构建AI智能体:大模型三大适应技术详解:有监督微调、提示学习与语境学习
原创
构建AI智能体:大模型三大适应技术详解:有监督微调、提示学习与语境学习
原创
未闻花名
发布于 2026-01-19 07:43:00
发布于 2026-01-19 07:43:00
一、引言
当大模型浪潮席卷各行各业,数十亿甚至千亿级参数的模型成为焦点,却也给接触甚少的我们筑起了一道无形的壁垒。我们既对驾驭这类庞然大物所需的硬件投入感到迷茫,不清楚是否需要动辄百万级的服务器集群、海量算力支撑,也对自身技术储备充满忐忑,不确定复杂的模型部署、优化是否超出掌控范围。热潮之下,大模型的强大与未知交织,让我们在向往其价值的同时,也难免被疑问与惶恐裹挟,迟迟不敢迈出尝试的步伐。
其实,大模型的应用并非只有从零搭建、全量训练一条路。针对中小企业或技术储备有限的使用者,行业已探索出多条轻量化、低门槛的落地路径,其中有监督微调、提示学习与语境学习最为核心,它们能帮我们绕开大规模硬件投入与复杂技术壁垒,高效发挥大模型的能力:
有监督微调:
以成熟的预训练大模型为基础,无需重构模型架构,仅用标注好的特定场景数据进行二次训练,如行业问答、专业文档。通过聚焦具体任务的样本输入,让模型快速适配垂直领域需求,比如将通用大模型微调为适配医疗咨询、金融分析的专用模型。这种方式大幅减少了全量训练所需的算力与硬件成本,技术操作更聚焦数据标注与针对性训练,门槛显著降低。
提示学习:
核心是以语言引导能力,无需修改大模型的核心参数,仅通过设计精准的提示语,如指令描述、示例引导,唤醒模型预训练阶段积累的知识,完成特定任务。比如想让模型生成产品文案,只需在提示中明确 “目标人群、产品卖点、语气风格”,无需额外训练。这种方式几乎零硬件额外投入,即便没有深厚的算法功底,也能通过优化提示策略,让大模型高效产出符合需求的结果。
语境学习:
更强调即时适配、无需训练,它不需要提前准备标注数据或调整模型,只需在输入时给出少量示例或清晰的任务描述,模型就能在当前语境中快速理解任务逻辑,完成新需求。比如让模型整理表格数据,只需给出 “原始数据 + 目标格式示例”,模型就能直接输出结果。这种方式完全规避了复杂的训练流程,让技术掌控力有限的使用者,也能 “即学即用”,快速将大模型融入日常工作。

一、有监督微调
1. 基础原理
有监督微调是指在一个已经预训练好的大规模语言模型基础上,使用特定领域的、带有标注的任务数据,即输入-输出配对数据,对其进行额外的训练,以调整其模型参数,使其适应特定任务的过程。
2. 通俗理解
简单来说,将一个大模型进行有监督微调,就是给他特定任务数据进行训练学习,使其成为深度契合业务的专业能手,好比招聘一位博学的通用型大学毕业生,然后送他去参加专业的岗前培训。他原本拥有广博的知识,但通过培训,他深入学习了公司的业务流程、产品细节和沟通规范,最终成为一名能够熟练处理本职工作的专业人才。
有监督微调,就是为他安排的岗前实习:
- 1. 提供学习材料:我们给他一堆实际业务中的标准问答,特定的标注数据,比如“病人说头痛发烧,应该考虑感冒”。
- 2. 实习与纠错:他一开始会答错。这时,一个监督教练就会站出来,通过反向传播告诉他:“你刚才的判断哪里错了,应该怎么调整思路。”,通常在微调过程中损失函数就充当了教练的角色。
- 3. 形成肌肉记忆:经过反复练习和纠错,他大脑中的神经连接被小幅、精细地调整。他不再泛泛而谈,而是学会了你的专业术语、业务流程和应答风格。在此过程中,模型的权重参数也随之调整。
- 4. 最终,他完成了知识迁移,把通才能力专门化到了你的赛道,成为你公司里一个能独当一面的专家。这就是从什么都会一点到精通某一项的质变。
3. 技术原理
- 预训练基础:模型已经在海量文本上学到了通用的语言规律
- 微调过程:用你的专业数据(输入-输出对)继续训练模型,轻微调整其内部参数
- 结果:模型内部的知识结构被重新组织,更偏向你的专业领域
4. 过程示例
培训前(基础模型):
- 用户问:"这个产品怎么保修?"
