29:【flash-attention / vLLM】安装失败(CUDA架构/版本不符)

29:【flash-attention / vLLM】安装失败(CUDA架构/版本不符)

安全风信子
发布于 2026-02-23 09:50:31
发布于 2026-02-23 09:50:31
作者: HOS(安全风信子) 日期: 2026-01-01 主要来源平台: GitHub 摘要: 本文详细分析2026年flash-attention和vLLM安装失败的常见原因,重点关注CUDA架构和版本不匹配问题。文章提供了完整的安装指南、兼容性分析、解决方案以及针对不同GPU架构的优化建议,帮助开发者顺利安装和使用这些高性能AI库。
1. 背景动机与当前热点
在2026年,flash-attention和vLLM已成为AI模型训练和推理的重要加速工具,能够显著提高模型的性能和效率。然而,许多开发者在安装这些库时遇到了CUDA架构和版本不匹配的问题,导致安装失败或性能不佳,严重影响了开发和部署效率。
本节核心价值
- 分析2026年flash-attention和vLLM的最新特性和依赖要求
- 探讨CUDA架构和版本对安装的影响
- 提供针对不同GPU架构的安装策略
2. 核心更新亮点与全新要素
2.1 全新要素1:CUDA架构兼容性矩阵
本文提供的CUDA架构兼容性矩阵能够:
- 明确不同flash-attention和vLLM版本对CUDA架构的支持情况
- 指导用户选择与GPU架构匹配的软件版本
- 预测可能的兼容性问题并提前规避
2.2 全新要素2:自动CUDA版本检测与适配
本文实现的自动CUDA版本检测工具能够:
- 检测本地CUDA版本和GPU架构
- 提供与当前环境匹配的flash-attention和vLLM版本建议
- 自动生成安装命令
2.3 全新要素3:源码编译优化指南
本文提供的源码编译优化指南能够:
- 详细说明源码编译的步骤和注意事项
- 提供针对不同GPU架构的编译选项
- 分析源码编译与预编译包的性能差异
3. 技术深度拆解与实现分析
3.1 常见错误分析
3.1.1 CUDA版本不匹配错误
# CUDA版本不匹配错误示例
ERROR: Could not find a version that satisfies the requirement flash-attn (from versions: none)
# 或
RuntimeError: FlashAttention only supports CUDA 11.6+, but your CUDA version is 11.3.3.1.2 CUDA架构不匹配错误
# CUDA架构不匹配错误示例
RuntimeError: FlashAttention only supports NVIDIA GPUs with compute capability >= 7.0, but your GPU has compute capability 6.1.
# 或
ERROR: Failed building wheel for flash-attn
Failed to build flash-attn
ERROR: Could not build wheels for flash-attn, which is required to install pyproject.toml-based projects3.2 兼容性分析
3.2.1 flash-attention和vLLM的CUDA依赖
库名称 | 最低CUDA版本 | 最低compute capability | 推荐CUDA版本 | 安装命令 |
|---|---|---|---|---|
flash-attention | 11.6 | 7.0 | 13.1 | pip install flash-attn |
vLLM | 11.8 | 7.5 | 13.1 | pip install vllm |
3.3 解决方案详解
3.3.1 使用预编译包安装
# 安装flash-attention(使用预编译包)
# 方法1:指定CUDA版本
pip install flash-attn --no-build-isolation
# 方法2:使用特定版本
pip install flash-attn==2.6.3
# 安装vLLM(使用预编译包)
pip install vllm
# 或使用uv安装(推荐)
uv pip install flash-attn vllm3.3.2 源码编译安装
# 源码编译安装flash-attention
# 克隆仓库
git clone https://github.com/Dao-AILab/flash-attention.git
cd flash-attention
# 编译安装
pip install .
