零拷贝技术详解:从传统IO到极致优化

零拷贝技术详解:从传统IO到极致优化

一个平凡而乐于分享的小比特
发布于 2026-02-02 16:57:03
发布于 2026-02-02 16:57:03
🔥作者简介: 一个平凡而乐于分享的小比特,中南民族大学通信工程专业研究生,研究方向无线联邦学习 🎬擅长领域:驱动开发,嵌入式软件开发,BSP开发 ❄️作者主页:一个平凡而乐于分享的小比特的个人主页 ✨收录专栏:操作系统,本专栏为讲解各操作系统的历史脉络,以及各性能对比,以及内部工作机制,方便开发选择 欢迎大家点赞 👍 收藏 ⭐ 加关注哦!💖💖

在这里插入图片描述
零拷贝技术详解:从传统I/O到极致优化
一、传统I/O的问题:效率低下的根源
1.1 传统I/O的数据流向
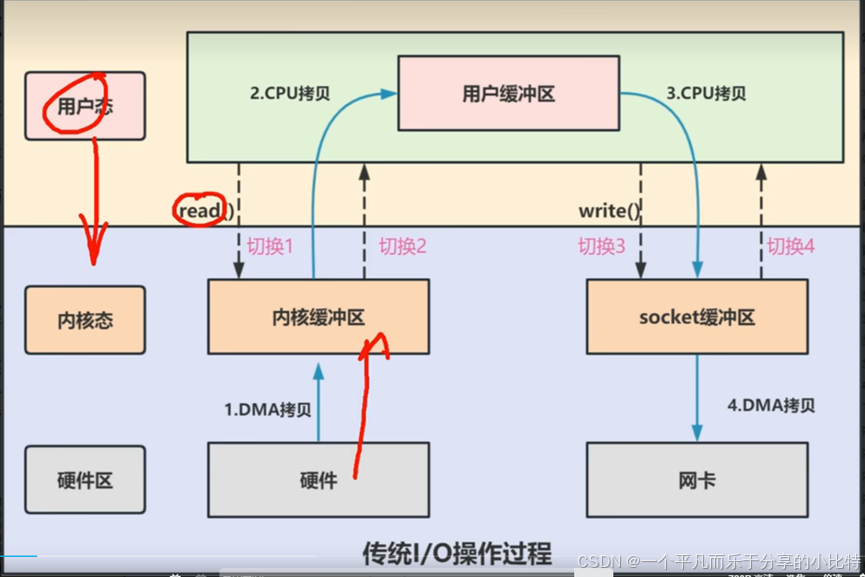
在这里插入图片描述
让我们先看看传统方式传输一个文件的完整过程:
应用程序 → read() → 内核缓冲区 → 用户缓冲区 → write() → socket缓冲区 → 网卡- 用户应用进程调用read函数,向操作系统发起I/O调用,上下文从用户态转为内核态(切换1)
- DMA控制器把数据从磁盘中,读取到内核缓冲区。
- CPU把内核缓冲区数据,拷贝到用户应用缓冲区,上下文从内核态转换为用户态(切换2),read函数返回
- 用户应用进程通过write函数,发起I/O调用,上下文从用户态转换为内核态(切换3)
- CPU将应用缓冲区的数据,拷贝到socket缓冲区
- DMA控制器把数据从socket缓冲区,拷贝到网卡设备,上下文从内核态切换回用户态(切换4)
总结:4次上下文切换(4次用户态和内核态切换),4次数据拷贝(两次CPU拷贝以及两次DMA拷贝)
关键问题分析:
问题点 | 具体表现 | 性能影响 |
|---|---|---|
冗余拷贝 | 数据在内核缓冲区→用户缓冲区→socket缓冲区之间来回复制 | CPU时间浪费,内存带宽占用 |
上下文切换 | 每次系统调用都需要用户态↔内核态切换 | 切换开销大,缓存失效 |
数据驻留 | 数据需要在用户空间“中转”一次 | 增加延迟,占用用户空间内存 |
1.2 为什么会有这些问题?
