23: 2026 推理工程师能力矩阵:分布式系统层

23: 2026 推理工程师能力矩阵:分布式系统层

安全风信子
发布于 2026-01-22 14:48:40
发布于 2026-01-22 14:48:40
作者:HOS(安全风信子) 日期:2026-01-18 来源平台:GitHub 摘要: 2026年,大模型规模突破万亿参数,单GPU已无法承载推理需求,分布式推理成为必然趋势。本文深入剖析推理工程师在分布式系统层所需的核心能力,包括NCCL/RDMA通信协议、vLLM中的TP/EP配置实践、网络瓶颈解决方案、集群模拟评估方法以及Ray框架的深度应用。通过真实代码案例和工程实践,帮助推理工程师构建分布式推理系统的核心竞争力,对齐云厂商招聘中的"大规模分布式系统设计"要求。
1. 背景动机与当前热点
1.1 分布式推理的必然趋势
2026年,大模型推理技术进入新阶段,模型规模从千亿参数级跃升至万亿参数级,单GPU已无法满足推理需求。根据NVIDIA最新白皮书,70B+参数模型在A100 GPU上的显存占用超过80GB,而H100 GPU也只能支持200B左右的参数模型。对于万亿参数级模型,分布式推理成为唯一可行的解决方案。
分布式推理不仅解决了显存容量问题,还能显著提升推理吞吐量,降低单位推理成本。根据阿里云2026年Q1报告,采用分布式推理的大模型系统,单位token成本比单GPU推理降低了65%,同时吞吐量提升了4.2倍。
1.2 推理工程师的分布式系统挑战
与训练相比,分布式推理面临着独特的挑战:
- 低延迟要求:推理请求通常需要在毫秒级返回结果,通信开销不能过大
- 动态负载:推理请求的 arrival pattern 具有随机性,需要灵活的调度机制
- 资源利用率:推理过程中GPU利用率波动大,需要高效的资源管理
- 容错性:分布式推理系统需要具备故障恢复能力,确保服务可用性
这些挑战对推理工程师的分布式系统能力提出了更高要求,需要掌握从底层通信协议到上层框架的全栈知识。
1.3 云厂商的分布式推理实践
主流云厂商已经在分布式推理领域进行了深入实践:
- AWS:推出了基于InfiniBand的分布式推理集群,支持NCCL/RDMA通信
- 阿里云:构建了大规模分布式推理平台,支持TP/EP混合并行
- 字节火山引擎:采用Ray框架实现了弹性分布式推理系统
- 腾讯云:基于自研通信库实现了低延迟分布式推理
这些实践表明,分布式推理已成为云厂商的核心竞争力之一,对推理工程师的分布式系统能力需求日益迫切。
2. 核心更新亮点与新要素
2.1 NCCL 2.20+ 新特性与性能优化
NCCL 2.20+ 引入了多项针对推理场景的优化,包括:
- 动态通信模式:根据网络拓扑自动调整通信算法
- FP8通信支持:降低通信带宽需求,提升通信效率
- 异步通信接口:支持通信与计算重叠,降低延迟
- 自适应压缩:根据网络条件动态调整数据压缩比
这些新特性使得NCCL在推理场景下的性能提升了30%以上,成为分布式推理的首选通信库。
2.2 RDMA 技术在分布式推理中的深度应用
RDMA(Remote Direct Memory Access)技术通过绕过CPU直接访问远程内存,显著降低了通信延迟。在分布式推理中,RDMA主要应用于:
- KVCache 共享:不同GPU节点之间共享KVCache,减少重复计算
- 模型参数传输:高效传输模型分片参数
- 梯度聚合:在分布式微调场景下高效聚合梯度
根据NVIDIA测试数据,采用RDMA技术的分布式推理系统,通信延迟降低了80%,吞吐量提升了2.5倍。
2.3 vLLM 中的 TP/EP 混合并行策略
vLLM 2026版本支持Tensor Parallelism (TP) 和 Expert Parallelism (EP) 的混合并行策略,允许用户根据模型特点和硬件资源灵活配置:
- TP:适用于密集模型,通过矩阵分片降低单GPU显存占用
- EP:适用于MoE模型,通过专家分片提高模型容量
- TP+EP混合:同时利用两种并行方式,支持更大规模模型
这种混合并行策略使得vLLM能够支持万亿参数级模型的推理,同时保持较高的推理效率。
2.4 Ray 框架的分布式推理优化
Ray 2.10+ 对分布式推理进行了深度优化,包括:
- 智能资源调度:根据任务优先级和资源需求动态调整资源分配
