CVPR 2026|复旦大学提出OmniLottie:首个端到端多模态矢量动画生成框架!

CVPR 2026|复旦大学提出OmniLottie:首个端到端多模态矢量动画生成框架!

AI生成未来
发布于 2026-03-05 15:08:10
发布于 2026-03-05 15:08:10

作者单位:复旦大学、阶跃星辰、HKU MMLab, University of Queensland
论文地址:https://arxiv.org/pdf/2603.02138 项目主页:https://openvglab.github.io/OmniLottie/ HuggingFace权重:https://huggingface.co/OmniLottie/OmniLottie 代码地址:https://github.com/OpenVGLab/OmniLottie 数据集地址 :https://huggingface.co/datasets/OmniLottie/MMLottie-2M Benchmark地址:https://huggingface.co/datasets/OmniLottie/MMLottieBench Huggingface在线demo地址:https://huggingface.co/spaces/OmniLottie/OmniLottie
亮点直击
- OmniLottie,这是第一个能够直接从多模态指令生成矢量动画的端到端框架。
- 构建了 MMLottie-2M,这是一个大规模的 Lottie 动画多模态数据集,并将公开发布以促进未来的研究。
- 提出了一种新颖的 Lottie 分词器,可将原始 JSON 转换为简洁的指令序列,从而提高训练效率和生成质量。
- 大量评估表明,OmniLottie 能够生成高质量的矢量动画,并在视觉保真度和语义对齐方面达到当前最优性能。
研究背景
当前的动画生成主要聚焦于像素级视频,虽然视觉效果逼真,但存在三大局限:
- 文件体积大,不适合网络传输
- 无法无损缩放,分辨率受限
- 难以编辑,无法提取结构化信息
Lottie作为Airbnb开源的矢量动画格式,天然解决了这些问题。但如何让AI直接生成Lottie,一直是未解决的难题。
OmniLottie
OmniLottie包含一个精心设计的Lottie分词器(tokenizer),用于将Lottie JSON文件编码/解码为紧凑的离散token序列;以及一个经过充分训练的VLM(视觉语言模型),能够处理图像、视频和文本作为交错的多模态指令,用于自回归地生成Lottie。生成的Lottie token随后被反分词(detokenized)为Lottie JSON格式,从而实现矢量动画的生成,如图3所示。
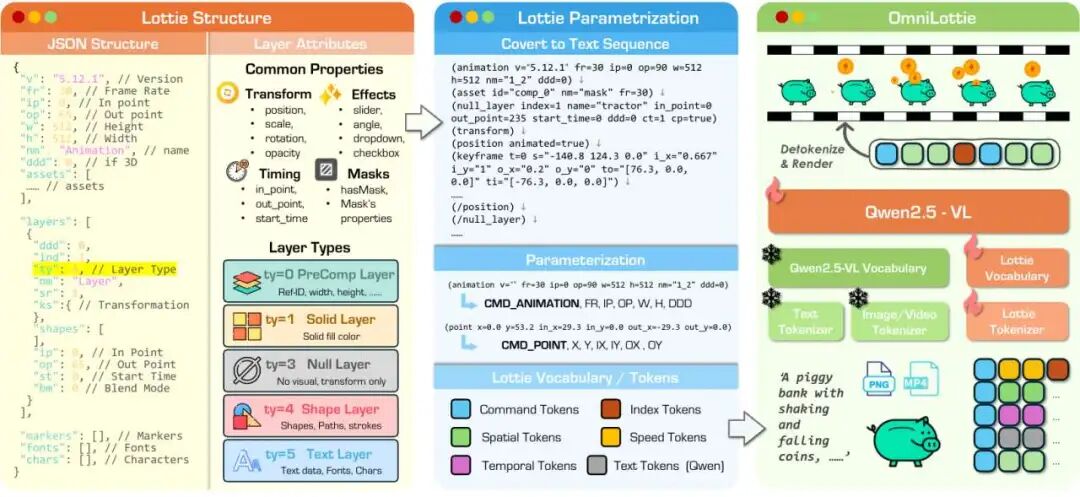
OmniLottie模型框架
OmniLottie模型框架
预备知识:Lottie图层属性
Lottie图层属性可以分为以下三类:
基础图层属性(Base layer properties) 捕获基本的元数据,包括标识符(, )、图层类型 、索引与层级关系(, ),以及诸如 (3D)和 (隐藏)等标志位。时间属性(, , , )定义了每个图层在动画时间轴上的位置。
视觉图层属性(Visual layer properties) 控制外观和渲染行为,包括几何变换()、方向()、遮罩关系(, , )、掩码(, )、效果()、样式()、混合模式()和渲染标签(, )。其中, 标志位用于控制变换的折叠(transformation collapsing)。
特定图层属性(Specific layer properties) 取决于图层类型:形状图层包含 ; 用于链接预合成(precomp)、图像、音频和数据资产;尺寸(, )用于预合成裁剪或纯色图层的大小设置; 用于时间重映射; 用于文本内容;纯色图层参数(, , )定义宽度、高度和颜色。
OmniLottie模型
Lottie结构(Lottie Structure)。 当代的VLM能够直接生成JSON,但直接生成完整的Lottie JSON对于矢量动画合成来说效率低下。该格式包含大量基本不变的结构化元数据,导致模型将容量浪费在重现格式化token上,而不是学习与动画相关的先验知识。这种冗余增加了序列长度,并分散了模型对形状、效果和时间动态等语义重要元素的注意力。
为了缓解这一问题,本文将Lottie表示重组为一组核心属性(v, fr, ip, op, w, h, nm, ddd, layers)和条件属性(assets, markers, fonts, chars),后者仅在特定图层类型需要时出现。缺失的条件字段被赋予空值,从而产生更简洁、更结构化的Lottie表示。
Lottie分词器(Lottie Tokenizer) 将Lottie动画抽象为动画命令和控制参数的紧凑序列,在去除冗余元数据的同时保留了完整的生成灵活性。该分词器支持五种基本图层类型,每种类型由唯一的类型参数标识:预合成(ty=0)、纯色(ty=1)、空对象(ty=3)、形状(ty=4)和文本(ty=5)。每种图层类型都需要特定的解析策略,以保持结构完整性和时间准确性。
基于每种图层类型的不同属性,Lottie分词器将输入的JSON封装为基础属性(包括v, ip, op, h, w, nm, ddd)和对应于不同图层属性分类的五类Python对象。本工作将Lottie动画形式化为一个结构化的层级关系:
其中 表示基础元数据, 表示单个图层。每个图层由其类型 和属性信息 参数化:
其中 和 分别表示变换(transformations)和效果(effects)。
因此,Lottie分词器通过父子关系重建了完整的场景层级,生成了一种树状结构表示,实现了对JSON格式的无损压缩。这种参数化表示为生成紧凑且语义丰富的token序列奠定了基础。
该转换过程系统地遍历每个Lottie图层,将公共属性及其后的特定类型属性序列化为连续的token。通过忽略底层的JSON格式,模型能够将注意力集中在核心生成内容上。Lottie分词器将这一过程形式化(见算法1),首先解析元数据,然后结合图层的类型和属性处理每个图层。如图3所示,基本属性被序列化为 animation v="...",空图层也以类似方式编码,从而产生了一种适合VLM高效处理的结构化、分层文本表示。
为了使预训练的VLM适应Lottie生成任务,本文使用基于偏移量(offset-based)的方案将Lottie的层级结构映射到统一的离散词表(vocabulary)中。为不同的参数类型(时间、空间、变换和样式)分配了不同的范围,在避免token冲突的同时保持了语义的连贯性。
本工作提出的基于偏移量的分词方法将连续的Lottie参数映射为离散的token:
其中 是参数值, 是参数类型, 是针对特定类型的缩放因子, 是词表偏移量。完整的离散token表示为:
模型架构(Model architecture)。 基于通过偏移量分词方案生成的token序列 ,本文训练模型以学习在这个离散词表空间中表示的Lottie动画的潜在分布。为了处理交错的多模态指令,本工作采用预训练的VLM,具体为Qwen2.5-VL,作为OmniLottie的骨干网络(backbone)。本文向模型中引入了一组额外随机初始化的Lottie词表嵌入(embeddings),以表示Lottie分词器生成的命令和参数结构。由于Qwen2.5-VL骨干网络已经在多样化的VLM任务上进行了广泛的预训练,能够基于交错的视频、图像和文本指令生成简洁的响应,因此这些预训练权重为生成遵循多模态指令的Lottie文件提供了有效的初始化。
训练目标(Training Objective)。 类似于LLM的训练,本文训练OmniLottie以自回归的方式生成新的Lottie token 。该生成过程以所有先前的token 以及提供的多模态指令 为条件,并使用标准的交叉熵损失函数进行优化:
OmniLottie能做什么?
- 输入单一文本生成Lottie动画
- 图像+文本生成Lottie动画
- 视频重建成Lottie动画
支持文本/文本+图像/视频多模态输入,生成对应的无损矢量Lottie动画格式。
OmniLottie生成流程
OmniLottie生成过程及效果展示



