第九章:Python的requests库和BeautifulSoup库实现网站信息爬取

第九章:Python的requests库和BeautifulSoup库实现网站信息爬取

啊阿狸不会拉杆
发布于 2026-01-21 10:12:05
发布于 2026-01-21 10:12:05
在如今这个信息爆炸的时代,数据的获取和整理变得尤为重要。而 Python 的 requests 和 BeautifulSoup 库则为我们提供了一种高效、便捷的网站信息爬取方式。今天,我将带大家深入了解爬虫的原理,并手把手地教大家如何利用这两个强大的库来实现网站信息的爬取。资源绑定附上完整源程序供读者参考学习。
一、爬虫原理
网络爬虫,简单来说,就是通过程序自动获取网站上的数据。其工作原理可以分为以下几个步骤:
- 发送请求:爬虫程序向目标网站发送 HTTP 请求,以获取网页内容。这类似于我们在浏览器中输入网址并访问网页的操作。
- 接收响应:网站服务器接收到请求后,会返回相应的 HTML 页面内容或其它资源。爬虫程序需要接收并处理这个响应。
- 解析 HTML:接收到的 HTML 内容是未经整理的源代码,爬虫程序需要通过解析这些代码,提取出有用的信息。这就需要用到像 BeautifulSoup 这样的 HTML 解析库。
- 提取数据:在解析 HTML 的基础上,根据特定的规则和选择器,提取出我们感兴趣的数据,如标题、链接、图片等。
- 保存数据:将提取到的数据按照一定的格式保存到本地或数据库中,以便后续的分析和使用。
- 遵守规则:在整个爬虫过程中,必须严格遵守法律法规和网站的使用条款,尊重网站的 robots.txt 文件规定,避免对网站服务器造成过大压力。
二、使用 requests 和 BeautifulSoup 库爬取网站信息的步骤
步骤一:安装必要的库
在开始之前,确保你的 Python 环境中已经安装了 requests 和 BeautifulSoup 库。若未安装,可以通过以下命令进行安装:
pip install requests beautifulsoup4步骤二:导入库
在 Python 脚本中,首先需要导入 requests 和 BeautifulSoup 库:
import requests
from bs4 import BeautifulSoup步骤三:发送 HTTP 请求
使用 requests 库向目标网站发送 GET 请求,获取网页内容:
url = '目标网站的 URL'
response = requests.get(url)步骤四:设置编码
为了确保获取到的内容能够正确显示,需要设置响应的编码格式:
response.encoding = 'utf-8' # 根据实际情况设置编码步骤五:检查请求是否成功
在继续之前,最好检查一下请求是否成功,即响应的状态码是否为 200:
if response.status_code == 200:
# 请求成功,继续处理
else:
print('请求失败,状态码:', response.status_code)步骤六:解析 HTML
使用 BeautifulSoup 对获取到的 HTML 内容进行解析:
soup = BeautifulSoup(response.text, 'html.parser')步骤七:提取数据
根据网页的结构,使用适当的选择器提取所需的数据。例如,提取表格中的数据:
table = soup.find('table')
if table:
rows = table.find_all('tr')
for row in rows:
cols = row.find_all('td')
# 提取具体数据步骤八:保存数据
将提取到的数据保存到本地文件或数据库中。例如,保存到文本文件:
with open('data.txt', 'w', encoding='utf-8') as f:
f.write('保存的数据内容')三、库函数总结
requests 库常用函数
函数名 | 参数 | 返回值 | 描述 |
|---|---|---|---|
get(url) | url: 目标网站的 URL | Response 对象: 包含服务器的响应内容 | 向指定 URL 发送 GET 请求 |
post(url, data) | url: 目标网站的 URL;data: 要发送的数据 | Response 对象 | 向指定 URL 发送 POST 请求 |
response.status_code | 无 | int: HTTP 响应状态码 | 获取响应的状态码 |
response.text | 无 | str: 响应内容的字符串形式 | 获取响应的文本内容 |
response.encoding | encoding: 编码格式 | 无 | 设置响应的编码格式 |
BeautifulSoup 库常用函数
函数名 | 参数 | 返回值 | 描述 |
|---|---|---|---|
BeautifulSoup(html, parser) | html: 要解析的 HTML 内容;parser: 解析器类型 | BeautifulSoup 对象 | 创建 BeautifulSoup 对象,用于解析 HTML |
