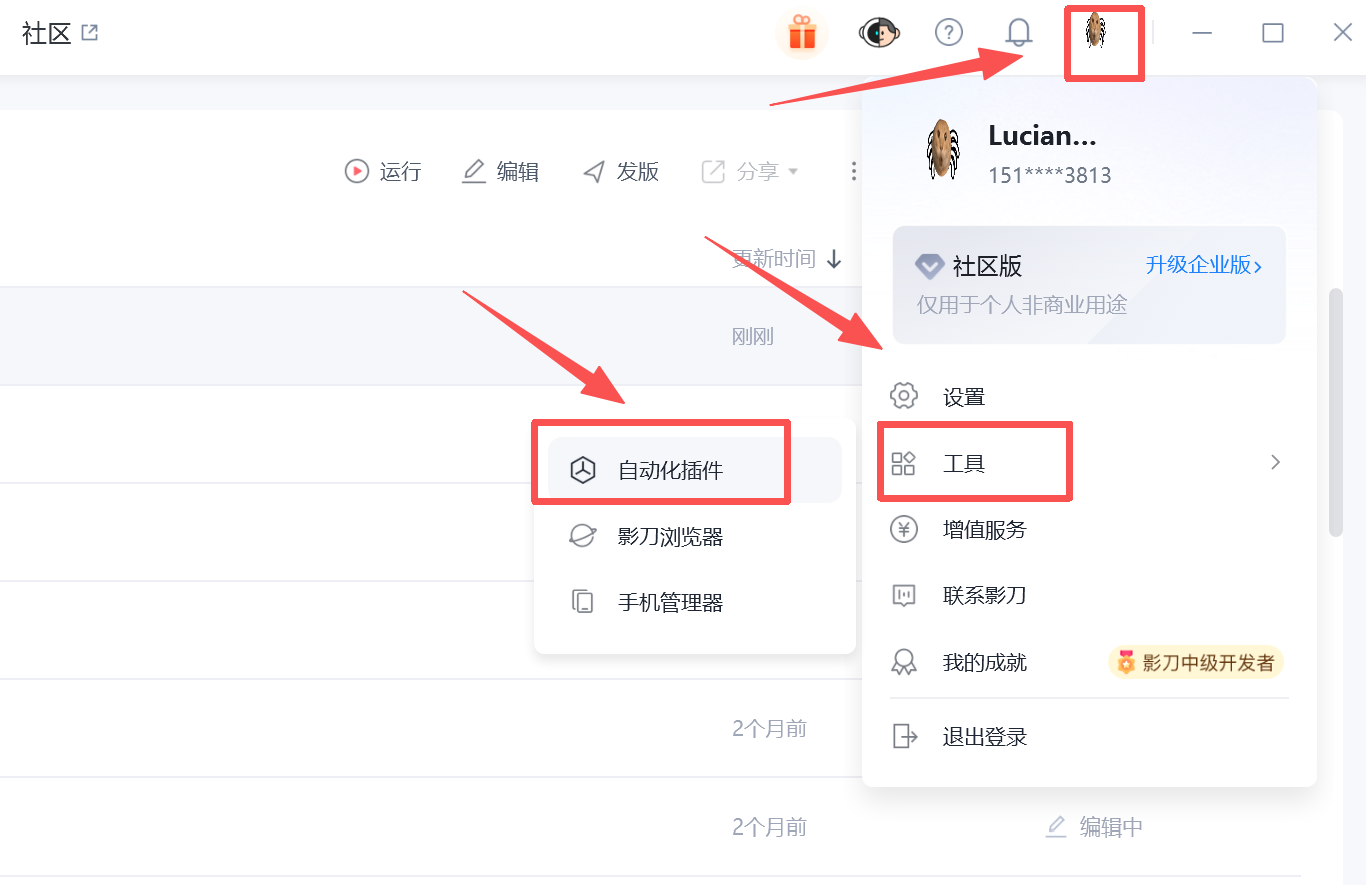
img
安装对应的插件。

img
2.2 小红书低粉爆款关键词笔记采集详细教程
2.2.1 多维表初始化
作用:存储采集的笔记,可以看作是一个数据库,放数据的空间。
1.去飞书开放平台(https://open.feishu.cn/app?lang=zh-CN),新建一个应用。
2.进入应用右侧的权限管理,开通多维表格和云文档两个的全部权限。
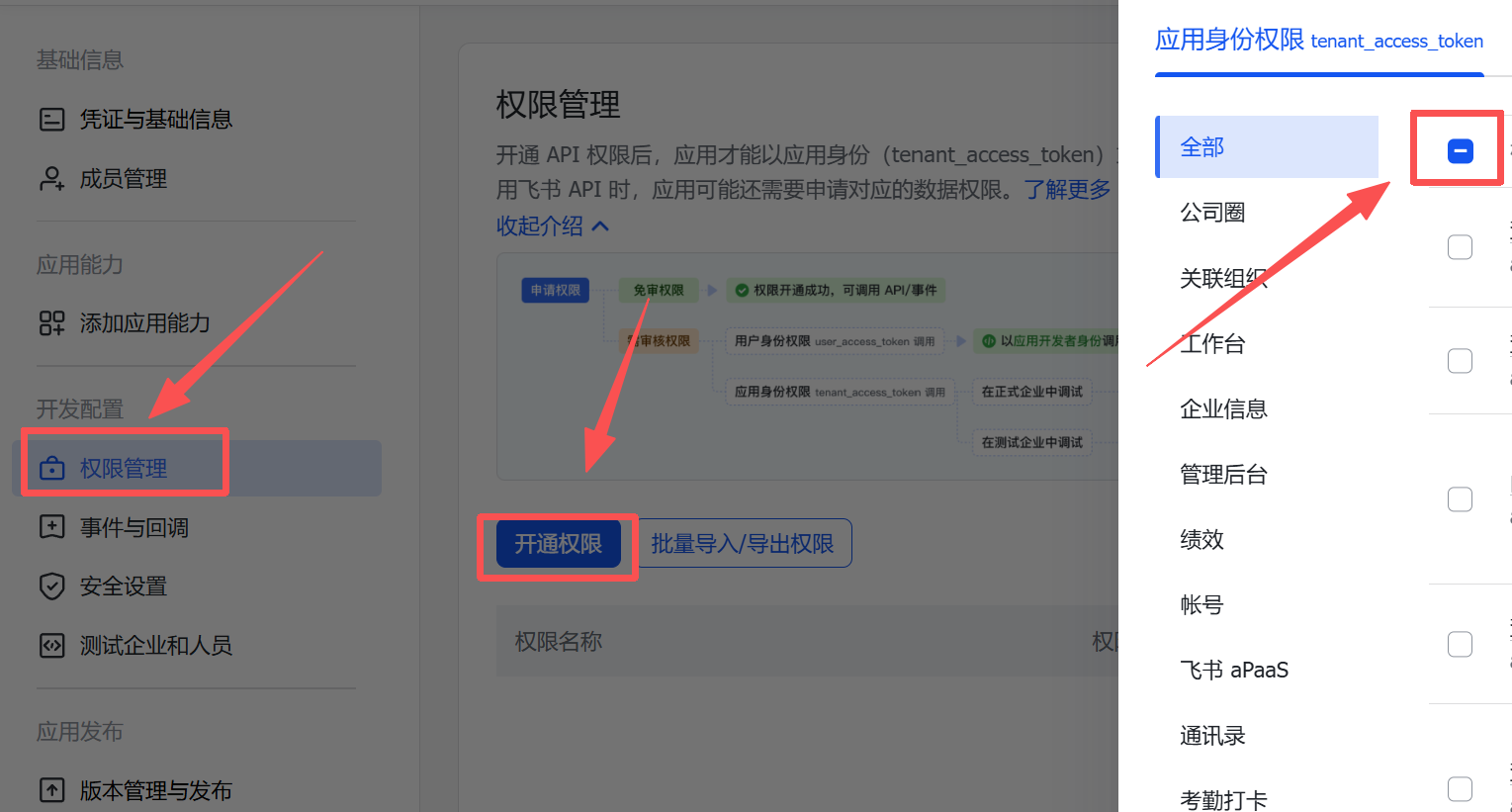
img
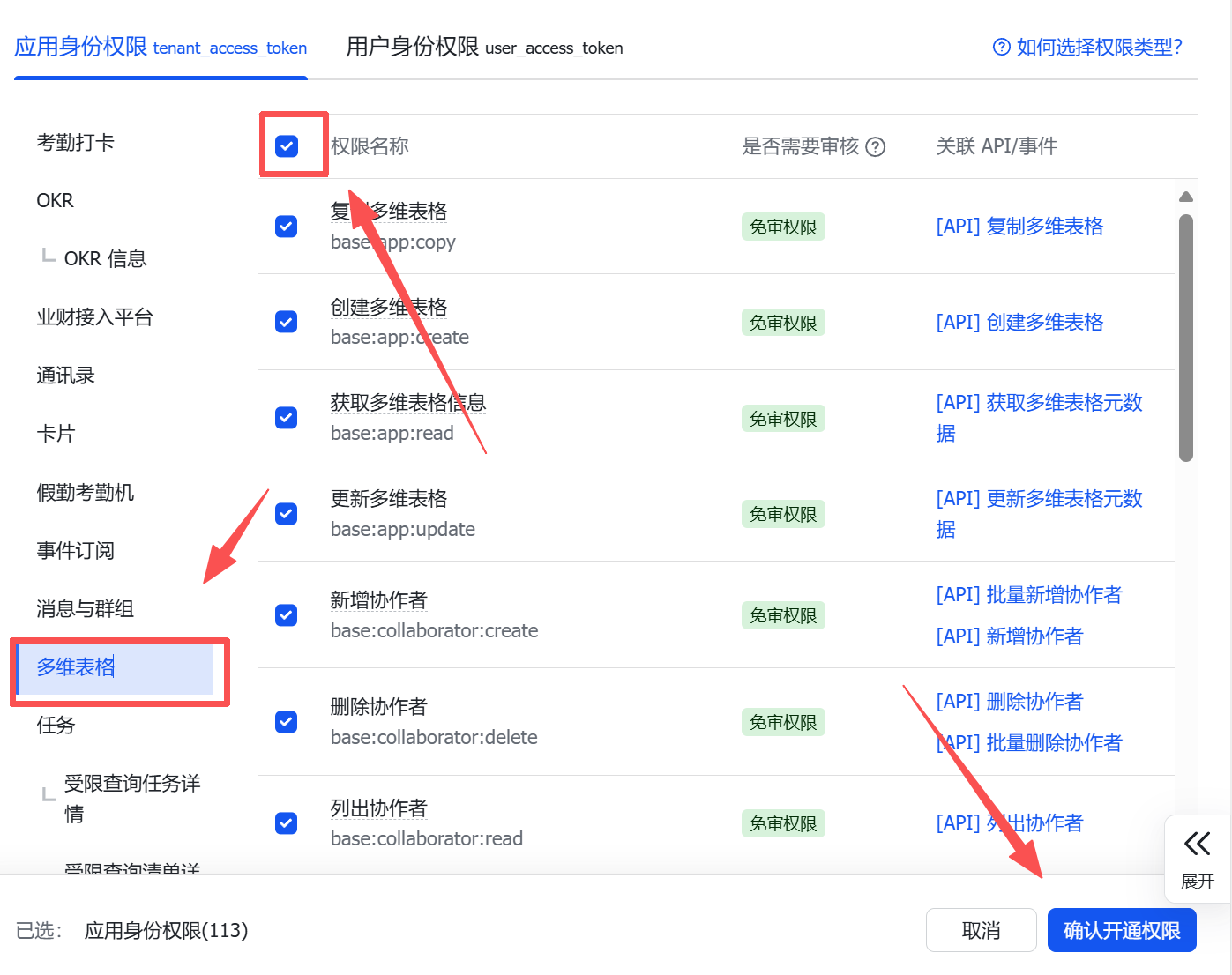
img
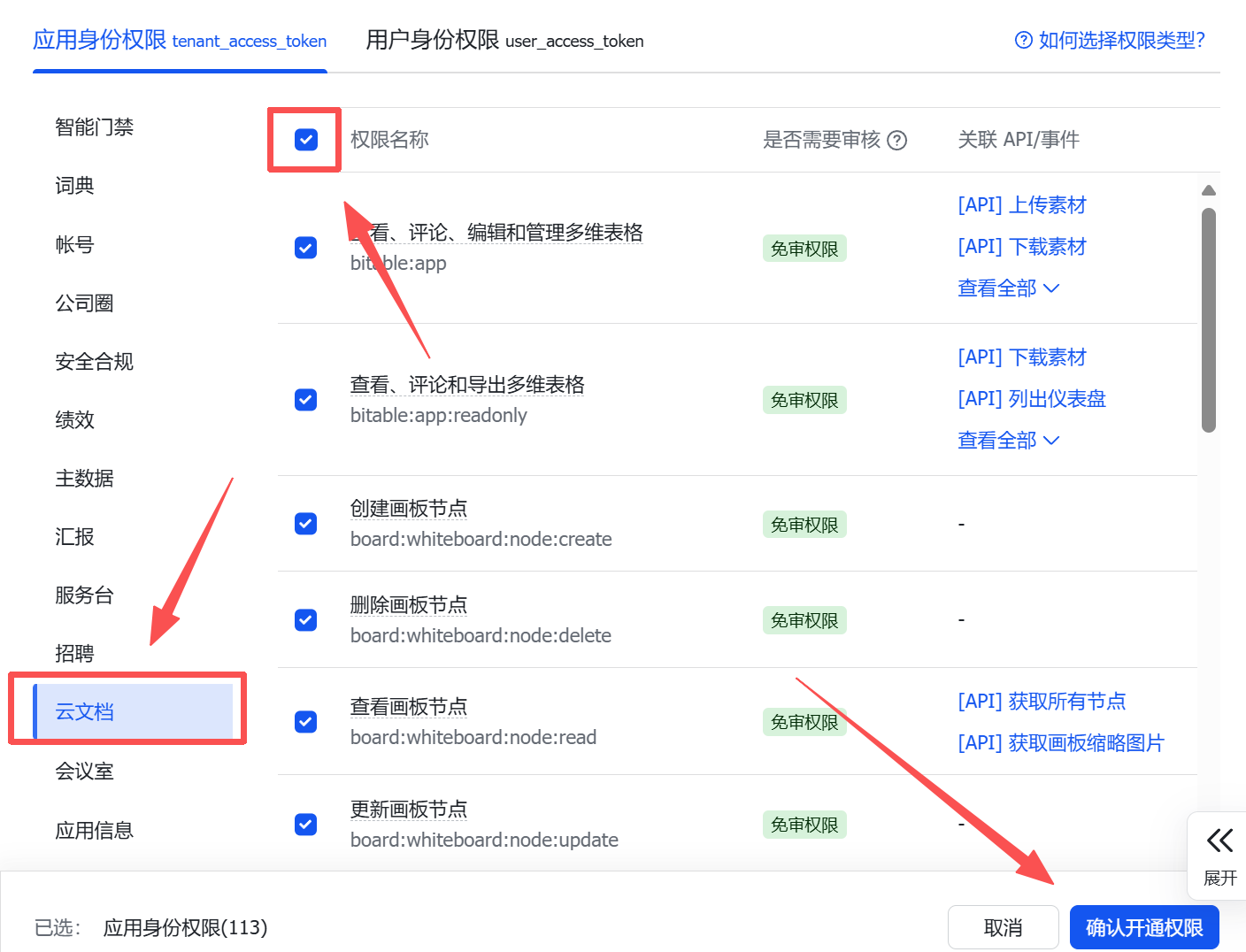
img
3.创建版本并发布应用。
4.在凭证与基础信息获取 AppId和 AppSecret。
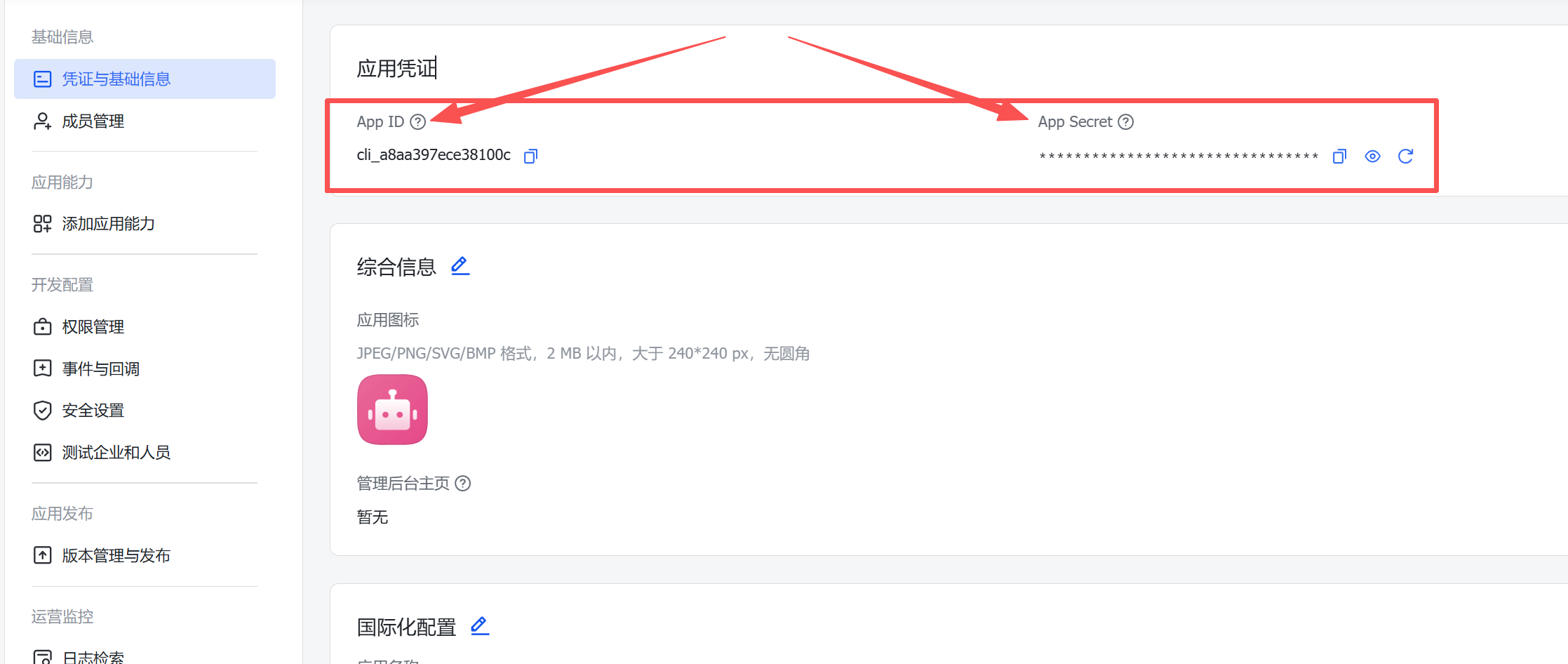
img
5.新建一个多维表(https://sxuwebtech.feishu.cn/base)。
6.给多维表添加应用。
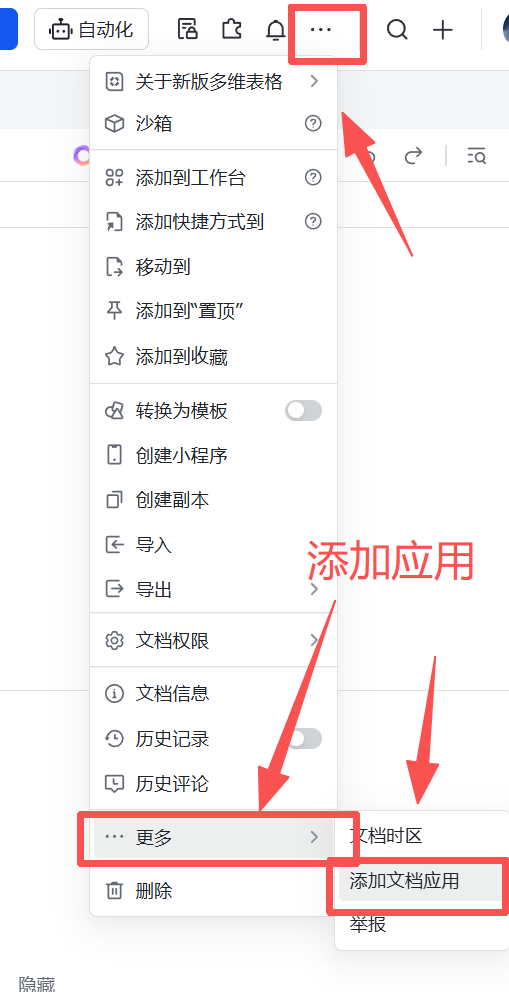
img
7.获取多维表格ID
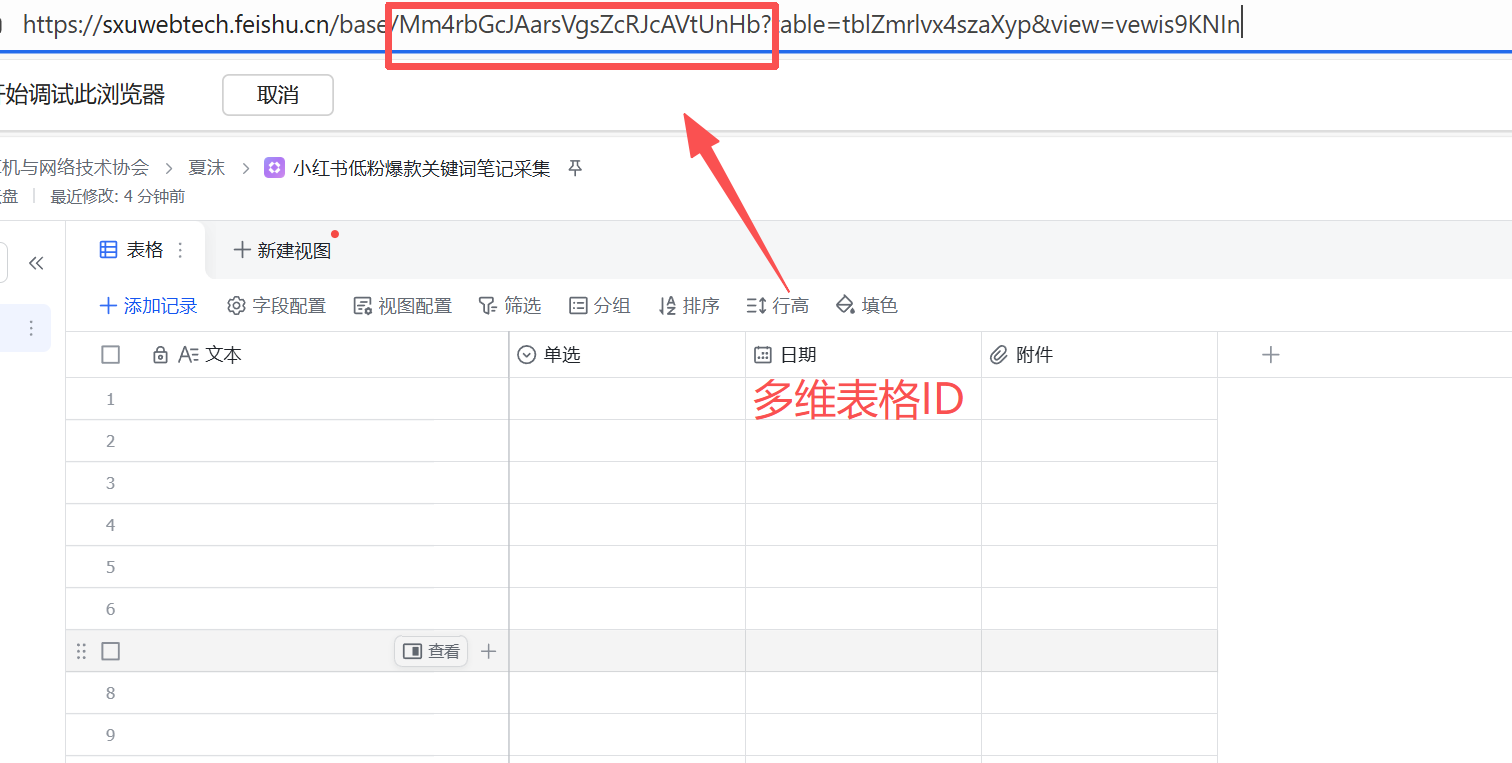
img
就这样我们得到了AppId,AppSecret以及多维表格ID。
AppId:
AppSecret:
多维表格ID:
2.2.2 设置自定义对话框
具体设置如下:
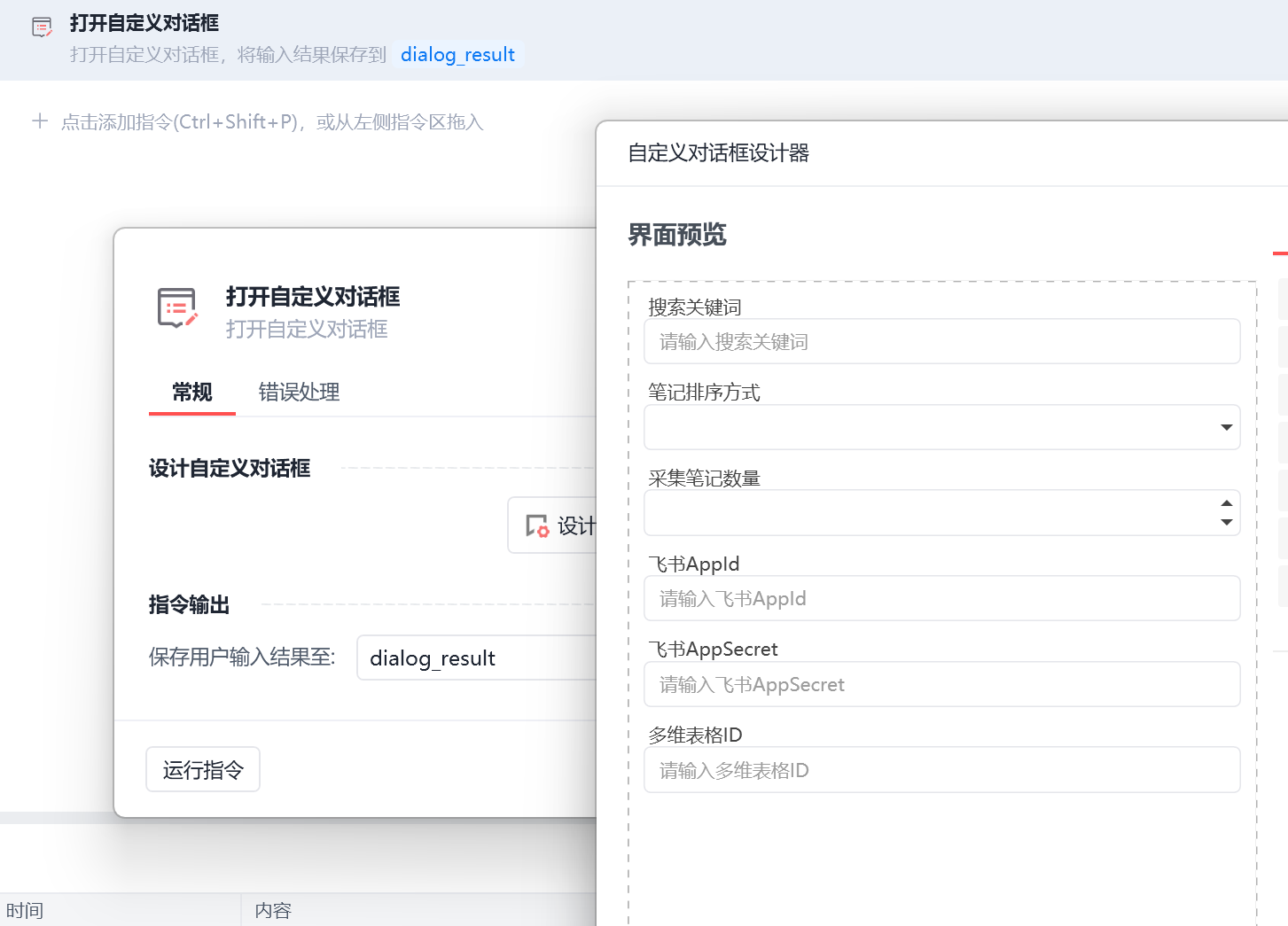
img
2.2.3 建立多维表连接
找到建立多维表格链接指令。
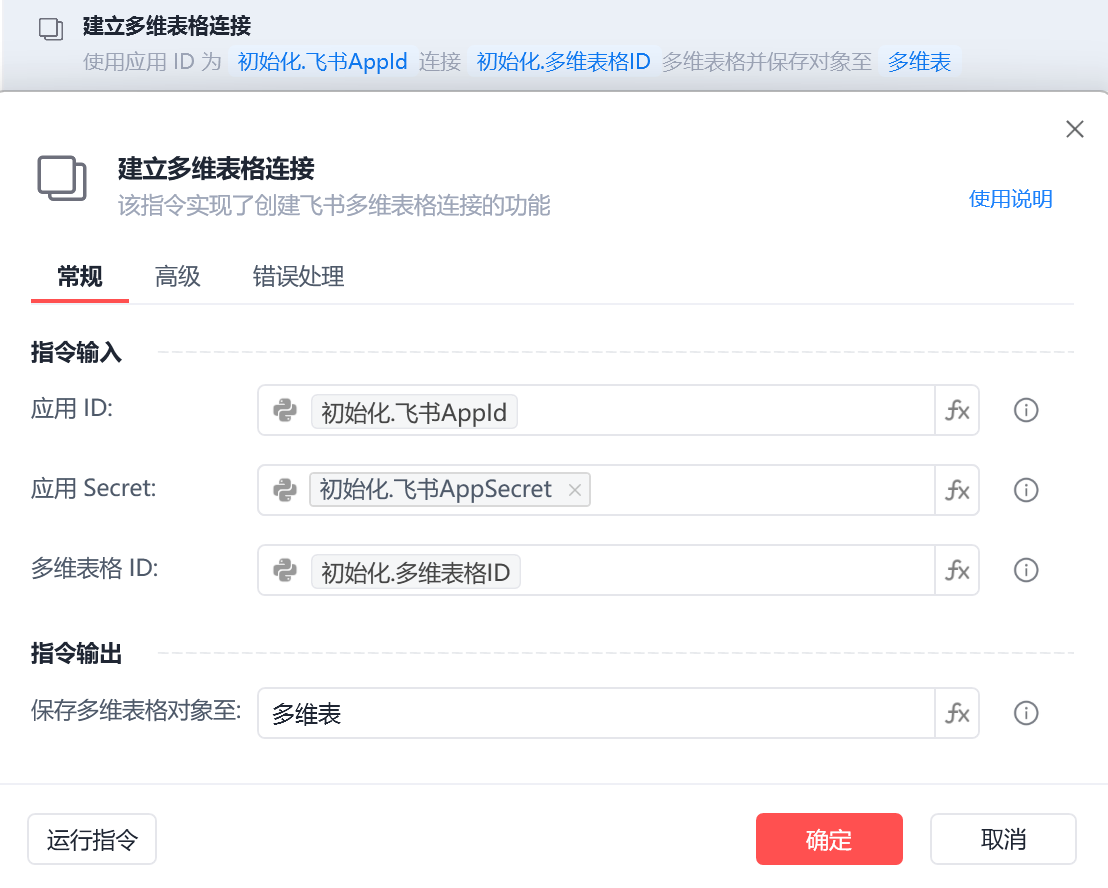
img
使用列出记录(视图)获取多维表内容。
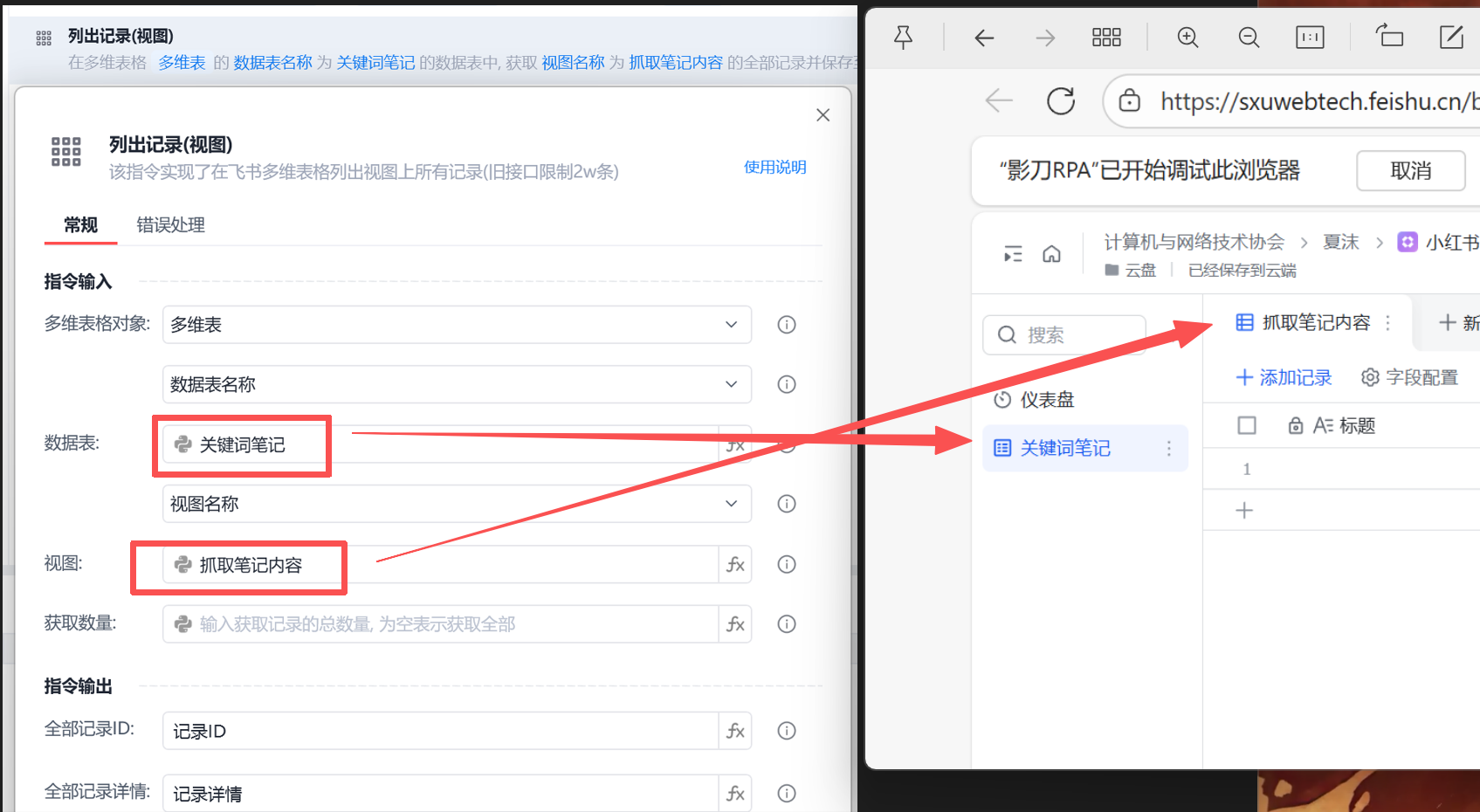
img
使用json数据提取提取具体的列的内容。
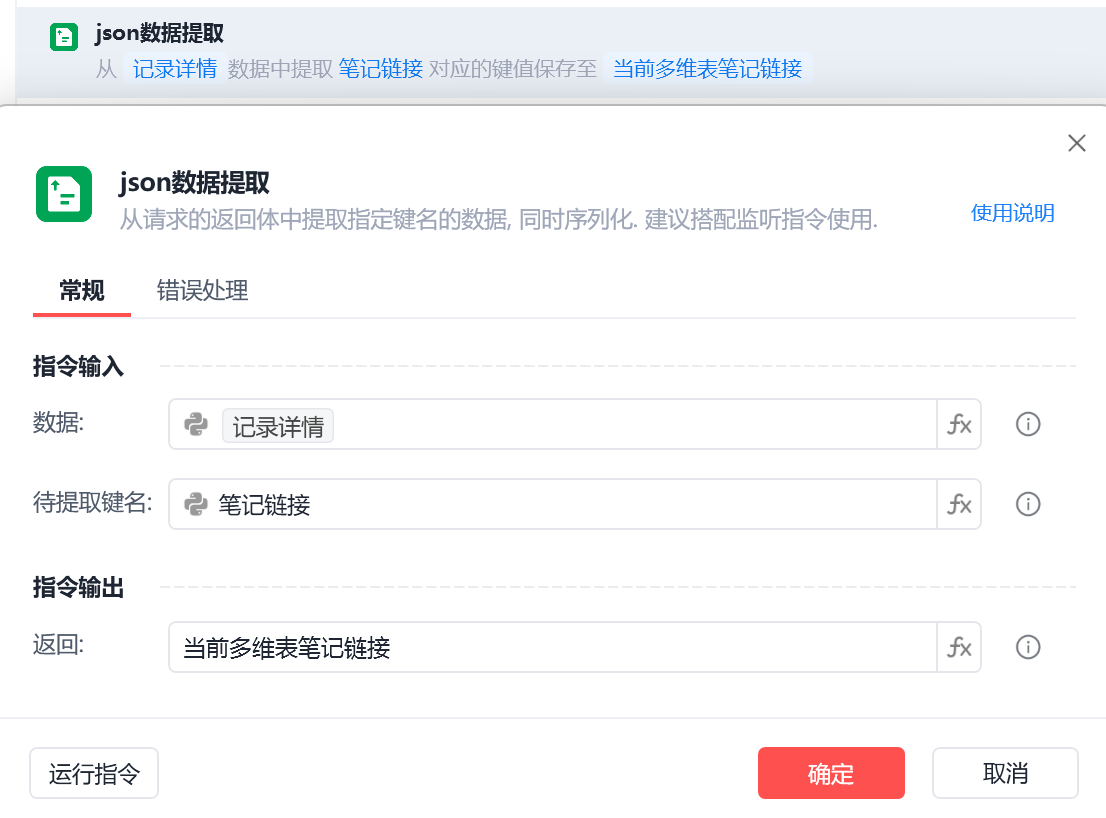
img
可以通过打印日志查看是否成功了解。
2.2.4 打开关键词网站
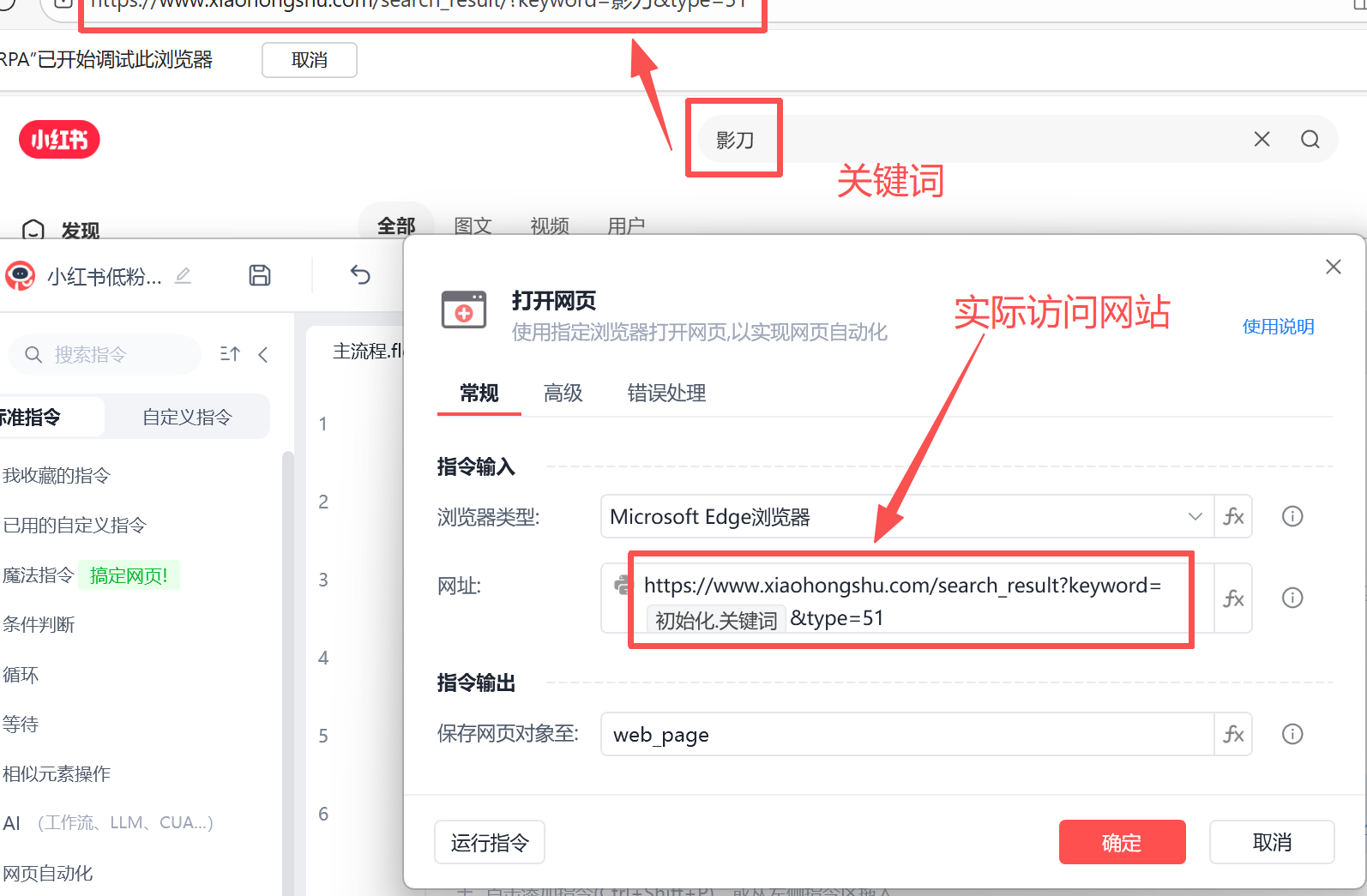
img
2.2.5 按照筛选排序
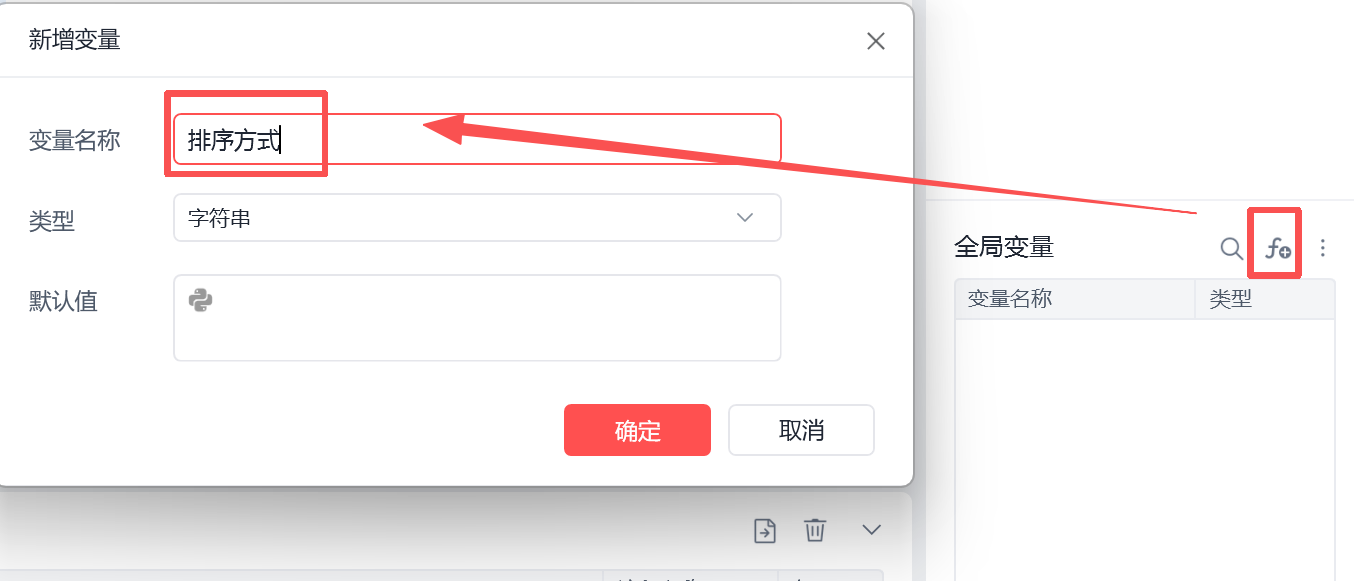
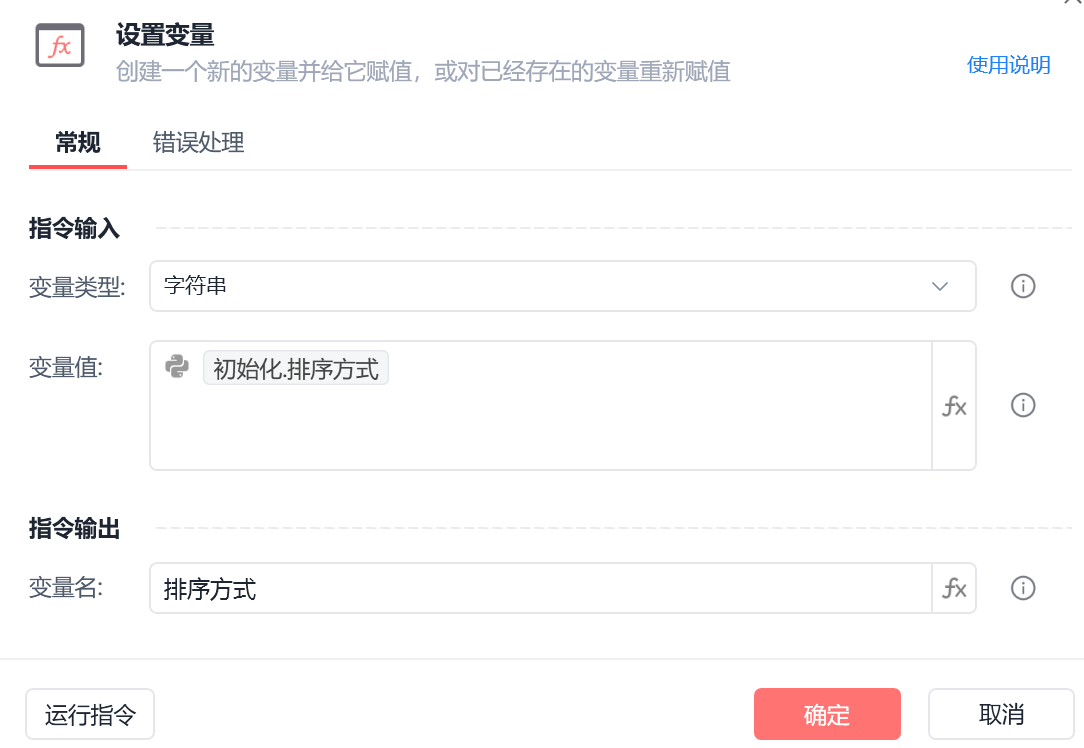
新建一个全局变量排序方式,并且为其赋值初始化时的排序方式,在后续会需要。
img
img
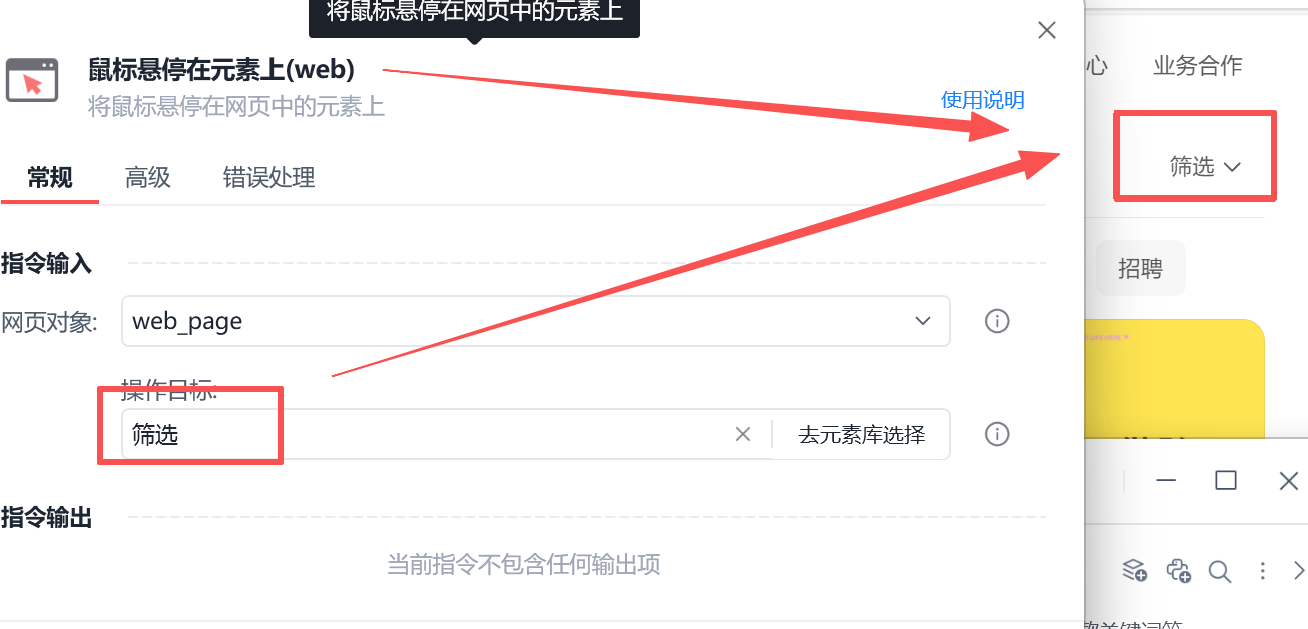
使鼠标停在筛选的按钮上才会出现选项。
img
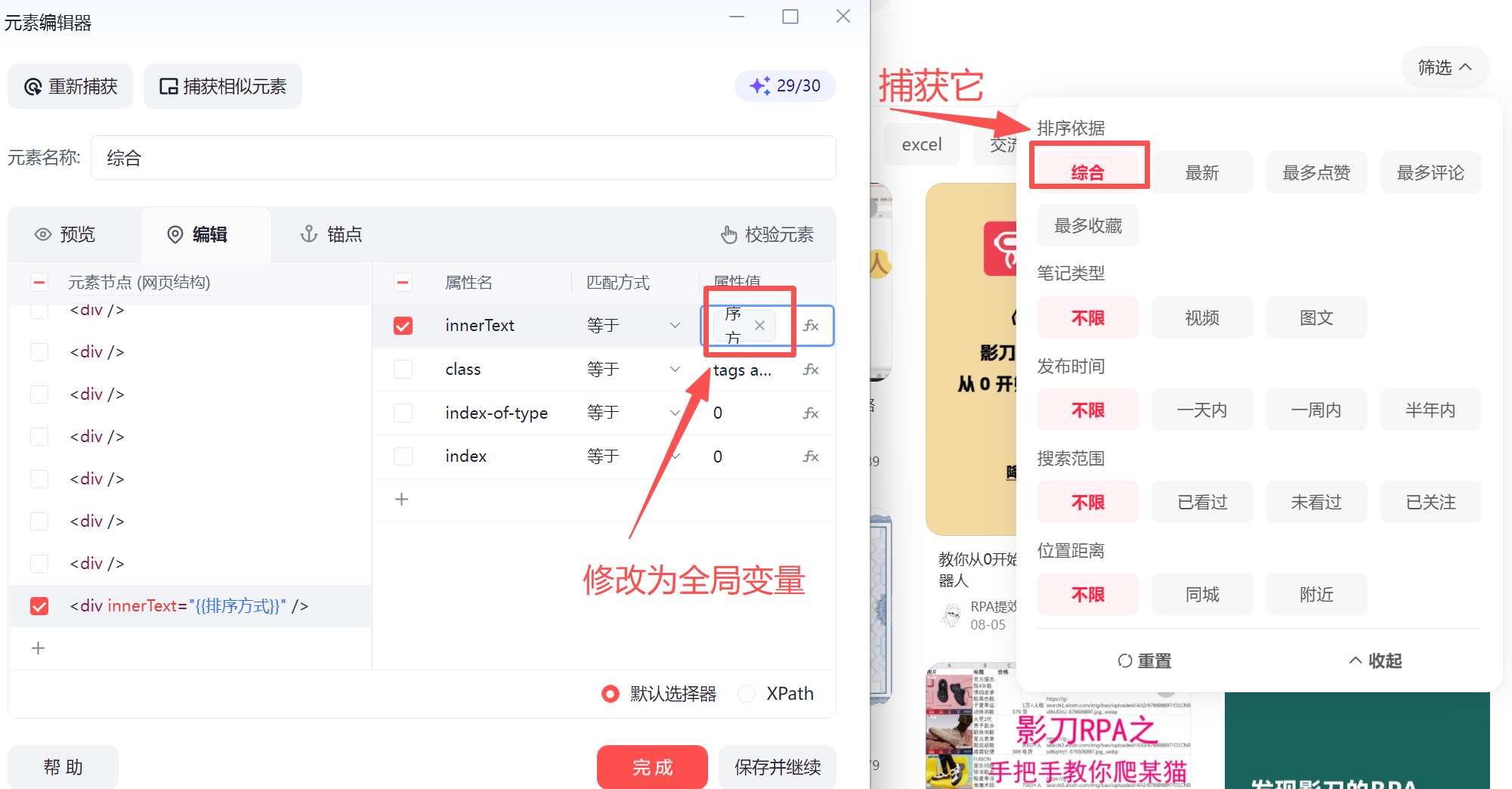
