LMCache 分层存储架构与调度机制详解

LMCache 分层存储架构与调度机制详解

Henry Zhang
发布于 2026-03-04 13:23:53
发布于 2026-03-04 13:23:53
本文转自公众号 AI原力注入 的原创文章,在大模型推理中,KV Cache 的管理是提升吞吐和降低延迟的关键。本文深度剖析 LMCache 的多级存储架构,揭秘它是如何通过 L1-L4 分层设计及智能调度机制,实现缓存的“极速访问”与“无限扩展”。
LMCache 分层存储架构与调度机制详解
本文档深入剖析 LMCache 的多级存储架构及其代码实现机制。重点阐述核心组件 StorageManager 如何协同管理内存 (L1)、弹性互联 (L2)、本地磁盘 (L3) 及远程共享存储 (L4),并通过智能调度策略实现 KV Cache 的高效流转与生命周期管理。
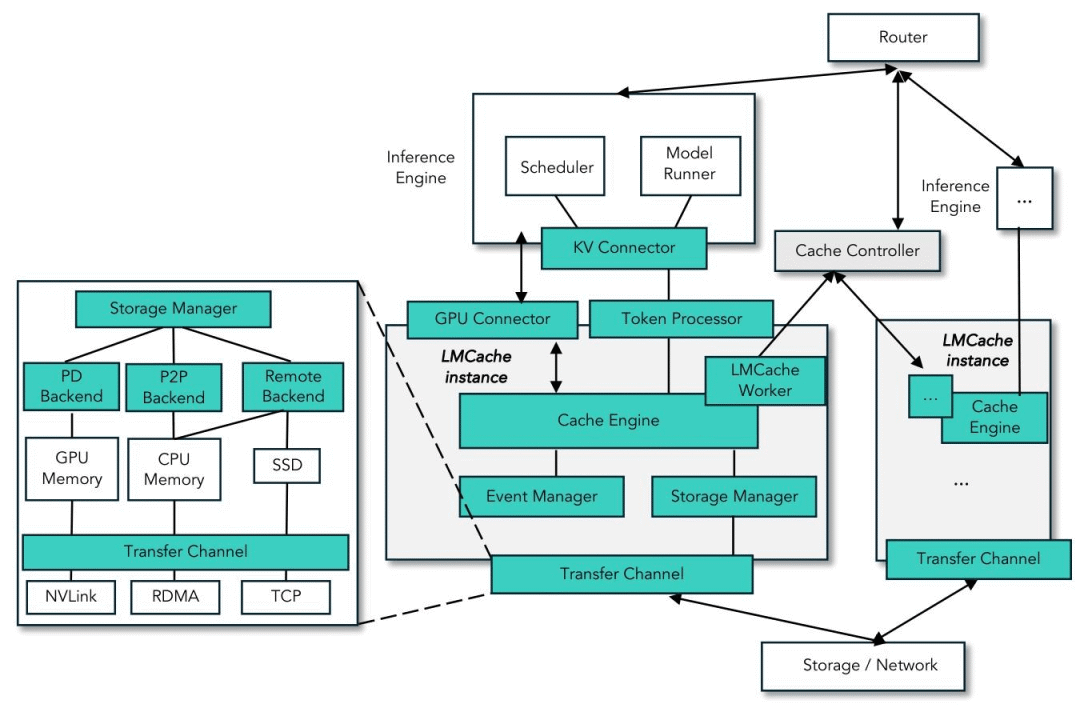
相关文章:LMCache 架构概览,持续更新,请参考:https://github.com/ForceInjection/AI-fundermentals/blob/main/inference/lmcache/lmcache_overview.md
说明:为了更清晰地阐述多级存储架构,本文引入了 L1 (内存)、L2 (弹性互联)、L3 (磁盘)、L4 (远程) 的分层概念。该模型旨在反映各存储介质的访问延迟与层级关系,并非 LMCache 代码中的官方命名。
1. 核心组件概览
LMCache 的存储系统采用模块化设计,主要由调度管理层和分级存储后端两部分构成。
1.1 调度与接口
这一层定义了系统的控制逻辑与交互规范,确保数据在复杂的多级存储结构中能够高效、准确地流转。
- • StorageManager: 核心调度器。负责协调所有存储后端,实现数据的分层写入 (Write-All) 和流水线检索 (Waterfall),并管理数据的生命周期(如自动提升)。
- • StorageBackendInterface: 统一抽象接口。定义了
put,get,exists等标准操作,所有存储后端均需实现此接口,确保了系统的可扩展性。
1.2 分级存储后端
LMCache 将存储介质划分为四个层级(部分层级可选),依据访问速度与容量成本的权衡,构建了从本地内存到远程服务的全方位存储体系。
L1: 极速内存层 (Memory Tier):
- • LocalCPUBackend: 默认的一级缓存。基于本地 CPU 内存,速度极快。它通常兼任内存分配器 (Allocator) 的角色,直接服务于 GPU 的换入换出。
- • PDBackend: (可选) 专为 Prefill-Decode 分离场景设计的特殊后端。在 Decoder 节点上替代
LocalCPUBackend充当 Allocator,基于 GPU 显存,负责接收来自 Prefiller 的数据流。
L2: 弹性互联层 (P2P Tier):
