用于水下环境海洋垃圾检测的改进型YOLOv11网络
原创
用于水下环境海洋垃圾检测的改进型YOLOv11网络
原创
AI小怪兽
发布于 2026-03-04 14:21:56
发布于 2026-03-04 14:21:56
本文核心贡献如下:
- 提出MixStructureBlock模块:针对水下环境多尺度特征提取需求,设计了融合多分支膨胀卷积与混合注意力机制的模块,增强了主干网络对复杂背景及小目标的表征能力。
- 引入EMA注意力模块:在检测头中集成了高效多尺度注意力机制,通过跨维度特征融合优化空间与通道注意力,有效抑制背景噪声并聚焦关键区域。
- 实现性能显著提升:在TrashCan等水下垃圾数据集上,所提模型mAP@0.5达到81.54%以上,显著优于YOLOv11等基线模型及多个水下专用SOTA方法。
- 兼顾精度与轻量化:模型仅5.2MB,在保持高检测精度的同时具备优异的部署效率,为实时水下监测提供了实用解决方案。

博主简介

AI小怪兽 | 计算机视觉布道者 | 视觉检测领域创新者
深耕计算机视觉与深度学习领域,专注于视觉检测前沿技术的探索与突破。长期致力于YOLO系列算法的结构性创新、性能极限优化与工业级落地实践,旨在打通从学术研究到产业应用的最后一公里。
🚀 核心专长与技术创新
- YOLO算法结构性创新:于CSDN平台原创发布《YOLOv13魔术师》、《YOLOv12魔术师》等全系列深度专栏。系统性提出并开源了多项原创自研模块,在模型轻量化设计、多维度注意力机制融合、特征金字塔重构等关键方向完成了一系列突破性实践,为行业提供了具备高参考价值的技术路径与完整解决方案。
- 技术生态建设与知识传播:独立运营 “计算机视觉大作战” 公众号(粉丝1.6万),成功构建高质量的技术交流社群。致力于将复杂算法转化为通俗易懂的解读与可复现的工程代码,显著降低了计算机视觉的技术入门门槛。
🏆 行业影响力与商业实践
- 荣获腾讯云年度影响力作者与创作之星奖项,内容质量与专业性获行业权威平台认证。
- 全网累计拥有 7万+ 垂直领域技术受众,专栏文章总阅读量突破百万,在目标检测领域形成了广泛的学术与工业影响力。
- 具备丰富的企业级项目交付经验,曾为工业视觉检测、智慧城市安防等多个关键领域提供定制化的算法模型与解决方案,驱动业务智能化升级。
💡 未来方向与使命
秉持 “让每一行代码都有温度” 的技术理念,未来将持续聚焦于实时检测、语义分割及工业缺陷检测的商业化闭环等核心方向。愿与业界同仁协同创新,共同推动技术边界,以坚实的技术能力赋能实体经济与行业变革。
原理介绍

论文:https://www.nature.com/articles/s41598-026-38305-0
摘要:海洋垃圾检测在环境保护与水下智能机器人领域具有关键作用。然而,水下环境因其低可见度、目标遮挡和高度背景噪声而带来独特挑战。为解决这些问题,本文提出了一种基于YOLOv11改进的目标检测框架,并引入两个新模块进行增强:MixStructureBlock与高效多尺度注意力机制。MixStructureBlock通过集成多尺度膨胀卷积与混合注意力机制,强化了骨干网络的特征提取能力;而EMA模块则通过空间-通道融合与分组注意力优化检测头中的特征图。该模型在TrashCan-Instance与TrashCan-Material数据集上进行训练与评估。实验结果表明,所提方法在两个数据集上分别达到81.54%和82.75%的mAP@0.5,优于包括YOLOv11、YOLOv8、YOLOTrashCan等基线检测器,并进一步超越了近期水下专用SOTA模型(如TC-YOLO与YOLOv8-MU),在对比方法中表现出领先且优异的性能。消融实验进一步验证了各模块的独立贡献。所提架构在精度与效率之间实现了良好平衡,使其适用于实时海洋垃圾监测应用。
1. 引言
随着沿海地区工业化进程的加快以及海洋活动的持续扩张,水下垃圾的积聚已成为一个严峻的全球性环境问题。海洋垃圾对水生生态系统产生不利影响,通过被生物误食和缠绕而威胁海洋生物,并干扰对环境保护和海底勘探至关重要的水下机器人系统的运行。特别是,河流已被确认为塑料垃圾输送到海洋的主要途径,加剧了全球垃圾问题。鉴于有效监测的迫切需求,准确且实时的海洋垃圾检测对于支持智能海洋监测系统和自主清理行动变得至关重要。然而,由于低可见度、动态光照条件、小尺度且相互重叠的垃圾以及高度杂乱的背景,水下环境给视觉检测带来了巨大挑战。
深度学习和计算机视觉的最新进展为更有效的海洋垃圾检测系统铺平了道路。早期的研究探索了适用于复杂水下环境的轻量级嵌入式算法、用于原位海洋垃圾检测的机器人视觉集成,以及用于监测漂浮大型垃圾的航空图像分析。来自邻近领域(如空间碎片检测)的技术进一步说明了基于深度学习的方法在嘈杂、稀疏目标检测任务中的可行性。近期的研究专门针对水下图像调整了YOLO系列检测器,以应对浑浊、色偏以及小尺度、被遮挡物体普遍存在等问题。例如,TC-YOLO集成了注意力机制与图像增强技术,以改进在浑浊水域中的检测。YOLOv8-MU采用了大核卷积块和多分支重参数化,在不增加大量计算开销的情况下拓宽了有效感受野。而Underwater-YOLO及其多个轻量级变体则采用了膨胀/可变形卷积和遮挡感知注意力机制,以提升水下场景中的小目标召回率。
YOLO系列在实时目标检测中发挥了重要作用,提供了高精度和快速推理能力。基于YOLOv4,YOLOTrashCan网络针对水下垃圾检测引入了专门的特征融合和骨干网络增强,在TrashCan-Instance数据集上实现了65.01%的mAP@0.5,优于SSD、EfficientDet、YOLOv3和YOLOv4。然而,有效捕捉小尺度、被遮挡以及语义相似的垃圾仍然具有挑战性。
