好莱坞导演坐不住了!SkyReels-V4发布:首个影院级音视频联合生成/修复/编辑统一框架

好莱坞导演坐不住了!SkyReels-V4发布:首个影院级音视频联合生成/修复/编辑统一框架

AI生成未来
发布于 2026-03-05 14:58:27
发布于 2026-03-05 14:58:27

- 论文链接:https://arxiv.org/abs/2602.21818
亮点直击
- 多模态音视频基础模型:SkyReels-V4,一个基于双流MMDiT的基础模型,能够在多模态指令和参考输入的引导下,联合生成视频和音频。
- 统一的通道拼接修复框架:在单一架构内无缝实现了图生视频、视频扩展、视频编辑以及基于视觉参考的视频修复任务。
- 设计高效的联合生成方案:将低分辨率全序列生成与高分辨率关键帧生成相结合,并配合超分辨率和插帧技术。使得生成 1080p、32 FPS、时长 15 秒且带有同步音频的多镜头视频变得可行。
- 树立多模态视频模型新标杆:是首个在电影级画质和生成速度下,将多模态输入、视音频联合生成以及生成/修复/编辑任务完美统一的模型,为多模态视频基础模型设定了新的基准。
效果一览









解决的问题
- 视音频分离与架构碎片化:现有的视频生成模型要么仅支持视觉生成(缺乏原生音频合成),要么通过外挂轻量级适配器实现音频驱动,导致视音频对齐效果差、口型不匹配。
- 多模态控制与编辑的割裂:当前的先进模型通常无法在同一个底层架构中完美兼容文本、图像、视频、掩码(Mask)及音频参考等多种条件输入,往往无法将生成与复杂的编辑/修复任务统一起来。
- 高分辨率长视频的计算瓶颈:使用基于扩散的架构生成 1080p、长达 15 秒的连续多镜头视频时,单纯的扩展(Scaling)会导致难以承受的显存和时间成本。
提出的方案
- 双流 MMDiT 架构与共享的 MLLM:视频分支与音频分支相互独立但通过注意力机制交互,同时共享一个强大的多模态大语言模型(MLLM)作为文本编码器,用以理解复杂的多模态指令。
- 统一的通道拼接修复框架:将图生视频(I2V)、视频扩展、视频编辑等多种任务视为特殊的“修复(Inpainting)”任务,通过在输入潜变量通道上拼接掩码和条件特征来实现统一处理。
- 高效的联合生成策略:模型首先联合生成“低分辨率的完整序列”和“高分辨率的关键帧”,随后交由专门的超分辨率与插帧模块(Refiner)进行重建,从而大幅降低高分辨率长视频的计算代价。
应用的技术
- 双流与单流混合的 MMDiT(Hybrid MMDiT Blocks):前期使用双流结构保留模态特性,后期使用单流结构提升计算效率。
