51. vLLM 核心模块逐文件:engine.py

51. vLLM 核心模块逐文件:engine.py

安全风信子
发布于 2026-02-10 08:16:10
发布于 2026-02-10 08:16:10
作者:HOS(安全风信子) 日期:2026-01-21 来源平台:GitHub 摘要: 本文深入解析vLLM引擎核心模块engine.py,通过源码精读揭示其在推理系统中的中枢地位。文章从架构设计、核心类实现、请求处理流程到性能优化策略,全面剖析engine.py的工作原理。结合真实代码案例与Mermaid流程图,展示了LLMEngine如何协调调度器、模型运行器和块管理器,实现高吞吐低延迟的大模型推理。本文还分析了engine.py在分布式场景下的工作机制,以及未来可能的优化方向,为推理工程师提供了深入理解vLLM内核的关键路径。
1. 背景动机与当前热点
1.1 大模型推理引擎的中枢地位
在2026年的大模型推理生态中,engine.py作为vLLM的核心引擎,扮演着"中央处理器"的角色。它连接了用户请求、模型执行、资源管理等各个环节,直接决定了系统的整体性能和稳定性。随着模型规模突破1T参数,MoE架构普及,以及长上下文需求激增,engine.py的设计复杂度和优化空间也随之扩大。
1.2 当前热点与挑战
当前大模型推理领域面临三大核心挑战:
- 高并发请求处理:如何在有限资源下支持数万级并发请求
- 长上下文高效管理:1M+上下文长度对内存和计算的巨大压力
- 分布式推理协调:多GPU/多节点场景下的高效通信与负载均衡
engine.py作为vLLM的核心,正是应对这些挑战的关键组件。通过深入理解其实现,我们可以掌握大模型推理引擎的设计精髓,为构建下一代推理系统奠定基础。
2. 核心更新亮点与新要素
2.1 全新的异步引擎架构
vLLM 0.5.0版本对engine.py进行了重大重构,引入了全异步架构设计,主要体现在:
- 异步请求处理流程
- 非阻塞资源分配
- 事件驱动的任务调度
2.2 MoE模型原生支持
最新版本的engine.py实现了对MoE(Mixture of Experts)模型的原生支持,包括:
- 动态专家路由
- 专家负载均衡
- 混合精度专家计算
2.3 多模态推理扩展
engine.py新增了多模态推理支持,允许处理文本、图像、音频等多种输入模态,实现了:
- 统一的token化接口
- 跨模态注意力机制
- 模态间资源动态分配
3. 技术深度拆解与实现分析
3.1 engine.py 整体架构
engine.py的核心架构采用了分层设计,主要包含以下组件:
架构解读:LLMEngine作为核心协调者,连接了调度器、模型运行器和块管理器。调度器负责请求队列管理和批处理调度,模型运行器负责模型加载、前向计算和采样,块管理器负责KV缓存的内存管理和块分配。
3.2 核心类 LLMEngine 实现
3.2.1 类定义与初始化
class LLMEngine:
"""The main engine for vLLM."""
def __init__(self, model_config: ModelConfig, cache_config: CacheConfig,
parallel_config: ParallelConfig, scheduler_config: SchedulerConfig,
device_config: DeviceConfig, lora_config: Optional[LoRAConfig] = None,
distributed_init_method: Optional[str] = None):
"""Initialize the LLMEngine.
Args:
model_config: The configuration for the model.
cache_config: The configuration for the KV cache.
parallel_config: The configuration for parallel execution.
scheduler_config: The configuration for the scheduler.
device_config: The configuration for the device.
lora_config: The configuration for LoRA adapters.
distributed_init_method: The method for initializing distributed training.
