开源文档解析避坑指南:看清“免费”背后的隐形成本
原创
开源文档解析避坑指南:看清“免费”背后的隐形成本
原创
合合技术团队
发布于 2026-03-04 15:14:52
发布于 2026-03-04 15:14:52
前言:当“免费”的代价开始显现
在构建AI知识库或文档解析系统时,许多技术团队会遵循一个看似完美的路径:首先拥抱开源。理由充分——零授权成本、源码透明、社区活跃。在概念验证阶段,这一切运转良好。然而,随着项目从试点走向规模化部署,一系列连锁问题开始集中爆发,往往让团队陷入“骑虎难下”的困境。
本文将剖析这一普遍现象背后的真实原因,并基于多个行业的实际案例,梳理从开源验证到生产部署的关键认知转变。
一、为什么早期选开源文档解析是合理的
在项目初期,选择开源方案具有其合理性。
- 成本透明:没有授权费,一次性投入只是开发成本。相比商业产品的license,开源的“免费”特性具有天然吸引力。
- 技术自主:源码在手,有问题可以自己改。这种“可控性幻觉”对技术团队特别有诱惑力——感觉一切都在掌握中。
- 学习曲线短:PoC 阶段效果通常还不错。国内外各款开源工具在单页文档、标准场景下表现通常令人满意,足以通过早期的Demo评审。
- 风险感知低:没有供应商依赖,从组织风险的角度看起来“更安全”。
所以,选择开源做试点,本身没有错。真正的误区在于,把试点阶段的成立性,误认为是生产阶段的可行性。
二、真实项目中,哪些变化开始出现?
当从PoC转向真实业务部署时,挑战接踵而至。
1、文档复杂性的指数级增长
试点时使用的“教科书式”PDF与业务中的真实文档相去甚远:
- 案例A(国家级大数据平台):需处理成千上万页的学术文献、专利和标准,内含大量复杂跨页表格。
- 案例B(国内顶级律所):文档布满手写签名、印章、涂改痕迹,且扫描质量参差不齐。
- 案例C(头部私立医院):病历、医学文献、诊疗指南格式杂乱,图表注释专业性强。
开源工具通常针对“标准 PDF”优化,一旦遇到真实业务数据的多样性时,准确率往往断崖式下跌。
标准PDF文档

真实医疗场景下的复杂文档
2、性能与运维瓶颈暴露
- 速度问题:某基金公司反馈,国内某主流开源方案解析速度慢,且缺乏详尽的性能基准数据。
- 资源利用不足:国家某大数据平台项目,在RTX 4090显卡上单页解析仍需2秒,硬件资源没吃满,性能调度不清楚。
- 部署不确定性:某券商团队花费4-5天才测出效果,部署推荐配置让人不放心。
开源方案的性能优化多停留在“能用”层面,远未达到“可靠运维”的生产级标准。
3、维护成本突然增加
- 支持缺失:某律所遇到Bug时,发现开源社区响应缓慢,自有团队难以深入修复核心代码。
- 定制两难:某ISV面对客户对效果的更高要求,陷入“自己改造开源代码”或“投入大量资源成本”的两难境地。
- 责任真空:某基金公司采用开源方案后效果未达预期,却找不到任何一方为此负责。
问题出现了,没有官方支持、没有SLA承诺。要么自己改源码(需要开发人力成本),要么搁置(项目延期)。
4、任务调度和多租户问题
真实业务部署后,会有:
- 优先级管理:不同业务方的任务优先级不一样
- 队列堆积:某个业务方突然大量上传,占满了资源
- 监控缺失:不知道每个任务的处理进度、卡在哪步了
开源方案通常没有生产级的任务调度能力。例如一个典型场景:高中低优先级不生效,高优任务要等低优任务跑完才能开始。
5、结果稳定性难以保障
- 跨页表格效果效果不好,官网与开源部署后的体验不一致;Excel会有内存溢出问题。
- 多页扫描件中间页不识别,当成图片了。
- 同一套代码,在不同条件下结果不一致。
这种输出的不稳定性,对于下游严重依赖其结果的RAG、抽取系统而言,是致命的。
三、这些问题为什么不是“优化能解决的”?
