彻底封神!智源Emu3登顶Nature



题图摄于故宫神武门
近期国内 AI 圈最大的新闻之一莫过于中国智源的Emu3多模态大模型,登上了 Nature 正刊!
可能有人不懂 Nature 的分量,如果说 AI 顶会是行业的‘入场券’,那么 Nature 正刊就是科研殿堂的‘紫禁之巅’。去年 DeepSeek 论文上过一次Nature,这次是中国科研机构主导的大模型,首次登上这个顶流舞台,直接打破了国外在多模态领域的话语权垄断!
Emu3到底牛在哪?
用一句话总结,就是别的多模态(文本、图片、视频一起懂、一起生)方法,都是“东拼西凑”——给语言模型配个视觉编码器,再搭个扩散模型,像给自行车装摩托车发动机,复杂又费电;
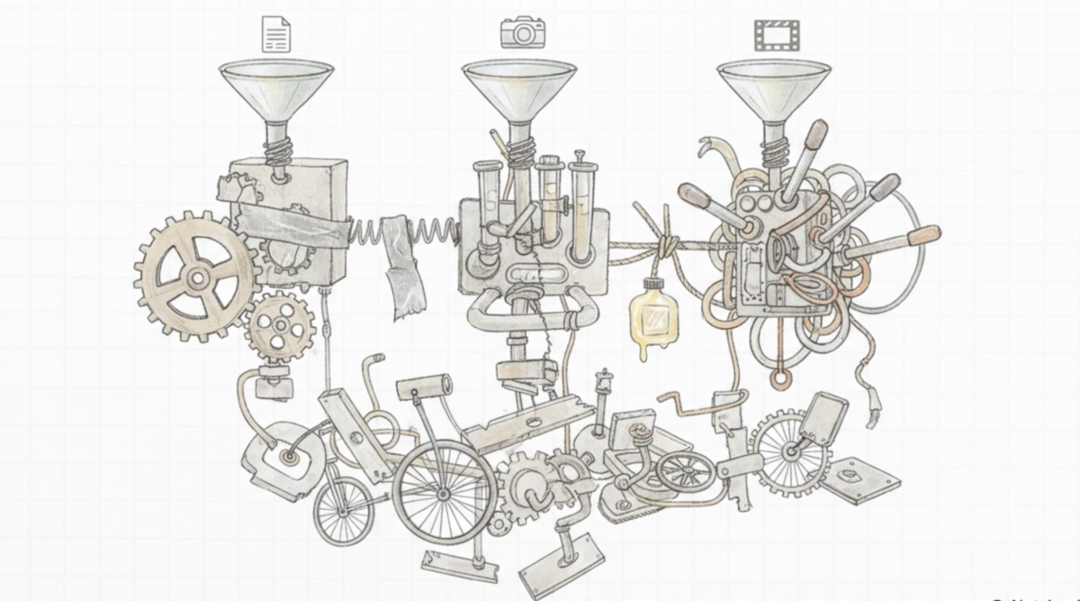
传统模型东拼西凑的模式
而Emu3只靠一招:“预测下一个Token”(类比成“猜下一个字/词”),就搞定了文本、图片、视频的所有任务,架构极简,却比别人更能打、更快和更省钱。
剩余部分把 Emu3 的核心原理以及Nature上的论文精髓,通俗地讲讲。
Emu3核心黑科技
咱们分4个关键点,拆解它的“神仙操作”,每一个都藏着它登Nature的底气!
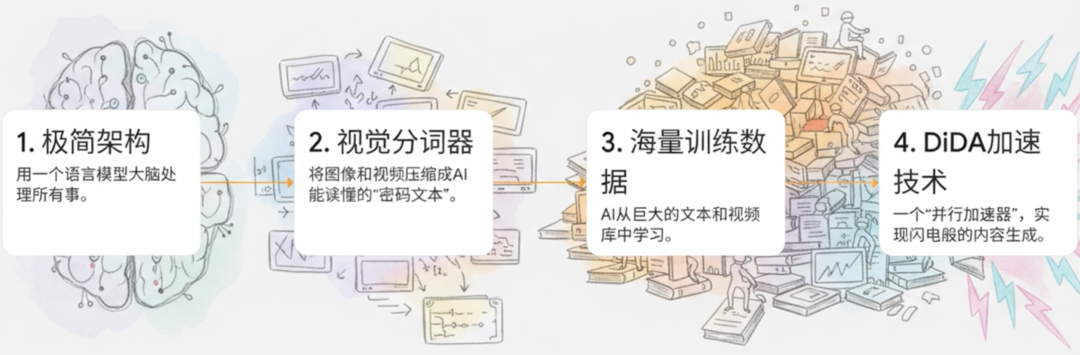
1. 极简架构:放弃“大杂烩”,靠一个“大脑”搞定所有
传统多模态模型,就像一个“组装机”——处理文本靠一个芯片,处理图片靠另一个芯片,处理视频再多加一个,还要专门装个“翻译器”,让这几个芯片能互通,又复杂又笨重,训练一次要花海量电费。
Emu3反其道而行之:只用一个“纯语言模型大脑”(类似ChatGPT的基础架构),不搞任何多余组装。
它的秘诀是:把图片、视频,都“翻译”成语言模型能看懂的“特殊文字”(也就是Token)。比如一张猫的图片,被编码成一串只有模型能懂的“密码文字”,视频就是更长的“密码文字序列”。
这样一来,模型不用学多种技能,只要像我们猜下一个字一样,“猜”出下一个Token,就能同时搞定文本生成、图片生成、视频生成——相当于一个人,不用换工具,就能同时写文章、画画、剪视频。
效果也很惊人:参数量比传统模型少60%(相当于大脑变小了,但更聪明),训练效率提升3倍(原来练1年,现在3个月就够),部署起来也更轻便。
2. 视觉分词器:AI界的“图片/视频压缩大师”
刚才说,Emu3要把图片、视频变成“密码文字”,靠的就是这个“视觉分词器”——相当于给图片、视频做“高效压缩+翻译”,而且压缩后不丢细节。
举个例子:一张512×512的高清图片,直接处理起来太费算力,就像我们要把一本厚书背下来,很难;而视觉分词器能把它压缩成4096个“密码文字”(Token),相当于把厚书改成4096个关键词,背起来就容易多了。
更厉害的是,它还能处理视频:一个4×512×512的视频片段(相当于4帧高清图),也能压缩成4096个Token,而且能保留视频的“时间顺序”——就像把一段视频,改成带顺序的关键词,模型猜下一个Token,就能延续视频的动作。
它还有个创新:加了“3D卷积核”,能同时捕捉图片的“空间信息”(比如猫的耳朵在头顶)和视频的“时间信息”(比如猫在走路,爪子的动作顺序),所以生成的视频,动作更连贯,不会出现“瞬移”“变形”的bug。
