ComfyUI v0.15.1 最新版本发布:重大修复与AI模型深度优化全面解析

ComfyUI v0.15.1 最新版本发布:重大修复与AI模型深度优化全面解析

福大大架构师每日一题
发布于 2026-03-04 19:57:18
发布于 2026-03-04 19:57:18
在这里插入图片描述
在这里插入图片描述
在这里插入图片描述
2026年2月28日,ComfyUI 正式推出了 v0.15.1 最新稳定版本,这是一次深度更新与性能优化的版本,被官方标记为“immutable release”,意味着除了发布标题和说明外,其内容将保持稳定,不再进行结构性更改。此次版本带来了多项修复、优化以及模型扩展支持,涉及低显存模式、模型推理稳定性、前端接口改进以及多模态生成能力的拓展。 以下是对于本次更新的系统性解析,全面涵盖代码改动、文件更新及新增特性。
一、版本信息与发布背景
- • 版本号:v0.15.1
- • 发布日期:2026年2月29日
- • 特性类型:Immutablerelease(仅标题和注释可修改)
- • 影响范围:核心代码框架、API节点、模型加载模块、前端、脚本执行体系
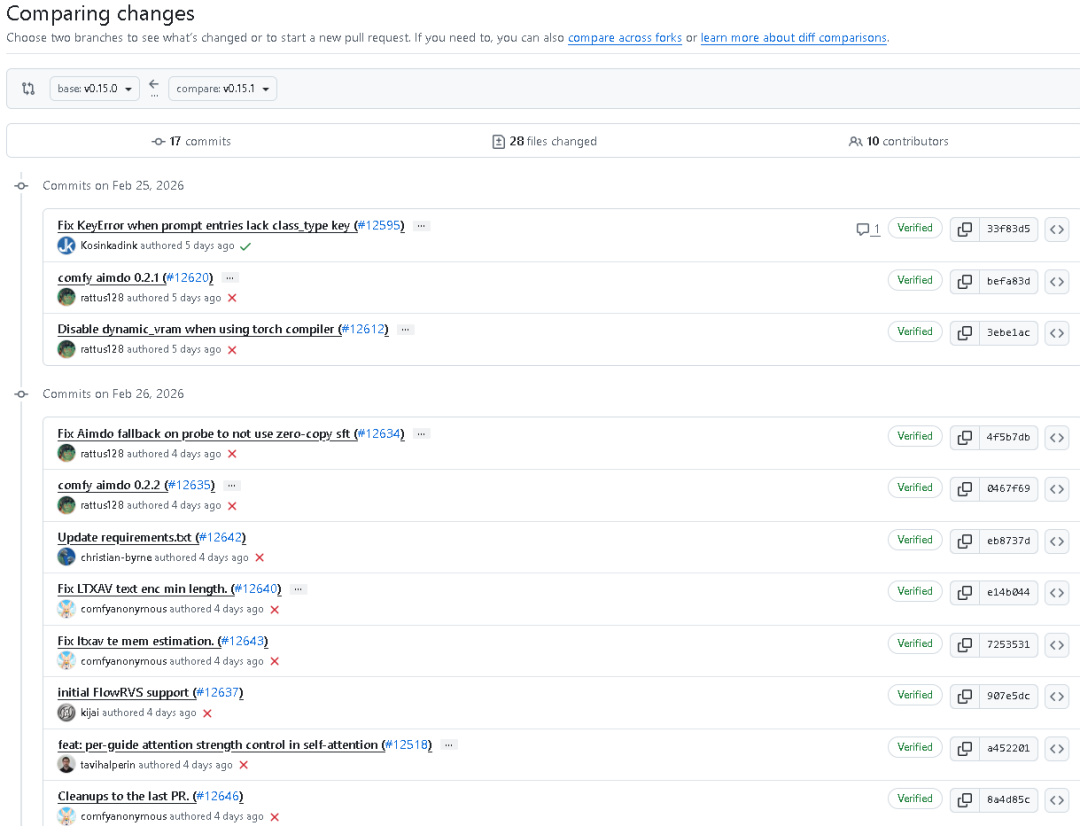
此次更新共涉及 17 次提交(commits)、28 个文件修改、632 行新增代码、65 行删除。主要涉及核心文件 main.py、comfy/model_base.py、comfy/ops.py、comfy_api_nodes/nodes_gemini.py 等关键模块。
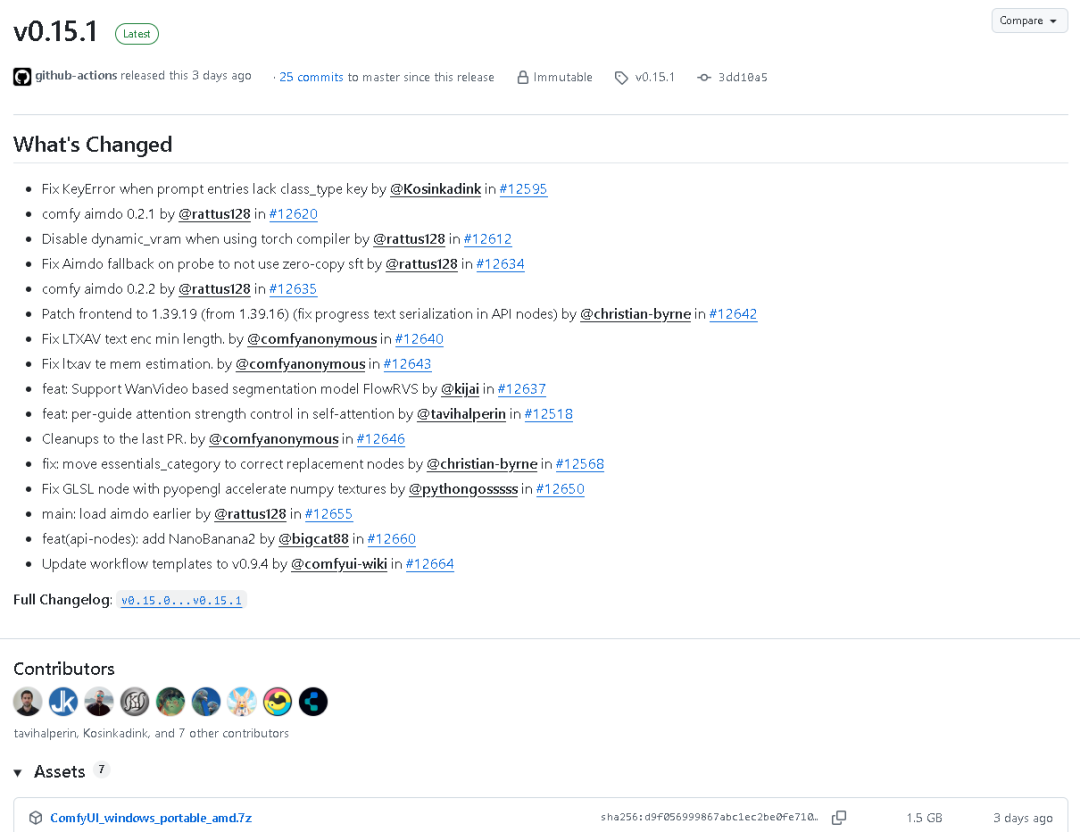
二、更新概览:What's Changed
本次 v0.15.1 的关键更新包括如下几个方面:
- 1. 修复 prompt entries 缺少 class_type 键导致的 KeyError
- 2. Comfy Aimdo 模块升级至 0.2.2 版本,全面接入动态显存控制优化。
- 3. 禁用 torch 编译器下的 dynamic_vram 功能,增强兼容性。
- 4. 修复 Aimdo fallback 机制在 probe 阶段的 zero-copy sft 使用问题。
- 5. 前端版本正式升级至 1.39.19(从 1.39.16),优化 API 节点的进度文本序列化能力。
- 6. 修复 LTXAV 模型 text encoding 最小长度与内存估算相关问题。
- 7. 新增 WanVideo 流式分割模型 FlowRVS 支持,实现视频级流动分割能力。
- 8. 新增 Self-Attention 每指引强度控制能力,强化模型注意力机制灵活性。
- 9. GLSL 节点优化:引入 PyOpenGL 加速 Numpy 纹理管理,提升渲染性能。
- 10. 新增 API 节点 NanoBanana2,支持 Gemini 3.1 Flash Image 模型自动生成。
- 11. 更新工作流模板至 0.9.4,全面同步生态工作流规范。
三、核心代码改进详解
1. Prompt Node修复与兼容增强