很多技术负责人的第一反应是:“我们再调调参数、优化一下代码”。但真相往往更复杂:
1、错误的不可逆性
文档解析的很多错误是不可逆的。比如:
- 表格识别错了,把表头当成内容,下游的Embedding、RAG就基于错的数据。
- 段落切分错了(本来应该分两个段落,却糅合成一个),后处理无法恢复层级关系。
解析阶段必须一次做对,否则下游再强大的大模型也救不了。
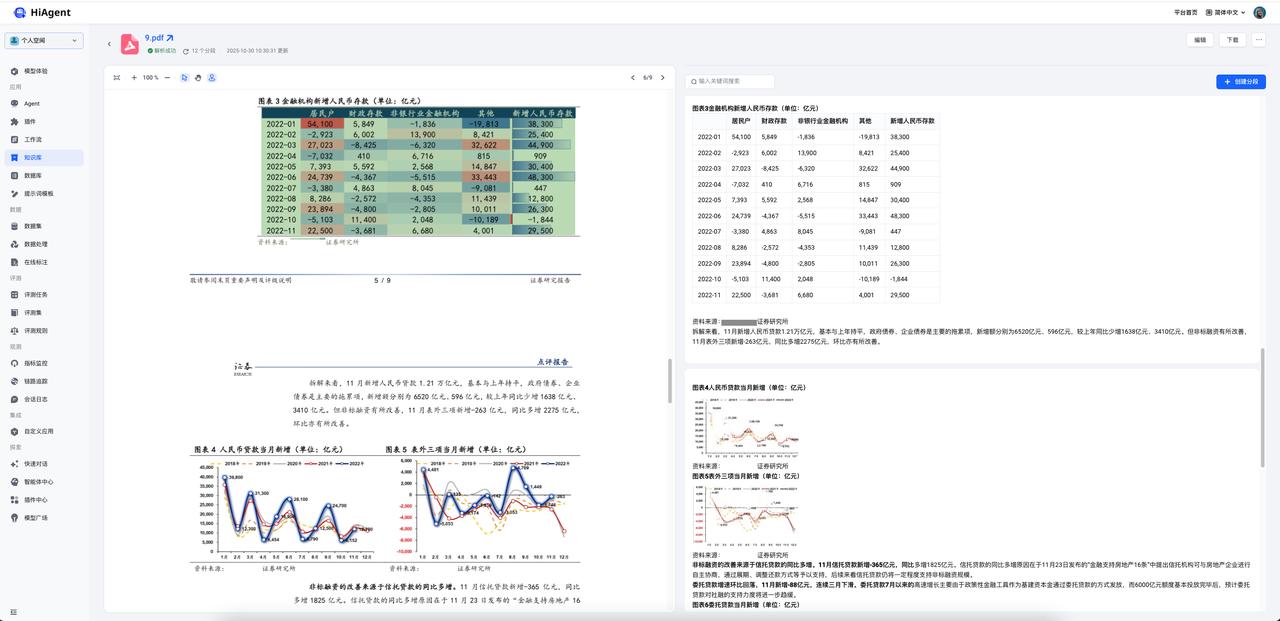
解析对下游Chunking质量存在决定性影响
2、多文档类型的覆盖问题
开源工具通常是一个通用方案。但不同行业、不同文档类型的要求差异很大:
- 法律文书:需要识别条款、编号、注脚。
- 医学文献:需要识别图表注释、参考文献类型。
- 财务报表:需要识别跨页表格、合并单元格。
要让一个开源工具覆盖所有场景,要么维护一套庞大的 if-else 规则(难以维护),要么接受效果不够好(业务受影响)。
3、工程可观测性缺失
开源方案没有生产级的日志、监控、告警体系。当效果下降时:
- 不知道是哪个环节出问题(OCR?切分?还是后处理?)
- 不知道是普遍问题还是特定文档问题
- 无法快速定位和回溯
真实场景一般需要:调度链路公开,明确每个任务跑的过程、每个步骤的耗时。但开源方案很难提供这样的透明度。
四、技术问题会如何转化为业务/组织风险?