最近提出的YOLOv11进行了一系列架构改进,例如增强的多尺度特征提取和轻量级注意力模块。其在车辆检测和医学成像任务(如骨折分类)中的成功应用展示了其跨领域的适应性。此外,近年来,越来越多的研究致力于将YOLO系列检测器适配到水下环境,重点关注浑浊、色偏、低对比度和小目标可见性等问题。一些近期面向水下的YOLO变体引入了色彩校正、大核特征提取、轻量级注意力或多分支结构,以增强在具有挑战性的水下场景中的鲁棒性。这些工作凸显了两个重要趋势:1)需要丰富的多尺度表征来捕捉小尺度和被遮挡的垃圾;2)基于注意力的上下文细化对于抑制水下背景噪声至关重要。受这些进展以及近期注意力增强深度网络成功的启发,本文提出了一种改进的基于YOLOv11的框架,该框架融合了一个新颖的MixStructureBlock模块和一个高效多尺度注意力模块。这些创新旨在增强特征提取能力和定位精度,特别是在具有挑战性的水下环境中。
2. 相关工作
在深度学习技术的辅助下,海洋垃圾检测任务得到了广泛研究。Deng等人提出了一种专为水下复杂环境设计、强调低计算成本的嵌入式检测算法。Fulton等人将深度检测模型集成到机器人平台中,用于海洋垃圾的原位识别,而Garcia-Garin等人开发了一个用于从航空图像检测漂浮垃圾的深度学习系统,并与实时网络应用相关联。补充性研究,如Massimi等人在空间碎片检测方面的研究,进一步证实了深度学习在处理动态环境中稀疏、嘈杂检测问题方面的潜力。
注意力机制已成为在挑战性条件下提升检测性能的关键组成部分。诸如EAPT等方法引入了基于金字塔的高效注意力机制以实现更好的多尺度特征聚合。FSAD-Net证明了反馈式空间注意力可以显著提升在去雾和水下视觉等能见度受损场景下的鲁棒性。此外,BaGFN和多模态级联CNN等工作强调了高阶特征交互和多模态学习在提升目标分类和定位精度方面的优势。
针对小目标检测和细粒度分类任务,Sthy-Net提出了一种密集分支模块设计以增强特征融合,这对于检测水下小型垃圾元素特别有益。此外,结合了注意力机制与膨胀大核卷积的增强型水下检测框架已被证明能有效应对水下杂波和尺度变化等特定挑战。
基于YOLO系列,YOLOTrashCan对YOLOv4进行了修改,引入了注意力机制和特征金字塔增强,在海洋垃圾检测方面取得了显著改进。YOLOv11通过旨在提升多尺度特征提取和高效上下文建模的架构优化,进一步推进了这项工作。其在交通和医学成像领域的应用证明了其鲁棒性和适应性。
近年来,几种基于YOLO的架构被专门设计用于水下检测任务。TC-YOLO将注意力模块与色彩校正预处理相结合,以减少水下图像中浑浊和色偏的影响。AWF-YOLO采用自适应加权特征金字塔网络以改进多尺度融合并增强小尺度海洋目标的检测。类似地,UGC-YOLO引入了全局上下文块以更好地捕捉视觉复杂水下背景中的长程依赖关系。更近期地,改进的YOLOv8变体如YOLOv8-MU和SPSM-YOLOv8集成了大核卷积和轻量级重参数化模块,以实现更强的感受野聚合和更高的效率。这些面向水下的检测网络一致地证明,增强的多尺度表征和注意力机制对于提升水下环境中的鲁棒性和准确性至关重要。
受这些先前工作的启发,我们的研究提出了一种改进的基于YOLOv11的检测器,集成了MixStructureBlock和EMA模块,以进一步提升针对海洋垃圾(特别是小尺度、被遮挡和视觉复杂的水下目标)的检测性能。
3. 方法论
本节描述了所提方法的整体架构,该方法基于YOLOv11目标检测框架构建。为了增强模型在水下海洋垃圾检测方面的能力,我们引入了两个新颖的结构组件:嵌入到骨干网络中的MixStructureBlock,以及集成到检测头中的EMA注意力模块。这些改进旨在解决水下检测任务中的常见挑战,如小目标定位、遮挡和背景干扰。
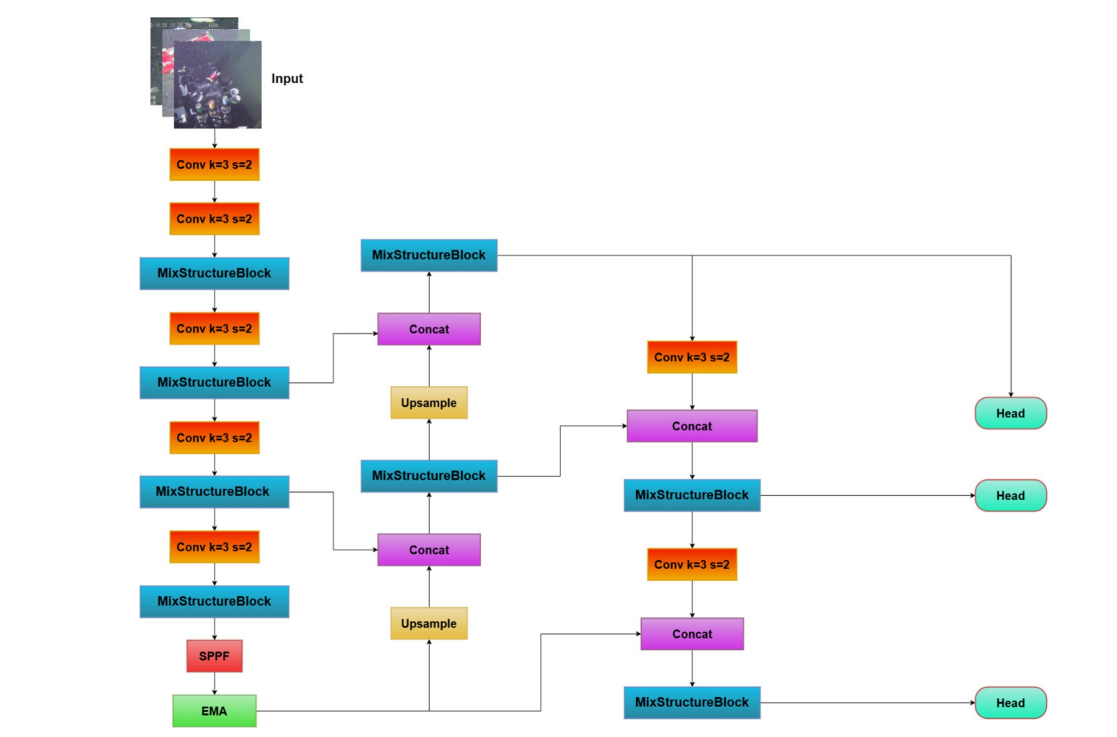
我们模型的整体架构如图1所示,由三个主要部分组成:
- 一个具有多尺度融合和注意力增强的特征提取骨干网络;
- 一个用于分层特征聚合的改进颈部结构;
- 一个带有高效多尺度注意力模块以进行精细化预测的改进检测头。
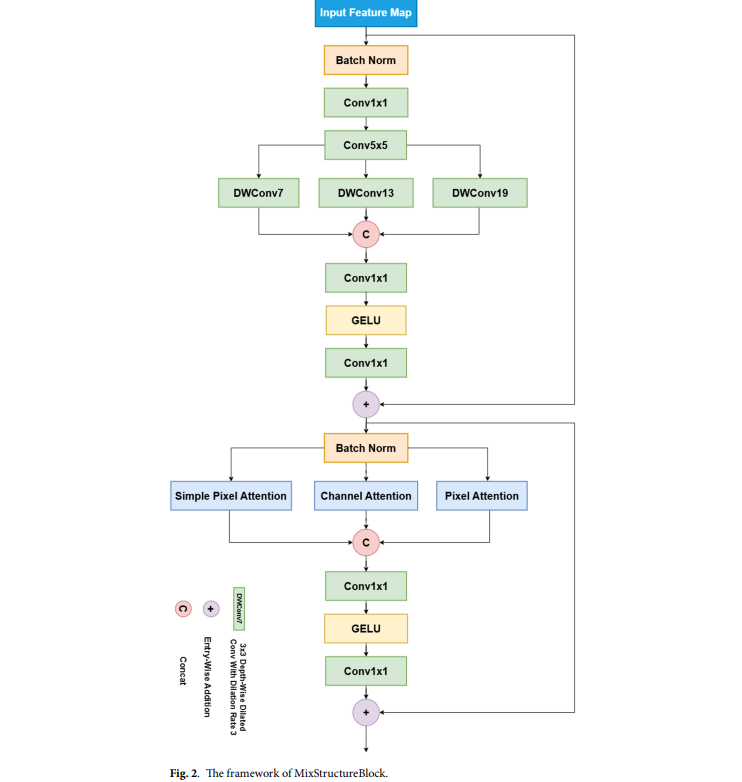
3.1. MixStructureBlock
原始YOLOv11的骨干网络由卷积层和残差块组成,旨在多个空间分辨率下提取丰富的视觉特征。尽管YOLOv11中原始的C3k2模块提供了轻量级的特征提取,但它仍然依赖于固定大小的卷积和有限的感受野模式。这种限制使得难以捕捉在水下场景中常见的、物体往往呈现小尺度、被遮挡或与嘈杂背景相融合的长程上下文线索和多尺度空间变化。
为了应对这些挑战,受YoloTrashCan引入Do-Conv的启发,我们提出了MixStructureBlock,这是一个将多分支膨胀卷积和复合注意力机制结合到骨干网络中的混合模块。使用膨胀卷积可以在不增加计算成本的情况下获得更大的感受野,而并行分支则捕捉从精细纹理到全局轮廓的多样化空间结构。此外,集成的通道-空间注意力机制可以选择性地强调在低对比度和高背景杂乱下的信息特征。该模块取代了YOLOv11中的标准C3k2模块,并提供了两个核心增强:
1. 多尺度特征提取 在模块内部,对输入特征应用具有不同卷积核大小和膨胀率的并行卷积路径。这些多样的感受野允许模块同时捕捉局部纹理和长程依赖关系,这对于以不同尺度和上下文出现的垃圾物体特别有益。
2. 集成注意力机制
- 通道注意力:使用全局平均池化,后接一个Sigmoid激活的多层感知机来重新加权特征通道,强调信息丰富的物体类别。
- 像素注意力:使用1×1卷积和激活函数来突出显著的空间位置。
- 简单像素注意力:通过将分组卷积与空间门控相结合来增强空间聚焦。 这些分支之后是通道拼接和一个基于1×1 MLP的融合层,该层将多分支输出压缩回原始通道维度。整个过程中使用了残差连接以稳定训练并保持梯度流动。
这些特性使得MixStructureBlock在处理水下垃圾时成为比C3k2更合适的替代品,因为水下垃圾的多尺度纹理和模糊的物体边界需要更丰富的上下文建模。该设计增强了模型检测各种尺度海洋垃圾的能力,提高了对噪声和杂波的鲁棒性,并在不产生过高计算成本的情况下显著提升了骨干网络的表征能力。此设计灵感来源于近期的大核卷积和重参数化研究,这些研究表明扩展的感受野可以显著改善小目标和上下文的表征。