- 双向视音频交叉注意力(Bidirectional Audio-Video Cross-Attention):实现精准的时空级视音频同步。
- 基于 3D RoPE 的时间位置解耦(Offset 3D RoPE):赋予参考条件负时间索引,使模型能够区分上下文条件帧与生成目标帧。
- 多模态上下文学习(In-Context Visual/Audio Conditioning):通过自注意力机制直接将参考图像/视频/音频注入生成过程。
- 视频稀疏注意力(Video Sparse Attention, VSA):在超分和插帧阶段应用,大幅降低高分辨率长视频带来的二次方计算复杂度。
达到的效果
SkyReels-V4 能够生成最高达 1080p、32 FPS、15 秒的带同步音频的电影级多镜头视频。在 Artificial Analysis 的文本到视频(带音频)竞技场盲测中排名第三。在综合人工评估基准(SkyReels-VABench)中,该模型在指令遵循、运动质量以及整体视觉和视音频同步表现上,均优于 Veo 3.1、Kling 2.6/3.0、Seedance 1.5 Pro 和 Wan 2.6 等当前一流的商用及开源系统。
模型设计
本文提出了 SkyReels-V4,这是一个用于视音频联合生成、修复和编辑的统一多模态视频基础模型。该模型采用带有丰富多模态指令遵循能力的双流 MMDiT 架构,无缝集成了文本、图像、视频、掩码和音频条件信号,同时在电影级分辨率和时长下保持了极高的计算效率。模型架构的概览如图 1 所示。
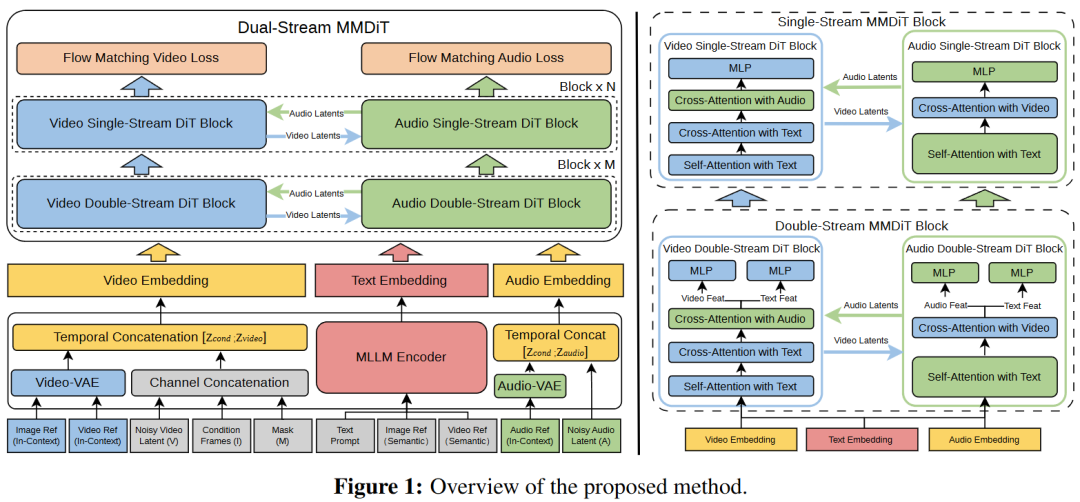
用于视音频联合生成的双流 MMDiT 架构
本工作的架构采用了一种对称的双骨干设计,包含平行的视频和音频分支,两者均构建于相同的多模态扩散 Transformer(MMDiT)框架之上。视频分支由预训练的文本到视频模型初始化,而音频分支则根据相匹配的架构规范从头开始训练。
混合双流与单流 MMDiT 模块。沿用 MMDiT 设计,每个 Transformer 模块通过混合架构处理视频(或音频)与文本模态,在模态对齐与参数效率之间取得平衡。最初的 层采用了双流设计,其中视频/音频与文本 Token 保留了各自独立的自适应层归一化、QKV 投影和 MLP 参数,但在联合自注意力计算中进行交互:
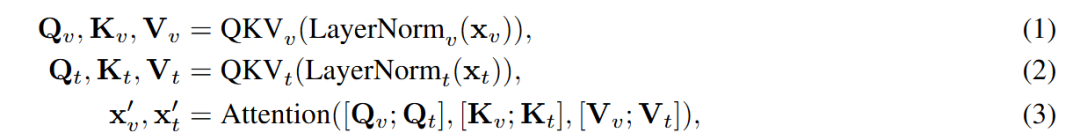