- • P2PBackend: (可选) 基于点对点通信的后端。当本地内存未命中时,优先尝试从其他节点的内存中拉取数据,速度通常快于本地磁盘。
L3: 本地持久层 (Disk Tier):
- • LocalDiskBackend: (可选) 基于本地磁盘(NVMe SSD 推荐)。容量巨大但速度慢于内存/网络,利用
O_DIRECT和异步 I/O 技术作为后备缓存,适合存储被逐出的冷数据。
L4: 远程共享层 (Remote/Shared Tier):
- • RemoteBackend: (可选) 基于中心化存储服务(如 LMCache Server, Redis)。用于跨实例共享数据,支持多实例集群。
2. StorageManager:核心调度器
StorageManager 是整个多级存储的大脑,位于 lmcache/v1/storage_backend/storage_manager.py。它负责初始化存储后端、分发存储请求以及协调数据检索。
2.1 初始化与后端创建
在 StorageManager.__init__ 中,它调用 CreateStorageBackends 来创建并初始化所有启用的存储后端。这些后端被存储在一个 OrderedDict 中,这个顺序至关重要,因为它定义了数据检索的优先级(层级)。
# lmcache/v1/storage_backend/storage_manager.py
class StorageManager:
def __init__(self, config, metadata, ...):
# ...
self.storage_backends: OrderedDict[str, StorageBackendInterface] = (
CreateStorageBackends(
config,
metadata,
self.loop,
dst_device,
lmcache_worker,
)
)2.2 数据存储逻辑 (Put)
StorageManager 的存储策略倾向于 "Write-All" (全写模式)。当调用 batched_put 时,它会将数据分发给所有活跃的存储后端。
为了保证主线程(通常是 GPU 推理线程)不被阻塞,batched_put 采用了以下优化:
- 1. 非阻塞提交:
backend.batched_submit_put_task是非阻塞的,它通常会将任务放入后台队列(如LocalDiskBackend的线程池)。 - 2. 异步数据拷贝: 对于需要从 GPU 拷贝到 CPU 的数据(D2H),
StorageManager使用独立的 CUDA Stream (internal_copy_stream) 进行异步拷贝,避免阻塞计算流。
# lmcache/v1/storage_backend/storage_manager.py
def batched_put(self, keys, memory_objs, ...):
# ...
for backend_name, backend in self.storage_backends.items():
