浅谈世界模型(下篇)
原创

在通往通用人工智能(AGI)的道路上,“世界模型”已成为核心战场。
由于篇幅较长,文章分为上下两篇:
● 心智模型:世界模型的哲学起点
● 世界模型:从强化学习到通用建模
● 联合嵌入流派:JEPA 系列
下篇:世界模型的生成、行动与空间智能路线
● 视频生成流派:Sora(OpenAI)、Genie(Google DeepMind)
● 强化学习流派:Dreamer(Google)
● 空间智能流派:World Labs
本文继续聊世界模型的生成,行动和空间智能路线。
1. 视频生成流派:从内容生成到世界模拟
1.1 Sora:视频生成模型作为世界模拟器
Video generation models as world simulators(2024.02)
技术报告:https://openai.com/index/video-generation-models-as-world-simulators/
问题和背景
OpenAI 在 2024 年推出 Sora,其意义远超视频生成本身,标志着从“内容生成”向“物理世界模拟”的范式跨越。技术报告中有提出sora目标:构建能够学习和模拟世界物理规律的“世界模拟器”。Sora旨在解决视频生成领域的三大核心挑战:
1. 时空复杂性
此前模型生成的视频时长很短,且连贯性差,难以对时间和空间进行统一、连贯的建模。
Sora:生成长达60秒、具有高度时空一致性的视频,确保角色、物体和背景在时间线上稳定存在且行为合理。
2. 物理真实性
早期模型的生成画面容易违背基本物理规律,缺乏对世界动态和因果关系的深层理解。
Sora:模拟真实世界的物理规律与因果关系,试图通过大规模数据与模型规模推动隐式物理规律的学习,让生成的动作及其结果符合逻辑直觉。
3. 通用智能路径
仅依靠文本数据训练智能体可能存在认知局限,高级智能需要从更本质的视觉动态数据中学习世界运作方式。
Sora:作为世界模拟器,为未来AGI提供理解并与动态物理世界交互的基础能力,开辟超越纯文本训练的智能进化路径。
上篇我们介绍了LeCun 在提出JEPA时一直强调的是世界模型不生成未来的世界,只生成未来隐世表征。而Sora就要生成世界(视频),他的目标是成为世界模拟器,能够理解和模拟物理世界的复杂互动和动态环境,帮助人们解决需要真实世界互动的问题。
Sora和JEPA的主要区别:
JEPA 是“不生成世界的世界模型表征学习范式”,而 Sora 是“直接生成世界的生成式模型”。虽然对于谁才是世界模型的纷争很大,但是我个人觉得都没对错,只是目标不一样而已。
JEPA:学“抽象世界状态”
JEPA 的核心目标是:学一个潜在空间(latent space),使得这个空间里的向量能表达世界的语义结构与因果关系,并且可以在这个空间里做预测。它关心的是:
物体关系,动作语义,状态转移,不变量/可预测结构等方面。不关心像素细节是否被重建出来。
Sora:生成“可见世界本身”
Sora 的核心目标是:给定文本条件,直接生成高保真、时序一致、符合物理直觉的视频像素序列。
它关心的是:每一帧像不像真的,运动是否平滑,光照、纹理、风格,人类观看是否可信,而世界是否被“理解”,并不是训练目标本身。
论文方案
Sora的技术核心主要有:
1. 变长输入:Spacetime Latent Patches
之前的 VDT 或 Latte 通常需要将视频预处理成固定尺寸(如 256x256)和固定长度。 Sora 的创新点在于它把视频切分为Patches。
灵活性: 它不强制裁剪视频,不管是竖屏、横屏还是不同分辨率,直接切片成 Patch 丢进去。这让它能学习到物体在各种比例下的真实动态,而不会因为裁剪导致特征丢失。
2. Scaling Law
OpenAI验证视觉版的 Scaling Law。当把参数量和计算量推向极致,模型展现出了*3D 一致性和物体持久性的能力。这种大力出奇迹带来的生成质量在当时(2024)是断层式领先。
3. 数据质量:重标注
Sora沿用了 DALL-E 3 的思路,先训练一个极其强大的视频描述模型,给海量的原始视频自动生成极度详细的描述词。
