八大数据结构
原创
八大数据结构
原创
大飞felix
发布于 2026-01-20 10:23:03
发布于 2026-01-20 10:23:03
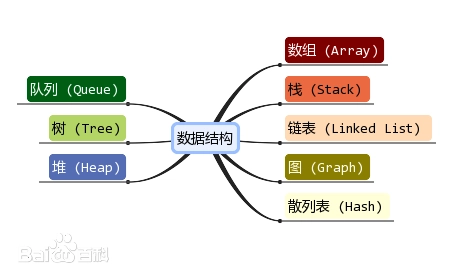
常用的数据结构有:数组、链表、栈、队列、哈希表/散列表、树,堆,图等
八大数据结构的分类表格
序号 | 数据结构名称 | 中文名称 | 特点描述 | 常见操作/应用场景 |
|---|---|---|---|---|
1 | Array | 数组 | 连续内存存储,相同类型元素,通过索引访问 | 随机访问快,插入/删除慢 |
2 | Linked List | 链表 | 由节点组成,节点包含数据和指针,非连续存储 | 插入/删除快,随机访问慢,分单/双/循环链表 |
3 | Stack | 栈 | 后进先出(LIFO),只能在栈顶插入和删除 | push(入栈)、pop(出栈)、peek(查顶) |
4 | Queue | 队列 | 先进先出(FIFO),从队尾入队,队头出队 | enqueue(入队)、dequeue(出队) |
5 | Hash Table | 哈希表/散列表 | 通过哈希函数将键映射到值,实现快速查找 | 查找、插入、删除快,可能有哈希冲突 |
6 | Tree | 树 | 层次结构,由节点和边组成,常见有二叉树、二叉搜索树、堆、Trie、AVL、红黑树等 | 搜索、排序、前/中/后序遍历等 |
7 | Heap | 堆 | 特殊的完全二叉树,分为最大堆和最小堆,常用于优先队列 | 快速获取最值,插入/删除高效 |
8 | Graph | 图 | 由顶点(节点)和边组成,表示多对多关系,有向图/无向图,可带权 | DFS、BFS、最短路径、最小生成树等算法 |
访问、插入/删除、内存占用对比表格
序号 | 数据结构 | 访问速度 | 插入/删除 | 内存占用 |
|---|---|---|---|---|
1 | 数组 | 快(O(1)随机访问) | 慢(O(n)) | 低(仅数据,紧凑) |
2 | 链表 | 慢(O(n)顺序访问) | 快(O(1)已知位置) | 高(含指针开销) |
