【JavaSE】数组的创建和初始化 && 数组与引用类型 && 数组的应用场景及常见方法使用 && 二维数组
原创
【JavaSE】数组的创建和初始化 && 数组与引用类型 && 数组的应用场景及常见方法使用 && 二维数组
原创
lirendada
发布于 2026-03-06 13:11:04
发布于 2026-03-06 13:11:04
Ⅰ. 数组的创建以及初始化
一、数组的创建
T[] 数组名 = new T[N];T:数组的类型N:数组的长度
🐛 举个例子:
int[] array1 = new int[10]; // 创建一个可以容纳10个int类型元素的数组
double[] array2 = new double[5]; // 创建一个可以容纳5个double类型元素的数组
String[] array3 = new String[3]; // 创建一个可以容纳3个字符串元素的数组二、数组的初始化
数组的初始化主要分为动态初始化以及静态初始化。
- 动态初始化:在创建数组时,直接指定数组中元素的个数
int[] array = new int[10];2. 静态初始化:在创建数组时不直接指定数据元素个数,而直接将具体的数据内容进行指定
int[] array1 = new int[]{0,1,2,3,4,5,6,7,8,9};
double[] array2 = new double[]{1.0, 2.0, 3.0, 4.0, 5.0};
String[] array3 = new String[]{"hell", "Java", "!!!"};【注意事项】
- 静态初始化虽然没有指定数组的长度,编译器在编译时会根据
{}中元素个数来确定数组的长度。 - 静态初始化时,
{}中数据类型必须与[]前数据类型一致。 - 静态初始化可以简写,省去后面的
new T[](推荐写法)
// 注意:虽然省去了new T[], 但是编译器编译代码时还是会还原
int[] array1 = {0,1,2,3,4,5,6,7,8,9};
double[] array2 = {1.0, 2.0, 3.0, 4.0, 5.0};
String[] array3 = {"hell", "Java", "!!!"};- 静态和动态初始化也可以分为两步,但是省略格式不可以
int[] array1;
array1 = new int[10];