用高质量、高一致性的“文本-视频对”去训练 Sora,这才是它能精准理解复杂指令。
报告特别强调了 Sora 在没有经过显式物理建模的情况下,产生了一些有趣的“模拟器”特性:
3D 一致性: 镜头移动时,背景和人物保持正确的三维空间关系。
长程连贯性: 即使人物被遮挡或离开画面,再次出现时仍能保持一致。
与世界互动: 比如模拟人在画布上留下笔触,或者吃汉堡留下咬痕。
(虽然从实际体验效果,Sora仍然还是很多失败案例,会出现很多反常规场景)
主要贡献
2024年2月的初代 Sora 堪称“视频领域的 GPT‑1 时刻”。2025年10月推出 Sora 2,OpenAI 表示其正迎来“GPT‑3.5 式突破”。尽管近期出现了 Veo、Kling、Seedance 等强劲竞品,但 Sora 的独特定位在于:
Seedance 等:优化叙事表达、多镜头生成、角色一致性与生产效率,侧重内容创作。
Sora:优化长序列一致性、物理合理性与世界演化能力,目标不是生成漂亮视频,而是构建可演化世界。
Sora认为它不仅仅是视频生成器,更是通往“通用世界模拟器”的一条路径。
至于他是不是世界模型这个问题,OpenAI 的逻辑是:如果一个模型能通过看海量视频,自发地学会物体怎么动、光影怎么变、3D 空间怎么保持一致,那它就模拟了物理世界。LeCun 等人认为Sora 只是在预测像素,但是根本没有理解世界,而且和世界都没有任何交互,算不上世界模型。
1.2 Genie:从生成内容到生成可交互环境
openai那么忙,当然google也没闲着,google也有自己的世界模型Genie。
2024年2月Genie1:
https://arxiv.org/pdf/2402.15391
2024年12月Genie2:
https://deepmind.google/blog/genie-2-a-large-scale-foundation-world-model/
2025年8月Genie3:
https://deepmind.google/blog/genie-3-a-new-frontier-for-world-models/
1.2.1 Genie1:无监督交互世界模型
2024年openai刚推出sora,DeepMind马上提出了一个11B的基础世界模型Genie1。
它的核心创新突破是:仅通过观看未经标记的互联网视频,以无监督方式从原始视频中学习到“交互性”的基础世界模型。
Genie 的三大核心能力:
图片转世界(Image-to-World): 输入单张图片或草图,即可生成可玩的交互环境。
动作可控(Action Controllability): 用户可以通过按键实时控制生成的角色。
无监督学习(Unsupervised Learning): 它不需要知道视频里的玩家做了什么,仅靠观察像素变化就学会了什么是“动作”。
虽然画质很差,延时严重,而且生成一致性也不好....但是已经具备可交互的世界模型的雏形。
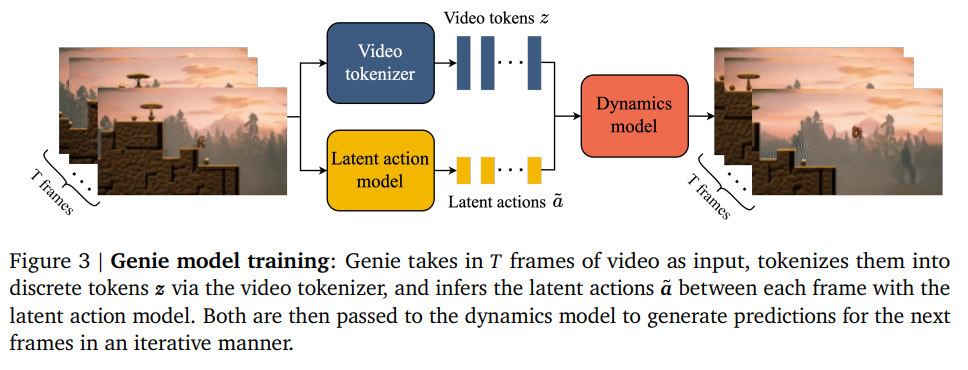
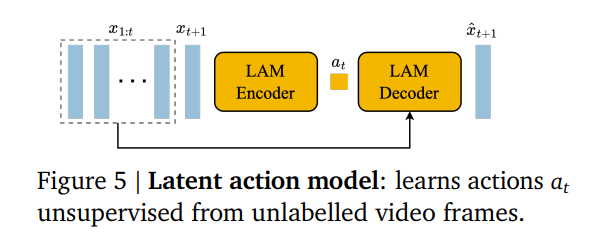
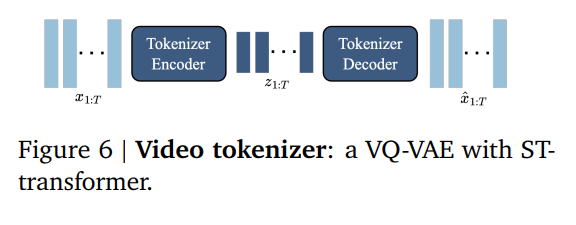
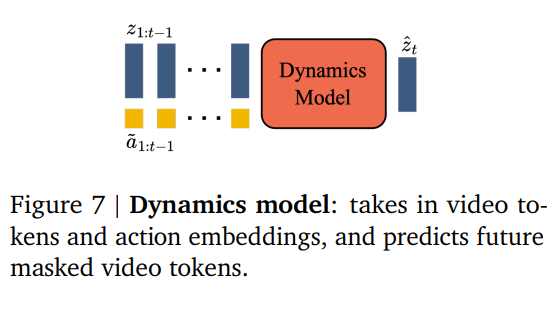
Genie的技术核心主要就是上图三个模块:
1. 时空视频分词器(Spatiotemporal Video Tokenizer)
视频数据量巨大且复杂。Genie 使用了基于 ST-ViT (Spatiotemporal Vision Transformer) 的分词器。
它将连续的视频帧压缩成离散的token。相比传统的图像分词,它能同时捕捉空间(画面细节)和时间(运动趋势)的信息,大大降低了模型处理视频的计算压力。
2. 潜动作模型(Latent Action Model, LAM)
这是 Genie 很创新的模块。通常训练 AI 玩游戏需要游戏手柄数据,但是数据难收集;互联网数据倒是海量,但互联网视频没有手游操作数据。LAM思路就是对比相邻的两帧画面去推断:“发生了什么变化?是什么动作导致了这种变化?”
