MySQL 8.4 升级踩坑实录:从 EOL 焦虑到官方 Bug,这份避坑指南请收好

MySQL 8.4 升级踩坑实录:从 EOL 焦虑到官方 Bug,这份避坑指南请收好

俊才
发布于 2026-03-06 10:44:45
发布于 2026-03-06 10:44:45
收到一名粉丝兄弟私信:mysql8.4不稳定,报错SQLSTATE(08S01), ErrorCode(1160)?
结合粉丝真实生产案例、MySQL官方Bug库验证结果,本次升级MySQL8.4后出现的SQL STATE(08601)、ErrorCode(1160)报错问题,并非单一原因导致,而是8.4.x服务端通信层缺陷+ 8.4.0驱动官方确认Bug+多端超时配置冲突三者叠加的结果,以下为完整的来龙去脉、官方验证及解决方案(解决方案也需要在后续实践中逐步完善。大家在升级时遇到哪些问题,也请留言分享,让更多的小伙伴避坑)。
一、事件综述
1. 升级背景
MySQL 8.0即将在2026年4月迎来官方EOL(生命周期终止),官方停止安全补丁和技术支持,为规避安全漏洞与合规审计风险,粉丝团队将生产环境从MySQL8.0.20+JDBC8.0.20升级至官方推荐的下一代LTS版本MySQL 8.4.x+JDBC8.4.0。
2. 问题爆发
升级后生产环境立即出现稳定性问题,核心报错为
java.sql.SQLNonTransientConnectionException: Got an error writing communication packets
对应错误码SQLSTATE(08S01)、ErrorCode(1160),具备明显特征:
- 非必现,并发量 / 访问人数越高,报错频率越高
- 应用端HikariCP连接池标记连接为broken,数据库连接工具也触发相同报错
- 调整连接池、MySQL超时参数后,问题无任何改善
3. 多轮实测:排除单一驱动 / 服务端版本问题
为定位根源,兄弟团队进行了多组对照测试,结果显示:
- 更换服务端版本:8.4.0→8.4.5→8.4.8,报错未消失,8.4.5后报错频率更高
- 旧驱动+新服务端:保持JDBC8.0.20不变,仅升级服务端至8.4.8,问题立即出现
- 新驱动+新服务端:JDBC8.4.0搭配 MySQL8.4.X,报错依然存在
- 全量回退:恢复至MySQL8.0.45+JDBC8.0.45,无需调整任何配置,报错彻底消失
二、官方Bug库验证:mysql-connector-j 8.4.0驱动缺陷
通过MySQL官方Bug库(https://bugs.mysql.com/bug.php?id=115736)可明确验证,mysql-connector-j8.4.0版本存在官方确认的驱动侧Bug
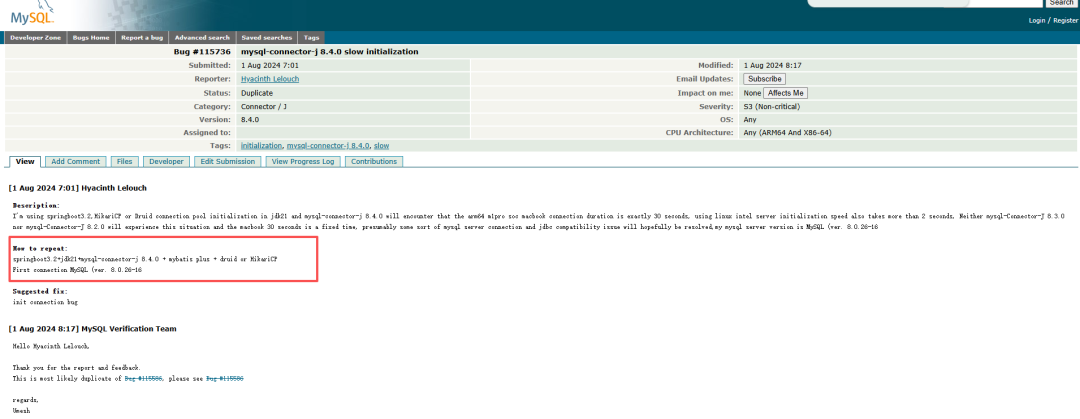
具体信息如下:
1. Bug 核心信息
- 归属模块:Connector / J(即MySQL JDBC驱动),确认为驱动本身问题
- 表现症状:驱动初始化速度极慢,ARM64架构下连接初始化耗时固定30秒,Linux Intel服务器也超2秒
- 影响环境:SpringBoot3.2+JDK21+HikariCP/Druid 连接池(与当前案例生产环境高度匹配)
- 官方状态:标记为Duplicate(重复Bug,对应#115586),确认为未修复的驱动缺陷,严重等级S3(非关键,但会影响连接稳定性)
2. 与案例问题的关联
该官方驱动Bug虽直接表现为初始化慢,但会导致连接池与MySQL服务端的通信握手异常,在高并发场景下,会与服务端的通信层问题叠加,大幅放大通信包写入错误的发生概率,是粉丝问题的重要诱因。
三、最终根因:三重问题叠加,高并发下集中爆发
结合实测结果、MySQL官方Bug库验证,本次报错的核心原因可归纳为一主两次,三者叠加导致问题在生产环境集中爆发:
1. 主因:MySQL8.4.x服务端存在通信层未修复缺陷
粉丝多轮测试已彻底验证:无论搭配哪个版本的JDBC驱动(8.0.20/8.4.0),只要服务端为MySQL8.4.x系列,就会触发通信包写入错误。