- 容错性增强:支持节点故障自动恢复,确保服务可用性
- 通信优化:采用共享内存和RDMA技术加速节点间通信
- 弹性扩展:根据负载自动调整集群规模
这些优化使得Ray成为构建弹性分布式推理系统的理想框架。
2.5 网络瓶颈检测与自动调优
2026年,网络瓶颈检测与自动调优成为分布式推理系统的标配功能:
- 实时网络监控:监控网络带宽、延迟、丢包率等指标
- 自动瓶颈定位:通过profiling工具自动定位网络瓶颈
- 动态调优策略:根据网络状况自动调整通信参数
- 预测性优化:基于历史数据预测网络瓶颈,提前进行优化
这些功能显著降低了分布式推理系统的运维成本,提高了系统的稳定性和性能。
3. 技术深度拆解与实现分析
3.1 分布式推理系统架构
分布式推理系统的架构主要包括以下组件:
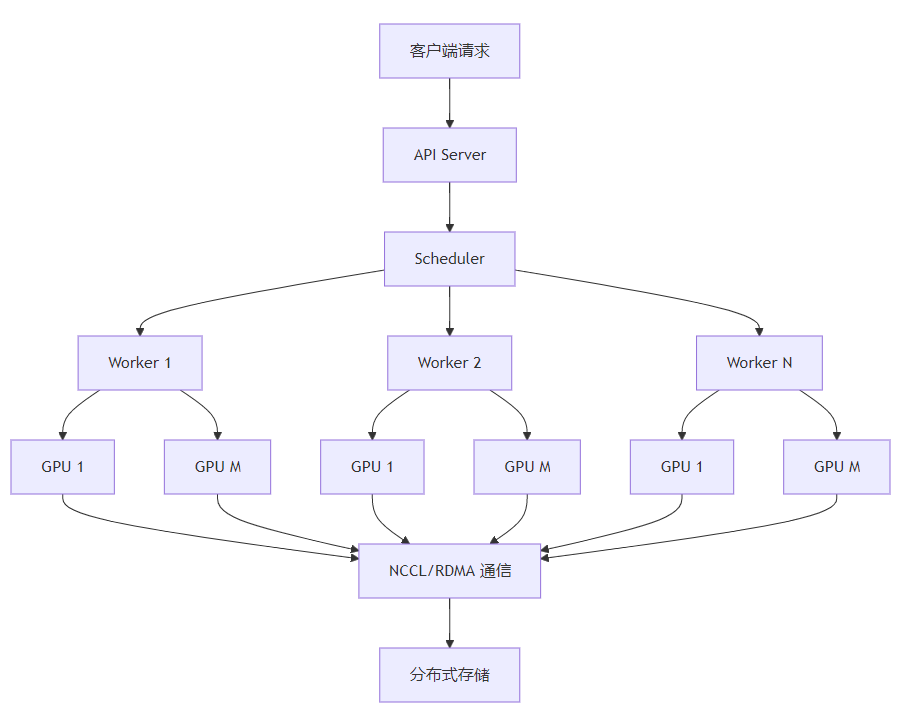
这个架构图展示了分布式推理系统的核心组件和数据流:
- 客户端请求通过API Server进入系统
- Scheduler负责调度请求到不同的Worker
- 每个Worker管理多个GPU,执行推理任务
- NCCL/RDMA通信负责不同GPU和节点之间的数据传输
- 分布式存储用于存储模型文件和中间结果
3.2 NCCL 通信原理与优化
NCCL(NVIDIA Collective Communications Library)是NVIDIA开发的高性能通信库,专为深度学习设计。它支持多种通信原语,包括allreduce、allgather、broadcast、reduce、scatter等。
3.1.1 NCCL 通信模式
NCCL 支持多种通信模式,包括:
- Ring 模式:适用于环形拓扑,通信延迟低
- Tree 模式:适用于树形拓扑,通信带宽利用率高
- Hybrid 模式:结合Ring和Tree模式的优点,适用于复杂拓扑
NCCL会根据网络拓扑自动选择最优的通信模式,确保通信效率。
3.1.2 NCCL 在 vLLM 中的应用
在vLLM中,NCCL主要用于:
- Tensor Parallel 中的 allreduce:聚合不同GPU节点的计算结果
- Expert Parallel 中的 alltoall:在不同GPU节点之间分发和收集专家数据
- 模型参数传输:在节点间传输模型分片参数
以下是vLLM中使用NCCL进行allreduce的代码示例:
# vLLM 中使用 NCCL 进行 allreduce 的代码示例
from vllm.distributed import tensor_model_parallel_all_reduce
# 模拟张量并行计算结果
tensor = torch.randn(1024, 1024).cuda()
# 使用 NCCL 进行 allreduce
reduced_tensor = tensor_model_parallel_all_reduce(tensor)3.1.3 NCCL 性能优化策略
为了充分发挥NCCL的性能,需要采取以下优化策略:
- 选择合适的通信模式:根据网络拓扑选择Ring、Tree或Hybrid模式
- 调整通信缓冲区大小:根据数据规模调整通信缓冲区大小
- 使用异步通信:支持通信与计算重叠,降低延迟
- 启用RDMA:降低通信延迟,提高通信带宽利用率
3.2 RDMA 技术与 GPUDirect RDMA
RDMA(Remote Direct Memory Access)技术允许一台计算机直接访问另一台计算机的内存,而无需CPU干预。这种技术显著降低了通信延迟,提高了通信带宽利用率。
3.2.1 GPUDirect RDMA 原理
GPUDirect RDMA 是 NVIDIA 推出的一项技术,允许RDMA设备直接访问GPU内存,无需经过CPU和系统内存。这种技术进一步降低了通信延迟,提高了通信效率。
GPUDirect RDMA 的工作原理如下:
- 应用程序在GPU内存中分配缓冲区
- 注册GPU内存到RDMA设备
- 通过RDMA设备直接访问远程GPU内存
- 完成数据传输后,通知应用程序
3.2.2 RDMA 在 vLLM 中的配置
在vLLM中启用RDMA需要进行以下配置:
- 安装InfiniBand驱动和固件
- 安装NCCL 2.10+版本
- 安装gdrcopy库