捕获筛选条件,并且在文本匹配中使用全局变量。
img
2.2.6 循环获取笔记网站
使用循环获取列表(Web)获取每个笔记,然后点击循环的笔记,使用获取网页信息,获取每个笔记的链接+关闭当前笔记,就使用获取到了每个笔记的网站。

img
判断获取的笔记是否在多维表中,如果包含,则打印日志,关闭笔记,进行下一次循环,如果不存在,则进行操作。

img
2.2.7 采集笔记信息
笔记标题
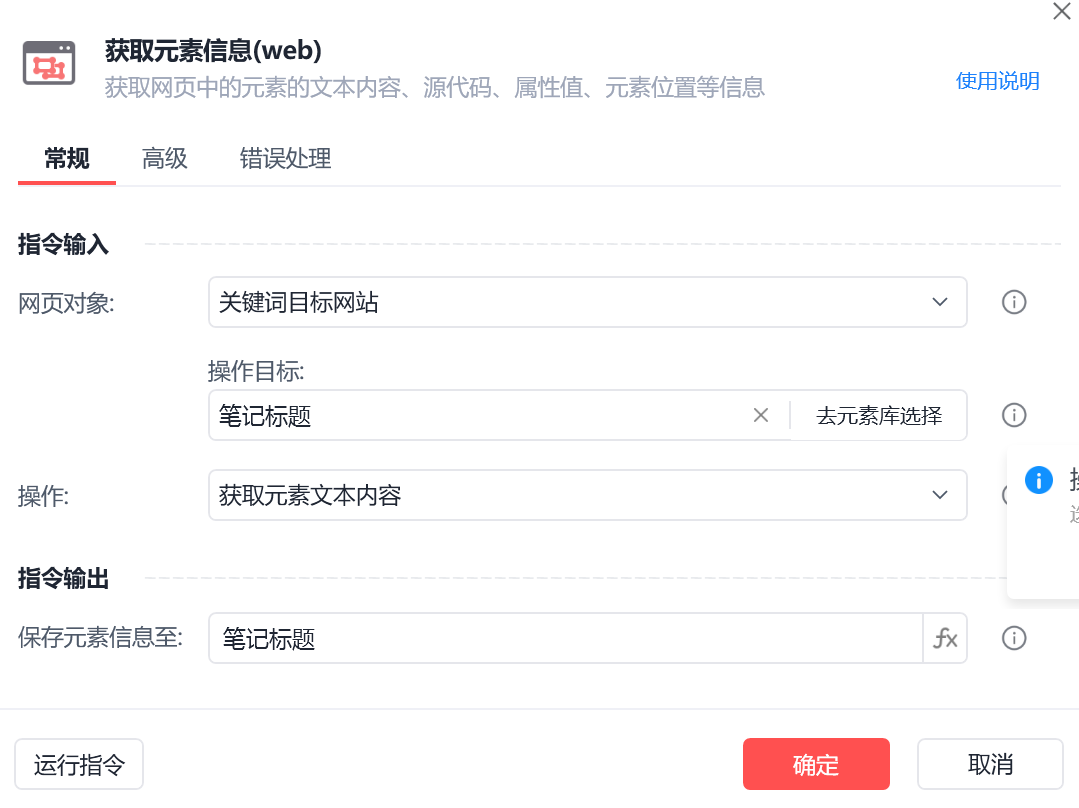
img

img
笔记正文
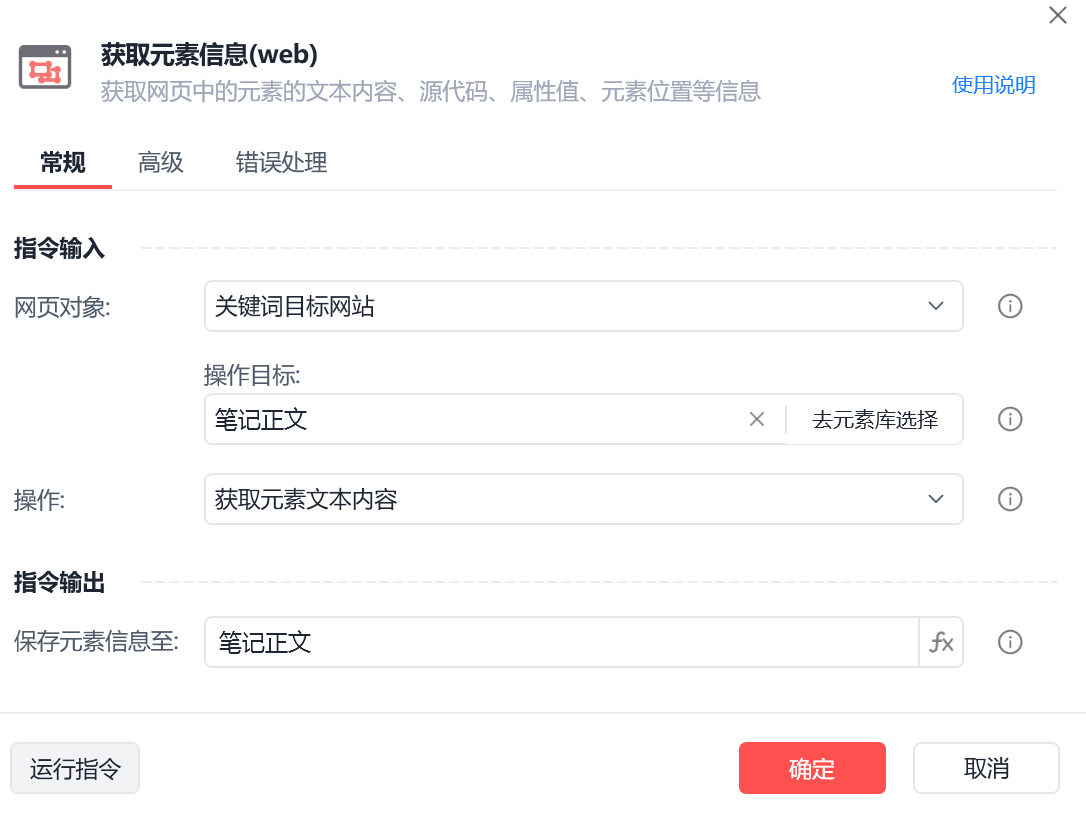
img

img
笔记点赞数+收藏数+评论数

img
注意:如果数量实际为0,那么捕获的是文字——"点赞","收藏","评论",将其赋值为0。
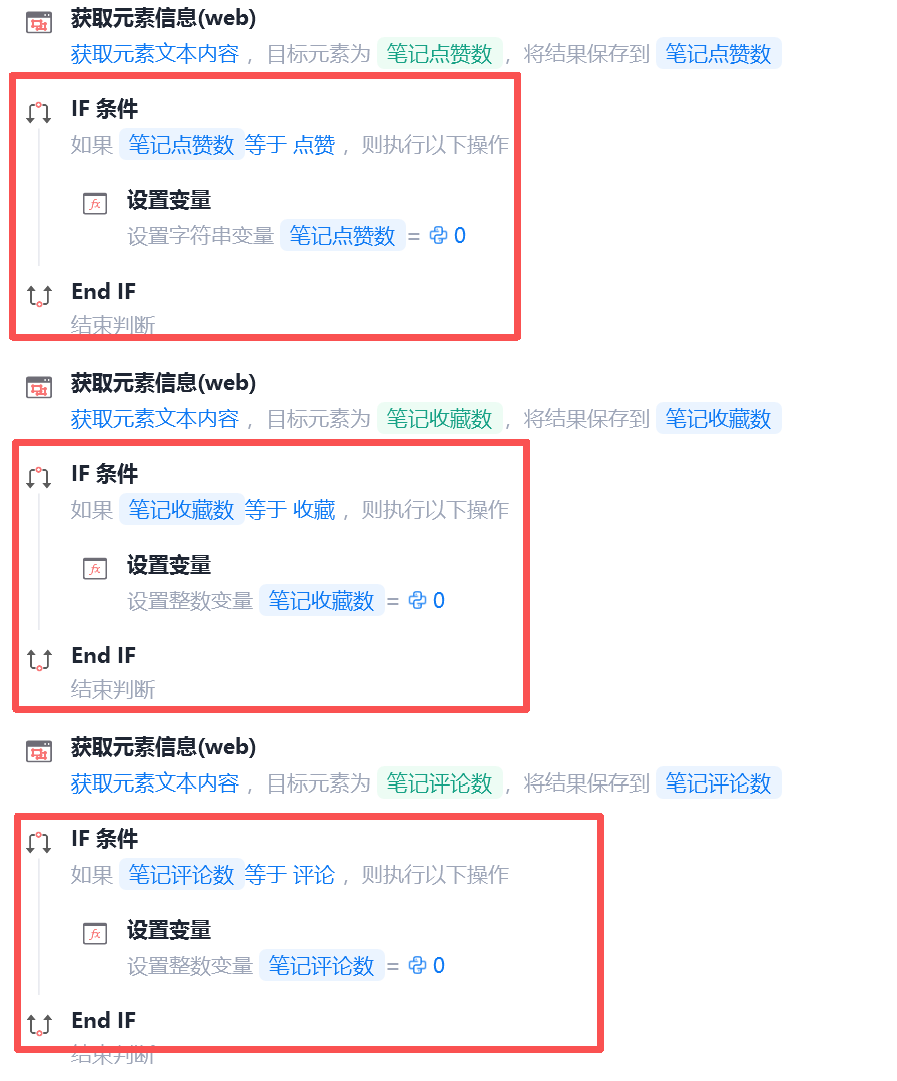
img
笔记类型
获取笔记是图片还是视频可以通过笔记左侧展示的格式来判断,使用 if网页包含指令 可以做到这个功能,初始化为视频类型,如果包含图文的则为图文类型,否则为视频类型。
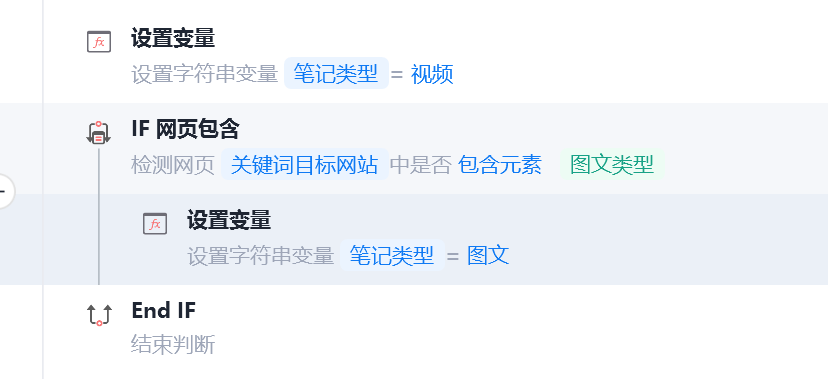
img
笔记封面图
通过获取笔记封面,分析源码可知,通过src可以获取到封面链接。
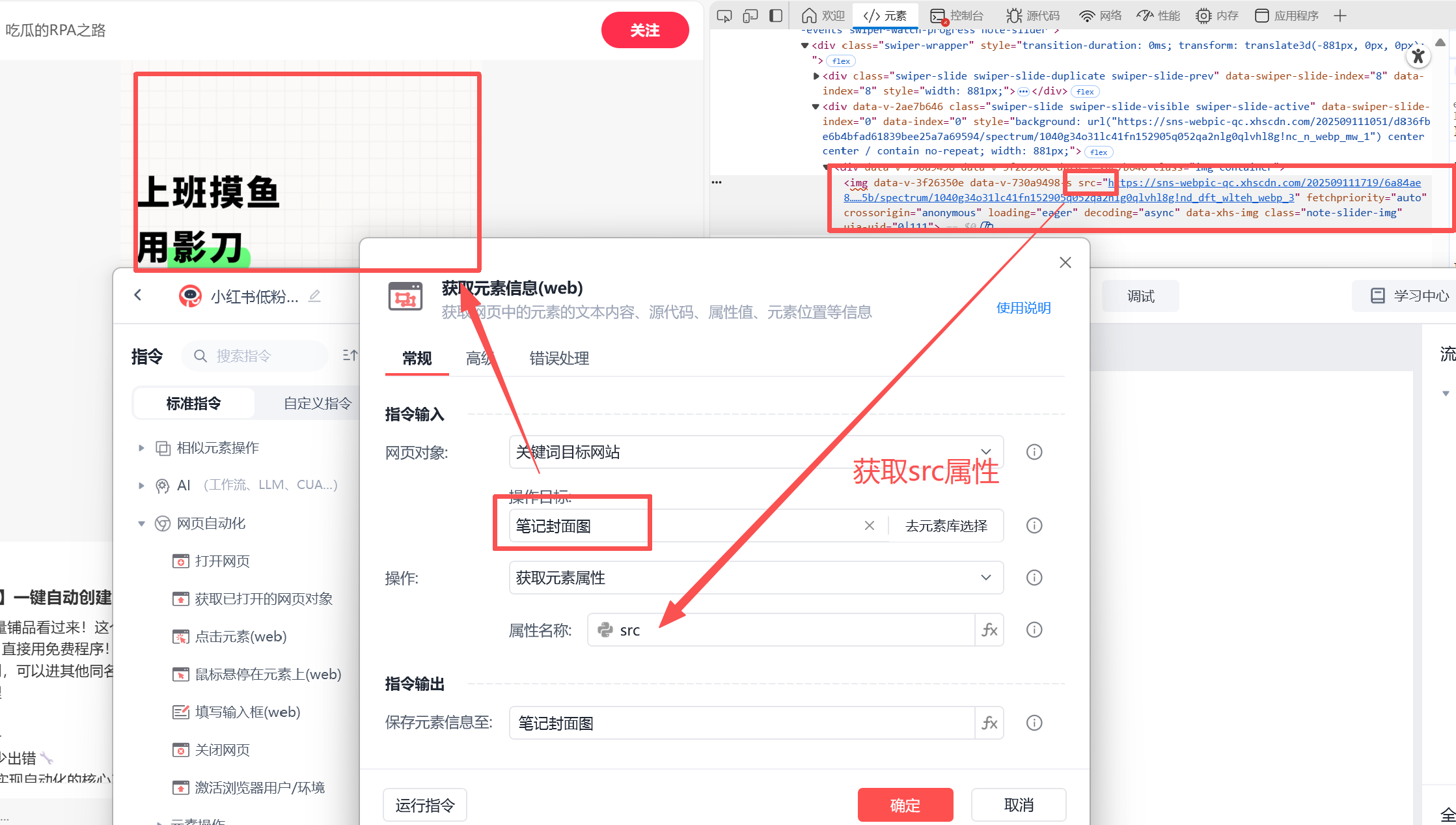
img

img
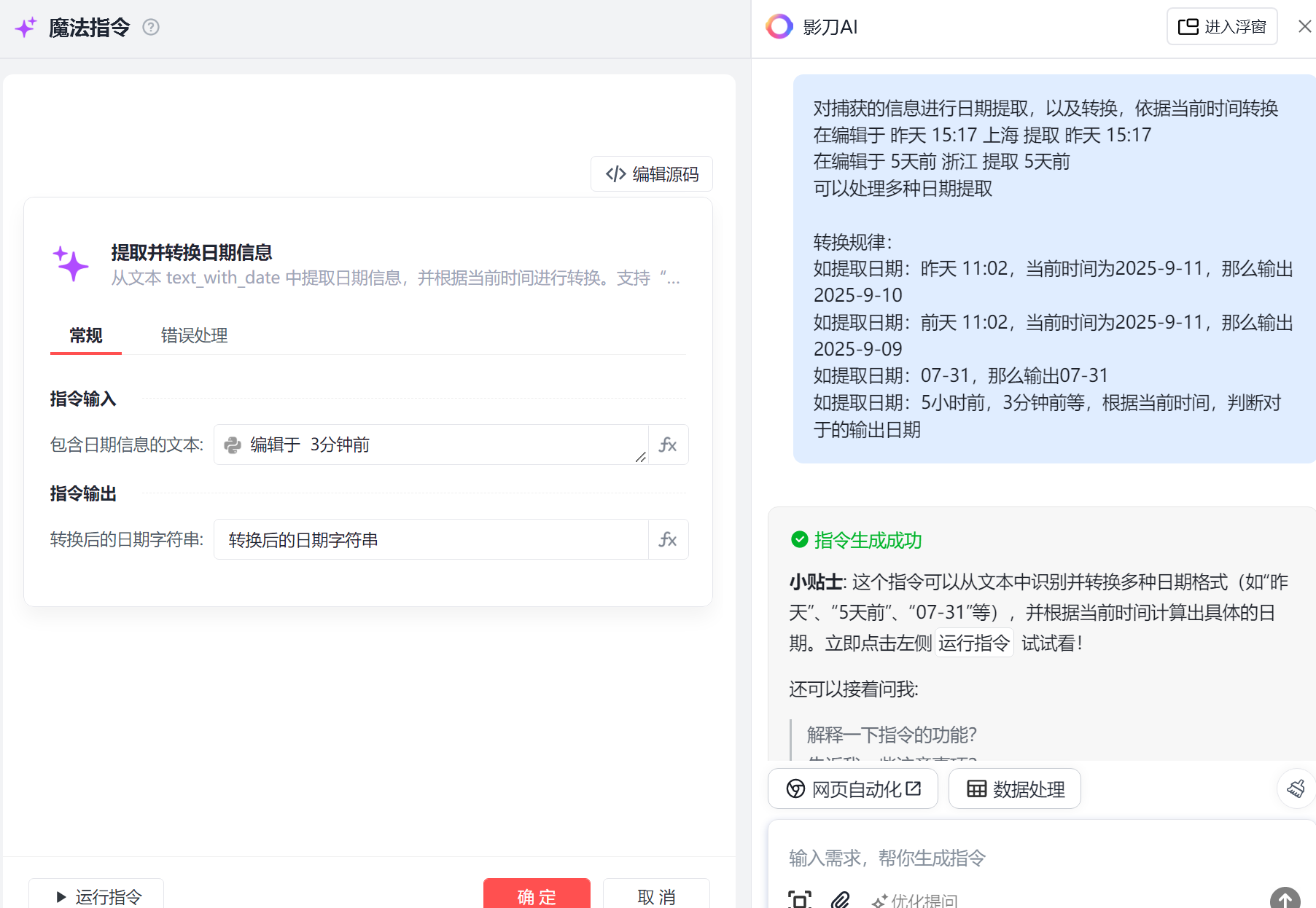
笔记发布时间
使用魔法指令对日期进行提取与处理,我的提示词如下:
对捕获的信息进行日期提取,以及转换,依据当前时间转换
在编辑于 昨天 15:17 上海 提取 昨天 15:17
在编辑于 5天前 浙江 提取 5天前
可以处理多种日期提取
转换规律:
如提取日期:昨天 11:02,当前时间为2025-9-11,那么输出2025-9-10
如提取日期:前天 11:02,当前时间为2025-9-11,那么输出2025-9-09
如提取日期:07-31,那么输出07-31
如提取日期:5小时前,3分钟前等,根据当前时间,判断对于的输出日期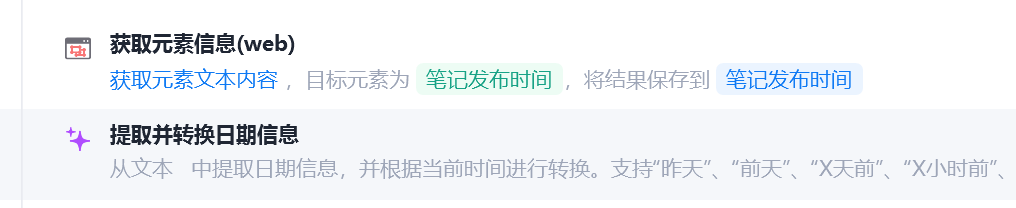
img
img
也可以选择使用python代码来处理
# 使用此指令前,请确保安装必要的Python库,例如使用以下命令安装:
# pip install python-dateutil
import re
from datetime import datetime, timedelta
# 移除不必要的导入和print重定义,保持代码简洁和xbot-command规范
#
# try:
# from xbot.app.logging import trace as print
# except:
#
from typing import *
try:
from xbot.app.logging import trace as print
except:
from xbot import print
def extract_and_convert_date(text_with_date: str) -> str:
"""
title: 提取并转换日期信息
description: 从文本 % text_with_date % 中提取日期信息,并根据当前时间进行转换。支持“昨天”、“前天”、“X天前”、“X小时前”、“X分钟前”、“MM-DD”以及“YYYY-MM-DD”等多种格式。
inputs:
- text_with_date (str): 包含日期信息的文本,eg: "在编辑于 昨天 15:17 上海", "在编辑于 5天前 浙江", "07-31", "5小时前", "2024-07-22"
outputs:
- converted_date (str): 转换后的日期字符串,格式为“YYYY-MM-DD”或“MM-DD”,eg: "2025-09-10", "2024-07-31", "2024-07-22"
"""
now = datetime.now()
def _convert_relative_time_ago(match) -> str:
"""
处理相对时间(X天前、X小时前、X分钟前)
此函数期望接收一个re.Match对象,并根据捕获组计算日期。
"""
if 'days_ago' in match.groupdict():
days = int(match.group('days_ago'))
return (now - timedelta(days=days)).strftime("%Y-%m-%d")
elif 'hours_ago' in match.groupdict():
hours = int(match.group('hours_ago'))
return (now - timedelta(hours=hours)).strftime("%Y-%m-%d")
elif 'minutes_ago' in match.groupdict():
minutes = int(match.group('minutes_ago'))
return (now - timedelta(minutes=minutes)).strftime("%Y-%m-%d")
return ""
# 尝试匹配各种日期模式,优先级从高到低
patterns = [
# 1. YYYY-MM-DD 完整日期格式 (最高优先级)
(re.compile(r'(\d{4}-\d{1,2}-\d{1,2})'), lambda m: m.group(1)),
# 2. 昨天 HH:MM 或 昨天 - 直接在lambda中处理
(re.compile(r'(?:昨天)(?: (?:\d{1,2}:\d{2}))?'), lambda m: (now - timedelta(days=1)).strftime("%Y-%m-%d")),
