腾讯云 Data Platform 构建 Agent Memory Lake:让智能体拥有无限记忆

腾讯云 Data Platform 构建 Agent Memory Lake:让智能体拥有无限记忆

云存储
发布于 2026-03-06 17:36:00
发布于 2026-03-06 17:36:00
导读
随着 AI Agent 技术的快速发展,其逐步从单一的模型训练与单次推理,转向持续运行、自主决策的业务闭环模式,这一转变推动了数据范式的根本性变革。与传统 AI 不同,AI Agent 运行过程中会持续产生轨迹数据、决策日志、工具调用记录等海量数据,这些数据需要满足低时延访问、长期保存、可分析复用的严苛需求。传统存储方案难以应对该需求,Memory 访问效率、容量与管理能力成为 AI Agent 推理效率的核心瓶颈。
在 Agentic AI Summit 2026 超级智能体系统架构峰会中,腾讯云存储解决方案总监温涛对上述挑战进行了深度剖析,并分享了腾讯云基于自身 Data Platform 技术底座,构建的 Agent Memory Lake 分层记忆体系,旨在解决 AI Agent 的记忆管理难题,支撑其高效推理、规划与持续进化。
01 背景介绍
1. 从训练到推理:AI Agent 正在改变算力与数据范式

图片
产生背景分析:底层存储重要性被低估:在 AI 系统构建初期,客户(如自动驾驶、AIGC、具身智能领域)往往忽视数据存储层(IaaS 层),更关注应用和平台层。但业务发展到一定规模后,存储层的任何变动都可能引发代价高昂的系统重构、业务中断,甚至业务风险。“烟囱式”架构的痛点:AI 业务流程(预处理、训练、推理)通常由不同部门负责,各自选用独立的存储方案,形成数据孤岛。随着数据量爆炸式增长(数据是 AI 的核心资产,只增不减),跨环节数据流动、共享、协作的效率低下、成本高昂(存储开销占比越来越大),且产生大量冗余副本。在这样的业务趋势下,AI Agent(智能体)的部署将产生海量交互数据,并带来实时访问与复杂治理需求,这对数据存储与管理提出了关键挑战。