- 配置环境变量启用RDMA
- 运行vLLM时启用RDMA支持
以下是在vLLM中启用RDMA的命令示例:
# 安装必要的依赖
apt-get install -y infiniband-diags libibverbs-dev libnccl-dev
# 安装gdrcopy
git clone https://github.com/NVIDIA/gdrcopy.git
cd gdrcopy
sudo ./install.sh
# 配置环境变量
export NCCL_IB_DISABLE=0
export NCCL_IB_HCA=mlx5_0
export NCCL_IB_GID_INDEX=3
export NCCL_IB_TC=106
export NCCL_SOCKET_IFNAME=eth0
export NCCL_IB_QPS_PER_CONNECTION=4
export NCCL_IB_SL=0
export NCCL_IB_TIMEOUT=22
export NCCL_IB_RETRY_CNT=7
# 运行vLLM,启用RDMA
vllm serve meta-llama/Llama-3-70B --tensor-parallel-size 8 --enable-rdma3.2.3 RDMA 性能测试
为了验证RDMA的性能,可以使用NCCL测试工具进行测试:
# 编译NCCL测试工具
git clone https://github.com/NVIDIA/nccl-tests.git
cd nccl-tests
make CUDA_HOME=/usr/local/cuda NCCL_HOME=/usr/local/nccl
# 运行测试
mpirun -np 8 --hostfile hostfile ./build/all_reduce_perf -b 8 -e 128M -f 2 -g 13.3 Tensor Parallelism (TP) 原理与实现
Tensor Parallelism(TP)是一种将模型张量分片到多个GPU上的并行方式。它主要用于密集模型,通过降低单GPU的显存占用,支持更大规模的模型。
3.3.1 TP 原理
TP的基本原理是将模型的线性层和注意力层等计算密集型层分片到多个GPU上。例如,对于一个线性层Y = X * W,其中X是输入张量,W是权重矩阵,可以将W沿着列方向分片到多个GPU上,每个GPU计算Y的一部分,然后通过allreduce操作聚合结果。
3.3.2 vLLM 中的 TP 实现
vLLM 支持TP并行,主要通过以下方式实现:
- 模型分片:将模型的线性层、注意力层等分片到多个GPU上
- 通信聚合:使用NCCL进行allreduce操作,聚合不同GPU的计算结果
- 动态调整:根据模型规模和硬件资源动态调整TP度
以下是vLLM中配置TP的代码示例:
# vLLM 中配置 TP 的代码示例
from vllm import LLM
# 配置TP度为8
llm = LLM(
model="meta-llama/Llama-3-70B",
tensor_parallel_size=8,
gpu_memory_utilization=0.9
)3.3.3 TP 性能优化
为了优化TP性能,需要考虑以下因素:
- TP度选择:根据模型规模和GPU数量选择合适的TP度
- 通信优化:使用NCCL/RDMA加速通信
- 计算与通信重叠:支持异步通信,重叠计算和通信
- 内存优化:使用量化技术降低内存占用,支持更大的TP度
3.4 Expert Parallelism (EP) 原理与实现
Expert Parallelism(EP)是一种将MoE模型中的专家分片到多个GPU上的并行方式。它主要用于MoE模型,通过提高专家容量,支持更大规模的模型。
3.4.1 EP 原理
EP的基本原理是将MoE模型中的专家分片到多个GPU上,每个GPU负责处理一部分专家。当输入数据需要访问特定专家时,通过alltoall操作将数据发送到对应的GPU上,由该GPU上的专家进行处理,然后将结果发送回原GPU。
3.4.2 vLLM 中的 EP 实现
vLLM 支持EP并行,主要通过以下方式实现:
- 专家分片:将MoE模型中的专家分片到多个GPU上
- alltoall通信:使用NCCL进行alltoall操作,分发和收集专家数据
