大模型应用:向量与元数据联动:解锁向量数据库复合查询的核心能力.30
原创
大模型应用:向量与元数据联动:解锁向量数据库复合查询的核心能力.30
原创
未闻花名
发布于 2026-02-27 08:03:41
发布于 2026-02-27 08:03:41
一、引言
在大模型与检索增强生成(RAG)技术普及的今天,向量数据库已成为连接非结构化数据与 AI 应用的核心组件。传统向量检索仅依靠向量相似度匹配目标数据,在实际业务场景中却往往力不从心,比如在检索“2024 年发布的 AI 技术论文”时,仅通过向量相似性可能会返回大量无关领域的旧文档。
为解决这一痛点,向量数据库引入了元数据联动机制:在存储向量的同时,关联文本内容、分类标签、时间戳、作者等结构化元数据,支持“向量相似性检索 + 元数据精准过滤”的复合查询模式。这种模式既保留了向量检索对语义的理解能力,又通过元数据实现了对检索范围的精细化约束,成为 RAG、智能问答、内容推荐等场景的关键技术支撑。今天我们深度分析向量与元数据联动的核心原理,从基础概念拆解到技术架构设计,再到完整代码实践与多场景应用,进一步的加深对向量的理解和应用。

二、概念解析
1. 核心概念定义
1.1 向量(Embedding)
向量是将文本、图片、音频等非结构化数据通过模型(如 BERT、Sentence-BERT)转化后的高维数值数组,其核心作用是将语义/特征相似的数据映射到向量空间的相近位置。例如,“猫是宠物” 和 “狗是伴侣动物” 的向量距离会远小于 “猫是宠物” 和 “手机是电子产品” 的向量距离。
1.2 元数据(Metadata)
元数据是描述数据属性的结构化信息,用于补充向量无法表达的“显性特征”。在向量数据库中,常见的元数据类型可分为四类:
- 1. 文本类:原始内容、摘要、关键词、文档标题;
- 2. 分类类:标签(如 “技术文档”“新闻资讯”)、领域(如 “人工智能”“生物医药”)、内容类型(如 “论文”“教程”);
- 3. 时间类:创建时间戳、更新时间、发布日期、有效期;
- 4. 自定义类:作者 ID、文档来源、权限等级、用户 ID、业务线标识。
1.3 复合查询
复合查询是向量相似性检索与元数据过滤的结合查询方式,核心逻辑是通过元数据的结构化约束,缩小向量检索的范围或筛选向量检索的结果,最终返回 “语义相似 + 条件匹配” 的精准结果。其执行逻辑通常分为两种路径:
- 1. 先过滤后检索:通过元数据条件筛选出符合范围的数据集,再在该范围内做向量相似性匹配;
- 2. 先检索后过滤:先全量检索相似向量,再通过元数据过滤掉不符合条件的结果。
2. 复合查询与纯向量检索的对比
纯向量检索仅依赖语义相似性,在实际业务中存在精度、效率、适配性的短板,而复合查询通过元数据联动实现了全方位提升,具体差异如下:
- 1. 从检索精度维度来看
- 纯向量检索易返回语义相似但领域、时间、权限等无关的结果,例如检索“2024 年 AI 论文” 时可能混入 2020 年的机械工程文档;
- 而向量 + 元数据复合检索可通过元数据约束精准锁定符合业务条件的相似数据,仅返回 2024 年发布的 AI 领域文档。
- 2. 从检索效率维度来看
- 纯向量检索需遍历全量向量,当数据量达到百万级以上时,相似性计算耗时显著增加;
- 而复合检索通过元数据过滤提前缩小检索范围,向量比对的数量级大幅降低,查询速度可提升数倍甚至数十倍。
- 3. 从业务适配性维度来看
- 纯向量检索仅适用于无明确约束的模糊检索场景,如“找和这段文字相似的内容”;
- 而复合检索可适配“限定条件 + 相似匹配” 的复杂业务场景,如“找 2024 年 Q2 发布的、面向金融领域的 RAG 教程文档”。
三、技术架构
1. 数据存储架构
向量数据库需同时支撑向量数据的高效检索和元数据的快速过滤,主流采用“混合存储 + 双索引”架构,具体流程如下:
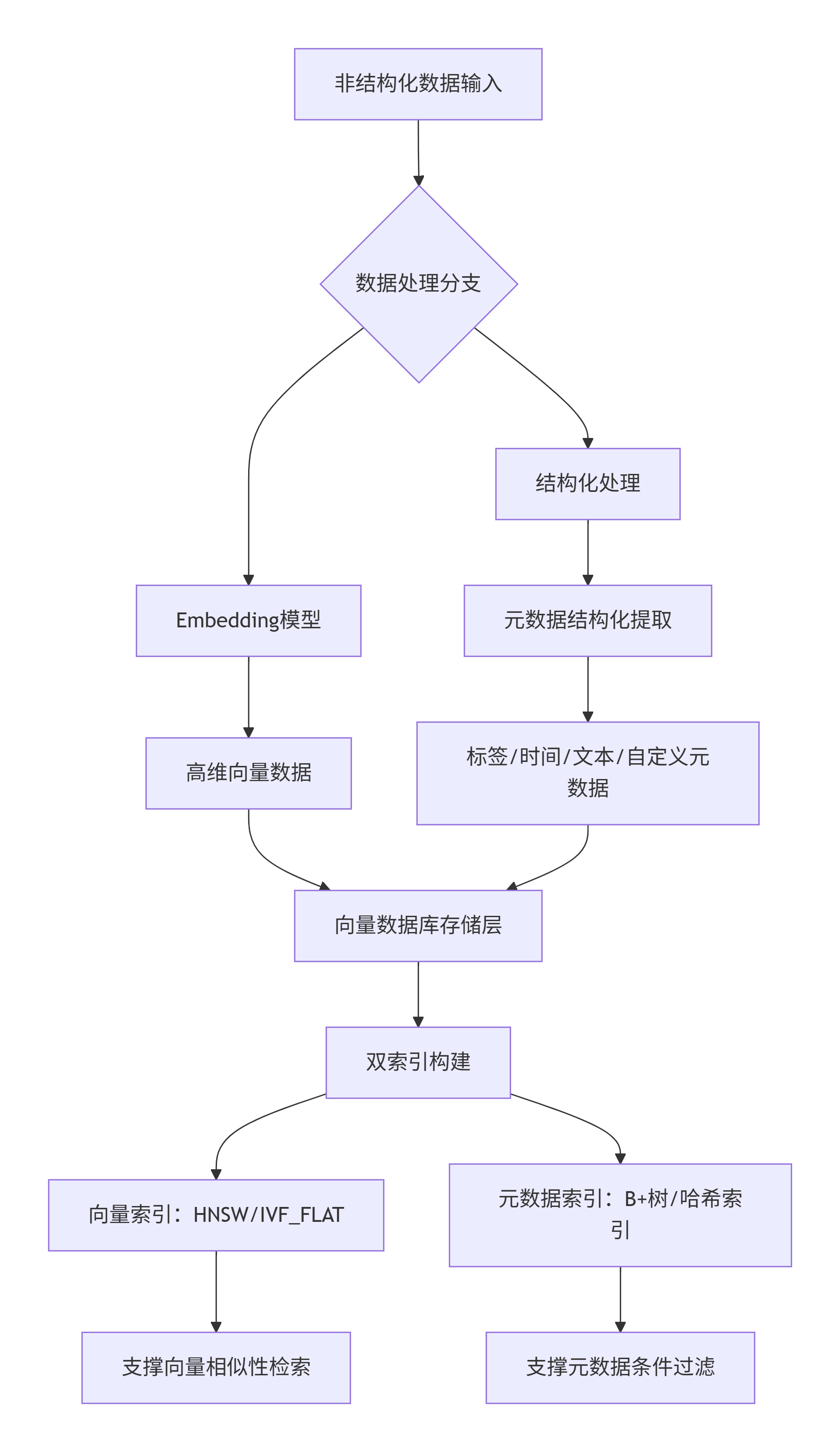