核心改进代码:
import torch
import torch.nn as nn
# 论文题目:MixDehazeNet : Mix Structure Block For Image Dehazing Network
# 论文链接:https://ieeexplore.ieee.org/document/10651326
# 官方github:https://github.com/AmeryXiong/MixDehazeNet
# 代码改进者:一勺汤
class MixStructureBlock(nn.Module):
def __init__(self, dim):
super().__init__()
self.norm1 = nn.BatchNorm2d(dim)
self.norm2 = nn.BatchNorm2d(dim)
self.conv1 = nn.Conv2d(dim, dim, kernel_size=1)
self.conv2 = nn.Conv2d(dim, dim, kernel_size=5, padding=2, padding_mode='reflect')
# self.conv3_19 = nn.Conv2d(dim, dim, kernel_size=7, padding=9, groups=dim, dilation=3, padding_mode='reflect')
# self.conv3_13 = nn.Conv2d(dim, dim, kernel_size=5, padding=6, groups=dim, dilation=3, padding_mode='reflect')
# self.conv3_7 = nn.Conv2d(dim, dim, kernel_size=3, padding=3, groups=dim, dilation=3, padding_mode='reflect')
self.conv3_19 = nn.Conv2d(dim, dim, kernel_size=7, padding=3, groups=dim, padding_mode='reflect')
self.conv3_13 = nn.Conv2d(dim, dim, kernel_size=5, padding=6, groups=dim, dilation=3, padding_mode='reflect')
self.conv3_7 = nn.Conv2d(dim, dim, kernel_size=3, padding=3, groups=dim, dilation=3, padding_mode='reflect')
# Simple Pixel Attention
self.Wv = nn.Sequential(
nn.Conv2d(dim, dim, 1),
nn.Conv2d(dim, dim, kernel_size=3, padding=3 // 2, groups=dim, padding_mode='reflect')
)
self.Wg = nn.Sequential(
nn.AdaptiveAvgPool2d(1),
nn.Conv2d(dim, dim, 1),
nn.Sigmoid()
)
# Channel Attention
self.ca = nn.Sequential(
nn.AdaptiveAvgPool2d(1),
nn.Conv2d(dim, dim, 1, padding=0, bias=True),
nn.GELU(),
# nn.ReLU(True),
nn.Conv2d(dim, dim, 1, padding=0, bias=True),
nn.Sigmoid()
)
# Pixel Attention
self.pa = nn.Sequential(
nn.Conv2d(dim, dim // 8, 1, padding=0, bias=True),
nn.GELU(),
# nn.ReLU(True),
nn.Conv2d(dim // 8, 1, 1, padding=0, bias=True),
nn.Sigmoid()
)
self.mlp = nn.Sequential(
nn.Conv2d(dim * 3, dim * 4, 1),
nn.GELU(),
# nn.ReLU(True),
nn.Conv2d(dim * 4, dim, 1)
)
self.mlp2 = nn.Sequential(
nn.Conv2d(dim * 3, dim * 4, 1),
nn.GELU(),
# nn.ReLU(True),
nn.Conv2d(dim * 4, dim, 1)
)
def forward(self, x):
identity = x
x = self.norm1(x)
x = self.conv1(x)
x = self.conv2(x)
x = torch.cat([self.conv3_19(x), self.conv3_13(x), self.conv3_7(x)], dim=1)
x = self.mlp(x)
x = identity + x
identity = x
x = self.norm2(x)
x = torch.cat([self.Wv(x) * self.Wg(x), self.ca(x) * x, self.pa(x) * x], dim=1)
x = self.mlp2(x)
x = identity + x
return x
def autopad(k, p=None, d=1): # kernel, padding, dilation
"""Pad to 'same' shape outputs."""