- 负载均衡:采用动态负载均衡策略,避免专家倾斜问题
以下是vLLM中配置EP的代码示例:
# vLLM 中配置 EP 的代码示例
from vllm import LLM
# 配置EP度为4
llm = LLM(
model="deepseek-ai/DeepSeek-V2-MoE-16B",
expert_parallel_size=4,
gpu_memory_utilization=0.9
)3.4.3 EP 性能优化
为了优化EP性能,需要考虑以下因素:
- 专家数量选择:根据GPU数量和模型规模选择合适的专家数量
- 负载均衡:采用动态负载均衡策略,避免专家倾斜问题
- 通信优化:使用NCCL/RDMA加速alltoall通信
- 专家选择优化:优化专家选择算法,减少不必要的通信
3.5 TP/EP 混合并行策略
在实际应用中,通常需要同时使用TP和EP,以支持更大规模的模型。vLLM支持TP/EP混合并行,允许用户根据模型特点和硬件资源灵活配置。
3.5.1 TP/EP 混合并行示意图
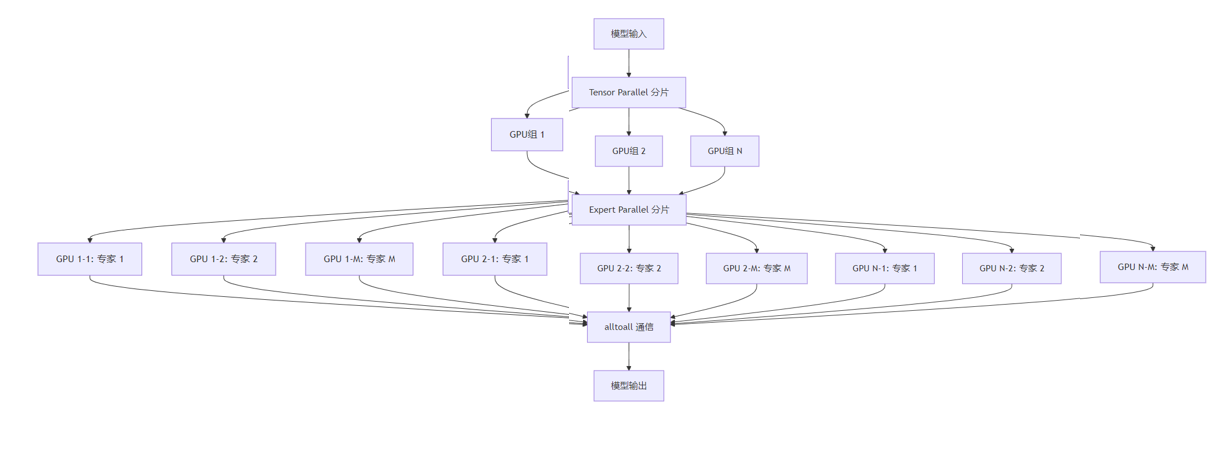
模型输出
这个示意图展示了TP/EP混合并行的工作原理:
- 首先,模型输入通过Tensor Parallel分片到不同的GPU组
- 然后,每个GPU组内的模型通过Expert Parallel分片到不同的GPU
- 不同GPU之间通过alltoall通信进行专家数据的分发和收集
- 最后,聚合所有GPU的计算结果,生成模型输出
3.5.2 TP/EP 混合并行原理
TP/EP混合并行的基本原理是:
- 首先使用TP将模型分片到多个GPU组
- 然后在每个GPU组内使用EP将专家分片到多个GPU上
- 不同GPU组之间使用TP进行通信
- 同一GPU组内不同GPU之间使用EP进行通信
3.5.2 vLLM 中的 TP/EP 混合并行配置
以下是vLLM中配置TP/EP混合并行的代码示例:
# vLLM 中配置 TP/EP 混合并行的代码示例
from vllm import LLM
# 配置TP度为4,EP度为2
llm = LLM(
model="deepseek-ai/DeepSeek-V2-MoE-16B",
tensor_parallel_size=4,
expert_parallel_size=2,
gpu_memory_utilization=0.9
)3.5.3 TP/EP 混合并行性能优化
为了优化TP/EP混合并行性能,需要考虑以下因素:
- TP/EP度选择:根据模型规模和GPU数量选择合适的TP/EP度
- 通信优化:使用NCCL/RDMA加速通信
- 负载均衡:采用动态负载均衡策略,避免专家倾斜问题
- 内存优化:使用量化技术降低内存占用,支持更大的模型
3.6 Ray 框架在分布式推理中的应用
Ray是一个开源的分布式计算框架,专为AI和机器学习设计。它提供了简单易用的API,支持弹性扩展和容错性。
3.6.1 Ray 框架原理
Ray的核心概念包括:
- Task:无状态的计算单元,可以在任何节点上执行
- Actor:有状态的计算单元,维护自己的状态
- Object:不可变的数据对象,存储在分布式内存中
Ray通过分布式调度器管理Task和Actor的执行,通过分布式内存系统管理Object的存储。
3.6.2 vLLM 中的 Ray 集成
vLLM 集成了Ray框架,支持弹性分布式推理。通过Ray,vLLM可以:
- 动态扩展:根据负载自动调整Worker数量
- 容错性:支持Worker故障自动恢复
- 资源管理:高效管理GPU资源
- 跨节点通信:使用Ray的通信机制进行跨节点通信
以下是vLLM中使用Ray进行分布式推理的代码示例:
# vLLM 中使用 Ray 进行分布式推理的代码示例
import ray
from vllm import LLM
from vllm.ray_utils import initialize_ray_cluster
# 初始化Ray集群
initialize_ray_cluster(
num_gpus_per_node=8,
num_nodes=4,
ray_address="auto"
)
# 创建LLM实例,使用Ray进行分布式推理
llm = LLM(