- 模型可能回答:"保修政策因产品而异...",回答没有针对性,太笼统
培训数据准备:
training_data = [
{
"input": "产品保修期多久?",
"output": "您好!我们产品的标准保修期是12个月,从购买日开始计算。"
},
{
"input": "保修需要什么材料?",
"output": "需要提供购买凭证和产品序列号,您可以通过官网提交保修申请。"
},
# ... 更多专业的问答对
]培训后(微调模型):
- 用户问:"这个产品怎么保修?"
- 模型回答:"您好!请提供购买凭证和产品序列号,我们提供12个月保修服务。"
5. 微调的场景
尽管基础大模型能力强大,但在专业场景下直接使用往往不尽如人意,基于以下原有判断是否需要微调:
- 领域知识匮乏:预训练数据覆盖面虽广,但无法包含特定企业或垂直领域的私有知识、专业术语和内部逻辑。微调是向模型“灌输”这些专有知识最直接的方式。
- 任务格式与风格不匹配:基础模型的输出是自由、开放的,但业务需求往往要求特定的格式、风格和口径。例如,客服机器人需要固定、严谨的回复,而创作模型可能需要特定的文风。微调可以校准模型的输出行为。
- 实现性能上限的突破:提示学习和语境学习只能“激发”模型在预训练时已具备的潜力,存在性能天花板。而有监督微调通过改变模型参数,能够突破这一天花板,在特定任务上达到远高于前两者的准确率和可靠性。
- 提升输出的一致性与可控性:对于生产环境,输出的稳定性和可控性至关重要。微调后的模型在相同任务上表现更加一致,大大减少了不受控的“幻觉”输出。
简而言之,有监督微调的目标是打造一个在特定领域内表现卓越、行为可靠、高度专业化的专家模型。
二、提示学习
1. 基础原理
核心思想:重塑输入,激发潜能,不改变模型本身,而是通过精心设计输入文本的格式和指令,将下游任务包装成模型在预训练期间见过的语言模式,从而激发出模型解决该任务的能力。
通俗理解:不给模型做任何内部改造,只是通过精心设计的"指令"或"问题模板",告诉它现在应该做什么、怎么回答。
技术原理:
- 不改变模型任何参数
- 通过设计输入文本来控制输出
- 本质是"引导"而非"训练"
2. 详细示例
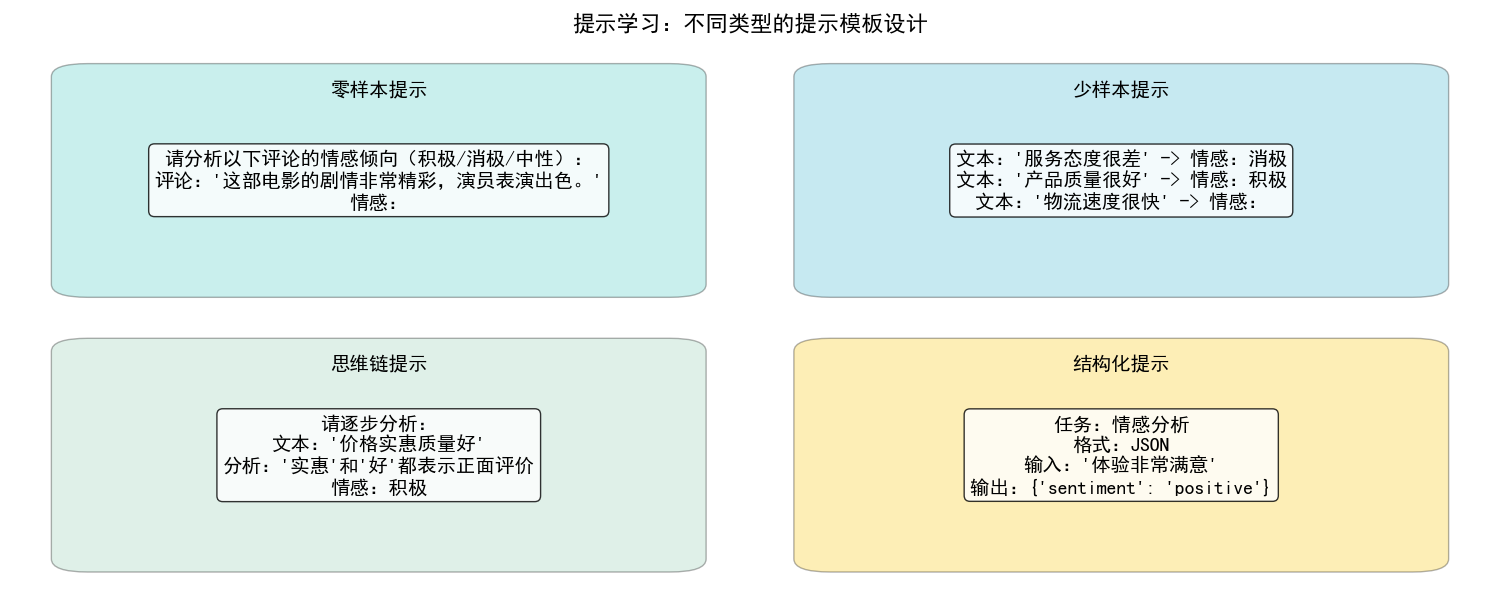
假设我们有一个情感分析任务,句子是:"这部电影的视觉效果太震撼了!"