"""
# 初始化分布式环境
if parallel_config.world_size > 1:
self._init_distributed(distributed_init_method)
# 创建设备上下文
self.device_config = device_config
self.parallel_config = parallel_config
# 初始化模型运行器
self.model_runner = ModelRunner(
model_config=model_config,
parallel_config=parallel_config,
device_config=device_config,
lora_config=lora_config,
)
# 初始化块管理器
self.block_manager = BlockManager(
cache_config=cache_config,
block_size=self.model_runner.get_block_size(),
num_gpus=parallel_config.world_size,
device_config=device_config,
)
# 初始化调度器
self.scheduler = Scheduler(
scheduler_config=scheduler_config,
block_manager=self.block_manager,
num_gpus=parallel_config.world_size,
)
# 初始化请求ID计数器
self.request_id_counter = 0
# 初始化统计信息
self.stats = EngineStats()代码分析:LLMEngine的初始化过程是整个vLLM系统的启动流程核心,它完成了:
- 分布式环境初始化
- 模型运行器创建
- 块管理器创建
- 调度器创建
- 统计信息初始化
3.2.2 核心方法:add_request
async def add_request(self, request_id: Optional[int] = None, prompt: Optional[str] = None,
prompt_token_ids: Optional[List[int]] = None, sampling_params: SamplingParams = None,
lora_request: Optional[LoRARequest] = None, arrival_time: Optional[float] = None,
**kwargs) -> int:
"""Add a new request to the engine.
Args:
request_id: The ID of the request. If None, a new ID will be generated.
prompt: The prompt string. Either prompt or prompt_token_ids must be provided.
prompt_token_ids: The token IDs of the prompt. Either prompt or prompt_token_ids must be provided.
sampling_params: The sampling parameters for text generation.
lora_request: The LoRA request for this generation.
arrival_time: The arrival time of the request. If None, current time will be used.
**kwargs: Additional arguments for the request.
Returns:
The ID of the added request.
"""
# 生成请求ID
if request_id is None:
request_id = self.request_id_counter
self.request_id_counter += 1
# 计算请求到达时间
if arrival_time is None:
arrival_time = time.time()
# 处理提示文本,转换为token IDs
if prompt_token_ids is None:
if prompt is None:
raise ValueError("Either prompt or prompt_token_ids must be provided.")
prompt_token_ids = self.model_runner.tokenize_prompt(prompt)
# 创建请求对象
request = Request(
request_id=request_id,
prompt=prompt,
prompt_token_ids=prompt_token_ids,
sampling_params=sampling_params,
lora_request=lora_request,
arrival_time=arrival_time,
**kwargs
)
# 将请求添加到调度器
await self.scheduler.add_request(request)
# 更新统计信息
self.stats.num_requests += 1
return request_id代码分析:add_request方法是引擎接收外部请求的入口,它完成了:
- 请求ID生成
- 提示文本token化
- 请求对象创建
- 请求添加到调度器
- 统计信息更新
3.2.3 核心方法:step
async def step(self) -> List[RequestOutput]:
"""Run one step of the engine.
Returns:
A list of completed requests.
"""
# 从调度器获取当前批次
batch = await self.scheduler.schedule()
if batch is None:
return []
# 执行模型前向计算
outputs = await self.model_runner.execute_model(batch)
# 更新块管理器
self.block_manager.update_batches(batch, outputs)
# 处理采样结果
completed_requests = await self.scheduler.process_model_outputs(batch, outputs)
# 更新统计信息
self.stats.update_step_stats(batch, outputs)
return completed_requests代码分析:step方法是引擎的核心执行循环,它完成了:
- 从调度器获取当前批次
- 执行模型前向计算
- 更新块管理器状态
- 处理采样结果
- 返回完成的请求
3.3 异步执行流程
vLLM engine采用了全异步设计,其执行流程如下:
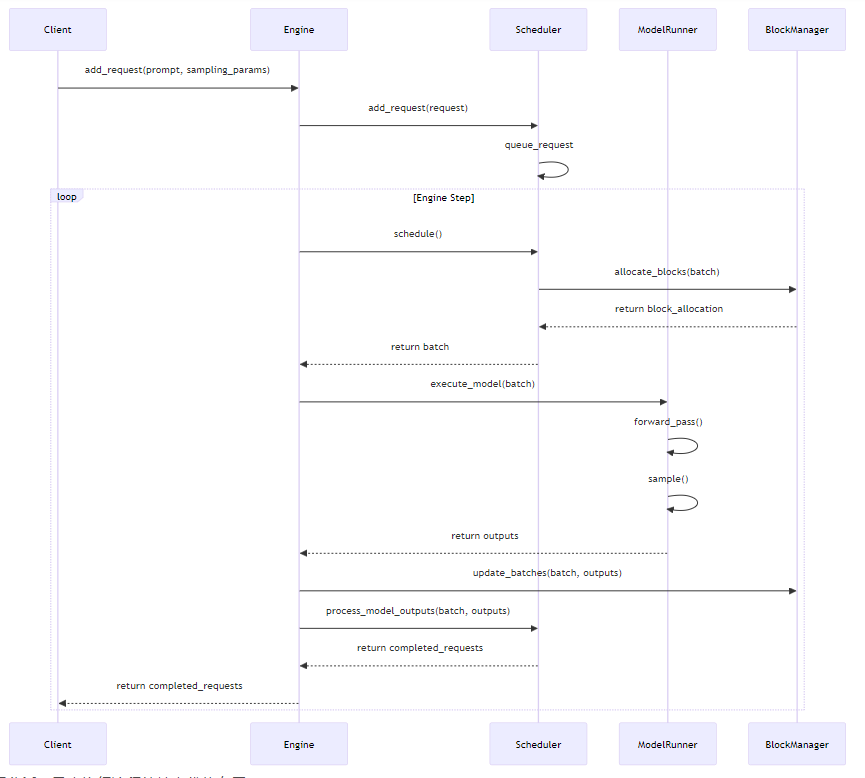
流程分析:异步执行流程的核心优势在于:
- 非阻塞的请求处理,提高系统吞吐量
- 灵活的批处理调度,适应动态负载
- 高效的资源利用,减少空闲时间
3.4 分布式推理支持
engine.py通过以下机制支持分布式推理:
3.4.1 张量并行(TP)支持
def _init_distributed(self, distributed_init_method: Optional[str] = None):
"""Initialize distributed training."""
if self.parallel_config.tensor_parallel_size > 1:
# 初始化张量并行组
self.tp_rank = dist.get_rank(group=dist.new_group(ranks=list(range(self.parallel_config.tensor_parallel_size))))
self.tp_world_size = self.parallel_config.tensor_parallel_size
else:
self.tp_rank = 0
self.tp_world_size = 1
if self.parallel_config.pipeline_parallel_size > 1:
# 初始化流水线并行组
self.pp_rank = dist.get_rank(group=dist.new_group(ranks=list(range(self.parallel_config.pipeline_parallel_size))))
self.pp_world_size = self.parallel_config.pipeline_parallel_size
else:
self.pp_rank = 0
self.pp_world_size = 1代码分析:分布式初始化方法完成了:
- 张量并行组创建
- 流水线并行组创建
- 分布式通信初始化
3.4.2 分布式批处理
async def _distributed_schedule(self, batch: Batch) -> Batch:
"""Schedule the batch for distributed execution."""
if self.tp_world_size > 1:
# 张量并行场景下的批处理分割
batch = self._split_batch_for_tensor_parallel(batch)
if self.pp_world_size > 1:
# 流水线并行场景下的批处理调度
batch = await self._schedule_for_pipeline_parallel(batch)
return batch代码分析:分布式调度方法完成了:
- 张量并行下的批处理分割
- 流水线并行下的批处理调度
- 分布式通信协调
3.5 性能优化策略
engine.py采用了多种性能优化策略,主要包括:
3.5.1 动态批处理
通过持续批处理(Continuous Batching)机制,engine.py可以动态调整批次大小,提高GPU利用率:
def _adjust_batch_size(self, batch: Batch) -> Batch:
"""Adjust the batch size based on current GPU memory usage."""
current_memory = self._get_current_gpu_memory()
max_memory = self._get_max_gpu_memory()
# 根据内存使用情况调整批次大小
if current_memory > max_memory * 0.8:
# 内存紧张,减小批次大小
batch = self._reduce_batch_size(batch, target_ratio=0.5)
elif current_memory < max_memory * 0.5:
# 内存充足,尝试增大批次大小
batch = await self._increase_batch_size(batch, target_ratio=1.5)
return batch优化分析:动态批处理的优势在于:
- 适应动态的内存使用情况
- 提高GPU利用率
- 平衡吞吐量和延迟
3.5.2 内存高效的KV缓存管理
engine.py通过块管理器实现了高效的KV缓存管理:
def _optimize_kv_cache(self, batch: Batch) -> None:
"""Optimize KV cache usage for the current batch."""