int[] array2;
array2 = new int[]{10, 20, 30};
// 注意省略格式不可以拆分, 否则编译失败
// int[] array3;
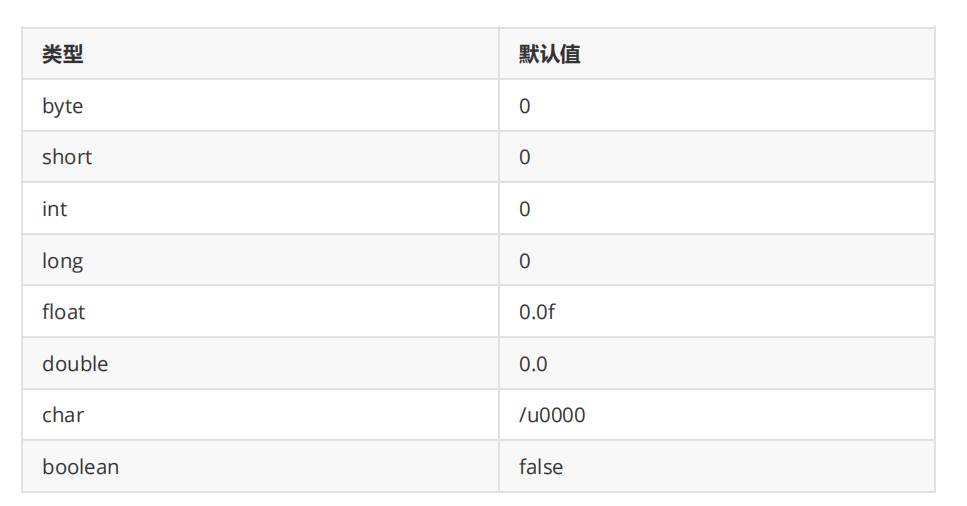
// array3 = {1, 2, 3};- 如果没有对数组进行初始化,数组中元素有其默认值:
- 如果数组中存储元素类型为引用类型,默认值为
null - 如果数组中存储元素类型为基类类型,默认值为基类类型对应的默认值,如下所示:
- 如果数组中存储元素类型为引用类型,默认值为
三、数组的使用
比如数组的访问、数组的遍历:
import java.util.Arrays;
public static void main(String[] args) {
int[] arr = {1,2,3,4,5,6,7,8,9,10,11,12,13};
// 遍历方式1:通过.length获取数组的长度
for(int i = 0; i < arr.length; ++i) {
System.out.println(arr[i]);
}
// 遍历方式2:范围for
for(int e : arr) {
System.out.println(e);
}
// 遍历方式3:使用Arrays中的函数toString(需要先导入包)
System.out.println(Arrays.toString(arr));
}
// 运行结果:
1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13
1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13]注意事项:使用 Arrays.toString 的时候要先导入 java.util.Arrays 这个包,这个包是专门做数组处理的一个包。
四、数组的销毁
在 java 中,不需要我们手动去释放数组,JVM 会有垃圾回收机制替我们工作!除此之外,当一个数组对象不被任何 “引用变量” 引用的时候,JVM 就会将这个数组对象给释放掉。
Ⅱ. 数组与引用类型
一、初识 JVM 的内存分布
内存是一段连续的存储空间,主要用来存储程序运行时数据的。比如:
- 程序运行时代码需要加载到内存
- 程序运行产生的中间数据要存放在内存