3 | 栈 | 快(O(1)栈顶访问) | 快(O(1)栈顶操作) | 低至中(依赖实现) |
4 | 队列 | 快(O(1)头尾操作) | 快(O(1)头尾操作) | 低至中(依赖实现) |
5 | 哈希表/散列表 | 快(平均O(1)) | 快(平均O(1)) | 中(含哈希与冲突处理) |
6 | 树 | 中到慢(依赖类型) | 中到慢(依赖类型) | 中(含指针/结构开销) |
7 | 堆 | 快(O(1)获取最值) | 中(O(log n)) | 中(完全二叉树结构) |
8 | 图 | 慢(依赖算法) | 慢(依赖算法) | 中到高(邻接表/矩阵) |
1.数组
一种线性数据结构,由一组相同类型的元素组成,这些元素在内存中连续存储,通过索引(下标)来访问各个元素。
下标从0开始。
特点
- 连续内存分配:数组中的元素在内存中是连续存放的,因此访问速度快。
- 固定大小(静态数组):大多数编程语言中,数组一旦创建,其长度不可更改(除非使用动态数组,如 Python 的 list)。
- 随机访问:可以通过索引直接访问任意位置的元素,时间复杂度为 O(1)。
- 插入/删除效率低:在非末尾位置插入或删除元素时,通常需要移动后续元素,时间复杂度为 O(n)。
- 支持多种类型操作:如遍历、查找、排序等。

常见应用场景
- 存储一组相同类型的数据,如整数列表、字符集合等。
- 实现其他数据结构的基础:如栈、队列、矩阵等常常基于数组实现。
- 数值计算与矩阵运算:如图像处理、科学计算中的二维数组(矩阵)。
- 作为哈希表、堆等数据结构的底层存储。
- 遍历与查找操作:如线性查找、二分查找(要求有序)等。
2.链表
一种线性数据结构,由一系列节点(Node)组成。每个节点包含两部分
- 数据域:存储实际数据;
- 指针域:存储指向下一个节点的引用(地址)。
链表中的节点在内存中不一定是连续存储的,而是通过指针链接起来形成逻辑上的线性序列。
特点
- 非连续存储 节点分散在内存中,通过指针连接,不需要连续内存空间。
- 动态大小 可以随时增加或删除节点,不需要提前固定大小。
- 插入/删除高效 在已知位置插入或删除节点效率高,通常为 O(1)(不含查找时间)。
- 访问效率低 访问某个位置的元素需要从头遍历,时间复杂度为 O(n)。
