LSTM基本介绍
原创

前言
循环神经网络(RNN)存在的弊端:虽然在序列建模方面具有天然的架构优势,但其在实际训练过程中会面临显著的长期依赖衰减问题。具体表现为:当输入序列长度增加时,模型在反向传播过程中难以将梯度信号有效地回传到序列的早期时间步。
这一问题的根源在于RNN的梯度计算涉及权重矩阵的连续乘法。当序列较长时,这一连乘会导致梯度呈现指数级衰减(梯度消失)或爆炸(梯度爆炸)。梯度消失使得早期时间步的参数更新几乎为零,导致模型无法学习长距离的依赖关系。
LSTM的引进
长短期记忆网络(LSTM)的提出,直接源于解决RNN在训练过程中出现的梯度消失或梯度爆炸这一核心难题。该模型由Hochreiter和Schmidhuber在1997年发表,其设计初衷就是为了让RNN能够有效地学习长期依赖关系。通过引入精巧的门控机制(输入门、遗忘门、输出门),LSTM能够有选择地让信息在序列中传递,从而显著提升了模型处理长序列数据的能力。
基础结构
LSTM 通过引入特殊的记忆单元(Memory Cell),能够有效提升模型对长序列依赖关系的建模能力。
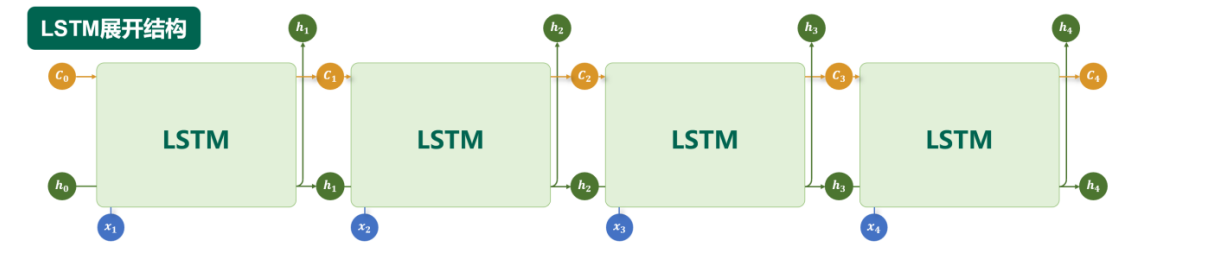
图中可以看到四个连续的LSTM单元,每个单元接收当前时刻的输入(如x₁, x₂, …)和上一时刻传递来的两个状态:隐藏状态h和细胞状态c,并在内部处理后输出更新后的h和c,传递给下一时刻。
核心要点:
- 状态传递机制:LSTM通过两个状态在时间步间传递信息——隐藏状态h(通常用于当前时间步输出)和细胞状态c(作为内部记忆,负责长程信息保持)。
- 门控结构:每个LSTM单元内部包含三个门(输入门、遗忘门、输出门)正是这些门控制着信息的保留、遗忘与输出,这也是LSTM能够缓解梯度消失/爆炸问题的关键。
- 时间展开视图:这种“展开”示意图将循环结构按时间步展开,直观呈现序列数据(如文本、时间序列)在LSTM中逐步处理的过程。
通过这种结构,LSTM能够有选择地记住长期信息(如段落开头的关键语义)并忘记次要信息,因此在机器翻译、文本生成、语音识别等需要建模长距离依赖的任务中表现优于普通RNN。
Ø 记忆单元(Memory Cell)
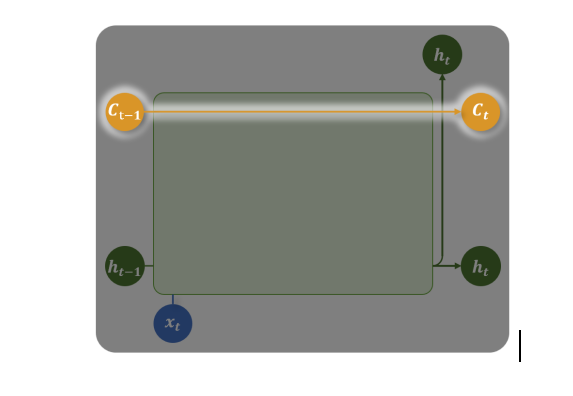
图中那条橙黄色的水平通道(Ct−1→Ct),正是 LSTM 实现长期信息传递的关键——细胞状态。
它的运作可以理解为两条并行的信息流:
- 长期记忆流(橙黄色通道) 细胞状态 Ct在时间步之间保持相对稳定的流动,它像一条“传送带”,能够跨越多步直接传递重要信息,而不易受到短期波动的干扰。这使得网络能够记住较早时间步的关键信息(例如句子的主语或段落主旨)。
- 短期记忆与交互流(绿色/蓝色通道) 隐藏状态 ht和输入 xt参与每个时间步的具体计算,负责捕捉局部依赖和当前输入的影响。ht通常作为当前步的输出,也参与下一时间步的计算,形成短期信息的循环。
遗忘门(Forget Gate)