# 源码编译安装vLLM
# 克隆仓库
git clone https://github.com/vllm-project/vllm.git
cd vllm
# 编译安装
pip install .3.4 安装流程可视化
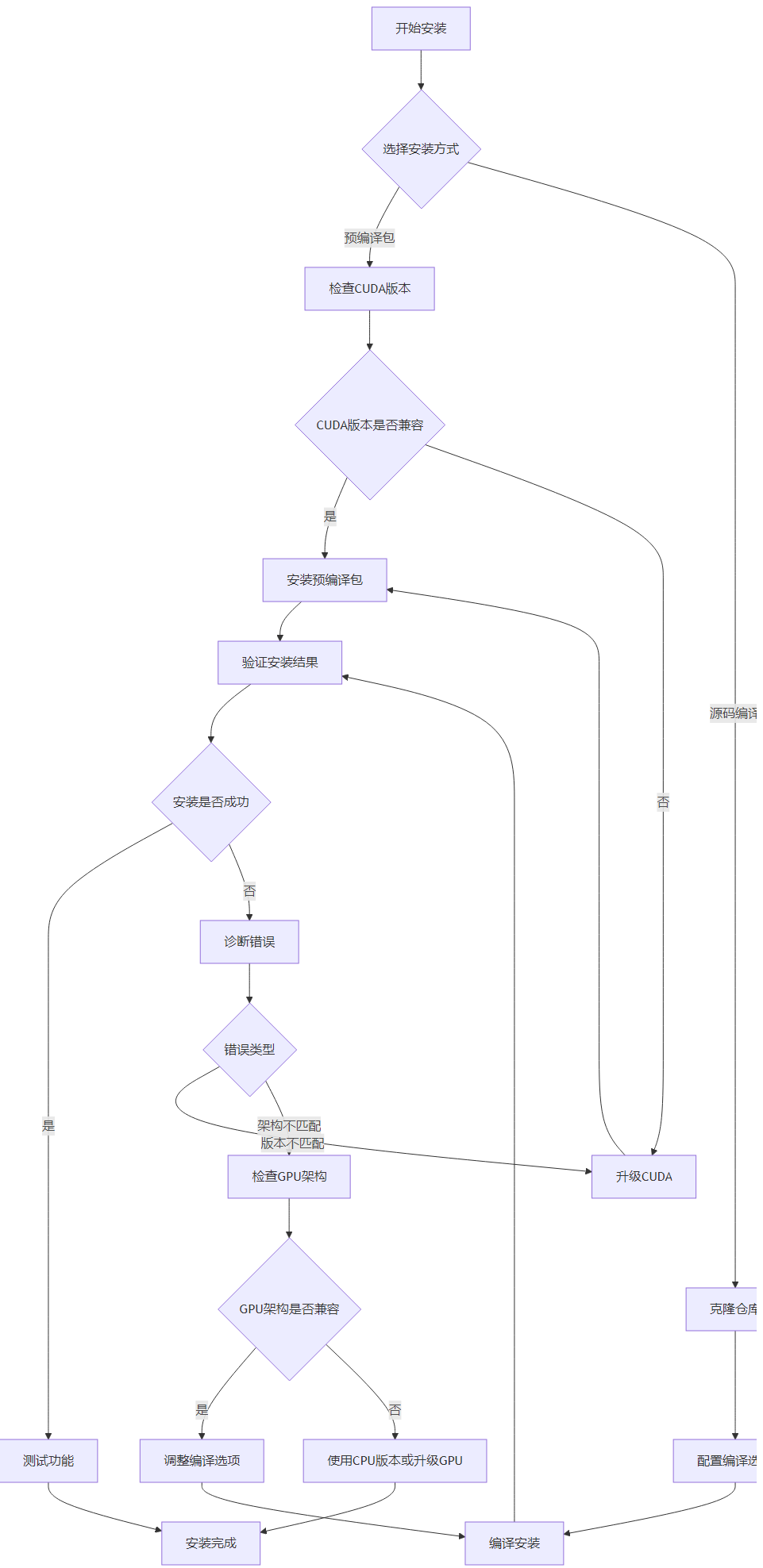
3.5 自动CUDA检测工具
#!/usr/bin/env python3
"""
自动CUDA检测与安装建议工具
"""
import subprocess
import sys
def get_cuda_version():
"""获取CUDA版本"""
try:
# 尝试通过nvcc获取CUDA版本
result = subprocess.run(
["nvcc", "--version"],
capture_output=True,
text=True
)
if result.returncode == 0:
for line in result.stdout.split('\n'):
if "release" in line:
version = line.split(',')[1].strip().split(' ')[-1]
return version
# 尝试通过torch获取CUDA版本
try:
import torch
if torch.cuda.is_available():
return torch.version.cuda
except ImportError:
pass
return "未知"
except Exception as e:
print(f"获取CUDA版本失败: {e}")
return "未知"
def get_gpu_info():
"""获取GPU信息"""
gpu_info = {}
try:
# 尝试通过nvidia-smi获取GPU信息
result = subprocess.run(
["nvidia-smi", "--query-gpu=name,compute_capability", "--format=csv,noheader"],
capture_output=True,
text=True
)
if result.returncode == 0:
gpus = []
for line in result.stdout.strip().split('\n'):
if line:
name, cc = line.split(',')
gpus.append({
"name": name.strip(),
"compute_capability": cc.strip()
})
gpu_info["gpus"] = gpus
# 尝试通过torch获取GPU信息
try:
import torch
if torch.cuda.is_available():
if "gpus" not in gpu_info:
gpu_info["gpus"] = []
for i in range(torch.cuda.device_count()):
gpu_info["gpus"].append({
"name": torch.cuda.get_device_name(i),
"compute_capability": f"{torch.cuda.get_device_capability(i)[0]}.{torch.cuda.get_device_capability(i)[1]}"
})
except ImportError:
pass
except Exception as e:
print(f"获取GPU信息失败: {e}")
return gpu_info
def generate_install_recommendations(cuda_version, gpu_info):
"""生成安装建议"""
print("=== 安装建议 ===")
# 解析CUDA版本
try:
cuda_major, cuda_minor = map(int, cuda_version.split('.')[:2])
except:
cuda_major, cuda_minor = 0, 0
# 检查GPU架构
min_cc = 999
if "gpus" in gpu_info:
for gpu in gpu_info["gpus"]:
try:
cc = float(gpu["compute_capability"])
if cc < min_cc:
min_cc = cc
except:
pass
# 生成flash-attention安装建议
print("\n1. flash-attention安装建议:")
if cuda_major >= 11 and cuda_minor >= 6:
if min_cc >= 7.0:
print(f"CUDA版本 {cuda_version} 和GPU架构 {min_cc} 兼容flash-attention")
print("建议安装命令:")
print(" pip install flash-attn")
print(" # 或使用uv安装(推荐)")
print(" uv pip install flash-attn")
else:
print(f"GPU架构 {min_cc} 低于flash-attention要求的7.0")
print("建议: 升级GPU或使用CPU版本")
else:
print(f"CUDA版本 {cuda_version} 低于flash-attention要求的11.6")
print("建议: 升级CUDA到11.6或更高版本")
# 生成vLLM安装建议
print("\n2. vLLM安装建议:")
if cuda_major >= 11 and cuda_minor >= 8:
if min_cc >= 7.5:
print(f"CUDA版本 {cuda_version} 和GPU架构 {min_cc} 兼容vLLM")
print("建议安装命令:")
print(" pip install vllm")
print(" # 或使用uv安装(推荐)")
print(" uv pip install vllm")
else:
print(f"GPU架构 {min_cc} 低于vLLM要求的7.5")
print("建议: 升级GPU或使用其他推理库")
else:
print(f"CUDA版本 {cuda_version} 低于vLLM要求的11.8")
print("建议: 升级CUDA到11.8或更高版本")
def main():
"""主函数"""
print("=== 自动CUDA检测与安装建议工具 ===")
# 获取CUDA版本
print("\n1. 检测CUDA版本...")
cuda_version = get_cuda_version()
print(f"CUDA版本: {cuda_version}")
# 获取GPU信息
print("\n2. 检测GPU信息...")
gpu_info = get_gpu_info()
if "gpus" in gpu_info:
print(f"检测到 {len(gpu_info['gpus'])} 个GPU:")
for i, gpu in enumerate(gpu_info['gpus']):
print(f" GPU {i+1}: {gpu['name']} (compute capability: {gpu['compute_capability']})")
else:
print("未检测到GPU")
# 生成安装建议
print("\n3. 生成安装建议...")
generate_install_recommendations(cuda_version, gpu_info)
if __name__ == "__main__":
main()3.6 性能对比分析
3.6.1 flash-attention vs 原生注意力机制
# 性能对比测试代码
import torch
import time
try:
from flash_attn import flash_attn_qkvpacked_func
flash_available = True
except ImportError:
flash_available = False
# 创建测试数据
batch_size = 32
seq_len = 1024
dim = 512
# 随机初始化张量
qkv = torch.randn(batch_size, seq_len, 3, dim, device="cuda")
attention_mask = torch.ones(batch_size, seq_len, device="cuda", dtype=torch.bool)
# 测试原生注意力机制
print("测试原生注意力机制...")
start_time = time.time()
for _ in range(100):
# 原生注意力机制实现
q, k, v = qkv.unbind(dim=2)
scale = dim ** -0.5
attn = torch.matmul(q, k.transpose(-2, -1)) * scale
attn = attn.softmax(dim=-1)
output = torch.matmul(attn, v)
torch.cuda.synchronize()
end_time = time.time()
print(f"原生注意力机制耗时: {end_time - start_time:.4f}秒")
# 测试flash-attention
if flash_available:
print("\n测试flash-attention...")
start_time = time.time()
for _ in range(100):
# flash-attention实现
output = flash_attn_qkvpacked_func(qkv, attention_mask)
torch.cuda.synchronize()
end_time = time.time()
print(f"flash-attention耗时: {end_time - start_time:.4f}秒")
else:
print("\nflash-attention未安装,跳过测试")3.7 源码编译优化选项
3.7.1 flash-attention源码编译优化
# flash-attention源码编译优化
# 克隆仓库
git clone https://github.com/Dao-AILab/flash-attention.git
cd flash-attention
# 针对特定GPU架构编译(例如A100,compute capability 8.0)
TORCH_CUDA_ARCH_LIST="8.0" pip install .