Gartner 预测,至 2026 年约 40% 的企业应用将集成任务型 AI Agent;到 2026 年 AI 推理将占 IaaS 支出的约 55%。
2. Agent 推理效率的真正挑战: Memory 记忆体成为关键因素

图片
而在 AI Agent 场景下,Agent 的核心在于记忆(Memory),这使得数据管理的范式和重要性发生了根本变化,主要表现在以下几个方面:
- 数据角色转变:数据从服务于模型训练,转变为支持业务运行和实时决策。
- 记忆成为核心:Agent 的推理过程高度依赖对过往记忆的读取和更新,以形成新的决策并创造新记忆。
- 新存储挑战: 上下文变长且多变:推理过程需要更长、更多样的上下文记忆。 访问成为常态路径:记忆的读写成为每一次推理的主要操作,而非偶发行为。 规模持续膨胀:记忆作为长期资产被反复复用,数据量只增不减。 性能要求更加苛刻:需要低时延、高吞吐、长期保存和强内容检索能力。
3. 基于进化 Memory Lake 构建分层记忆体系,支撑 Agent 推理、规划与持续
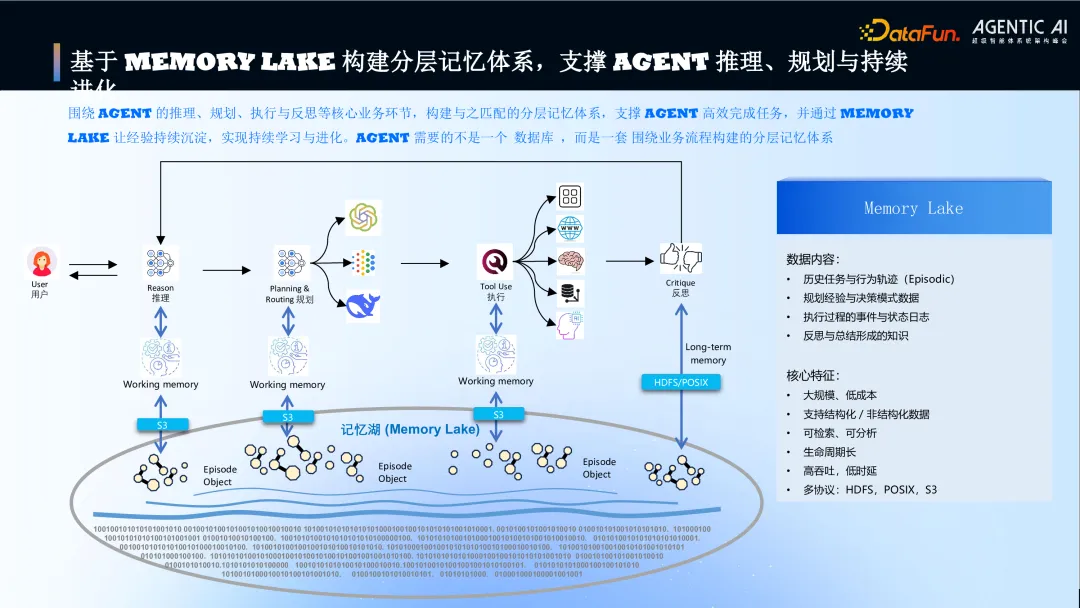
图片
Agent 需要的不是单一的数据库,而是一套围绕业务流程构建的分层记忆体系,为解决 Agent 特有的记忆管理挑战,我们提出了 “记忆湖(Memory Lake)” 这一新概念,Memory Lake 是面向 AI Agent 场景、以“记忆”为核心资产的数据管理与存储体系。它类比于大数据领域的“数据湖”,但专门针对 Agent 业务场景中记忆数据的特殊性。基于 Memory Lake 构建分层记忆体系,以支撑 Agent 的推理、规划、执行与反思等核心环节。Memory Lake 数据内容包括历史任务与行为轨迹、规划经验与决策模式、执行过程的事件与状态日志、反思总结形成的知识。其核心特征:大规模、低成本;支持结构化/非结构化数据;可检索、可分析;生命周期长;高吞吐、低时延;支持多协议(HDFS, POSIX, S3),具体核心能力归纳如下:
- 大规模与低成本:支撑海量、持续膨胀的记忆数据,同时控制成本。
- 多模态数据支持:能存储结构化、半结构化、非结构化等各种形态的记忆数据(任务轨迹、决策日志、反思总结等)。
- 检索与分析能力:支持高效的元数据管理和内容检索(如向量化搜索),以便在正确时间推送正确的记忆。
- 精细化生命周期管理:能够根据时间、逻辑、知识体系等维度对记忆进行分类(如区分短期/长期记忆、设定不同“温度”),优化存储效率和访问性能。
- 高性能访问:高吞吐、低时延,以满足推理过程的实时性要求。
- 多协议兼容:除对象存储接口(如 S3)外,还需支持文件存储(POSIX)、大数据(HDFS)等协议,以适配上层多样的应用和平台。
- 安全与合规:保障记忆资产的安全性(加密、认证、访问控制),并满足国内外合规要求。
02 方案介绍
1. 腾讯云 Data Platform: 构建 Agent Memory Lake 的基础底座
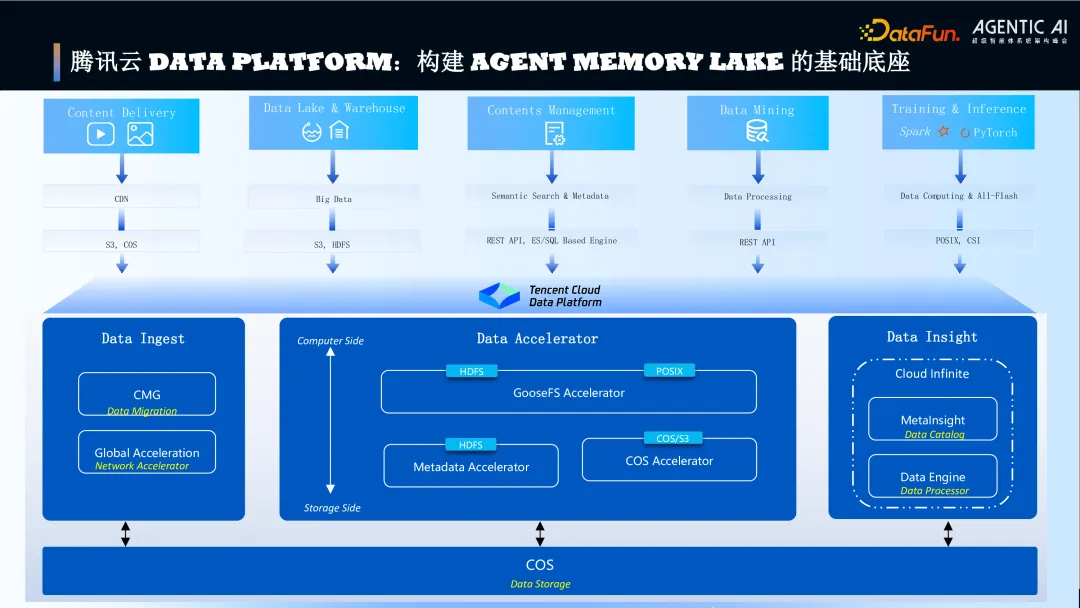
图片
腾讯云提出了以 Data Platform 为基础的解决方案来构建“记忆湖”。腾讯云 Data Platform 作为构建 Agent Memory Lake 的基础技术架构,核心组件如下:
- 对象存储(COS): 基础:提供近乎无限扩展、高可靠、高可用的底层存储底座,满足百 PB 级规模需求。 安全性:提供端到端加密、访问控制、多地多可用区容灾等能力。
- 数据加速器(GooseFS): 作用:在计算侧近端构建缓存层,通过预测和预加载算法,将高频访问的记忆数据提前加载到高性能介质中。 价值:极大提升读取性能(缓解对象存储在 HTTP / REST 接口下的高时延访问问题),减少网络传输延迟,并可将对象存储能力扩展为高性能文件存储服务。
- 记忆洞察(MetaInsight): 角色:核心的元数据管理和分析引擎,作为 Memory Lake 的元数据管理与智能检索中枢。 功能:负责记忆内容的向量化、知识图谱构建、元数据提取与管理、分类分级、生命周期策略制定以及与加速器协同的智能数据预取调度。