架构说明:
- 1. 非结构化数据(文本 / 图片等)分为两路处理:一路通过 Embedding 模型转化为向量,另一路提取结构化元数据;
- 2. 存储层同时存储向量数据和元数据,并分别构建专用索引:
- 向量索引(如 HNSW)用于加速高维向量的相似性计算;
- 元数据索引(如 B + 树)用于加速等值、范围等条件过滤;
- 3. 双索引协同工作,为复合查询提供底层性能支撑。
2. 复合查询执行流程
复合查询执行的流程,有两种核心路径,首先是元数据过滤优先,注重的是效率,其次是向量检索优先,更注重的是精度,详细对比看看两者的差异;
2.1 路径1:元数据过滤优先
适用于数据量极大、元数据约束条件明确的场景(如“检索 2024 年 10 月发布的大模型相关论文”),执行流程如下:

关键步骤解析:
- 解析条件:提取用户指定的元数据约束(如publish_time >= 2024-10-01、tag = "大模型");
- 元数据过滤:通过元数据索引快速筛选出符合条件的文档 ID,缩小检索范围;
- 向量检索:仅在筛选后的 ID 集合内进行向量相似度计算,减少计算量;
- 结果整合:将相似度排名与元数据信息结合,输出最终结果。
2.2 路径2:向量检索优先
适用于元数据约束较宽松、需优先保证语义相似度的场景(如 “检索与‘RAG 技术原理’相似的文档,并排除 2023 年之前的内容”),执行流程如下:

关键步骤解析:
- 向量检索:先全量检索与查询向量最相似的 Top-K 文档,优先保证语义相似度;
- 元数据过滤:从 Top-K 结果中过滤掉不符合元数据条件的文档;
- 结果补全:若过滤后结果数量不足,重新检索补充相似文档,直至满足需求。
四、示例实践
基于 Chroma 的向量实现元数据复合查询,示例通过“技术文档的向量检索 + 标签 + 时间戳过滤” 复合查询,并增加可视化图例输出
1. Chroma + $gte 多条件过滤
我们先基于向量数据库 Chroma 实现的「电商商品向量检索 + 元数据复合过滤」实战案例,了解对向量数据通过多条件组合检索的功能特性,示例核心目标是从 4 款运动鞋商品中,精准检索出 “语义相似 + 多条件元数据匹配” 的商品。
import chromadb
import datetime
from chromadb.utils import embedding_functions
# 工具函数:日期字符串转Unix时间戳(int)
def date_to_timestamp(date_str):
dt = datetime.datetime.strptime(date_str, "%Y-%m-%d")
return int(dt.timestamp())
# 1. 初始化环境
ef = embedding_functions.SentenceTransformerEmbeddingFunction(model_name="all-MiniLM-L6-v2")
client = chromadb.Client()
collection = client.create_collection("ecommerce_products", embedding_function=ef)
# 2. 插入测试数据(日期转时间戳,统一为int类型)
products = [
"新款运动鞋 轻便透气",
"复古帆布鞋 百搭休闲",
"专业跑步鞋 减震防滑",
"篮球鞋 高帮护踝"
]
# 替换shelf_date为时间戳(int),保留原日期字符串作为冗余字段(方便展示)
metadatas = [
{"price": 199, "shelf_date": "2024-05-10", "shelf_timestamp": date_to_timestamp("2024-05-10"), "sales": 500},
