ITIL v5:Discover不是“收需求”,ITIL 第5版为什么把洞察放在第一步
原创
ITIL v5:Discover不是“收需求”,ITIL 第5版为什么把洞察放在第一步
原创
AI加ITIL教练长河achotsao
发布于 2026-02-06 14:16:39
发布于 2026-02-06 14:16:39
一、Discover被放在第一位,是在纠正一种长期的“伪高效”
2026年1月29日,PeopleCert正式发布了ITIL 第5版。作为ITIL官方中国区产品大使,我将会推出系列文章帮大家解读ITIL 第5版到底有哪些重大的更新。

ITIL v5(即ITIL 第5版)已经正式发布。很多人第一次看到生命周期的八个阶段里把Discover(发现)放在第一步,会下意识觉得:这不就是“需求分析”的换皮吗?但做过产品与交付的人都知道,组织最常见的浪费,恰恰发生在“需求看起来很明确”的时候——你以为你在高效推进,其实你在把未经验证的假设快速变成系统欠账。
所谓伪高效,就是把“收需求”当成起点:业务说要什么,团队赶紧写方案、排期、开发、上线。上线之后才发现:
• 需求描述的是手段,而不是目的
• 真正的痛点不在这里,而在流程的另一个断点
• 使用场景没想清楚,例外情况一堆
• 验收标准模糊,返工成为常态
• 支持与运营压力激增,体验摩擦被放大
这类问题不是努力不够,而是起点错了。Discover被放到第一位,就是ITIL 第5版在提醒组织:价值交付的起点不是“需求”,而是“机会”。机会意味着你要先看见问题的本质,先识别价值在哪,先把不确定性压下去,然后再进入设计与构建。否则你会把团队的能力消耗在无效建设上,最后用事故、返工与抱怨来支付利息。
Discover不是更慢,而是更稳;不是更玄,而是更可控。它的目标只有一个:让后面的每一步都更接近真实价值。
二、ITIL 第5版升级内容全景
要理解Discover为什么关键,必须先把ITIL 第5版的更新内容概述完整交代。因为Discover不是单点技巧,它被放在第一位,是整个框架重心迁移的一部分。
1)定位升级:从服务管理走向数字产品与服务管理
ITIL 第5版把管理对象扩展为数字产品与服务的整体,强调端到端价值交付。Discover之所以重要,是因为数字产品与服务的价值往往来自对机会的把握,而不是对需求清单的完成。你需要先识别“要创造的结果”,再决定“要交付的形态”。
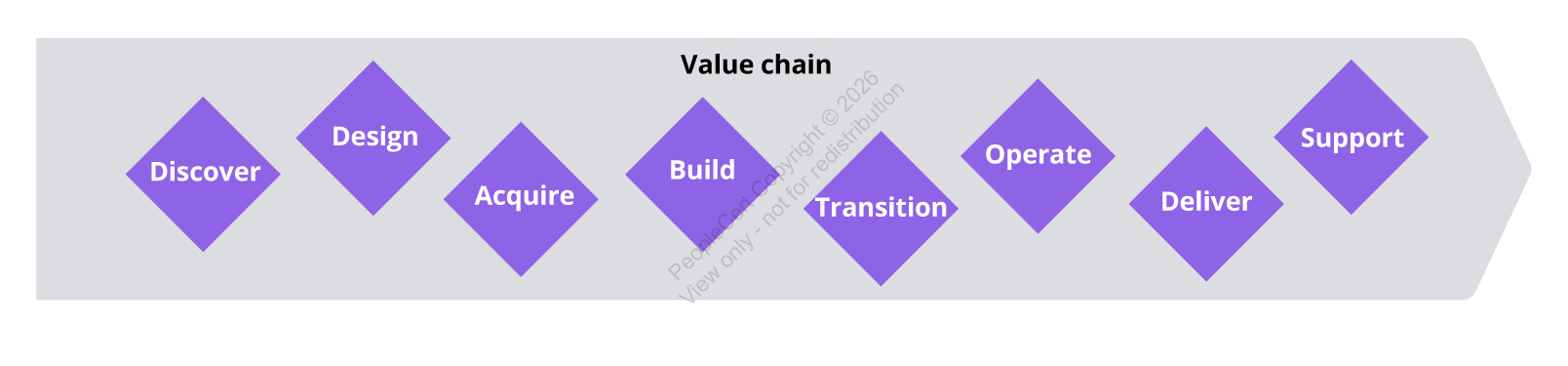
2)生命周期模型升级:八个阶段覆盖从想法到退役