- 数据处理引擎(Data Engine): 角色:记忆内容的加工与治理引擎。 功能:负责短期/长期记忆的格式转换、记忆内容的分类打标、优先级判定、内容安全审核(如合规性检查)、以及多媒体(图/音/视频/文档)处理等。
2. 腾讯云 Data Platform Agent Memory Lake 解决方案
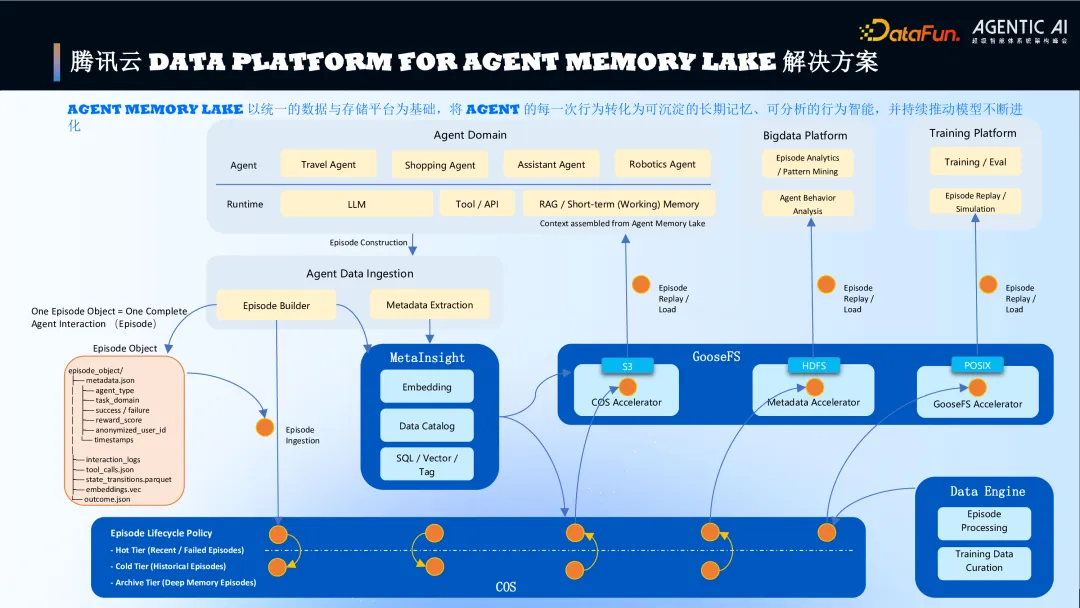
图片
完整解决方案流程图的核心流程包括 Agent 行为数据(Episode)通过摄入、元数据提取(MetaInsight)进入存储(COS),进而支持训练评估、行为分析、模式挖掘、并最终通过 RAG/工作记忆(Working Memory)辅助 LLM 进行决策与工具调用,形成数据闭环,推动模型持续进化。
具体工作流程(与 Agent 业务结合)如下:
- 记忆摄入:Agent 任务产生的记忆数据(如交互会话、决策日志)被打包后,存入底层对象存储(COS)。
- 洞察与分析:“记忆洞察(MetaInsight)”组件对这些记忆数据进行内容分析、向量化,提取元数据并建立关联索引。
- 加速访问:当 Agent 进行推理需要读取记忆时,“数据加速器(GooseFS)”根据预测和索引,将相关数据高效缓存至近计算端,提供低时延访问。
- 治理与反馈:“数据处理引擎(Data Engine)”负责记忆的合规检查、格式转换、分类等。处理后的高质量记忆还可用于模型的持续精调(Fine-tuning),形成闭环。
3. COS 对象存储:功能全面、高可靠性、高性价比的 Data Platform 存储底座

图片
腾讯云 COS(对象存储)作为 Data Platform 的高可靠、高性价比存储底座,关键能力包括接入层具备弹性扩缩容和负载均衡;YottaStore 存储引擎支持原生多 AZ、数据自动均衡;提供极高的可用性(99.995%)和数据持久性(99.999999999%);单集群架构可扩展至百 EB 级以上规模。