其中 和 分别表示视频/音频和文本的 Token 嵌入, 表示拼接。这种设计有助于在早期层中实现强大的跨模态对齐。随后的 层过渡到单流架构,使用共享参数处理拼接后的视频(或音频)与文本 Token,以最大化计算效率。这种混合策略相比纯粹的单流或双流方法能实现更快的收敛。
通过交叉注意力强化文本条件。为了解决单流阶段潜在的文本特征语义稀释问题,本工作在自注意力层之后立即增加了一个额外的文本交叉注意力层来增强视频模块:
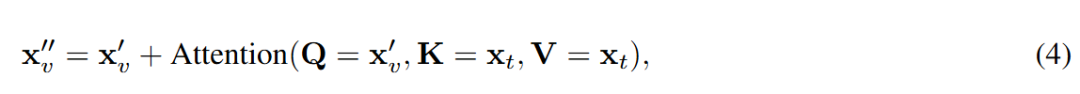
其中视频流会查询文本嵌入,在整个生成过程中强化文本的引导作用。这种交叉注意力机制对于在模型后期阶段保持细粒度的语义控制至关重要。
双向音频-视频交叉注意力。为了实现模态间的时间同步,每个 Transformer 模块均包含成对的交叉注意力层:音频流对视频特征进行注意力计算,同时视频流也互惠地对音频特征进行注意力计算。这种双向机制在整个网络深度中交换同步线索:
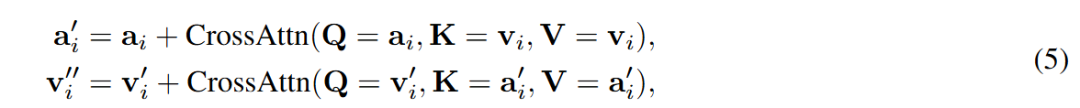
其中 和 分别是第 层的音频和视频特征。架构的对称性确保了两种模态共享相同的潜在维度,消除了对中间投影层的需求,并保留了从单模态预训练中继承的注意力结构。
通过 RoPE 缩放实现时间对齐。尽管架构是对称的,但两种模态的时间分辨率存在差异:视频潜变量跨越 帧,而音频潜变量包含 个 Token()。为了对齐这些时间尺度,本工作对两种模态均应用了旋转位置编码(RoPE),并通过缩放因子 对音频 RoPE 的频率进行缩放,以匹配视频较粗糙的时间分辨率。这确保了音频和视频 Token 在互相关注时能保持时间上的一致性。
共享的多模态文本编码器。本工作通过应用单一的冻结 MLLM 文本编码器来简化提示(Prompt)条件注入。该编码器处理结合了视觉和声音描述的联合提示词,生成的多模态嵌入分别通过自注意力和交叉注意力被音频和视频分支独立消费。这种统一的语义上下文改善了跨模态对齐,同时简化了训练与推理,并极其关键地使模型能够处理包括文本、图像、视频片段和音频参考在内的多模态指令。
训练目标。本工作采用流匹配(Flow Matching)框架进行训练。给定视频潜变量 和音频潜变量 ,随机采样时间步 ,并构造加噪潜变量 与 ,其中 。模型预测将噪声推向真实数据的速度场 :
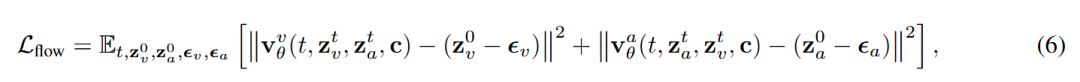
其中 表示条件信息(多模态嵌入和可选的时空掩码)。该联合训练目标鼓励两个分支在保持各自模态特性的同时学习同步生成。