# ...
# 如果需要,使用 CUDA Stream 异步拷贝数据到 CPU
if cname not in obj_dict:
new_keys, new_objs = allocate_and_copy_objects(
allocator_backend, keys, memory_objs, self.internal_copy_stream
)
obj_dict[cname] = (new_keys, new_objs)
# 提交非阻塞任务
backend.batched_submit_put_task(ks, objs, transfer_spec=transfer_spec)这种机制确保了数据在各个层级(如 L1 内存、L3 磁盘、L4 远程)都有副本。
2.3 数据检索逻辑 (Get)与自动提升 (Promotion)
StorageManager 提供了同步和异步两种检索方式。它们都遵循 "层级遍历" (Waterfall) 的原则:按照 storage_backends 中定义的顺序,依次查询数据。
更重要的是,StorageManager 在 get 方法中实现了 "自动提升" (Promotion / Write-Back) 机制:当数据在低层级(如 L3 Disk 或 L4 Remote)被找到时,它会被自动写回高层级(L1 CPU),以加速后续的访问。
# lmcache/v1/storage_backend/storage_manager.py
def get(self, key, location=None):
# 遍历所有活跃的后端(按顺序:CPU -> P2P -> Disk -> Remote)
for backend_name, backend in self.get_active_storage_backends(location):
memory_obj = backend.get_blocking(key)
if memory_obj:
# 如果不是从 L1 获取的,则提升到 L1
if (
backend_name not in ["LocalCPUBackend", "PDBackend"]
and "LocalCPUBackend" in self.storage_backends
):
local_cpu_backend = self.storage_backends["LocalCPUBackend"]
local_cpu_backend.submit_put_task(key, memory_obj)
return memory_obj
return None这种机制确保了 LMCache 总是优先从速度最快的层级(如 CPU)获取数据,如果未命中,再尝试下一层级(如 Disk)。
2.4 缓存逐出策略 (Cache Eviction Policy)
由于 L1 (LocalCPUBackend) 和 L3 (LocalDiskBackend) 的容量有限,LMCache 必须通过高效的策略管理数据生命周期。
注意:
PDBackend作为特殊的 L1 实现,不参与自动缓存逐出。当内存不足时,它会阻塞等待直到有可用内存(通常依赖上层应用释放)。只有LocalCPUBackend支持以下逐出策略。
- • 策略目标: 最大化高层级存储的命中率。
- • Write-All 的优势: 由于数据在写入时已分发到底层(如 Remote),L1 的逐出不会导致数据丢失,无需复杂的“下沉 (Write-Back)”操作,直接释放内存即可。
- • 支持算法:
- • LRU (默认): 优先淘汰最久未使用的 Key。
- • LFU/FIFO/MRU: 可根据访问模式灵活配置。
3. 存储后端详解
本章详细解析 LMCache 中关键存储后端的实现细节,包括内存分配器 (PDBackend / LocalCPUBackend)、本地磁盘 (LocalDiskBackend) 和远程存储 (RemoteBackend)。
3.1 存储层级构建
存储后端的创建顺序定义在 lmcache/v1/storage_backend/__init__.py 中的 CreateStorageBackends 函数里。
lmcache/v1/storage_backend/__init__.py
目前的层级顺序是固定的(Hardcoded):
- 1. PDBackend: 如果启用 P-D 分离 (
enable_pd=True),它是第一个被创建的,并替代 LocalCPUBackend 成为核心 Allocator。 - 2. LocalCPUBackend: 如果未启用 PD,它总是第一个被创建。如果启用了 PD 且
local_cpu=True,它也会被创建,但在 PDBackend 之后。 - 3. P2PBackend: 如果启用 P2P,优先级高于磁盘和远程。
- 4. LocalDiskBackend: 如果配置了
local_disk路径,则创建。 - 5. GdsBackend: GPUDirect Storage 后端(如果启用)。
- 6. RemoteBackend: 远程存储后端。
- 7. Dynamic Plugins: 通过
storage_plugin_launcher加载的自定义后端(如果有配置)。
重要说明:内存分配器 (Allocator) 的必要性 系统必须启用
LocalCPUBackend或PDBackend其中之一。这是因为它们不仅作为存储后端,还实现了AllocatorBackendInterface,承担了内存分配器 (Allocator) 的角色。 即使数据最终只存储在远程 (RemoteBackend),系统也需要先通过 Allocator 分配本地 CPU 内存 或 GPU 显存 作为中转 Buffer,才能将数据发送到远程。因此,Allocator 后端是系统运行的基石。
3.2 LocalCPUBackend (L1) 实现细节
LocalCPUBackend 位于 lmcache/v1/storage_backend/local_cpu_backend.py,利用系统内存存储 KV Cache。它是 LMCache 最基础的存储后端,也是默认的内存分配器 (Allocator)。
3.2.1 内存分配与逐出 (Eviction)
LocalCPUBackend 负责管理有限的内存资源。当调用 allocate 分配内存时,如果当前内存不足,它会触发逐出机制。逐出策略是可插拔的,通过 CachePolicy 接口实现。
- 1. 检查容量: 判断是否有足够的空闲内存块(Chunk)。
- 2. 获取逐出候选: 调用
cache_policy.get_evict_candidates获取最近最少使用的 Key。 - 3. 释放内存: 将选中的 Key 从
hot_cache中移除。由于 LMCache 采用 Write-All 策略,这些数据通常已存在于磁盘或远程后端,因此直接丢弃是安全的。
# lmcache/v1/storage_backend/local_cpu_backend.py
def allocate(self, ...):