ITIL 第5版提出生命周期八个阶段:Discover、Design、Acquire、Build、Transition、Operate、Deliver、Support。Discover位于第一步,意味着框架要求组织把洞察与价值定义做成正式阶段,而不是靠经验拍脑袋。它要给后续阶段提供清晰输入,减少返工与风险集中爆发。
3)体验进入核心:Discover阶段决定体验上限
体验进入核心后,Discover不再只是“业务访谈”,它必须看到用户旅程(service journey,服务旅程)的摩擦点,识别触点(touchpoint,接触点)上的不确定性与绕路。很多体验问题不是支持阶段解决不了,而是上游从一开始就没有把旅程看清。
4)AI进入框架中心:没有高质量输入,AI与自动化只会放大偏差
AI越深入,数据质量门槛越高。Discover阶段如果不能定义清晰的验收标准(acceptance criteria,验收标准)、口径与证据链,后续自动化与智能化就无法稳定落地,风险边界也无法治理。
5)实践使用方式变化:从清单背诵走向情境化组合
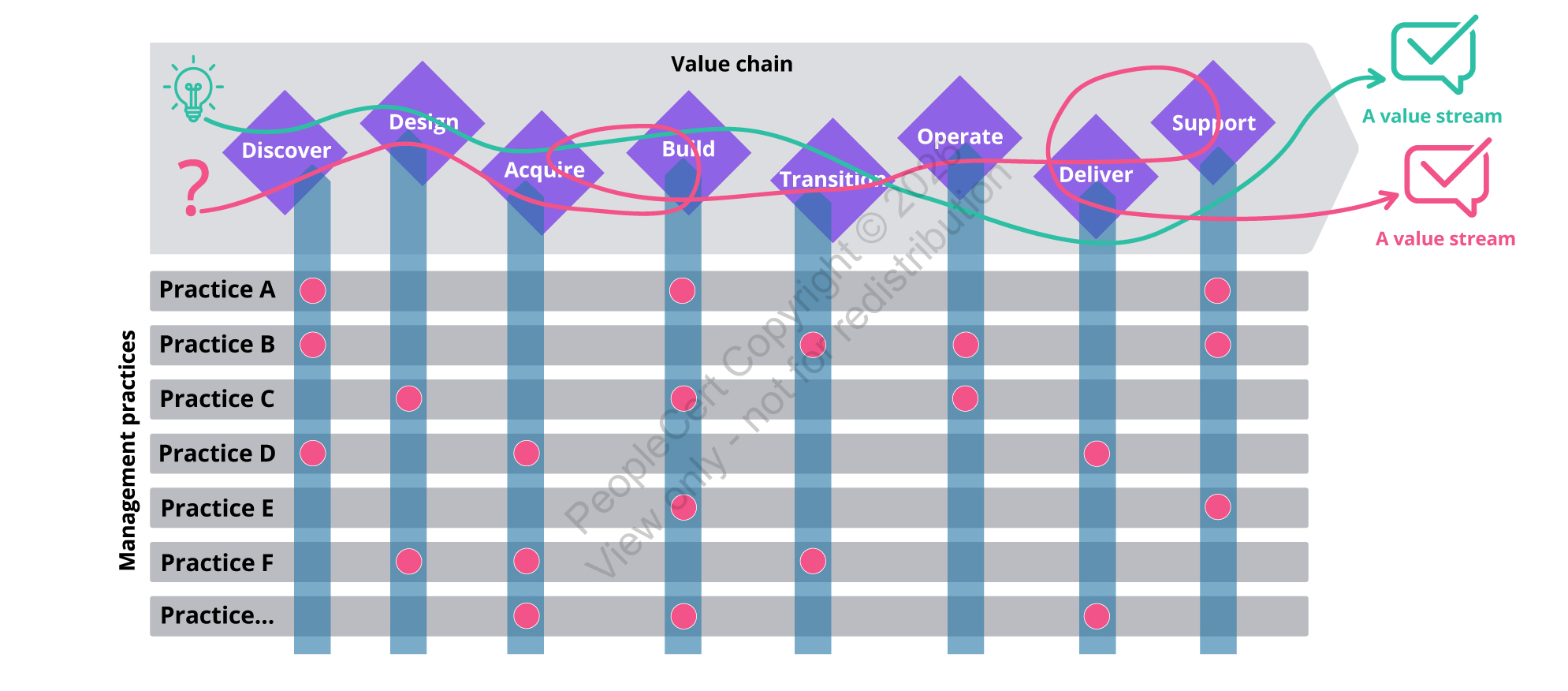
Discover并不属于某一个“流程实践”的独角戏,它需要多实践协同:业务分析、关系管理、度量与报告、风险管理、知识管理等围绕价值流组合,形成可持续的洞察与决策机制。
这五点连起来,你会发现Discover被放在第一位,是因为ITIL 第5版要组织先把价值与不确定性管理好,再去谈速度与规模。
三、Discover到底在做什么:不是收集“想要”,而是识别“值得做”
把Discover做成“收需求”,最大的风险是:你会把业务表达的解决方案当成问题本身。真正的Discover要完成三件事:找机会、验假设、定价值。

1)找机会:把问题从局部症状拉回端到端旅程
机会往往藏在旅程断点里,而不是藏在某个部门的抱怨里。Discover要做的是把问题放回端到端价值流,看清摩擦在哪里。
常见机会识别角度包括:
• 等待与排队:哪里等待占比最高
• 交接与转派:哪里责任边界最混乱
• 信息缺口:哪里总要反复补资料
• 返工与重复:哪些问题一再发生
• 不确定性:用户最焦虑的时刻在哪里
• 风险集中:事故与投诉最常发生在哪段链路
这一步的价值是:把“想要一个功能”变成“要消除一个摩擦”,把“想上线一个系统”变成“要缩短一个周期时间”。机会一旦清晰,解决方案才有可能做对。
2)验假设:把“我觉得”变成“我能证明”
需求往往带着假设:做了A就会带来B。但如果不验证,组织就会把假设当事实,把不确定性推给后面阶段。Discover要做的是把关键假设找出来,并设计验证方式。

常见关键假设包括:
• 用户真的需要这个,还是只是暂时抱怨
• 痛点的根因在这里,还是在上游/下游
• 这个改变能改善体验,还是会制造新的摩擦