4. COS 对象存储:全面的数据加密能力,保证云上数据安全、可靠、合规
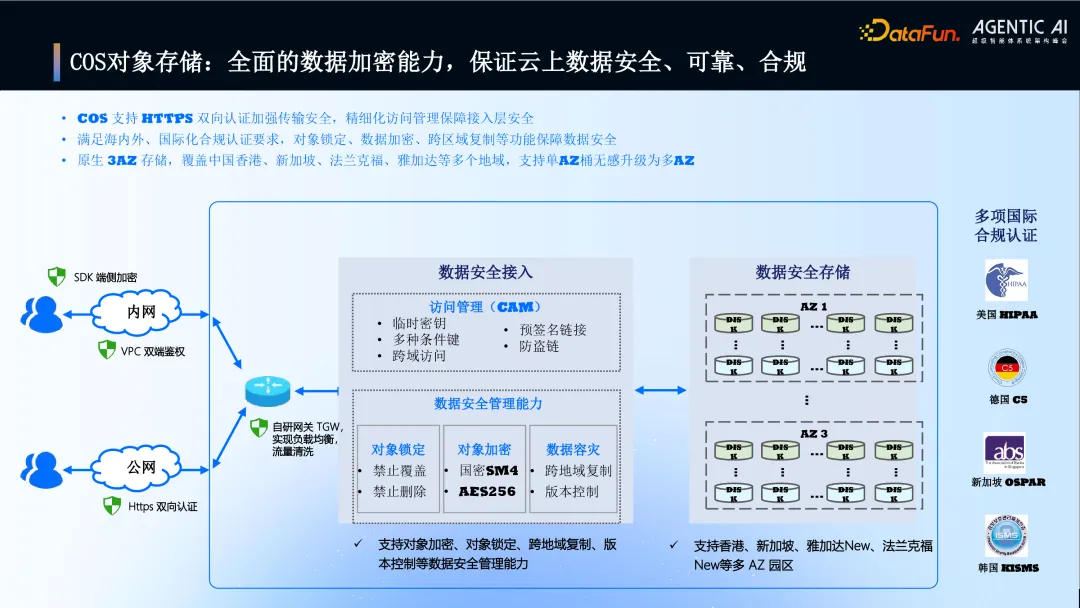
图片
强调 COS 全面的数据安全与合规能力。
安全特性:支持 HTTPS、精细化访问管理(CAM)、对象锁定、数据加密(国密 SM4/AES256)、跨区域复制等。
合规认证:获得多项国际合规认证,如 HIPAA、德国 C5、新加坡 OSPAR 等。
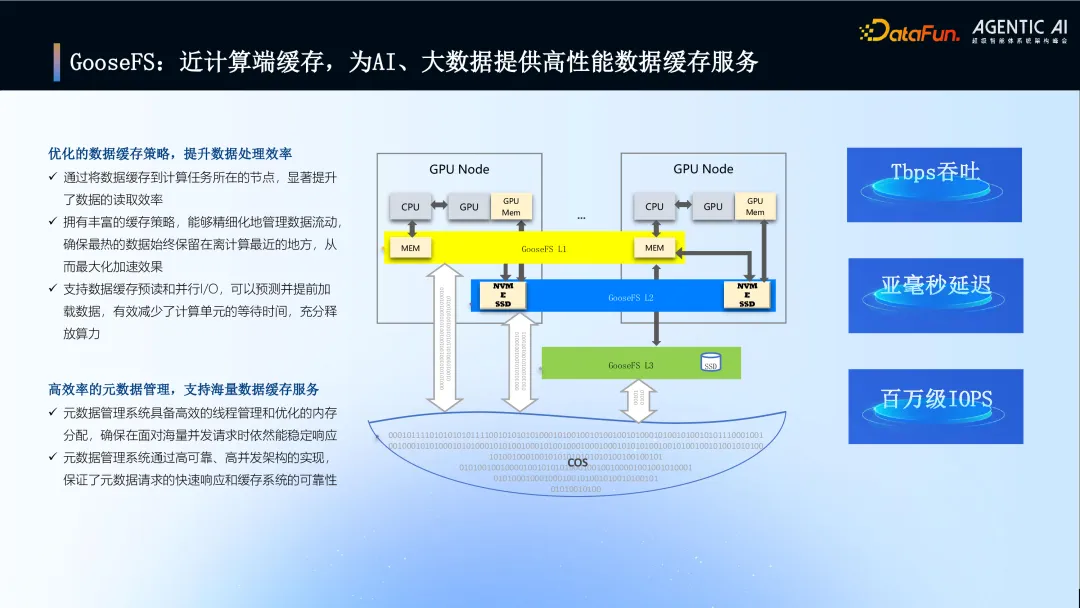
5. GooseFS:近计算端缓存,为 AI、大数据提供高性能数据缓存服务
图片
介绍 GooseFS 作为近计算端的高性能数据缓存服务,用于加速 AI、大数据场景。
核心价值:通过将热数据缓存到计算节点(如 GPU 节点),显著提升数据读取效率;支持丰富的缓存策略、数据预读和并行 I/O;高效的元数据管理支持海量并发。
性能指标:提供亚毫秒延迟、百万级 IOPS 和 Tbps 级吞吐
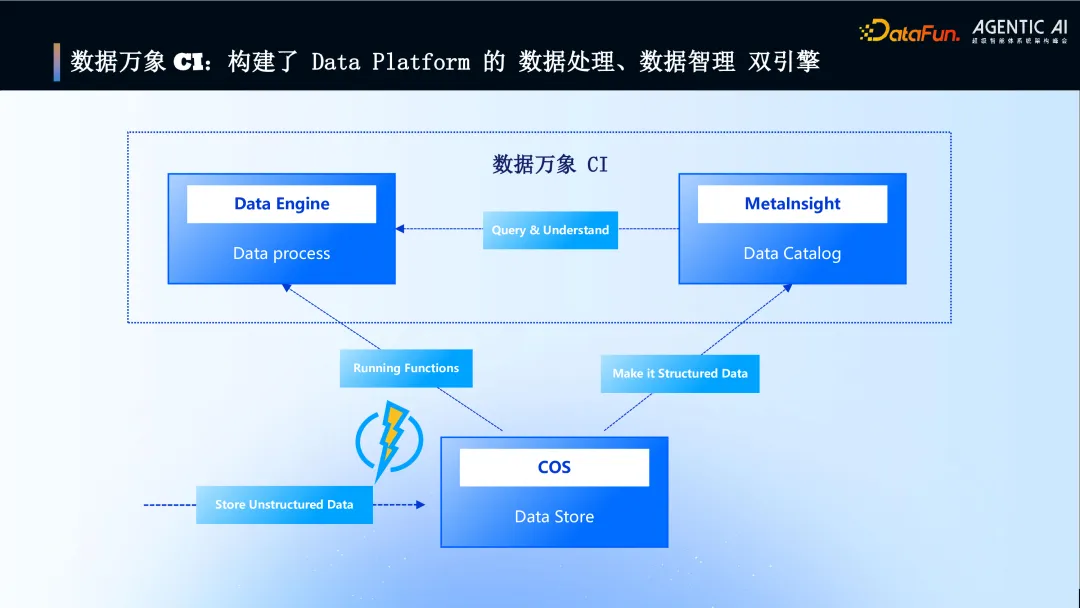
6. 数据万象 CI : 构建了 Data Platform 的数据处理、数据智理双引擎
图片
介绍数据万象(CI)构建了 Data Platform 的“数据处理”与“数据智理”双引擎。
Data Engine:提供一站式数据处理服务。
MetaInsight:提供数据智能检索服务。
7. 数据万象 CI:数据处理引擎 Data Engine,提供一站式数据处理服务

图片
详细列举数据万象数据处理引擎(Data Engine)的丰富功能,包括内容审核(图/文/音/视频)、图片处理(压缩/裁剪/水印等)、视频处理(转码/加密/水印等)、音频处理(转码/ASR/TTS 等)、文档服务、文件处理以及智能处理(标签/超分/修复等)。
8. 数据万象 CI:数据智理引擎 MetaInsight,提供数据智能检索服务

图片