# ...
while True:
# 尝试逐出
if self.use_hot:
evict_keys = self.cache_policy.get_evict_candidates(self.hot_cache, ...)
if evict_keys:
self.batched_remove(evict_keys, force=False)
# ...3.3 PDBackend(L1)实现细节
PDBackend (位于 lmcache/v1/storage_backend/pd_backend.py) 是为了支持 Prefill-Decode 分离 (Disaggregation) 架构而设计的特殊后端。在此架构中,计算负载被拆分为 Prefill(预填充)和 Decode(解码)两个阶段,通常部署在不同的实例甚至机器上。
3.3.1 核心角色与功能
PDBackend 根据配置 (pd_role) 扮演两种角色,并替代 LocalCPUBackend 成为系统的内存分配器 (Allocator):
- 1. Sender (Prefiller):
- • 职责: 负责计算 Prompt 的 KV Cache。
- • 行为: 它作为 Allocator 分配内存,但在
put操作时,不进行本地存储,而是直接通过网络将数据推送到 Receiver。 - • 数据流: GPU -> GPU Buffer -> Network (Proxy/Direct) -> Receiver。
- 2. Receiver (Decoder):
- • 职责: 负责接收 KV Cache 并进行后续的 Token 生成。
- • 行为: 启动监听服务,接收来自 Sender 的数据并存入本地内存/显存,供推理引擎直接使用。
3.3.2 与 LocalCPUBackend 的关系
在 StorageManager 初始化时:
- • 如果
enable_pd=True,系统会初始化PDBackend。 - • 此时
PDBackend成为主要的 Allocator (_get_allocator_backend返回PDBackend)。 - •
LocalCPUBackend可能仍会被初始化(如果local_cpu=True),但主要作为本地缓存使用,而非核心分配器。
# lmcache/v1/storage_backend/storage_manager.py
def _get_allocator_backend(self, config):
if self.enable_pd:
return self.storage_backends["PDBackend"]
else:
return self.storage_backends["LocalCPUBackend"]这一设计允许 LMCache 在保持统一存储接口的同时,支持高性能的跨实例 KV Cache 传输流。
3.4 P2PBackend 实现细节
P2PBackend 位于 lmcache/v1/storage_backend/p2p_backend.py,它在存储层级中拥有比本地磁盘更高的优先级。这意味着当本地 CPU 未命中时,系统会优先尝试从其他节点的 CPU 内存中拉取数据,而不是读取本地磁盘。
3.4.1 查找机制 (Multi-Tier Lookup)
P2PBackend 采用分层查找策略来定位数据,以最小化延迟:
- 1. Tier 1: 本地查找缓存 (Local Lookup Cache): (开发中) 尝试在本地维护的元数据缓存中查找,如果命中则直接发起连接。
- 2. Tier 2: 控制面查找 (Controller Lookup): 向
Cache Controller发送批量查找请求 (BatchedP2PLookupMsg)。Controller 维护了全局的 Key 分布视图(RegistryTree),返回持有数据的 Peer 节点地址。 - 3. Tier 3: 确认与传输: 在建立连接并请求数据时,隐式地确认数据是否存在。
3.4.2 数据传输 (Data Plane)
- • NIXL 传输通道: 使用
CreateTransferChannel创建抽象传输通道,底层可支持 RDMA、TCP 等多种协议。 - • 零拷贝: 结合
LocalCPUBackend的内存池,尽量实现数据在网络与 GPU/CPU 之间的零拷贝传输。
3.5 LocalDiskBackend (L3) 实现细节
LocalDiskBackend 位于 lmcache/v1/storage_backend/local_disk_backend.py。
3.4.1 依赖 LocalCPUBackend
值得注意的是,LocalDiskBackend 在初始化时需要传入 local_cpu_backend。这是因为磁盘 I/O 通常需要经过 CPU 内存作为中转(Buffer),或者在读取后将数据“提升”回 CPU 缓存以加速后续访问。
3.4.2 异步 I/O 与优先级队列