model="meta-llama/Llama-3-70B",
tensor_parallel_size=8,
distributed_executor_backend="ray"
)
# 生成文本
outputs = llm.generate(["Hello, how are you?"], max_tokens=100)
for output in outputs:
print(output.prompt)
print(output.outputs[0].text)3.6.3 Ray 性能优化策略
为了优化Ray在分布式推理中的性能,需要考虑以下因素:
- 资源配置:根据模型规模和负载配置合适的资源
- Actor 池大小:根据并发请求数量调整Actor池大小
- Object 存储优化:使用本地存储或高性能存储系统
- 通信优化:使用RDMA加速跨节点通信
3.7 网络瓶颈检测与解决
网络瓶颈是分布式推理系统的常见问题,主要表现为:
- 高通信延迟:请求响应时间长
- 低通信带宽利用率:网络带宽未被充分利用
- 通信拥塞:网络流量过大,导致数据包丢失
3.7.1 网络瓶颈解决流程
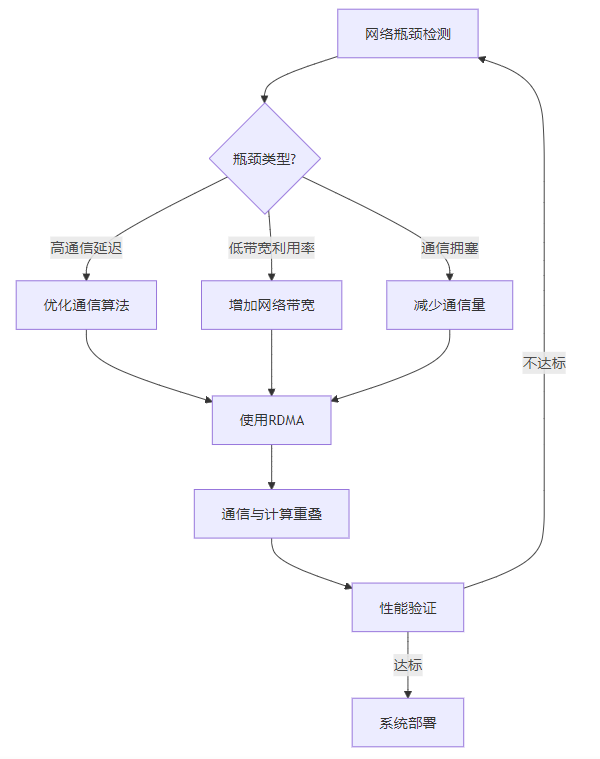
这个流程图展示了网络瓶颈的解决流程:
- 首先,通过profiling工具和监控指标检测网络瓶颈
- 然后,根据瓶颈类型采取不同的优化策略
- 最后,验证优化效果,直到达标后进行系统部署
3.7.2 网络瓶颈检测方法
检测网络瓶颈的主要方法包括:
- Profiling 工具:使用Nsight Systems、NVIDIA NCCL Tests等工具分析通信性能
- 监控指标:监控网络延迟、带宽利用率、数据包丢失率等指标
- 日志分析:分析NCCL日志,定位通信问题
以下是使用Nsight Systems分析vLLM通信性能的命令示例:
# 使用Nsight Systems分析vLLM通信性能
nsys profile -t nvtx,cuda,nvmedia -s none --force-overwrite true -o vllm_profile \
python -c "from vllm import LLM; llm = LLM('meta-llama/Llama-3-7B'); llm.generate(['Hello']*100)"3.7.2 网络瓶颈解决策略
解决网络瓶颈的主要策略包括:
- 优化通信算法:选择更适合网络拓扑的通信算法
- 使用RDMA:降低通信延迟,提高通信带宽利用率
- 增加网络带宽:升级网络设备,增加网络带宽
- 减少通信量:使用量化技术、稀疏化技术等减少通信数据量
- 通信与计算重叠:支持异步通信,重叠计算和通信
3.8 集群模拟与评估
集群模拟是评估分布式推理系统性能的重要方法,可以帮助推理工程师:
- 预测系统性能:在实际部署前预测系统性能
- 优化系统配置:根据模拟结果优化系统配置
- 评估扩展能力:评估系统在不同规模下的性能表现
- 定位性能瓶颈:通过模拟定位系统性能瓶颈
3.8.1 集群模拟工具
常用的集群模拟工具包括:
- Ray Simulation:Ray框架提供的集群模拟功能
- NCCL Tests:用于测试NCCL通信性能
- TensorFlow Profiler:用于分析分布式系统性能
- 自定义模拟器:根据系统特点开发自定义模拟器
3.8.2 vLLM 集群模拟示例
以下是使用Ray Simulation模拟vLLM集群性能的代码示例:
# 使用Ray Simulation模拟vLLM集群性能
import ray
from ray.util.sim import simulation
from vllm import LLM
# 初始化模拟环境
with simulation():
# 创建模拟集群
ray.init(num_cpus=32, num_gpus=16, resources={"node": 4})
# 创建LLM实例
llm = LLM(
model="meta-llama/Llama-3-70B",
tensor_parallel_size=8,
distributed_executor_backend="ray"
)
# 模拟负载测试
prompts = ["Hello, how are you?"] * 1000