- 额外空间开销 每个节点需要额外存储指针,占用更多内存。
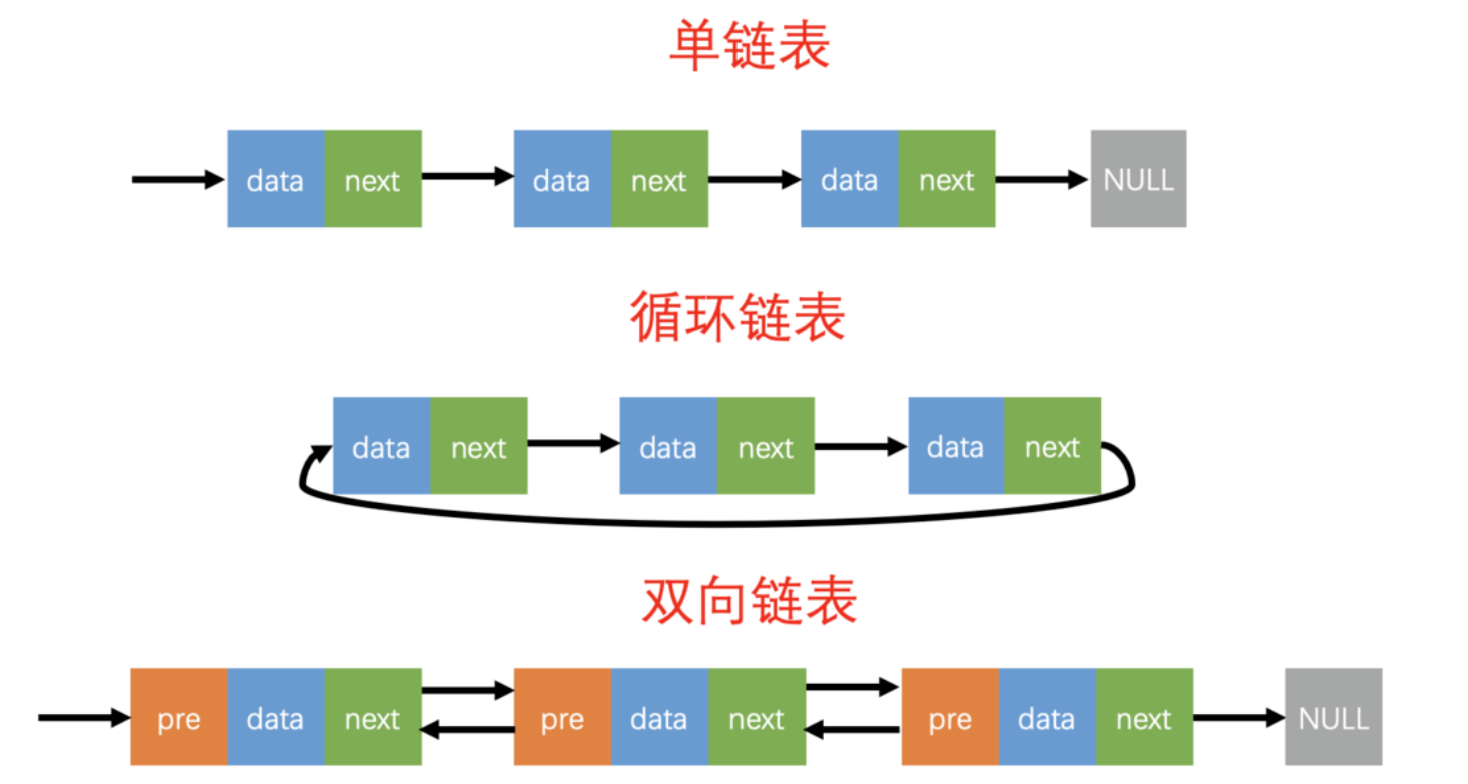
常见类型
1. 单向链表(单链表)
- 每个节点只包含一个指针,指向下一个节点。
- 只能从头节点开始顺序访问。
2. 双向链表(双链表)
- 每个节点包含两个指针:一个指向前一个节点(prev),一个指向后一个节点(next)。
- 支持双向遍历,插入和删除更灵活。
3. 循环链表
- 尾节点的指针不是指向 null,而是指向头节点,形成一个环。
- 可以从任意节点出发遍历整个链表。
应用场景
- 实现队列、栈等动态数据结构(尤其是双端队列);
- 操作系统中的进程调度链表;
- 图的邻接表表示;
- 实现大文件或大数据的分块存储与处理;
- 当数据频繁插入/删除而访问较少时,链表比数组更高效;
3.栈
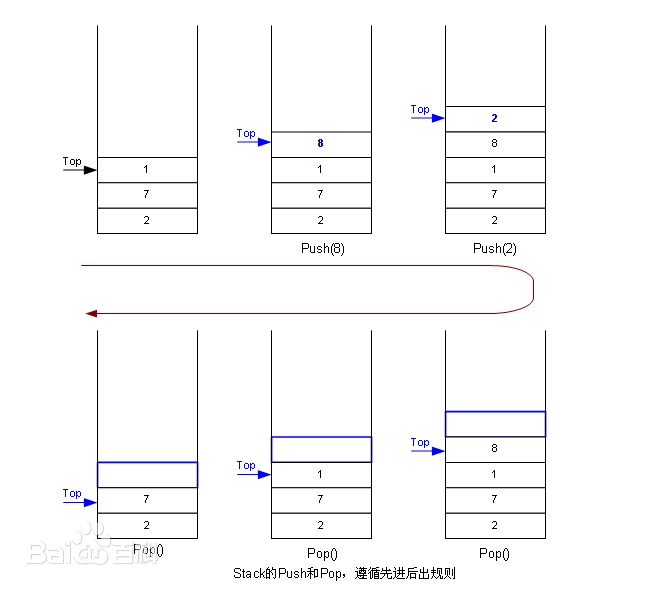
栈是一种后进先出(LIFO,Last In First Out)的线性数据结构,只允许在栈顶(top)进行数据的插入(入栈/push)和删除(出栈/pop)操作,类似于现实生活中的“叠盘子”,最后放上去的盘子总是最先被拿走。
特点
- 后进先出(LIFO):最后入栈的元素最先出栈。
- 仅允许一端操作:数据的插入和删除只能在栈顶进行,另一端称为栈底(bottom)。
- 操作高效:入栈和出栈操作的时间复杂度通常为 O(1)。
- 常基于数组或链表实现。
- 支持获取栈顶元素(peek/top)而不移除它。
常见应用场景
- 函数调用与递归:程序运行时的函数调用栈,保存返回地址和局部变量。
- 表达式求值与括号匹配:如计算算术表达式、检查括号是否成对。
- 撤销(Undo)操作:如文本编辑器中的撤销功能通常基于栈实现。
- 浏览器的前进后退:通过两个栈分别记录前进和后退的历史记录。
- 深度优先搜索(DFS):图或树的遍历算法常用栈来模拟递归过程。
- 表达式转换:如中缀表达式转后缀表达式(逆波兰表达式)。
4.队列
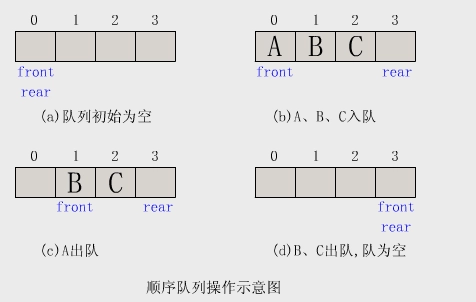