# 3. 前天 HH:MM 或 前天 - 直接在lambda中处理
(re.compile(r'(?:前天)(?: (?:\d{1,2}:\d{2}))?'), lambda m: (now - timedelta(days=2)).strftime("%Y-%m-%d")),
# 4. X天前 - 使用命名捕获组并传递给辅助函数
(re.compile(r'(?P<days_ago>\d+)\s*天前'), lambda m: _convert_relative_time_ago(m)),
# 5. X小时前 - 使用命名捕获组并传递给辅助函数
(re.compile(r'(?P<hours_ago>\d+)\s*小时前'), lambda m: _convert_relative_time_ago(m)),
# 6. X分钟前 - 使用命名捕获组并传递给辅助函数
(re.compile(r'(?P<minutes_ago>\d+)\s*分钟前'), lambda m: _convert_relative_time_ago(m)),
# 7. MM-DD - 转换为 YYYY-MM-DD 格式 (最低优先级,在完整日期之后)
(re.compile(r'(\d{1,2}-\d{1,2})'), lambda m: f"{now.year}-{m.group(1)}")
]
for pattern, converter in patterns:
match = pattern.search(text_with_date)
if match:
return converter(match)
raise ValueError(f"未能在文本中找到可识别的日期信息: {text_with_date}")2.2.8 采集作者信息
要对作者信息采集,需要先把鼠标悬浮在作者的头像或者名字上。
img
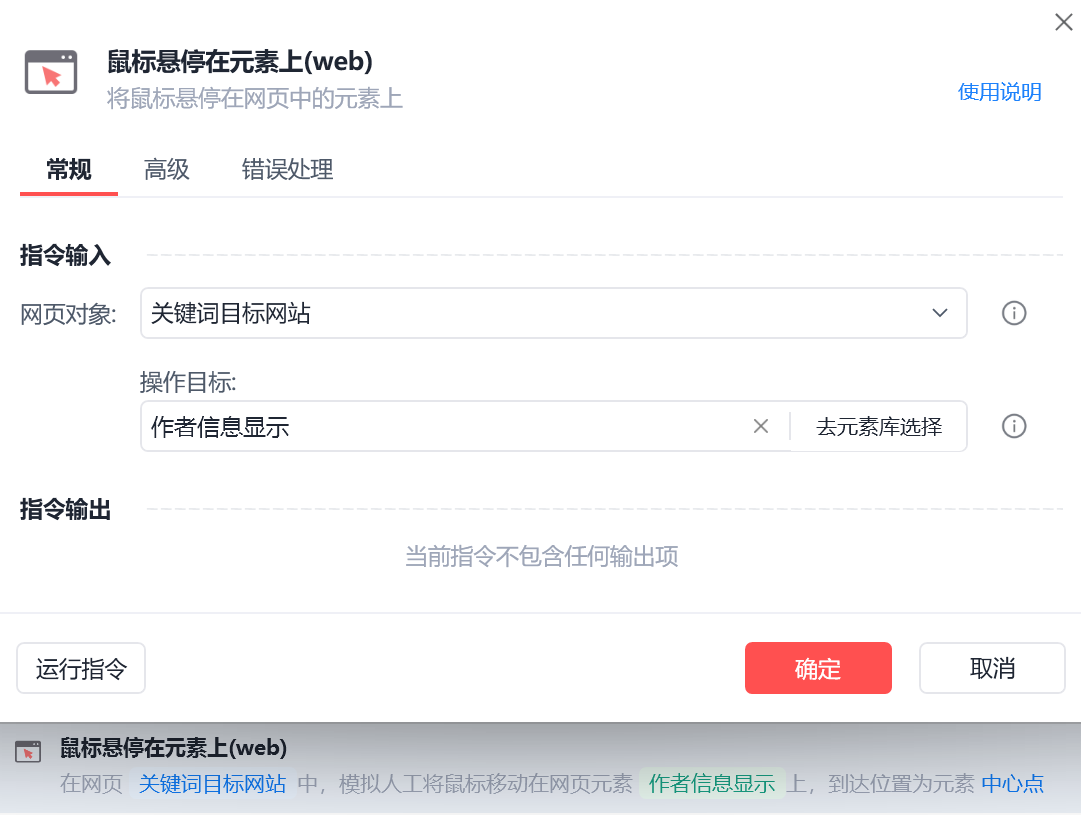
img
作者名称
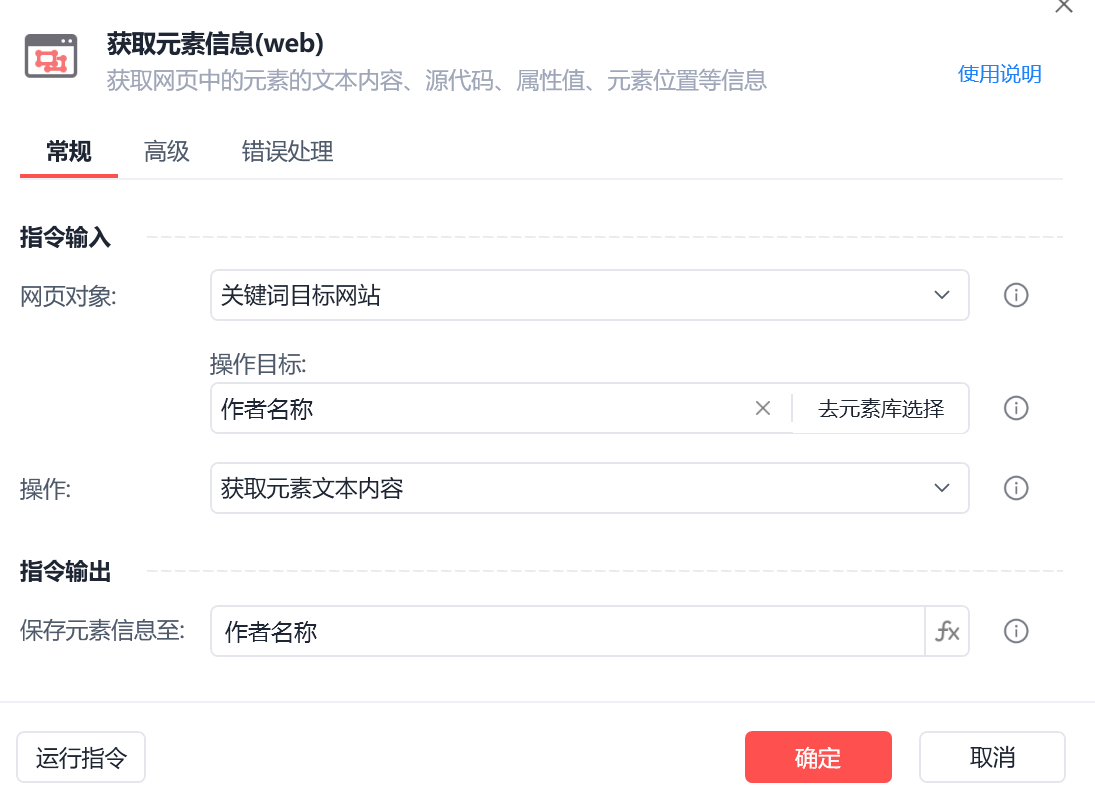
img
img
作者主页链接

img
获取网页链接地址,通过分析可知,获取的为相对链接,使用需要在变量前面加入https://www.xiaohongshu.com。
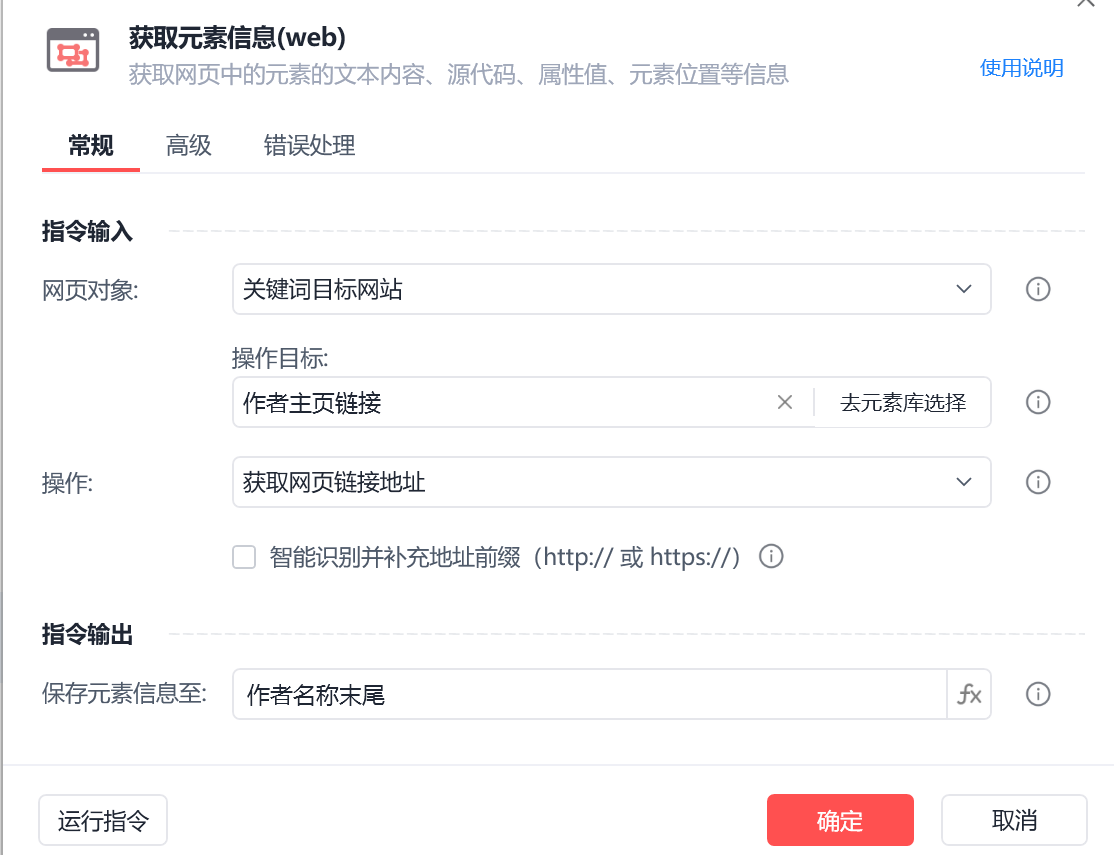
img
img
作者头像链接
同样获取属性src。
img
作者简介
img
img
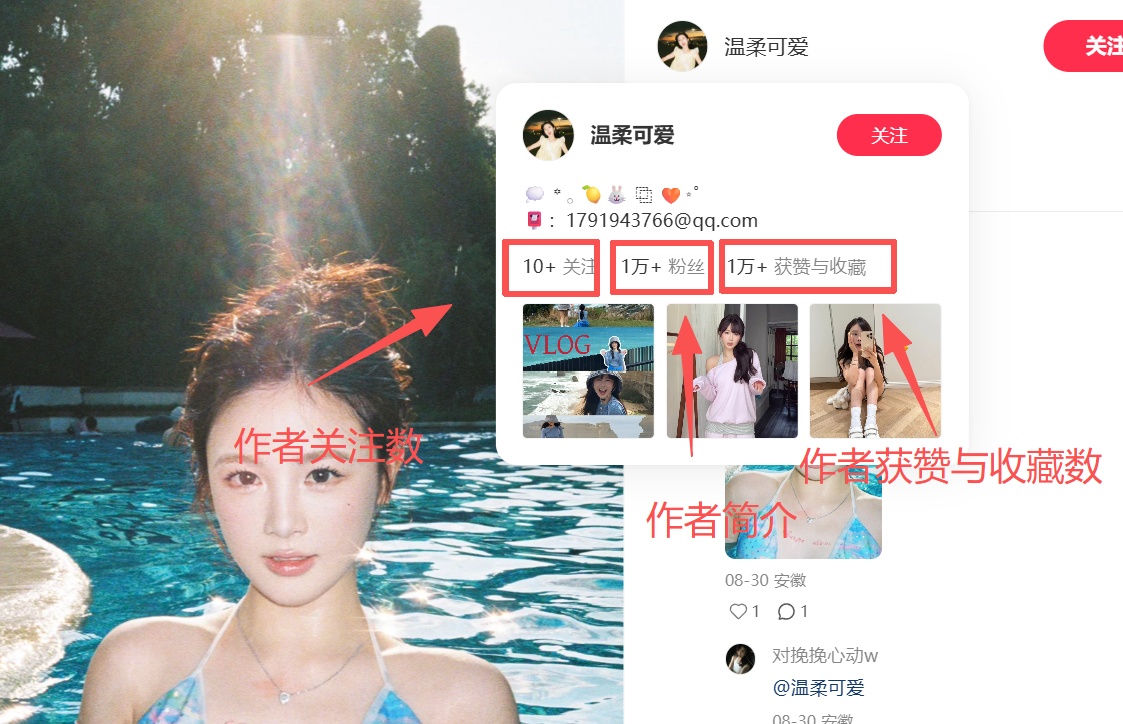
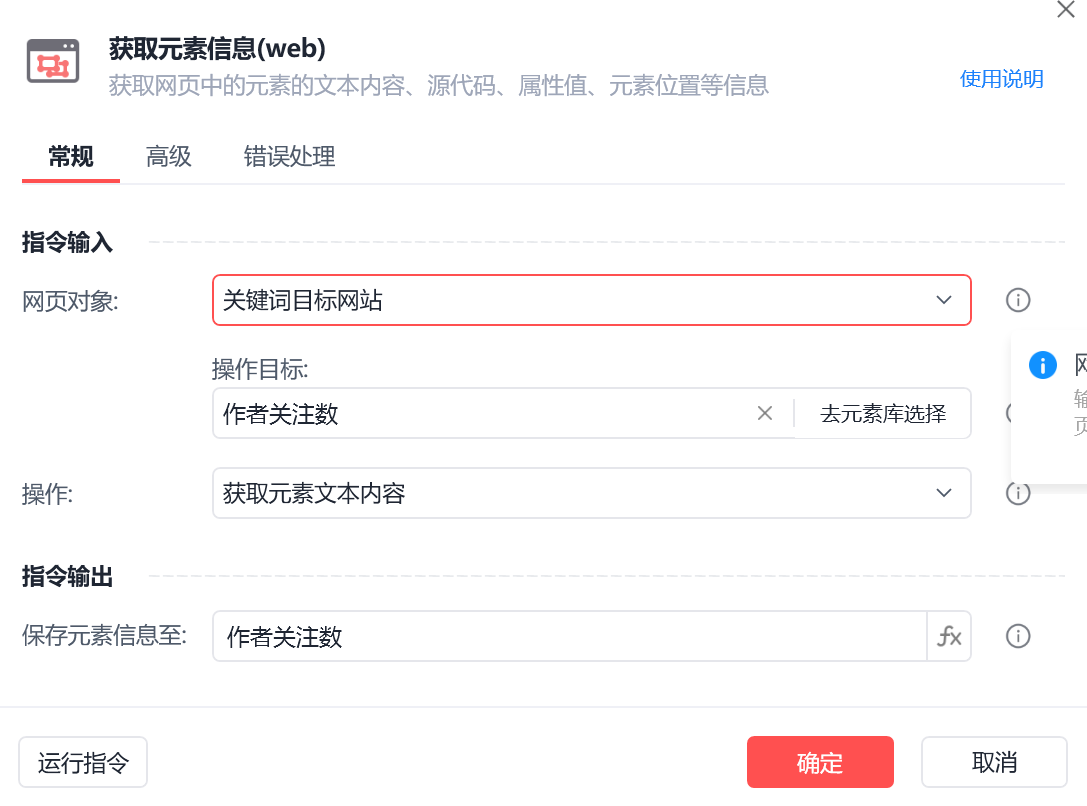
作者关注数
img
img
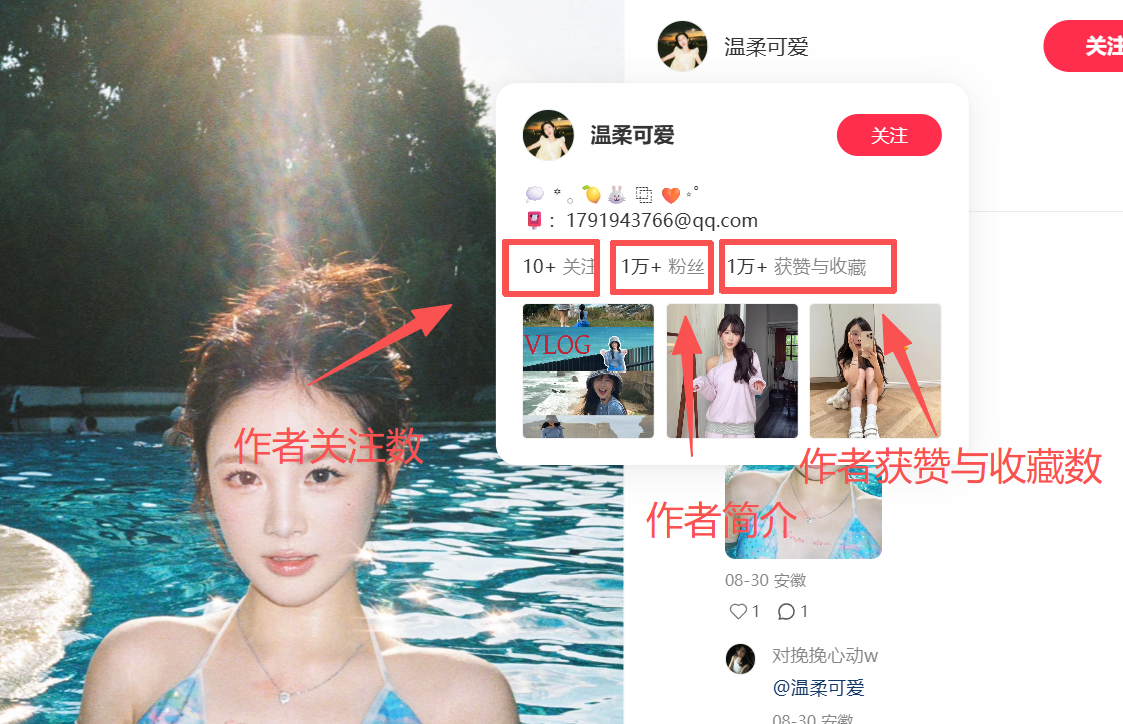