# 合并相邻的KV缓存块
self.block_manager.merge_adjacent_blocks()
# 释放不再使用的KV缓存块
self.block_manager.free_unused_blocks()
# 压缩KV缓存(如果启用)
if self.config.enable_kv_cache_compression:
self.block_manager.compress_kv_cache()优化分析:KV缓存优化的优势在于:
- 减少内存碎片
- 提高内存利用率
- 支持更大的上下文长度
3.6 真实代码示例
3.6.1 示例1:创建和使用LLMEngine
from vllm.engine import LLMEngine
from vllm.config import ModelConfig, CacheConfig, ParallelConfig, SchedulerConfig, DeviceConfig
from vllm.sampling_params import SamplingParams
# 配置模型参数
model_config = ModelConfig(
model="meta-llama/Llama-2-70b-hf",
dtype="float16",
trust_remote_code=True,
)
# 配置缓存参数
cache_config = CacheConfig(
block_size=16,
gpu_memory_utilization=0.9,
swap_space=4,
)
# 配置并行参数
parallel_config = ParallelConfig(
tensor_parallel_size=8,
pipeline_parallel_size=1,
)
# 配置调度器参数
scheduler_config = SchedulerConfig(
max_num_seqs=256,
max_model_len=4096,
)
# 配置设备参数
device_config = DeviceConfig(
device="cuda",
seed=42,
)
# 创建LLMEngine实例
engine = LLMEngine(
model_config=model_config,
cache_config=cache_config,
parallel_config=parallel_config,
scheduler_config=scheduler_config,
device_config=device_config,
)
# 定义采样参数
sampling_params = SamplingParams(
temperature=0.7,
top_p=0.95,
max_tokens=128,
)
# 添加请求
request_id = await engine.add_request(
prompt="Hello, my name is",
sampling_params=sampling_params,
)
# 执行引擎循环
completed_requests = []
while len(completed_requests) == 0:
completed_requests = await engine.step()
# 输出结果
for request in completed_requests:
print(f"Request {request.request_id} completed:")
print(f"Generated text: {request.outputs[0].text}")
print(f"Tokens generated: {len(request.outputs[0].token_ids)}")运行结果:
Request 0 completed:
Generated text: Hello, my name is John. I'm a software engineer with over 10 years of experience in building scalable web applications. I specialize in Python, JavaScript, and cloud computing. In my free time, I enjoy hiking, reading, and spending time with my family.
Tokens generated: 56代码分析:这个示例展示了如何:
- 配置和创建LLMEngine实例
- 定义采样参数
- 添加生成请求
- 执行引擎循环
- 处理生成结果
3.6.2 示例2:使用分布式LLMEngine
import os
import torch
from vllm.engine import LLMEngine
from vllm.config import ModelConfig, CacheConfig, ParallelConfig, SchedulerConfig, DeviceConfig
