AI落地第一课,先把数据治理整明白
原创
AI落地第一课,先把数据治理整明白
原创
数据狗忙忙忙
发布于 2026-03-04 13:57:59
发布于 2026-03-04 13:57:59
你花了三个月,上了一套AI客户分析系统。业务部门试用了两周,甩来一句话:“不准,不用了。”然后再也没打开过。
这种情况,你有没有遇到过?
不只是你。买了大模型API,对接完发现回答驴唇不对马嘴;搭了智能预测系统,跑出来的结论业务部门一眼看出不靠谱;搞了AI客服,客户问题答非所问,投诉反而多了。这些企业不是不舍得花钱,不是团队不努力,技术选型也没出问题。但AI就是跑不起来。
说实话,我见过太多这样的情况了。根子不在AI,在数据。
问题出在哪?出在数据上。
说实话,我见过的AI项目,真正跑起来的没几个,大多数死在同一个地方——数据。Gartner预测,到2026年,60%的AI项目将因为数据没准备好而被迫放弃。
你以为在卡模型?其实在卡地基。
一、先说说AI到底在“吃”什么
很多人把AI想象成一个聪明的大脑,只要买回来、接上去,它就能帮你做事。
但这个逻辑有个根本性的问题:大脑再聪明,吃进去的是垃圾,出来的也是垃圾。
我举个具体的场景,你来判断这能不能用AI。
一家公司想做AI客户流失预测——这是个很成熟的AI应用场景了,理论上可行。但一查数据,发现:这个客户在销售系统里是一个合同编号,在客服系统里是一个来电手机号,在营销系统里是一个邮箱地址。三套系统,三套“客户”,根本没人知道它们指的是不是同一个人。
你让AI去预测这个客户会不会流失?
它连“这是谁”都搞不清楚,预测个什么劲。
这就是当下很多企业AI落地的真实困境:不是AI不够聪明,是喂给它的数据,它根本读不懂。
二、数据问题,到底卡在哪几块
根据我这些年的实践经验,企业数据喂不好AI,基本卡在三个地方。
第一个坑:大家说的不是同一件事
说白了,就是同一件事,不同部门叫法不一样、口径不一样、定义不一样。
“客户数量”——销售说1200个,财务说900个,运营说1500个。谁对?可能都对,因为大家对“客户”的定义压根就不一样。销售把签了合同的算客户,财务把付了款的算客户,运营把注册了账号的算客户。三个部门各有各的道理,但AI不知道该信谁。
AI要处理这些数据,连最基本的“同一个词说的是不是同一件事”都搞不定,后面所有的分析都是在沙堆上盖楼。
第二个坑:数据进来就是烂的
这个问题比你想象的要严重得多。
很多企业的数据现状是:缺失的字段一大堆,重复录入的记录到处都是,格式乱七八糟(日期有写2024/1/1的,有写20240101的,有写2024年1月1日的),还有大量已经过时、不再准确的历史数据安静地躺在数据库里。
你觉得这种数据喂给AI,AI能学出什么来?它学的,是你数据里的错误规律。
Zillow就栽在这上面。这家美国知名房产平台花了大价钱搭了AI估价系统,最后因为喂进去的数据出了问题,估值严重跑偏,被迫关闭iBuyer业务,直接减记超过5亿美元资产。这笔损失,是货真价实的真金白银打水漂。
第三个坑:数字有了,意思没了
这个问题更隐蔽,也更要命。
给AI一列销售额数字,它只会算统计。但它不知道这列数字背后是什么含义:是含税还是不含税?是退货前还是退货后?是哪个渠道的?发生在什么营销活动期间?