{"price": 89, "shelf_date": "2024-03-15", "shelf_timestamp": date_to_timestamp("2024-03-15"), "sales": 1200},
{"price": 299, "shelf_date": "2024-06-20", "shelf_timestamp": date_to_timestamp("2024-06-20"), "sales": 800},
{"price": 399, "shelf_date": "2024-07-05", "shelf_timestamp": date_to_timestamp("2024-07-05"), "sales": 300}
]
ids = ["p1", "p2", "p3", "p4"]
collection.add(documents=products, metadatas=metadatas, ids=ids)
# 3. $gte 多条件过滤(时间戳数字做数值过滤)
query_text = "运动鞋 舒适"
# 目标日期转时间戳
target_timestamp = date_to_timestamp("2024-05-01")
results = collection.query(
query_texts=[query_text],
where={
"$and": [
{"price": {"$gte": 100}}, # 价格≥100(int)
{"shelf_timestamp": {"$gte": target_timestamp}}, # 上架时间≥2024-05-01(时间戳int)
{"sales": {"$gte": 500}} # 销量≥500(int)
]
},
n_results=2
)
# 4. 输出结果
print("===== 过滤结果 =====")
for i, (doc, meta) in enumerate(zip(results["documents"][0], results["metadatas"][0])):
print(f"商品{i+1}:{doc}")
print(f"元数据:价格={meta['price']} | 上架时间={meta['shelf_date']} | 销量={meta['sales']}\n")输出结果:
===== 过滤结果 ===== 商品1:专业跑步鞋 减震防滑 元数据:价格=299 | 上架时间=2024-06-20 | 销量=800 商品2:新款运动鞋 轻便透气 元数据:价格=199 | 上架时间=2024-05-10 | 销量=500
代码分析:
- 1. 数据层:
- 存储 4 款运动鞋的文本描述(如 “新款运动鞋 轻便透气”),并通过 all-MiniLM-L6-v2 模型自动转化为向量;
- 为每个商品绑定结构化元数据:价格(int)、上架时间(兼容处理为 “日期字符串 + 时间戳数字”)、销量(int),兼顾展示和过滤需求。
- 2. 查询层:
- 向量检索:基于 “运动鞋 舒适” 的语义相似性匹配商品;
- 元数据复合过滤:通过 $and 组合 3 个 $gte 条件(价格≥100、上架时间≥2024-05-01、销量≥500),缩小检索范围。
- 3.执行结果
- 过滤逻辑:仅保留 “价格≥100、2024 年 5 月 1 日后上架、销量≥500” 且与 “运动鞋 舒适” 语义相似的商品;
- 最终结果:筛选出 2 款符合条件的商品(新款运动鞋、专业跑步鞋),排除价格过低(帆布鞋 89 元)或销量不足(篮球鞋 300)的商品。
2. 数据准备与向量转化
import chromadb
import pandas as pd
import matplotlib.pyplot as plt
from chromadb.utils import embedding_functions
from datetime import datetime
