MongoDB 核心原理(二):Oplog 深度解析 —— 复制集同步的生命线

MongoDB 核心原理(二):Oplog 深度解析 —— 复制集同步的生命线

运维小路
发布于 2026-01-26 12:53:42
发布于 2026-01-26 12:53:42
作者介绍:简历上没有一个精通的运维工程师,下面的思维导图也是预计更新的内容和当前进度(不定时更新)。
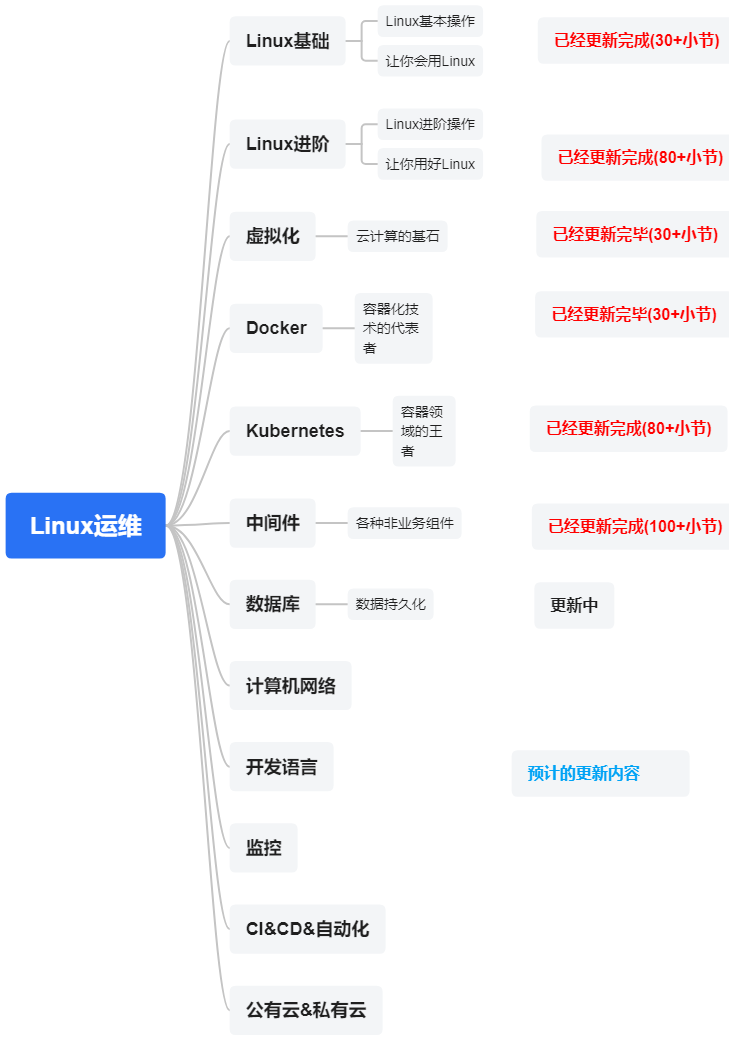
数据库是一个系统(应用)最重要的资产之一,所以我们的数据库将从以下几个数据库来进行介绍。
MySQL
PostgreSQL
MongoDB(本章节)
Redis
Etcd
我们在前面介绍MongoDB的复制集的时候,介绍过Oplog,今天来详细介绍他。
一、 主从同步原理:Oplog 如何驱动数据一致性
复制集的核心目标是让所有节点(一个主节点,多个从节点)的数据最终保持一致。Oplog 是实现这一目标的唯一权威数据变更流。
1. 角色与流程
- 主节点 (Primary):
- 接收客户端的所有写操作(增、删、改、DDL命令)。
- 在执行写操作、更新自身数据后,会立即将该操作转换成一个具有幂等性的Oplog条目,写入本地
local.oplog.rs集合。 - “先写Oplog,再响应客户端”:这是关键。只有成功写入Oplog后,主节点才认为写操作“已提交”,并向客户端返回成功。这确保了任何已确认的写操作都必定有记录可循,类似于强同步。
- 从节点 (Secondary):
- 每个从节点都维护一个指向主节点Oplog的“游标”,持续轮询或长连接(尾随) 主节点的Oplog。
- 获取到新的Oplog条目后,将其按
ts字段的顺序(保证全局有序)应用到自己的数据集中。这个应用过程就是“重放”。 - 同时,从节点也会将获取到的Oplog条目写入自己的
local.oplog.rs。这使得每个健康的从节点都拥有一份完整的、与主节点内容相同(可能有微小延迟)的Oplog副本。这一点对于故障转移至关重要。
2. 故障转移与选举
当主节点宕机时,复制集会触发选举,选出新的主节点。选举的关键依据之一就是 Oplog的新旧程度。
- 候选节点会相互比较各自Oplog中最新一条记录的
ts(时间戳)。 - 拥有最新、最完整Oplog的节点(即数据最接近原主节点的节点)更有可能当选为新主。这被称为“最新性优先”原则,最大程度避免了数据回滚和数据丢失。和ZooKeeper的事务id类似。
- 因此,Oplog不仅是同步的数据源,也是选举的数据凭证。
3. 初始同步
当一个全新的节点加入复制集,或一个从节点的数据落后太多(所需的Oplog已在主节点被覆盖)时,会进行全量同步。
- 新节点克隆主节点上除