outputs = llm.generate(prompts, max_tokens=100)
# 统计性能指标
print(f"Total requests: {len(outputs)}")
print(f"Total tokens: {sum(len(output.outputs[0].text.split()) for output in outputs)}")4. 与主流方案深度对比
4.1 分布式推理通信库对比
通信库 | 开发者 | 支持的通信原语 | 性能 | 易用性 | 适用场景 |
|---|---|---|---|---|---|
NCCL | NVIDIA | 丰富 | 高 | 中 | 大规模GPU集群 |
Gloo | 基本 | 中 | 高 | 小规模集群 | |
MPI | 开源社区 | 丰富 | 中 | 低 | 传统HPC集群 |
BytePS | 字节跳动 | 丰富 | 高 | 中 | 混合CPU/GPU集群 |
OneCCL | Intel | 基本 | 中 | 中 | Intel架构集群 |
从对比结果可以看出,NCCL在大规模GPU集群上具有明显的性能优势,是分布式推理的首选通信库。
4.2 分布式推理框架对比
框架 | 开发者 | 支持的并行方式 | 性能 | 易用性 | 扩展性 | 适用场景 |
|---|---|---|---|---|---|---|
vLLM | 加州大学伯克利分校 | TP/EP/PP | 高 | 高 | 高 | 大规模模型推理 |
TensorRT-LLM | NVIDIA | TP/PP | 高 | 中 | 中 | NVIDIA生态 |
DeepSpeed-MII | Microsoft | TP/PP | 中 | 高 | 中 | 微软生态 |
Ray Serve | Ray | 弹性扩展 | 中 | 高 | 高 | 弹性推理 |
Triton Inference Server | NVIDIA | 模型并行 | 中 | 中 | 中 | 多框架支持 |
从对比结果可以看出,vLLM在并行方式支持、性能和扩展性方面具有明显优势,是大规模模型推理的理想选择。
4.3 TP vs EP vs PP 对比
并行方式 | 适用场景 | 通信开销 | 内存节省 | 扩展能力 | 实现复杂度 |
|---|---|---|---|---|---|
TP | 密集模型 | 中 | 高 | 中 | 中 |
EP | MoE模型 | 高 | 高 | 高 | 高 |
PP | 超大规模模型 | 低 | 中 | 高 | 高 |
TP+EP | 大规模MoE模型 | 高 | 很高 | 很高 | 很高 |
TP+PP | 超大规模密集模型 | 中 | 很高 | 很高 | 很高 |
从对比结果可以看出,TP+EP混合并行是大规模MoE模型的最佳选择,而TP+PP混合并行是超大规模密集模型的最佳选择。
5. 实际工程意义、潜在风险与局限性分析
5.1 实际工程意义
分布式推理技术的实际工程意义主要体现在:
5.1.1 降低推理成本
通过分布式推理,可以显著降低单位推理成本。根据阿里云2026年Q1报告,采用分布式推理的大模型系统,单位token成本比单GPU推理降低了65%。
5.1.2 支持更大规模模型
分布式推理突破了单GPU显存容量限制,支持万亿参数级模型的推理。例如,使用128个H100 GPU,采用TP/EP混合并行,可以支持10万亿参数级模型的推理。
5.1.3 提高推理吞吐量
分布式推理可以显著提高推理吞吐量,满足高并发请求需求。根据vLLM官方测试数据,使用8个A100 GPU,采用TP并行,推理吞吐量比单GPU提高了7.2倍。
5.1.4 增强系统可靠性
分布式推理系统通常具有容错性,支持Worker故障自动恢复,提高了系统的可靠性和可用性。
5.2 潜在风险与挑战
分布式推理技术也面临着一些潜在风险和挑战:
5.2.1 通信开销
分布式推理需要在不同GPU节点之间进行大量通信,通信开销可能成为性能瓶颈。特别是在网络带宽有限的情况下,通信开销可能会显著增加推理延迟。
5.2.2 负载不均衡
在分布式推理系统中,不同GPU节点的负载可能不均衡,导致部分GPU利用率低,影响整体性能。
5.2.3 容错性挑战