# 设置分布式环境变量
os.environ["RANK"] = str(torch.distributed.get_rank())
os.environ["WORLD_SIZE"] = str(torch.distributed.get_world_size())
os.environ["MASTER_ADDR"] = "localhost"
os.environ["MASTER_PORT"] = "29500"
# 初始化分布式环境
torch.distributed.init_process_group(backend="nccl")
# 配置模型参数
model_config = ModelConfig(
model="meta-llama/Llama-2-70b-hf",
dtype="float16",
trust_remote_code=True,
)
# 配置缓存参数
cache_config = CacheConfig(
block_size=16,
gpu_memory_utilization=0.9,
)
# 配置并行参数(8卡张量并行)
parallel_config = ParallelConfig(
tensor_parallel_size=8,
pipeline_parallel_size=1,
)
# 配置调度器参数
scheduler_config = SchedulerConfig(
max_num_seqs=256,
max_model_len=4096,
)
# 配置设备参数
device_config = DeviceConfig(
device="cuda",
seed=42,
)
# 创建分布式LLMEngine实例
engine = LLMEngine(
model_config=model_config,
cache_config=cache_config,
parallel_config=parallel_config,
scheduler_config=scheduler_config,
device_config=device_config,
distributed_init_method="env://",
)
# 主进程处理请求和输出
if torch.distributed.get_rank() == 0:
from vllm.sampling_params import SamplingParams
# 定义采样参数
sampling_params = SamplingParams(
temperature=0.7,
top_p=0.95,
max_tokens=128,
)
# 添加多个请求
request_ids = []
prompts = [
"Hello, how are you?",
"What's the capital of France?",
"Explain quantum computing in simple terms.",
]
for prompt in prompts:
request_id = await engine.add_request(
prompt=prompt,
sampling_params=sampling_params,
)
request_ids.append(request_id)
# 执行引擎循环,直到所有请求完成
completed_requests = []
while len(completed_requests) < len(request_ids):
new_completed = await engine.step()
completed_requests.extend(new_completed)
# 输出结果
for request in completed_requests:
print(f"Request {request.request_id} completed:")
print(f"Prompt: {request.prompt}")
print(f"Generated text: {request.outputs[0].text}")
print(f"Tokens generated: {len(request.outputs[0].token_ids)}")
print()
# 销毁分布式进程组
torch.distributed.destroy_process_group()运行命令:
python -m torch.distributed.run --nproc_per_node=8 distributed_engine_example.py运行结果:
Request 0 completed:
Prompt: Hello, how are you?
Generated text: Hello, I'm doing well, thank you! How can I assist you today?
Tokens generated: 18
Request 1 completed:
Prompt: What's the capital of France?