通过通道拼接实现的统一视频修复
为了在单一框架内实现多样化的视频生成和编辑任务,本工作在视频分支采用了灵活的输入条件机制。视频 MMDiT 的输入由三个张量在通道维度拼接而成:

其中 是加噪的视频潜变量, 包含 VAE 编码后的条件帧(无条件帧则用黑色图像潜变量填充),而 是一个二值掩码,用于指定哪些时空区域是已知条件(值为 ),哪些是要生成的区域(值为 )。 这种形式通过不同的掩码配置统一了多种生成任务:
- 文本到视频 (T2V) :(生成所有帧)
- 图像到视频 (I2V) :,(以第一帧为条件)
- 视频扩展:,(以首 帧为条件)
- 首尾插帧:,其余为
- 视频编辑:对于保留区域 ,对于编辑区域为 (任意时空掩码)
这种统一的表示形式天然兼容固定的前景/背景掩码和动态的逐帧编辑掩码,实现了精确的空间和时间层面的修改控制。 关键在于,修复机制专属于视频流。在修复和编辑任务中,音频分支基于(部分被作为条件的或已被编辑的)视频内容从头生成音频,确保了声学特征与生成或修改后的视觉内容的一致性。这种设计允许音频自适应地响应视频的修改,同时通过双向交叉注意力机制维持时间同步。
用于视觉参考生成与编辑的多模态上下文学习
除了文本和修复掩码之外,本工作的框架还支持通过参考图像和视频片段进行丰富的多模态条件控制,实现了在多模态提示下的复杂视觉参考生成任务(如多 ID 视频生成和保持 ID 的视频编辑)。
基于 MLLM 的多模态指令遵循。参考的视觉内容(图像或视频帧)通过 MLLM 文本编码器与文本提示联合处理,提取出富含语义的多模态嵌入。MLLM 的指令遵循能力使得模型能够理解将视觉参考与文本描述相结合的复杂构图请求(例如,“根据参考 @image_1 生成人物 A 说话的视频hello, how are you?,采用人物 B 的风格 @video_1”)。这些多模态嵌入同时被视频和音频分支消费。
基于自注意力的上下文视觉控制。为了在语义引导之外提供显式的视觉参考信号,本工作将视觉参考直接注入到视频流的自注意力机制中。每一个参考图像或视频帧都通过 VAE 进行编码,补齐到统一的空间分辨率,并沿时间维度进行拼接。这些条件潜变量 在进入自注意力计算前,会被前置(Prepend)到加噪视频潜变量 之前:

拼接后的序列共同进行自注意力计算。这种上下文学习机制使模型在生成或编辑内容时,能够直接参考来自条件中的细粒度视觉模式(例如,特征身份、纹理细节、姿态变化等)。
