从"硬编码"到"零配置":OoderAgent 技能闭环系统的设计哲学与实践
原创
从"硬编码"到"零配置":OoderAgent 技能闭环系统的设计哲学与实践
原创
OneCode
发布于 2026-02-14 19:24:17
发布于 2026-02-14 19:24:17
在传统的企业应用集成中,我们习惯了这样的开发模式:配置文件中写死服务地址、手动管理依赖关系、人工处理服务发现。这种方式在单体应用时代尚可接受,但在分布式、智能化、快速迭代的今天,它已成为制约效率的瓶颈。 OoderAgent SDK 0.7.0 提出了一种全新的技能闭环系统设计,将"零配置发现"、"场景驱动"、"无中心组网"等理念融为一体,重新定义了应用与能力之间的连接方式。
零、版本演进:从 0.6.6 到 0.7.0
0.1 0.6.6 的设计基础
OoderAgent 0.6.6 版本已经建立了完整的 Agent 体系架构:
OoderAgent 0.6.6 架构
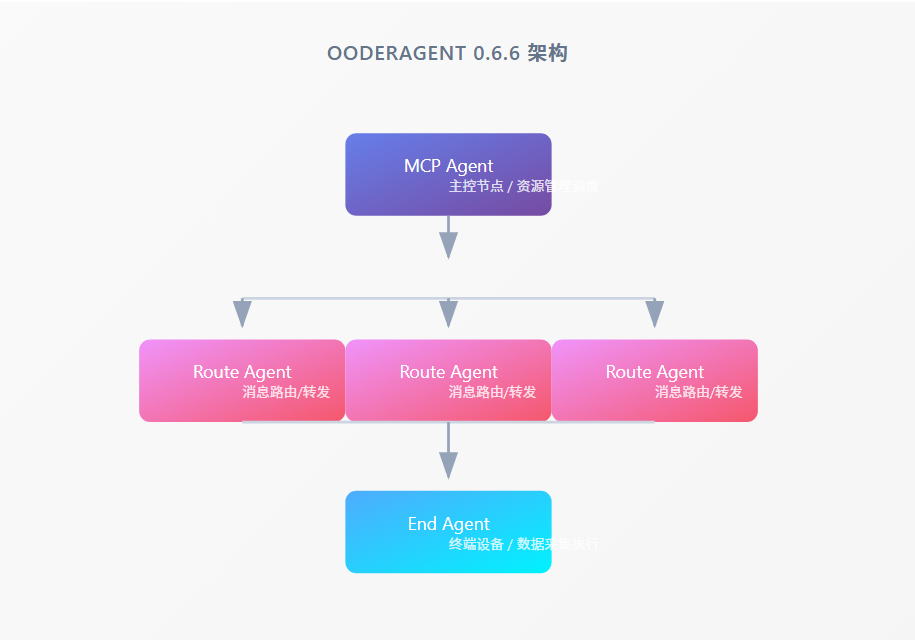
MCP Agent主控节点 / 资源管理调度Route Agent消息路由/转发Route Agent消息路由/转发Route Agent消息路由/转发End Agent终端设备 / 数据采集执行
0.6.6 核心协议
协议 | 说明 |
|---|---|
Agent 协议 | 南向协议,Agent 间通信 |
Skill 协议 | 技能注册、调用、健康检查 |
P2P 协议 | 无中心组网基础 |
VFS 协议 | 文件存储和同步 |
0.6.6 的 Skill-Capability 关系
Skill-Capability 关系图
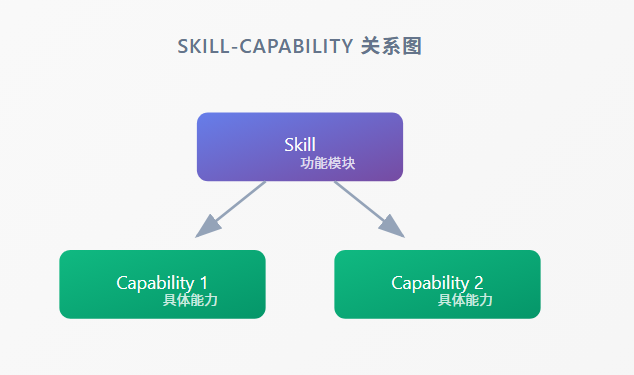
Skill功能模块Capability 1具体能力Capability 2具体能力
0.2 0.7.0 的演进方向