• 这个改变能被运营与支持承接,还是会造成欠账
• 数据能支撑度量与自动化,还是口径混乱
验证不一定很重。很多时候,一个小范围试点、一个可运行原型(prototype,原型)、一段影子流程,就能把假设验证掉一半。Discover的目的不是把一切确定,而是把最危险的不确定性提前暴露。
3)定价值:把“做了什么”换成“产生什么结果”
Discover阶段要把价值定义成“结果”,而不是“功能列表”。结果需要可衡量,否则后续就无法判断是否成功。
结果可以从三类维度定义:
-- 效率结果
• 周期时间缩短、等待占比下降、一次解决率提升
-- 体验结果
• 触点摩擦减少、不确定性下降、满意度提升
-- 风险结果
• 事故减少、变更风险可控、可审计性提升
当价值以结果形式定义,团队的讨论会变得更清晰:不是争论要不要做某个功能,而是讨论哪种方式更能达成结果。
四、Discover的核心产出:四个交付物,决定后面七步会不会返工
Discover不是讨论会,它必须产生可用交付物。否则它就会被贴上“空谈”的标签。更实用的做法,是把Discover的核心产出收敛到四类交付物,每一类都能直接喂给后续阶段。
1)机会陈述:问题是什么,机会在哪里,为什么现在做
机会陈述不需要长,但要硬:
• 当前痛点与影响范围
• 端到端旅程中的摩擦点位置
• 不做的代价与风险
• 为什么现在值得做(例如业务窗口期、合规要求、客户体验压力)
2)价值假设与验证计划:要验证什么,用什么方式验证
这部分是Discover的灵魂。建议明确:
• 关键假设清单
• 每个假设的验证方式
• 试点范围与时间
• 需要的数据与证据来源
• 失败如何止损与调整
有了验证计划,后续就不会把“未知”带着跑。
3)验收标准:什么算成功,怎么验证,谁来确认
验收标准(acceptance criteria,验收标准)不是测试团队的事情,它是端到端协作的共同语言。建议包括:
• 结果性指标与目标值
• 体验相关指标(例如等待占比、信息往返次数)
• 风险控制指标(例如回滚可用、证据链完整)
• 验收责任人与验收节奏
验收标准越清晰,后面返工越少。
4)最小范围与路线图:先做什么,后做什么,如何扩展
Discover阶段要给出最小可行的路径,而不是一次性大而全:
• MVP(Minimum Viable Product,最小可行产品)或最小改进范围
• 依赖与约束(constraint,约束)
• 与现有系统/流程的兼容点
• 后续扩展路线图与风险点
这四类产出一旦齐,Discover就不再是“讨论”,而是“把不确定性压到可控范围内的决策”。
五、Discover怎么做得稳:一套可直接照做的动作集