通过偏移的 3D RoPE 消除时间位置歧义。为了将条件潜变量与加噪目标潜变量区分开来并组织多个参考视觉输入,本工作引入了带有时间索引偏移的 3D 旋转位置编码。条件潜变量会被分配负的时间索引,在生成的视频帧之前依次对每个参考视觉进行编码:
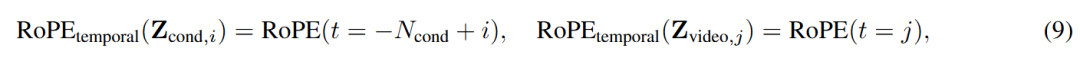
其中 是条件 Token 的总数, 分别是条件 Token 和视频 Token 的索引。空间索引在所有 Token 间保持不变,以确保注意力关系尊重空间和时间结构。这种基于偏移的位置编码在不引入特定任务架构修改的情况下,为区分条件上下文与生成目标提供了有效的归纳偏置(Inductive Bias),并自然地扩展到支持各种类型(图像、短片段等)的多个参考输入。
音频参考控制。与此类似,音频参考(例如,语音样本、音乐主题、环境声景)也会被编码并作为音频分支的上下文条件进行处理。通过结合来自 MLLM 的多模态语义引导、来自视频分支的上下文视觉模式以及来自音频参考的音频模式,模型实现了对视觉和声学生成的细粒度双重控制。
数据pipeline
本工作的数据pipeline包含三个主要组件:数据采集、数据处理和字幕生成。该管线处理图像、视频和音频三种模态,以支持多模态模型训练。
数据采集
训练数据包括跨三种模态的真实世界数据和合成数据。真实世界数据:主要从公开数据集和内部授权数据收集。合成数据:为弥补现实数据未能充分覆盖的稀疏场景和生成任务,本工作在多语言文本生成、多语言语音合成和多模态修复/编辑任务三个关键领域合成了大量数据。对于多模态修复与编辑任务,由于真实数据集中本质上缺乏配对数据,因此本工作通过包含视觉分割模型、图像/视频编辑模型以及可控生成技术的复杂管线来构建这部分数据。
数据处理
数据处理pipeline针对图像、纯音频和视频(带或不带音频)进行量身定制。图像数据处理:包括去重、过滤和平衡。音频数据处理:包括类别分类、质量过滤、持续时间控制、内容识别和音频加注。采用 Whisper 转录语音和歌唱内容,并统一使用 Qwen3-Omni 进行音频字幕生成。视频数据处理:包含预处理(智能转场分割和去重)、过滤、平衡以及针对带有音频轨迹的视频进行的视音频同步(过滤掉音画不同步的视频)。
字幕生成
生成三种类型的字幕:短字幕、长字幕和结构化字幕。短字幕提供简明的描述;长字幕详细描述环境、主体等;结构化字幕采用标准化描述顺序并引入特殊 Token(如 <text>、<sfx>、<dialogue>、<singing>、<bgm>)。在最终的训练阶段中仅使用结构化字幕,并利用提示增强器将用户的自由文本输入格式化为该结构化表示。
训练策略