历史原因:早期操作系统设计时,出于安全考虑,内核空间和用户空间严格隔离。应用程序不能直接访问内核缓冲区,必须通过“用户缓冲区”这个中介。
类比理解:
想象你要把一本书从图书馆(磁盘)寄给朋友(网络):
- 传统方式:图书管理员(内核)把书从书库拿出(DMA拷贝到内核缓冲区)→ 交给你(CPU拷贝到用户缓冲区)→ 你检查书(应用处理)→ 你交给快递员(CPU拷贝到socket缓冲区)→ 快递员打包发货(DMA拷贝到网卡)
问题:书在你手里中转了一次,既浪费你的时间,又增加损坏风险。
二、mmap + write:减少一次拷贝的优化
2.1 技术原理
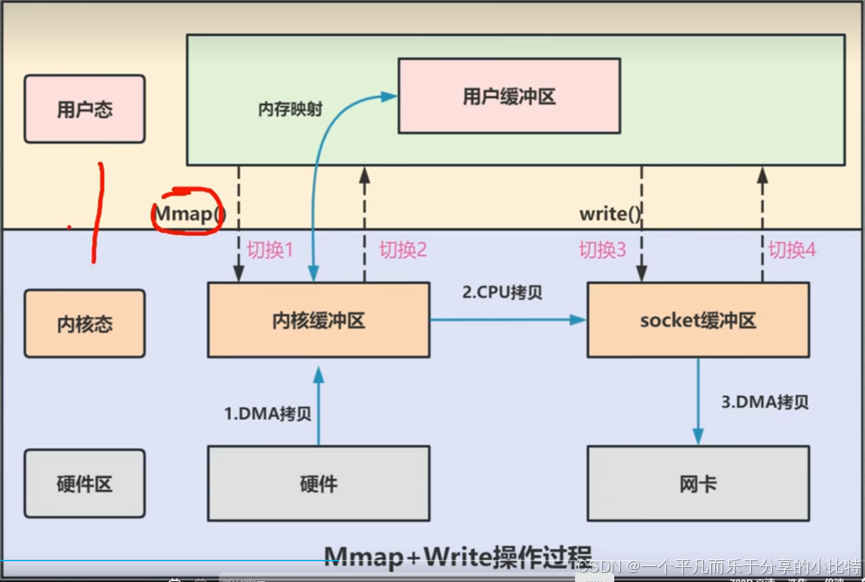
在这里插入图片描述
mmap(内存映射)的核心思想:
- 不拷贝数据,而是建立映射关系
- 用户空间和内核空间共享同一块物理内存
- 应用程序通过指针直接访问内核缓冲区
内存映射的魔法:
用户虚拟地址空间 → 映射关系 → 内核缓冲区物理内存
↓ ↗
直接访问 共享- 用户进程通过mmap方法向操作系统内核发起I/O调用,上下文从用户态切换为内核态。
- CPU利用DMA控制器,把数据从硬盘中拷贝到内核缓冲区,上下文从内核态切换回用户态,mmap方法返回
- 用户进程通过write方法向操作系统内核发起I/O调用,上下文从用户态切换为内核态。
- CPU将内核缓冲区的数据拷贝到socket缓冲区
- CPU利用DMA控制器,把数据从socket缓冲区拷贝到网卡,上下文从内核态切换回用户态,write调用返回。
总结:4次用户空间与内核空间的上下文切换,以及3次数据拷贝(2次DMA拷贝和一次CPU拷贝)
2.2 性能提升分析
传统方式: 磁盘 → 内核缓冲区 → 用户缓冲区 → socket缓冲区 → 网卡
(DMA) (CPU) (CPU) (DMA)
mmap方式: 磁盘 → 内核缓冲区 → socket缓冲区 → 网卡
(DMA) (CPU) (DMA)
↗
用户空间直接访问减少了一次CPU拷贝:数据不再需要从内核缓冲区复制到用户缓冲区
2.3 适用场景与限制
适合场景:
- 大文件传输(视频、镜像文件)
- 需要多次访问相同数据的应用
- 进程间共享内存通信
仍然存在的问题:
- ❌ 仍有4次上下文切换(用户态↔内核态)
- ❌ 仍有1次CPU拷贝(内核缓冲区→socket缓冲区)
- ⚠️ 内存占用风险:文件较大时,mmap可能导致内存压力
三、sendfile:真正的“零拷贝”实现
3.1 技术突破
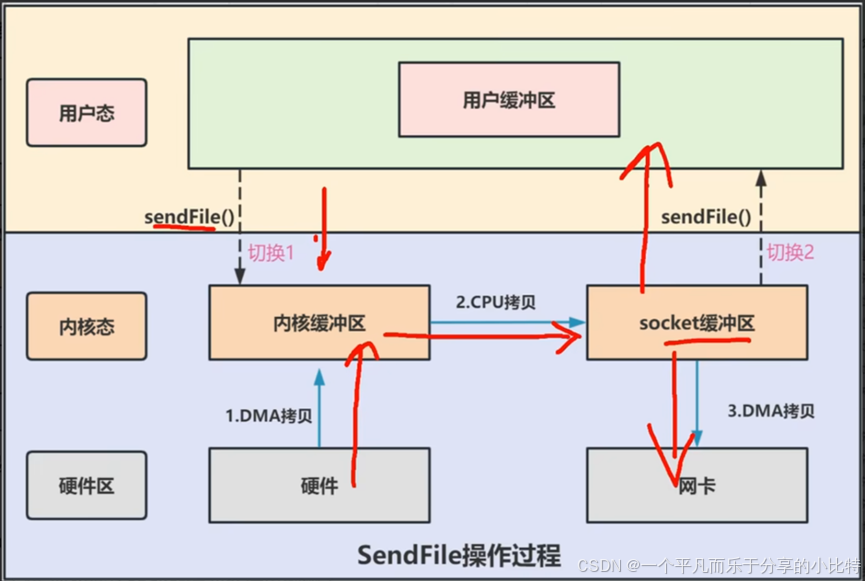
在这里插入图片描述
sendfile的革命性改进:
- 合并系统调用:read + write → 一个sendfile调用
- 完全绕过用户空间:数据流不经过应用程序缓冲区