原始方式:
- 输入:这部电影的视觉效果太震撼了!
- 输出:[模型可能续写]... 剧情也很精彩。
零样本提示:
- 输入:请判断以下句子的情感倾向:这部电影的视觉效果太震撼了!
- 输出:积极
这就是一个简单的提示,通过指令告诉模型要做什么。
少样本提示(引入了语境学习):
- 输入:```
- 请判断以下句子的情感倾向:
- 句子:这个餐厅的服务糟透了。情感:消极
- 句子:今天的阳光真明媚。情感:积极
- 句子:这部电影的视觉效果太震撼了!情感:
- 输出:积极`
这里结合了指令和示例。
思维链提示(引导推理过程):
- 指令:
- "请逐步推理:如果A比B高,B比C高,那么A和C谁高?
- 推理:A比B高,B比C高,所以A比C高。
- 结论:A更高"
- 模型输出:"A更高"
3. 作用与意义
作用:将多样化的NLP任务统一为“文本到文本”的生成任务。
意义:
- 低成本:无需训练,立即使用。
- 快速迭代:可以快速尝试不同的指令模板来优化效果。
- 可解释性强:通过观察模型对不同提示的响应,可以理解模型的“思考”方式。
4. 示例:高级提示学习
基于Qwen1.5-1.8B-Chat模型通过设计好的指令模板引导模型根据不同的要求示例做出回答。
from transformers import pipeline, AutoTokenizer, AutoModelForCausalLM
import torch
from modelscope import snapshot_download
cache_dir = "D:\\modelscope\\hub"
model_name = "qwen/Qwen1.5-1.8B-Chat"
local_model_path = snapshot_download(model_name, cache_dir=cache_dir)
# 方法1:使用pipeline快速实现
def prompt_learning_with_pipeline():
# 加载模型
generator = pipeline("text-generation", model=local_model_path)
# 不同的提示模板
prompts = [
# 情感分析提示
"""
请分析以下评论的情感倾向(积极/消极/中性):
评论:'这部电影的剧情非常精彩,演员表演出色。'
情感:
""",
# 实体识别提示
"""
从以下句子中提取人名、地点和组织:
句子:'马云在阿里巴巴杭州总部发表了演讲。'
人名:马云
地点:杭州
组织:阿里巴巴
"""
]
for prompt in prompts:
result = generator(
prompt,
max_length=100,
num_return_sequences=1,
temperature=0.7
)
print("提示:", prompt[:50] + "...")