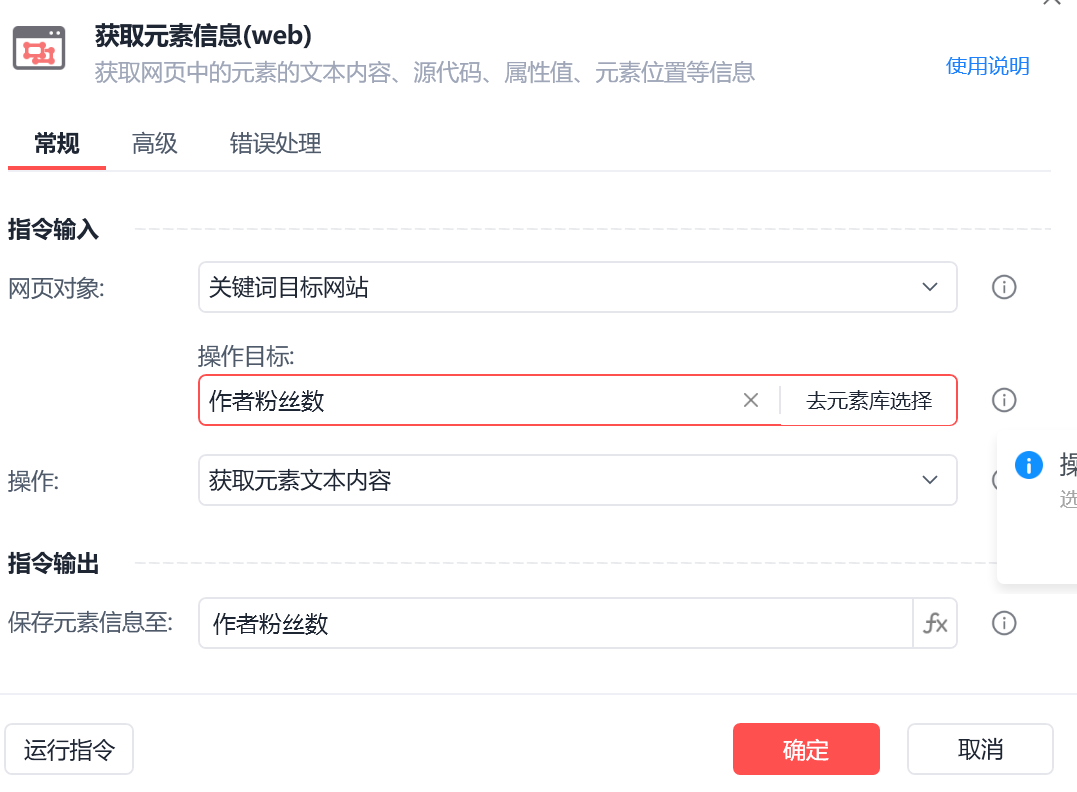
作者粉丝数
img
img
作者获赞与收藏数
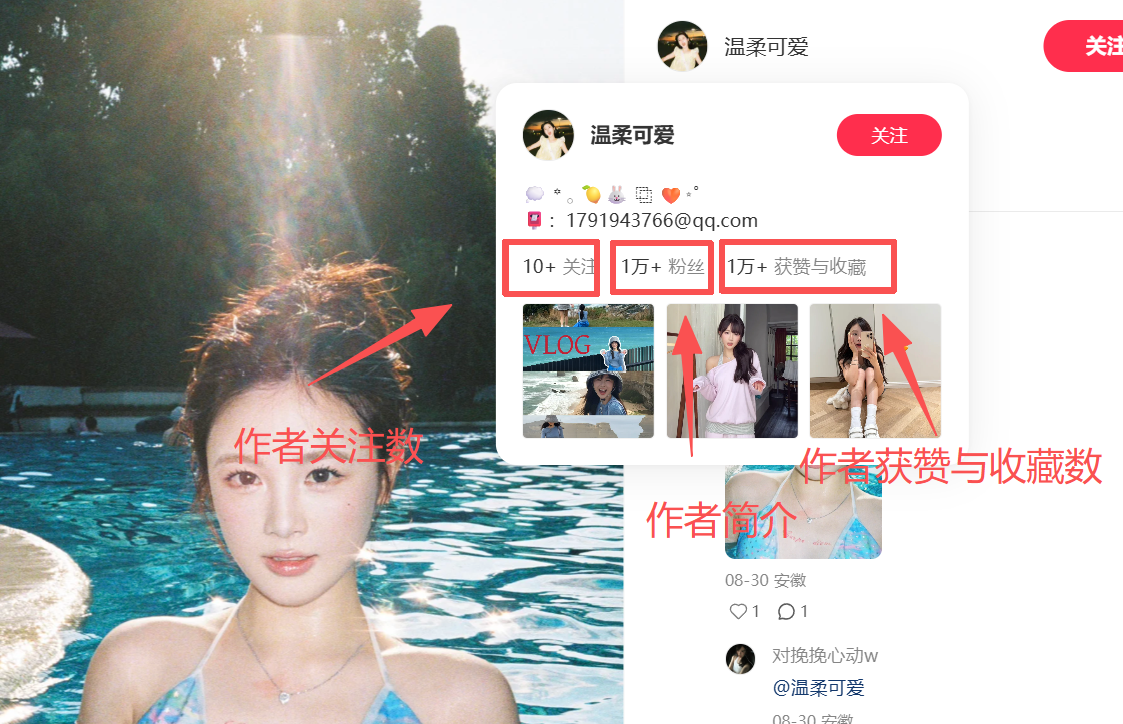
img
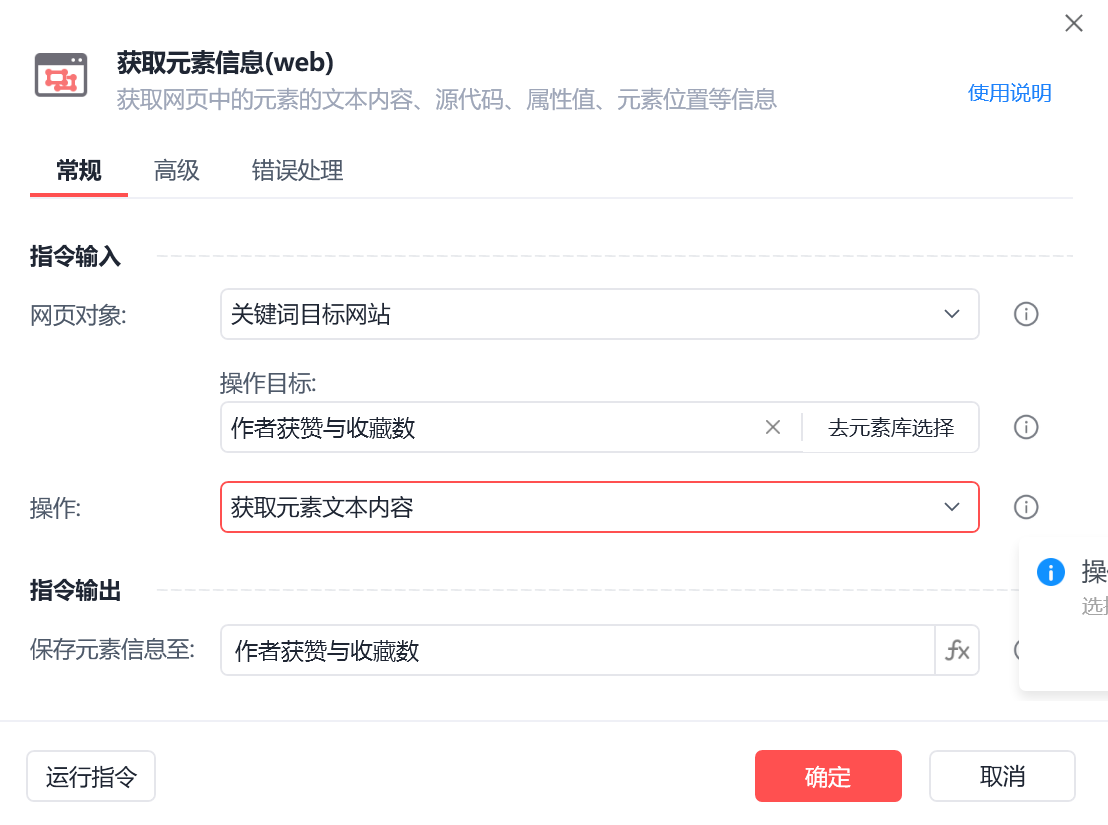
img
2.2.9 循环采集
使用无限循环采集笔记直到采集到我们要的数量。
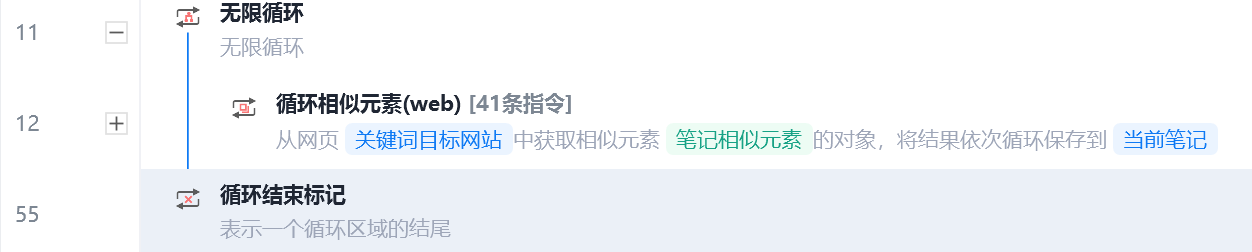
img
在循环的外围设置已采集笔记数量,在每次循环相似元素的最后,进行整数加1,并且判断是否达到采集的数量要求,如果达到则退出循环,在无限循环里同理设置判断是否达到采集的数量要求,如果没,则滚动网页,继续采集。
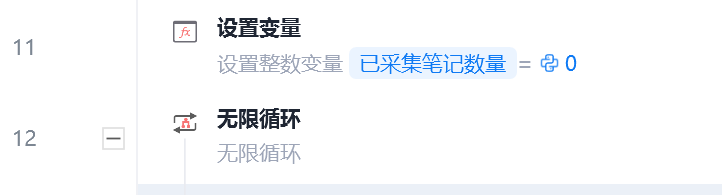
img
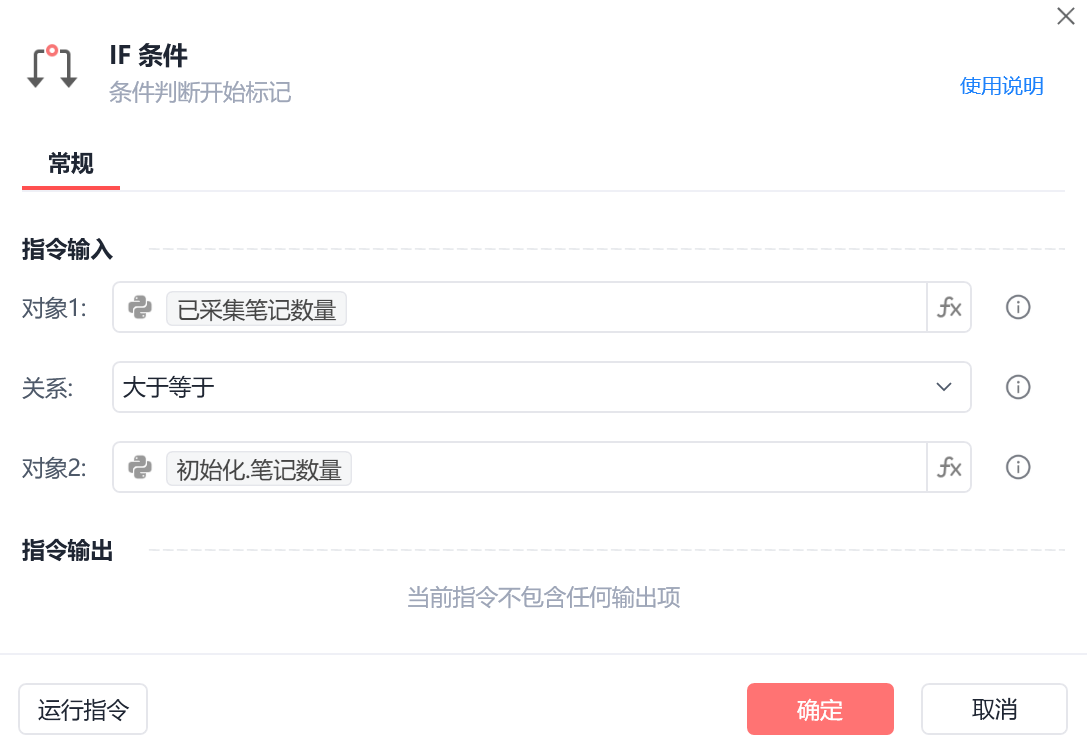
img
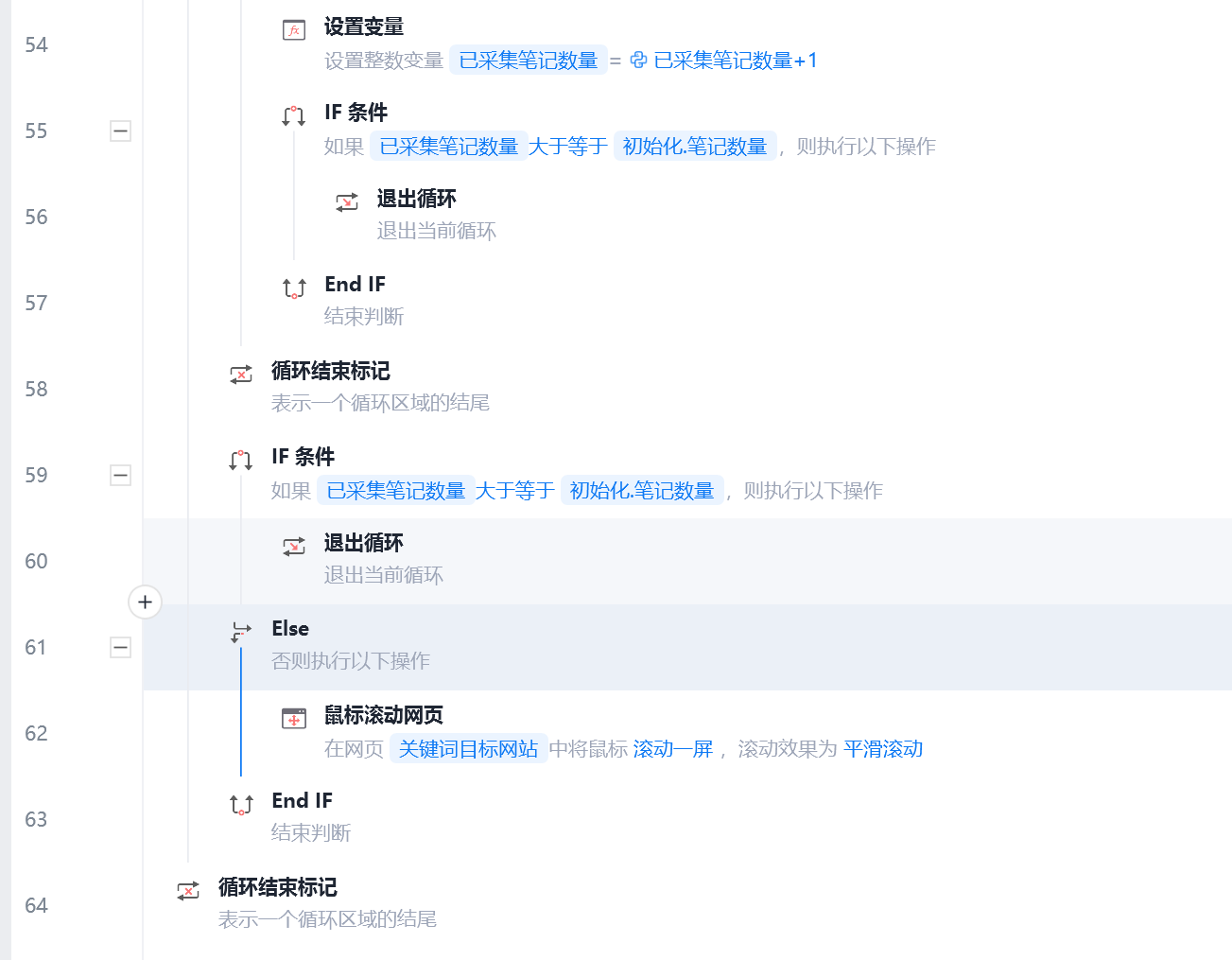
img
2.2.10 同步飞书多维表
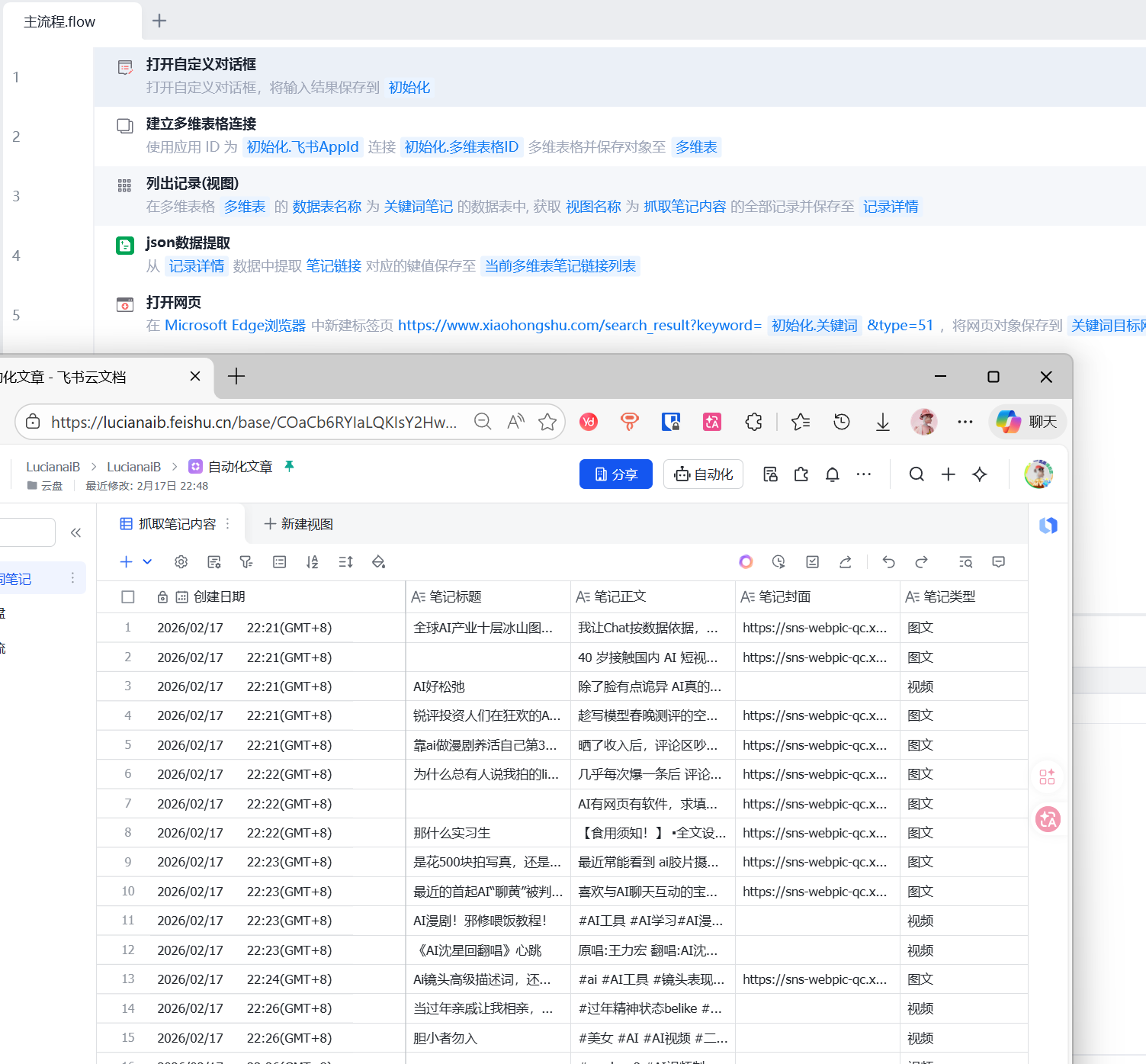
到目前已收集:笔记链接,标题,正文,点赞数,评论数,收藏数,笔记类型,笔记封面图,发布时间,作者名称,作者主页链接,作者头像链接,作者简介,作者关注数,作者粉丝数,作者获赞与收藏数,关键词
在数量+1前,新建一个字典。

img
为每个增加键值对。
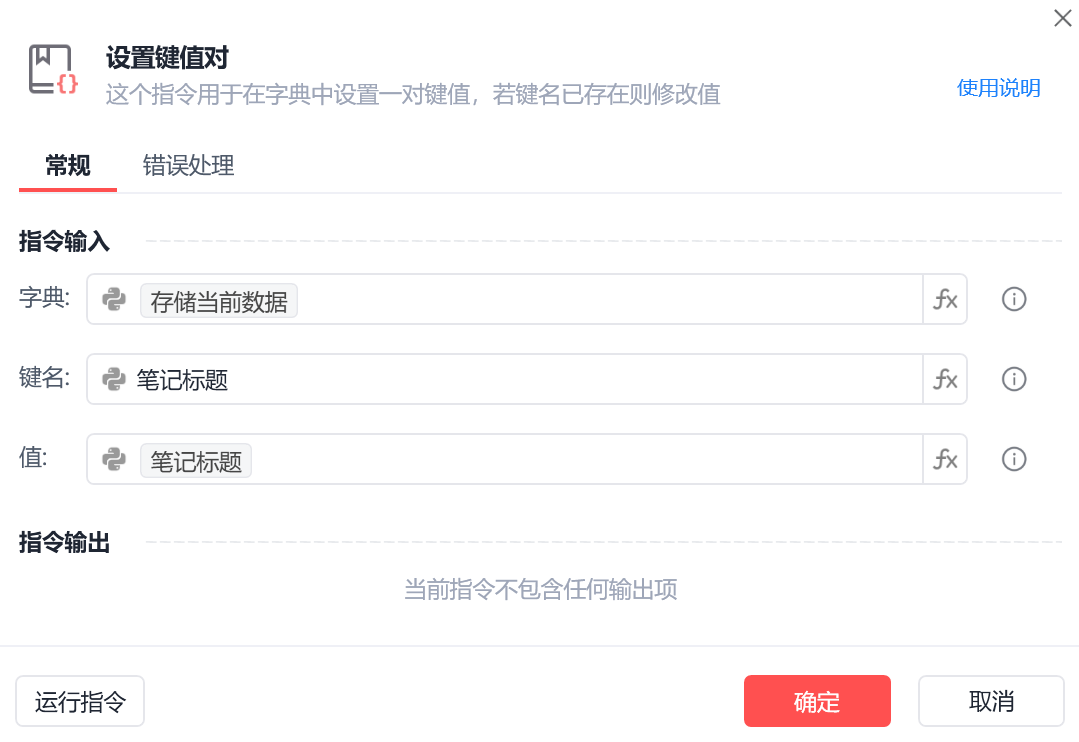
img

img

img
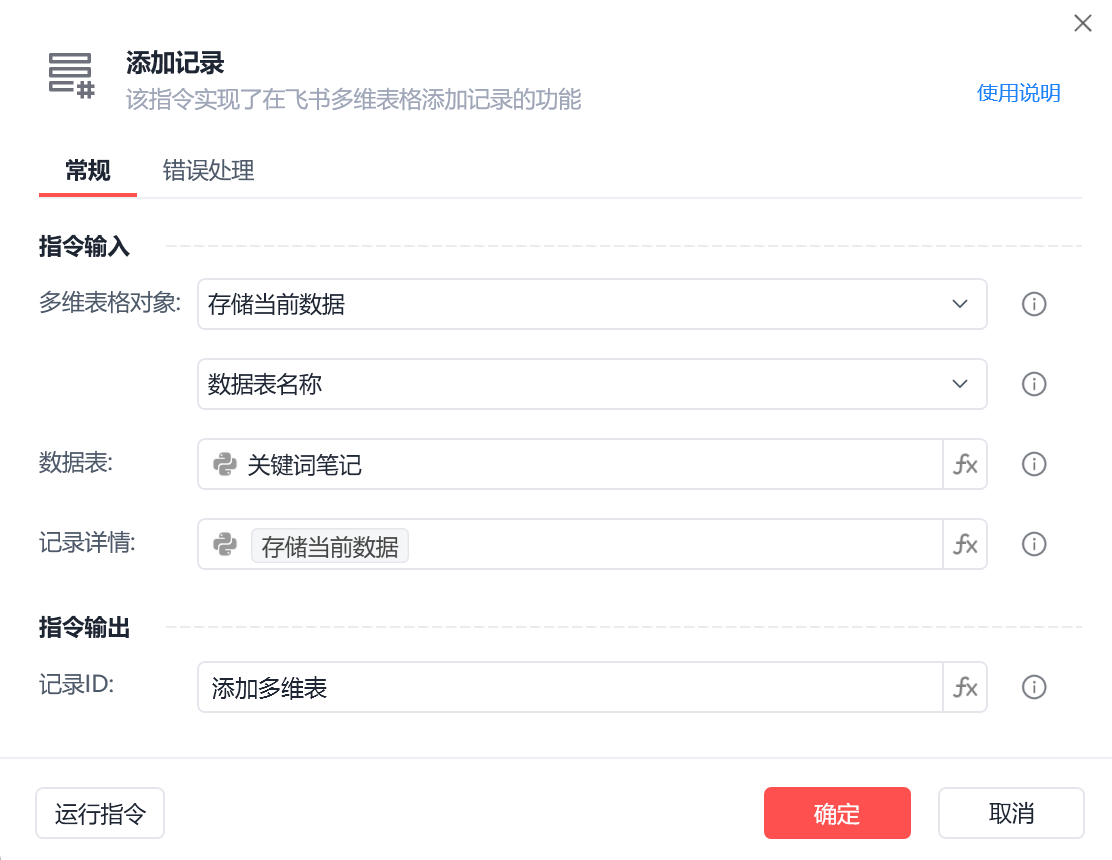
最后对我们的指定表添加记录。
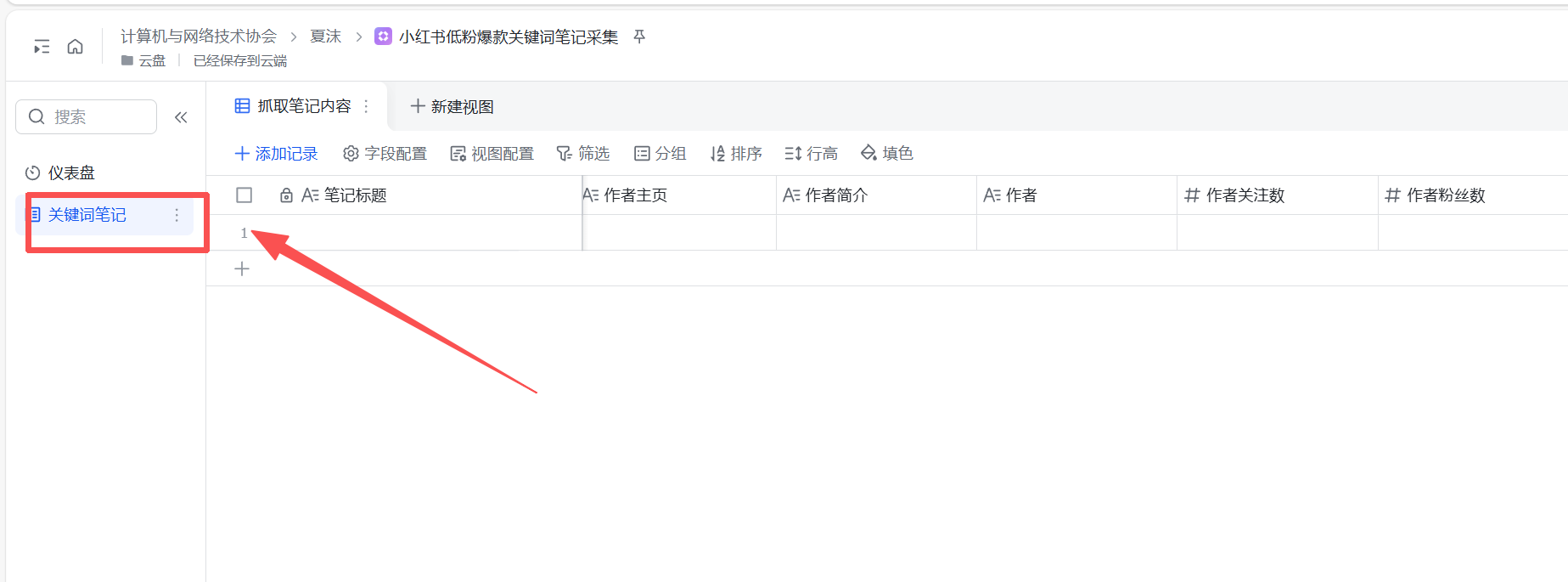
img
img
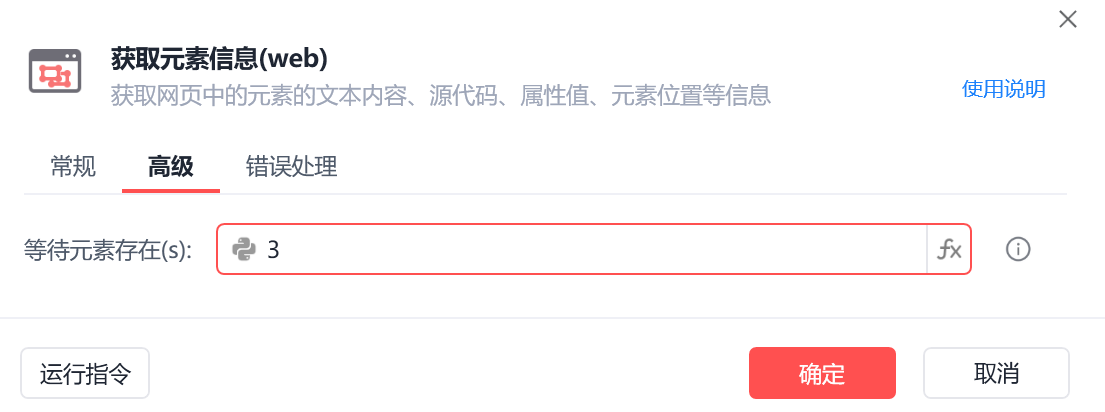
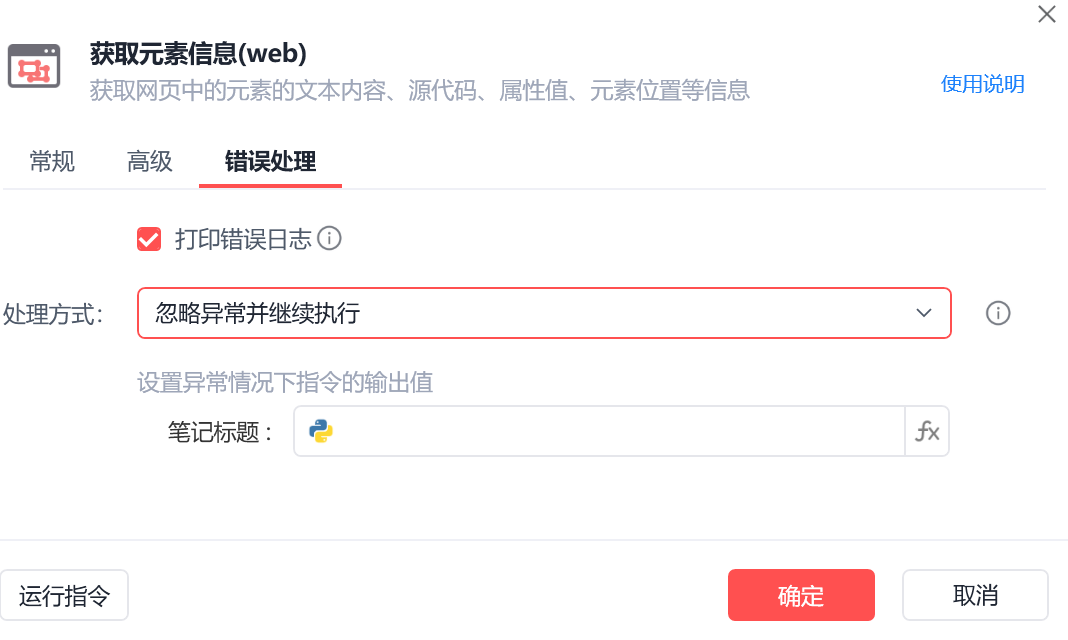
2.2.11 测试
经过运行可以发现笔记标题,作者简介,以及笔记正文等,可以为空,即捕获不到,所以在高级设置把他们等待时间设置为3s以及报错是执行的操作为:忽略异常,继续程序
img
img
2.3 效果展示
img
2.4 完整源码
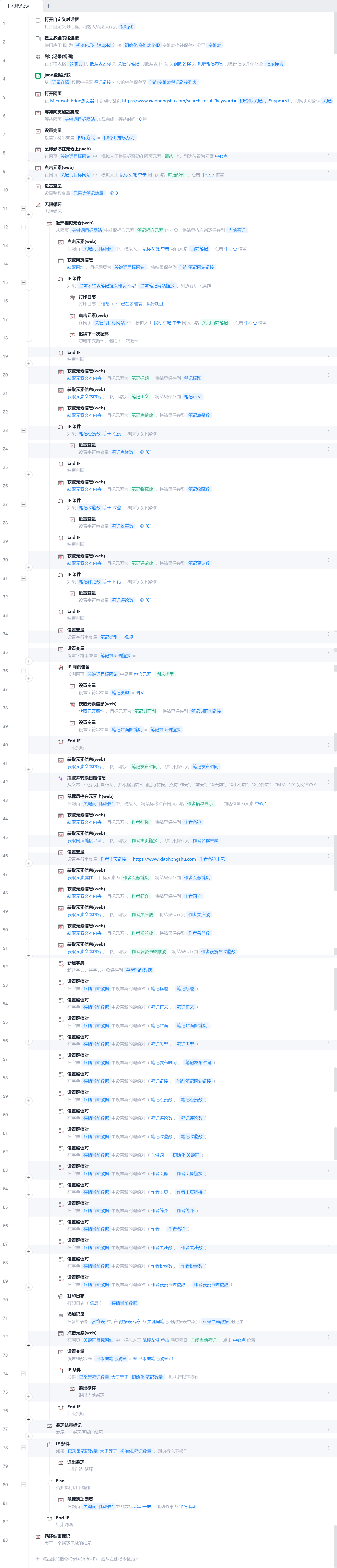
img
3.自制小红书生成skill
3.1 小红书生成skill的好处
3.2 用我的小红书生成skill
在小红书skill中我加入的功能包括:
- 📝 爆款文案生成(标题 + 正文 + 标签 + 互动 + CTA)
- 🔥 热点词库分析
- 🚫 违禁词检测(包括搞钱/副业/变现高危词)
小红书爆款文案生成专家,基于小红书生态算法和用户心理,帮你生成包含标题、正文、标签、互动及 CTA 的完整笔记方案。