下面给出一套更贴近现场的Discover动作集。它不追求完美,但足够把方向拉正,把风险压下去。
动作一:从一条旅程开始,而不是从一份需求开始
先选定一条端到端旅程,把触点串起来:谁发起、谁处理、谁交接、谁验证、谁受影响。重点找摩擦点与绕路点。
可用问题清单:
• 用户最焦虑的时刻在哪里
• 等待最长的环节在哪里
• 信息最容易缺失的环节在哪里
• 交接最多的环节在哪里
• 返工最多的环节在哪里
• 事故与投诉最常发生在哪段

动作二:把关键假设写在桌面上
假设不写出来,就会被默认当事实。建议把假设按三类拆开:
• 价值假设:做了就会带来什么收益
• 可行性假设:技术、流程、组织是否能承接
• 风险假设:可能翻车在哪里,边界怎么定
动作三:设计最小验证,把“拍脑袋”变成“拿证据”
验证方式不必复杂,但要能快速给方向:
• 小范围试点
• 原型与演示
• 影子流程
• 数据回放与历史分析
• 用户访谈与环境验证
关键是把验证结果能对齐到验收标准,让后续决策可追溯。
动作四:提前把运营与支持拉进来,避免欠账
很多项目失败不是做不出来,而是做出来后没人接得住。Discover阶段就要问:
• 运营需要什么可观测性与手册
• 支持需要什么知识与证据链
• 转换阶段需要什么风险控制与回滚机制
• 数据口径能否统一,是否可审计
这一步能显著降低“上线即巅峰”的概率。
六、最常见的三种坑:Discover做不好,后面七步会加倍还债
最后点三种常见坑,很多团队都踩过。
1)把Discover当需求收集会
需求越收越多,方向越走越散。Discover的目标不是把愿望装满,而是把机会与结果钉住,把不确定性压下去。
2)没有验收标准,导致“做完了但没法证明”
没有验收标准,项目就只能靠感觉验收,返工与扯皮不可避免。验收标准必须在Discover阶段定下来,并能被验证。
3)不把运营与支持纳入早期决策,导致欠账滚到后期爆炸
最昂贵的欠账,往往来自上游没想清楚的边界:日志不全、手册缺失、发布说明不清、知识无法回流、数据口径不一致。Discover阶段不处理,后面只能用救火来偿还。
Discover不是为了写漂亮文档,而是为了减少返工、减少事故、减少体验摩擦。它看起来慢一点,但能让整体更快。
ITIL v5把Discover放在生命周期第一步,是ITIL 第5版对“伪高效”的纠偏:Discover不是收需求,而是围绕端到端旅程识别机会、把关键假设摆上桌面并用最小验证拿到证据,再用验收标准把结果定义清楚、把不确定性压到可控范围内,同时提前把运营与支持的承接条件纳入决策;当你把这一步做扎实,后面七个阶段才不会靠返工与救火来完成所谓的交付。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号