# 1. 初始化Embedding模型(使用Sentence-BERT)
sentence_transformer_ef = embedding_functions.SentenceTransformerEmbeddingFunction(
model_name="D:/modelscope/hub/models/sentence-transformers/all-MiniLM-L6-v2"
)
# 2. 初始化Chroma客户端(内存模式)
client = chromadb.Client()
# 3. 创建集合:指定Embedding函数,支持元数据过滤
collection = client.create_collection(
name="tech_docs",
embedding_function=sentence_transformer_ef,
metadata={"hnsw:space": "cosine"} # 余弦相似度计算
)
# 4. 准备测试数据:包含文档内容、元数据(标签、发布时间、来源)
docs = [
"RAG技术核心是将检索到的知识融入大模型生成过程,提升回答准确性",
"向量数据库的索引算法HNSW能够显著提升高维向量的检索效率",
"大模型的微调技术包括LoRA和QLoRA,可在低资源设备上实现模型优化",
"向量与元数据联动是实现复合查询的关键,广泛应用于RAG场景",
"金融领域RAG应用需解决数据隐私问题,常用联邦学习方案",
"2024年最新HNSW优化算法可将向量检索速度提升300%"
]
# 元数据设计:标签(tag)、发布时间(publish_date)、来源(source)
metadatas = [
{"tag": "RAG", "publish_date": "2024-05-10", "source": "技术博客"},
{"tag": "向量数据库", "publish_date": "2024-06-15", "source": "学术论文"},
{"tag": "大模型微调", "publish_date": "2023-12-20", "source": "教程"},
{"tag": "向量数据库", "publish_date": "2024-07-02", "source": "技术博客"},
{"tag": "RAG", "publish_date": "2024-08-18", "source": "行业报告"},
{"tag": "向量数据库", "publish_date": "2024-09-05", "source": "学术论文"}
]
# 文档ID
ids = ["doc1", "doc2", "doc3", "doc4", "doc5", "doc6"]
# 5. 将数据添加到集合(自动转化为向量+存储元数据)
collection.add(
documents=docs,
metadatas=metadatas,
ids=ids
)
print("数据入库完成!共存储{}篇文档".format(len(ids)))输出结果:
数据入库完成!共存储6篇文档
3. 复合查询实现
实现三个典型复合查询场景,并通过图表可视化相似度分布:
- 场景 A:过滤优先 - 检索 2024 年 6 月后发布的、来源为 “学术论文” 的向量数据库相关文档;
- 场景 B:检索优先 - 检索与 “大模型落地应用” 相似的 Top-5 文档,过滤出标签为 “RAG” 的内容;
- 场景 C:多条件嵌套 - 检索 2024 年 5-8 月发布的、标签为 RAG 或向量数据库的技术博客文档。
import chromadb
import pandas as pd
import matplotlib.pyplot as plt
from chromadb.utils import embedding_functions
from datetime import datetime