- 程序中的常量也要保存
- 有些数据可能需要长时间存储,而有些数据当方法运行结束后就要被销毁
如果对内存中存储的数据不加区分的随意存储,那对内存管理起来将会非常麻烦。因此JVM也对所使用的内存按照功能的不同进行了划分:
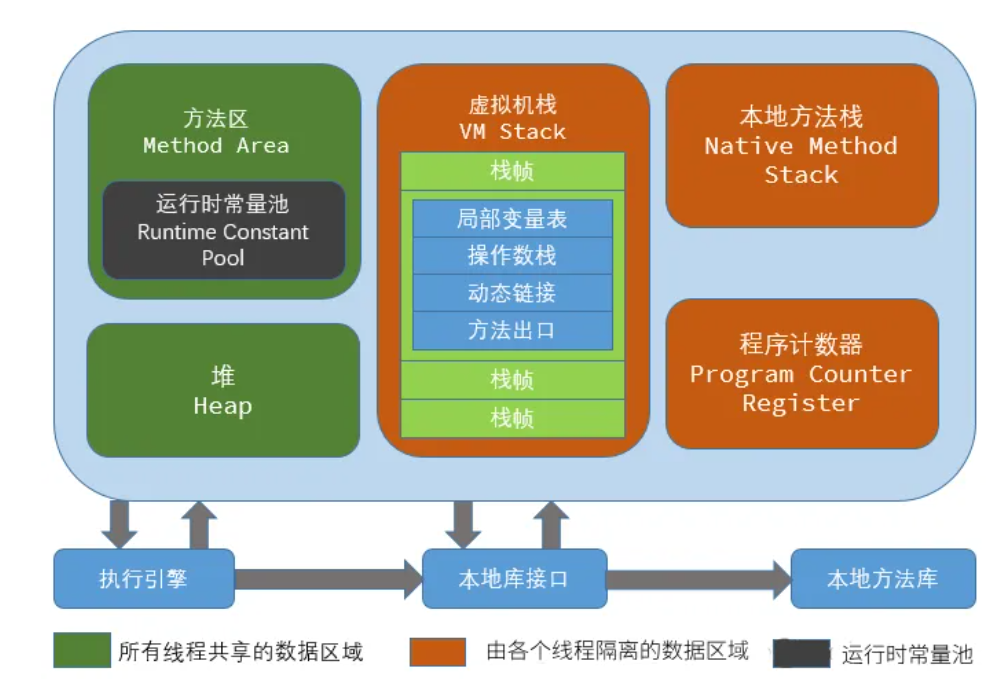
- 程序计数器(
PC Register):只是一个很小的空间,保存下一条执行的指令的地址。 - 虚拟机栈(
JVM Stack):与方法调用相关的一些信息,每个方法在执行时,都会先创建一个栈帧!- 栈帧中包含有:局部变量表、操作数栈、动态链接、返回地址以及其他的一些信息,保存的都是与方法执行时相关的一些信息。
- 比如:局部变量,当方法运行结束后,栈帧就被销毁了,即栈帧中保存的数据也被销毁了。
- 本地方法栈(
Native Method Stack):本地方法栈与虚拟机栈的作用类似,只不过保存的内容是Native方法的局部变量,底层是C/C++实现的,在有些版本的JVM实现中(例如HotSpot),本地方法栈和虚拟机栈是一起的。 - 堆(
Heap):JVM所管理的最大内存区域,使用new创建的对象都是在堆上保存(例如前面的new int[]{1, 2, 3}),堆是随着程序开始运行时而创建,随着程序的退出而销毁,堆中的数据只要还有在使用,就不会被销毁。 - 方法区 (
Method Area):用于存储已被虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码等数据,方法编译出的的字节码就是保存在这个区域。
二、基本类型变量与引用类型变量的区别
- 基本数据类型创建的变量,称为基本变量,该变量空间中直接存放的是其所对应的值。
- 引用数据类型创建的变量,称为对象的引用,该变量空间中存储的是对象所在空间的地址。
public static void main(String[] args) {
// 对于基本类型无法对其取地址,因为基本类型在空间中是直接存放的
int a = 10;
float b = 20.1f;
// 打印数组名其实就是打印其地址
// 因为java中的数组其实new出来的,也就是在堆上的
// 而arr数组名其实存放的是一个地址,类似于指针指向堆中的数据
int[] arr = {1,3,5,7,9};
System.out.println(arr);