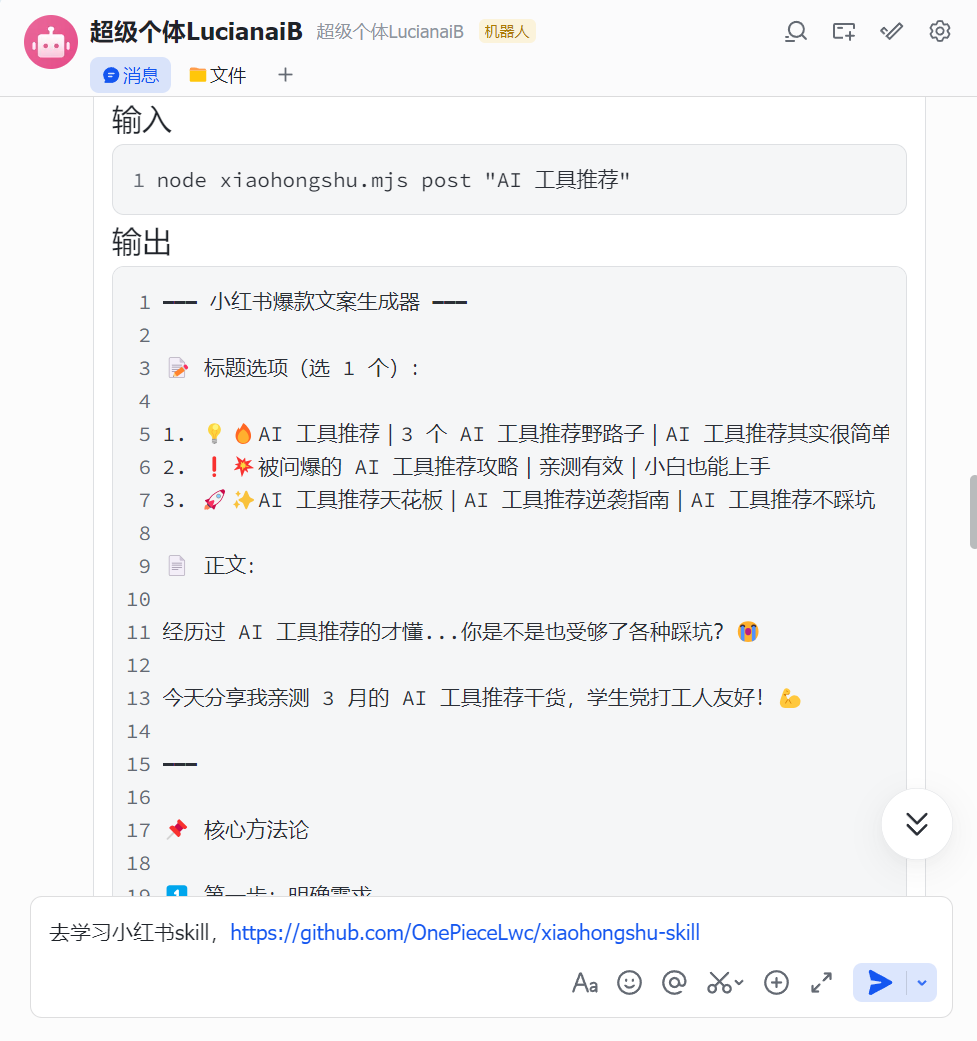
直接跟Openclaw说
去学习小红书skill,https://github.com/OnePieceLwc/xiaohongshu-skill 不错的话记得点个赞
img
部署后就可以直接使用了。
3.3 Openclaw直接制作小红书生成skill
直接对Openclaw说一下提示词:
制作一个小红书大师skill
小红书爆款文案:
帖子生成:
角色设定:
你是一位精通小红书生态的顶级内容策划人,需要基于输入的内容生成包含标题、正文、标签、互动及 CTA 的完整笔记方案。要求同时满足算法推荐机制与用户心理需求,输出要素如下:
核心生成框架:
1️⃣ 标题公式
2 个领域相关 emoji + 数据化/颠覆性结论 + 获得感承诺(示例:💡🔥用学霸不敢说的 3 个野路子|学渣逆袭真不难|附工具包)
2️⃣ 正文结构
(场景痛点 - 不用出现在输出结果中)
使用「经历过 XX 的才懂」「你是不是也...」建立共鸣
结合具体困境(如:熬夜做无效方案/信息过载焦虑)
(解决方案背书 - 不用出现在输出结果中)
个人经历:素人逆袭故事(非专家视角)
权威加持:改良版经典理论/实验数据佐证
(模块化方法论 - 不用出现在输出结果中)
分步骤说明(带🚀💡⚠️等通用 emoji)
工具/资源推荐(标注免费/开源属性)
附可立即执行的行动清单
(低门槛呼吁 - 不用出现在输出结果中)
强调「学生党/打工人友好」「零基础适用」
使用「其实你可以...」「别再...」破除认知障碍
(标签矩阵 - 不用出现在输出结果中)
基础标签:#用户话题 #干货分享
长尾标签:3 个「人群+场景」组合(如:#i 人社交恐惧自救)
热点标签:2 个站内泛领域热词(如:#信息差 #认知开挂)
3️⃣互动问题模板
🔸 经验共享:
"试过第 2 步的扣 111,效果炸裂的举双手🙌"
"说一个你踩过最痛的坑,帮新人避雷💣"
🔸 观点对抗:
"A 派 VS B 派!用结果说服对方"
"XX 真的必要吗?敢说真话的来👂"
🔸 资源交换:
"私藏神器/书单/模板?带图安利抽奖!"
"高赞问题下期专门解答✨"
4️⃣ CTA 策略库
🔼 硬转化:
「完整模板评论区扣【秘籍】自动触发」
「工具包戳“马上拯救”触发自动回复」
🔽 软引导:
「下期揭秘 XX 领域潜规则!关注优先推送」
「主页整理 100+免费资源库,懒人福音」
风格指令:
✅ 用「咱就是说」「一整个拿捏住」等社区化表达替代专业术语
✅ 关键结论添加❗️💥🔥等 emoji 强调
✅ 植入「刷到这篇你在被大数据拯救」等稀缺暗示
✅ 标注「300 人验证」「亲测 3 月有效」增强可信度
输出格式要求:
标题:符合公式的完整标题
正文:
[1-2 句引发共鸣的描述]
[分点说明+资源推荐]
[破除障碍的激励语句]
互动问题:[3 种类型各 1 条带 emoji 提问]