if d > 1:
k = d * (k - 1) + 1 if isinstance(k, int) else [d * (x - 1) + 1 for x in k] # actual kernel-size
if p is None:
p = k // 2 if isinstance(k, int) else [x // 2 for x in k] # auto-pad
return p
class Conv(nn.Module):
"""Standard convolution with args(ch_in, ch_out, kernel, stride, padding, groups, dilation, activation)."""
default_act = nn.SiLU() # default activation
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, d=1, act=True):
"""Initialize Conv layer with given arguments including activation."""
super().__init__()
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p, d), groups=g, dilation=d, bias=False)
self.bn = nn.BatchNorm2d(c2)
self.act = self.default_act if act is True else act if isinstance(act, nn.Module) else nn.Identity()
def forward(self, x):
"""Apply convolution, batch normalization and activation to input tensor."""
return self.act(self.bn(self.conv(x)))
def forward_fuse(self, x):
"""Perform transposed convolution of 2D data."""
return self.act(self.conv(x))
class Bottleneck(nn.Module):
"""Standard bottleneck."""
def __init__(self, c1, c2, shortcut=True, g=1, k=(3, 3), e=0.5):
"""Initializes a standard bottleneck module with optional shortcut connection and configurable parameters."""
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, k[0], 1)
self.cv2 = Conv(c_, c2, k[1], 1, g=g)
self.add = shortcut and c1 == c2
def forward(self, x):
"""Applies the YOLO FPN to input data."""
return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))
class C2f(nn.Module):
"""Faster Implementation of CSP Bottleneck with 2 convolutions."""
def __init__(self, c1, c2, n=1, shortcut=False, g=1, e=0.5):
"""Initializes a CSP bottleneck with 2 convolutions and n Bottleneck blocks for faster processing."""
super().__init__()
self.c = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, 2 * self.c, 1, 1)
self.cv2 = Conv((2 + n) * self.c, c2, 1) # optional act=FReLU(c2)
self.m = nn.ModuleList(Bottleneck(self.c, self.c, shortcut, g, k=((3, 3), (3, 3)), e=1.0) for _ in range(n))
def forward(self, x):
"""Forward pass through C2f layer."""
y = list(self.cv1(x).chunk(2, 1))
y.extend(m(y[-1]) for m in self.m)
return self.cv2(torch.cat(y, 1))
def forward_split(self, x):
"""Forward pass using split() instead of chunk()."""
y = self.cv1(x).split((self.c, self.c), 1)
y = [y[0], y[1]]
y.extend(m(y[-1]) for m in self.m)
return self.cv2(torch.cat(y, 1))
class C3(nn.Module):
"""CSP Bottleneck with 3 convolutions."""
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5):
"""Initialize the CSP Bottleneck with given channels, number, shortcut, groups, and expansion values."""
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c1, c_, 1, 1)
self.cv3 = Conv(2 * c_, c2, 1) # optional act=FReLU(c2)
self.m = nn.Sequential(*(Bottleneck(c_, c_, shortcut, g, k=((1, 1), (3, 3)), e=1.0) for _ in range(n)))
def forward(self, x):
"""Forward pass through the CSP bottleneck with 2 convolutions."""
return self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)), 1))
class Bottleneck_MixStructureBlock(nn.Module):
"""Standard bottleneck."""
def __init__(self, c1, c2, shortcut=True, g=1, k=(3, 3), e=0.5):
"""Initializes a standard bottleneck module with optional shortcut connection and configurable parameters."""
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, k[0], 1)
self.cv2 = MixStructureBlock(c_)
self.add = shortcut and c1 == c2
def forward(self, x):
"""Applies the YOLO FPN to input data."""
return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))
class C3k(C3):
"""C3k is a CSP bottleneck module with customizable kernel sizes for feature extraction in neural networks."""
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5, k=3):
"""Initializes the C3k module with specified channels, number of layers, and configurations."""
super().__init__(c1, c2, n, shortcut, g, e)
c_ = int(c2 * e) # hidden channels
# self.m = nn.Sequential(*(RepBottleneck(c_, c_, shortcut, g, k=(k, k), e=1.0) for _ in range(n)))
self.m = nn.Sequential(*(Bottleneck_MixStructureBlock(c_, c_, shortcut, g, k=(k, k), e=1.0) for _ in range(n)))
# 在c3k=True时,使用Bottleneck_LLSKM特征融合,为false的时候我们使用普通的Bottleneck提取特征
class C3k2_MixStructureBlock(C2f):
"""Faster Implementation of CSP Bottleneck with 2 convolutions."""
def __init__(self, c1, c2, n=1, c3k=False, e=0.5, g=1, shortcut=True):
"""Initializes the C3k2 module, a faster CSP Bottleneck with 2 convolutions and optional C3k blocks."""
super().__init__(c1, c2, n, shortcut, g, e)
self.m = nn.ModuleList(
C3k(self.c, self.c, 2, shortcut, g) if c3k else Bottleneck(self.c, self.c, shortcut, g) for _ in range(n)
)
import torch
def main():
# 设置随机种子以确保可重复性
torch.manual_seed(42)
# 定义输入张量的形状 (batch_size, channels, height, width)
# 创建一个随机输入张量
x = torch.randn(4, 64, 27, 32)
# 打印输入张量的形状
print(f"Input shape: {x.shape}")
# 初始化 MixStructureBlock 模块
mix_structure_block = MixStructureBlock(dim=64)
# 前向传播
output = mix_structure_block(x)
# 打印输出张量的形状
print(f"Output shape: {output.shape}")
# 检查输入和输出形状是否一致
assert x.shape == output.shape, "Input and output shapes do not match!"
