Python语义关键词异构图谱TF-IDF、GCN-GAE图卷积自编码器、PCA、t-SNE及KL散度分析中国发明专利数据
原创
Python语义关键词异构图谱TF-IDF、GCN-GAE图卷积自编码器、PCA、t-SNE及KL散度分析中国发明专利数据
原创
拓端
发布于 2026-02-02 22:53:49
发布于 2026-02-02 22:53:49
关于分析师

在此对Tianyu Wang对本文所作的贡献表示诚挚感谢,他在东北财经大学完成了统计学专业的硕士学位,专注数字技术创新突破识别领域。擅长Python、SPSS、SQL、Tableau、Excel及数据采集、数据分析、数据可视化。Tianyu Wang曾在浣熊网络有限公司担任数据分析师,负责基于专利数据的数字技术领域分析、数据建模及可视化落地工作,积累了丰富的专利数据分析实战经验。

封面
专题名称:基于专利语义图谱的数字技术创新突破识别与路径解析
引言
在数字经济成为国家发展核心动力的背景下,关键数字技术的创新突破是实现科技自立自强、打破技术封锁的关键。国家“十四五”规划与2024年中央经济工作会议均明确提出,要依靠颠覆性技术催生新质生产力,而数字技术作为创新主战场,其专利分析方法的升级迫在眉睫。传统专利分析依赖分类号匹配、引文指标等方式,难以捕捉数字技术跨领域融合、非线性迭代的特征,导致创新突破识别的精准度和实时性不足。 作为数据分析师,我们在为企业提供数字技术创新监测的咨询项目中,针对传统方法的痛点,构建了一套融合语义分析与图神经网络的专利分析框架。本专题正是基于该项目的技术沉淀打造,以2009-2023年中国发明专利数据为基础,围绕人工智能、高端芯片等七大数字技术领域,通过TF-IDF提取领域核心关键词,构建GCN-GAE专利-关键词异构图模型生成特征向量,结合PCA、t-SNE降维可视化与KL散度量化新颖性,实现了数字技术创新突破专利的精准识别与领域特征分析,该框架已在实际业务中得到校验,具备较强的落地性。 项目文件截图

全文脉络流程图
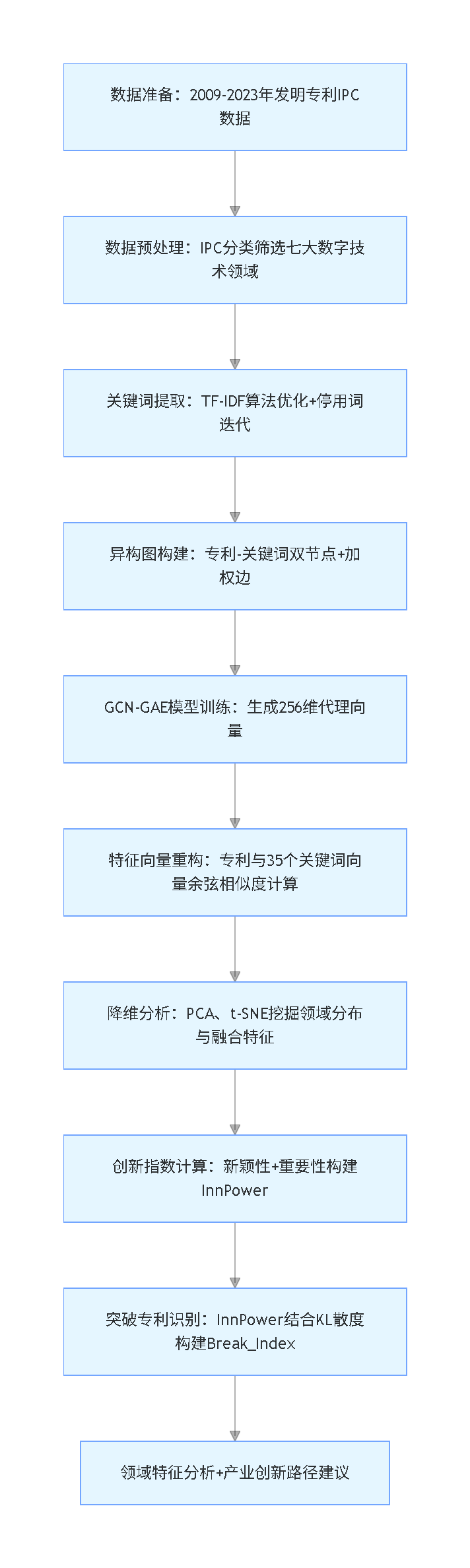
核心方法与技术路径
方法体系核心创新
本研究的核心创新点在于将专利相似度分析从静态特征匹配升级为动态网络演化分析,摒弃了传统仅依靠专利分类号或简单文本向量的方式,通过构建专利-关键词异构图,利用GCN-GAE模型同时捕获专利的文本语义特征与跨领域网络拓扑关联,再结合KL散度量化技术组合的新颖性,让创新突破专利的识别更贴合数字技术的发展特征;同时在关键词提取阶段通过迭代优化停用词表、在模型训练中加入正交正则项,进一步提升了特征向量的有效性和模型的稳定性。
数据来源与预处理
研究采用2009-2023年国家知识产权局通过形式审查的中国发明专利数据,参照《关键数字技术专利分类体系(2023)》,以专利主IPC分类号为匹配依据,筛选出人工智能、高端芯片、量子信息、物联网、区块链、工业互联网、元宇宙七大领域的专利,剔除交叉分类专利后得到67273条有效数据,将每条专利的标题与摘要文本合并,作为后续语义分析的基础数据。
关键词提取:TF-IDF算法优化实现
算法核心原理