遗忘门的核心作用是决定从上一时间步的记忆单元 Ct-1 中保留多少信息。它通过一个 sigmoid 函数(图中紫色 σ 模块)生成一个介于 0 到 1 之间的控制系数 ft:
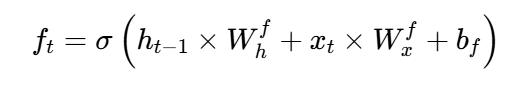
其中:
- ft:遗忘门的输出,取值范围在0到1之间(通过Sigmoid函数 σ实现),表示保留上一时间步记忆的比例。
- ht−1:上一时间步的隐藏状态(历史信息)。
- xt:当前时间步的输入(新信息)。
- Whf和 Wxf:分别对应隐藏状态和输入的权重矩阵。
- bf:偏置项。
案例:文档主题切换
假设历史输入是:
“本次会议重点讨论了第三季度的财务报告。数据显示营收超出预期,但利润率有所下滑。接下来我们将规划明年的市场策略。”
此时,当前时间步的输入是:
“关于新产品的用户反馈……”
分析:
当模型读到“关于新产品的用户反馈”时,遗忘门应该发挥作用,显著降低与“财务报告”、“市场策略”等上一主题相关的信息在记忆单元中的权重。因为新输入明确指示了话题已从“财务与规划”切换到了“产品反馈”,之前讨论的财务细节对于生成后续关于用户反馈的内容不再重要。
通过这种方式,LSTM 能够动态地“忘记”不再相关的旧话题信息,为处理新话题腾出认知资源,从而保证生成内容的相关性和一致性。
输入门(Input Gate)
输入门的公式与遗忘门类似,但参数不同:
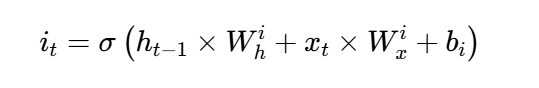
同时,当前输入信息会通过 tanh层形成一个候选记忆:
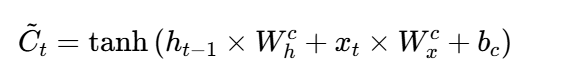
最终输入门 it控制多少候选记忆 C~t写入当前记忆单元。
例子理解:
在当前输入为“新产品”时,输入门 it会控制将“新产品”作为新主语的这一信息写入到记忆单元中,从而更新话题主语。
- 遗忘门决定保留多少旧记忆 Ct−1(图中公式部分)。
- 输入门决定写入多少新信息 C~t(您补充的部分)。
- 更新记忆单元:
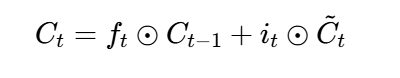
输出门(Output Gate)
输出门(Output Gate)在 LSTM 中的作用是控制当前时间步从记忆单元(Cell State)中读取多少信息,以生成当前隐藏状态(Hidden State)。其计算逻辑与遗忘门、输入门类似,但功能不同。
基于当前输入 xt和上一时间步的隐藏状态 ht−1,通过 Sigmoid 函数生成一个介于 0 到 1 之间的控制系数 ot:
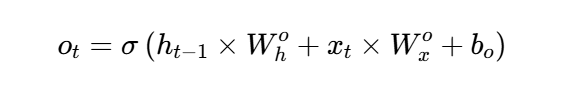
输出门是 LSTM 的“信息释放阀门”,它确保隐藏状态 ht仅包含当前时间步需要的信息,而非记忆单元中的全部内容。这种选择性输出机制使 LSTM 能灵活控制信息的暴露程度,适应不同上下文需求。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号