print("MixStructureBlock forward pass successful!")
if __name__ == "__main__":
main()3.2. 高效多尺度注意力模块
近年来,以CBAM、ResNest和ECA为代表的注意力机制被广泛采用,因为它们已被证明能显著提升深度神经网络的性能。
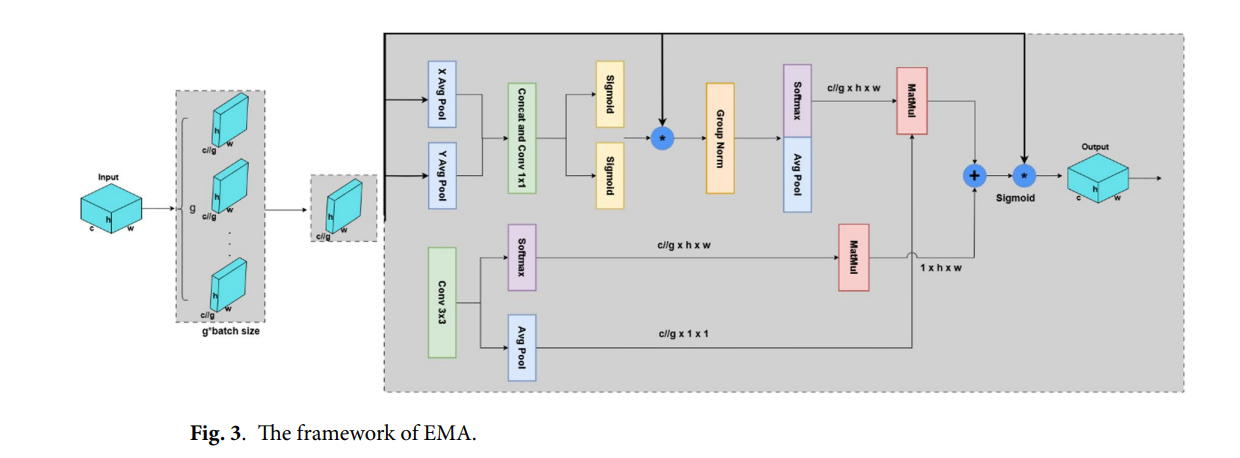
为了增强模型在视觉复杂的水下环境中感知和区分海洋垃圾的能力,我们用高效多尺度注意力模块替换了YOLOv11中原始的C2PSA模块。引入的EMA模块旨在改进多尺度特征提取并自适应地关注显著区域,特别有利于检测水下场景中常见的小型、重叠和低对比度物体。许多实验已证明,将EMA引入YOLO能提升检测性能。在图3中阐述了EMA模块的框架。
原始的C2PSA模块主要侧重于像素级空间注意力,这限制了其建模长程上下文依赖和多层次语义交互的能力。水下垃圾图像通常表现出低对比度、浑浊和重叠目标等特点,纯空间注意力无法充分地将前景与背景分离。
EMA通过分组池化和跨维度特征融合联合建模全局通道描述符和多尺度空间上下文,提供了一个更全面的机制。该设计增强了对小目标的敏感性,并提高了对视觉退化的鲁棒性,使得EMA在水下场景中成为比C2PSA更有效的替代方案。
EMA模块以一种轻量且计算高效的方式融合了空间和通道注意力机制。在结构上,它由以下关键组件组成:
- 多尺度空间上下文建模:输入特征通过并行的3×3卷积和自适应平均池化层,以捕捉局部和全局的空间依赖关系。
- 分组归一化与加权:应用分组归一化和Softmax激活来调节组内特征分布,并自适应地重新加权重要的特征通道。
- 跨维度注意力融合:利用池化后的空间特征与通道描述符之间的矩阵乘法,EMA捕捉跨维度的高阶依赖关系。应用Sigmoid激活来生成最终的注意力映射图,用于动态特征调制。
在修改后的网络架构中,EMA模块被嵌入到颈部的末端,取代了YOLOv11中原始的C2PSA。它作为一个轻量级的注意力单元,重新校准跨空间和通道的特征响应,有效抑制背景噪声,同时增强判别性特征。EMA借鉴了近期强调紧凑的多尺度跨维度特征融合的高效注意力和动态卷积工作,这为我们使用分组池化和跨维度融合来实现轻量级但有效的注意力提供了依据。
核心改进代码:
import torch
from torch import nn
from ultralytics.nn.modules.conv import Conv
class EMA(nn.Module):
def __init__(self, channels, c2=None, factor=32):
super(EMA, self).__init__()
self.groups = factor
assert channels // self.groups > 0
self.softmax = nn.Softmax(-1)
self.agp = nn.AdaptiveAvgPool2d((1, 1))
self.pool_h = nn.AdaptiveAvgPool2d((None, 1))
self.pool_w = nn.AdaptiveAvgPool2d((1, None))
self.gn = nn.GroupNorm(channels // self.groups, channels // self.groups)
self.conv1x1 = nn.Conv2d(channels // self.groups, channels // self.groups, kernel_size=1, stride=1, padding=0)
self.conv3x3 = nn.Conv2d(channels // self.groups, channels // self.groups, kernel_size=3, stride=1, padding=1)
def forward(self, x):
b, c, h, w = x.size()
group_x = x.reshape(b * self.groups, -1, h, w) # b*g,c//g,h,w
x_h = self.pool_h(group_x)
x_w = self.pool_w(group_x).permute(0, 1, 3, 2)
hw = self.conv1x1(torch.cat([x_h, x_w], dim=2))
x_h, x_w = torch.split(hw, [h, w], dim=2)
x1 = self.gn(group_x * x_h.sigmoid() * x_w.permute(0, 1, 3, 2).sigmoid())
x2 = self.conv3x3(group_x)
x11 = self.softmax(self.agp(x1).reshape(b * self.groups, -1, 1).permute(0, 2, 1))
x12 = x2.reshape(b * self.groups, c // self.groups, -1) # b*g, c//g, hw
x21 = self.softmax(self.agp(x2).reshape(b * self.groups, -1, 1).permute(0, 2, 1))
x22 = x1.reshape(b * self.groups, c // self.groups, -1) # b*g, c//g, hw
weights = (torch.matmul(x11, x12) + torch.matmul(x21, x22)).reshape(b * self.groups, 1, h, w)
return (group_x * weights.sigmoid()).reshape(b, c, h, w)
class Bottleneck_EMA(nn.Module):
"""Standard bottleneck."""
def __init__(self, c1, c2, shortcut=True, g=1, k=(3, 3), e=0.5):
"""Initializes a standard bottleneck module with optional shortcut connection and configurable parameters."""