为了不阻塞主线程,LocalDiskBackend 使用了一个专门的 Worker 类 LocalDiskWorker,内部维护了一个 AsyncPQThreadPoolExecutor(基于优先级的线程池执行器)来处理磁盘读写任务。
任务优先级(Priority)设计如下(数值越小优先级越高):
- • Prefetch (0): 预取任务优先级最高,确保读取路径的低延迟。
- • Delete (1): 删除任务次之。
- • Put (2): 写入任务优先级最低,作为后台任务运行。由于写入操作通常发生在推理生成之后,降低其优先级可以避免抢占 I/O 资源,确保前台推理和关键的预取任务(Prefetch)不受影响。
# lmcache/v1/storage_backend/local_disk_backend.py
class LocalDiskWorker:
def __init__(self, loop):
# 使用线程池进行磁盘 I/O
self.executor = AsyncPQThreadPoolExecutor(loop, max_workers=4)
async def submit_task(self, task_type, ...):
if task_type == "prefetch":
priority = 0
elif task_type == "delete":
priority = 1
elif task_type == "put":
priority = 2
# ...3.4.3 文件存储结构与 O_DIRECT
- • 文件映射: 每个 Key 对应磁盘上的一个独立文件,文件名由 Key 的字符串表示转换而来(
/替换为-,后缀.pt)。 - • O_DIRECT: 支持使用
O_DIRECT标志打开文件,绕过操作系统页缓存(Page Cache),直接在用户空间缓冲区和磁盘之间传输数据,减少内存拷贝并降低 CPU 开销。
# lmcache/v1/storage_backend/local_disk_backend.py
def write_file(self, buffer, path):
# ...
if size % self.os_disk_bs != 0 or not self.use_odirect:
with open(path, "wb") as f:
f.write(buffer)
else:
# 使用 O_DIRECT 进行高性能写入
fd = os.open(path, os.O_CREAT | os.O_WRONLY | os.O_DIRECT, 0o644)
os.write(fd, buffer)
os.close(fd)3.6 RemoteBackend (L4) 实现细节
RemoteBackend 位于 lmcache/v1/storage_backend/remote_backend.py,作为四级缓存,负责与远程存储服务交互。
3.5.1 RemoteConnector 抽象
为了支持多种远程存储后端(如 Redis, S3, Memcached 等),RemoteBackend 使用了 RemoteConnector 抽象层。
- • RemoteConnector: 定义了与远程服务交互的通用接口(如
put,get,exists)。 - • Serde (序列化/反序列化): 在网络传输前,KV Cache 需要被序列化。
RemoteBackend使用CreateSerde工厂创建序列化器(如CacheGen编码器),以优化传输效率。
3.5.2 异步操作与连接管理
RemoteBackend 同样支持异步操作,并通过 RemoteMonitor 动态监控连接状态。如果连接断开,它会尝试自动重连,并在断连期间降级服务(例如返回 False),避免阻塞本地推理。
# lmcache/v1/storage_backend/remote_backend.py
class RemoteBackend(StorageBackendInterface):
def __init__(self, ...):
# ...
# 初始化序列化器
self.serializer, self.deserializer = CreateSerde(...)
# 启动连接监控
self.remote_monitor = RemoteMonitor(self)
self.remote_monitor.start()4. 典型部署场景与后端组合
LMCache 根据应用场景的不同,通过配置组合出不同的存储后端拓扑。
4.1 单实例加速
本模式是 LMCache 最基础的用法,旨在通过利用本地资源(CPU 内存和磁盘)来加速单机环境下的推理任务,特别适合开发、测试以及对延迟敏感的单实例服务。
- • 场景说明: 适用于开发测试或单机服务场景。利用本地内存 (RAM) 和磁盘 (Disk) 缓存历史 KV 数据,加速本地复用的 Prompt,减少重复计算。
- • 关键配置:
- •
local_cpu=True - •
local_disk=Path(可选)
- •
- • 激活后端 (按层级):
- 1.