队列是一种先进先出(FIFO,First In First Out)的线性数据结构,数据元素只能从队尾(rear)插入(入队),从队头(front)删除(出队),类似于现实生活中排队的规则,先进入的元素先被处理。
特点
- 先进先出(FIFO):最先插入的元素最先被移除。
- 只能从两端操作:一般只允许在队尾插入,在队头删除。
- 操作高效:入队(enqueue)和出队(dequeue)的时间复杂度通常为 O(1)。
- 常基于数组或链表实现,也可使用循环队列优化空间利用。
常见类型
1. 普通队列(基本队列 / FIFO 队列)
- 最基础的队列,严格遵循先进先出原则,元素从队尾入队,队头出队。
- 只能在队尾插入,在队头删除。
2. 循环队列
- 将普通队列的首尾相连,形成一个环状结构,更高效地利用数组空间。
- 解决了普通数组队列的“假溢出”问题,插入和删除操作仍为 O(1)。
3. 双端队列
- 允许在队列的两端进行插入和删除操作的队列。
- 既可以从队头入队/出队,也可以从队尾入队/出队,灵活性更高。
4. 优先队列
- 不是严格按照 FIFO 原则,而是根据元素的优先级决定出队顺序,优先级高的先出队。
- 通常使用堆(如二叉堆)来实现,常见于任务调度、Dijkstra 算法等场景。
5. 阻塞队列
- 在多线程环境下使用的特殊队列,当队列为空时,出队操作会被阻塞,直到有元素入队;当队列满时,入队操作会被阻塞,直到有空间。
- 常用于生产者-消费者模型,保证线程安全与同步。
6. 并发队列
- 支持多线程并发操作的队列,通常通过锁或无锁算法实现线程安全。
- 适用于高并发场景,如线程池任务队列。
常见应用场景
- 任务调度:操作系统中的进程调度、打印任务队列。
- 消息队列:系统间异步通信,如 RabbitMQ、Kafka 等消息中间件。
- 广度优先搜索(BFS):图或树的层次遍历算法。
- 缓冲区管理:如网络数据包接收、键盘输入缓冲。
- 线程池/请求队列:Web 服务器处理用户请求时的排队机制。
- 撤销/重做功能:部分编辑软件使用队列管理操作历史。
5.哈希表/散列表
散列表(Hash Table,也叫哈希表)是一种通过哈希函数将键(Key)映射到存储位置(桶/槽),从而实现快速数据存取的数据结构。以 键值对(key-value) 的形式存储数据。