0.7.0 在 0.6.6 的基础上,重点解决了以下问题:
问题 | 0.6.6 现状 | 0.7.0 解决方案 |
|---|---|---|
技能发现 | UDP 广播发现 | 多层发现策略(UDP + DHT + SkillCenter) |
技能安装 | 手动部署 | SkillPackageManager 自动安装 |
场景管理 | 场景定义存在 | 场景组管理 + 硬地址解码 |
配置管理 | 手动配置 | 配置模板 + 自动注入 |
文档体系 | 协议文档 | 三层文档(用户/AI/开发者/运维) |
0.3 架构演进对比
架构演进对比
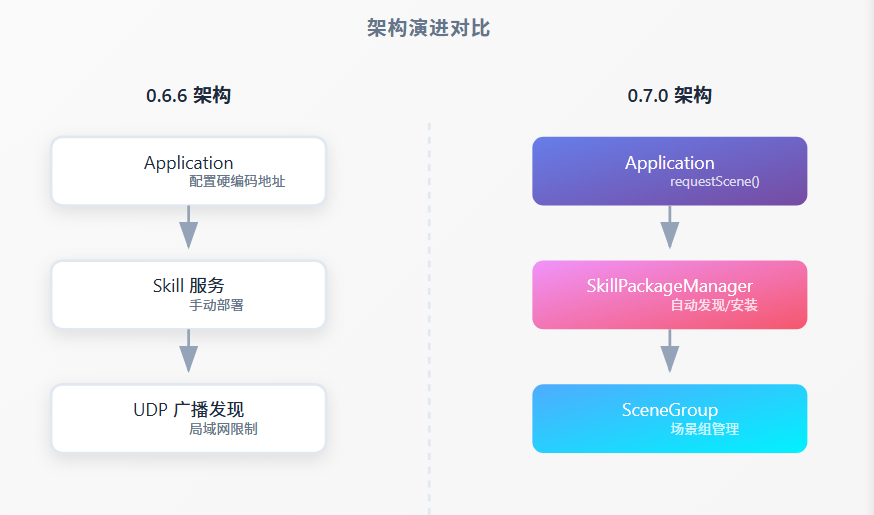
0.6.6 架构0.7.0 架构Application配置硬编码地址ApplicationrequestScene()Skill 服务手动部署SkillPackageManager自动发现/安装UDP 广播发现局域网限制SceneGroup场景组管理
一、问题的本质
1.1 传统模式的困境
考虑一个典型的企业应用场景:一个 Nexus 应用需要集成飞书的组织机构数据。
传统做法:
# application.yml
feishu:
server-url: https://feishu-api.company.com
app-id: cli_xxx
app-secret: xxx这种做法存在几个问题:
- 硬编码依赖:服务地址需要人工配置,环境迁移时容易出错
- 缺乏灵活性:无法动态切换服务提供者
- 无自动发现:新增服务需要手动更新配置
- 无故障转移:服务不可用时没有自动切换机制
1.2 核心矛盾
传统模式的根本矛盾在于:应用关注的是"能力",而配置关注的是"地址"。
用户真正需要的是"读取组织数据"这个能力,而不是"连接到 192.168.1.100:8080"这个地址。将能力与地址解耦,是我们设计的出发点。
二、核心理念:场景驱动
2.1 什么是场景?