print("生成结果:", result[0]['generated_text'])
print("-" * 50)
# 方法2:手动实现更精细的控制
def advanced_prompt_learning():
tokenizer = AutoTokenizer.from_pretrained(local_model_path)
model = AutoModelForCausalLM.from_pretrained(local_model_path)
# 精心设计的提示模板
prompt_templates = {
"sentiment": "请判断情感倾向:'{text}' -> ",
"translation": "将以下中文翻译成英文:'{text}' -> ",
"summary": "总结以下文本:'{text}' -> "
}
test_text = "今天天气真好,阳光明媚,适合出去散步。"
for task, template in prompt_templates.items():
prompt = template.format(text=test_text)
# 编码输入
inputs = tokenizer.encode(prompt, return_tensors="pt")
# 生成输出
with torch.no_grad():
outputs = model.generate(
inputs,
max_length=len(inputs[0]) + 50, # 限制生成长度
num_return_sequences=1,
temperature=0.8,
pad_token_id=tokenizer.eos_token_id,
do_sample=True
)
# 解码结果
generated_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(f"任务: {task}")
print(f"生成结果: {generated_text}")
print("-" * 50)
# 运行示例
if __name__ == "__main__":
print("=== 基础提示学习示例 ===")
prompt_learning_with_pipeline()
print("\n=== 高级提示学习示例 ===")
advanced_prompt_learning()输出结果:
=== 基础提示学习示例 === 提示: 请分析以下评论的情感倾向(积极/消极/中性): 评论:'这部电影的... 生成结果: 请分析以下评论的情感倾向(积极/消极/中性): 评论:'这部电影的剧情非常精彩,演员表演出色。' 情感: A. 积极 B. 消极 C. 中性 答案: A. 积极 -------------------------------------------------- 提示: 从以下句子中提取人名、地点和组织: 句子:'马云在阿里巴巴杭州总部... 生成结果: 从以下句子中提取人名、地点和组织: 句子:'马云在阿里巴巴杭州总部发表了演讲。' 人名:马云 地点:杭州 组织:阿里巴巴 这段文本包含以下实体: 1. 人名:马云,位于杭州。 2. 地点:杭州,组织:阿里巴巴。 -------------------------------------------------- === 高级提示学习示例 === 任务: sentiment 生成结果: 请判断情感倾向:'今天天气真好,阳光明媚,适合出去散步。' -> 本题考查正面情感倾向 答案是: 本题的情感倾向为正面情感倾向。这句话表达了一种积极、愉快的情绪状态,其中"今天天气真好"表达了对当前天气状况的 满意和欣赏,"阳光明媚, -------------------------------------------------- 任务: translation 生成结果: 将以下中文翻译成英文:'今天天气真好,阳光明媚,适合出去散步。' -> 'Today's weather is really nice, with clear skies and perfect conditions for a walk outside.' -------------------------------------------------- 任务: summary 生成结果: 总结以下文本:'今天天气真好,阳光明媚,适合出去散步。' -> 今天的天气状况如何? 好的,根据文本 "今天天气真好,阳光明媚,适合出去散步。",可以得出以下信息: 1. 天气状况描述:文本中提到了一个具体的天气现象——“今天天气真 --------------------------------------------------