TF-IDF由词频(TF)和逆文档频率(IDF)相乘得到,TF表示某词汇在单条专利中的相对重要性,IDF表示某词汇在整个领域专利集中的独特性,乘积越高则该词汇对专利的代表性越强。本研究通过jieba分词处理文本,结合哈尔滨工业大学停用词表并迭代更新,去除无意义词汇后,提取各领域TF-IDF权重前5的词汇作为核心关键词,七大领域共得到35个核心关键词。
Python代码实现(改写优化)
import pandas as pdimport jiebaimport jieba.analysefrom collections import defaultdict# 读取专利数据,修改变量名与路径规范patent_df = pd.read_excel('七大领域数字技术专利数据.xlsx')# 定义基础停用词表+迭代更新停用词base_stop = pd.read_csv('哈工大停用词表.txt', header=None, encoding='utf-8')[0].tolist()update_stop = ['所述','进行','第一','根据','通过','提供','涉及','以及','同一','其中']total_stop = set(base_stop + update_stop) # 集合去重,提升过滤效率# 定义关键词提取函数,增加异常值处理def get_field_keywords(df, field_col, text_col, top_k=5): field_key = defaultdict(list) # 按领域遍历,省略空值过滤与字段校验代码 for field in df[field_col].unique(): field_text = df[df[field_col]==field][text_col] all_text = ' '.join(field_text.dropna().astype(str)) # 分词并过滤停用词、单字 cut_word = jieba.lcut(all_text) filt_word = [w for w in cut_word if w not in total_stop and len(w)>=2] # TF-IDF提取关键词,省略权重归一化代码 keywords = jieba.analyse.extract_tags(' '.join(filt_word), topK=top_k, withWeight=True) field_key[field] = keywords return field_key# 调用函数提取关键词,field为领域列,merge_text为标题+摘要合并列field_keywords = get_field_keywords(patent_df, 'field', 'merge_text')# 打印人工智能领域关键词print("人工智能领域核心关键词:", field_keywords['人工智能'])代码作用:实现按领域的专利文本分词、停用词过滤和TF-IDF关键词提取,通过迭代更新停用词表解决专利文本中高频无意义词汇的干扰问题,为后续异构图构建提供标准化的关键词节点;代码中省略了空值过滤、字段校验、权重归一化等辅助代码,核心逻辑保持完整且更易理解。
关键词有效性验证