在 app/node_replace_manager.py 中新增了容错逻辑:
if "class_type" not in node_struct or "inputs" not in node_struct:
continue此修改解决了当 prompt 条目缺失 class_type 键时触发关键错误(KeyError)的 bug,使得节点替换逻辑更加稳健。
2. 条件比较函数升级 - comfy/conds.py
新增 is_equal(x, y) 函数用于深层递归比较字典、张量与序列结构,提高条件合并与判断的稳定性。
该函数支持 tensor、dict、list、tuple 全类型比对,避免传统直接比较引发异常。
在 CONDRegular 类中,原有的直接比较:
if self.cond != other.cond:现已升级为:
if not is_equal(self.cond, other.cond):这使得复杂条件在合并过程中可正常识别,从而改善生成稳定性。
3. Light Tricks 模块全面增强
位于 comfy/ldm/lightricks/av_model.py 与 model.py:
新增参数 self_attention_mask,为多模态自注意机制引入独立控制层。
这意味着模型的内部注意力不再固定,而可通过 mask 动态调节噪声到引导信号之间的注意强度,实现更加精细的多模态融合。
新增 _build_guide_self_attention_mask() 方法,允许模型根据每个引导参考自定义注意力衰减。
该函数基于每个 guide_attention_entries 构建遮罩矩阵,对噪声↔引导 token 的注意力进行定量调整。
在计算过程中,遵循以下逻辑:
- •
strength < 1.0时,进行关注度衰减。 - • 支持通过 pixel_mask 生成自适应遮罩。
- • 构建 log-space 加法偏置,用于 Transformer 的注意力层。
此功能的意义在于:模型对于多个引导输入(如视频帧、图像提示)可形成独立的注意力权重分布,从而提升多参考控制下的生成一致性。
4. 模型检测与元数据兼容扩展
文件:comfy/model_detection.py
新增自动提取 metadata 配置中 transformer 字段的能力,使保存的模型可加载自定义的 transformer 优化参数。
5. 模型克隆机制扩展
文件:comfy/model_patcher.py
新增参数 disable_dynamic=False,可在 clone 时禁用动态显存机制,实现与 torch.compile 一致的模型静态化操作。
并通过缓存 cached_patcher_init 保留模型加载初始化信息,为后续冷启动提供支持。
6. 动态 VRAM 管理逻辑优化
文件:comfy/ops.py
原有的 enables_dynamic_vram() 调用被替换为 comfy.memory_management.aimdo_enabled 逻辑。
这意味着系统不再依赖命令行参数,而通过内部内存管理器自动判断 AIMDO 动态显存支持状态,极大简化配置复杂度。