介绍数据万象数据智理引擎(MetaInsight)的核心能力和特点,主要包括支持跨模态(内容、向量、标签、元信息)检索;覆盖 1000+细分场景;高性能(千亿数据毫秒级查询,95%+召回率)
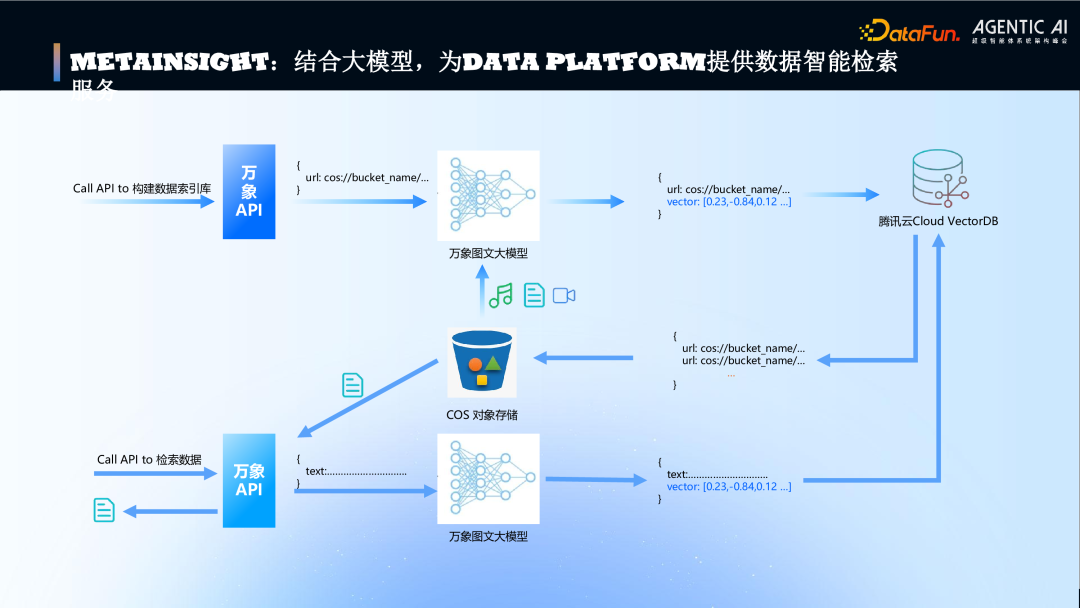
9. MetaInsight:结合大模型,为 Data Platform 提供数据智能检索服务
图片
针对 MetaInsight 如何结合大模型(如万象图文大模型)和向量数据库(Cloud VectorDB),为 Data Platform 提供智能数据检索服务,实现从非结构化数据到向量索引和语义查询的闭环
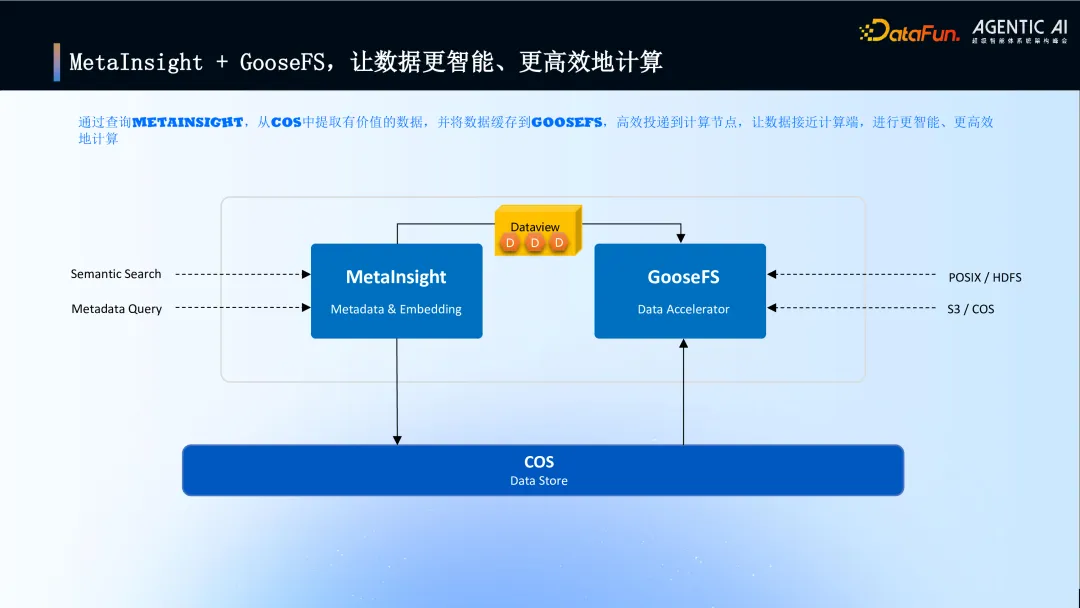
10. MetaInsight + GooseFS,让数据更智能、更高效地计算
图片
强调 MetaInsight 与 GooseFS 的协同效应:通过 MetaInsight 从 COS 中智能检索出有价值的数据,并利用 GooseFS 将其高效缓存并投递到计算节点,实现数据“更智能、更高效地计算”
11. 具身智能 Agent 基于海量、多元化数据集,训练跨模态大模型,来构建大脑
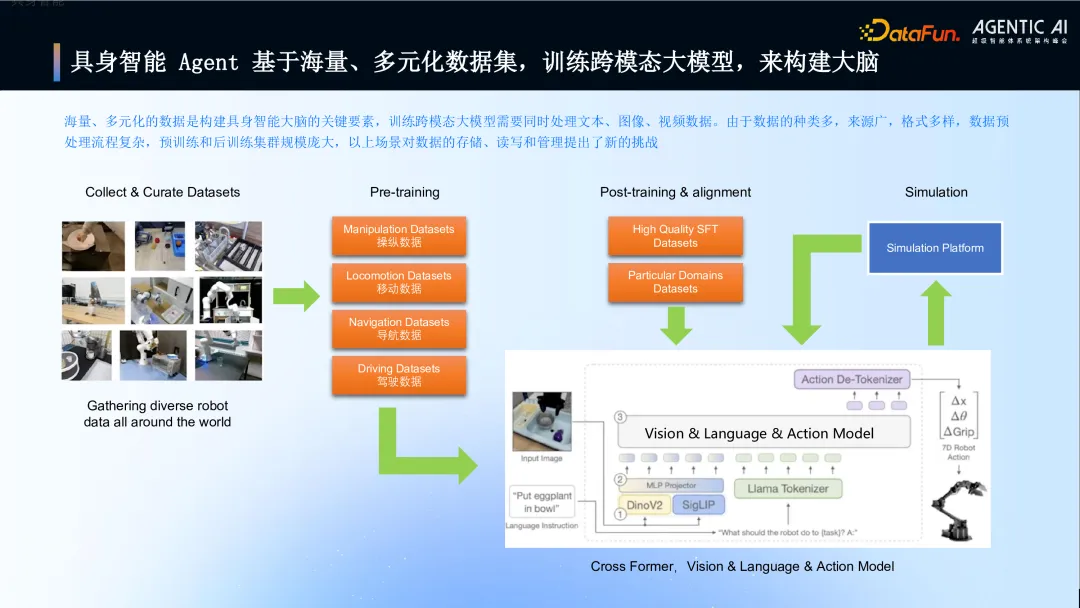
图片
指出构建具身智能大脑(训练跨模态大模型)面临的数据挑战:需要海量、多元化的文本、图像、视频数据;数据预处理复杂;训练集群规模庞大;对数据存储、读写和管理提出了高要求。
03 解决方案
1. 解决方案:腾讯云 Data Platform 智能驾驶/具身智能场景解决方案
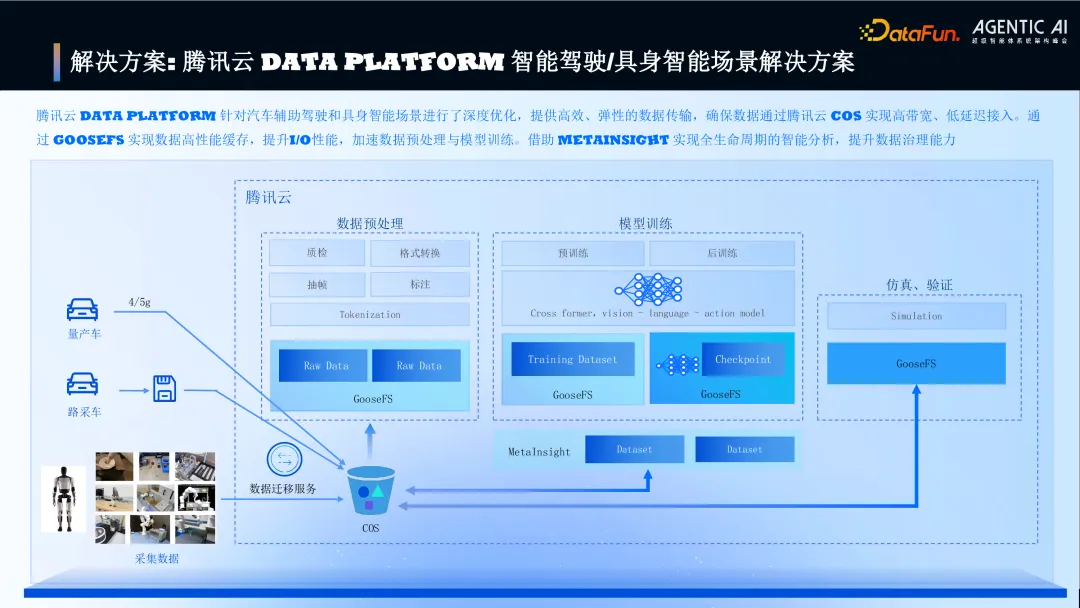
图片
针对智能驾驶/具身智能场景的解决方案。
核心要点:通过 COS 实现高带宽、低延迟的数据接入;通过 GooseFS 实现数据高性能缓存,加速预处理与训练;通过 MetaInsight 实现数据全生命周期智能分析,提升治理能力
2. 客户案例:基于腾讯云 Data Platform 构建汽车辅助驾驶训练平台