特点
- 基于键值对存储:每个数据项都包含一个唯一的键和对应的值。
- 通过哈希函数计算存储位置:将键转换为数组下标,实现快速定位。
- 平均时间复杂度低:在理想情况下,查找、插入、删除操作的时间复杂度为 O(1)。
- 可能发生哈希冲突:不同键可能映射到同一个位置,需要采用冲突解决策略(如链地址法、开放寻址法)。
- 不是有序存储:散列表中的元素一般不按特定顺序排列。
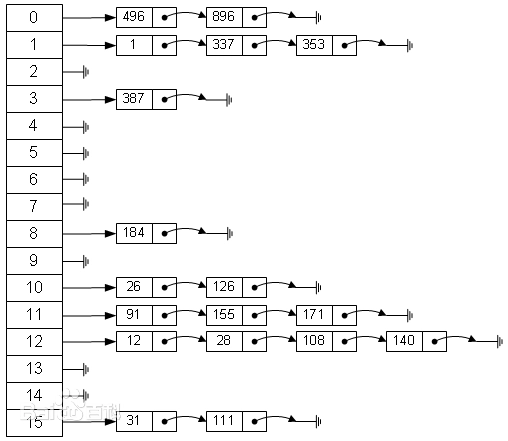
常见类型
1. 链地址法
- 每个哈希桶(bucket)存储一个链表(或其他容器),所有哈希到同一位置的键值对都存放在该链表中。
2. 开放寻址法
- 当发生冲突时,按照某种探测方法(如线性探测、二次探测、双重哈希)寻找下一个可用的空位存放数据。
- 常见探测方式:线性探测、二次探测、双重哈希。
3. 再哈希法
- 使用第二个哈希函数计算步长,以减少聚集现象,属于开放寻址法的一种。
常见应用场景
- 实现字典/映射:如Python 的 dict、Java 的 HashMap
- 缓存系统:Memcached、Redis 的键值存储
- 数据库索引:如哈希索引
- 快速查找表:如编译器中的符号表
- 去重处理:如检测重复元素
- 路由表、缓存淘汰算法:如 LRU 缓存常结合哈希表 + 链表实现
- 用户信息、权限等快速检索系统
6.树
树(Tree) 是一种非线性、层次结构的数据结构,由节点(Node) 和 边(Edge) 组成,用来表示具有层级关系的数据集合。树中有一个特殊的节点叫根节点(Root),其余节点分为多个互不相交的子集,每个子集本身也是一棵树,称为子树(Subtree)。
树中不存在环,且除根节点外,每个节点有且只有一个父节点。
特点
- 根节点(Root):树的顶端节点,没有父节点。
- 叶子节点(Leaf Node):没有子节点的节点,也叫终端节点。
- 内部节点(Internal Node):至少有一个子节点的节点(非叶子节点)。
- 父节点(Parent):一个节点的直接上级节点。
- 子节点(Child):一个节点的直接下级节点。
- 兄弟节点(Sibling):拥有相同父节点的节点。
