oodAgent 场景引擎 招聘系统实战
原创
oodAgent 场景引擎 招聘系统实战
原创
OneCode
发布于 2026-03-07 19:35:20
发布于 2026-03-07 19:35:20
Ooder Team · 2026-03-07
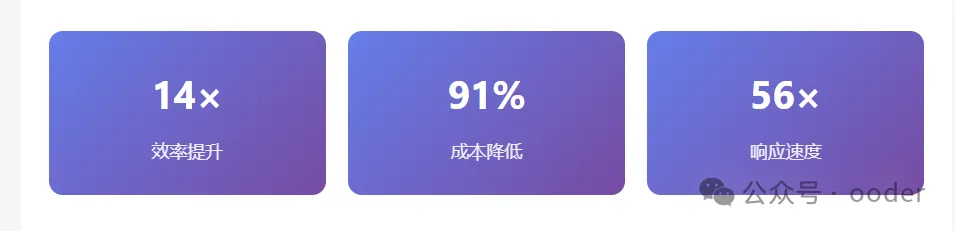
导读:本文以招聘管理系统为例,介绍如何使用 Ooder SceneEngine 的场景技能能力,在1周内快速构建智能化的业务应用模块,开发效率提升14倍,成本降低91%。
一、为什么选择场景开发?
构建一个招聘管理系统,传统方式需要10-15周,而使用场景技能开发,只需1周内即可完成。让我们看看两者的对比:
❌ 传统开发
需求分析 | 2-3周 |
|---|---|
系统设计 | 2-3周 |
编码开发 | 4-6周 |
测试上线 | 2-3周 |
总计 | 10-15周 |
✅ 场景开发
场景定义 | 1-2天 |
|---|---|
技能组装 | 2-3天 |
配置调试 | 1-2天 |
上线运行 | 1天 |
总计 | 1周内 |
二、场景技能是什么?
场景技能(Scene Skill)是 Ooder SceneEngine 的核心概念,它将业务场景封装为可复用的能力单元:
💡 场景技能 = 业务场景 + 能力集合 + 知识库 + 智能决策
- 业务场景:招聘、审批、客服、销售等
- 能力集合:简历筛选、面试安排、通知发送等
- 知识库:岗位要求、候选人信息、公司制度等
- 智能决策:LLM意图理解、规则引擎、降级策略
2.1 五层架构设计
用户层
User → SceneGroup → SceneAgent(用户交互、协作管理)
场景层
SceneSkill → Driver/Executor Capabilities(场景编排、能力协调)
决策层
LLM Decision ◄──► Rule Engine(在线优先,离线降级)
能力层
ToolRegistry → 内置工具 + 自定义工具(工具注册与调用)
基础层
LLM Provider | Knowledge Base | Vector Store(原子能力提供)
三、核心技术解析
3.1 决策引擎:双引擎架构
决策引擎是场景技能的"大脑",采用LLM + 规则引擎双引擎架构:
🤖 LLM Engine(在线)
意图理解 | 参数提取 | 能力选择 | 结果生成
⚙️ Rule Engine(离线)
关键词匹配 | 正则提取 | 路由规则 | 降级处理
三种决策模式:
模式 | 延迟 | 准确率 | 适用场景 |
|---|---|---|---|
ONLINE_ONLY | 200-500ms | >95% | 对准确性要求高 |
OFFLINE_ONLY | 5-20ms | ~80% | 离线环境、性能敏感 |
ONLINE_FIRST | 5-500ms | >90% | 默认模式,兼顾两者 |
3.2 知识库:三层架构
知识库采用三层架构设计,实现知识的分层管理和跨层检索:
Layer 3: 场景知识层(私有)
候选人简历、面试记录、评价结果 | 权限:场景参与者
Layer 2: 专业模块层(领域共享)
岗位要求、面试题库、技能标准 | 权限:领域角色
Layer 1: 通用知识层(全局共享)
公司制度、流程规范、FAQ | 权限:所有用户
✨ RAG增强流程
用户问题 → 向量化 → 知识检索 → 上下文构建 → LLM生成 → 返回结果