- 内核内部直通:在内核空间内完成数据传输
3.2 sendfile数据流向详解
第一步: 磁盘 → DMA拷贝 → 内核缓冲区
↓
第二步:内核缓冲区 → CPU拷贝 → socket缓冲区
↓
第三步:socket缓冲区 → DMA拷贝 → 网卡- 用户进程发起sendfile系统调用,上下文(切换1)从用户态转向内核态
- DMA控制器,把数据从硬盘中拷贝到内核缓冲区。
- CPU将读缓冲区数据拷贝到socket缓冲区
- DMA控制器,异步把数据从socket缓冲区拷贝到网卡,上下文(切换2)从内核态转向用户态,sendfile系统调用返回
总结:2次用户空间与内核空间的上下文切换,以及3次数据拷贝(2次DMA拷贝和一次CPU拷贝)
关键优化点:
- 上下文切换减半:4次 → 2次
- 系统调用合并:2次调用 → 1次调用
- 用户空间零参与:应用程序完全不用接触数据
3.3 sendfile的进化:SG-DMA技术
Linux 2.4+版本的进一步优化:
磁盘 → DMA拷贝 → 内核缓冲区
↓
SG-DMA技术
↓
网卡 ← DMA拷贝 ← 直接读取SG-DMA(Scatter-Gather DMA)的魔力:
- 零CPU拷贝:完全消除内核缓冲区到socket缓冲区的拷贝
- 内核缓冲区直接到网卡:DMA控制器直接从内核缓冲区读取数据
- 最终形态:只有2次DMA拷贝,0次CPU拷贝
四、三种方式对比分析
4.1 技术指标对比表
对比维度 | 传统I/O | mmap + write | sendfile | sendfile + SG-DMA |
|---|---|---|---|---|
CPU拷贝次数 | 2次 | 1次 | 1次 | 0次 |
DMA拷贝次数 | 2次 | 2次 | 2次 | 2次 |
总拷贝次数 | 4次 | 3次 | 3次 | 2次 |
上下文切换 | 4次 | 4次 | 2次 | 2次 |
系统调用 | 2次 | 2次 | 1次 | 1次 |
用户空间参与 | 完全参与 | 直接访问但不拷贝 | 完全不参与 | 完全不参与 |
4.2 性能影响量化分析
假设传输一个1GB文件,不同技术的开销对比:
传统I/O:
- 内存拷贝:1GB × 2次 = 2GB数据移动
- CPU时间:主要消耗在拷贝上
- 总耗时:T(磁盘读取) + T(拷贝) + T(网络发送)
sendfile + SG-DMA:
- 内存拷贝:仅DMA传输,CPU几乎不参与
- CPU时间:主要用于调度和协议处理
- 总耗时:接近 max(T磁盘读取, T网络发送)实际测试数据参考:
- 小文件(10KB):sendfile比传统方式快20-30%
- 大文件(1GB):sendfile比传统方式快2-3倍
五、实际应用场景分析
5.1 哪些软件使用了零拷贝?