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, k[0], 1)
self.cv2 = Conv(c_, c2, k[1], 1, g=g)
self.cv3 = EMA(c2)
self.add = shortcut and c1 == c2
def forward(self, x):
"""Applies the YOLO FPN to input data."""
return x + self.cv2(self.cv3(self.cv1(x))) if self.add else self.cv2(self.cv3(self.cv1(x)))
class C2f_EMA(nn.Module):
"""Faster Implementation of CSP Bottleneck with 2 convolutions."""
def __init__(self, c1, c2, n=1, shortcut=False, g=1, e=0.5):
"""Initializes a CSP bottleneck with 2 convolutions and n Bottleneck blocks for faster processing."""
super().__init__()
self.c = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, 2 * self.c, 1, 1)
self.cv2 = Conv((2 + n) * self.c, c2, 1) # optional act=FReLU(c2)
self.m = nn.ModuleList(Bottleneck_EMA(self.c, self.c, shortcut, g, k=((3, 3), (3, 3)), e=1.0) for _ in range(n))
def forward(self, x):
"""Forward pass through C2f layer."""
y = list(self.cv1(x).chunk(2, 1))
y.extend(m(y[-1]) for m in self.m)
return self.cv2(torch.cat(y, 1))
def forward_split(self, x):
"""Forward pass using split() instead of chunk()."""
y = list(self.cv1(x).split((self.c, self.c), 1))
y.extend(m(y[-1]) for m in self.m)
return self.cv2(torch.cat(y, 1))
if __name__ =='__main__':
EMA =EMA(256)
#创建一个输入张量,形状为(batch_size, H*W,C)
batch_size = 8
input_tensor=torch.randn(batch_size, 256, 64, 64 )
#运行模型并打印输入和输出的形状
output_tensor =EMA(input_tensor)
print("Input shape:",input_tensor.shape)
print("0utput shape:",output_tensor.shape)3.3. 模型架构
所提出的模型是YOLOv11的增强版本,旨在改进在挑战性水下条件下的检测性能。它由一个用于特征提取的骨干网络、一个特征融合颈部和一个检测头组成。
网络开始时是一系列步长为2的卷积层,用于对输入图像进行下采样并增加特征维度。在每个阶段,特征图由MixStructureBlock处理,该模块旨在捕获更丰富的上下文信息。此模块结合了具有不同感受野的多分支卷积,并整合了局部和全局依赖关系,使模型能够更好地处理不同形状和尺度的物体。
在骨干网络之后,最深层的特征图由空间金字塔池化-快速模块处理,以增强感受野。随后,输出由EMA模块进行细化,该模块取代了YOLOv11中原始的C2PSA模块。EMA通过分组池化和高效注意力融合聚合空间和通道信息,提升了模型聚焦于信息区域同时抑制背景噪声的能力。
颈部采用了PANet风格的自顶向下路径,通过上采样并将深层特征与浅层特征拼接来生成高分辨率特征。融合之后,应用额外的MixStructureBlock模块以进一步细化语义表征。随后是自底向上路径,将特征图再次下采样并拼接,以丰富跨多个层次的上下文信息。
最后,三个不同层级的特征被馈送到并行的检测头中。每个检测头预测物体边界框、类别概率和置信度分数。所有检测头的输出被组合,并应用非极大值抑制以获取最终的检测结果。
总体而言,受控的消融实验表明,每个组件都对性能提升有独立贡献,这为在所提出的架构中用MixStructureBlock替换C3k2以及用EMA替换C2PSA提供了明确的理由。
4. 实验结果与分析
4.1. 数据集
为了有效训练和评估我们提出的水下垃圾检测模型,我们使用了TrashCan数据集,这是一个专门为海洋视觉任务设计的大规模基准数据集。该数据集构建自日本海洋地球科学技术机构维护的J-EDI深海图像电子图书馆。它包含在日本周边不同海域、在各种光照和环境条件下拍摄的超过1000个水下视频。