该缺陷存在于服务端TCP通信包的写入 / 解析底层逻辑中,高并发下会随机导致通信链路中断,且 8.4.0/8.4.5/8.4.8 等多个早期子版本均受影响,官方暂未发布修复版本。
2. 次因1:mysql-connector-j8.4.0驱动官方确认的缺陷
根据Bug#115736,8.4.0驱动本身存在初始化慢、通信握手异常的问题,该驱动侧缺陷虽非报错主因,但会加剧连接池与服务端的通信不稳定性,在高并发下与服务端缺陷形成 “叠加效应”,让报错频率大幅提升。
3. 次因2:TCP/MySQL/ 连接池超时配置联动冲突
粉丝原有配置中,各组件超时时间未统一规划,形成 “下层超时小于上层” 的不合理配置,加速了连接异常:
- 系统TCP保活总检测时间:tcp_keepalive_time(60s)+tcp_keepalive_intvl(10s)×tcp_keepalive_probes(3)=90s;
- MySQL 网络超时:net_read_timeout/net_write_timeout仅为60s,小于TCP保活检测时间。
该配置导致MySQL在TCP完成连接有效性检测前,就主动关闭连接,而HikariCP连接池仍认为连接有效,继续使用时直接触发通信包写入错误。
补充:粉丝已将max_allowed_packet设为256M,排除了通信包大小超限的常见诱因;HikariCP基础配置无明显错误,问题不在连接池本身。
四、分场景处理建议:兼顾生产稳定与EOL合规
结合问题根因、案例实测结果及MySQL官方现状,按业务重要性分3个场景给出处理建议,优先级从高到低,核心原则为核心业务保稳定,非核心业务做过渡,长期等官方修复(如果大家想用在非核心业务且并发不高的系统上,可以使用MySQL8.4,可以提前积累运维及使用经验):
场景1:核心业务
- 目标:立即恢复生产稳定性,同时规避MySQL8.0 EOL风险
- 方案:全量回退至MySQL8.0.45+JDBC8.0.45,并通过第三方获取EOL延伸支持
- 操作步骤:直接将服务端和驱动版本同步回退,无需调整任何配置,即可彻底解决报错问题;
- EOL 风险规避:8.0.45作为8.0系列当前最后一个稳定版之一,可通过Percona、MariaDB等第三方厂商获取3年延伸支持,官方级安全补丁、Bug修复持续更新,为升级8.4稳定版争取1-3个月缓冲时间。
场景2:非核心 / 测试业务(临时过渡,无法回退时使用)
- 目标:在保留MySQL8.4.x服务端的前提下,大幅降低报错频率
- 方案:驱动降级+统一超时配置+连接池优化,利用8.0.x稳定驱动规避官方驱动Bug,同时消除配置冲突
步骤1:降级JDBC驱动,避开8.4.0官方缺陷
将mysql-connector-j从8.4.0降级至8.0.45(与粉丝回退的稳定版本一致),该版本无官方已知Bug,且可兼容MySQL8.4.x基础通信协议,是缓解问题的核心步骤。
<!-- Maven依赖示例,Gradle同理 -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.45</version>
</dependency>步骤2:调整MySQL配置,统一超时时间
修改my.cnf/my.ini,重启MySQL生效,核心让MySQL网络超时大于TCP保活检测时间(90s):
[mysqld]
# 调大网络读写超时,消除配置冲突
net_write_timeout = 120
net_read_timeout = 120
# 保持原有空闲超时配置,无需修改
wait_timeout = 1800
interactive_timeout = 1800
# 跳过DNS解析,减少高并发连接耗时
skip-name-resolve
# 原有最优配置,保留
max_allowed_packet = 268435456步骤3:微调HikariCP配置,强化连接异常检测
在原有配置基础上微调,让连接池更积极地检测、淘汰异常连接,适配8.4.x服务端特性:
spring:
datasource:
db1:
maximum-pool-size: 30 # 保持不变
minimum-idle: 3 # 保持不变
connection-test-query: SELECT 1 # 保持不变
max-lifetime: 1200000 # 调小,小于MySQL wait_timeout(1800000ms)
connection-timeout: 60000 # 保持不变
validation-timeout: 5000 # 保持不变
idle-timeout: 600000 # 保持不变
keepalive-time: 180000 # 调短,每3分钟检测一次连接
jdbcUrl: jdbc:mysql://10.0.99.13:3306/numen_auth?useUnicode=true&characterEncoding=utf8&zeroDateTimeBehavior=convertToNull&useSSL=false&serverTimezone=Asia/Shanghai&allowPublicKeyRetrieval=true&allowMultiQueries=true&tcpKeepAlive=true&socketTimeout=300000 # 调大socketTimeout,匹配MySQL超时步骤4:系统TCP参数补充(原有配置已调优,仅开启保活)
TCP保活配置为生产环境最优,无需修改,仅需确保系统开启TCP保活:
# 临时生效
echo 1 > /proc/sys/net/ipv4/tcp_keepalive_on
# 永久生效,修改/etc/sysctl.conf
net.ipv4.tcp_keepalive_on = 1
# 配置生效
sysctl -p场景3:长期规划(解决EOL+报错问题)
- 目标:完成合规升级,彻底解决8.4.x版本稳定性问题
- 方案:等待官方双端修复版,或选择第三方优化发行版
- 关注官方修复动态:持续监控MySQL官方Bug库,同时确认服务端8.4.x通信层缺陷和驱动8.4.x初始化缺陷均被修复后,再升级至8.4稳定版,升级时严格遵循服务端版本 = 驱动版本
- 选择第三方优化版:可以优先使用Percona Server for MySQL8.4,该版本基于MySQL官方8.4LTS版本优化,经过额外生产环境测试,修复了部分官方未解决的适配问题,稳定性远优于官方原版,且提供完善的技术支持
- 升级前必做:全量备份生产数据,8.4与8.0语法基本兼容,但需提前检查弃用特性(如原生密码认证),避免业务代码异常
五、总结
结合本次踩坑经历、MySQL官方Bug库验证结果,总结出数据库版本升级的核心避坑原则,尤其适用于EOL升级场景:
- 稳定性优先于新特性:数据库作为业务核心中间件,生产环境优先选择经过充分生产验证的稳定版,而非官方最新版,8.4.x作为新一代LTS版本,需避开早期子版本
- 升级前必查官方Bug库:重点核查服务端、驱动的已知未修复缺陷,本次 8.4.0 驱动的 Bug 在官方库已有明确记录,提前核查可避免踩坑
- 版本一致性原则:MySQL服务端与JDBC驱动版本需严格匹配,若需跨版本适配,优先选择 8.0.x 稳定驱动,避开新版驱动的未知缺陷
- 超时配置统一规划:TCP、MySQL、连接池的超时时间需遵循上层超时时间大于下层的原则,避免连接被提前关闭导致的通信异常
- EOL升级留缓冲:若新版存在稳定性问题,不要硬扛旧版EOL风险,通过Percona等第三方获取延伸支持,为新版修复争取时间,核心业务绝不冒进
本文只是MySQL升级踩坑案例的冰山一角,解决方案也需要在后续实践中逐步完善。大家在升级时遇到哪些问题,也请留言分享,让更多的小伙伴避坑。
关注微信公众号「数据库干货铺」,获取更多数据库运维干货。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-03-05,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号