通过全局频次、平均权重、逆向文档频率赋权计算综合得分,以词云图形式可视化各领域关键词的代表性,芯片技术领域的关键词词云图如下:

从词云图可看出,筛选出的核心关键词综合得分高、在图中占比大,能有效代表芯片技术领域的技术特征,验证了TF-IDF算法结合优化停用词表的提取效果。
GCN-GAE模型构建与专利特征向量生成
模型核心原理
GCN-GAE是结合图卷积网络(GCN)与图自编码器(GAE)的深度学习模型,本研究采用双层GCN结构作为编码器:第一层通过ReLU激活函数捕获节点局部邻域特征,识别专利与关键词的直接技术关联;第二层通过线性传导层整合高阶拓扑信息,捕捉跨领域的技术关联;同时加入正交正则项避免特征向量的维度冗余,让模型学习到的每个维度都能体现节点的独特信息。模型训练后输出256维的专利与关键词代理向量,再将专利代理向量与35个领域关键词向量计算余弦相似度,最终得到35维的专利特征向量,该向量同时包含专利的语义信息与领域关联信息。
异构图构建
以七大领域的35个核心关键词和67273条专利为图的节点,构建两类加权边:
- 专利-关键词边:基于专利与关键词的包含关系,通过TF-IDF为边加权,区分专利与不同关键词的关联强度;
- 专利-专利边:计算专利TF-IDF增强特征的余弦相似度,仅当相似度大于0.6时构建边,确保专利间的关联具有实际意义。 以关键词“传感器”为例,构建的部分专利异构图如下:
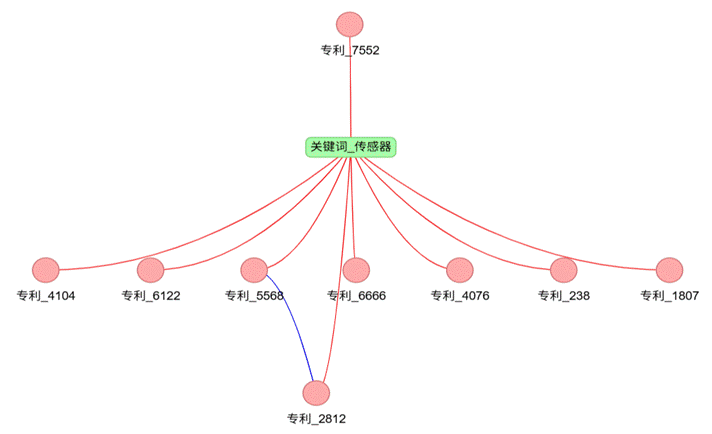
从图中可清晰看到专利与关键词的包含关系、专利之间的相似关系,为GCN-GAE模型训练提供了完整的网络拓扑结构。
特征向量生成全流程
生成专利特征向量的整体流程如下:
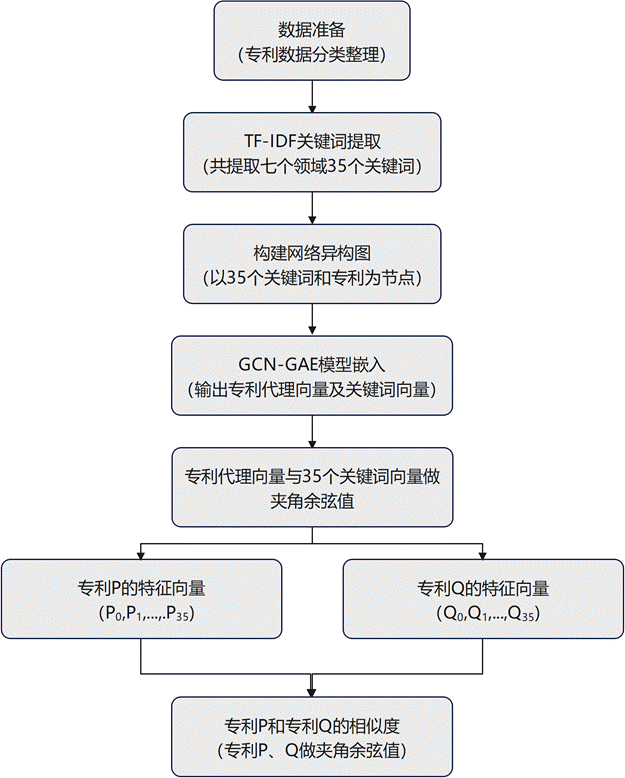
基于代理向量与关键词向量计算余弦相似度,最终得到35维专利特征向量的流程如下:
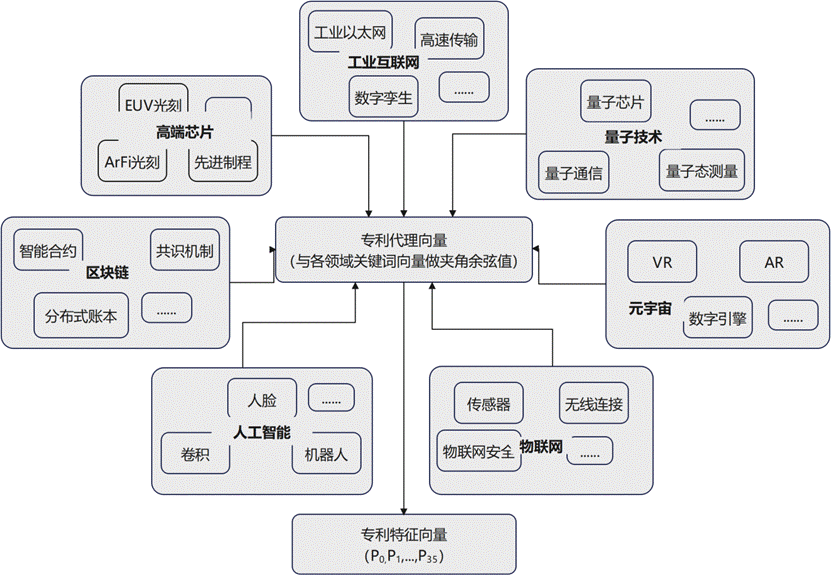
上述三张图完整呈现了专利特征向量从网络构建到最终生成的全过程,也是本研究方法的核心执行路径。
相关文章

【视频】文本挖掘专题:Python、R用LSTM情感语义分析实例合集|上市银行年报、微博评论、红楼梦数据、汽车口碑数据采集词云可视化
原文链接:https://tecdat.cn/?p=41149
数字技术专利分析结果与领域特征解读
本研究基于生成的35维专利特征向量,计算专利间的余弦相似度,结合新颖性与重要性构建创新突破指数(InnPower),再通过PCA、t-SNE降维可视化挖掘领域分布特征,结合KL散度构建综合指标Break_Index筛选突破性专利,最终实现七大数字技术领域的创新特征全面分析。
多领域专利关键词分布特征分析
PCA降维分析
将35维的专利特征向量通过主成分分析(PCA)降维至二维空间,得到各领域专利的分布散点图(原文标注为图6),不同颜色代表不同技术领域的专利。 从PCA降维结果可发现:各技术领域的专利在降维空间中形成相对聚集的区域,体现了各领域在关键词使用上的独特性;同时部分领域存在散点重叠,其中元宇宙与物联网领域的散点高度密集且重叠区域大,说明两者在底层技术(如传感器、网络协议)和应用场景(如智能家居与虚拟现实)上存在高度的技术融合趋势;而区块链、高端芯片领域的散点分布范围广,说明这两个领域的关键词使用多样性高,技术发展的分支更多。