本工作采用了渐进式的多阶段训练范式,系统性地开发模型跨多种模态和任务的能力。训练流程包含三个主要阶段:视频预训练、音频预训练和视音频联合训练,随后是监督微调。这种结构化方法使模型能够稳定、高效地学习空间概念、时间动态、音频生成及多模态对齐。
视频预训练
视频预训练阶段遵循渐进式策略,逐步提高空间分辨率、时间长度和任务复杂度。本工作从文本到图像(T2I)训练开始,以建立强大的语义理解和视觉概念学习能力,这显著加速了后续视频训练的收敛。
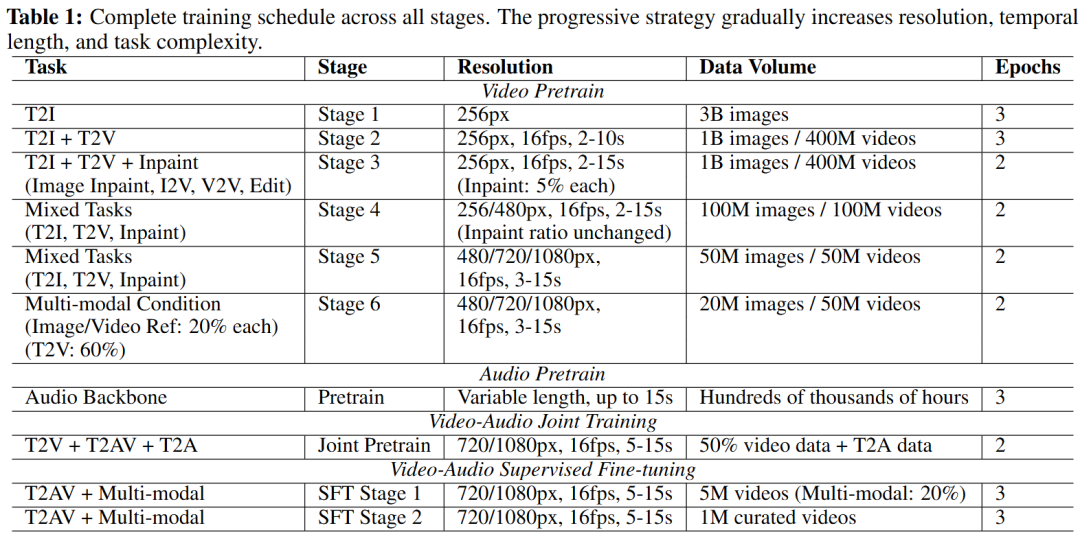
- 阶段 1:文生图基础。在 256px 分辨率下使用 30 亿张图像训练 3 个 Epoch。
- 阶段 2:初始视频学习。在保持 T2I 的同时引入文生视频(T2V)。在 256px 和 16 fps 下,使用 10 亿张图像和 4 亿个视频(2-10秒)训练 3 个 Epoch。
- 阶段 3:修复能力。将任务扩展到图像修复、图生视频、视频到视频及视频编辑任务,各占训练混合比例的 5%。视频时长延长至 2-15 秒。
- 阶段 4:混合分辨率扩展。采用 256px 和 480px 的混合分辨率训练,保持 16 fps,使模型逐渐适应高分辨率。
- 阶段 5:高分辨率训练。进一步扩展到 480px、720px 和 1080px 混合分辨率,16 fps,视频时长为 3-15 秒。
- 阶段 6:多模态条件预训练。引入图像和视频参考条件控制。图像与视频参考控制各占 20%,剩余 60% 为 T2V。
音频预训练
音频主干网络使用数以十万小时计的(主要为语音的)数据从头开始预训练,持续时间最高达 15 秒。训练中采用变长音频以最大化对各种声学特征的覆盖。
视音频联合训练
完成视频和音频的独立预训练后,进入联合训练阶段,同时训练三个任务:T2V、T2AV(文生视音频)、T2A(文生音频)。此阶段调配 50% 的视频预训练数据用于 T2AV,并结合 T2A 数据以支持视听同步生成。
视音频监督微调 (SFT)
在最终的 SFT 阶段,专注于联合生成数据,使用 500 万个具有多模态条件支持的视频进行训练,并最终在 100 万个人工精选的高质量视频上进行微调,以完善生成质量、运动连贯性以及视音频对齐。
视频超分辨率与插帧(细化器 Refiner)
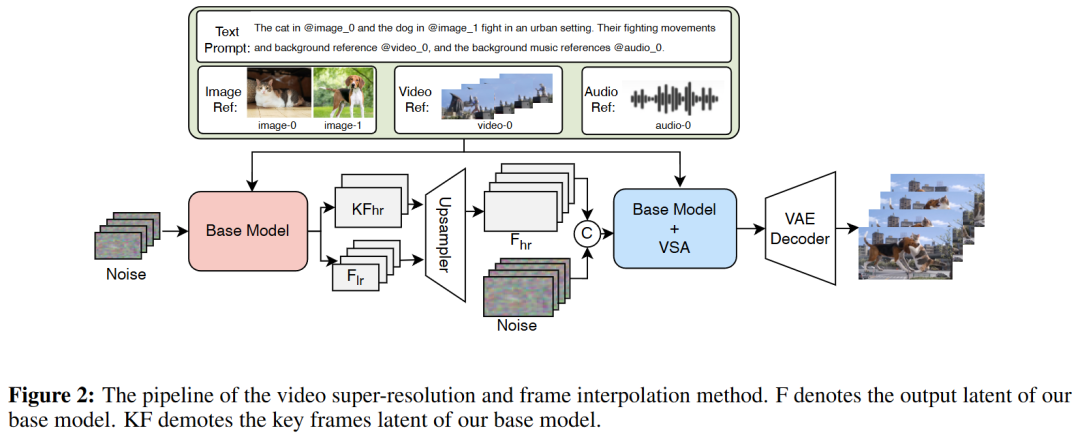
为了进一步提升视觉质量和生成视频的时间平滑度,本工作引入了一个专属的细化器(Refiner)模块,用于联合执行视频超分辨率(VSR)和插帧。