场景(Scene)是一组相关能力的静态定义,描述了"谁在什么情况下能做什么"。
name: auth
description: 认证场景,提供用户认证和组织数据访问能力
capabilities:
- org-data-read
- user-auth
roles:
- roleId: org-provider
required: true
capabilities: [org-data-read, user-auth]场景的特点:
- 静态性:场景定义在技能发布时就已确定,不会在运行时改变
- 平等性:所有场景在网络中是平等的,没有父子关系
- 可组合性:多个技能可以参与同一个场景
2.2 场景 vs 服务
维度 | 传统服务 | 场景 |
|---|---|---|
关注点 | 地址和协议 | 能力和角色 |
发现方式 | 配置文件 | 自动发现 |
扩展方式 | 修改配置 | 加入场景组 |
容错方式 | 手动切换 | 自动选举 |
2.3 从场景到组
场景是静态定义,组(Group)是场景在运行时的实例化。
场景与组的关系
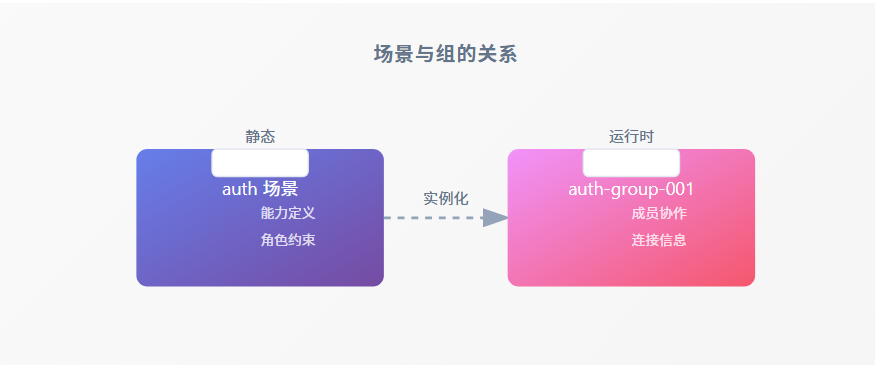
auth 场景能力定义角色约束静态实例化auth-group-001成员协作连接信息运行时
组负责两件事:
- 实时连接情况反馈:谁在线、谁离线
- 场景实例关系处理:如何协作、如何选主
2.4 场景与 Agent 的关系
基于 0.6.6 的 Agent 体系,场景与角色的对应关系:
Agent 类型 | 场景角色 | 职责 |
|---|---|---|
RouteAgent | 服务提供者 (Provider) | 提供能力服务,创建场景组 |
EndAgent | 服务消费者 (Consumer) | 消费能力服务,加入场景组 |
MCPAgent | 场景协调者 (Coordinator) | 协调场景组,管理元数据 |
三、零配置发现机制
3.1 设计目标
用户只需要表达"我需要什么能力",系统自动完成:
- 发现可用的技能
- 选择最优的提供者
- 建立连接并获取服务
3.2 发现流程
零配置发现流程
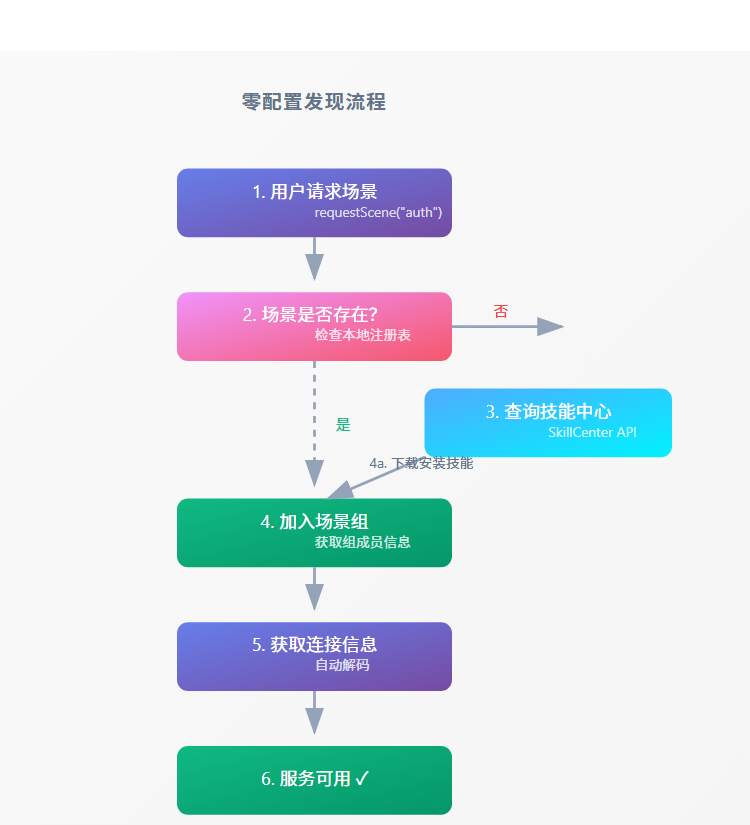
1. 用户请求场景requestScene("auth")2. 场景是否存在?检查本地注册表否3. 查询技能中心SkillCenter API是4. 加入场景组获取组成员信息4a. 下载安装技能5. 获取连接信息自动解码6. 服务可用 ✓
3.3 多层发现策略
系统支持多种发现方式,按优先级自动切换:
优先级 | 发现方式 | 适用场景 | 协议基础 |
|---|---|---|---|
1 | UDP广播 | 局域网环境 | 0.6.6 DiscoveryService |
2 | DHT (Kademlia) | 跨网络 P2P | 0.6.6 P2P 协议 |
3 | SkillCenter API | 集中式查询 | 0.7.0 新增 |