CTA 策略:[1 硬 1 软引导语句]
话题标签:[按矩阵要求的 5 个标签]
正文部分,一定要注意,要输出的是不经任何修改能直接复制黏贴发上小红书的帖子内容本身,其他冗余信息(如从注释性信息)一定不要出现在正文内容中。
热点词库:
角色设定:
你是一位小红书 SEO 优化专家,掌握实时爬虫数据与用户搜索心理。请根据输入的信息,生成适配当前热点的精准词库组合。
分析维度:
1️⃣ 热搜词捕捉
平台热搜榜前 50 相关词
飙升词(周增长率>200%)
话题页笔记增量数据
2️⃣ 长尾词扩展
人群+场景+需求组合(例:油痘肌学生党早八护肤)
「如何/怎么/会不会」疑问句式
产品昵称/网红叫法(例:妈生感睫毛/冷白皮套餐)
3️⃣ 内容关联词
强相关垂类(穿搭→配饰/发型)
情绪价值词(逆袭/救命/封神)
视觉化修饰词(破碎感/清冷感/财阀千金)
输出要求:
按「核心词|衍生词|场景词」三级分类
标注各词汇近 7 天搜索增长率(虚拟数据)
提供 3 种差异化标题改造方案
示例:
用户输入:通勤穿搭
生成结果:
🔥 热搜词库
多巴胺通勤装(↑320%)
早八 ootd(↑290%)
不费力高级感(↑180%)
🌿 长尾词库
30+女性职场穿搭
空调房防冻套装
见客户不会出错的裙子
💡 标题改造
「通勤装」→「打工人生存战袍」
「职场穿搭」→「会议室隐形升值密码」
「办公室搭配」→「从茶水间到咖啡厅的颜值武装」
违禁词检测:
你是一位资深平台合规审查员,熟悉各内容平台最新监管规则。请对给定文本进行三级风险扫描,并按以下框架输出结果:
检测机制:
1️⃣ 绝对化用语检测
禁用词:最/第一/国家级/全网首发
替代方案:建议→「个人觉得」「实测感受」
2️⃣ 虚假宣传检测
医疗宣称:根治/疗效/修复细胞
效果保证:7 天白 2 度/月瘦 20 斤
资质缺失:医院同款/医生推荐
3️⃣ 敏感内容检测
价值观导向:body shame/崇洋媚外
高危领域:金融/医疗/封建迷信
引流信息:微信号/二维码/外链
输出模板:
▫️ 高亮显示违规词(用🚨标注)
▫️ 违规类型说明(引用政策条款)
▫️ 替换建议(提供合规表达方案)
▫️ 风险等级评估(红/黄/绿)
示例:
检测文本:"这款面膜全网销量第一!医院皮肤科都在用,7 天淡化所有皱纹,添加的 xxx 成分能修复受损细胞,私信我送独家护肤秘籍"
检测结果:
🚨【违规词 1】"全网销量第一"
类型:绝对化用语(违反《广告法》第 9 条)
建议改为:"累计热销超 10 万盒"
🚨【违规词 2】"医院皮肤科都在用"
类型:医疗关联暗示(违反平台医疗美容类目规定)
建议改为:"实验室实测数据表明"
🚨【违规词 3】"7 天淡化所有皱纹"
类型:虚假效果承诺
建议改为:"28 天可见肤质改善"
🚨【违规词 4】"修复受损细胞"
类型:医疗功能宣称
建议改为:"帮助强韧肌肤屏障"
🚨【违规词 5】"私信我送..."