总延迟约370ms,其中知识检索约100ms
3.3 规则引擎:MVEL实现
规则引擎用于离线场景和降级处理,支持五种规则类型:
类型 | 说明 | 示例 |
|---|---|---|
DECISION | 决策规则 | 意图路由、能力选择 |
TRANSFORM | 转换规则 | 数据格式化、字段映射 |
VALIDATION | 验证规则 | 参数校验、权限检查 |
ROUTING | 路由规则 | 多分支决策 |
FALLBACK | 降级规则 | 异常处理 |
四、实战:构建招聘系统
4.1 业务流程定义
招聘场景的核心业务流程:
发布职位 → 简历筛选 → 面试安排 → 面试评估 → 发放Offer
4.2 创建知识库
// 1. 通用知识层 - 公司制度库
KnowledgeBase companyPolicyKb = kbService.create(
KnowledgeBaseCreateRequest.builder()
.name("公司制度库")
.layer(KnowledgeLayer.GENERAL)
.description("招聘政策、薪酬标准、入职流程")
.build()
);
// 2. 专业模块层 - 岗位要求库
KnowledgeBase jobRequirementKb = kbService.create(
KnowledgeBaseCreateRequest.builder()
.name("岗位要求库")
.layer(KnowledgeLayer.PROFESSIONAL)
.description("职位描述、技能要求、面试题库")
.build()
);
// 3. 场景知识层 - 候选人库
KnowledgeBase candidateKb = kbService.create(
KnowledgeBaseCreateRequest.builder()
.name("候选人库")
.layer(KnowledgeLayer.SCENE)
.description("简历数据、面试记录、评价结果")
.build()
);4.3 配置决策引擎
// 创建决策引擎
DecisionEngine engine = new DecisionEngineImpl(llmProvider, ruleEngine);
// 设置决策模式(默认:在线优先,自动降级)
engine.setMode(DecisionMode.ONLINE_FIRST);
// 配置离线规则(用于降级)
RuleScript routingRule = RuleScript.builder()
.ruleId("recruitment-routing")
.type(RuleType.ROUTING)
.script("""
if (query.contains('筛选') || query.contains('简历')) {
return 'resume_screening';
} else if (query.contains('面试')) {
return 'interview_schedule';
}
return 'recruitment_help';
""")
.build();
ruleEngine.compile(routingRule);4.4 创建场景技能
// 创建招聘场景技能
SceneSkill recruitmentSkill = SceneSkill.builder()
.skillId("recruitment-scene")