# ===================== 新增:日期兼容处理工具函数 =====================
def date_to_timestamp(date_str):
"""将YYYY-MM-DD格式的日期字符串转为Unix时间戳(int),适配低版本Chroma的数值过滤"""
dt = datetime.strptime(date_str, "%Y-%m-%d")
return int(dt.timestamp())
def timestamp_to_date(timestamp):
"""将时间戳转回日期字符串,用于结果展示"""
return datetime.fromtimestamp(timestamp).strftime("%Y-%m-%d")
# ===================== 初始化环境 + 数据入库(兼容日期格式) =====================
# 1. 初始化Embedding模型
sentence_transformer_ef = embedding_functions.SentenceTransformerEmbeddingFunction(
model_name="all-MiniLM-L6-v2"
)
# 2. 初始化Chroma客户端
client = chromadb.Client()
# 3. 创建集合
collection = client.create_collection(
name="tech_docs",
embedding_function=sentence_transformer_ef,
metadata={"hnsw:space": "cosine"} # 余弦相似度计算
)
# 4. 准备测试数据(新增publish_timestamp字段,用于数值过滤)
docs = [
"RAG技术核心是将检索到的知识融入大模型生成过程,提升回答准确性",
"向量数据库的索引算法HNSW能够显著提升高维向量的检索效率",
"大模型的微调技术包括LoRA和QLoRA,可在低资源设备上实现模型优化",
"向量与元数据联动是实现复合查询的关键,广泛应用于RAG场景",
"金融领域RAG应用需解决数据隐私问题,常用联邦学习方案",
"2024年最新HNSW优化算法可将向量检索速度提升300%"
]
# 元数据:保留publish_date(字符串,展示用)+ 新增publish_timestamp(时间戳int,过滤用)
metadatas = [
{"tag": "RAG", "publish_date": "2024-05-10", "publish_timestamp": date_to_timestamp("2024-05-10"), "source": "技术博客"},
{"tag": "向量数据库", "publish_date": "2024-06-15", "publish_timestamp": date_to_timestamp("2024-06-15"), "source": "学术论文"},
{"tag": "大模型微调", "publish_date": "2023-12-20", "publish_timestamp": date_to_timestamp("2023-12-20"), "source": "教程"},
{"tag": "向量数据库", "publish_date": "2024-07-02", "publish_timestamp": date_to_timestamp("2024-07-02"), "source": "技术博客"},
{"tag": "RAG", "publish_date": "2024-08-18", "publish_timestamp": date_to_timestamp("2024-08-18"), "source": "行业报告"},