- 节点的度(Degree):一个节点拥有的子节点的数量。
- 树的度:树中所有节点的度的最大值。
- 深度(Depth):从根节点到某一节点所经过的边的数量(或层数,从0或1开始计数)。
- 高度(Height):从某一节点到最远叶子节点的最长路径上的边数。
- 二叉树(Binary Tree):每个节点最多有两个子节点(左子节点和右子节点)的树。
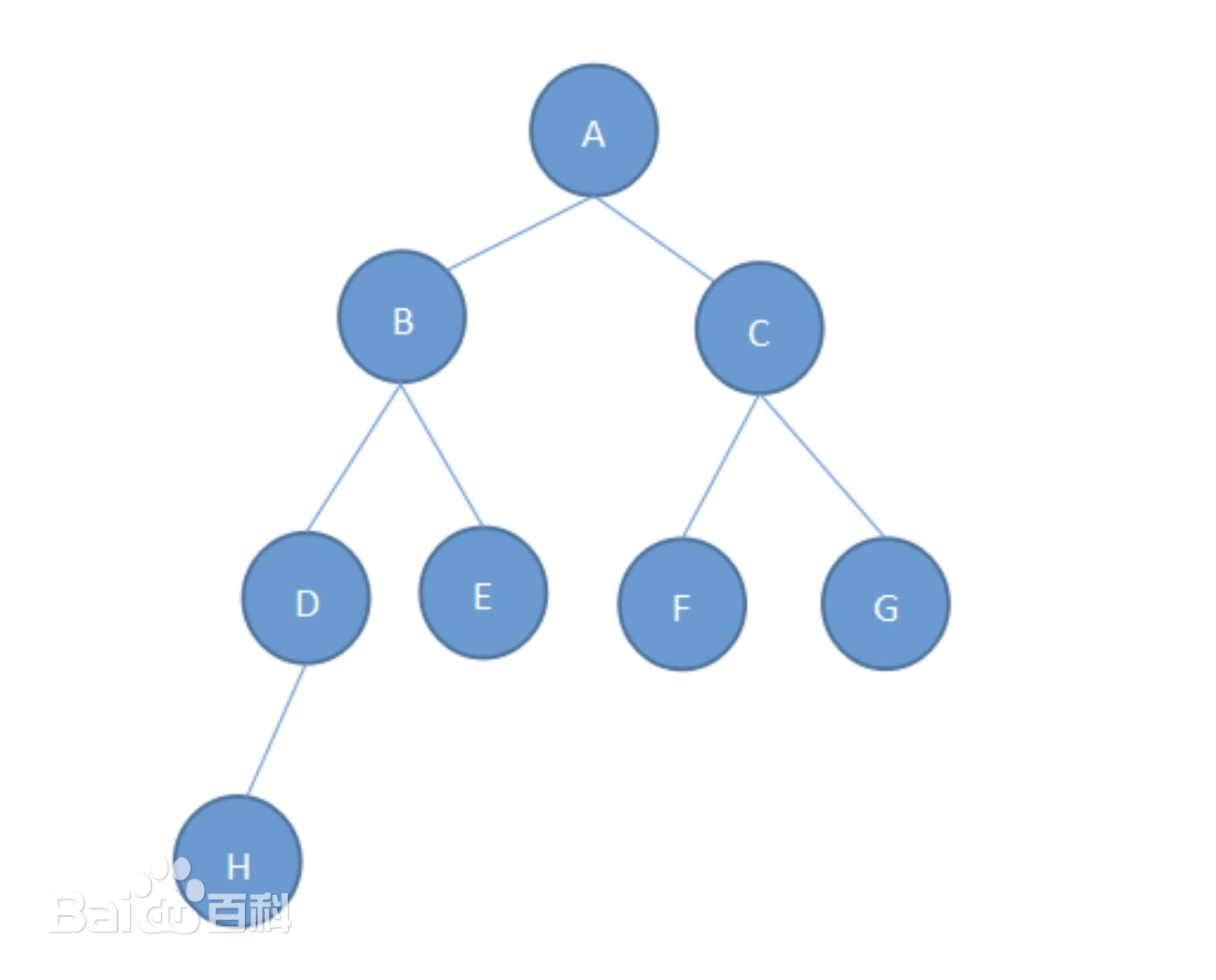
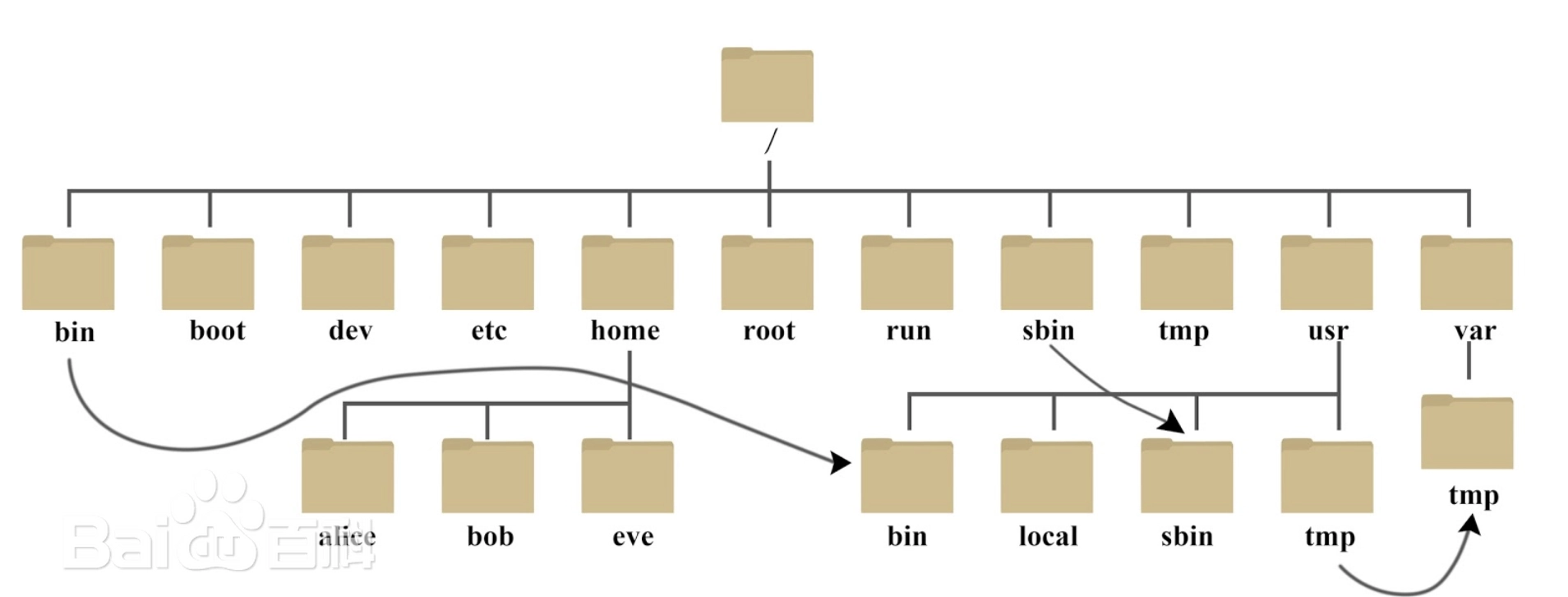
常见类型
1. 普通树(General Tree):每个节点可以有任意多个子节点。
2. 二叉树(Binary Tree):每个节点最多有两个子节点:左孩子和右孩子。
3. 二叉搜索树(Binary Search Tree, BST):
- 左子树上所有节点的值 < 根节点的值
- 右子树上所有节点的值 > 根节点的值
- 左右子树也分别为二叉搜索树
- 支持高效的查找、插入、删除(平均 O(log n))
4. 平衡二叉树(如 AVL 树、红黑树):在二叉搜索树基础上,通过旋转等操作保持左右子树高度平衡,确保操作效率。
5. 满二叉树(Full Binary Tree):每个节点都有 0 或 2 个子节点。
6. 完全二叉树(Complete Binary Tree):除了最后一层,其他层都完全填满,且最后一层节点靠左排列。
7. 堆(Heap):一种特殊的完全二叉树,如最大堆(父节点 ≥ 子节点)和最小堆(父节点 ≤ 子节点),常用于优先队列。
8. B树、B+树:常用于数据库和文件系统索引,适合磁盘存储与查询优化。
常见应用场景
- 文件系统与目录结构:表示文件夹与文件的层级关系。
- 数据库索引:如 B 树、B+ 树用于高效检索与范围查询。
- 搜索算法:如二叉搜索树用于快速查找。
- 表达式解析:如用二叉树表示数学表达式。
- 路由算法、决策树:如 AI 中的决策模型。
- 堆排序、优先队列:利用堆这种特殊树结构。
- 前缀树(Trie):用于字符串检索、自动补全等场景。
7.堆
堆是一种特殊的完全二叉树,并且满足以下性质:
- 在最大堆(Max Heap)中,每个节点的值都大于或等于其子节点的值,因此根节点是最大值。