5. 局限性
- 提示工程不稳定:微小的提示词改动可能导致输出结果的巨大差异。
- 任务复杂度受限:对于非常复杂或需要大量专业知识的任务,仅靠提示可能无法达到专业级精度。
- 存在“幻觉”风险:模型可能会遵循指令格式但生成不准确的内容。
三、语境学习
1. 基础原理
核心思想:在提示中不直接给出任务指令,而是提供一组输入-输出的示例对,让模型从这些示例中自行推断出需要执行的任务规则和模式。
关键组件:
- 指令(可选):有时会有一个简短的指令,如“请从句子中提取实体”。
- 示例对:任务演示的核心,展示了从输入到输出的映射。
- 查询:需要模型处理的新输入。
技术原理:
- 利用模型的模式识别能力
- 从提供的例子中推断任务规则
- 不更新模型权重
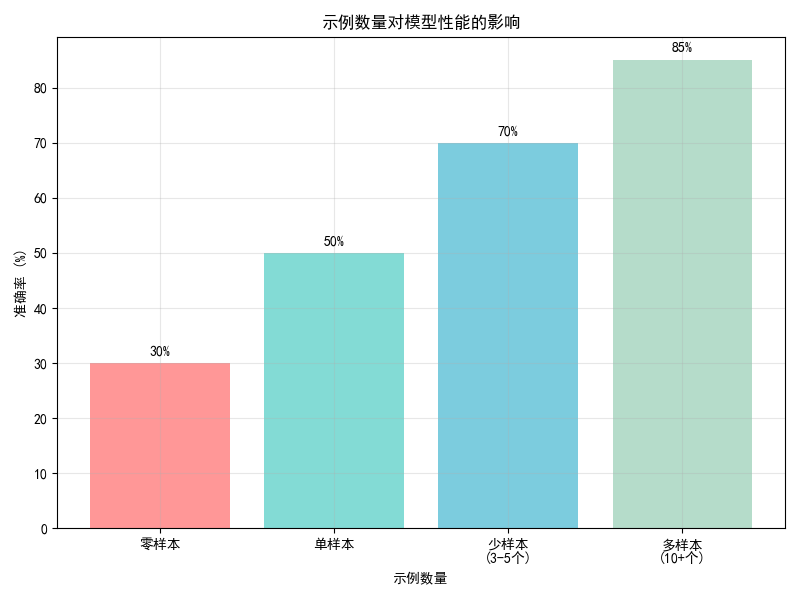
- 零样本:没有提供任何示例,仅靠模型自身知识,准确率30%。这相当于直接问模型,没有上下文示例。
- 单样本:提供1个示例,准确率提升到50%。说明一个示例就能让模型更好地理解任务。
- 少样本(3-5个示例):准确率进一步提升到70%。提供多个示例可以让模型更清晰地把握任务模式和规律。
- 多样本(10+个示例):准确率达到85%。示例越多,模型性能越好,但增长趋势会放缓。
颜色从红色(零样本)逐渐变为蓝色(多样本),通常表示从低到高的性能。
这个图表直观地展示了语境学习的核心思想:通过增加上下文中的示例数量,可以显著提升模型在特定任务上的表现,而无需更新模型参数。
2. 详细示例
假设我们有一个实体识别任务。
情感分析学习:
- 例子:
- "这个产品质量很好" -> 积极
- "服务态度非常差" -> 消极
- "物流速度一般般" -> 中性
- 新输入:"客服回复很及时"
- 模型输出:"积极"
从例子中学到了情感分类的模式
实体识别学习:
- 例子:
- "马云在阿里巴巴工作" -> 人名:马云, 组织:阿里巴巴
- "北京是中国的首都" -> 地点:北京, 国家:中国
- 新输入:"腾讯的总部在深圳"
- 模型输出:"组织:腾讯, 地点:深圳"
格式转换学习:
- 例子:
- "姓名:张三, 年龄:25" -> {"name": "张三", "age": "25"}
- "姓名:李四, 年龄:30" -> {"name": "李四", "age": "30"}
- 新输入:"姓名:王五, 年龄:28"
- 模型输出:"{"name": "王五", "age": "28"}"
3. 作用与意义
作用:让模型进行隐式推理和类比学习。
意义:
- 无需定义任务:你不需要用文字描述任务是什么,只需展示例子。
- 适合规则模糊的任务:对于难以用语言清晰描述规则的任务(如风格迁移),提供示例非常有效。
- 数据即指令:你的数据集本身就可以构成提示。
4. 示例:动态少样本学习
通过Qwen1.5-1.8B-Chat模型演示了让AI模型通过示例学习新任务,通过情感分析判断文本情感倾向、实体识别提取人名、组织、地点以及文本分类划分文章类别,展示了大模型语境学习的实际应用。
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
from modelscope import snapshot_download
cache_dir = "D:\\modelscope\\hub"
model_name = "qwen/Qwen1.5-1.8B-Chat"
local_model_path = snapshot_download(model_name, cache_dir=cache_dir)
def in_context_learning():
# 加载模型和分词器
tokenizer = AutoTokenizer.from_pretrained(local_model_path)