7. 新模型流派支持:WAN21_FlowRVS 与 IMG_TO_IMG_FLOW
文件:comfy/model_base.py 与 comfy/model_sampling.py
新增模型类型枚举值 IMG_TO_IMG_FLOW (11)。
并定义对应的模型类 WAN21_FlowRVS:
class WAN21_FlowRVS(WAN21):
def __init__(self, model_config, model_type=ModelType.IMG_TO_IMG_FLOW, image_to_video=False, device=None):
model_config.unet_config["model_type"] = "t2v"该模型继承 WAN2.1 架构,支持图像到视频流变变换(Flow-based Realistic Video Segmentation)。
在采样类型中新增:
class IMG_TO_IMG_FLOW(CONST):
def calculate_denoised(self, sigma, model_output, model_input):
return model_output为 ComfyUI 框架增加了新的视频分割式生成管线支持。
8. Gemini 系列 API 全面扩展
文件:comfy_api_nodes/nodes_gemini.py
新增 Gemini NanoBanana2 节点——支持 Google Vertex AI 的 Gemini 3.1 Flash Image 模型调用。
此节点可生成高分辨率图像(1K~4K),支持 thinking_level 控制,可在 MINIMAL 与 HIGH 两种思维层次间切换。
新增价格徽章逻辑 GEMINI_IMAGE_2_PRICE_BADGE,用于 API 自动计算使用费用。
所有配置类均升级,例如:
class GeminiThinkingConfig(BaseModel):
includeThoughts: bool | None = Field(None)
thinkingLevel: str = Field(...)这使生成请求可通过 thinkingLevel 影响模型推理策略,从而在简洁与复杂思维之间平衡图像质量与成本。
9. GLSL 节点与纹理加速修复
文件:comfy_extras/nodes_glsl.py
修复纹理删除逻辑,确保在启用 PyOpenGL 加速后,类型强制转换为 int 避免 numpy 类型错误:
gl.glDeleteTextures(int(tex))提高系统渲染稳定性。
10. 前端与依赖更新
文件:requirements.txt
关键依赖升级:
- • comfyui-frontend-package → 1.39.19
- • comfyui-workflow-templates → 0.9.4
- • comfy-aimdo → 0.2.2
增强前端 API 节点的进度文本序列化,和 workflow 模板的自动化管理能力。
11. 脚本执行主入口调整