- 在最小堆(Min Heap)中,每个节点的值都小于或等于其子节点的值,因此根节点是最小值。
堆通常使用数组来实现,因其本质是完全二叉树,可以高效地用数组表示父子节点关系。
特点
- 完全二叉树结构:除了最后一层,其他层都是满的,且最后一层从左到右填充。
- 基于数组存储:通过下标关系快速访问父节点和子节点,无需额外指针。
- 快速访问极值:最大堆的根是最大值,最小堆的根是最小值,访问时间为 O(1)。
- 插入和删除操作高效:插入和删除操作的时间复杂度为 O(log n),因为需要维护堆的性质(通过上浮或下沉调整)。
- 常用于实现优先队列(Priority Queue)。
常见类型
1. 最大堆(Max Heap):父节点的值 ≥ 子节点的值,根节点为最大值。
2. 最小堆(Min Heap):父节点的值 ≤ 子节点的值,根节点为最小值。
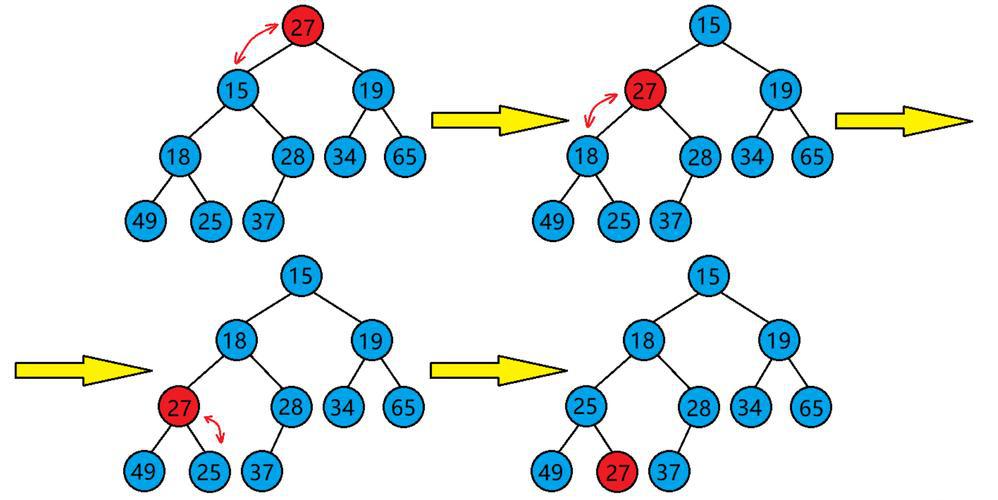
常见应用场景
- 优先队列(Priority Queue):如任务调度系统,优先处理优先级最高的任务。
- 堆排序(Heap Sort):一种基于堆结构的比较排序算法,时间复杂度为 O(n log n)。
- Top K 问题:如“找出最大的 K 个数”或“最小的 K 个数”,常用小顶堆或大顶堆解决。
- Dijkstra 最短路径算法:用最小堆优化寻找当前最短路径的节点。
- 合并多个有序序列(如多路归并)。
- 实时系统中调度最紧急的事件。
8.图
图(Graph) 是由一组顶点(Vertex,或称为节点 Node) 和一组边(Edge) 组成的非线性数据结构,用于表示多对多的关系。
在图中,顶点代表对象,边代表对象之间的关系或连接,边可以是有方向的,也可以是无方向的,还可以带有权重。
特点
- 顶点(Vertex / 节点 Node):图中的基本元素,表示实体或对象。
- 边(Edge):连接两个顶点的线,表示顶点之间的关系。
- 无向图(Undirected Graph):边没有方向,若存在边 (A, B),则 A 与 B 相互连通。
- 有向图(Directed Graph / 有向图 Digraph):边有方向,如箭头从 A 指向 B,表示从 A 到 B 的连接,反向不一定存在。