4 | 本地缓存 | 离线降级 | 0.6.6 VFS 协议 |
3.4 UDP 广播发现(继承自 0.6.6)
基于 0.6.6 的安全广播消息格式:
发现请求消息:
DISCOVER:SKILL:{agentId};{skillName};{skillType};{endpoint};{timestamp};{signature}加入响应消息:
JOIN_RESPONSE:SKILL:{agentId};{skillType};{sceneId};{status};{timestamp};{signature}安全机制:
- HMAC-SHA256 签名验证
- 时间戳防重放攻击
- 预共享密钥管理
3.5 连接信息解码
用户不需要知道服务的具体地址,连接信息从组中动态获取:
SceneJoinResult result = sdk.requestScene("auth").get();
// 自动获取连接信息
String endpoint = result.getEndpoint(); // 动态解析
String apiKey = result.getApiKey(); // 自动注入这种"硬地址解码"机制,让应用完全与基础设施解耦。
四、双模式部署
4.1 远程托管模式
技能运行在 SkillCenter,用户只需配置认证信息:
InstallRequest.builder()
.skillId("skill-org-feishu")
.mode(InstallMode.REMOTE_HOSTED)
.config("FEISHU_APP_ID", "xxx")
.build();优势:
- 快速部署,无需维护
- 自动升级,无需干预
- 资源共享,降低成本
4.2 本地部署模式
技能下载到本地运行:
InstallRequest.builder()
.skillId("skill-org-feishu")
.mode(InstallMode.LOCAL_DEPLOYED)
.config("FEISHU_APP_ID", "xxx")
.autoStart(true)
.build();优势:
- 数据安全,不出内网
- 低延迟,本地调用
- 可定制,深度集成
4.3 与 VFS 的集成
基于 0.6.6 的 VFS 协议,本地部署的技能可以:
- 自动同步配置:配置文件通过 VFS 同步
- 数据持久化:技能数据存储在 VFS
- 故障恢复:VFS 不可用时自动切换到本地存储
VFS 集成架构
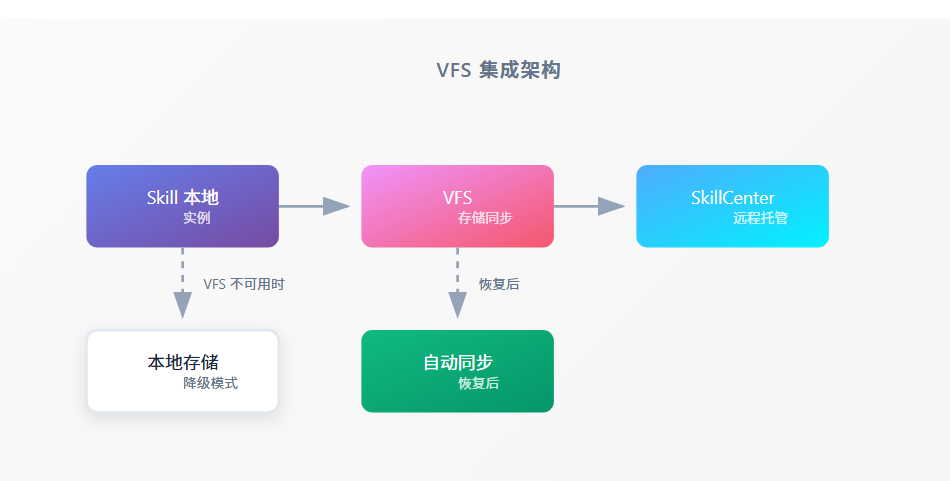
Skill 本地实例VFS存储同步SkillCenter远程托管VFS 不可用时本地存储降级模式恢复后自动同步恢复后
4.4 模式选择建议
场景 | 推荐模式 |
|---|---|
快速验证 | 远程托管 |
生产环境(公网) | 远程托管 |
生产环境(内网) | 本地部署 |
数据敏感业务 | 本地部署 |
高性能要求 | 本地部署 |
五、无中心组网
5.1 为什么需要无中心?