{"tag": "向量数据库", "publish_date": "2024-09-05", "publish_timestamp": date_to_timestamp("2024-09-05"), "source": "学术论文"}
]
ids = ["doc1", "doc2", "doc3", "doc4", "doc5", "doc6"]
# 5. 数据入库
collection.add(
documents=docs,
metadatas=metadatas,
ids=ids
)
# ===================== 工具函数(适配兼容后的元数据) =====================
def plot_similarity(results, title):
"""绘制相似度(距离)分布柱状图"""
distances = results["distances"][0]
doc_ids = [f"文档{idx+1}" for idx in range(len(distances))]
plt.rcParams["font.sans-serif"] = ["SimHei"] # 支持中文
plt.figure(figsize=(8, 4))
plt.bar(doc_ids, distances, color="#4285F4")
plt.title(title)
plt.xlabel("文档")
plt.ylabel("余弦距离(越小越相似)")
plt.grid(axis="y", linestyle="--", alpha=0.7)
plt.tight_layout()
plt.show()
def print_formatted_results(results, scene_name):
"""格式化输出查询结果(展示原日期字符串)"""
print(f"\n===== {scene_name} 查询结果 =====")
for i, (doc, meta, dist) in enumerate(zip(
results["documents"][0],
results["metadatas"][0],
results["distances"][0]
)):
print(f"\n【结果{i+1}】")
print(f"文档内容:{doc}")
# 展示原日期字符串,而非时间戳
print(f"元数据:标签={meta['tag']} | 发布时间={meta['publish_date']} | 来源={meta['source']}")
print(f"余弦距离:{dist:.4f}(越小越相似)")
# ===================== 场景A:过滤优先(日期用时间戳过滤) =====================
query_text_a = "向量数据库优化算法"
# 日期条件转为时间戳数值过滤
target_timestamp_a = date_to_timestamp("2024-06-01")
where_clause_a = {
"$and": [
{"publish_timestamp": {"$gte": target_timestamp_a}}, # 用时间戳int过滤
{"source": "学术论文"},
{"tag": "向量数据库"}
]
}
results_a = collection.query(
query_texts=[query_text_a],
where=where_clause_a,
n_results=2
)
print_formatted_results(results_a, "场景A(过滤优先)")
plot_similarity(results_a, "场景A:向量数据库学术论文相似度分布")
# ===================== 场景B:检索优先(过滤逻辑不变,展示兼容) =====================
query_text_b = "大模型落地应用"