它将这些变化归类为 8 到 16 种“潜在动作”(Latent Actions)。虽然模型不知道这些动作叫“跳”或“走”,但它可以去识别出这些动作的模式。
3. 动力学模型(Dynamics Model)
这是世界的大脑,一个 110 亿参数的 Transformer。
给定当前的画面 Tokens 和用户输入的潜在动作,预测下一帧画面。
预测公式: P(z_{t+1} \mid z_{1:t}, a_{1:t})。它通过这种方式,一帧接一帧地“渲染”出整个可交互的世界。
论文中除了 2D 游戏,DeepMind 还尝试用机器人操作视频训练 Genie。在没有人类干预情况下,模型也学会了模拟机械臂拨动物体的动态效果。这证明了 Genie 作为一个通用世界模型的潜力。
总的来说,Genie 通过模拟交互,学会了“如果我这么做,世界会发生什么”,这比单纯的文本或图像生成更接近人类的认知逻辑。同样是显示生成,相对于Sora,它是和世界有交互的,从生成式内容进入了生成式交互环境。
1.2.2 Genie2:迈向 3D 与长效记忆
Genie 2 没有发布论文,但是发布技术报告。Genie2是一个大规模基础世界模型(Foundation World Model),Genie 1 主要局限于 2D 平台游戏,而 Genie 2 它将 AI 生成的交互性从简单的 2D 平面提升到了复杂的 3D 环境。而且相比前代,在通用性、物理真实感和记忆时长上实现了质的飞跃。
Genie 2 延续并强化了视频预训练的范式,架构还是Autoregressive Latent Diffusion,另外使用了更庞大的数据集和算力。
此外与 Genie 1 模糊的潜在动作不同,Genie 2 已经可以很好地响应人类习惯的键盘和鼠标控制,这使得它生成的环境能够直接作为训练沙盒。相比Genie1,在通用性、物理真实感和记忆时长上实现了质的飞跃。
1. 纯粹的 3D 世界模拟
Genie 1 主要局限于 2D 平台游戏,而 Genie 2 可以生成丰富的 3D 环境。从第一人称视角探索森林、地下城到城市,AI 能够实时模拟视角转动、景深变化和复杂的 3D 空间结构。
2. 长效的一致性与记忆(Long Horizon Memory)
最令人头疼的“转头就忘”问题在 Genie 2 中得到了显著改善。
物体恒常性: 如果你在房间里看到一盆花,转身走开再回来,那盆花依然在原位。
一分钟记忆: 模型可以保持长达 10-60 秒 的稳定连贯交互,这比 Genie 1 的几秒钟有了巨大提升。
3. 涌现的物理规律(Emergent Physics)
尽管没有写过一行物理代码,Genie 2 却在训练中“悟出”物理特性,比如:
重力与碰撞: 角色跳起会下落,撞到墙壁会停止。
光影交互: 模拟复杂的实时光照、反射、烟雾和火光效果。
报告中也指出DeepMind 研发 Genie 2 的初衷并非为了做游戏,而是为了解决具身智能的训练瓶颈。比如具身面临的在真实环境下收集数据的安全训练问题,数据问题,动作对环境的交互问题等。
Genie2和sora可以看出最核心的区别是,视频不再只是用来看的,而是可以用来进行交互的。
1.2.3 Genie3:电影级画质与实时交互
2025 年 8 月,Google DeepMind 发布了 Genie 3,进化的更高清、更流畅、更持久、更可控。如果说 Genie 1 是原型证明,Genie 2 是规模化尝试,那么 Genie 3 则真正实现了电影级画质与游戏级实时交互的融合。它不仅是视频生成工具,更是一个能够实时运行、具备长效记忆的数字物理世界。
主要功能点:
1. 真正的实时交互
Genie 1 和 2 往往给人一种卡成PPT的感觉,而 Genie 3 实现了 24 FPS 的流畅渲染。
极低延迟: 响应用户操作(如按下键盘或转动视角)的延迟低于 50ms。
高清分辨率: 从 360p 飞跃至 720p HD,画面的纹理细节(如皮肤褶皱、水面波纹)达到了商用视频游戏的水平。
2. 长时程一致性与视觉记忆
空间持久性: 解决了“转身即忘”的经典难题。即使在复杂的 3D 场景中移动数分钟,场景中的物体状态(如黑板上的粉笔画、移位的桌椅)依然保持原位。