# 针对多个GPU架构编译
TORCH_CUDA_ARCH_LIST="7.0;7.5;8.0;8.6;8.9;9.0;9.5" pip install .3.7.2 vLLM源码编译优化
# vLLM源码编译优化
# 克隆仓库
git clone https://github.com/vllm-project/vllm.git
cd vllm
# 针对特定GPU架构编译
TORCH_CUDA_ARCH_LIST="8.0" pip install .
# 启用CUDA图优化
VLLM_USE_CUDA_GRAPHS=1 pip install .4. 与主流方案深度对比
解决方案 | 适用场景 | 实施难度 | 效果 | 维护成本 |
|---|---|---|---|---|
预编译包安装 | 快速部署 | 低 | 中 | 低 |
源码编译 | 性能优化 | 高 | 高 | 高 |
容器化部署 | 生产环境 | 中 | 高 | 中 |
CPU版本 | 紧急情况 | 低 | 低 | 低 |
云服务 | 无GPU环境 | 低 | 高 | 高 |
5. 工程实践意义、风险与局限性
5.1 工程实践意义
- 确保flash-attention和vLLM的成功安装,充分利用其性能优势
- 提高模型训练和推理速度,减少计算成本
- 标准化安装流程,便于团队协作
- 降低部署失败率,提高生产环境的可靠性
5.2 风险与局限性
- 不同GPU架构可能需要不同的安装策略
- 源码编译需要较高的技术水平和时间成本
- 部分老型号GPU可能无法使用最新版本的flash-attention和vLLM
- 自动检测工具可能无法覆盖所有边缘情况
6. 未来趋势与前瞻预测
6.1 flash-attention和vLLM发展趋势
- 支持的CUDA版本和GPU架构将不断扩展
- 安装流程将更加简化,减少用户配置负担
- 性能优化将更加精细,针对不同模型和硬件进行定制
- 与其他深度学习库的集成将更加紧密
6.2 CUDA生态系统发展趋势
- CUDA版本管理将更加简化,减少版本兼容性问题
- 硬件抽象层将更加完善,减少架构差异对软件的影响
- 自动优化技术将成为标准功能,根据硬件特性调整算法
- 开源替代方案的竞争将促进生态系统的发展
6.3 模型推理优化趋势
- 注意力机制优化将成为模型推理性能的关键
- 内存优化将更加重要,支持更大规模的模型
- 多GPU并行推理将成为标准配置
- 边缘设备的优化将成为新的研究方向
参考链接:
- 主要来源:flash-attention GitHub仓库 - Dao-AILab flash-attention库
- 辅助:vLLM GitHub仓库 - vLLM项目
- 辅助:NVIDIA CUDA官方文档 - NVIDIA CUDA官方文档
附录(Appendix):
完整的安装脚本
#!/bin/bash
# 检查当前环境
echo "=== 检查当前环境 ==="
nvidia-smi
# 检查CUDA版本
nvcc --version 2>/dev/null || echo "nvcc not found"
# 检查Python版本
python --version
# 安装uv(如果未安装)
echo "\n=== 安装uv ==="
pip install uv
# 创建虚拟环境
echo "\n=== 创建虚拟环境 ==="
uv venv
uv activate
# 安装PyTorch(如果未安装)
echo "\n=== 安装PyTorch ==="
uv pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu131
# 安装flash-attention
echo "\n=== 安装flash-attention ==="
uv pip install flash-attn
# 安装vLLM
echo "\n=== 安装vLLM ==="
uv pip install vllm
# 验证安装结果
echo "\n=== 验证安装结果 ==="
python -c "
import torch
try:
from flash_attn import flash_attn_qkvpacked_func
print('flash-attention安装成功')
except ImportError:
print('flash-attention安装失败')
try:
import vllm
print('vLLM安装成功')
except ImportError:
print('vLLM安装失败')
"
# 测试性能
echo "\n=== 测试性能 ==="
python -c "
import torch
import time
try:
from flash_attn import flash_attn_qkvpacked_func
flash_available = True
except ImportError:
flash_available = False
# 创建测试数据
batch_size = 32
seq_len = 1024
dim = 512
# 随机初始化张量
qkv = torch.randn(batch_size, seq_len, 3, dim, device='cuda')
# 测试flash-attention
if flash_available:
print('测试flash-attention性能...')
start_time = time.time()
for _ in range(100):
output = flash_attn_qkvpacked_func(qkv)
torch.cuda.synchronize()
end_time = time.time()
print(f'flash-attention耗时: {end_time - start_time:.4f}秒')
else:
print('flash-attention未安装,跳过性能测试')
"
echo "\n=== 安装完成 ==="关键词: flash-attention, vLLM, CUDA架构, CUDA版本, 安装失败, 性能优化, 深度学习, 模型推理
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2026-02-23,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号