LocalCPUBackend - 2.
LocalDiskBackend(可选)
- 1.
- • 读写流程:
- • Write:
- 1. GPU 数据拷贝到 CPU (
LocalCPUBackend)。 - 2. 若配置了磁盘,异步提交任务给
LocalDiskBackend,后台线程将数据写入磁盘文件。
- 1. GPU 数据拷贝到 CPU (
- • Read:
- 1. 查询
LocalCPUBackend,若命中则直接使用。 - 2. 若未命中则查询
LocalDiskBackend。 - 3. 磁盘命中后,读取文件并将数据加载到 CPU。
- 4. 触发 Promotion 机制,将数据写回
LocalCPUBackend以加速后续访问。
- 1. 查询
- • Write:
4.2 多实例共享 - 中心化模式
本模式通过引入中心化的存储服务,实现了多实例间的 KV Cache 共享,适用于中小型集群或对一致性要求较高的场景。
- • 场景说明: 适用于多节点共享 KV Cache 的场景。假设有两个实例 Instance A 和 Instance B。Instance A 生成的 KV Cache 可以被 Instance B 复用。数据通过中心化的 LMCache Server (支持 Redis/S3 协议) 传输。
- • 关键配置:
- •
remote_url="lm://<host>:<port>"
- •
- • 激活后端 (按层级):
- 1.
LocalCPUBackend - 2.
RemoteBackend
- 1.
- • 读写流程:
- • Write (Instance A):
- 1. 数据存入本地
LocalCPUBackend。 - 2.
StorageManager通过RemoteBackend异步将数据序列化。 - 3. 通过网络发送给
LMCache Server进行持久化存储。
- 1. 数据存入本地
- • Read (Instance B):
- 1. 查询本地
LocalCPUBackend(未命中)。 - 2. 查询
RemoteBackend,向 Server 发送 Lookup 请求。 - 3. 若数据存在,从 Server 下载数据并反序列化到本地 CPU。
- 4. 触发 Promotion 机制,将数据提升到 Instance B 的
LocalCPUBackend。
- 1. 查询本地
- • Write (Instance A):
4.3 多实例共享 - P2P 模式
本模式专为大规模高并发集群设计,去除了中心化存储瓶颈,通过点对点直接传输实现高性能的数据共享。
- • 场景说明: 适用于大规模分布式集群。假设 Instance A 持有热门 KV Cache,Instance B 需要访问它。实例间直接传输数据,
Cache Controller仅负责元数据管理和对等点发现。 - • 关键配置:
- •
enable_p2p=True
- •
- • 激活后端 (按层级):
- 1.
LocalCPUBackend - 2.
P2PBackend
- 1.
- • 读写流程:
- • Write (Instance A):
- 1. 数据存入本地
LocalCPUBackend。 - 2.
P2PBackend异步向Cache Controller发送ADMIT消息,注册 KV Cache 的位置信息。
- 1. 数据存入本地
- • Read (Instance B):
- 1. 查询本地
LocalCPUBackend(未命中)。 - 2.
P2PBackend向Cache Controller发起查询,获取持有数据的节点列表 (如 Instance A)。 - 3. Instance B 与 Instance A 建立 P2P 连接,直接从 Instance A 拉取数据。
- 4. 数据加载到 Instance B 的 CPU,并提升到
LocalCPUBackend。
- 1. 查询本地
- • Write (Instance A):
特别说明:
- • 当前 LMCache 的 P2P 协议仅支持从 内存 (LocalCPUBackend) 共享数据。
- • 如果 Instance A 的 KV Cache 被逐出到磁盘 (LocalDiskBackend): Instance A 收到 P2P 查询请求时,仅会检查内存。由于数据不在内存中,Instance A 会返回 "未找到" (Miss)。因此,Instance B 无法获取该数据,将视作 Cache Miss 并重新计算。即 P2P 共享无法穿透到磁盘层。
- • 代码:
lmcache/v1/storage_backend/p2p_backend.py中的_handle_batched_lookup_and_get方法仅调用了local_cpu_backend。
# lmcache/v1/storage_backend/p2p_backend.py
async def _handle_batched_lookup_and_get(
self, msg: BatchedLookupAndGetMsg
) -> P2PMsgBase:
# ...
# 仅查询本地 CPU 后端 (Memory)
num_hit_chunks = await self.local_cpu_backend.batched_async_contains(
lookup_id=lookup_id,
keys=keys,
pin=True,
)
mem_objs = await self.local_cpu_backend.batched_get_non_blocking(
lookup_id=lookup_id,
keys=keys[:num_hit_chunks],
)
# ...设计思考 (Design Rationale): 为什么 P2P 不穿透磁盘?
- 1. 性能隔离 (Performance Isolation): P2P 请求通常发生在 Instance A 正在服务其他推理请求时。强制 Instance A 进行磁盘 I/O 可能会争抢带宽,导致 Instance A 自身的推理延迟增加 (Noisy Neighbor 问题)。
- 2. 延迟可预测性 (Latency Predictability): 内存访问是微秒级的,而磁盘 I/O 是毫秒级的且波动较大。限制 P2P 仅在内存层,保证了该路径的低延迟特性。
- 3. 元数据一致性 (Metadata Consistency): LMCache 的元数据管理策略倾向于 "内存即服务"。当数据从内存逐出时,系统会向 Controller 发送
EVICT信号,从路由表中移除该节点。这种设计简化了状态管理,避免了复杂的跨层级一致性维护。
4.4 分布式推理支持 (Tensor/Pipeline Parallelism)
本模式确保了 LMCache 能够无缝集成到基于张量并行 (TP) 或流水线并行 (PP) 的大模型推理架构中,维持各并行 Rank 的数据一致性。
- • 场景说明: 适用于大模型分布式推理 (TP/PP)。LMCache 在每个 GPU Worker 进程中独立运行,负责管理该 Rank 对应的 KV 切片 (Partition)。
- • 关键配置:
- • 兼容上述任意场景 (1/2/3) 的配置。
- • 激活后端 (按层级):
- • 对应场景的后端组合 (Per-Rank 隔离运行)。
- • 读写流程:
- • Write/Read: 每个 Rank 的 LMCache 实例独立执行上述 (4.1/4.2/4.3) 的流程,仅处理属于自己 Rank 的 KV 数据切片。上层应用 (vLLM) 负责协调各 Rank 的计算。
4.5 Prefill-Decode 分离
本模式针对极致性能优化的 Prefill-Decode 分离架构,通过内存直传机制,实现了跨节点的毫秒级 KV Cache 传输。
- • 场景说明: 专用于 Prefill-Decode 分离架构。Prefiller 节点计算完 Prompt 后,通过
PDBackend直接将 KV Cache 推送给 Decoder 节点。 - • 关键配置:
- •
enable_pd=True
- •
- • 激活后端 (按层级):
- 1.
PDBackend - 2.
LocalCPUBackend(可选)
- 1.
- • 读写流程:
- • Write (Prefiller):
- 1.
StorageManager调用PDBackend。 - 2.
PDBackend作为 Allocator 分配传输 Buffer。 - 3. 数据直接通过网络 (ZMQ) 推送给指定的 Decoder 节点,不进行本地持久化。
- 1.