find(name, attrs) | name: 标签名;attrs: 属性字典 | Tag 对象: 匹配的第一个标签 | 查找符合指定条件的第一个标签 |
find_all(name, attrs) | name: 标签名;attrs: 属性字典 | ResultSet 对象: 匹配的所有标签 | 查找符合指定条件的所有标签 |
select(selector) | selector: CSS 选择器 | ResultSet 对象: 匹配的所有元素 | 使用 CSS 选择器查找元素 |
tag.name | 无 | str: 标签名 | 获取标签的名称 |
tag.attrs | 无 | dict: 标签的属性字典 | 获取标签的属性 |
tag.string | 无 | str: 标签内的文本内容 | 获取标签内的纯文本内容(若标签内只有单一文本节点) |
四、示例程序
示例一:2016 中国大学排名爬虫
import requests
from bs4 import BeautifulSoup
# 目标 URL
url = 'https://www.shanghairanking.cn/rankings/bcur/2016'
# 发送 HTTP 请求
response = requests.get(url)
response.encoding = 'utf-8' # 确保正确的编码
# 检查请求是否成功
if response.status_code == 200:
# 使用 BeautifulSoup 解析 HTML
soup = BeautifulSoup(response.text, 'html.parser')
# 查找表格
table = soup.find('table')
# 检查是否找到了表格
if table:
# 找到所有的行
rows = table.find_all('tr')
# 遍历每一行,打印数据
for row in rows:
cols = row.find_all('td')
if len(cols) > 1: # 确保行中有数据
rank = cols[0].text.strip()
university = cols[1].text.strip().split('\n')[0]
score = cols[4].text.strip()
print(f'排名: {rank}, 学校: {university}, 总分: {score}')
else:
print('没有找到表格')
else:
print('请求失败,状态码:', response.status_code)
效果展示:
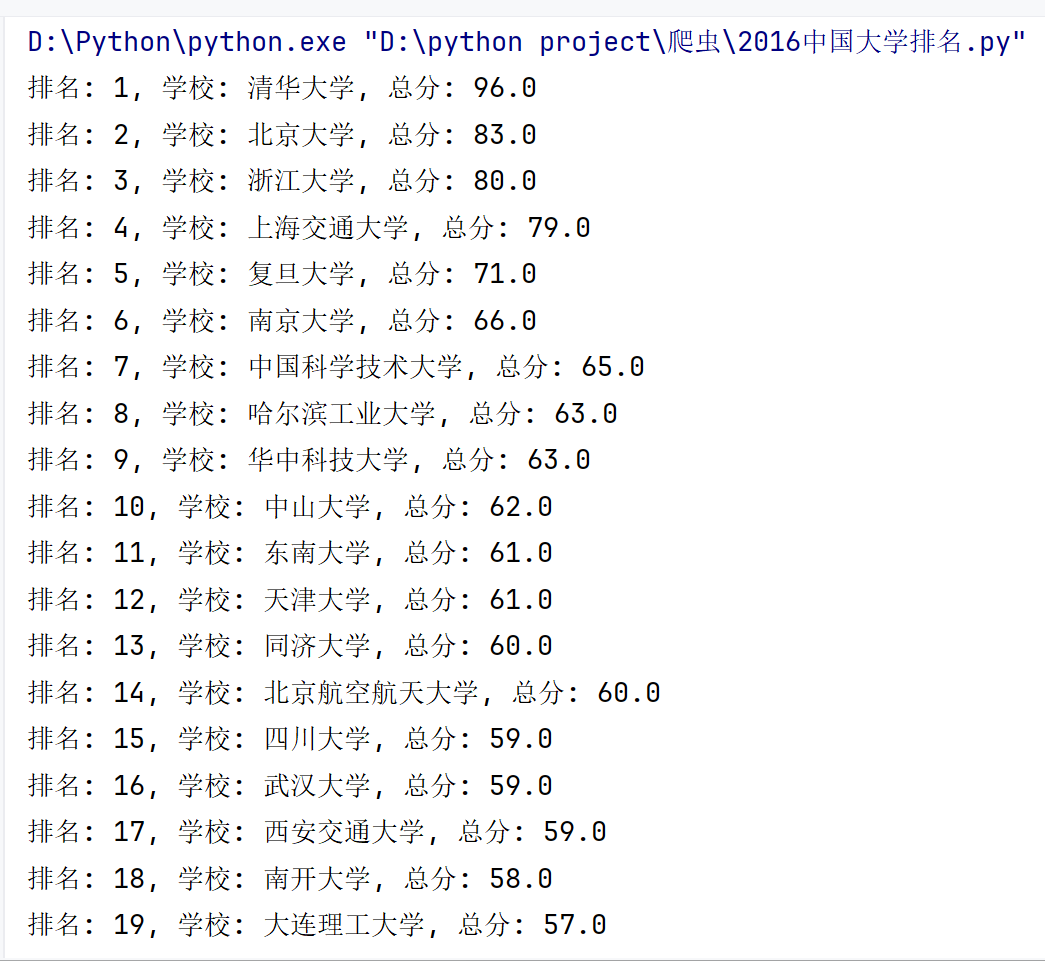
示例二:电影排名爬虫
import requests
from bs4 import BeautifulSoup
# 更换为可访问的电影排名网页(示例使用豆瓣电影Top250)
url = 'https://movie.douban.com/top250'
# 添加请求头模拟浏览器访问
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
try:
response = requests.get(url, headers=headers)
response.raise_for_status() # 检查请求是否成功
response.encoding = 'utf-8'
except requests.exceptions.RequestException as e:
print(f"网络请求失败: {e}")
exit()
soup = BeautifulSoup(response.text, 'html.parser')
# 根据豆瓣网页结构调整解析逻辑
movie_list = soup.find_all('div', class_='hd')
if not movie_list:
print("未找到电影信息,请检查网页结构。")
else:
print('排名\t电影名称')
for index, movie in enumerate(movie_list[:10], 1): # 取前10名
title = movie.a.span.text.strip()
print(f"{index}\t{title}")效果展示:

五、总结
通过以上内容,我们详细讲解了爬虫的原理以及使用 Python 的 requests 和 BeautifulSoup 库实现网站信息爬取的步骤。同时,我们还对这两个库中的常用函数进行了总结,以便大家在实际操作中能够更加得心应手。但是相对来说,爬虫这个板块还是很复杂的,建议感兴趣的读者进行系统学习,可以先从HTML(超文本标记语言)开始学习,了解网页中的元素组成。最后,通过两个示例程序,展示了如何将这些知识应用到实际的爬虫项目中。希望这篇帖子能够帮助大家更好地理解和掌握网站信息爬取的技术,为今后的数据分析和处理工作提供有力的支持。资源绑定附上完整源程序供读者参考学习。
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2025-03-27,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号