这些“上下文”,是让AI从“统计工具”变成“分析专家”的关键。
没有这些业务语义,AI给你的结论就是一堆没有灵魂的数字,业务部门看了也不知道怎么用。
三、那要怎么治,才能让AI用起来
既然根子在数据,那就从数据治理下手。但很多企业一听“数据治理”就头疼——这不是个短期能见效的事。
我的建议是:不要试图一口吃成胖子,从最影响AI落地的三件事开始做。
第一件事:建统一的数据标准
就是给全公司的数据定一套“说话的规矩”——什么叫客户,什么叫订单,什么叫有效交易,每个字段叫什么、格式是什么、谁来维护、谁是权威来源。
这件事说起来简单,做起来最大的难点是谁来拍板。
用过来人的经验告诉你,这件事的主导方必须是业务部门,不能让IT来定。IT可以执行,可以赋能,但业务部门不认可的标准,最后都是白纸一张。
拍完板,要落进系统,让系统强制约束,不符合标准的数据进不来。否则定了标准没人遵守,等于没定。
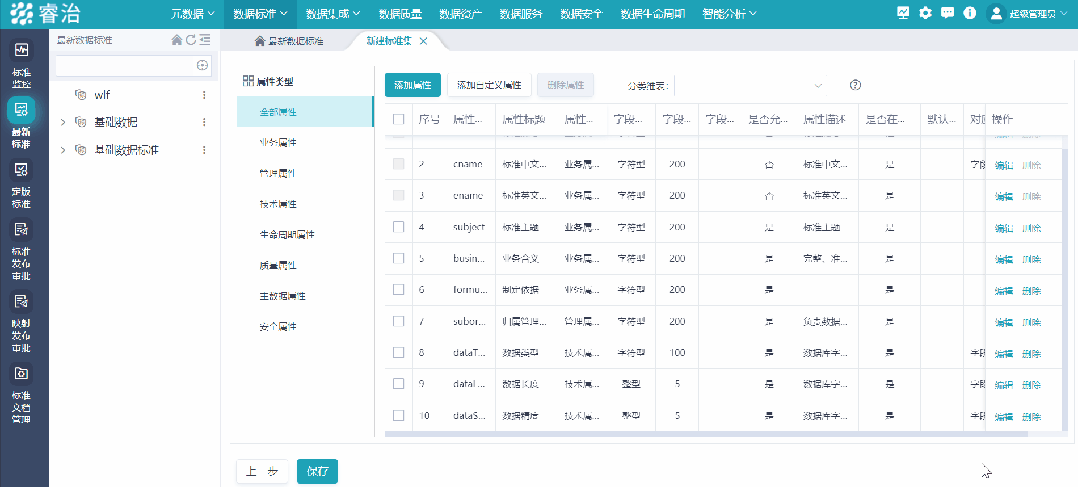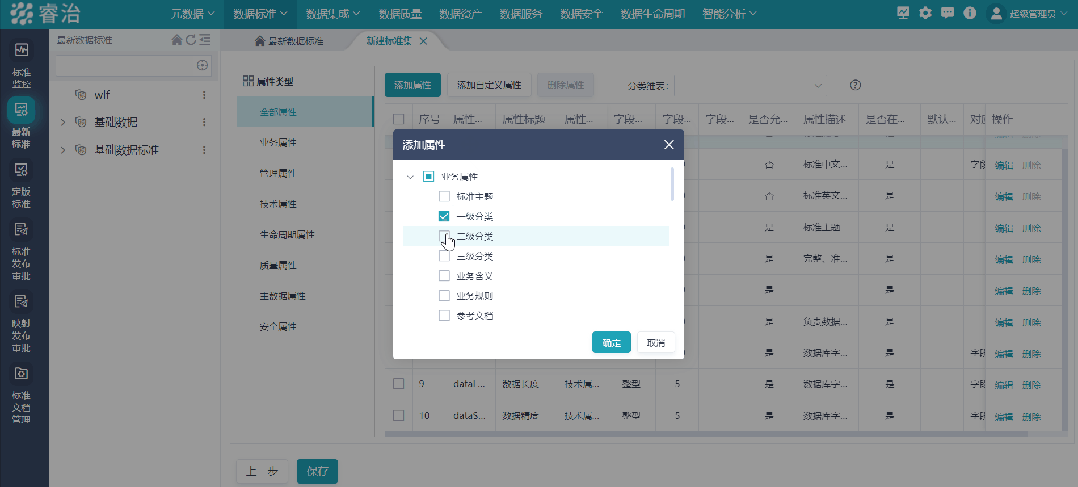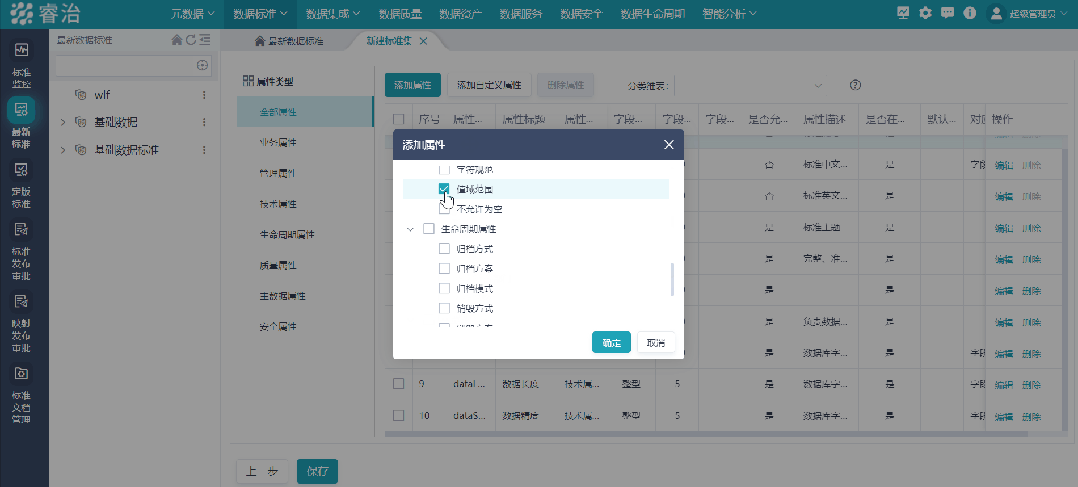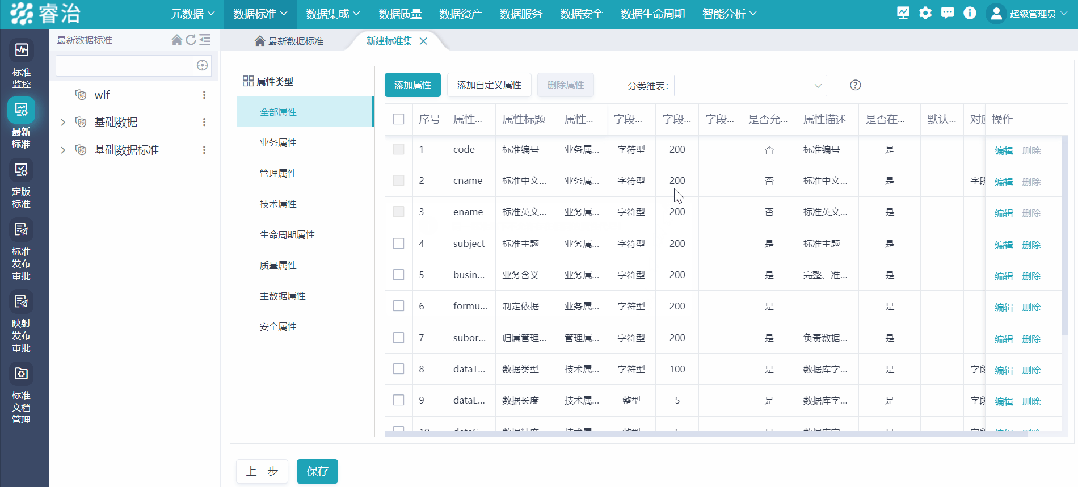
第二件事:把数据质量管理内嵌到流程里
这里有一个思维误区,很多企业这样干:先让数据进来,进来之后再统一清洗。
这条路走不通。
原因很简单:烂数据一旦进了系统,就开始扩散。它被引用、被复制、被关联,等你发现问题的时候,已经污染了一大片。而且清洗的成本,比在源头卡住要高出几倍不止。