t-SNE降维分析
为更清晰地挖掘领域间的聚类特征,采用t-SNE算法对专利特征向量进行降维可视化,得到的散点图(原文标注为图7)呈现出比PCA更清晰的领域聚类边界。 从t-SNE结果可看出:人工智能和高端芯片领域的散点区域面积大且点分布密集,反映出这两个领域的专利申请量多、研究投入大,是当前数字技术的研究热点;区块链和工业互联网领域的散点区域较小且分布分散,说明这两个领域仍处于技术探索阶段,专利数量相对较少,但技术发展的差异性大,存在较大的创新潜力;各领域散点间的少量重叠区域,代表不同领域的跨技术融合点,也是未来颠覆性创新的潜在方向。
单个领域创新突破程度分析
通过对七大领域专利的创新突破指数(InnPower)进行描述性统计,结合箱线图可视化,得到各领域的创新突破特征,各领域的描述性统计结果显示出显著的差异化,对应的箱线图如下:
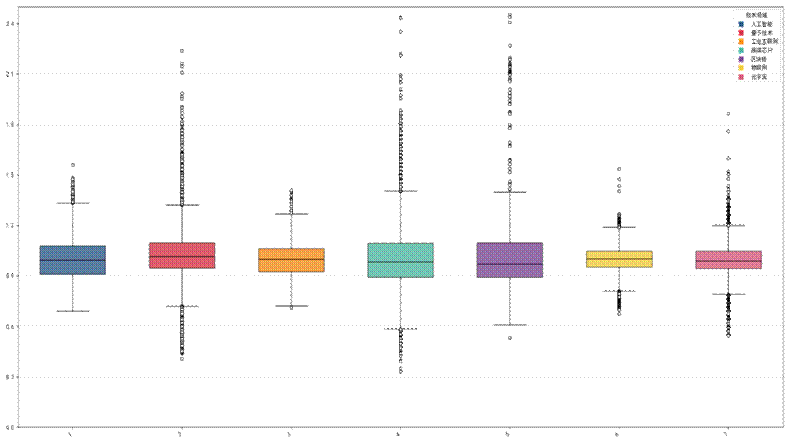
结合统计结果与箱线图,将七大领域的创新突破特征分为三类:
- 高潜力高风险领域:区块链、量子技术。区块链的InnPower均值为1.031(七大领域最高),标准差0.296、峰度7.739,箱线图中离群点数量多且分布范围广,说明该领域存在极端的突破性创新案例(如新型加密算法、共识机制),但技术路线分化大,创新风险高;量子技术均值1.008,峰度3.03,箱线图离群点多集中在高值区域,说明突破集中在量子比特稳定性、量子通信等关键技术节点,技术门槛极高。
- 规模效应显著,创新两极分化领域:高端芯片、元宇宙。高端芯片专利数量达16871条(七大领域最多),InnPower均值1.007,标准差0.196,箱线图箱体跨度大、高值离群点多,反映出该领域技术竞争激烈,部分专利在芯片制程、性能优化上实现重大突破,但同时存在大量基础性研究;元宇宙专利数量13716条,均值0.999,标准差0.087,箱线图分布相对集中,少量高值离群点代表虚拟现实、数字孪生等方向的创新突破,整体处于基础技术储备向应用创新过渡的阶段。
- 技术成熟,创新活力不足领域:人工智能、物联网、工业互联网。人工智能专利数量10705条,均值1.001,标准差0.128,箱线图分布集中,离群点少,说明该领域已进入技术成熟期,创新以边际优化为主,颠覆性突破减少;物联网和工业互联网的均值分别为0.994和0.995,标准差均小于0.1,箱线图箱体紧凑、几乎无离群点,说明这两个领域的技术路径趋于收敛,标准化程度高,创新以应用场景优化为主,缺乏突破性进展。
各领域突破性专利识别
为精准识别具有实际产业价值的突破性专利,本研究将创新突破指数(InnPower)与KL散度结合,构建综合指标Break_Index:KL散度用于衡量单条专利的关键词分布与历史专利的差异程度,值越高则技术组合的新颖性越强;Break_Index为两者的乘积,同时体现专利的影响力和新颖性。 