.name("招聘管理场景")
// 注册能力
.capability("resume_screening", new ResumeScreeningCapability())
.capability("interview_schedule", new InterviewScheduleCapability())
.capability("offer_management", new OfferManagementCapability())
// 关联知识库
.knowledgeBase("company_policy", companyPolicyKb.getKbId())
.knowledgeBase("job_requirement", jobRequirementKb.getKbId())
.knowledgeBase("candidate", candidateKb.getKbId())
// 配置决策引擎
.decisionEngine(engine)
.build();
// 注册场景技能
skillRegistry.register(recruitmentSkill);五、智能交互示例
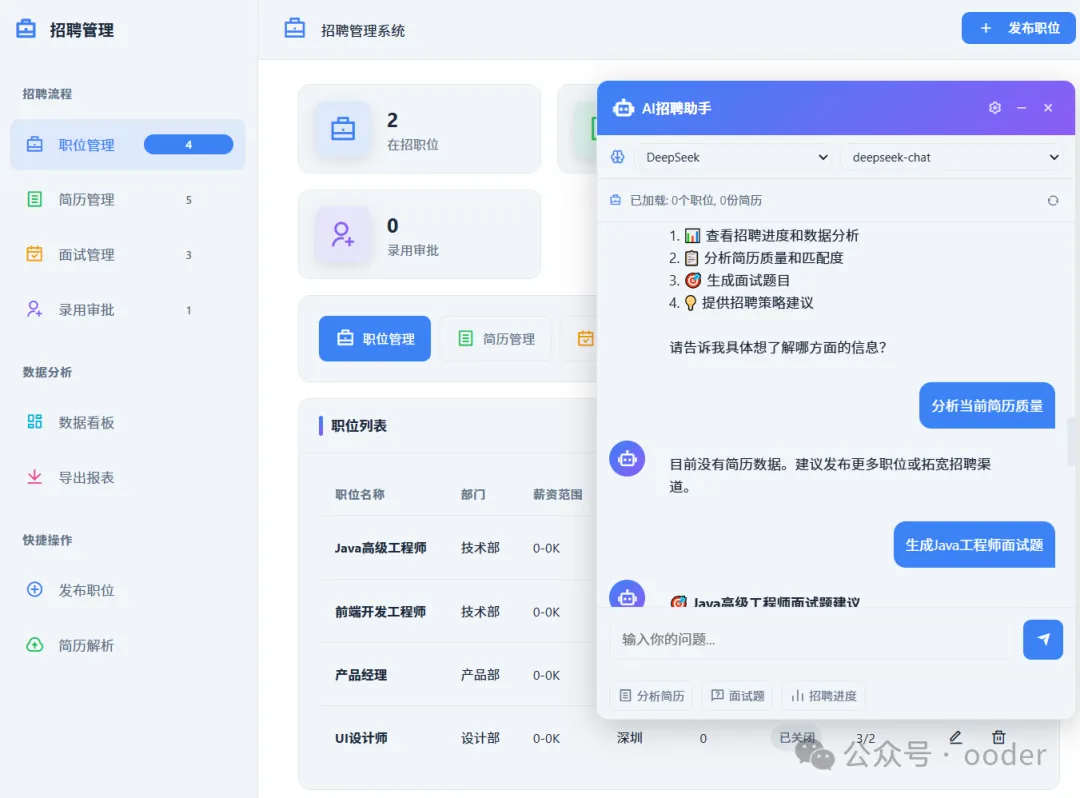
用户通过自然语言与系统交互:
👤 用户
"帮我筛选一下今天收到的简历,找出符合条件的Java开发候选人"
系统处理流程:
1 LLM意图理解
意图:简历筛选 | 时间:今天 | 岗位:Java开发
2 知识库检索
从岗位要求库获取筛选标准,从候选人库检索简历数据
3 能力执行
resume_screening.execute({dateRange: 'today', position: 'Java开发'})
4 结果生成
LLM生成自然语言回复
🤖 系统回复
"今天收到15份简历,筛选出3份符合条件的候选人: 1. 张三 - 5年Java经验,熟悉Spring Cloud 2. 李四 - 4年Java经验,有微服务项目经验 3. 王五 - 3年Java经验,全栈开发能力"
六、最佳实践
💡 知识库设计原则
- 分层管理:通用知识、专业模块、场景知识分离
- 权限控制:不同层级设置不同访问权限
- 质量监控:定期检查知识库数据质量
- 版本管理:知识更新保留历史版本
⚠️ LLM使用策略
- 优先规则:简单场景优先使用规则引擎
- LLM增强:复杂场景使用LLM增强体验
- 降级保障:始终配置离线降级方案
- 成本控制:缓存常用结果,减少LLM调用
🔒 安全注意事项
- 规则沙箱:限制危险操作,如exit、exec
- 输入验证:所有用户输入进行校验
- 权限检查:每次操作验证用户权限
- 审计日志:记录所有关键操作
七、总结
使用场景技能构建业务应用模块,核心优势在于:

适用场景:
招聘管理 智能客服 审批流程 知识问答 数据分析
技术栈:
- Scene Engine v2.3.1 + Spring Boot 2.x + Java 8+
- LLM Provider (OpenAI/Azure) + Embedding Service
- Vector Store (SQLite/Milvus) + Knowledge Base
- MVEL 2.5.x + 安全沙箱 + 动态规则生成
相关文档
二次开发指南 | 配置修改说明 | 招聘用户故事分析
Ooder Team 让AI能力触手可及
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号