技术层面的挑战很快会向上渗透,转化为实实在在的业务风险:
1、项目延期风险
- 某知识库项目用于施工参考,识别准确率有问题 → 建议不可用 → 项目无法上线。
- 某大数据处理项目需要在2周内上线系统,用开源工具实现可能性较小。
2、数据质量问题引发决策风险
- 银行、证券的 AI 平台:如果 RAG 的源数据有问题,最终给分析师的建议就是误导。
- 医疗领域:病历识别错了,可能影响诊疗建议。
这不只是“效果差”,是业务风险。
3、隐形人力成本爆发
一开始觉得“免费”,但到了项目后期:
- 需要负担一个专职团队的人力成本去维护、修改源码。
- 需要手工处理那些识别错的文档。
- 需要不停地调参、优化。
最终的总成本(开发投入+人力成本)往往超过一开始选商业方案的成本。
4、组织风险:决策链条被拉长
- 有的团队一上来选择主流开源方案,结果发现又要审核开源、又要做定制开发。
- 也有的团队选自研解析,后续发现效果不符合预期,仍需要进一步外采,试错成本高。
每次变更都意味着重新论证、重新测试和重新部署。
五、成熟组织通常如何处理这类问题?
我们和各行业头部客户接触下来,大家有一些共同模式:
1、阶段性思维:POC 和生产要分开
- 某数据厂商:2023年试过开源,效果不行就中止了。直到2024年验证有更好的方案,才重新立项。
- 某基金:经过数月测试,最初关注的是解析能力本身,最后意识到开源的问题在于没有服务支撑。
不是开源不行,而是PoC有效 ≠ 生产可行。
2、建立评估标准,在规模化前验证
- 某数据厂商:对精度要求极高,否则会发生误报。因此选择时特别谨慎,要使用跨页表格最好的引擎。
- 某证券:注重文档底层能力,作为建设AI中台的基础设施使用。
他们发现:解析质量直接影响下游应用的可信度。
3、把解析当作专业化能力,而不是“一个模块”
领先的运营商和医院客户普遍经历了一个认知进化过程:从自研或开源,最终转向专业的商业方案或API服务。他们视文档解析为影响业务质量的“能力中心”,而非可妥协的“成本中心”。
六、本质上发生了什么?
问题的核心并非开源工具本身“不行”,而是在于阶段错配。
阶段 | 开源方案 | 商业方案 |
|---|---|---|
PoC验证 | ✓ 成本低,效果够用 | × 成本高,过度配置 |
试点扩大 | △ 开始暴露问题 | △ 需要运维支撑 |
生产规模 | × 维护成本高,效果不稳定 | ✓ 生产级 SLA,专业运维 |
开源方案在PoC阶段的优势明显。然而,一旦进入生产规模,其隐性成本会呈几何级数增长,最终总拥有成本可能远超商业方案:
- 人力成本(维护、调试)
- 质量风险(错误率无法保证)
- 机会成本(技术团队被牵扯,无法做更有价值的工作)
七、值得思考的问题
如果你的团队现在在用开源方案做文档解析,可以问自己:
- 选择开源,主要是出于成本控制还是技术考量?
- PoC的效果验证,是基于理想的标准文档,还是具代表性的真实业务数据?
- 如果效果不达预期,是否有明确的升级或备选方案?
- 当下游业务系统已深度依赖当前解析结果时,更换方案的代价有多大?
- 谁在承担效果不足带来的业务风险?
如果答案显示:你们已处于生产环境、处理复杂数据、下游高度依赖且无备选,那么很可能已走到了必须进行架构评估与升级的十字路口。
小结
开源文档解析方案绝非能力不佳,它们是技术探索和原型验证的宝贵工具。真正的教训在于,不应将PoC的成功直接等同于生产部署的可行性。
两者之间存在一条由工程化能力、专业维护、稳定性和商业支持所构成的鸿沟。许多团队在项目后期才发现这个问题,那时已背负业务承诺并投入大量沉没成本,改方案的成本反而更高。
明智的做法,是在规模化前主动进行这场关键的评估: 不仅要问“这个工具技术能力牛不牛?”,更要追问“用它支撑核心生产系统,我们面临的真实成本与风险是什么?”
毕竟,在AI落地的道路上,选择的代价,往往在做出选择很久之后才会完全显现。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号