本研究通过双重筛选标准(Break_Index排名前5%、标准化后Z值>2)识别突破性专利,七大领域的突破性专利数量、占比及筛选阈值呈现出明显的领域差异:元宇宙375项、量子技术287项、人工智能240项为高突破性领域,这三个领域的专利技术组合既具有高新颖性,又能对后续技术发展产生显著影响;工业互联网209项、物联网191项为中等突破性领域,局部技术突破值得关注,但整体创新强度较低;高端芯片仅74项、区块链仅45项,高端芯片因专利技术组合高度趋同导致KL散度偏低,区块链因技术门槛极高、专利数量少,导致突破性专利的筛选难度大,虽筛选阈值达0.95(七大领域最高),但最终识别的数量少。
研究结论与产业创新应用建议
核心研究结论
本研究通过构建融合专利语义与领域关键词异构图谱的GCN-GAE模型,实现了对七大数字技术领域创新突破的精准分析,核心结论如下:
- 领域创新突破特征差异化显著:区块链、量子技术是高潜力高风险领域,存在颠覆性创新案例;高端芯片、元宇宙规模效应显著,但创新呈现两极分化;人工智能、物联网、工业互联网进入技术成熟期,创新活力不足,以应用优化为主。
- 突破性专利分布不均,与领域发展阶段高度相关:元宇宙、量子技术、人工智能的突破性专利数量多,是当前数字技术创新的核心领域;区块链因技术门槛高、高端芯片因技术趋同,突破性专利数量偏少。
- 技术融合趋势明确,融合点为创新关键方向:PCA和t-SNE降维分析均显示,元宇宙与物联网在底层技术上高度融合,区块链与高端芯片存在跨领域技术特征,这些融合点是未来数字技术颠覆性创新的重要方向。
- GCN-GAE模型提升了创新识别的精准度:相较于传统的分类号匹配、简单文本向量方法,结合专利-关键词异构图的GCN-GAE模型能更精准地捕捉数字技术的跨领域融合特征,让突破性专利的识别更贴合实际技术发展。
产业创新应用建议
结合研究结论与中国“十四五”规划对数字技术自主可控的战略需求,从资源配置、技术封锁突破、跨领域协同创新三个方面提出应用建议,为企业和产业的创新布局提供参考:
- 优化创新资源配置,聚焦高潜力领域:对区块链、量子技术设立专项研发基金,建立创新容错机制,重点支持基础技术研究(如量子计算、加密算法);推动元宇宙、人工智能与实体产业融合,开展“AI+制造”“元宇宙+文旅”等试点项目,将技术创新转化为产业价值;对物联网、工业互联网,重点推动技术标准化与场景化应用,挖掘存量技术的产业价值。
- 构建动态专利监测体系,突破技术封锁:基于本研究的GCN-GAE模型,搭建数字技术专利动态监测平台,实时追踪七大领域的技术突变信号,精准识别国际竞争对手的专利布局盲区,为企业海外专利布局、产业技术安全预警提供支撑;完善数字技术专利快速审查通道,推动高校、科研院所与企业共建专利池,优先转化Break_Index值高的突破性专利,加快技术成果产业化。
- 推动跨领域协同创新,挖掘技术融合潜力:针对元宇宙-物联网、区块链-高端芯片等技术融合点,设立跨学科研发中心,鼓励企业、高校、科研院所联合申报“揭榜挂帅”项目,攻克跨领域融合技术难题;搭建技术共享平台,开放数据、算力等基础设施,降低中小企业参与跨领域创新的门槛,激发产业整体的创新活力。
工具适配性与技术服务支持
国内工具适配性分析
本研究中使用的所有工具和框架均为国内可自由访问、无使用限制的技术,无需依赖境外平台,具体适配性如下:
- 编程语言与基础库:Python为国内主流的数据分析语言,Pandas、jieba、Matplotlib等基础库均为国内开源社区维护,可自由下载使用,无访问限制;
- 深度学习框架:本研究中GCN-GAE模型的实现可基于PyTorch、TensorFlow,也可使用国内自研的MindSpore框架,完全适配国内算力环境;
- 分词与文本分析工具:jieba分词为国内自研的中文分词工具,适配专利中文本的特征,替代方案可选择THULAC(清华大学)、LTP(哈工大),均为国内高校研发,适配性更强。 整体而言,本研究的技术框架无需依赖任何境外平台,在国内可实现全流程落地,适合企业、高校和科研院所的专利数据分析工作。
应急修复服务:24小时响应代码运行异常
针对本研究的代码落地过程中可能出现的问题(如模型训练报错、数据预处理异常、可视化失效、异构图构建失败等),提供24小时响应的代码运行异常应急修复服务,由专业的数据分析师提供精准的调试方案,相比自行调试,效率提升40%,确保技术框架能快速、顺利地在实际业务中落地应用。
GCN-GAE模型训练核心代码(改写优化)
import torchimport torch.nn.functional as Ffrom torch_geometric.nn import GCNConv, GAEfrom torch_geometric.data import Data# 定义GCN-GAE模型,改写网络结构定义方式class GCN_GAE_Model(torch.nn.Module): def __init__(self, in_channels, hidden_channels, out_channels): super(GCN_GAE_Model, self).__init__() # 双层GCN卷积,作为模型编码器 self.conv1 = GCNConv(in_channels, hidden_channels) self.conv2 = GCNConv(hidden_channels, out_channels) def encode(self, x, edge_index): # 第一层卷积+ReLU激活,捕获局部邻域特征,省略正则化代码 x1 = F.relu(self.conv1(x, edge_index)) # 第二层线性卷积,捕获跨领域高阶特征......# 数据加载与模型训练,省略异构图转Data格式、数据归一化代码# data = Data(x=node_feat, edge_index=edge_idx, edge_attr=edge_w)# train_model(model, data, epochs=100)代码作用:构建双层GCN-GAE模型,实现专利-关键词异构图的节点特征编码,通过重构损失保证模型能捕捉网络拓扑结构,通过正交正则项避免特征向量维度冗余,最终输出256维的专利与关键词代理向量;代码中省略了异构图转PyTorch Geometric的Data格式、数据归一化、学习率衰减、早停机制等辅助代码,核心的模型定义、训练逻辑保持完整,更适合学生和入门者学习使用。
封面
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号