正确的做法是三步:
- 源头定标:数据入库前,先校验是否符合标准,不符合的直接拦截;
- 过程监控:持续监测数据质量的健康度,异常早发现早处理;
- 血缘可溯:每一条数据从哪来、经过哪些加工、流向哪里,要能查得清楚。
这套机制建起来,进AI的数据才是可信的。
第三件事:把业务知识“装进”数据里
这是数据治理里最容易被忽视、但对AI最重要的一步。
光有数据不够,还要让数据“有意义”。
具体怎么做?是要建业务术语库——把“销售额”、“活跃用户”、“复购率”这些词,和背后的计算逻辑、口径说明、适用场景挂钩,形成一套机器可读的“业务语言”。
举个例子,“销售额”这个字段,在术语库里要标清楚:含税还是不含税、退货前还是退货后、适用哪些渠道、是否叠加了某个促销活动的数据。这些标注做完,AI在调用这个字段时,处理的不是一列孤立的数字,而是一个有上下文、有业务含义的概念。你懂我意思吗?同样是“销售额下滑”,有了这些上下文,AI才能判断是真的下滑,还是因为退货政策调整、还是活动结束后的正常回落。
这样,当业务部门用自然语言问AI“为什么A产品在华东区上个月销售额下滑了?”AI才能听懂问题,才知道去哪找答案,才能关联产品数据、物流数据、竞品动态、营销活动记录,给出一个有逻辑、有依据的回答。
少了这一步,AI永远只是个高级计算器,给不了真正的业务洞察。
四、落地顺序怎么排
如果你现在手头有一个AI项目正在推,或者正在规划,我建议按这个优先级来:
第一步:摸清现状。 把AI要用到的那几个核心数据域先摸一遍——数据在哪个系统、口径是否统一、质量问题出在哪、有没有权威来源。这一步不要贪多,围绕AI的场景来。
第二步:先做标准,再做AI。 这不是在拖AI项目,这是在给AI项目买保险。标准没定清楚,AI项目大概率是在白忙活。
第三步:选对工具。 数据治理的三件事——标准管理、质量监控、元数据管理,都有专业工具可以用。比如睿治数据治理平台可以在数据入库前设定全局清洗规则,不符合标准的数据直接拦截,不用等数据进来再手工处理,省掉大量事后救火的功夫。
第四步:持续运营,别当项目做。 数据治理不是做完就结束的事。数据在变,业务在变,治理机制要跟着动。建议每月做一次数据质量检查,发现问题及时处理,别让治好的数据再慢慢烂掉。
打好地基,AI才是加速器
沃尔玛是全球最早在AI应用上大规模投入的零售企业之一。但他们在大规模铺AI之前,花了好几年时间做一件事——把供应链数据、销售数据、供应商数据统一打通、标准化。这件事不性感,不好看,也不是一个季度能出成绩的。但正是因为这件事做扎实了,后来他们的AI一上来就能跑,在供应链这块削成本、降缺货、优化配送,效果显著。
你懂我意思吗?地基不是障碍,地基是速度。
说到最后,我想强调一件事:AI能不能落地,决定权不在模型,在数据。
我一直坚持一个观点:数据质量是企业智能化的真正门槛。买模型容易,打地基难。但偏偏只有地基扎实了,上面盖什么都稳。
想做AI,先把数据治理整明白。这不是绕弯路,这是最短的路。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号