OmniLottie 开启了 Lottie 动画生成的新范式,是首个支持从文本、图像、视频多模态指令端到端生成复杂动画的系列模型。为了解决 Lottie 文件原生 JSON 格式过于冗长的问题,我们研发了高效表征的 Lottie Tokenizer。该方案利用精妙的参数化建模,实现了 10 倍的数据压缩比,在显著降低模型计算负担的同时,确保了动画表征的零损耗与完整表达能力。
OmniLottie团队还开源了 MMLottie-2M。作为目前业界规模最大的 200 万量级多模态矢量动画数据集,它填补了该领域高质量训练数据的空白。通过建立统一的数据格式与评估标准,该数据集极大地推动了矢量动画生成领域的标准化进程,为社区后续研究提供了坚实的底层支撑。
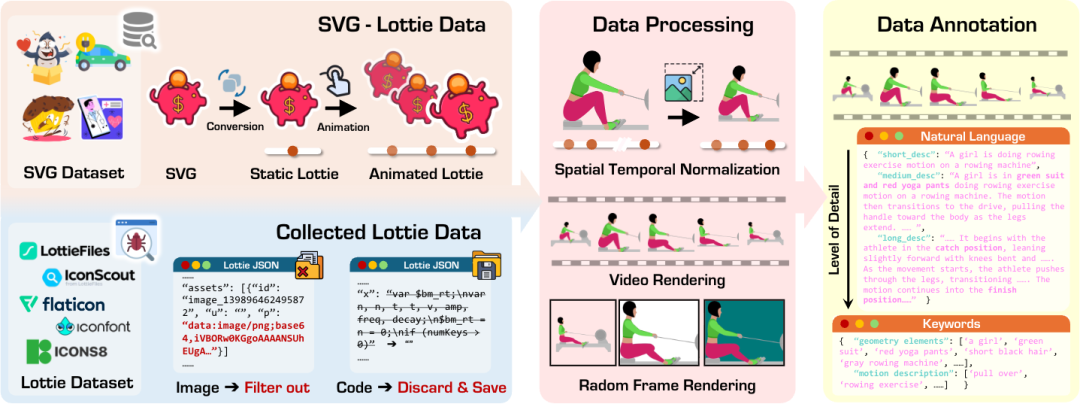
MMLottie-2M数据集的构建过程