}
// 运行结果:
[I@1b6d3586在上述代码中,a、b、arr 都是函数内部的变量,因此其空间都在 main 方法对应的栈帧中分配。其中 a、b 是内置类型的变量,因此其空间中保存的就是给该变量初始化的值。而 array 是数组类型的引用变量,其内部保存的内容可以简单理解成是数组在堆空间中的首地址。
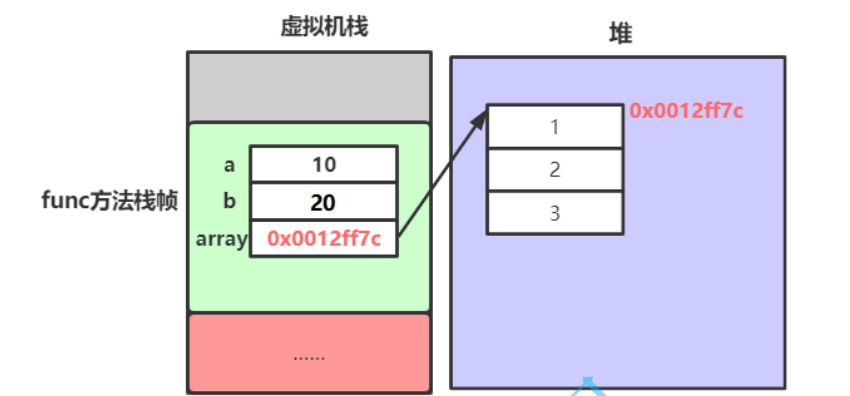
从上图可以看到,引用变量并不直接存储对象本身,可以简单理解成存储的是对象在堆中空间的起始地址。通过该地址,引用变量便可以去操作对象。且该地址其实是通过哈希得到的!有点类似C语言中的指针,但是 Java 中引用要比指针的操作更简单。
三、再谈引用变量
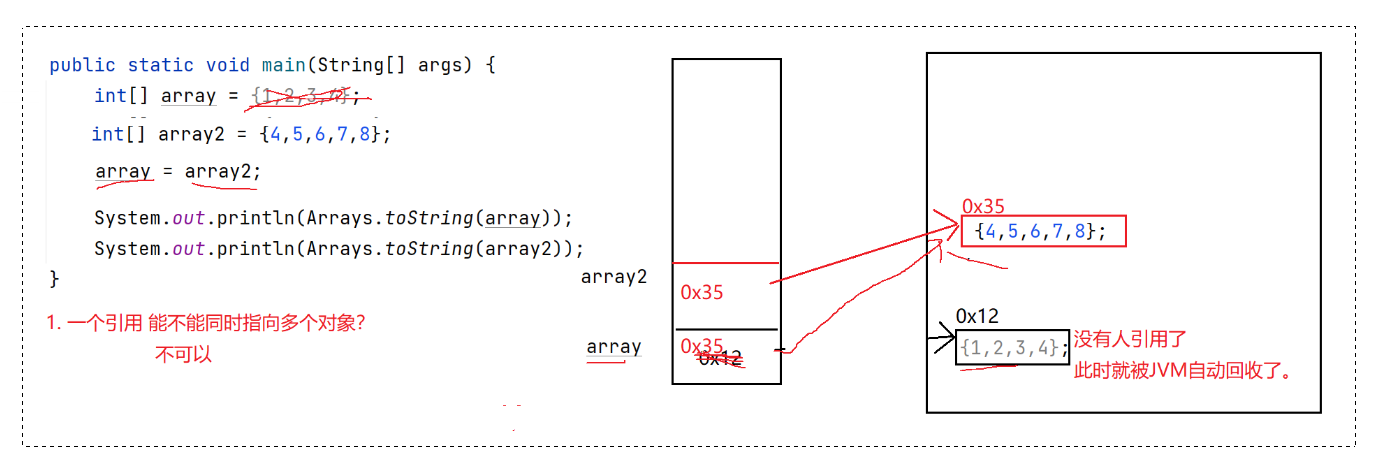
public static void main(String[] args) {
int[] array1 = new int[3];
array1[0] = 10;
array1[1] = 20;
array1[2] = 30;
int[] array2 = new int[]{1,2,3,4,5};
array2[0] = 100;
array2[1] = 200;
array1 = array2; // 重点!!!
array1[2] = 300;
array1[3] = 400;
array2[4] = 500;
for (int i : array2) {
System.out.println(i);
}
}
// 运行结果:
100 200 300 400 500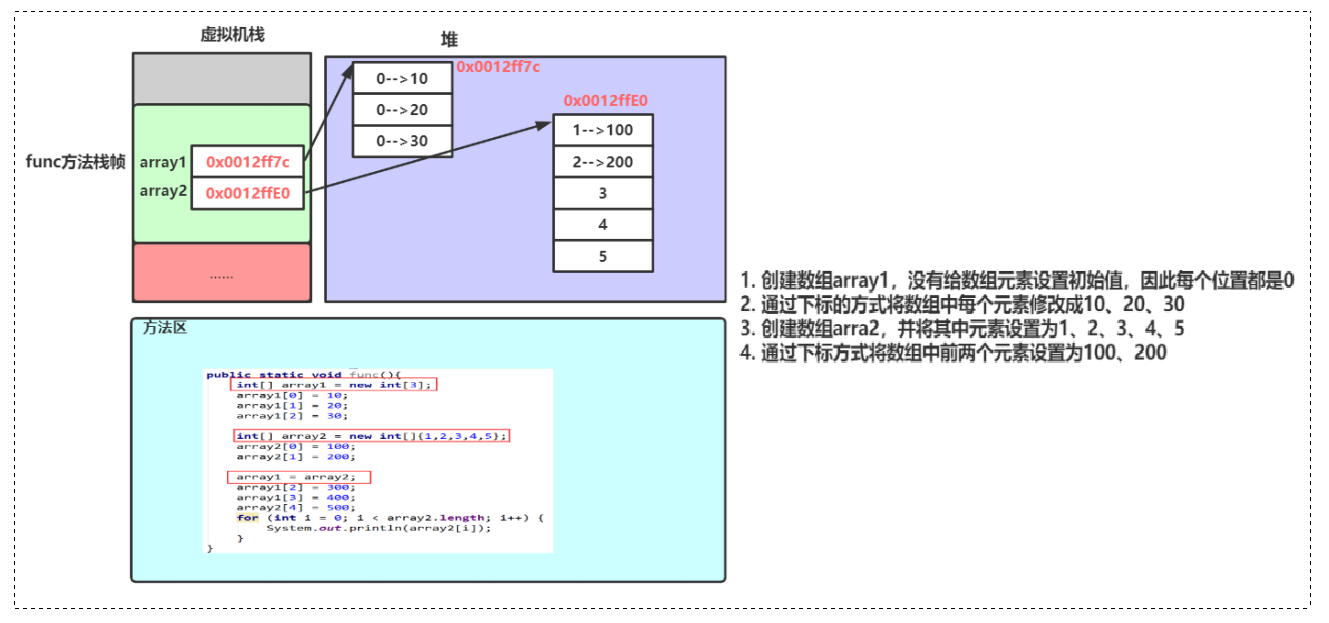

四、认识 null
null 在 java 中表示空引用,也就是一个不指向对象的引用。
int[] arr = null;
System.out.println(arr[0]);
// 执行结果
Exception in thread "main" java.lang.NullPointerException at Test.main(Test.java:6)null 的作用类似于 C 语言中的 NULL(空指针),都是表示一个无效的内存位置。因此不能对这个内存进行任何读写操作,一旦尝试读写,就会抛出 NullPointerException.