架构与设计。细化器权重由预训练的视频生成模型初始化。其接收三类输入:(1) 高分辨率的多模态视觉条件,(2) 文本指令,(3) 基础模型的输出(包含所有帧的低分辨率预测和关键帧的高分辨率预测)。通过线性插值低分辨率潜变量并用预测的高分辨率关键帧替换对应位置,随后与高分辨率的噪声潜变量进行通道拼接,一同送入 DiT 模型。同时其也结合掩码机制实现了统一的条件编辑与超分修复。
计算效率。为了解决长序列和高分辨率带来的庞大计算开销,采用了视频稀疏注意力(Video Sparse Attention, VSA)机制。VSA采用两阶段策略:粗阶段通过轻量级池化注意力寻找关键时空块(Cubes),细阶段仅在选定的 Top-K 块内执行密集注意力。这消除了全局二次方注意力的计算需求,将注意力计算开销降低了约 3 倍,同时保持了生成质量。
训练数据与配置。精心筛选了 100 万个高质量、分辨率从 1K 到 4K 的视频片段,并混合高分辨率图像。细化器的所有权重在流匹配的范式下进行全参数训练。
模型性能
为了全面评估 SkyReels-V4 模型的联合视听生成能力,本研究不仅在开放式评测平台 Artificial Analysis 上进行了盲测比对,还提出了一个细粒度的创新人类评估基准 SkyReels-VABench。
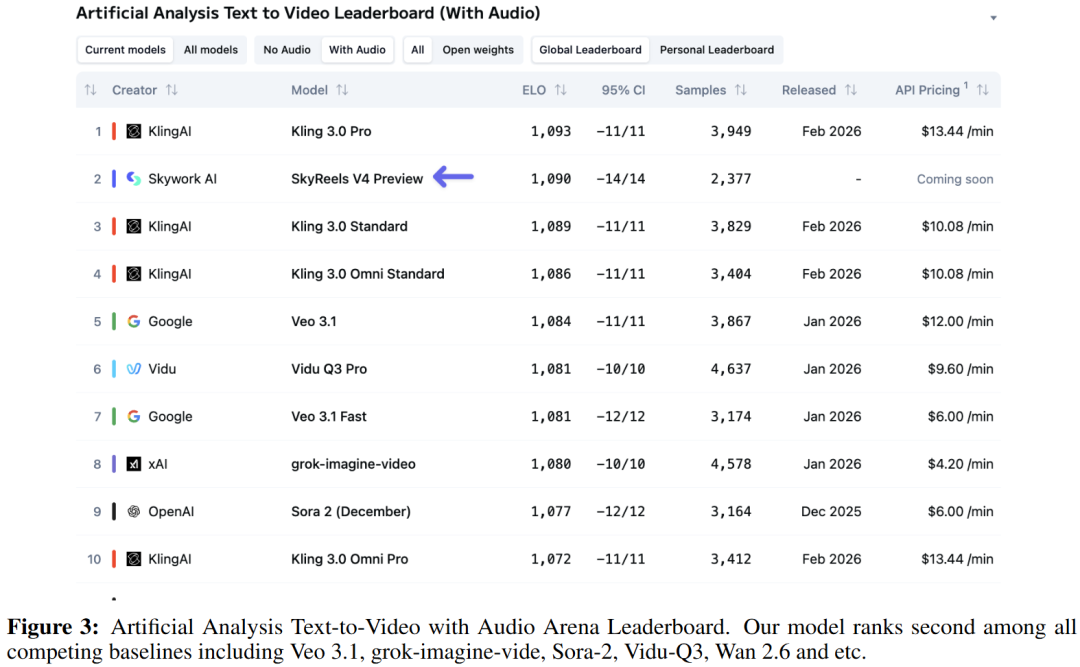
Artificial Analysis 竞技场测试该平台采用群众盲测并结合 Elo 机制进行评分。在“带有音频的文生视频”赛道中,SkyReels-V4 与 Veo 3.1, Kling 3.0, grok-imagine-video, Sora-2, Vidu-Q3, Wan 2.6等主流强力模型展开了对决。结果显示(截至2026年2月25日),SkyReels-V4 排名第二,展现了极具竞争力的音视频综合生成质量和用户偏好度。
综合人工评估 (SkyReels-VABench)本工作提出了包含 2000 多个精心构建的 Prompt 的 SkyReels-VABench,涵盖广告、社媒、故事叙述等多种复杂的多镜头和跨语言场景。评估体系包含五大核心维度:指令遵循、视音频同步、视觉质量、运动质量以及音频质量。
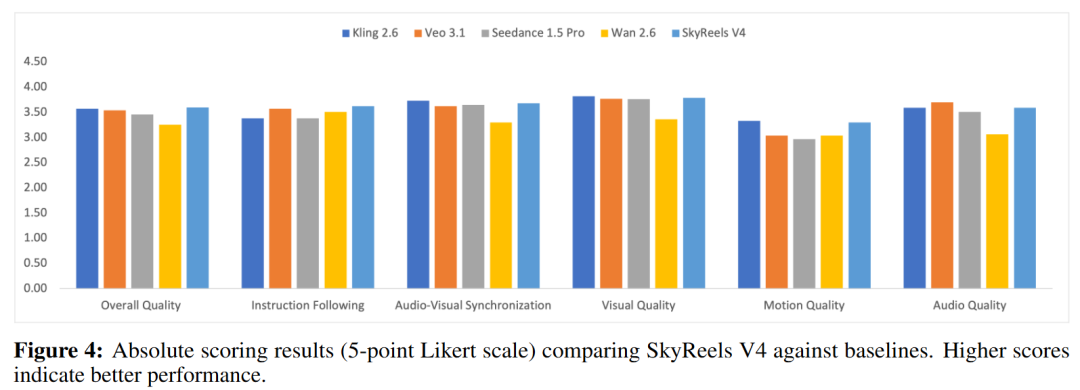
- 绝对评分(Absolute Scoring):由 50 名专业评测员使用5 分的李克特量表进行打分。结果显示,SkyReels-V4 获得了最高的整体平均分,其在“指令遵循”和“运动质量”两方面表现出了尤为强劲的优势。