local库外的所有数据(相当于mongodump)。 - 克隆期间,主节点的数据仍在变化。克隆完成后,新节点开始拉取从克隆开始时刻起的主节点Oplog。
- 将拉取的Oplog重放到本地,直到追上主节点的最新状态,然后转为正常的持续同步模式。Oplog在这里确保了全量同步后数据的最终一致性。
二、 读写数据视角:Oplog 如何影响读写行为
从应用程序读写数据的角度看,Oplog 是幕后英雄,它直接决定了数据的可靠性、一致性和读写分离的可能性。
1. 写操作 (Write Operations)
- 数据流向:客户端的写请求 -> 主节点 -> 写入数据文件 & 写入Oplog -> 响应客户端 -> Oplog异步流式推送 -> 从节点拉取并重放Oplog。
- Write Concern(写关注):这是客户端调和写入速度与数据耐久性的关键机制,与Oplog直接相关。
w: 1(默认):主节点写入Oplog成功后即返回。数据可能还未同步到任何从节点。如果此时主节点崩溃,可能导致数据丢失。w: “majority”:要求写操作已复制到大多数节点(包括主节点)的Oplog中后才返回。这能保证即使主节点故障,数据也已存在于新主节点的候选节点中,不会丢失。这是生产环境推荐的安全写法。j: true:要求写操作已写入磁盘日志(Journal)。与Oplog结合(w: “majority”, j: true)提供了最强的持久性保证。
2. 读操作 (Read Operations)
- 主节点读:总是读到最新已确认的数据。
- 从节点读(读写分离):通过设置
readPreference为secondary或secondaryPreferred,可以将读请求路由到从节点,减轻主节点压力。- 数据新鲜度问题:由于Oplog的同步是异步的,从节点上的数据总是滞后于主节点。这个滞后时间就是复制延迟。
- Oplog的作用:通过监控
rs.printSlaveReplicationInfo()可以获知延迟时间。应用程序需要评估是否能容忍此延迟(如报表查询可以,实时交易可能不行)。 - 一致性读:要确保读到最新数据,必须从主节点读(
readPreference: primary)。
3. 数据一致性级别
Oplog 的有序性和 ts 时间戳,为 MongoDB 提供了实现因果一致性的基础。
- 客户端会话可以设置
afterClusterTime,确保其读操作能至少读到之前某个写操作之后的数据状态,即使该读发生在从节点上。复制集会利用 Oplog 的ts来保证这一点。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-12-29,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号