# 先检索Top-5
raw_results_b = collection.query(
query_texts=[query_text_b],
n_results=5
)
# 过滤标签为RAG的文档
filtered_docs = []
filtered_metas = []
filtered_dists = []
for doc, meta, dist in zip(raw_results_b["documents"][0], raw_results_b["metadatas"][0], raw_results_b["distances"][0]):
if meta["tag"] == "RAG":
filtered_docs.append(doc)
filtered_metas.append(meta)
filtered_dists.append(dist)
# 构造过滤后的结果格式
results_b = {
"documents": [filtered_docs],
"metadatas": [filtered_metas],
"distances": [filtered_dists]
}
print_formatted_results(results_b, "场景B(检索优先)")
plot_similarity(results_b, "场景B:大模型应用-RAG文档相似度分布")
# ===================== 场景C:多条件嵌套(日期范围用时间戳过滤) =====================
query_text_c = "AI技术落地实践"
# 日期范围转为时间戳数值
start_timestamp = date_to_timestamp("2024-05-01")
end_timestamp = date_to_timestamp("2024-08-31")
where_clause_c = {
"$and": [
{"publish_timestamp": {"$gte": start_timestamp}},
{"publish_timestamp": {"$lte": end_timestamp}},
{"source": "技术博客"},
{"tag": {"$in": ["RAG", "向量数据库"]}}
]
}
results_c = collection.query(
query_texts=[query_text_c],
where=where_clause_c,
n_results=3
)
print_formatted_results(results_c, "场景C(多条件嵌套)")
plot_similarity(results_c, "场景C:AI技术落地博客相似度分布")输出结果:
===== 场景A(过滤优先) 查询结果 ===== 【结果1】 文档内容:向量数据库的索引算法HNSW能够显著提升高维向量的检索效率 元数据:标签=向量数据库 | 发布时间=2024-06-15 | 来源=学术论文 余弦距离:0.2829(越小越相似) 【结果2】 文档内容:2024年最新HNSW优化算法可将向量检索速度提升300% 元数据:标签=向量数据库 | 发布时间=2024-09-05 | 来源=学术论文 余弦距离:0.5589(越小越相似)
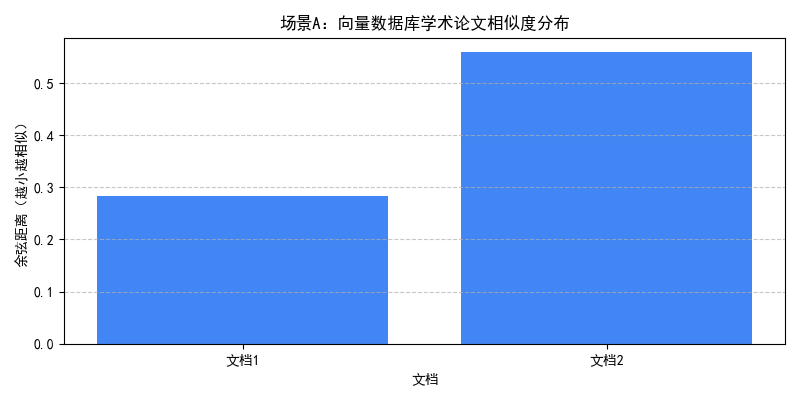
===== 场景B(检索优先) 查询结果 ===== 【结果1】 文档内容:RAG技术核心是将检索到的知识融入大模型生成过程,提升回答准确性 元数据:标签=RAG | 发布时间=2024-05-10 | 来源=技术博客 余弦距离:0.4955(越小越相似) 【结果2】 文档内容:金融领域RAG应用需解决数据隐私问题,常用联邦学习方案 元数据:标签=RAG | 发布时间=2024-08-18 | 来源=行业报告 余弦距离:0.6374(越小越相似)