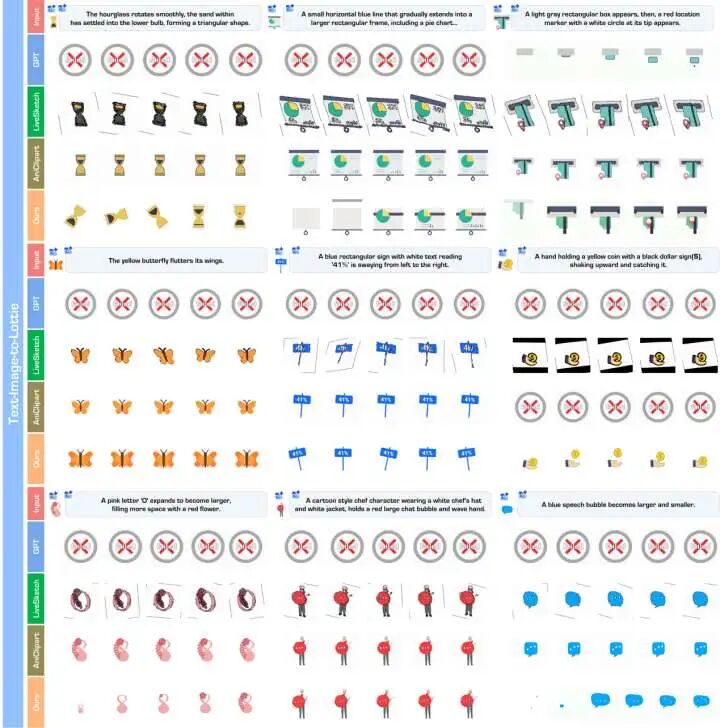
总结
综上所述,OmniLottie 实现了矢量动画生成领域的范式飞跃:在技术架构上,验证了“高效参数化表征 + 多模态 VLM”是攻克复杂矢量格式生成难题的高效路径;在数据生态上,MMLottie-2M 为后续研究提供了前所未有的海量资源支撑;在实际应用上,得益于远超现有模型的生成可靠性,它成功推动了 AI 动画生成从受限的“实验性探索”迈向成熟的“专业级生产力工具”。
同时,我们始终保持着清醒的行业认知: 尽管 OmniLottie 实现了质的飞跃,但当前系统仍非止境,在面对极端复杂的交互场景时,仍需进一步的技术攻坚以填补最后的一丝精度缺口。我们认为,在现阶段,人机协同的创作模式或许比纯粹的无人干预自动化更具现实意义。
然而,正如互联网与智能手机等颠覆性技术的演进历程,初代产品的局限性从未能阻挡其最终重塑世界的步伐。 我们坚信,OmniLottie 所开启的这一技术范式,已然点燃了矢量动画智能创作的火炬,终将照亮由 AI 驱动的创意设计未来。
参考文献
[1] OmniLottie: Generating Vector Animations via Parameterized Lottie Tokens
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-03-04,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号