传统中心化架构存在单点故障风险:
- 注册中心宕机 → 服务发现失败
- 配置中心宕机 → 配置无法更新
- 网关宕机 → 服务无法访问
无中心组网通过 P2P 协议,让每个节点都可以作为发现节点,消除了单点故障。
5.2 Kademlia DHT
基于 0.6.6 的 P2P 协议,我们采用 Kademlia 算法实现分布式哈希表(DHT):
Kademlia DHT 架构
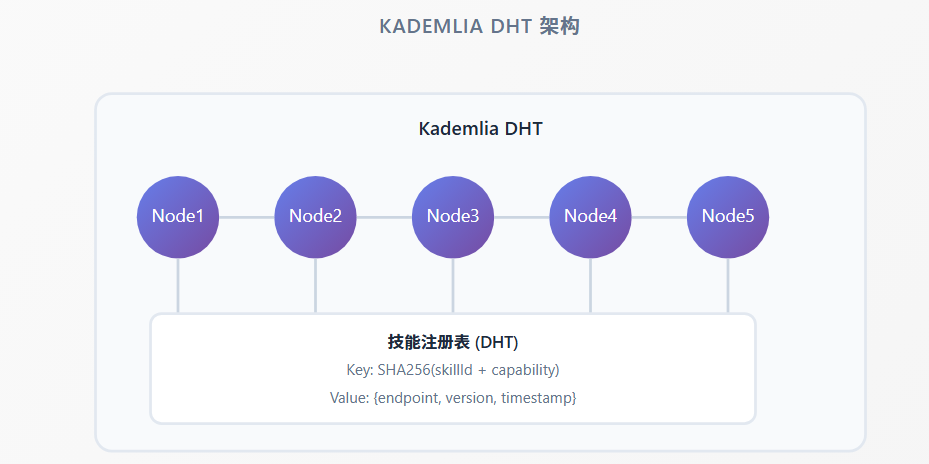
Kademlia DHTNode1Node2Node3Node4Node5技能注册表 (DHT)Key: SHA256(skillId + capability)Value: {endpoint, version, timestamp}
5.3 自组织特性
无中心组网具有自组织特性:
- 自发现:新节点自动加入网络
- 自愈合:节点离线后自动重新选主
- 自负载:请求自动路由到最优节点
- 自扩展:新节点自动分担负载
5.4 与 0.6.6 Agent 层次的融合
无中心组网与 Agent 层次
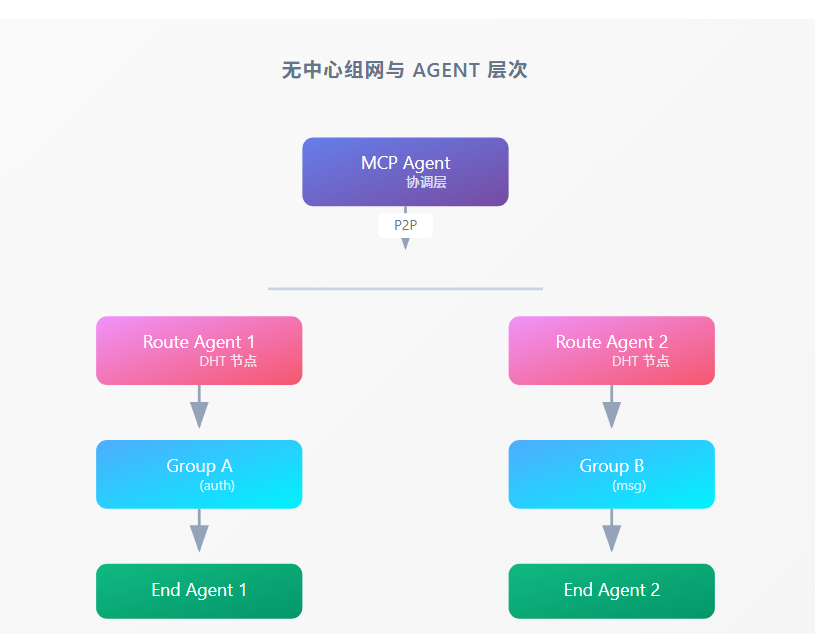
MCP Agent协调层P2PRoute Agent 1DHT 节点Route Agent 2DHT 节点Group A(auth)Group B(msg)End Agent 1End Agent 2
六、AI 友好设计
6.1 SKILLS.md 规范
技能通过自然语言描述,便于 AI 理解:
# skill-org-feishu
## 提供的能力
### org-data-read
读取飞书组织机构数据,包括部门树、成员列表等。
**参数:**
- orgId (可选): 组织ID
- includeInactive (可选): 是否包含停用成员
**返回:**
组织树结构
## 配置示例
```yaml
feishu:
app-id: cli_xxx
app-secret: xxx
```6.2 AI 调用流程
AI 调用流程
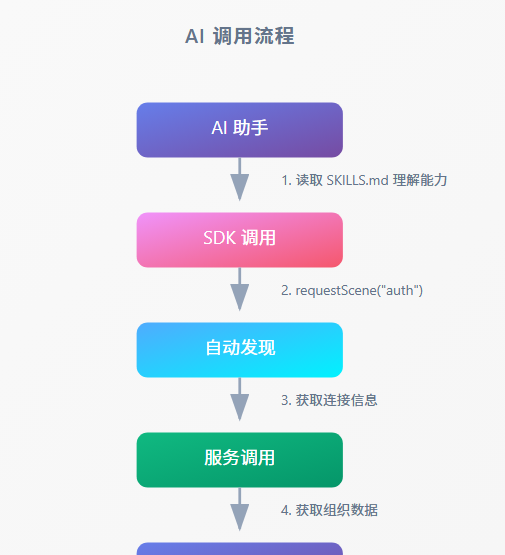
AI 助手1. 读取 SKILLS.md 理解能力SDK 调用2. requestScene("auth")自动发现3. 获取连接信息服务调用4. 获取组织数据返回结果
6.3 与 0.6.6 Capability 模型的对应
0.6.6 概念 | 0.7.0 概念 | 说明 |
|---|---|---|
Capability | Capability | 能力定义(继承) |
Skill | Skill + Scene | 技能 + 场景组织 |
Endpoint | ConnectionInfo | 连接信息(动态解析) |
Register API | SkillPackageManager | 注册 → 安装管理 |
七、三层文档体系
7.1 设计理念
不同角色对技能的理解需求不同:
角色 | 关注点 | 文档 |
|---|---|---|
终端用户 | 如何使用 | SKILLS-README.md |
AI 智能体 | 能力边界 | SKILLS.md |