注意:Java 中并没有约定 null 和 0 号地址的内存有任何关联。
Ⅲ. 数组的应用场景及常见方法使用
一、作为函数的参数
情形①
public static void func(int[] tmp) {
tmp[0] = 199;
}
public static void main(String[] args) {
int[] arr = {2,4,6,7,8};
System.out.println(Arrays.toString(arr));
func(arr);
System.out.println(Arrays.toString(arr));
}
// 运行结果:
[199, 4, 6, 7, 8]可以发现,上面 func 中的 tmp 其实也是指向该 arr 数组中的数据的,那么 tmp[0] = 199 其实最后改的就是同一个数组里面中的数据,如下图所示:
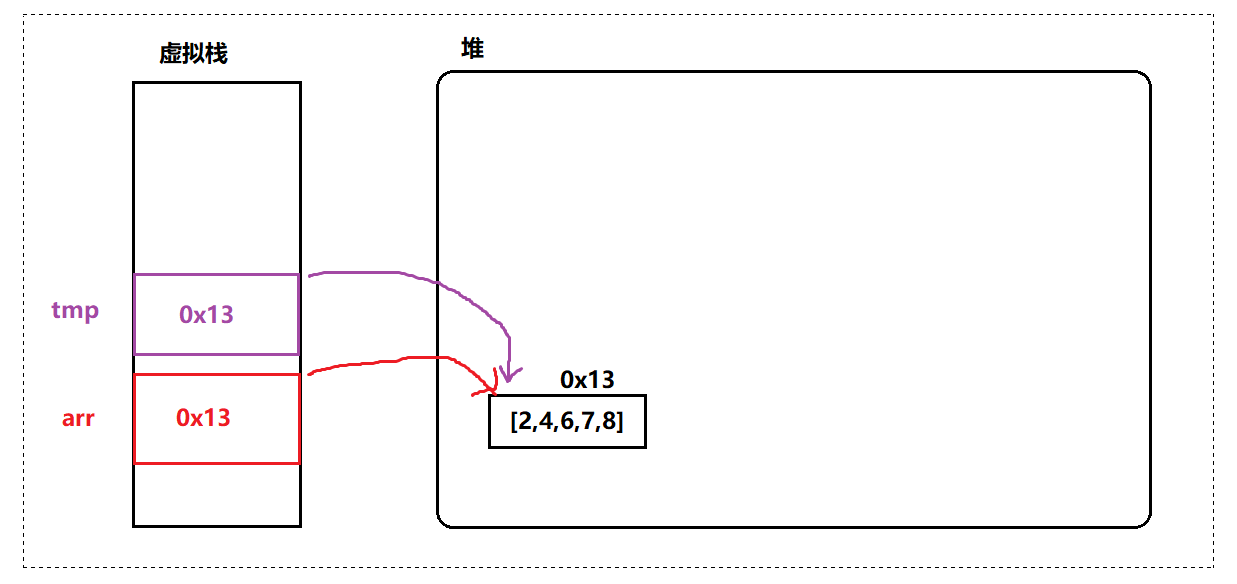
因为数组是引用类型,按照引用类型来进行传递,是可以修改其中存放的内容的。
情形②
在上面的基础上添加一个 newArr 函数:
public static void func(int[] tmp) {
tmp[0] = 199;
}
public static void newArr(int[] tmp) {
tmp = new int[10];
}
public static void main(String[] args) {
int[] arr1 = {2,4,6,7,8};
func(arr1);
System.out.println(Arrays.toString(arr1));
int[] arr2 = {2,4,6,7,8};
newArr(arr2);
System.out.println(Arrays.toString(arr2));
}
// 运行结果:
[199, 4, 6, 7, 8]
[2, 4, 6, 7, 8]这里非常容易搞错,就是误以为 newArr 中的 tmp 是C语言中的指针,其实不是,tmp 只是存放了堆中数据的地址,当 tmp = new int[10] 后,就是重新开辟了一段空间并改变了指向,最重要的是,这里的 tmp 也只是个引用变量,和 arr 变量是不相关的,所以改了 tmp 的指向,对原来 arr 是没有影响的。
因为有些情况下形参名字和实参是一样的,会让我们觉得形参改变后实参也改变了,其实是互不影响的,但是对于 func 中的函数指向同一块空间进行了修改,那才是有影响的!