- 权重(Weight):边可以带有数值,表示两个顶点之间的“代价”、“距离”或“成本”。带权图也叫网络(Network)。
- 度(Degree):在无向图中,一个顶点的度是与之相连的边的数量;在有向图中分为入度(In-degree)和出度(Out-degree)。
- 路径(Path):从一个顶点到另一个顶点经过的边的序列。
- 连通图(Connected Graph)(无向图):任意两个顶点之间都存在路径。
- 强连通图(Strongly Connected Graph)(有向图):任意两个顶点之间都存在双向路径。
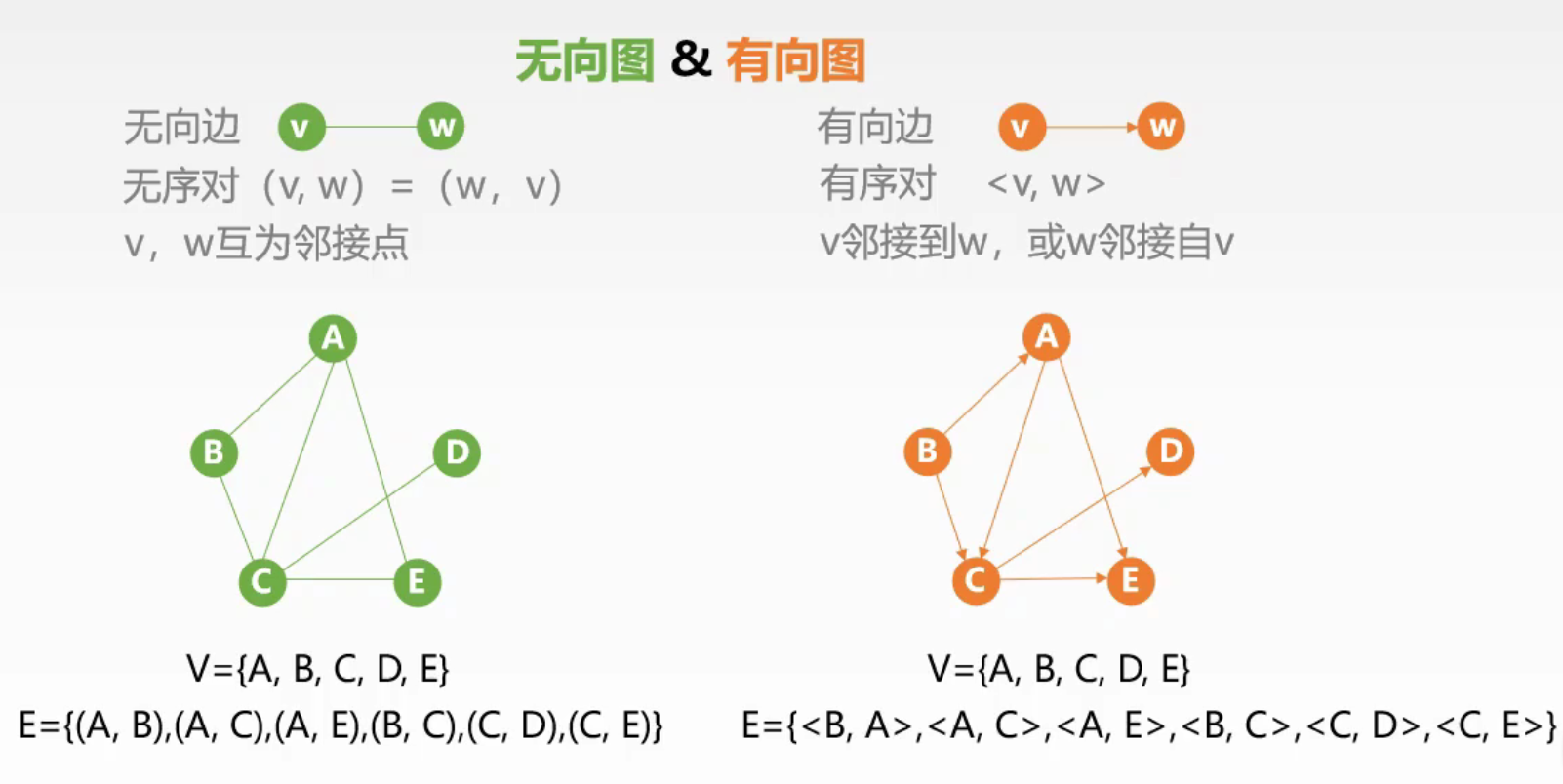
常见类型
1. 无向图(Undirected Graph):边没有方向,如社交网络中的好友关系。
2. 有向图(Directed Graph):边有方向,如网页链接、任务依赖关系。
3. 加权图(Weighted Graph):边带有权重,如地图中的距离、网络中的延迟。
4. 无权图(Unweighted Graph):边没有权重,仅表示连接关系。
5. 稀疏图与稠密图:根据边的数量相对于顶点数的比例区分,边少为稀疏图,边多为稠密图。
6. 有环图与无环图:图中是否存在环(即路径的起点和终点为同一个顶点)。
7. 完全图:任意两个顶点之间都有一条边相连(无向完全图或定向完全图)。
常见应用场景
- 社交网络分析:如用户之间的关注/好友关系(无向图或有向图)。
- 地图与导航系统:顶点表示地点,边表示路线,权重表示距离或时间。
- 网页链接与搜索引擎:如 PageRank 算法基于有向图分析网页重要性。
- 任务调度与依赖管理:如项目任务之间的前后关系(有向无环图 DAG)。
- 网络路由与通信:表示路由器之间的连接与数据传输路径。
- 推荐系统:基于图结构挖掘用户与物品之间的关系。
- 知识图谱:用于表示实体及其之间的关系,如 Google 知识图谱。
- 电路设计、状态机、编译器语法分析等也常用图结构建模。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号