记忆范围: 它的逻辑连贯性从前代的 20 秒提升到了数分钟之久。
3. 可编程世界事件
用户不仅可以控制角色移动,还可以在运行过程中用自然语言修改世界规则。
公式推导: 模型预测概率由 P(x_t \mid x_{<t}, a_t) 进化为加入全局上下文变量:
P(x_t \mid x_{<t}, a_t, C_{prompt})
其中 $C_{prompt}$ 为用户输入的实时指令。
动态指令: 在探索沙漠时输入“突然降下暴雨”,模型会实时模拟天空变暗、雨滴落在沙地上的物理反馈,而不需要重启模拟。
报告指出,Genie 3 的模拟环境已成功用于测试自动驾驶算法在复杂天气下的鲁棒性,以及机器人末端执行器的交互准确度。
和Sora和JEPA进行比较的话,简单来说,OpenAI Sora侧重于影视级生成、Google Genie侧重于可交互性, LeCun 的 JEPA侧重于非生成式预测,在 2024-2025 年间,世界模型领域已经形成了一个“多极化”的生态。
2. 强化学习流派:在潜在空间中学习与规划
除了Genie项目,google还有Dreamer项目。Dreamer最初主要由 Google Research 团队主导,23年Google Brain和DeepMind就合并了,最新的Dreamer V4 版本直接产自合并后的 Google DeepMind。
Dreamer 核心是基于深度强化学习算法,它的目标是让 AI 机器人或智能体通过在大脑中模拟来学习。
2.1 Dreamer1:潜在想象范式的确立
Dream to control:learning behaviors by latent imagination(2019.12)
论文地址:https://arxiv.org/pdf/1912.01603
问题和背景
传统强化学习,特别是基于高维图像输入有两大痛点:
样本效率极低:无模型(Model-Free)方法需要与环境进行海量交互才能学到有效策略,这在真实世界中成本太高。
规划视野短视:基于模型(Model-Based)方法在潜在动态模型中规划时,往往只优化固定步长内的奖励,缺乏对长期收益的考虑,导致短视行为。
论文提出需要一个完全在内部世界模型的潜在空间中想象和学习的智能体,以更高的数据效率和计算效率,解决需要长期规划的复杂视觉控制任务。
论文方案
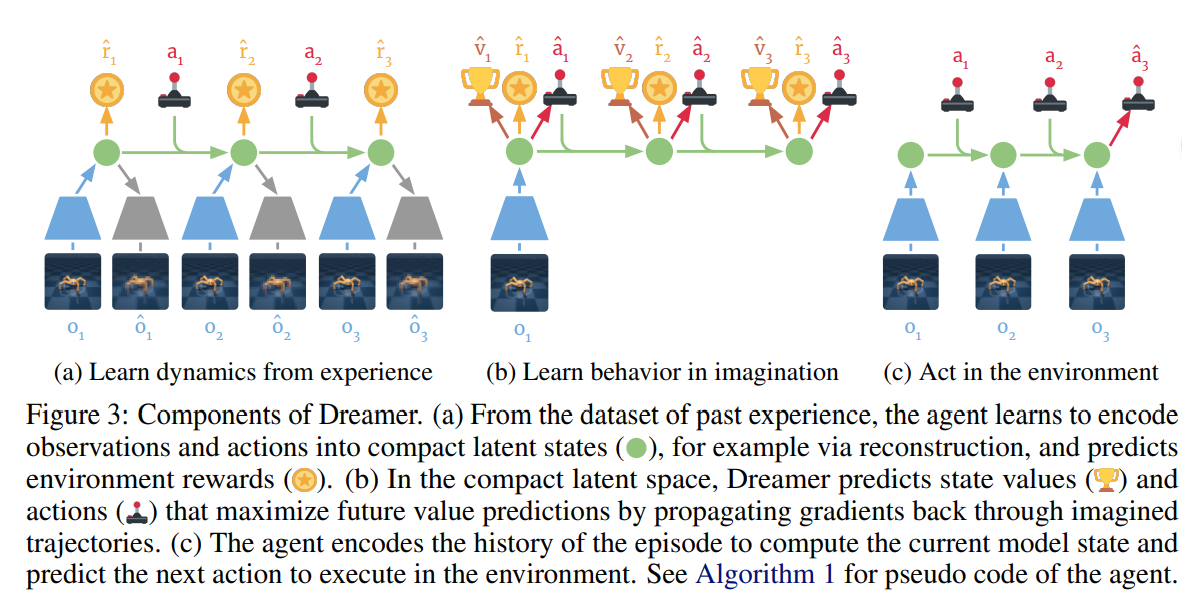
Dreamer核心思路是学习一个能够生成逼真未来场景的隐变量世界模型,然后在这个世界模型中学习如何行动训练策略。
为了实现“在梦中学习”,如上图Dreamer 包含三个主要部分:
(a)从经验中学习动力学 (Learn dynamics from experience)
这一步就是构建世界模型的过程。论文采用 RSSM(Recurrent State-Space Model,循环状态空间模型) 的架构。agent将观察到的画面和动作编码到潜状态空间(绿色圆点),灰色就是在训练过程中尝试还原原始图像,橙色星星是学习预测在某个状态下能获得的奖励 。
(b)在想象中学习行为 (Learn behavior in imagination)
在紧凑的潜空间中,Dreamer 通过将梯度在想象的轨迹中进行反向传播,预测状态价值和动作,从而使未来的价值预测最大化。除了第一个起点o_1,后面的过程完全没有蓝色的图像输入 这意味着它能预见到长远的后果,从而做出更聪明的决策。
(c) 在环境中执行任务 (Act in the environment)
智能体对当前片段的历史信息进行编码,计算出当前的模型状态,并预测下一个要在环境中执行的动作。
总的来说,Dreamer可以认为是在自己的梦境里通过不断试错来理解物理世界指导和预测未来的动作,和2028年world Model的思路非常一致。
主要贡献
Dreamer主要贡献是开创潜在想象范式:系统性地提出了在已学习的世界模型潜在空间中进行完全离线的、基于梯度的策略优化,极大地提升了数据效率。另外通过引入价值函数并利用其分析梯度,克服了以往基于模型的短视规划问题,使智能体能够学习考虑长远收益的行为。在DeepMind Control Suite的20项视觉控制任务上,Dreamer用极少的真实环境交互(约100万步),在数据效率、计算速度和最终性能上全面超越了当时的顶尖无模型方法和基于模型的规划方法。