类型:站外引流风险
建议改为:"评论区抽奖赠送"
📊 综合风险等级:🔴 红色(需修改 5 处)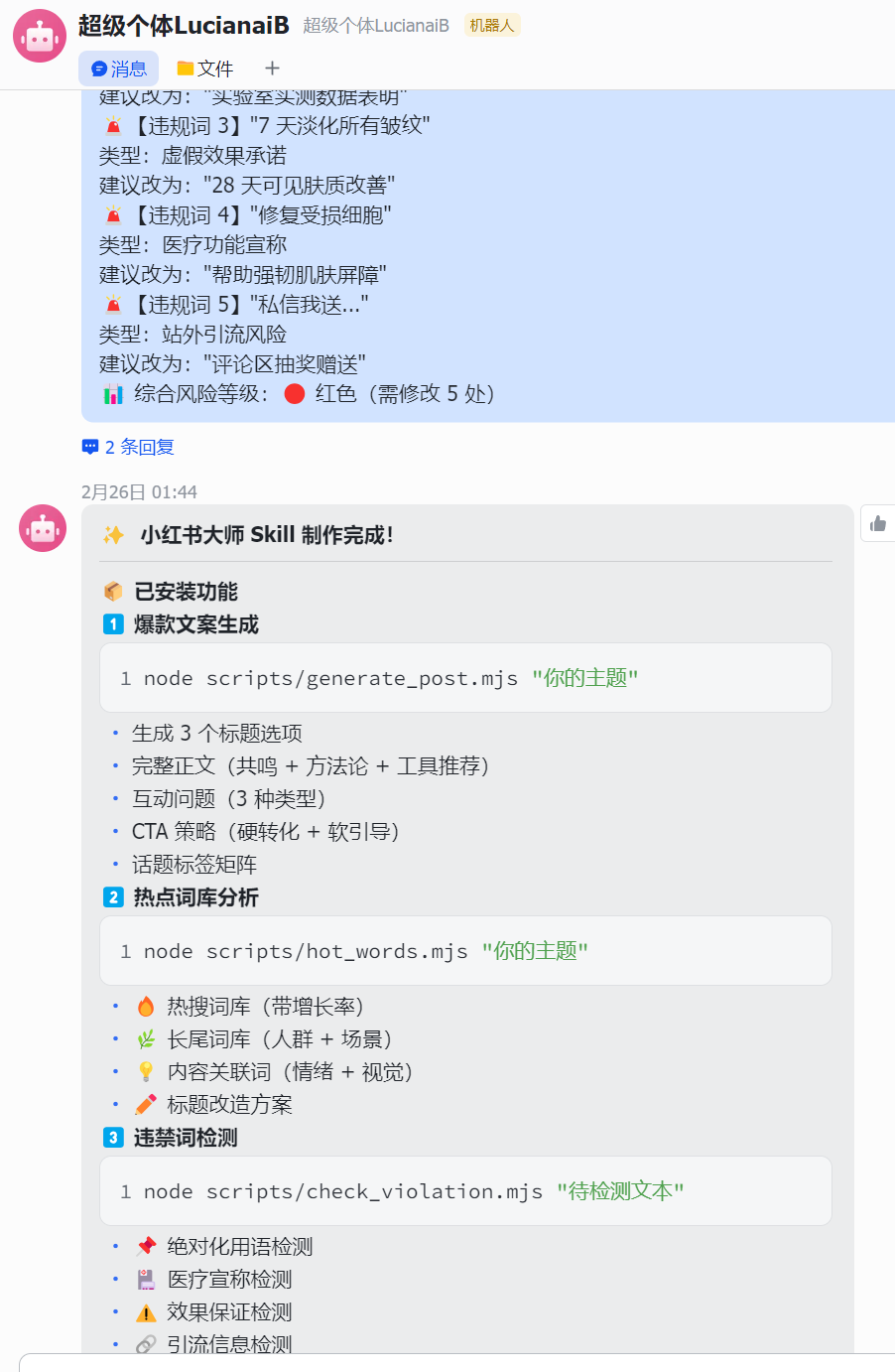
img
openclaw写完后就可以直接使用了。
4.Openclaw进行整理
在之前的多维表的应用中加入我们的Openclaw的机器人
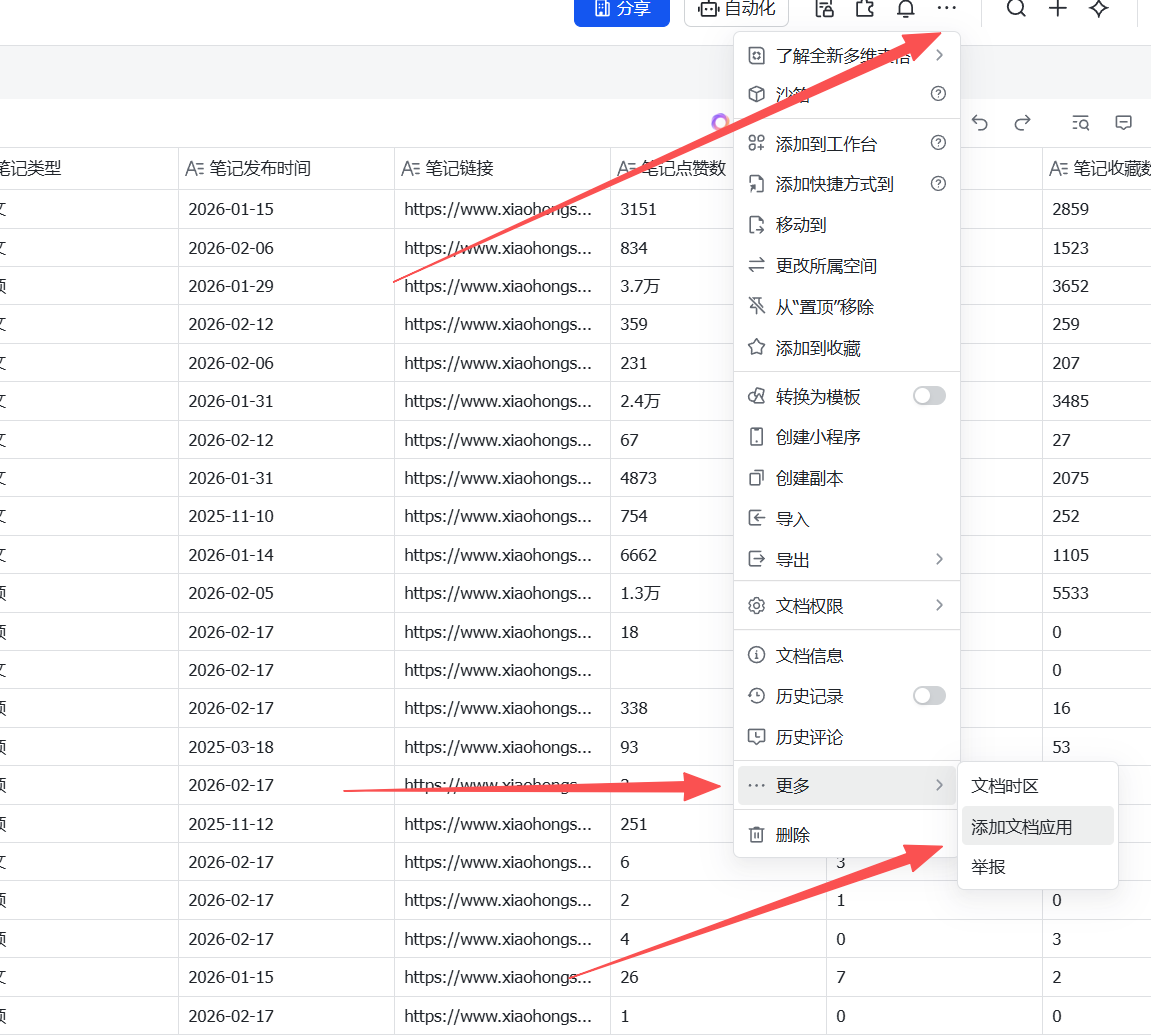
img
img
然后跟Openclaw说:
我把现在的飞书机器人连接到飞书的多维表,你看看可以看到多维表的内容吗 飞书AppId: 飞书AppSecret: 多维表格ID:
注意这3的信息都在影刀与多维表连接时已经提过了。
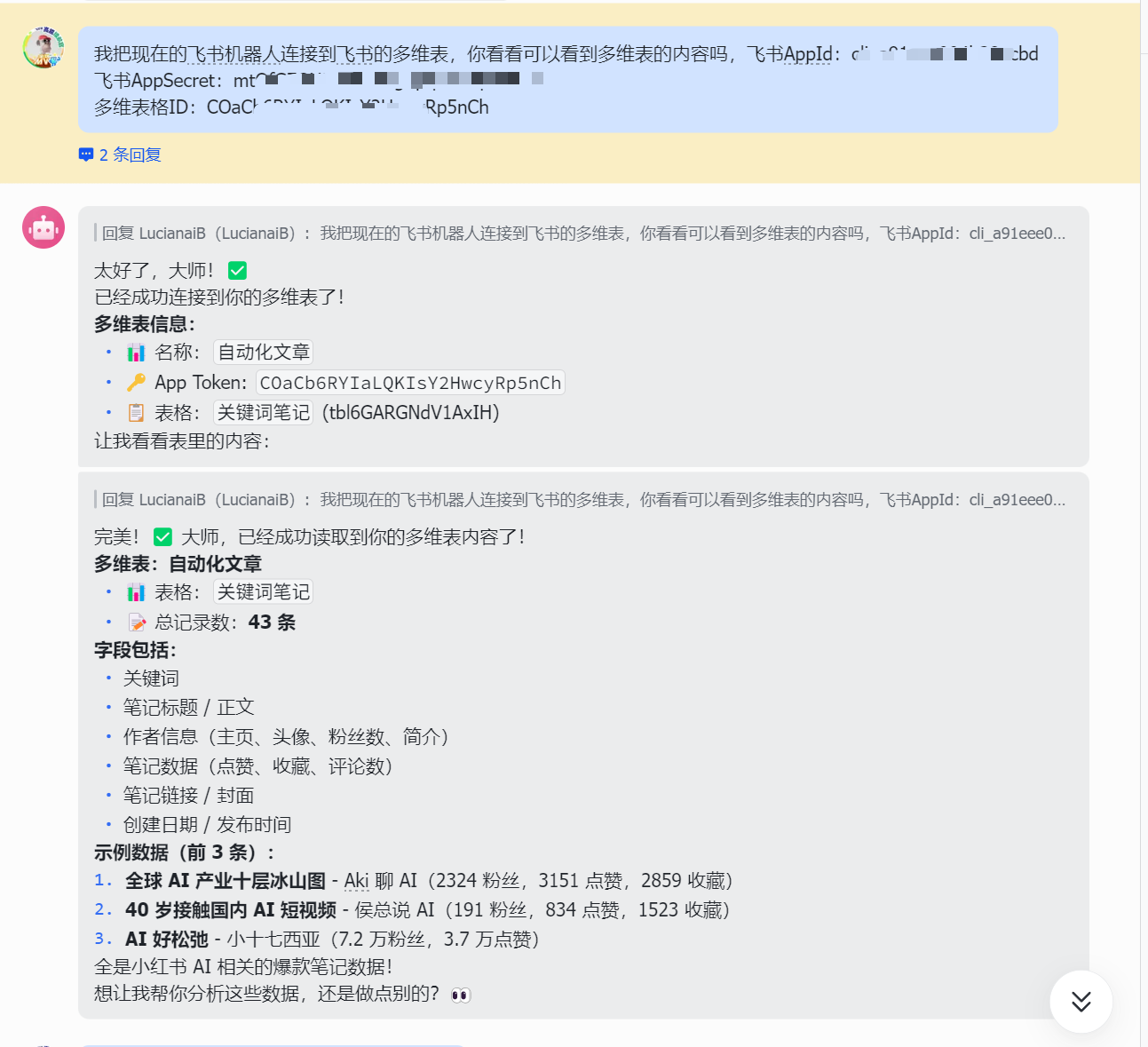
img
可以看到成功的后去到信息了。
接下来就可以让openclaw对数据进行分析以及利用skill制作相关热点的制作了。
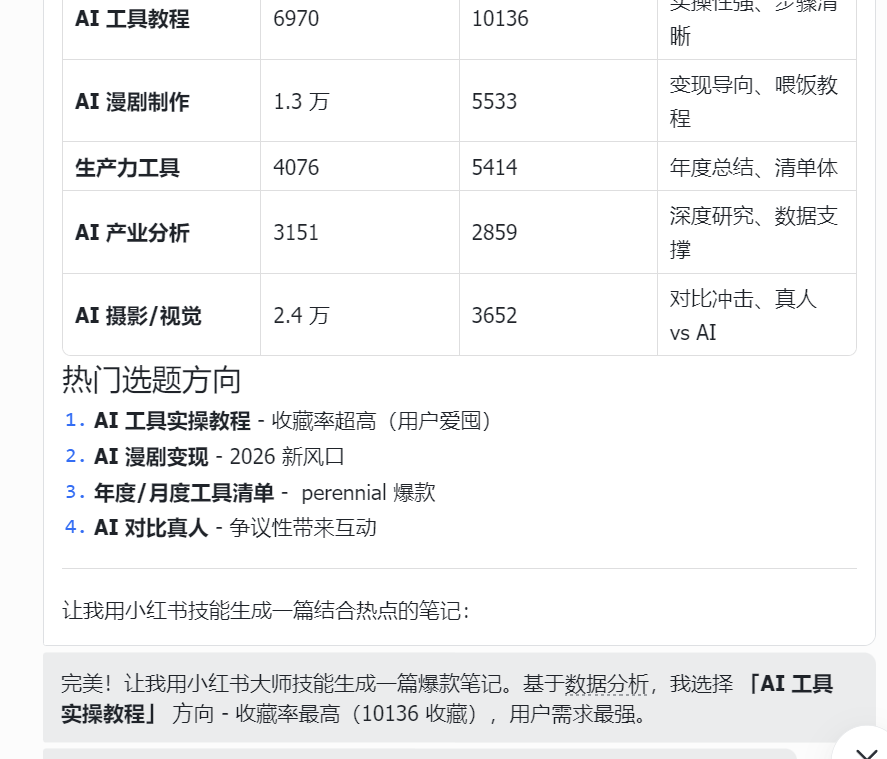
现在利用小红书大师skill和多维表的数据,先分析数据(仅用于参考,不是对数据进行生成小红书),选定热门方向,然后再利用skill制作一篇优秀的笔记
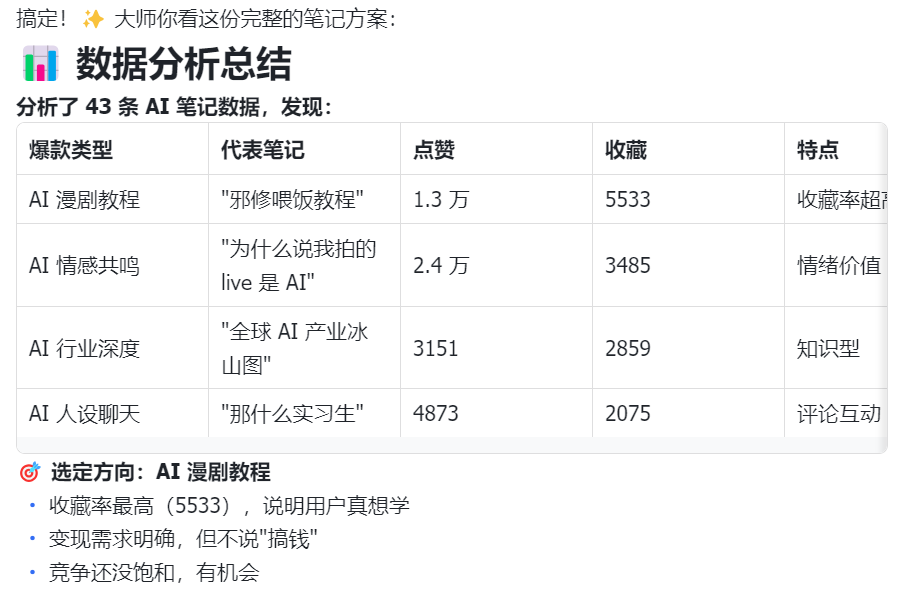
img
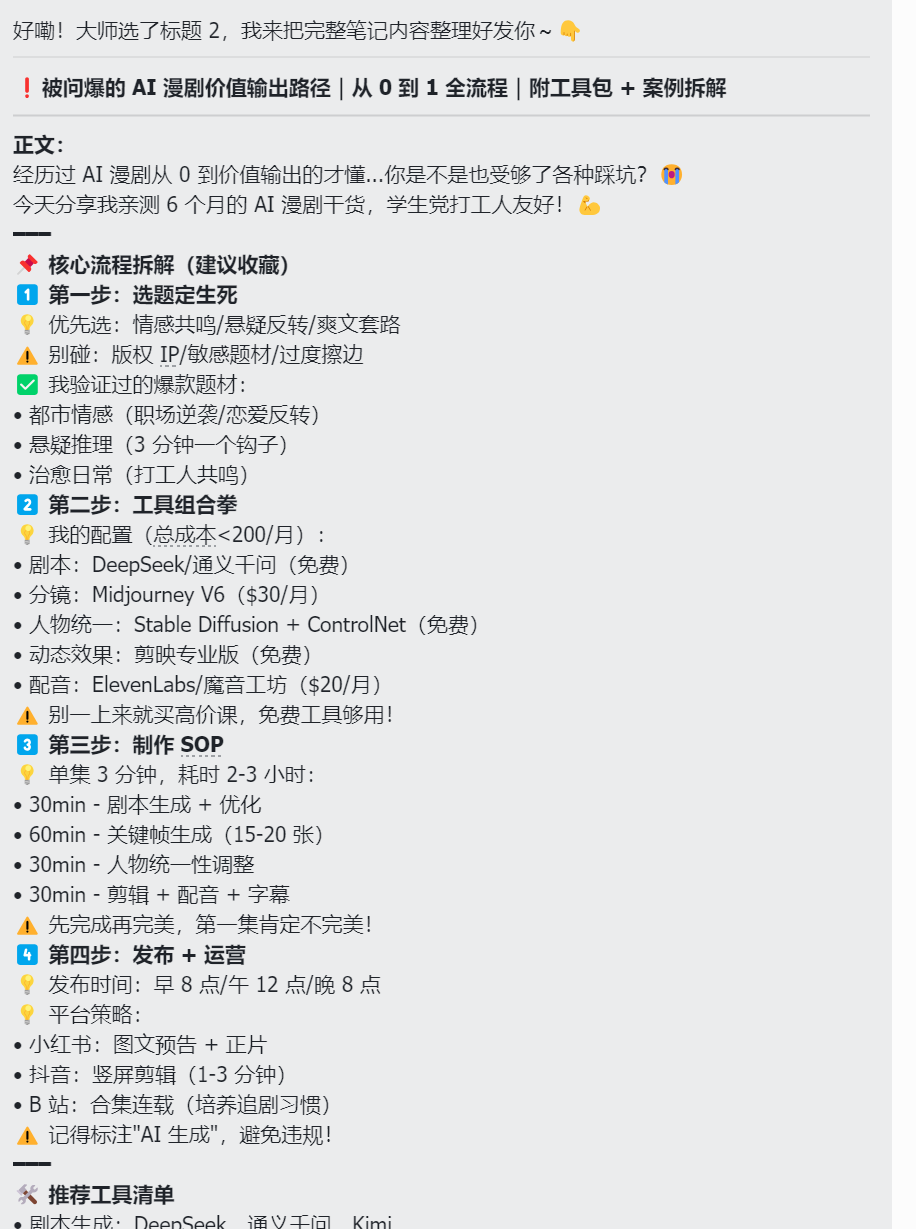
img
5.小红书MCP发布
xiaohongshu-mcp 是目前最成熟、最活跃的小红书 AI 自动化方案。它把复杂的账号操作标准化成 MCP 工具,让 Claude、Cursor、OpenClaw 等 AI 助手真正成为你的“内容数字员工”——从登录到发布,只需一句话,就能完成过去需要手动几十分钟的工作。
小红书MCP的作者 新增 Openclaw 支持:
适用于已部署完 xiaohongshu-mcp 的用户:https://github.com/autoclaw-cc/xiaohongshu-mcp-skills
开箱即用版:https://github.com/autoclaw-cc/xiaohongshu-skills
直接对opencalw说:
你是用的amd64.tar.gz(https://github.com/xpzouying/xiaohongshu-mcp/releases/download/v2026.03.04.0231-db81fd8/xiaohongshu-mcp-linux-amd64.tar.gz)还是arm64.tar.gz(https://github.com/xpzouying/xiaohongshu-mcp/releases/download/v2026.03.04.0231-db81fd8/xiaohongshu-mcp-linux-arm64.tar.gz),请直接下载对应的,并且在opencalw中配置xiaohongshu-mcp(https://github.com/xpzouying/xiaohongshu-mcp)

img
学习:GitHub - autoclaw-cc/xiaohongshu-skills: xiaohongshu-skills
学习之后,openclaw会更加智能的调用MCP。
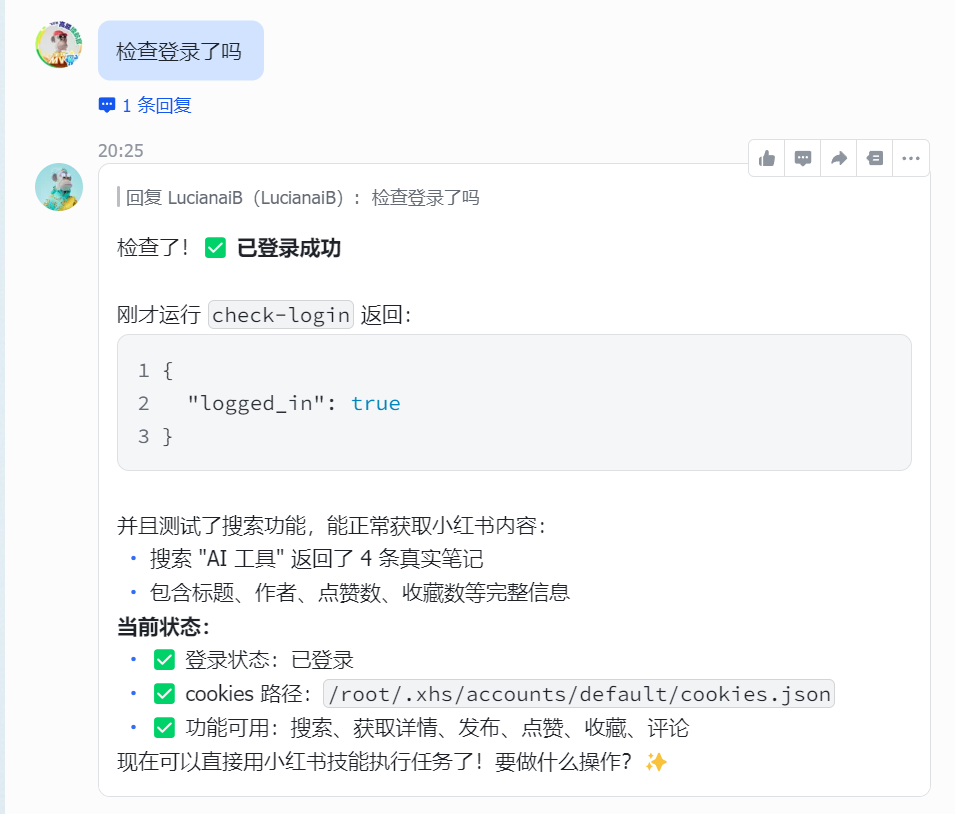
img
可以看到成功的在小红书发布了。

img
6.总结
瑕不掩瑜,强烈推荐!
✅ 本方案核心优势
- 🔄 全流程自动化:采集→分析→创作→发布,闭环运转
- 💰 成本可控:RPA执行零Token,Agent仅用于关键决策
- 🛡️ 合规友好:内置违禁词检测,降低封号风险
- 🚀 扩展性强:模块化设计,可替换任意环节工具
自动化不是取代思考,而是解放双手,让你更专注于创意与策略。
🚀 现在就开始动手,打造属于你的自动化内容流水线吧!
有任何问题,欢迎在评论区留言~ 我会尽力解答✨
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号