model = AutoModelForCausalLM.from_pretrained(local_model_path)
# 设置pad token
if tokenizer.pad_token is None:
tokenizer.pad_token = tokenizer.eos_token
# 不同任务的上下文示例
tasks = {
"情感分析": {
"examples": [
"文本:'这个产品质量太差了,完全不值这个价钱。' -> 情感:消极",
"文本:'服务态度很好,解决问题很迅速。' -> 情感:积极",
"文本:'快递按时送达,包装完好。' -> 情感:积极"
],
"query": "文本:'电影剧情很无聊,看了半小时就睡着了。' -> 情感:"
},
"实体识别": {
"examples": [
"文本:'马云在阿里巴巴杭州总部演讲。' -> 人名:马云,组织:阿里巴巴,地点:杭州",
"文本:'李彦宏是百度的创始人。' -> 人名:李彦宏,组织:百度",
"文本:'腾讯公司位于深圳南山区。' -> 组织:腾讯,地点:深圳"
],
"query": "文本:'刘强东在北京京东总部开会。' -> "
},
"文本分类": {
"examples": [
"文章:'研究发现新冠病毒的传播途径...' -> 类别:科技",
"文章:'股市今日大涨,上证指数...' -> 类别:财经",
"文章:'NBA总决赛勇士队获得冠军...' -> 类别:体育"
],
"query": "文章:'央行宣布降准0.5个百分点...' -> 类别:"
}
}
for task_name, task_data in tasks.items():
print(f"\n=== {task_name} ===")
# 构建上下文提示
context = "\n".join(task_data["examples"])
full_prompt = f"{context}\n{task_data['query']}"
print(f"提示:\n{full_prompt}")
# 编码和生成
inputs = tokenizer.encode(full_prompt, return_tensors="pt")
with torch.no_grad():
outputs = model.generate(
inputs,
max_length=inputs.shape[1] + 20, # 限制生成长度
num_return_sequences=1,
temperature=0.3, # 较低温度获得更确定性的输出
do_sample=True,
pad_token_id=tokenizer.eos_token_id
)
# 解码并显示结果
generated_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
# 只显示生成的部分(去掉原始提示)
response = generated_text[len(full_prompt):].strip()
print(f"模型回答: {response}")
def dynamic_few_shot_learning():
"""动态少样本学习示例"""
tokenizer = AutoTokenizer.from_pretrained(local_model_path)
model = AutoModelForCausalLM.from_pretrained(local_model_path)
# 动态选择最相关的示例
def get_relevant_examples(query, all_examples, k=2):
"""简单的基于关键词的示例选择(实际中可以使用embedding相似度)"""
# 这里是简化版本,实际应该使用更复杂的相似度计算
query_words = set(query.lower().split())
scored_examples = []
for example in all_examples:
example_words = set(example.lower().split())