3. 海量训练数据:给AI喂了“790年的视频+13万亿字的书”
AI的聪明程度,离不开“喂饭”:喂的资料越多越杂,它就越懂世界。Emu3的“饭量”,堪称惊人,而且越吃越精。
基础版Emu3,就喂了中英文高质量文本、海量开源图片、各类视频(风景、动物、游戏等);到了Emu3.5,直接“加餐”:
- 预训练数据超过13万亿个Token(相当于13万亿个汉字,比人类历史上所有书籍的字数加起来还多);
- 视频数据时长从15年,暴涨到790年(相当于从清朝康熙年间,一直看到现在的所有视频,涵盖教育、科技、娱乐等所有领域);
这么多数据,相当于给Emu3装上了“全世界的知识库+视频库”,它能看懂各种场景、各种动作,生成的内容也更贴近现实——比如生成“教你修自行车”的视频,能准确还原扳手的动作、螺丝的位置,不会出错。
4. DiDA技术:让AI生成速度,从“龟速”变“飞速”
传统自回归模型(比如早期的文本生成模型),最大的缺点是“慢”——生成一张1024×1024的图片,要等120秒(2分钟),生成视频更慢,根本没法实用。
Emu3靠“DiDA技术”,直接解决了这个痛点——相当于给AI加了“并行加速器”,把“顺序猜Token”,改成“并行猜Token”,就像我们原来一个人写文章,现在一群人分工写,速度瞬间翻倍。
效果有多明显?1024×1024的图片,生成时间从120秒,降到10秒;入门级显卡(比如NVIDIA L4),生成一张512×512的图片,只要2-3秒,和我们刷手机加载图片的速度差不多!
Emu3成长时间线
Emu3不是突然“封神”的,它的成长路线很清晰,每一步都在迭代升级,咱们用时间线,一眼看懂它的进化史:
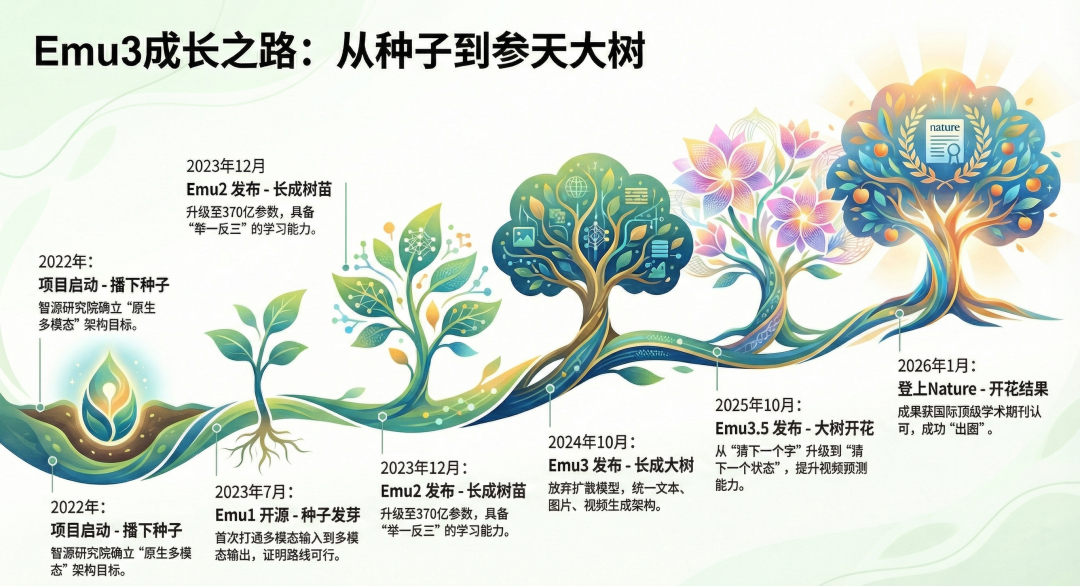
- 2022年:启动研发——智源研究院正式立项,定下“原生多模态”的目标(就是不搞组装,靠一个架构搞定所有),相当于“播下种子”;
- 2023年7月:Emu1开源——第一个版本上线,打通了“多模态输入→多模态输出”(比如输入文字,能生成图片+文本),相当于“种子发芽”,证明了路线可行;
- 2023年12月:Emu2发布——升级成“370亿参数的大块头”,能“举一反三”(给几个例子,就能学会新任务),还结合了扩散模型,图片生成更逼真,相当于“长成小树苗”;
- 2024年10月:Emu3革命性发布——放弃扩散模型,只用“预测下一个Token”,实现文本、图片、视频统一生成,架构极简,一战成名,相当于“长成大树”;
- 2025年10月:Emu3.5发布——参数量涨到34B,视频数据涨到790年,加入DiDA加速技术,从“猜下一个字”,升级到“猜下一个状态”(比如预测视频里“球掉地上会弹起来”),相当于“大树开花”;
- 2026年1月:登Nature正刊——中国科研机构主导的大模型,第一次登上Nature,得到国际学术界认可,相当于“开花结果,封神出圈”!
封神的Nature论文解读
Emu3 能登上 Nature,论文标题是:《通过预测下一个词元进行多模态学习的多模态大模型》),论文的核心要点如下:
1. 核心结论:“猜下一个Token”,能搞定所有多模态任务
这是论文最颠覆的观点——以前大家都觉得,多模态必须“分模块、多目标”训练(比如文本练“猜字”,图片练“生成”),而这篇论文证明:只用“预测下一个 Token ”这一个目标,就能让模型同时具备顶级的理解和生成能力。
就像我们人类,小时候只学“说话、认字”,长大后就能自然地读书、写字、画画、理解别人的表情:Emu3 就是模仿这种“通用学习能力”,打破了多模态模型的“模块化魔咒”。
2. 三个核心贡献
- 提出“统一多模态 Token 预测框架”:把文本、图片、视频都变成Token,用一个架构、一个目标训练,彻底抛弃复杂组装;
- 设计“高效视觉分词器”:解决了“图片/视频压缩+时序保留”的难题,让模型能高效处理视觉信息;
- 大量实验证明:通过“预测下一个 Token ”训练的模型,性能不输给专门设计的模型,而且更简洁、更高效。
3. 意义:中国AI,从“跟跑”到“领跑”
这篇论文最重磅的意义,不是技术多厉害,而是中国科研机构主导的大模型,第一次登上 Nature 正刊。

以前,多模态大模型的核心技术和学术话语权,都被 OpenAI、Google 等国外企业/机构垄断,我们大多是“跟着别人的路线走”;而Emu3的论文,证明了“预测下一个Token”这条中国路线的可行性,甚至比国外的路线更优。
Nature杂志也评价:Emu3的成果,对构建“简洁、可扩展的多模态智能系统”,有里程碑意义,相当于国际顶流学术界,正式认可了中国AI的原始创新能力。
Emu3的封神,只是开始
看完这些,相信大家都懂了:Emu3 能登 Nature,不是偶然,而是“极简创新+海量积累+开源精神”的结果。
它不只是一个“能生成图片、视频的AI”,更代表着中国AI的发展方向——不盲目追求“大参数、高成本”,而是靠“架构创新”,实现“更高效、更实用、更开放”的AI。
从 2022 年启动研发,到 2026 年登 Nature,Emu3 用 4 年时间,完成了从“新手”到“国际顶尖”的跃迁。而这,只是中国AI走向世界舞台中央的一个开始。
未来,当 Emu3 继续优化长视频能力、进一步降低部署成本,或许我们每个人,都能用上“中国造”的全能AI,轻松实现“文字→图片→视频”的一键生成。
一起期待,中国AI的下一个封神时刻!
如果喜欢本文,欢迎关注, 👍 点赞 | ⭐ 收藏 | ↗️ 转发。
近期人工智能文章:
1340亿美金的理想主义大清算:马斯克与OpenAI,谁在定义人类的未来?
GitHub 6万多星!这个能“动手”的开源项目,让普通人拥有“数字分身”
别再只会写提示词了!MCP+Skills这两大杀器,正在终结“AI智障”时代!
打破十年瓶颈!DeepSeek 重构神经网络底层逻辑,V4/R2 渐行渐近
本公众号聚焦人工智能,云原生和区块链等技术原理,请立即关注亨利笔记 ( henglibiji ),以免错过更新。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-02-03,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号