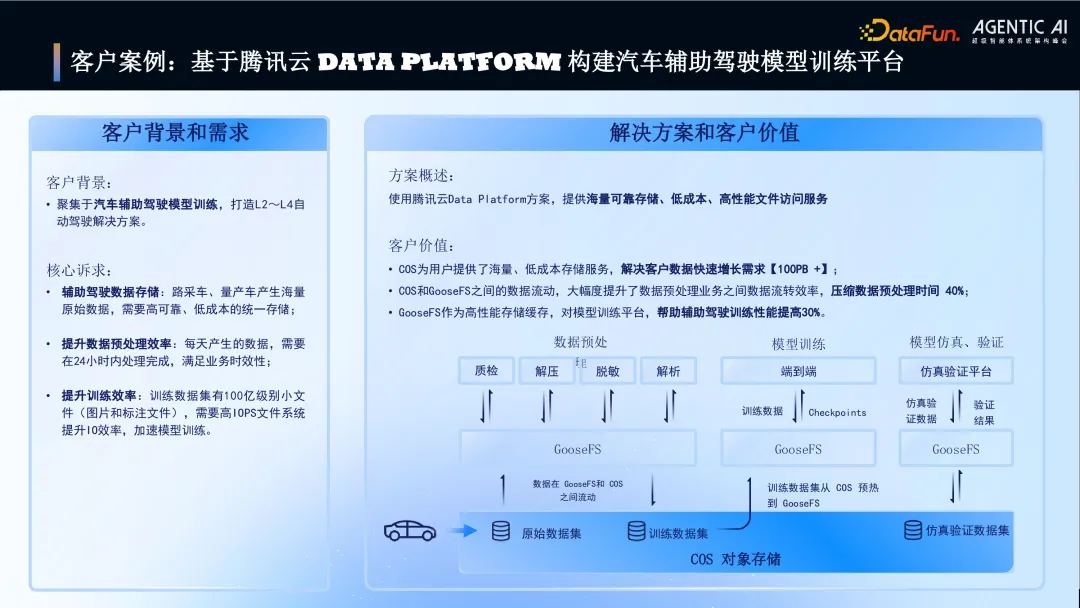
图片
针对汽车辅助驾驶模型训练平台的客户案例。
客户需求:海量原始数据(路采车、量产车)的高可靠低成本存储;提升数据预处理效率(日数据 24 小时内处理);提升训练效率(处理 100 亿级小文件的高 IOPS)。
解决方案与价值:使用 COS 满足海量低成本存储需求(100PB+);COS 与 GooseFS 的数据流动将预处理时间压缩 40%;GooseFS 作为高性能缓存将训练性能提升 30%
3. 客户案例:基于腾讯云 Data Platform 构建具身智能模型训练平台
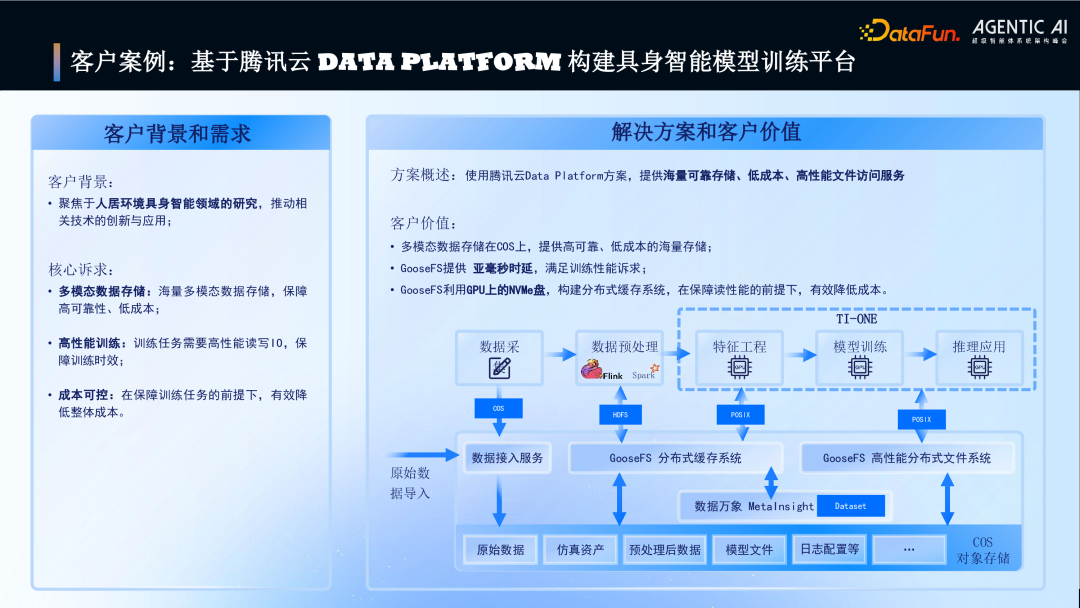
图片
针对具身智能模型训练平台的客户案例。
客户需求:海量多模态数据的高可靠低成本存储;训练任务的高性能读写 IO;有效控制整体成本。
解决方案与价值:COS 提供高可靠低成本的海量存储;GooseFS 提供亚毫秒级延迟满足训练性能;利用 GPU 节点 NVMe 盘构建缓存系统,在保障性能的同时降低成本。
4. 解决方案:腾讯云 Data Platform AIGC 场景解决方案
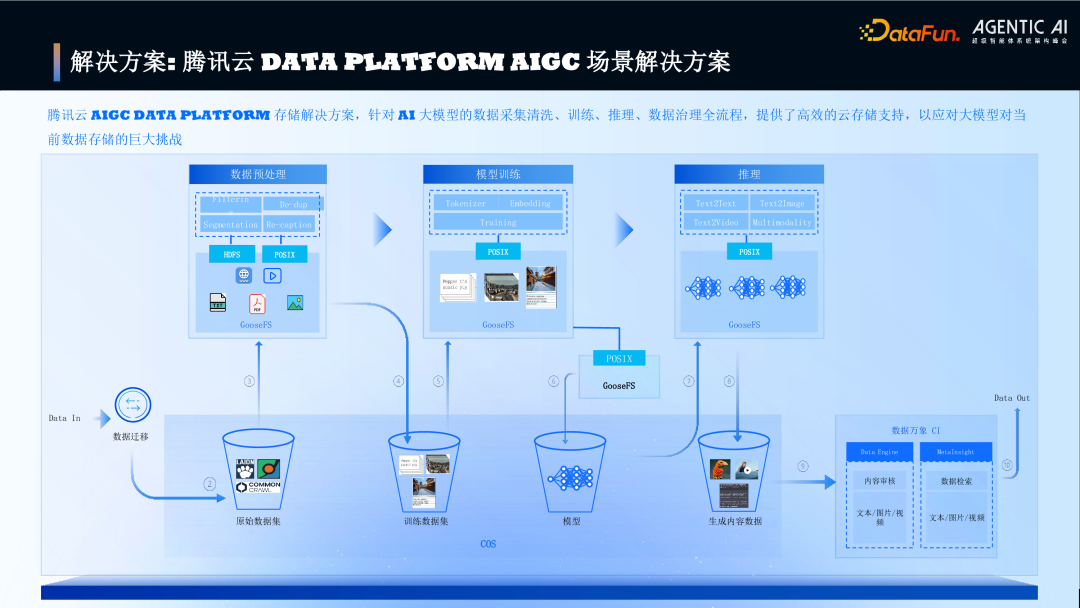
图片
5. 客户案例:基于腾讯云 Data Platform 构建 AIGC 业务全流程解决方案
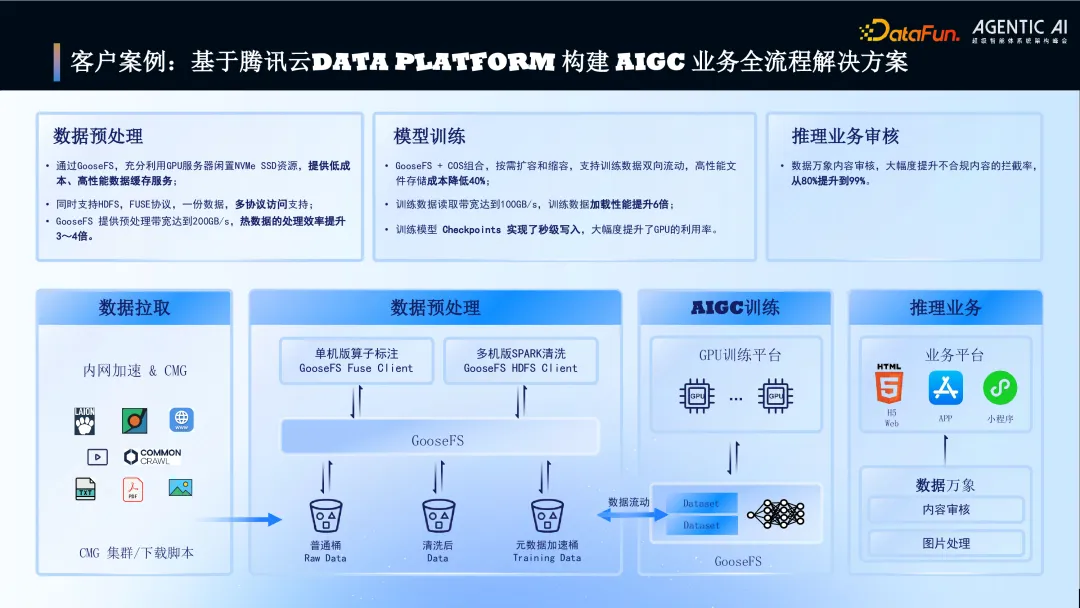
图片
针对 AIGC 业务全流程解决方案的客户案例。
数据预处理:GooseFS 利用闲置 NVMe 资源提供低成本高性能缓存,支持多协议访问,预处理带宽达 200GB/s,效率提升 3-4 倍。
模型训练:GooseFS+COS 组合支持弹性伸缩和双向数据流动,训练数据读取带宽达 100GB/s,加载性能提升 6 倍,Checkpoint 秒级写入提升 GPU 利用率。推理业务审核:数据万象内容审核将不合规内容拦截率从 80% 提升至 99%。