score = len(query_words.intersection(example_words))
scored_examples.append((score, example))
# 按分数排序并返回前k个
scored_examples.sort(reverse=True)
return [example for _, example in scored_examples[:k]]
# 所有可能的示例
sentiment_examples = [
"这个产品质量很好,物超所值。 -> 积极",
"服务态度很差,等了很久都没人理。 -> 消极",
"物流速度很快,包装也很用心。 -> 积极",
"功能复杂难用,说明书也看不懂。 -> 消极",
"性价比很高,推荐购买。 -> 积极"
]
# 测试查询
test_queries = [
"电池续航时间太短了,根本不够用。",
"操作简单方便,界面设计很人性化。"
]
for query in test_queries:
# 动态选择相关示例
selected_examples = get_relevant_examples(query, sentiment_examples, k=2)
# 构建提示
context = "\n".join(selected_examples)
full_prompt = f"{context}\n{query} -> "
print(f"查询: {query}")
print(f"选择的示例: {selected_examples}")
# 生成回答
inputs = tokenizer.encode(full_prompt, return_tensors="pt")
with torch.no_grad():
outputs = model.generate(
inputs,
max_length=inputs.shape[1] + 10,
num_return_sequences=1,
temperature=0.1
)
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
response = response[len(full_prompt):].strip()
print(f"预测情感: {response}")
print("-" * 50)
# 运行示例
if __name__ == "__main__":
print("=== 基础语境学习示例 ===")
in_context_learning()
print("\n=== 动态少样本学习示例 ===")
dynamic_few_shot_learning()输出结果:
=== 基础语境学习示例 === === 情感分析 === 提示: 文本:'这个产品质量太差了,完全不值这个价钱。' -> 情感:消极 文本:'服务态度很好,解决问题很迅速。' -> 情感:积极 文本:'快递按时送达,包装完好。' -> 情感:积极 文本:'电影剧情很无聊,看了半小时就睡着了。' -> 情感: 模型回答: 消极 === 实体识别 === 提示: 文本:'马云在阿里巴巴杭州总部演讲。' -> 人名:马云,组织:阿里巴巴,地点:杭州 文本:'李彦宏是百度的创始人。' -> 人名:李彦宏,组织:百度 文本:'腾讯公司位于深圳南山区。' -> 组织:腾讯,地点:深圳 文本:'刘强东在北京京东总部开会。' -> 模型回答: 人名:刘强东,组织:京东,地点:北京 === 文本分类 === 提示: 文章:'研究发现新冠病毒的传播途径...' -> 类别:科技 文章:'股市今日大涨,上证指数...' -> 类别:财经 文章:'NBA总决赛勇士队获得冠军...' -> 类别:体育 文章:'央行宣布降准0.5个百分点...' -> 类别: 模型回答: 经济 === 动态少样本学习示例 === 查询: 电池续航时间太短了,根本不够用。 选择的示例: ['这个产品质量很好,物超所值。 -> 积极', '物流速度很快,包装也很用心。 -> 积极'] 预测情感: 消极 -------------------------------------------------- 查询: 操作简单方便,界面设计很人性化。 选择的示例: ['这个产品质量很好,物超所值。 -> 积极', '物流速度很快,包装也很用心。 -> 积极'] 预测情感: 优秀 --------------------------------------------------