软件/系统 | 使用的零拷贝技术 | 应用场景 |
|---|---|---|
Nginx | sendfile | 静态文件服务 |
Kafka | sendfile + mmap | 消息持久化和消费 |
Apache | sendfile(需配置) | 文件传输 |
VSFTPD | sendfile | 文件下载 |
MySQL | 零拷贝网络I/O | 查询结果传输 |
5.2 具体场景:Web服务器发送图片
场景:用户请求一个1MB的图片文件
传统方式流程:
1. Nginx进程调用read()【切换内核态】
2. 硬盘→内核缓冲区(DMA 1MB)
3. 内核缓冲区→Nginx进程内存(CPU拷贝 1MB)【切换用户态】
4. Nginx调用write()【切换内核态】
5. Nginx内存→socket缓冲区(CPU拷贝 1MB)
6. socket缓冲区→网卡(DMA 1MB)【切换用户态】
**总计:4次切换,4次拷贝,处理1MB数据**sendfile方式流程:
1. Nginx调用sendfile()【切换内核态】
2. 硬盘→内核缓冲区(DMA 1MB)
3. 内核缓冲区→socket缓冲区(CPU拷贝 1MB)
4. socket缓冲区→网卡(DMA 1MB)【切换用户态】
**总计:2次切换,3次拷贝,处理1MB数据**效率提升:
- CPU使用率降低40-50%
- 内存带宽占用减少50%
- QPS(每秒查询数)提升30%以上
5.3 什么时候不适合用零拷贝?
不适合的场景:
- 需要修改数据:零拷贝是只读的,如果要压缩、加密数据,必须先拷贝
- 小文件随机访问:mmap的映射开销可能比收益大
- 兼容性要求:某些老系统或特殊硬件可能不支持
- 实时性要求极高:有时直接操作缓冲区更可控
六、零拷贝的设计思想精髓
6.1 核心设计原则
原则1:数据不动,指针动
// 传统:复制数据
memcpy(dest, src, size);
// 零拷贝思想:传递引用/指针
sendfile(out_fd, in_fd, NULL, size);原则2:减少中间商
- 用户空间是数据的"中间商"
- 内核内部传输也是"中间商"
- 目标是:生产者 → 消费者直接传输
原则3:批量处理
- 合并多次操作为一次
- 减少边界跨越次数
6.2 硬件协作优化
DMA技术的关键作用:
没有DMA: CPU负责所有数据传输
↓
有DMA: CPU:"DMA,你去搬数据"
DMA:"收到,搬完了通知你"
CPU可以并行处理其他任务SG-DMA的进一步优化:
普通DMA: 只能连续内存传输
↓
SG-DMA: 可以"收集"分散的内存块
直接从内核缓冲区→网卡,绕过socket缓冲区七、现代零拷贝技术的发展
7.1 内核旁路技术(Kernel Bypass)
更激进的优化:完全绕过操作系统内核
技术代表:
- DPDK(Data Plane Development Kit)
- RDMA(Remote Direct Memory Access)
- AF_XDP(Linux内核新特性)
性能对比:
传统socket: 应用 → 内核协议栈 → 网卡
(多次拷贝,多次切换)
DPDK/RDMA: 应用直接 ↔ 网卡
(零拷贝,零切换)7.2 零拷贝的代价与权衡
没有银弹:零拷贝也有代价
优化维度 | 获得的收益 | 付出的代价 |
|---|---|---|
减少拷贝 | CPU时间↓,吞吐量↑ | 实现复杂,兼容性↓ |
减少切换 | 延迟↓,吞吐量↑ | 调试困难,灵活性↓ |
内核旁路 | 极致性能 | 安全性↓,生态支持↓ |
八、总结:零拷贝的本质
8.1 技术演进路线图
第一阶段:传统I/O(4拷贝4切换)
↓ 优化方向:减少拷贝
第二阶段:mmap(3拷贝4切换)
↓ 优化方向:减少切换
第三阶段:sendfile(3拷贝2切换)
↓ 优化方向:消除CPU拷贝
第四阶段:sendfile+SG-DMA(2拷贝2切换)
↓ 优化方向:完全内核旁路
第五阶段:DPDK/RDMA(0拷贝0切换)8.2 给开发者的建议
何时使用零拷贝:
- ✅ 静态文件服务:Web服务器发送图片、视频
- ✅ 消息中间件:Kafka等需要高吞吐的场景
- ✅ 数据库系统:大量数据扫描和传输
- ✅ 科学计算:大规模数据处理
如何选择具体技术:
- 如果需要兼容性:sendfile
- 如果需要处理数据:mmap
- 如果需要极致性能:考虑DPDK/RDMA
- 如果文件很小:传统I/O可能更简单
8.3 未来展望
零拷贝技术仍在发展:
- 异构计算:GPU、NPU参与的数据传输
- 持久内存:PMEM带来的新机会
- 量子网络:未来的零拷贝可能更颠覆
最终目标:让数据以最直接的路径,从生产者流向消费者,就像光线一样,走最短的路径,没有反射和折射。
通过这三个图的对比,我们可以清晰地看到零拷贝技术的演进思路:不断减少不必要的中间环节,让数据流动更直接、更高效。从传统I/O到现代零拷贝,每一步优化都体现了计算机系统设计者对性能极限的不懈追求。
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2026-02-02,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号