2.2 Dreamer2:离散潜变量
Mastering Atari with Discrete World Models(2020.10)
论文地址:https://arxiv.org/pdf/2010.02193
问题和背景
在强化学习中,传统的 Model-free 算法虽然在 Atari 上表现卓越,但数据效率较低。Model-based 算法理论上可以通过在想象中训练来提高效率,但在处理像 Atari 这样具有高维视觉输入和复杂动态的环境时,往往表现不如前者。
主要问题是:
误差累积: 在预测长期的未来状态时,微小的预测误差会累计并且迅速放大,导致代理在想象中训练时偏离轨迹。
连续向量的局限性: 之前的模型(如DreamerV1)使用连续向量来表示世界状态。然而,Atari 游戏中的许多元素(如怪物的消失、分数的跳动)本质上是离散且不连续的。
多模态预测困难: 连续模型在处理“下一步可能有多种可能结果”的情况时,容易预测出一个模糊的平均值,而不是清晰的可能状态。
论文方案
Dreamer2的核心创新就是引入了离散潜变量(Categorical Latents),使世界模型能够更准确地模拟不连续的物理变化。
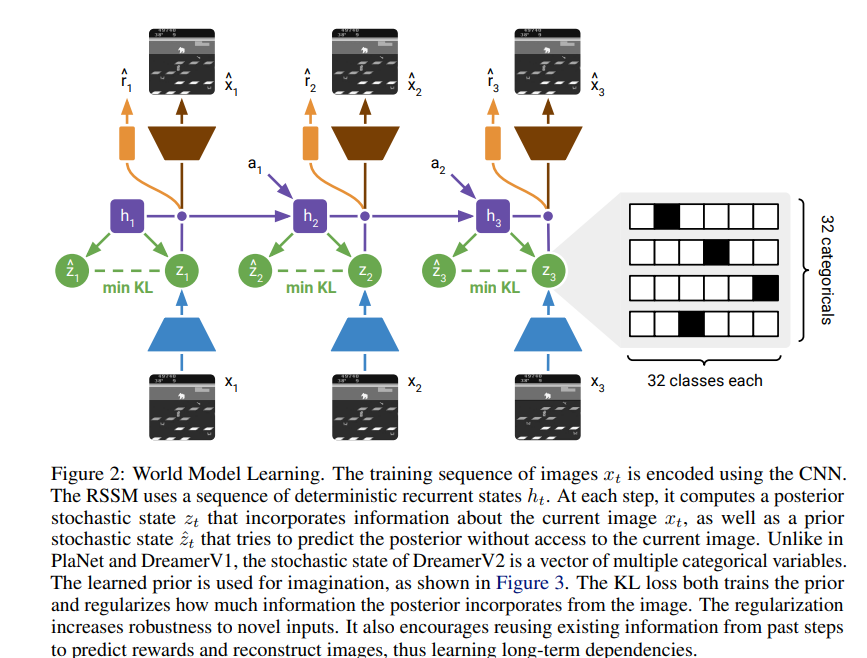
如上图所示训练序列中的图像 $x_t$ 使用 CNN进行编码。RSSM 使用一系列确定性循环状态 $h_t$。在每一步中,它计算一个后验随机状态z_t 该状态包含了当前图像 x_tt的信息;同时计算一个先验随机状态 \hat{z}_t,它在不接触当前图像的情况下尝试预测后验状态。与 PlaNet 和 DreamerV1 不同,DreamerV2 的随机状态是由多个分类变量(Categorical variables)组成的向量。学习到的先验用于想象。KL 损失既训练了先验,又限制了后验从图像中吸收的信息量。这种正则化增加了对新输入数据的鲁棒性。它还鼓励模型重用过去步骤中的现有信息来预测奖励和重建图像,从而学习长程依赖关系。
解释下图中一些符号的意义:
其中h_t本质就是RNN的隐藏状态,它代表了模型的记忆,负责整合过去所有的历史信息(历史图像、动作)。
z_t它是从概率分布中采样出来的潜变量。它负责捕捉当前时刻图像 x_t中的即时信息。由于单张图片可能存在遮挡或不确定性,用随机变量表示能让模型更具鲁棒性。 这里V2也V1不一样的是对Z_t进行了离散化处理。那Z_t是怎么获取的呢?
这是一个非常关键的问题:既然z是离散的,它的 Ground Truth从哪来?
在模型训练阶段,并没有人工标注的 GT。z_t的学习是通过 变分自编码器 (VAE) 的思想,利用以下两个来源进行相互约束:
后验分布 (Posterior):
它是通过当前图像 x_t 和历史 h_t 共同生成的。图中由蓝色编码器指向上方的绿球 z_t。
它的目标是确保能从这个 z_t 中重建出原始图像x_t 以及预测出奖励 r_t。
先验分布 (Prior):
图中左侧的\hat{z}_t 仅根据上一时刻的状态和动作预测当前时刻。
训练逻辑:模型通过 KL 散度 (KL Loss) 强制让先验 \hat{z}_t靠近后验 z_t。
在框架上V2和V1是一致的,最大的创新模块就是V2中z的离散化。
针对这里离散化传播的问题,论文中使用了两个核心技术。
直通估计器(Straight-Through Estimator, ST)
1. 分类采样(Categorical Sampling): 编码器输出 32 组概率分布。在训练前向传播时,模型会从每个分布中随机采样出一个最高频的类别(变成 One-hot 编码,即图中黑白的方块)。
2. 梯度强行传递: 离散采样函数在数学上是不可导的。DreamerV2 使用了“直通”技巧:在反向传播计算梯度时,假装采样函数不存在,直接把梯度传给采样前的概率分布。
代码实现上也很方便:
z_sample = z_logit + (z_onehot - z_logit).detach()前向传播:z_logit 和 -z_logit 抵消,结果就是 z_onehot。模型看到的是纯粹的离散状态。
反向传播:由于 (z_onehot - z_logit) 被 detach() 掉了(截断了梯度),求导时这一项消失。梯度会直接作用在 z_logit 上。
KL Balancing优化
在最小化先验(Prior,预测状态)与后验(Posterior,真实状态)之间的 KL 散度时,分别给两者设置不同的学习率。允许后验状态向先验状态靠拢得慢一些,从而保护后验状态中从真实图像学到的丰富信息不被预测模型过快地抹平,防止先验向后验塌缩过快,从而保证模型能学到更丰富的预测能力,极大地增强了潜空间表征的质量。
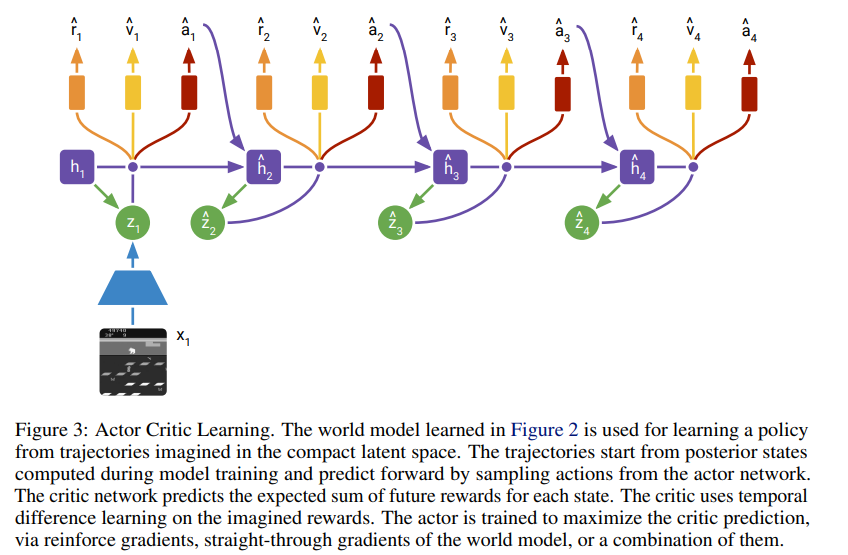
Actor-Critic 行为学习:利用训练好的世界模型,在潜空间内通过想象生成的轨迹来学习行为策略。这些想象轨迹以模型训练时得到的后验状态为起点,通过从 Actor 网络中采样动作来向未来进行推演。Critic 网络负责预估每个状态下未来奖励的期望总和,并对这些想象出的奖励运行时序差分(TD)学习。Actor 的训练目标是最大化Critic的预测价值。
主要贡献
和V1比较,V2放弃了传统的连续向量,改用的离散分类变量来表示世界状态。通过实验也标明,离散表示能更有效地捕捉游戏中的不连续逻辑,并显著缓解长程预测中的误差累积和模糊问题。Dreamer2是首个在55款Atari 游戏基准测试中,平均性能超越人类专家且能比肩顶级 Model-free算法的Model-based强化学习算法。
2.3 Dreamer3:跨领域通用性与鲁棒性
Mastering Diverse Domains through World Models(2023.01)
论文地址:https://arxiv.org/abs/2301.04104
问题和背景
基于之前的世界模型的方法DreamerV1/V2,虽然数据效率高,但在不同领域的学习稳定性、泛化能力和计算效率上仍存在不足,限制了其广泛应用。
DreamerV3 是Google DeepMind 研发的第三代世界模型智能体。它的核心突破在于实现了算法的鲁棒性,使其能够在完全不调整超参数的情况下,通关从视觉游戏到复杂机器人控制的 150 多个不同领域的任务。
论文方案
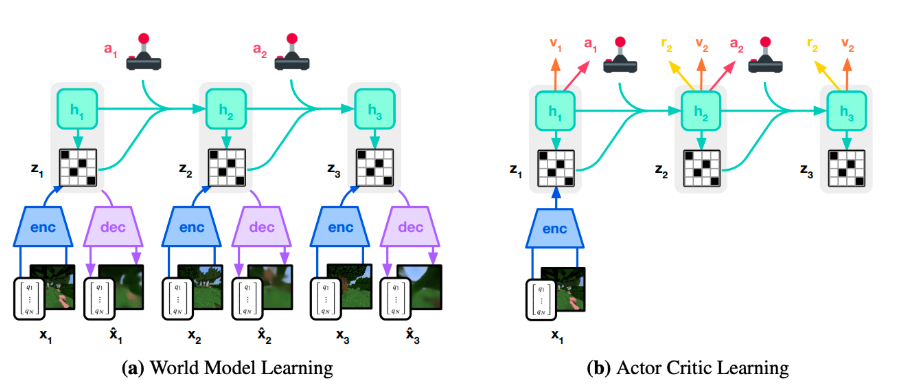
如上图,训练框架继续沿用DreamerV2。
Dreamer V3主要是解决强化学习中不同任务的奖励和观察量级差异巨大的痛点。Dreamer V3的核心技术方案:
1. Symlog 预测(Symlog Predictions)
针对任务奖励差异很大,某些任务奖励是 0.01,某些是 10000的问题,DreamerV3 对预测目标进行了 Symlog 转换:

这使得模型可以压缩巨大的数值范围,同时保持对小数值的敏感度,增强了训练的稳定性。
2. 离散回归(Categorical Regression)
模型不再仅仅预测一个标量值,而是将奖励和价值预测数值划分为多个离散桶,使用Two-hot编码。这种做法相比传统的均方误差回归,对极端值和噪声更不敏感,同时也能更好地表达多峰分布,存在多个可能的奖励模式。因此,在复杂环境中,Critic 可以获得更稳定、更准确的价值估计。
3. 固定超参数(Fixed Hyperparameters)
DreamerV3 使用统一的超参数配置跨领域执行学习,不再为每个任务单独调整。
包括交互步长、学习率、正则化等参数均统一,这是 V3 最显著的工程突破,证明了其极强的通用性和稳定性。
主要贡献
DreamerV3 在超过 150 种不同任务 上,使用统一超参即可达到或超过现有专用算法性能。最出名的成就就是在《我的世界》游戏中,从零开始收集钻石是一个极难的任务,涉及长程规划和极其稀疏的奖励。DreamerV3 是首个在不利用人类演示数据、不进行课程学习的情况下,仅凭像素输入和稀疏奖励就挖到钻石的算法。
2.4 Dreamer4:完全离线学习与可扩展世界模型