文件:main.py
在主执行体之前新增 AIMDO 初始化逻辑:
import comfy_aimdo.control
if enables_dynamic_vram():
comfy_aimdo.control.init()确保系统在导入 Torch 模块前完成显存动态优化启动,防止显存管理冲突。
12. 版本号统一与构建文件更新
- •
comfyui_version.py更新为 0.15.1 - •
pyproject.toml同步为 0.15.1 版本标识与依赖一致,确保构建系统与安装文件保持同步。
四、总体评估与技术意义
本次更新可被视为 ComfyUI 框架的一次底层稳定性强化版本。 显著改进如下:
- 1. 增强错误容忍度:节点处理更稳健,避免低级键缺失导致进程中断。
- 2. 模型泛化扩展:FlowRVS、NanoBanana2、Gemini 3.1 Flash 等新模型支持。
- 3. 动态显存机制优化:显存控制由命令行切换至自动检测机制。
- 4. 注意力控制升级:引入 per-guide attention mask,优化多参考图像特征融合。
- 5. 前端和API协同更新:前端升级与API节点同步,交互更加实时、准确。
这使得 ComfyUI 在处理高维度视觉生成任务时,更加高效、稳定且具备较强的扩展性。
五、结语
ComfyUI v0.15.1 的发布,是一次非常重要的稳定性版本更新。它在保持架构完整性的同时,进一步增强了AI生成体系的连续性与智能性。 尤其是针对多模态融合和视频流式模型的支持,使得其在视频生成、图像修复和AI艺术设计领域再进一步。
对于开发者与AI内容创作者而言,建议尽快将环境升级至 v0.15.1,以充分体验其改进后的运行效率与生成质量。
版本总结表:
项目模块 | 更新内容 | 优势说明 |
|---|---|---|
comfy_aimdo | 升级至 0.2.2 | 动态显存优化 |
comfy/model_base | 新增 FlowRVS 模型支持 | 视频生成更自然 |
comfy_api_nodes/gemini | NanoBanana2 节点 | 支持 Gemini 3.1 图像模型 |
comfy/ops.py | 内部显存检测改进 | 稳定性提升 |
comfy_extras/nodes_lt.py | Guide attention 功能 | 多参考融合 |
comfyui_version.py | 版本同步更新 | 构建一致性 |
前端工作流模板 | 升级至 v0.9.4 | 工作流可扩展性提升 |
·
我们相信人工智能为普通人提供了一种“增强工具”,并致力于分享全方位的AI知识。在这里,您可以找到最新的AI科普文章、工具评测、提升效率的秘籍以及行业洞察。 欢迎关注“福大大架构师每日一题”,发消息可获得面试资料,让AI助力您的未来发展。
·
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-03-02,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号