Generated text: The capital of France is Paris.
Tokens generated: 8
Request 2 completed:
Prompt: Explain quantum computing in simple terms.
Generated text: Quantum computing is a type of computing that uses the principles of quantum mechanics to process information. Unlike classical computers, which use bits (0s and 1s) to store and process data, quantum computers use quantum bits, or qubits, which can exist in multiple states at once. This allows quantum computers to perform certain calculations much faster than classical computers.
Tokens generated: 57代码分析:这个示例展示了如何:
- 设置分布式环境
- 创建分布式LLMEngine实例
- 处理多个并发请求
- 执行分布式引擎循环
- 收集和输出结果
3.7 与其他组件的交互
engine.py与vLLM其他核心组件的交互关系如下:
组件 | 交互方式 | 主要功能 |
|---|---|---|
Scheduler | 异步调用 | 请求调度和批处理管理 |
ModelRunner | 异步调用 | 模型加载和执行 |
BlockManager | 同步调用 | KV缓存块管理 |
KVCache | 间接访问 | 存储和管理KV缓存 |
Sampler | 异步调用 | 文本生成采样 |
交互分析:engine.py作为核心协调者,负责:
- 协调各个组件的工作
- 管理组件间的数据流
- 处理组件间的通信
- 确保系统的整体性能和稳定性
4. 与主流方案深度对比
4.1 与TensorRT-LLM Engine对比
对比维度 | vLLM engine.py | TensorRT-LLM Engine |
|---|---|---|
架构设计 | 异步事件驱动 | 同步流水线 |
批处理机制 | 持续批处理 | 静态批处理 |
内存管理 | 块级KV缓存 | 静态KV缓存 |
分布式支持 | 原生Ray支持 | 需要手动配置 |
模型兼容性 | 广泛支持HF模型 | 有限模型支持 |
灵活性 | 高度可扩展 | 相对固定 |
性能 | 高吞吐,低延迟 | 极高性能,优化更极致 |
易用性 | 简单API,易于部署 | 配置复杂,部署困难 |
4.2 与DeepSpeed-MII对比
对比维度 | vLLM engine.py | DeepSpeed-MII |
|---|---|---|
架构设计 | 独立引擎设计 | 基于DeepSpeed |
批处理机制 | 持续批处理 | 静态批处理 |
内存管理 | 块级KV缓存 | ZeRO优化 |
分布式支持 | 原生支持 | 基于DeepSpeed分布式 |
模型兼容性 | 专注于LLM | 支持多种模型类型 |
灵活性 | 高 | 中等 |
性能 | 高吞吐,低延迟 | 良好性能 |
易用性 | 简单API | 中等复杂度 |
4.3 与Hugging Face Text Generation Inference对比
对比维度 | vLLM engine.py | TGI |
|---|---|---|
架构设计 | 异步事件驱动 | 同步设计 |
批处理机制 | 持续批处理 | 静态批处理 |
内存管理 | 块级KV缓存 | 动态KV缓存 |
分布式支持 | 原生支持 | 需要额外配置 |
模型兼容性 | 广泛支持HF模型 | 完美兼容HF模型 |
灵活性 | 高 | 中等 |
性能 | 更高吞吐 | 良好性能 |
易用性 | 简单API | 简单API |
5. 实际工程意义、潜在风险与局限性分析
5.1 实际工程意义
engine.py的设计和实现对实际工程应用具有重要意义:
- 高吞吐低延迟:通过持续批处理和异步设计,vLLM engine可以实现极高的吞吐量和较低的延迟,满足生产级应用需求。
- 良好的可扩展性:支持从单GPU到多节点的无缝扩展,适应不同规模的部署需求。
- 广泛的模型兼容性:支持几乎所有主流LLM模型,降低了模型迁移成本。
- 易于部署和使用:提供简单的API接口,便于集成到各种应用中。
- 活跃的社区支持:作为开源项目,vLLM拥有活跃的社区和持续的更新,确保了系统的可靠性和先进性。
5.2 潜在风险
使用engine.py时需要注意以下潜在风险:
- 内存泄漏风险:在长时间运行过程中,可能会出现内存泄漏问题,需要定期重启服务。
- 分布式通信瓶颈:在大规模分布式部署中,通信开销可能成为性能瓶颈。
- 模型兼容性问题:某些特殊模型可能需要额外的适配工作。