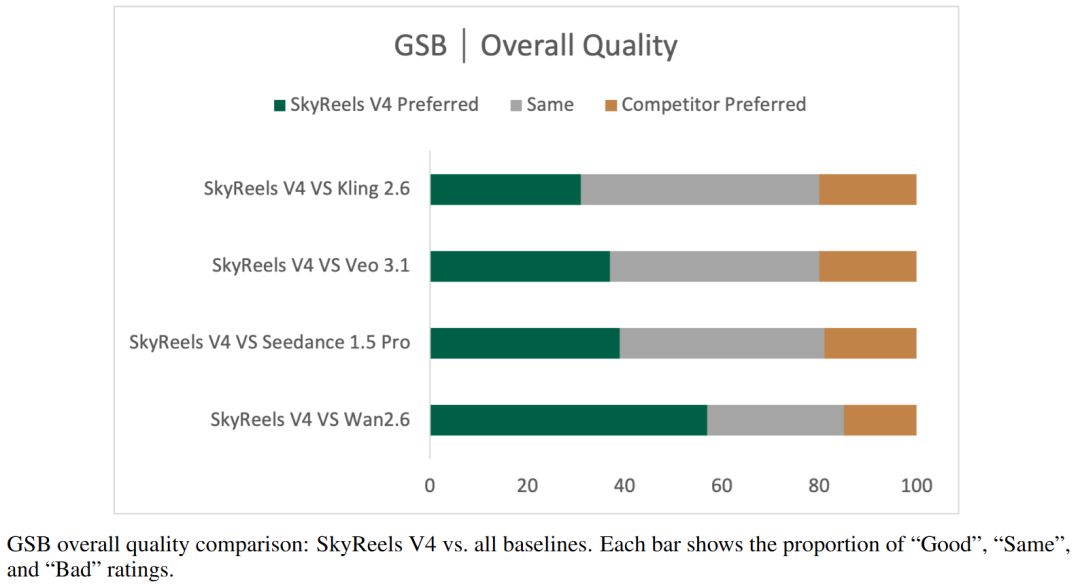
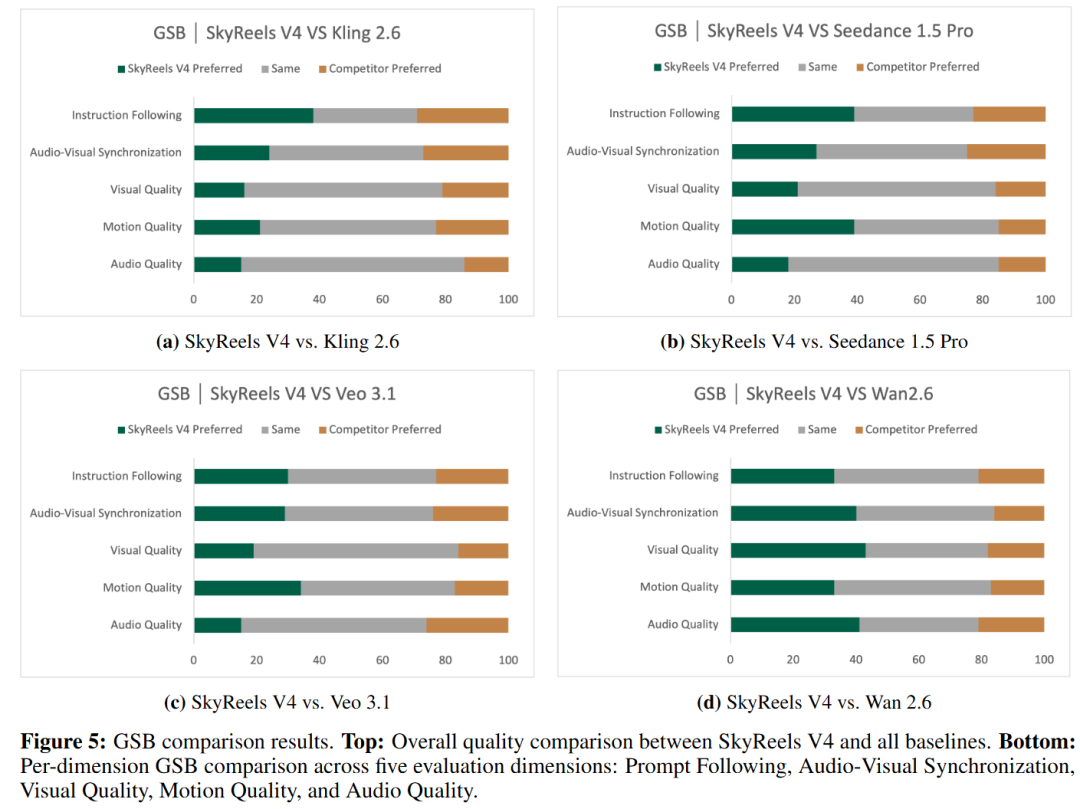
- Good-Same-Bad (GSB) 对比评估:在两两对比盲测中,SkyReels-V4 在绝大多数评估维度上,面对 Kling 2.6、Seedance 1.5 Pro、Veo 3.1 以及 Wan 2.6 等竞争对手时,均获得了更高比例的 "Good"(明显更好)评价,有力验证了其作为下一代专业视听内容创作底座的优越性。
总结
SkyReels-V4,这是一个统一的多模态视频基础模型,能够在单一架构内联合生成视频与音频,并同时支持生成、修复和编辑功能。基于双流 MMDiT 设计与共享的基于 MLLM 的文本编码器,SkyReels-V4 能够接收丰富的多模态条件输入(包括文本、图像、视频片段、掩码和音频参考),并输出电影级画质(最高可达 1080p,32 FPS,15 秒)的高保真、同步的视音频内容。为了支持多样化的视频创作任务,本工作采用了通道拼接技术,通过将生成、修复和编辑重新构建为特定掩码配置下的修复(Inpainting)问题来实现统一;同时,利用时间拼接机制灵活地整合图像、视频片段和音频等多模态参考信息。此外,本工作提出的低分辨率/高分辨率关键帧联合生成策略实现了大规模的高效生成。
广泛的评估验证了 SkyReels-V4 的有效性。在 Artificial Analysis 竞技场中,该模型在带音频的文生视频赛道上位列头部系统。在本团队提出的 SkyReels-VABench 上,SkyReels-V4 取得了最高的整体平均得分,尤其在指令遵循和运动质量方面表现卓越,同时在所有评估维度上都保持了领先性能。两两对比进一步证实了 SkyReels-V4 稳定超越了基线竞争系统。
据本团队所知,SkyReels-V4 是首个在电影级别的画质和规模下,同时统一了多模态输入、视音频联合生成以及生成/修复/编辑能力的基础模型。本团队期望这项工作能为多模态视频生成系统的未来研究奠定基础。
参考文献
[1] SKYREELS-V4: MULTI-MODAL VIDEO-AUDIO GENERATION, INPAINTING AND EDITING MODEL技术交流
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-03-02,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号