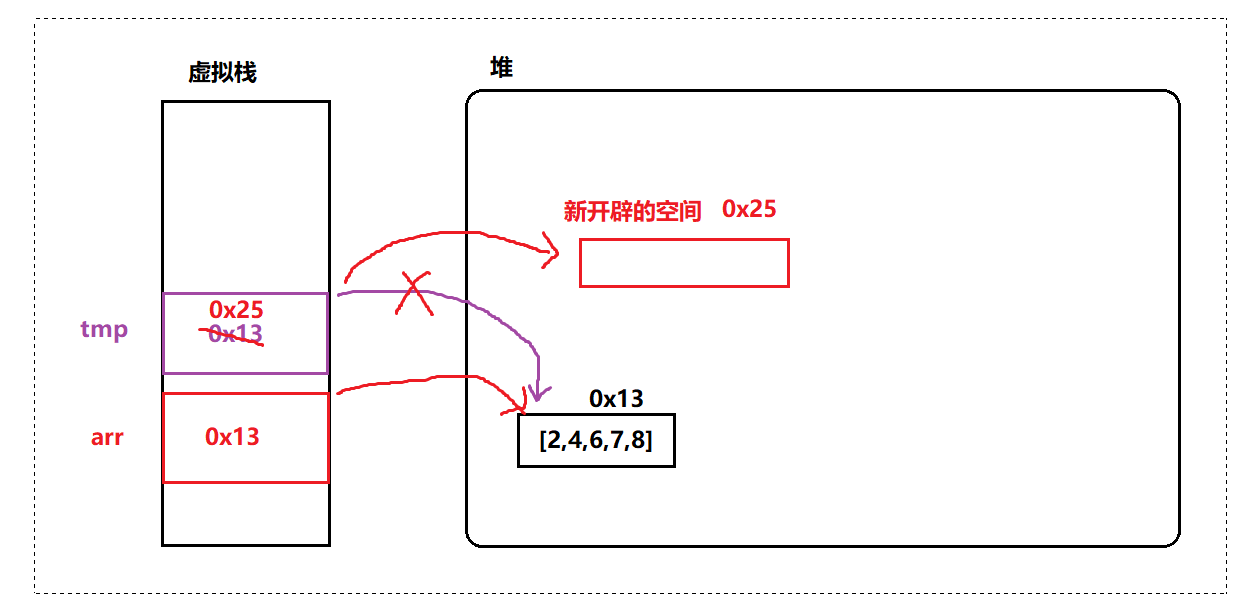
总结:所谓的 "引用" 本质上只是存了一个地址。Java 将数组设定成引用类型,这样的话后续进行数组参数传参,其实只是将数组的地址传入到函数形参中,这样可以避免对整个数组的拷贝(数组可能比较长, 那么拷贝开销就会很大)。
二、作为函数的返回值
在 java 中支持返回一个数组,类似于C语言中返回数组名一样,如下所示:
public static int[] CreateArr() {
int[] arr = new int[10];
return arr;
}
public static void main(String[] args) {
int[] Newarr = CreateArr();
System.out.println(Arrays.toString(Newarr));
}
// 运行结果
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0]三、数组拷贝
我们先来看下列的代码,看看这是不是拷贝:
public static void main(String[] args) {
int[] arr = new int[10];
int[] newarr = arr;
arr[0] = 1;
System.out.println(Arrays.toString(arr));
System.out.println(Arrays.toString(newarr));
}
//运行结果
[1, 0, 0, 0, 0, 0, 0, 0, 0, 0]
[1, 0, 0, 0, 0, 0, 0, 0, 0, 0]很显然这不是我们想的拷贝对吧,arr 和 newarr 指向了同一块空间,这是引用,下面才是真正的拷贝方法!