Training Agents Inside of Scalable World Models(2025.09)
论文地址:https://arxiv.org/abs/2509.24527
问题和背景
“世界模型”旨在从视频等高维感知数据中学习环境的动态,并在内部模拟未来,从而让智能体在想象中学习行为策略。这一策略可以显著提高强化学习的样本效率,并减少对真实环境交互的依赖。但是还是存在以下限制:
1. 复杂环境下的互动预测困难
以往的世界模型难以准确模拟复杂环境中物体之间的交互与因果关系(例如 Minecraft 里的合成、破坏、工具使用等),导致策略学习失败或质量低下。
2. 高计算消耗与推理延迟
传统视频生成或世界模型通常计算量大,在现实条件下难以实现实时、互动式推理(尤其是在一张 GPU 上运行)。
3. 依赖大量动作标注数据
先前的离线 RL 与 world model 方法往往依赖大规模具有动作标签的视频数据,这在现实机器人、数据稀缺场景下往往不可行。
4. 长时序、高稀疏奖励问题
例如任务 “在 Minecraft 中获得钻石” 需要超过 20,000 步低级动作序列,属于极端长时序稀疏奖励控制问题。
特别在在机器人等现实领域,在线交互代价高昂或存在安全风险,这迫切需要一种纯离线数据驱动、无需环境交互的学习方法。
DreamerV4 的核心突破就在于可扩展性与离线学习能力。它首次实现了在不与环境发生任何实际交互的情况下,仅通过观看视频数据,在复杂的《我的世界》中完成挖掘钻石的任务。
论文方案
V4首先在架构上进行了升级:从 RSSM 到Transformer (Block-Causal Transformer)
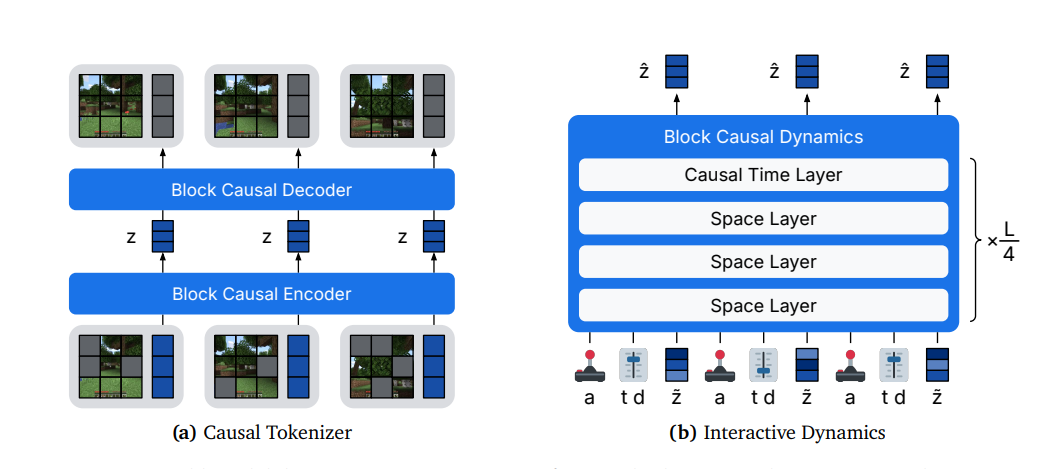
DreamerV1-V3 长期依赖基于 GRU 的循环状态空间模型(RSSM)。DreamerV4 彻底倒向了 Transformer 架构:因果分词器(Causal Tokenizer)用于时空压缩,交互式动力学模型(Interactive Dynamics Model)用于预测未来。主要将先进的Transform和流匹配技术替换了之前的GRU技术。
Dreamer V4训练三阶段范式:
阶段一:通用动力学预训练 (Foundation Pre-training) 在大规模无标签视频集上预训练 Tokenizer 与 Transformer 动力学模型。通过预测长程时空演化,使模型学习到通用的视觉表征与物理世界的内在逻辑。
阶段二:动作对齐与行为关联 (Action Grounding) 在带动作与任务标签的特定数据上,为世界模型接入策略与奖励预测头。利用行为克隆进行微调,将抽象的物理规律与具体的操控指令进行对齐。
阶段三:潜在空间想象训练 (Latent RL Optimization) 冻结世界模型底座,智能体完全在生成的“潜在轨迹(梦境)”中进化。采用 PMPO策略进行高强度强化学习,以最大化预期收益。该阶段实现“零环境交互”下的复杂策略蒸馏。
前文中的V1-V3也是在潜在空间想象学习,但是世界模型是服务于在线RL,而不是替代环境的“模拟世界”。路径如下:
online data → world model → imagination(rollout) → policy → online data
而V4的设计是完全离线学习,把世界模型当成世界本身,路径如下:
offline data → world model → imagination(rollout) → policy → imagination → policy → ...(不用回到真实世界)
主要贡献
DreamerV4 是首个在仅用离线视频数据下,在 Minecraft 中获取钻石的RL体系,不需真实环境交互。该任务涉及超过 20,000 步低级操作,是长时序、极端稀疏奖励的代表。论文从大量无标签视频中学习世界模型,只需少量带动作标签视频就能学会动作的条件控制,并能将这种控制能力泛化到新的、未见过动作的场景中。
这一路径对于机器人、自动驾驶等需要大量数据且在线试错成本高昂的领域具有极其重要的意义。