开发者 | 如何开发 | SCENE-DESIGN.md |
运维人员 | 如何运维 | SKILL-RUNTIME.md |
7.2 文档闭环
文档闭环流程
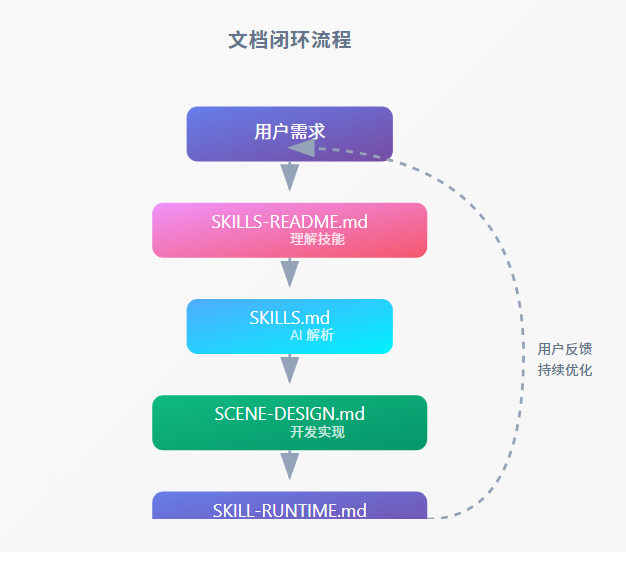
用户需求SKILLS-README.md理解技能SKILLS.mdAI 解析SCENE-DESIGN.md开发实现SKILL-RUNTIME.md运维部署用户反馈持续优化
7.3 与 0.6.6 协议文档的关系
0.6.6 文档 | 0.7.0 文档 | 关系 |
|---|---|---|
skill-protocol.md | skill-package-protocol.md | 协议扩展 |
skill-interface.md | skill-manifest-spec.md | 接口 → 清单规范 |
agent-protocol.md | skill-discovery-protocol.md | 发现机制增强 |
p2p-protocol.md | (继承) | 无变化 |
八、实践案例
8.1 场景:企业组织集成
某企业需要将飞书组织数据集成到内部应用。
传统方式(0.6.6):
- 手动部署 skill-org-feishu
- 配置飞书 API 地址
- 配置 App ID 和 Secret
- 手动处理 Token 刷新
- 手动处理故障转移
OoderAgent 0.7.0 方式:
// 1. 请求场景(自动发现、自动安装)
SceneJoinResult result = sdk.requestScene(
SceneRequest.builder()
.sceneName("auth")
.capability("org-data-read")
.build()
).get();
// 2. 获取数据
OrgClient client = new OrgClient(result.getEndpoint(), result.getApiKey());
Org org = client.getOrgTree();
// 完成!无需配置地址,无需管理 Token8.2 场景:多技能协作
某应用需要同时使用组织数据和消息通知。
// 请求认证场景
SceneJoinResult authResult = sdk.requestScene("auth").get();
// 请求消息场景
SceneJoinResult msgResult = sdk.requestScene("messaging").get();
// 组合使用
OrgClient orgClient = new OrgClient(authResult.getEndpoint(), authResult.getApiKey());
MsgClient msgClient = new MsgClient(msgResult.getEndpoint(), msgResult.getApiKey());
// 获取组织成员并发送通知
List members = orgClient.getOrgMembers("dept-001");