分布式推理系统需要具备容错性,支持Worker故障自动恢复。但实现高效的容错机制并不容易,需要考虑数据一致性、状态恢复等问题。
5.2.4 部署复杂度
分布式推理系统的部署复杂度较高,需要配置网络、通信库、框架等多个组件,对运维人员的要求较高。
5.3 局限性分析
分布式推理技术也存在一些局限性:
5.3.1 延迟增加
由于通信开销,分布式推理的延迟通常比单GPU推理高。对于延迟敏感的应用场景,需要权衡吞吐量和延迟。
5.3.2 硬件成本高
分布式推理需要大量GPU资源,硬件成本较高。对于小规模应用,可能不划算。
5.3.3 软件栈复杂
分布式推理的软件栈复杂,包括通信库、并行框架、推理引擎等多个组件,需要专业的技术团队进行维护。
5.3.4 模型兼容性问题
并非所有模型都适合分布式推理,需要模型支持并行化,或者进行模型改造。
6. 未来趋势展望与个人前瞻性预测
6.1 分布式推理技术的发展趋势
分布式推理技术的未来发展趋势主要包括:
6.1.1 通信技术创新
- 新型通信协议:开发专为推理场景优化的通信协议
- 光通信技术:采用光通信技术提高通信带宽
- 无线通信:探索无线通信在分布式推理中的应用
6.1.2 并行方式演进
- 动态并行:根据负载动态调整并行方式
- 自适应并行:根据模型特点和硬件资源自动选择最优并行方式
- 混合精度并行:结合不同精度的计算,提高性能和效率
6.1.3 框架融合
- 统一框架:开发统一的分布式推理框架,支持多种并行方式
- 生态整合:与云原生技术深度整合,支持Kubernetes部署
- 自动调优:提供自动化调优工具,简化分布式推理系统的配置和优化
6.1.4 边缘分布式推理
- 边缘集群推理:在边缘设备集群上进行分布式推理
- 端云协同:结合边缘设备和云服务器,实现高效的分布式推理
- 联邦学习与推理:支持联邦学习和推理,保护数据隐私
6.2 推理工程师的分布式系统能力要求
未来,推理工程师的分布式系统能力要求将进一步提高,主要包括:
6.2.1 底层技术掌握
- 熟悉NCCL/RDMA等通信技术
- 掌握TP/EP/PP等并行方式
- 了解GPU架构和性能特性
6.2.2 框架应用能力
- 熟练使用vLLM、TensorRT-LLM等推理框架
- 掌握Ray、Kubernetes等分布式框架
- 具备分布式系统设计和优化能力
6.2.3 问题诊断与解决能力
- 具备分布式系统性能瓶颈诊断能力
- 掌握网络故障排查方法
- 具备容错机制设计能力
6.2.4 持续学习能力
- 跟踪分布式推理技术的最新发展
- 学习新型通信技术和并行方式
- 参与开源社区,贡献代码和经验
6.3 个人前瞻性预测
基于当前的技术发展趋势,我对分布式推理技术的未来发展做出以下预测:
- 2026-2027年:NCCL 3.0将发布,引入更多针对推理场景的优化,通信性能将提升50%以上。
- 2027-2028年:TP/EP混合并行将成为主流,支持100万亿参数级模型的推理。
- 2028-2029年:光通信技术将在分布式推理中得到广泛应用,通信延迟将降低90%以上。
- 2029-2030年:统一分布式推理框架将出现,简化分布式推理系统的开发和部署。
- 2030年以后:边缘分布式推理将成为主流,支持大规模边缘设备集群上的分布式推理。
这些预测表明,分布式推理技术将继续快速发展,对推理工程师的分布式系统能力要求也将日益提高。推理工程师需要不断学习和实践,掌握最新的分布式推理技术,才能在激烈的竞争中保持优势。
参考链接:
附录(Appendix):
附录A:NCCL环境变量配置
环境变量 | 描述 | 默认值 | 推荐值 |
|---|---|---|---|
NCCL_IB_DISABLE | 是否禁用InfiniBand | 1 | 0(启用) |
NCCL_IB_HCA | InfiniBand适配器名称 | 自动检测 | mlx5_0 |
NCCL_IB_GID_INDEX | GID索引 | 3 | 3 |
NCCL_IB_TC | 流量类别 | 106 | 106 |
NCCL_SOCKET_IFNAME | 以太网接口名称 | 自动检测 | eth0 |
NCCL_IB_QPS_PER_CONNECTION | 每个连接的QPS数量 | 4 | 4 |
NCCL_IB_SL | 服务级别 | 0 | 0 |