从这些视频中,总共提取并标注了7212张RGB图像。该数据集反映了真实世界的海洋复杂性,包括各种形式的海洋垃圾、生物体(如鱼类、珊瑚)、水下设备和杂乱的背景。为了支持不同的检测场景,TrashCan提供了两种标注格式:
- TrashCan-Instance:包含22个物体类别,包括具体的垃圾类型(如垃圾袋、垃圾杯、垃圾树枝),以及生物(动植物)、遥控潜水器和未知类别。
- TrashCan-Material:包含16个类别,根据材料类型(如塑料、金属、织物)进行分类。
在我们的实验中,我们采用TrashCan-Instance版本,因为其具有更精细的物体级粒度,非常适合评估多类别目标检测性能。数据集被划分为6065张图像的训练集和1147张图像的验证集。在这两个集合中,总共提供了12,128个标注的物体实例,涵盖了广泛的目标大小、形状和外观。

4.2. 评估指标
为了全面评估所提目标检测模型的性能,我们采用了一组目标检测领域广泛使用的标准指标,特别是在COCO和PASCAL VOC评估协议的背景下。关键评估标准包括精确率、召回率、F1分数和平均精度均值。
- 精确率:衡量在所有预测为正的样本中,正确预测的正样本比例,表明检测器避免误报的能力。
- 召回率:衡量在所有真实正样本中,正确预测的正样本比例,反映检测器捕获相关物体的能力。
- F1分数:精确率和召回率的调和平均数,提供了一个平衡的检测性能指标。
- 平均精度均值:在IoU阈值为0.5时,所有物体类别的AP分数的平均值。我们还报告mAP@0.5:0.95,这是在IoU从0.5到0.95以步长0.05变化时的平均AP,提供了更严格和全面的评估。
- 模型大小:报告模型大小和参数量,以评估所提架构的计算效率和部署潜力。
4.3. 实验环境与训练
所有实验均在配备Windows 10、Intel Core i5-12400F CPU @ 2.50 GHz、16 GB内存和拥有12 GB显存的NVIDIA GeForce RTX 3060 GPU的设备上进行。训练使用PyTorch 2.1.0+cu121、CUDA 12.1和Ultralytics YOLO框架实现。
对于所有训练,输入图像被调整为416×416像素的分辨率。模型使用128的批量大小训练180个轮次,并应用余弦学习率调度来稳定收敛过程并防止过拟合。除非另有说明,所有其他参数均保持默认值。
4.4. 结果
4.4.1. TrashCan-Instance 实验结果
尽管最近提出的几种水下专用YOLO变体(如AWF-YOLO、SPSM-YOLOv8和LFN-YOLO)表现出良好的性能,但它们中的许多缺乏公开的代码库、预训练权重或可重复的训练流程。为确保所有比较是公平且可重复的,本工作的实验评估仅包括在TrashCan-Instance数据集上具有可公开访问的实现和可重新训练配置的模型。因此,基准模型包括两个可复现的水下最先进检测器(TC-YOLO和YOLOv8-MU)、一个海洋垃圾专用模型(YOLOTrashCan)、两个代表性的通用检测器(YOLOv8和YOLOv11),以及我们提出的模型。其他近期的水下YOLO变体在相关工作部分进行了定性讨论,分析了其设计原理和架构动机与我们方法的关联。
表1展示了模型在TrashCan-Instance数据集上的全面性能比较。结果显示,我们的方法实现了最高的整体准确率,mAP@0.5达到了81.54%。这显著超过了两个水下SOTA模型TC-YOLO和YOLOv8-MU,这两个模型都显示出很强的基线性能,但仍然比我们提出的方法低几个百分点。同时,YOLOTrashCan虽然是专门为海洋垃圾检测设计的,但其性能明显较低,凸显了其较重的骨干网络和较旧的架构设计的局限性。与通用检测器(如YOLOv8和YOLOv11)相比,我们的模型也表现出明显的改进,证实了所引入的MixStructureBlock和EMA注意力机制有效地增强了在复杂水下环境中的特征表示和目标定位能力。
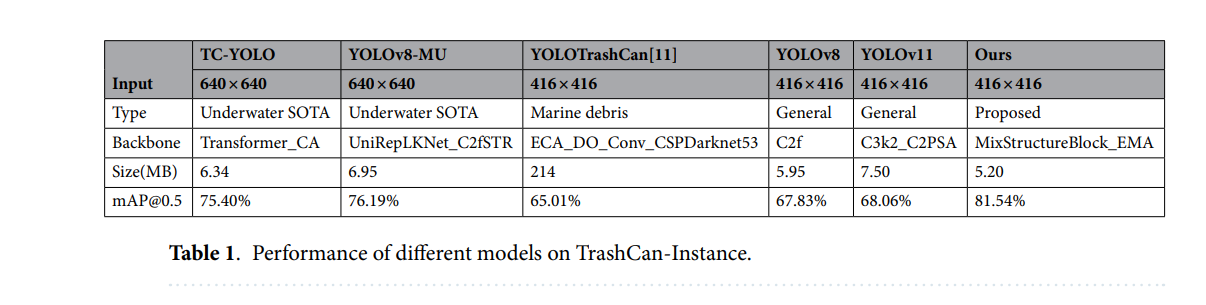
尽管提供了最佳的检测精度,我们的模型保持了仅5.20 MB的轻量级大小。这比YOLOv11和YOLOv8更小,与体积明显更大的YOLOTrashCan模型相比则更为紧凑。这种紧凑性,结合改进的准确性,证明了我们架构改进的效率,并强调了将所提模型部署在计算资源通常有限的实时嵌入式水下系统中的实用性。
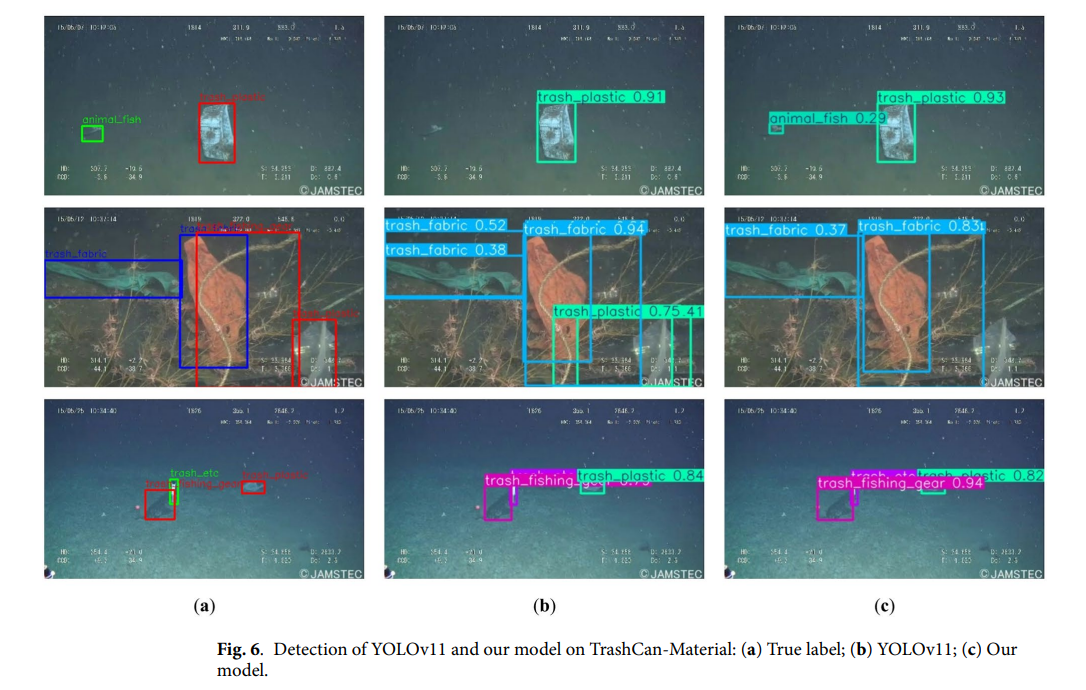
为直观展示我们提出的模型带来的检测性能提升,图5展示了TrashCan-Instance数据集上的视觉比较,分为三组:(a) 真实标注,(b) 原始YOLOv11的预测,和 (c) 我们改进模型的预测。每一行对应一个场景,涵盖了各种具有挑战性的水下条件,如遮挡、类别模糊性和复杂背景。

在第一行中,YOLOv11和我们的模型都能够检测到多个trash_unknown_instance实例。然而,我们的模型输出了更高的置信度分数和更准确的边界框定位,特别是对于较小的物体,而YOLOv11往往容易遗漏或以较低的置信度预测。