6. 腾讯云 Data Platform,优化存储性能与智能化管理,全面释放数据潜能
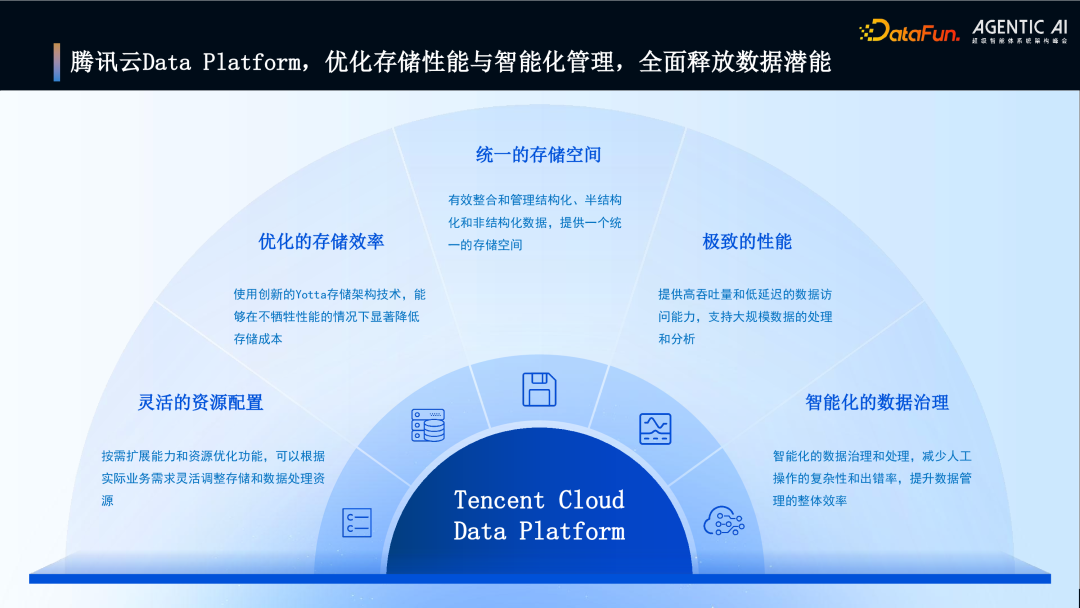
图片
腾讯云旨在通过其 Data Platform 解决方案(COS + GooseFS + MetaInsight + Data Engine),打造满足 Agent 业务需求的 Memory Lake,实现:
- 灵活资源配置与效率优化
- 统一存储空间,减少数据流动损耗
- 极致的访问性能
- 智能化的数据治理(核心)
在记忆湖(Memory Lake)与数据湖(Data Lake)的关系方面:记忆湖是数据湖概念的演进和深化。它包含了数据湖的基础存储和多模态支持能力,但更侧重于满足记忆数据特有的强关联性、复杂元数据管理和精细化生命周期治理等更高阶要求,是更贴近 Agent 业务层的数据管理范式。
总结腾讯云 Data Platform 的五大核心价值:
- 统一的存储空间:整合管理各类数据。
- 极致的性能:高吞吐、低延迟数据访问。
- 优化的存储效率:创新 Yotta 架构降低存储成本。
- 灵活的资源配置:按需扩展与资源优化。
- 智能化的数据治理:提升数据管理效率
7. 腾讯云存储服务千行万业
腾讯云存储服务已应用于电商、金融、汽车、AI、物联网、生物医疗、游戏、政务等广泛行业。针对 Agent 场景,方案将重点增强记忆数据洞察(MetaInsight)和数据处理(Data Process) 这两个组件的能力,可以应对记忆数据更复杂的关联性、分类和安全管理需求。根据 Frost & Sullivan 报告,腾讯云为“中国AI云存储解决方案领导者”,并已携手 300+行业先锋完成 AI 地图的探索和落地。
以上就是本次分享的内容,谢谢大家。
本文系转载,前往查看
如有侵权,请联系 cloudcommunity@tencent.com 删除。
本文系转载,前往查看
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号