① 遍历 arr 逐个给 newarr 赋值
这种方法比较麻烦!
public static void main(String[] args) {
int[] arr = new int[]{2,4,6,7,8};
int[] newarr = new int[arr.length];
// 遍历arr,逐个赋值给newarr
for(int i = 0; i < arr.length; ++i) {
newarr[i] = arr[i];
}
arr[0] = 100;
System.out.println(Arrays.toString(arr));
System.out.println(Arrays.toString(newarr));
}
//运行结果
[100, 4, 6, 7, 8]
[2, 4, 6, 7, 8]② 使用 Arrays 包中 copyOf 方法
public static void main(String[] args) {
int[] arr = new int[]{2,4,6,7,8};
// 使用copyOf方法进行拷贝
int[] newarr = Arrays.copyOf(arr, arr.length);
arr[0] = 100;
System.out.println(Arrays.toString(arr));
System.out.println(Arrays.toString(newarr));
}
//运行结果
[100, 4, 6, 7, 8]
[2, 4, 6, 7, 8]③ 使用 copyOf 方法中调用的 arraycopy 方法

这个方法在 JDK 中是看不到源码的,因为 arraycopy 被 native 关键字修饰,说明是用 C/C++ 写的,我们只能去调用!

public static void main(String[] args) {
int[] array = {1,3,5,7,91,11,22,44,88,18,29,17,14};
int[] copy = new int[array.length];
//局部的拷贝
System.arraycopy(array,0,copy,0,array.length);
System.out.println(Arrays.toString(array));
System.out.println(Arrays.toString(copy));
}
//运行结果
[1, 3, 5, 7, 91, 11, 22, 44, 88, 18, 29, 17, 14]
[1, 3, 5, 7, 91, 11, 22, 44, 88, 18, 29, 17, 14]④ 使用 Arrays 包中 copyOfRange 方法
public static void main(String[] args) {
int[] array = {1,3,5,7,91,11,22,44,88,18,29,17,14};
// copyOfRange可以控制拷贝的范围
int[] copy = Arrays.copyOfRange(array, 2, 5); //[2,5)
System.out.println(Arrays.toString(array));
System.out.println(Arrays.toString(copy));
}
//运行结果
[1, 3, 5, 7, 91, 11, 22, 44, 88, 18, 29, 17, 14]
[5, 7, 91]⑤ 使用 Object 类中的 clone 方法
Object 是 Java 类库中的一个特殊类,也是所有类的父类。也就是说,Java 允许把任何类型的对象赋给 Object 类型的变量,并且当一个类被定义后,如果没有指定继承的父类,那么默认父类就是 Object 类。
其中 Object 类位于 java.lang 包中,编译时会自动导入。
public static void main(String[] args) {
int[] array = {1,3,5,7,91,11,22,44,88,18,29,17,14};
// 使用clone方法产生副本
int[] copy = array.clone();
array[0] = 100;
System.out.println(Arrays.toString(array));
System.out.println(Arrays.toString(copy));
}
//运行结果
[100, 3, 5, 7, 91, 11, 22, 44, 88, 18, 29, 17, 14]
[1, 3, 5, 7, 91, 11, 22, 44, 88, 18, 29, 17, 14]四、排序 + 二分查找
我们可以调用 Arrays.sort() 进行排序以及 Arrays.binarySearch() 函数进行二分查找,如下所示:
public static void main(String[] args) {
int[] array = {1,3,5,7,91,11,22,44,88,18,29,17,14};
// 排序
Arrays.sort(array);
System.out.println(Arrays.toString(array));
// 二分查找,找到返回下标,没找到返回-(left+1)
System.out.println(Arrays.binarySearch(array, 14));
System.out.println(Arrays.binarySearch(array, 188));
}
//运行结果
[1, 3, 5, 7, 11, 14, 17, 18, 22, 29, 44, 88, 91]