- • Read (Decoder):
- 1. Decoder 节点的
PDBackend在后台监听并接收数据,存入本地内存字典 (self.data)。 - 2. 推理请求到达时,
StorageManager查询PDBackend。 - 3. 直接从
PDBackend的本地接收缓冲区获取已就绪的 KV Cache,并加载到 GPU 进行 Decode。
- 1. Decoder 节点的
- • Write (Prefiller):
5. 缓存逐出策略详解
本章详细介绍 LMCache 中缓存逐出策略的实现机制。该模块位于 lmcache/v1/storage_backend/cache_policy/,主要被 LocalCPUBackend 和 LocalDiskBackend 调用以维护容量限制。
5.1 策略接口与分层关系
正如 2.4 节 所述,逐出策略的核心目标是最大化高层级存储的命中率。
- • 接口定义: 所有策略继承自
BaseCachePolicy。 - • 与 Write-All 的配合: 策略仅负责选择要丢弃的 Key。由于数据已在底层持久化,后端在收到逐出指令后,只需简单地释放资源。
5.2 支持的策略算法
LMCache 目前支持多种标准的缓存淘汰算法,用户可以通过配置 cache_policy 参数进行选择(默认为 LRU):
- • LRU (Least Recently Used): 默认策略。优先保留最近访问的数据,淘汰最久未使用的。
- • LFU (Least Frequently Used): 优先保留访问频率最高的数据。
- • FIFO (First In First Out): 先进先出,淘汰最早写入的数据。
- • MRU (Most Recently Used): 优先淘汰最近使用的数据(特定场景下使用)。
5.3 实现原理 (以 LRU 为例)
LRU 策略通过维护一个双向链表(在 Python 中通常使用 OrderedDict)来跟踪 Key 的访问历史。
- • On Hit/Put (访问/写入): 每当 KV Cache 被读取或写入时,策略管理器会将对应的 Key 移动到链表末尾 (
move_to_end),标记为“最近活跃”。 - • Eviction (逐出): 当存储空间不足需要释放内存时,策略管理器会从链表头部开始选择 Key 进行删除,因为头部代表了“最久未使用”的数据。
# lmcache/v1/storage_backend/cache_policy/lru.py
class LRUCachePolicy(BaseCachePolicy):
def update_on_hit(self, key, cache_dict):
# 命中时将 Key 移动到末尾,表示最近被使用
cache_dict.move_to_end(key)
def get_evict_candidates(self, cache_dict, num_candidates=1):
# 从字典头部(最久未使用)开始选择需要逐出的 Key
evict_keys = []
for key, cache in cache_dict.items():
if not cache.can_evict: continue
evict_keys.append(key)
if len(evict_keys) == num_candidates: break
return evict_keys5.4 逐出通知机制 (Eviction Notification)
当 KV Cache 被从内存 (LocalCPUBackend) 或磁盘 (LocalDiskBackend) 中逐出时,LMCache 会主动通知 Cache Controller 更新全局元数据。这是保证 P2P 路由准确性的关键。
- • 触发时机: 当后端执行
remove操作(通常由缓存策略触发)时。 - • 通信流程:
- 1. 后端调用
batched_msg_sender.add_kv_op(OpType.EVICT, key)。 - 2.
LMCacheWorker通过长连接异步将EVICT消息批量发送给Cache Controller。 - 3. Controller 更新全局路由表,标记该实例不再持有该 KV Cache。
- 1. 后端调用
- • 相关代码:
- •
lmcache/v1/storage_backend/local_cpu_backend.py:remove方法中发送消息。 - •
lmcache/v1/storage_backend/local_disk_backend.py:remove方法中发送消息。
- •
6. 总结
LMCache 通过精妙的分层存储架构和灵活的调度策略,有效地解决了大模型推理中的 KV Cache 管理难题。
- • 统一调度与分层存储: 核心组件
StorageManager统一管理 L1 (Local CPU/PDBackend)、L2 (P2P)、L3 (Local Disk) 和 L4 (Remote) 多级后端,实现了从极速内存到大容量磁盘再到远程共享存储的无缝衔接。 - • 高效的数据流转: 采用 Write-All 策略确保数据的多级持久化,结合 Waterfall 检索策略和 自动提升 (Promotion) 机制,保证了热点数据始终驻留在最快的存储层级。
- • 多样化的部署支持: 从单实例的 CPU/Disk Offload,到多实例的 P2P 互联与中心化共享,再到专为高吞吐设计的 Prefill-Decode 分离架构,LMCache 能够适应不同规模和需求的生产环境。
- • 极致性能优化: 通过异步 I/O、优先级队列、
O_DIRECT以及智能的缓存逐出策略 (LRU),LMCache 在显著扩展 KV Cache 容量(支持无限上下文)的同时,最大限度地降低了首字延迟 (TTFT) 并提升了推理吞吐量。
欢迎关注 亨利笔记, 👍 点赞 | ⭐ 收藏 | ↗️ 转发。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-02-25,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号