for (Person member : members) {
msgClient.sendMessage(member.getId(), "系统通知");
}九、总结与展望
9.1 版本演进总结
维度 | 0.6.6 | 0.7.0 |
|---|---|---|
技能发现 | UDP 广播 | 多层发现策略 |
技能管理 | 手动部署 | SkillPackageManager |
场景管理 | 基础支持 | 场景组 + 硬地址解码 |
配置管理 | 手动配置 | 模板 + 自动注入 |
文档体系 | 协议文档 | 三层文档体系 |
AI 支持 | 无 | SKILLS.md 自然语言 |
9.2 设计亮点回顾
OoderAgent 技能闭环系统的核心设计亮点:
- 零配置发现:从"配置地址"到"请求能力"
- 场景驱动:从"服务为中心"到"场景为中心"
- 双模式部署:灵活适应不同环境需求
- 无中心组网:消除单点故障,实现自组织
- AI 友好:自然语言描述,便于 AI 理解和调用
- 三层文档:分层设计,满足不同角色需求
- 向后兼容:继承 0.6.6 核心协议,平滑升级
9.3 技术价值
这套设计带来的技术价值:
- 降低集成成本:从天级降到分钟级
- 提高系统韧性:自动故障转移和恢复
- 增强灵活性:动态发现和切换服务
- 支持智能化:AI 可自主发现和调用能力
9.4 未来展望
后续规划:
- 技能市场:构建技能生态系统
- 智能路由:基于负载和延迟的智能调度
- 联邦学习:跨组织的技能共享
- 低代码集成:可视化技能编排
附录一:关键概念对照表
概念 | 定义 | 类比 | 版本 |
|---|---|---|---|
Skill | 能力单元 | 手机 App | 0.6.6+ |
Capability | 具体能力 | API 接口 | 0.6.6+ |
Scene | 能力场景 | App 功能分类 | 0.7.0 |
Group | 运行时协作组 | 聊天群 | 0.7.0 |
Role | 场景角色 | 群成员身份 | 0.7.0 |
RouteAgent | 服务提供者 | 群主 | 0.6.6+ |
EndAgent | 服务消费者 | 群成员 | 0.6.6+ |
MCPAgent | 场景协调者 | 群管理员 | 0.6.6+ |
VFS | 虚拟文件系统 | 云盘 | 0.6.6+ |
SkillCenter | 技能中心 | 应用商店 | 0.7.0 |
附录二:协议版本对照
协议 | 0.6.6 | 0.7.0 | 变化 |
|---|---|---|---|
Agent 协议 | ✅ | ✅ | 继承 |
Skill 协议 | ✅ | ✅ | 扩展 |
P2P 协议 | ✅ | ✅ | 继承 |
VFS 协议 | ✅ | ✅ | 继承 |
Skill Package 协议 | ❌ | ✅ | 新增 |
Skill Discovery 协议 | 部分 | ✅ | 增强 |
本文基于 OoderAgent SDK 0.7.0 设计实践整理,相关代码和文档已开源。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号