5
-14五、填充数组元素
我们可以调用 Arrays.fill() 函数进行数组区间的元素填充,如下所示:
public static void main(String[] args) {
int[] array1 = new int[10];
// 填充下标2到5的元素
Arrays.fill(array1,2,5,-1);
System.out.println(Arrays.toString(array1));
}
//运行结果
[0, 0, -1, -1, -1, 0, 0, 0, 0, 0]六、数组比较
我们可以调用 Arrays.equals() 函数进行数组之间的比较,如果元素都相同才会返回 true,否则返回 false,如下所示:
public static void main(String[] args) {
int[] array1 = {1,3,5,7,91,11,22,44,88,18,29,17,14};
int[] array2 = {1,3,5,7,91,11,22,44,88,18,29,17,14};
System.out.println(Arrays.equals(array1, array2));
int[] array3 = {8,29,17,14};
System.out.println(Arrays.equals(array1, array3));
}
//运行结果
true
falseⅣ. 二维数组
一、基本语法
二维数组本质上也就是一维数组,只不过每个元素又是一个一维数组,其语法如下所示:
数据类型[][] 数组名称 = new 数据类型 [行数][列数] { 初始化数据 };
举个例子:
int[][] arr1 = new int[2][3]; // ✅正确
int[][] arr2 = new int[][]{1,2,3,4,5,6}; // ❌错误,初始化中要用花括号指明,如arr3
int[][] arr3 = new int[][]{{1,2,3}, {4,5,6}}; // ✅正确
int[][] arr4 = {{1,2,3}, {4,5,6}}; // ✅正确
int[][] arr5 = {{1,2}, {3,4,5}}; // ✅正确,也可以个数不同注意事项:
- 在
java中如果要初始化数据,一定要用{}将每行的数据括起来,而不能直接写数字,并且不能写行数和列数。 - 若没有初始化,那么数组中默认放的是就是类型的默认值。
二、二维数组的遍历
public static void main(String[] args) {
int[][] arr = {{1,2,3},{4,5,6}};
// 遍历方法1
for(int i = 0; i < arr.length; ++i) {
for(int j = 0; j < arr[i].length; ++j) {
System.out.print(arr[i][j] + " ");
}
System.out.println();
}
// 遍历方法2:使用deepToString方法
System.out.println(Arrays.deepToString(arr));
// 遍历方法3:范围for
for(int[] i : arr) {
for(int j : i) {
System.out.print(j + " ");
}
System.out.println();
}
}
// 运行结果
1 2 3
4 5 6
[[1, 2, 3], [4, 5, 6]]
1 2 3
4 5 6 问题:为什么不能直接用 toString() 打印二维数组呢❓❓❓
这是因为二维数组其实就是存放了多个一维数组的地址,那么每取一个二维数组的元素,其实拿到的是一维数组的地址,所以直接 toString(arr) 拿到的是每个一维数组元素的地址,如果想拿到一维数组的元素,则要访问一维数组的地址才可以 toString(arr[0]) ,比如下面的代码:
System.out.println(Arrays.toString(arr));
System.out.println(Arrays.toString(arr[0]));
System.out.println(Arrays.toString(arr[1]));
// 运行结果
[[I@1b6d3586, [I@4554617c]
[1, 2, 3]
[4, 5, 6]三、不规则数组
不规则数组其实是为了让每一列的个数不一样而产生的,其实就是把列数省略了,举个例子如下所示:
int[][] arr = new int[2][];当我们不去初始化的时候,它们的默认值是 null:
public static void main(String[] args) {
int[][] arr = new int[2][];
System.out.println(arr[0]);
System.out.println(arr[1]);
}
// 运行结果
null
null所以不规则数组在没有初始化之前不能遍历其元素,因为根本没有元素,编译器是会抛异常的~
接下来我们去指定它每一行的列数:
public static void main(String[] args) {
int[][] arr = new int[2][];
// 指定列数
arr[0] = new int[3];
arr[1] = new int[4];
System.out.println(Arrays.deepToString(arr));
}
// 运行结果
[[0, 0, 0], [0, 0, 0, 0]]原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号