在第二行中,我们的模型抑制了冗余的边界框,并正确区分了相邻或重叠的物体。虽然YOLOv11识别出了主要物体,但其预测存在边界不精确和冗余框输出的问题。
在第三行中,对于trash_pipe类别,与YOLOv11略显碎片化的检测相比,我们的模型产生了置信度更高、更清晰的预测,并且与物体轮廓的对齐更好。
这些定性结果表明,我们提出的改进(即MixStructureBlock和EMA注意力机制)帮助模型聚焦于信息丰富的特征,同时在杂乱的水下场景中保持鲁棒性。与基线YOLOv11相比,我们的模型在多目标场景下产生了更准确的检测结果,误报更少,一致性更强。
4.4.2. 消融实验
为了研究所提出的架构改进的有效性,我们在TrashCan-Instance数据集上进行了一系列消融实验。比较了四种变体:基线YOLOv11模型、YOLOv11+EMA、YOLOv11+MixStructureBlock,以及集成了两个组件的完整模型。表2总结了这四种变体在精确率、召回率、F1分数和mAP@0.5方面的性能。
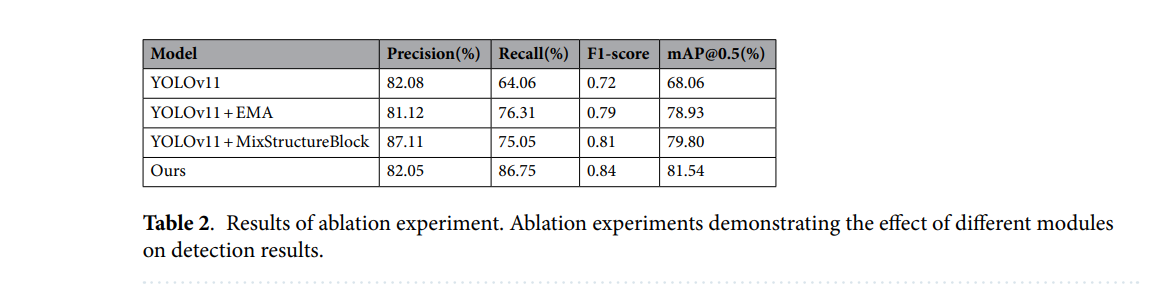
基线YOLOv11模型实现了82.08%的精确率、64.06%的召回率和68.06%的mAP@0.5。通过将原始的C2PSA模块替换为提出的EMA,模型(YOLOv11+EMA)将召回率提高到76.31%,F1分数提高到0.79,从而使mAP@0.5达到78.93%。这表明EMA有效地增强了上下文特征学习,并更好地捕获了多尺度依赖关系,特别有利于杂乱的水下环境。
单独引入MixStructureBlock(YOLOv11+MixStructure)将精确率显著提高到87.11%(所有变体中最高的),并将mAP@0.5提升到79.80%。这证实了MixStructureBlock提高了检测器的空间特征提取能力,并减少了误报,特别是对于小物体或重叠物体。
当两个模块在我们的最终模型中结合时(我们的模型),性能得到进一步增强。F1分数达到0.84,mAP@0.5提高到81.54%,证明了两模块的互补效应。精确率和召回率的均衡提升表明检测鲁棒性和分类准确性得到了改善。
受控实验清晰地分离了每个提出模块的效果。当仅添加EMA时,模型实现了更高的召回率(+12.25%)和F1分数,表明EMA通过增强全局上下文推理,提高了对小目标和低对比度目标的敏感性。相比之下,仅添加MixStructureBlock则显著提高了精确率(+5.03%),表明混合膨胀卷积结构通过捕捉更丰富的空间线索并提高在杂乱水下场景中的特征区分度,减少了误报。
当两个模块结合时,它们的互补优势导致了精确率和召回率的同时提升,从而获得了最高的整体mAP@0.5(81.54%)。这证实了MixStructureBlock和EMA解决了基线YOLOv11的不同弱点:前者改进了空间结构表示,而后者增强了多尺度注意力和全局上下文聚合。它们的联合效果证明了在最终模型中采用的架构修改是合理的。
4.4.3. TrashCan-Material 实验结果
为了进一步评估所提模型的有效性,我们在TrashCan-Material数据集上进行了实验,并将我们的结果与几个基线模型进行了比较,包括TC-YOLO、YOLOv8-MU、YOLOTrashCan、YOLOv8和YOLOv11。如表3所示,我们的模型实现了最高的检测精度,mAP@0.5为82.75%,超过了YOLOv11(70.06%)和YOLOTrashCan(58.66%)。图6展示了TrashCan-Material数据集上的定性检测结果,比较了在复杂水下条件下真实标注、YOLOv11预测和我们提出的模型的结果。
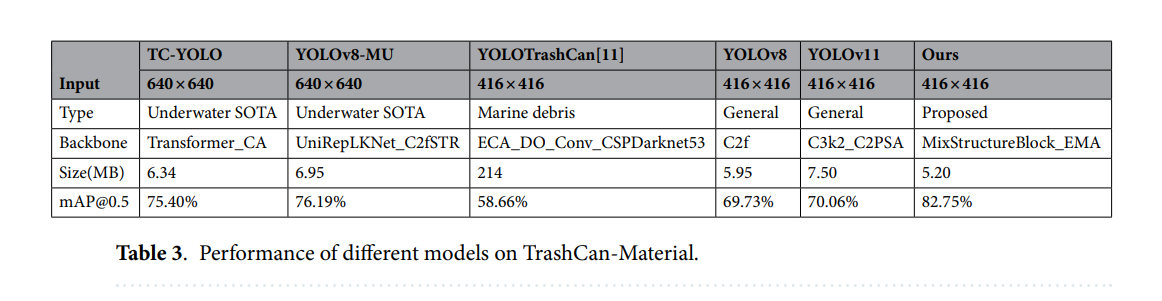
尽管我们的模型在尺寸上显著更轻(5.20 MB),但它保持了强劲的性能,突显了所提架构的效率。这一改进主要归功于MixStructureBlock和EMA模块的集成,它们有效地增强了在复杂水下环境中的多尺度特征提取和基于注意力的特征细化能力。
5. 结论
在本研究中,我们提出了一种改进的基于YOLOv11的架构,用于水下海洋垃圾检测。为了应对复杂水下环境(如物体遮挡、尺度变化和背景噪声)带来的挑战,我们引入了两个关键模块:MixStructureBlock(通过混合卷积结构增强多尺度特征表示)和EMA模块(自适应地聚焦于信息丰富的空间和通道特征)。
在TrashCan-Instance和TrashCan-Material数据集上的大量实验证明了所提模型的有效性。与基线YOLOv11和其他最先进的水下专用模型相比,我们的方法取得了优越的性能,在TrashCan-Instance上的mAP@0.5最高达到81.54%,在TrashCan-Material上达到82.75%。同时,我们的模型大小相较于先前研究更为轻量,仅为5.2 MB。消融研究进一步证实了EMA和MixStructureBlock对检测精度和鲁棒性的独立及联合贡献。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号