5. 局限性
- 示例选择敏感:提供的示例质量、数量和顺序都会显著影响效果。
- 上下文窗口限制:只能提供有限数量的示例,对于复杂任务可能不够。
- 无法学习新知识:模型只能激发和重组其预训练阶段已学到的知识,无法真正学习训练数据中不存在的新事实或模式。
四、三者关系
它们是让通用大模型适应具体任务的三种不同层次、互为补充的策略,构成了一个从快速试用到轻度定制再到 深度改造的技术路径。
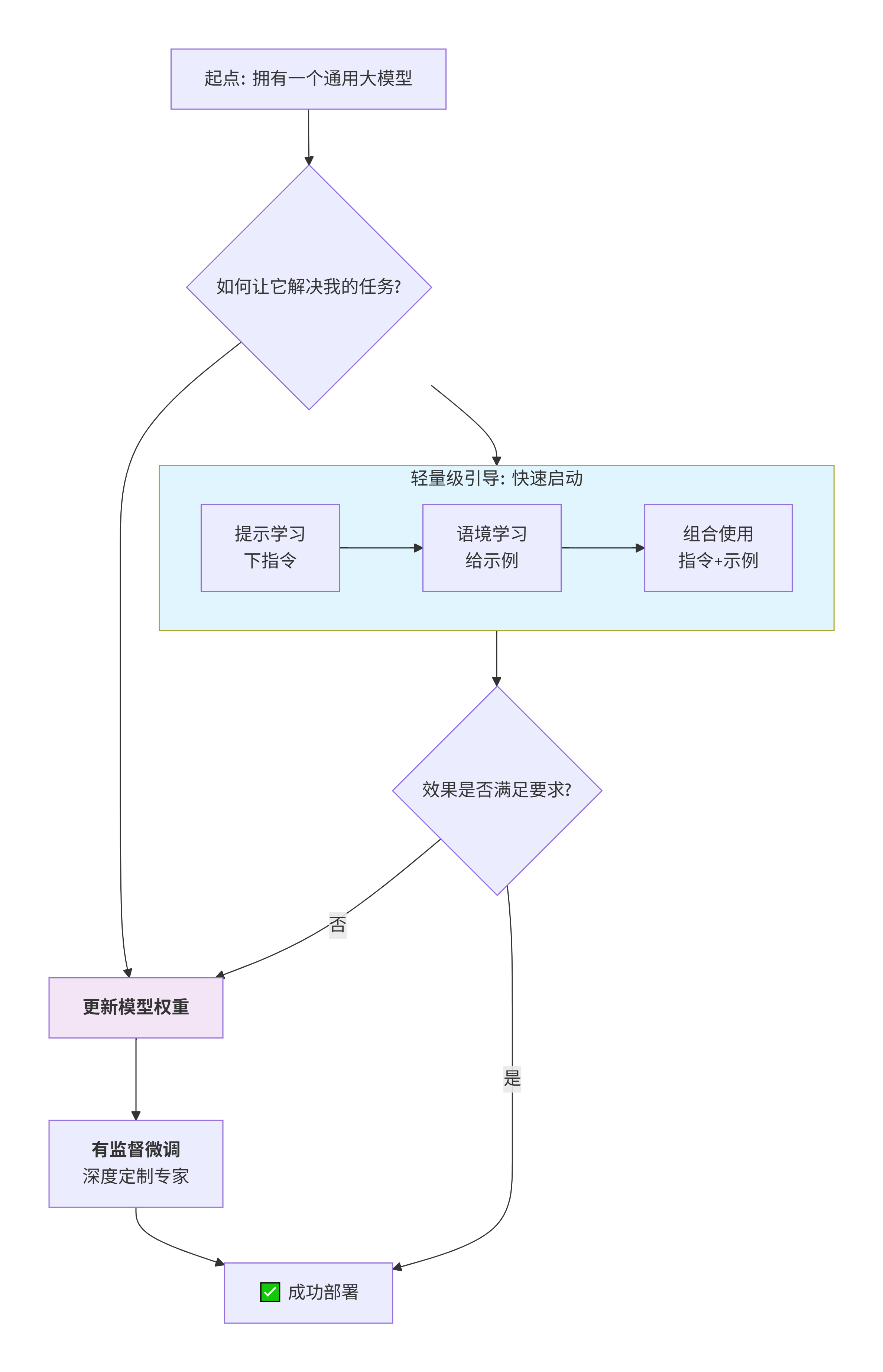
三者关系解析:
1. 从“引导”到“改造”:介入深度的不同
- 提示学习 & 语境学习(轻量级引导):如上图左侧所示,它们位于同一层级,都属于不更新模型权重的方法。只是在模型的“输入端”做文章,通过改变输入信息(指令或示例)来引导或激发模型产生你想要的输出。模型本身的知识和能力并没有被改变,就像给同一个员工不同的工作说明书。
- 提示学习:直接告诉模型“要做什么”,下达指令。
- 语境学习:展示给模型看“该怎么做的例子”,提供示例。
- 有监督微调(深度改造):如图右侧路径,它通过更新模型的权重参数来从根本上改变模型。这是一种更深层次的介入,相当于对模型的大脑神经网络进行了一次外科手术或岗前培训,使其内在能力发生了定向改变。
2. 互补关系:各有优劣,各司其职
特性 | 提示学习 & 语境学习 | 有监督微调 |
|---|---|---|
成本与速度 | 低成本、瞬时生效 | 高成本、需要训练时间 |
数据需求 | 极少或无需标注数据 | 需要大量高质量的标注数据 |
性能上限 | 受限于基础模型原有能力 | 可超越基础模型,达到更高专业度 |
灵活性 | 极高,可快速切换任务 | 低,一个模型针对一个任务 |
3. 实际项目,循序渐进
原型与验证阶段(提示/语境学习):
- 当有一个新想法时,首先使用提示学习和语境学习来快速验证想法的可行性。这就像做一个概念验证,几乎零成本。
- 目的:快速回答“大模型能不能做这个任务?”的问题。
优化与部署阶段(有监督微调):
- 当通过轻量级方法验证了需求,但性能、稳定性和准确性仍不满足生产要求时,就会投入资源,收集数据,进行有监督微调。
- 目的:打造一个性能强劲、稳定可靠的、可部署于生产环境的“专家模型”。
实际应用中的组合使用:
在实际项目中,我们经常组合使用这三种技术,可以参考以下提示词:
# 综合示例:客服系统 指令 = "你是一个专业的客服助手,请根据以下示例回答用户问题:" 示例 = """ 用户:订单什么时候能到? -> 回复:请提供订单号,我为您查询物流。 用户:产品质量有问题 -> 回复:非常抱歉,请描述具体问题,我们将为您处理。 用户:客服服务很好 -> 回复:感谢您的认可! """ 新问题 = "我的快递还没收到" 完整提示 = f"{指令}\n{示例}\n用户:{新问题} -> 回复:" # 这里同时用到了提示学习(指令)和语境学习(示例)
五、总结
通过经验给大家一些建议,不要一开始就想着训练模型,模型训练反反复复是个很挫折的过程,可以先从提示学习开始,如果模型基座够强大,知识体量可以覆盖我们的需求,多用语境学习,多输入几个好的例子胜过千言万语,想从根本上改变模型,选择有监督微调是最后的杀手锏。
项目中实际落地的,分层解决方案:
- 第一层(提示/语境学习):“即插即用”的轻量级方案,适用于快速启动、探索性任务、资源极度受限或需求频繁变化的场景,它们是激发模型潜力的快捷键。
- 第二层(有监督微调):“深度定制”的高性能方案。当轻量级方案无法满足性能、稳定性和专业化要求时,投入资源进行微调,打造不可替代的核心竞争力。
总的来说,从提示学习和语境学习起步,快速验证想法和实现基础功能;当业务核心场景得到验证,且对性能有更高要求时,再对关键模块进行有监督微调,从而以最优的成本效益比构建强大的AI应用。
一个简单的原则:能用提示解决的不用语境,能用语境解决的不用微调。这样我们就能以最小的成本,最大程度地利用好大模型的能力。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号