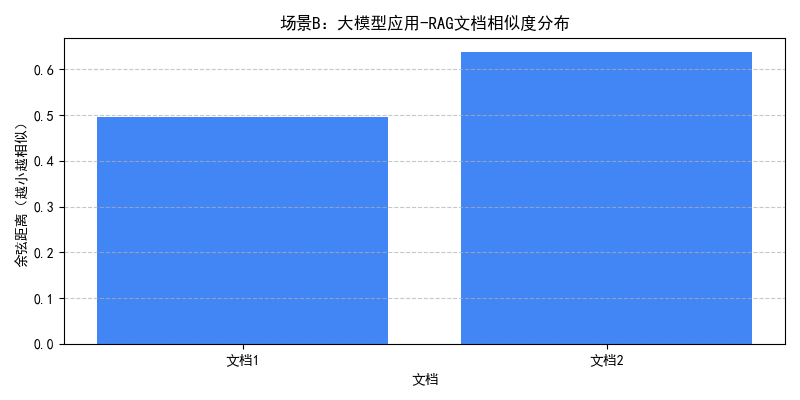
===== 场景C(多条件嵌套) 查询结果 ===== 【结果1】 文档内容:向量与元数据联动是实现复合查询的关键,广泛应用于RAG场景 元数据:标签=向量数据库 | 发布时间=2024-07-02 | 来源=技术博客 余弦距离:0.4942(越小越相似) 【结果2】 文档内容:RAG技术核心是将检索到的知识融入大模型生成过程,提升回答准确性 元数据:标签=RAG | 发布时间=2024-05-10 | 来源=技术博客 余弦距离:0.5478(越小越相似)
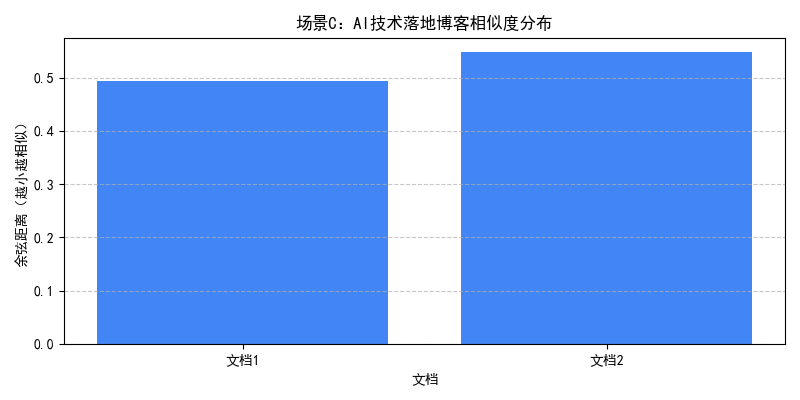
结果说明:
- 场景 A:仅返回doc2(2024-06-15,学术论文)和doc6(2024-09-05,学术论文),这两个文档同时满足元数据约束和向量相似性,柱状图可直观看到doc6的相似度更高(距离更小);
- 场景 B:先检索到 5 篇与 “大模型落地应用” 相似的文档,过滤后仅保留doc1和doc5(标签为 RAG),可视化图表清晰展示两者的相似度差异;
- 场景 C:通过嵌套条件筛选出 2024 年 5-8 月发布的技术博客,且标签为 RAG 或向量数据库的文档(doc1、doc4),实现多维度精准约束。
五、应用场景
向量与元数据联动的复合查询已广泛应用于各行业 AI 场景,以下是 4 个典型落地案例:
1. 企业智能知识库(RAG 场景)
- 业务需求:员工检索 “2024 年发布的、面向金融行业的 Python 风控模型教程”;
- 复合查询设计:
- 向量检索:匹配与 “Python 风控模型” 语义相似的文档;
- 元数据过滤:publish_date >= 2024-01-01 + industry = "金融" + type = "教程";
- 价值:避免返回非金融领域的旧教程,提升知识库检索精准度,降低员工信息筛选成本。
2. 电商智能推荐
- 业务需求:给用户推荐 “近 30 天上架的、价格在 100-500 元的、与用户浏览过的商品相似的运动鞋”;
- 复合查询设计:
- 向量检索:匹配与用户浏览商品向量相似的运动鞋;
- 元数据过滤:shelf_time >= 近30天 + price >= 100 + price <= 500 + category = "运动鞋";
- 价值:结合商品语义相似性和上架时间、价格等属性,提升推荐的精准度和时效性。
3. 医疗文献检索
- 业务需求:医生检索 “2023-2024 年发表的、核心期刊的、与肺癌靶向治疗相关的中文文献”;
- 复合查询设计:
- 向量检索:匹配与 “肺癌靶向治疗” 语义相似的文献;
- 元数据过滤:publish_year in [2023,2024] + journal_level = "核心" + language = "中文";
- 价值:快速定位符合时间、期刊等级约束的相关文献,辅助临床决策。
4. 智能客服工单处理
- 业务需求:客服检索 “近 7 天未解决的、属于支付问题的、与用户当前咨询相似的工单”;
- 复合查询设计:
- 向量检索:匹配与用户咨询内容相似的工单;
- 元数据过滤:create_time >= 近7天 + status = "未解决" + problem_type = "支付";
- 价值:快速找到同类未解决工单,参考历史处理方案,提升客服响应效率。
六、总结
向量与元数据的联动,是向量数据库从“单纯相似性检索”走向“业务级精准检索”的关键一步。通过复合查询模式,我们既发挥了向量对非结构化数据的语义理解能力,又利用元数据实现了业务规则的精准约束,为 RAG、智能推荐、医疗文献检索等场景提供了核心技术支撑。掌握了解向量与元数据的联动技术,为多模态的元数据联度提供了非常大的想象空间,我们也可以根据实际业务需求灵活的扩展。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号