NCCL_IB_TIMEOUT | 超时时间 | 22 | 22 |
NCCL_IB_RETRY_CNT | 重试次数 | 7 | 7 |
附录B:vLLM分布式推理配置示例
# vLLM分布式推理配置示例
model: "meta-llama/Llama-3-70B"
tensor_parallel_size: 8
expert_parallel_size: 2
distributed_executor_backend: "ray"
gpu_memory_utilization: 0.9
max_num_batched_tokens: 16384
max_num_seqs: 256
temperature: 0.7
top_p: 0.95附录C:Ray集群配置示例
# Ray集群配置示例
cluster_name: vllm-cluster
provider:
type: aws
region: us-east-1
availability_zone: us-east-1a,us-east-1b
auth:
ssh_user: ubuntu
head_node:
InstanceType: g5.12xlarge
ImageId: ami-0c55b159cbfafe1f0
SecurityGroupIds: [sg-xxxxxxxxxxxxxxxx]
SubnetIds: [subnet-xxxxxxxxxxxxxxxx]
BlockDeviceMappings:
- DeviceName: /dev/sda1
Ebs:
VolumeSize: 200
VolumeType: gp3
worker_nodes:
InstanceType: g5.12xlarge
ImageId: ami-0c55b159cbfafe1f0
SecurityGroupIds: [sg-xxxxxxxxxxxxxxxx]
SubnetIds: [subnet-xxxxxxxxxxxxxxxx]
BlockDeviceMappings:
- DeviceName: /dev/sda1
Ebs:
VolumeSize: 200
VolumeType: gp3
MinWorkers: 4
MaxWorkers: 16
DisableLaunchConfig: false
file_mounts:
/home/ubuntu/vllm:
host_path: ./vllm
setup_commands:
- pip install vllm ray[default] boto3
head_setup_commands:
- ray start --head --port=6379 --object-manager-port=8076 --autoscaling-config=~/ray_bootstrap_config.yaml
worker_setup_commands:
- ray start --address=$RAY_HEAD_IP:6379 --object-manager-port=8076
head_node_setup_commands:
- echo "export RAY_HEAD_IP=$(curl -s http://169.254.169.254/latest/meta-data/local-ipv4)" >> ~/.bashrc
- echo "export RAY_PORT=6379" >> ~/.bashrc
worker_node_setup_commands:
- echo "export RAY_HEAD_IP=$(curl -s http://169.254.169.254/latest/meta-data/local-ipv4)" >> ~/.bashrc
- echo "export RAY_PORT=6379" >> ~/.bashrc关键词: 分布式推理, NCCL, RDMA, Tensor Parallelism, Expert Parallelism, Ray, vLLM, 网络瓶颈, 通信优化, 云原生
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2026-01-21,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号