这意味着以后训练机器人可能不再需要昂贵的物理实验室,只需要喂给它几十万小时的 YouTube 工业操作视频,它就能在“梦境”里学会拧螺丝,这才是工业界最想看到的世界模型落地路径。
3. 空间智能流派:从 2D 到可交互 3D 世界
World Labs 是李飞飞在2024年创立的初创公司,成立后迅速爆红,短短四个月内估值便突破 10 亿美元,晋升为独角兽企业。World Labs 致力于构建能够感知、生成、推理并与3D世界互动的前沿世界模型。
官网地址:https://www.worldlabs.ai/blog
Wold Labs的主要技术成果:
1. Marble :多模态 3D 世界生成模型
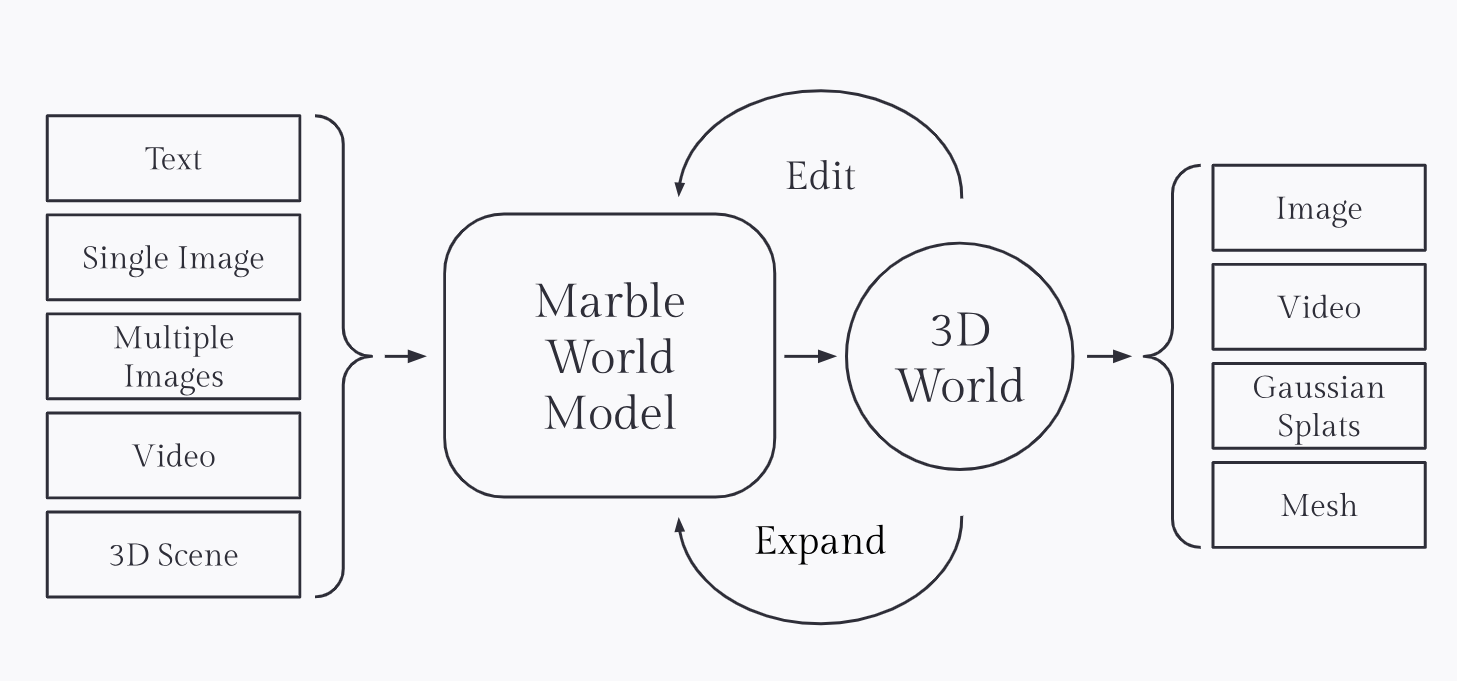
Marble 是 World Labs 推出的第一个多模态世界模型。
3D 世界生成: 用户只需提供一张 2D 图片或一段文字,Marble 就能生成一个持久且可交互的三维环境。
无限扩展: 与传统的短视频生成不同,Marble 生成的是场景。你可以在生成的 3D 空间里漫游,甚至跳出初始图片的框架去探索未知的边界。
创意控制: 允许用户通过草图和自然语言实时编辑场景的布局。
由于Marble输出了3D Gaussian Splatting ,所以他的输出可以导出为高精度视觉流:Gaussian Splats (.ply)和Triangle Meshes (GLB/OBJ),和传统的3d建模软件无缝连接,但是要注意的是他和传统的建模软件不一样,他不是显示去利用公式和代码建模,完全是模型生成的。
2. RTFM: 实时帧模型
这是一项实时的生成式世界模型技术。它允许用户在浏览器中交互式探索生成的 3D 环境,保证了视觉的连贯性和物理的稳定性。
RTFM 的设计基于以下 3 个核心原则:
高效性 (Efficiency): RTFM 仅需单块 H100 GPU,即可在交互式帧率下运行推理。
可扩展性 (Scalability): RTFM 旨在随数据量和算力的增加而扩展。它在不依赖显式 3D 表示(如 3D 建模软件中的几何体)的情况下对三维世界进行建模,并采用一种通用的端到端架构,通过大规模视频数据进行学习。
持久性 (Persistence): 你可以与 RTFM 进行无限期的交互,且该世界永远不会被“遗忘”。它模拟的是一个持久存在的 3D 世界,即使你转身离开,它也不会消失。
3. Spark:开源渲染库
为了支持开发者,World Labs 开源了名为 Spark 的渲染库。它能够将当前尖端的 3D Gaussian Splatting (3DGS) 技术原生集成到 Web 开发环境中,极大降低了在网页上渲染高质量 3D AI 内容的门槛。
Marble的交互目前主要体现在空间导航和环境编辑上,但是,未来的目标是空间智能,所以动作交互应该是其未来的核心发展方向。
4. 总结
通过两篇文章简单介绍了世界模型,可以看到世界模型通往AGI的核心跃迁:
从“理解”到“生成”
JEPA学习世界的抽象规律,在潜在空间中捕捉结构与因果。Sora等生成模型直接合成逼真、符合物理的动态视觉世界,标志着从“知道世界如何运作”到“亲手创造世界”的跨越。
从“观看”到“行动”
Genie与Dreamer将世界模型推向可交互的新阶段。Genie让静态画面变成可操控的环境,Dreamer让智能体在梦境中试错与规划,共同指向一个核心:智能必须通过行动来验证并影响对世界的理解。
从“2D”到“3D”
World Labs等探索使世界模型走向空间化与持久化。生成的3D环境可与人类物理体验对齐,为游戏、仿真、具身智能的虚拟预训练提供了新的基础设施。
现在不同路径处于并行探索阶段。未来的世界模型可能融合各家之长:既能理解抽象规律,又能生成动态场景,还能支持智能体在其中安全高效地学习交互策略。
至少世界模型已从概念走向实践,成为快速演进的AI基础设施。演进方向也日益清晰:智能的本质,在于构建并利用一个内在的、可推演的、能与现实互动的世界模型。 幸运的是,我们正见证这一进程。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号