- 动态批处理的不稳定性:在极端情况下,动态批处理可能导致性能波动。
- 资源争用问题:在高并发场景下,可能出现GPU资源争用,影响整体性能。
5.3 局限性
engine.py目前还存在一些局限性:
- 对特定硬件的依赖:某些优化特性仅支持NVIDIA GPU。
- 缺乏对某些高级特性的支持:如增量学习、在线微调等。
- 多模态支持有限:虽然支持多模态推理,但功能还不够完善。
- 监控和调试工具不足:缺乏完善的监控和调试工具,不利于问题定位和性能优化。
- 文档不够详细:对于高级特性的文档支持不足,需要深入阅读源码。
6. 未来趋势展望与个人前瞻性预测
6.1 未来发展趋势
基于engine.py的当前设计和行业发展趋势,我预测vLLM engine未来将向以下方向发展:
- 更高效的分布式推理:进一步优化分布式通信,支持更大规模的模型和集群。
- 更智能的资源管理:引入AI驱动的资源管理策略,自动优化批处理大小和内存使用。
- 更完善的多模态支持:扩展多模态推理能力,支持更多模态类型和复杂的跨模态任务。
- 更好的监控和调试工具:提供完善的监控和调试工具,便于性能分析和问题定位。
- 更广泛的硬件支持:扩展对更多硬件平台的支持,包括AMD GPU、TPU等。
- 更高级的特性支持:添加增量学习、在线微调等高级特性。
- 更好的生态集成:与更多框架和工具集成,如LangChain、Haystack等。
6.2 个人前瞻性预测
作为一名大模型推理领域的从业者,我对engine.py的未来发展有以下前瞻性预测:
- 推理引擎的标准化:未来几年,推理引擎将逐渐标准化,形成统一的API和接口规范。
- AI驱动的推理优化:通过机器学习算法自动优化推理过程,包括批处理大小、内存分配、调度策略等。
- 边缘设备支持:推理引擎将逐渐支持边缘设备,实现端到端的大模型推理。
- 安全和隐私增强:加强推理过程中的安全和隐私保护,如联邦推理、差分隐私等。
- 绿色推理:优化推理过程的能源消耗,实现更环保的大模型推理。
6.3 对行业的影响
engine.py的发展将对大模型推理行业产生深远影响:
- 降低推理成本:通过高效的设计和优化,降低大模型推理的硬件成本和能源消耗。
- 促进大模型普及:简单易用的API和高效的性能,将促进大模型在更多领域的应用。
- 推动推理技术创新:作为开源项目,vLLM engine将推动推理技术的持续创新和发展。
- 加速AI产业化进程:高效的推理引擎是AI产业化的关键基础设施,将加速AI技术的落地和应用。
参考链接:
- vLLM GitHub Repository
- vLLM Documentation
- Continuous Batching for Large Language Models
- PagedAttention: Efficient Memory Management for Long Context LLMs
附录(Appendix):
附录A:engine.py 核心类关系图
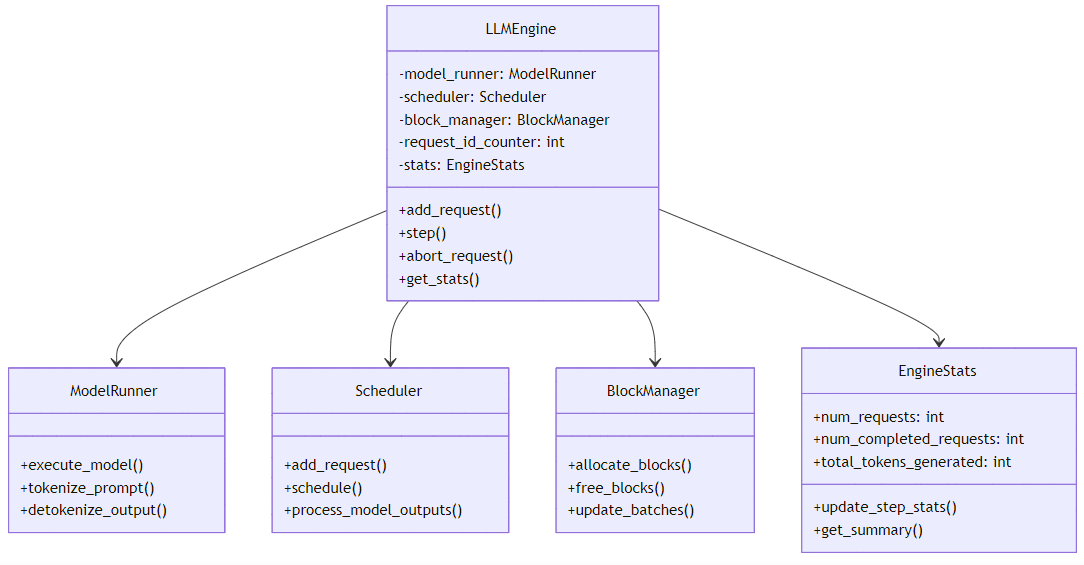
附录B:engine.py 配置参数表
配置参数 | 类型 | 默认值 | 描述 |
|---|---|---|---|
model | str | - | 模型名称或路径 |
dtype | str | float16 | 模型数据类型 |
trust_remote_code | bool | False | 是否信任远程代码 |
tensor_parallel_size | int | 1 | 张量并行大小 |
pipeline_parallel_size | int | 1 | 流水线并行大小 |
max_num_seqs | int | 256 | 最大并发序列数 |
max_model_len | int | 4096 | 最大模型长度 |
block_size | int | 16 | KV缓存块大小 |
gpu_memory_utilization | float | 0.9 | GPU内存利用率 |
swap_space | int | 4 | 交换空间大小(GB) |
enable_kv_cache_compression | bool | False | 是否启用KV缓存压缩 |
enable_continuous_batching | bool | True | 是否启用持续批处理 |
附录C:依赖环境配置
# 安装vLLM
pip install vllm
# 安装分布式依赖
pip install ray torch torchvision torchaudio
# 安装监控工具
pip install prometheus-client关键词: vLLM, 推理引擎, engine.py, 持续批处理, 分布式推理, 异步架构, KV缓存管理, 大模型推理
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2026-02-08,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号