CPU爆满,IO躺平:一次数据库迁移引发的“血案”
原创
CPU爆满,IO躺平:一次数据库迁移引发的“血案”
原创
薛晓刚-
发布于 2026-01-15 21:55:44
发布于 2026-01-15 21:55:44
许多开发者在数据库选型和使用时,往往并不清楚为何选择某一种数据库,以及它在特定场景下的真正能力。例如,何时使用 ElasticSearch、ClickHouse、Redis、MongoDB 或 MySQL,常常缺乏清晰的判断。这种模糊的认知可能为系统埋下隐患。本次分享的案例正是由于对 MongoDB 使用不当而导致的问题。
问题现象
用户反馈 MongoDB 负载异常,从系统监控可见 CPU 使用率几乎满载,而通过 sar命令查看,磁盘 I/O 负载并不高。
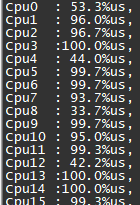
image.png
- 但是从sar看到的io没什么负载。
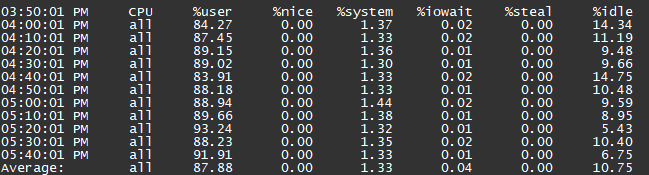
image.png
初步分析
通过一系列命令排查,最终发现问题根源是 MongoDB 中运行的大量查询耗时过长,许多查询执行时间达到 20-50 秒级别。
令人困惑的是,该数据库近期并未经历大的变更,业务量也未显著上涨,为何会突然出现性能恶化?

image.png
进一步观察发现,在 CPU 负载升高前后,系统唯一的变化是数据库被迁移至信创环境(操作系统与处理器架构发生变化),而数据、查询模式等均未调整。
因此,在撰写本文时,我仍无法完全确定,是否是信创环境对查询指令的处理机制存在差异。该假设目前难以直接验证。
查询语句分析
从慢查询日志中,发现大量查询具有共同特征: 大范围数据检索并排序,这与 CPU 高负载的表现高度吻合。
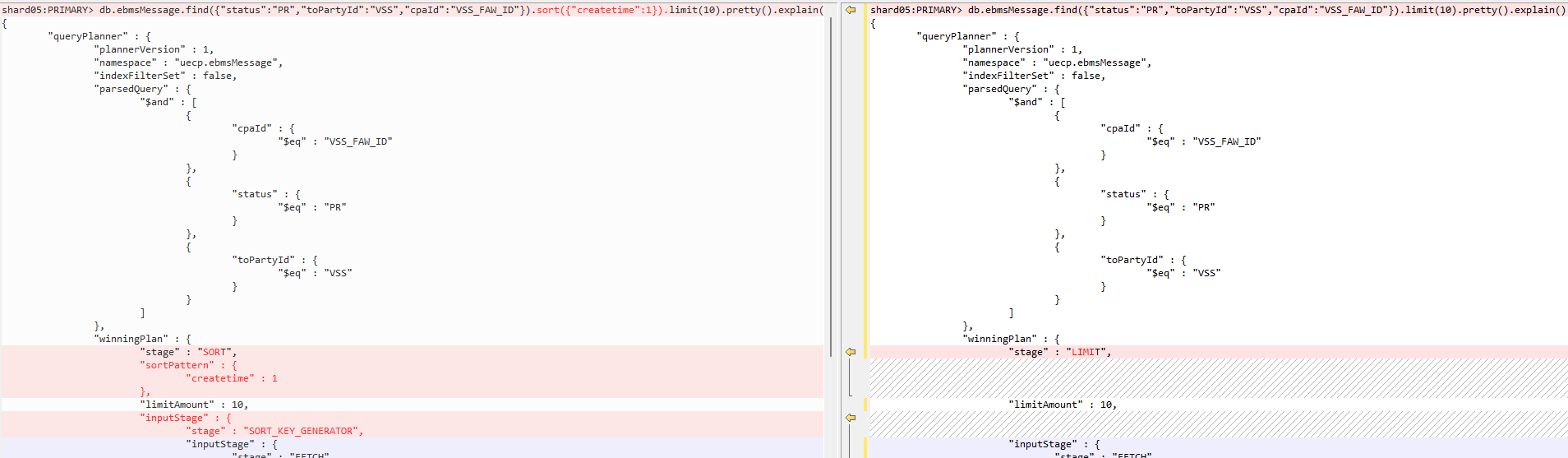
image.png
对比有无排序的执行计划,发现二者差异显著。这让我联想到在 MySQL 中类似的情况:当查询需要读取大量数据,并按某个未在查询条件中的列(例如主键或某个索引列)排序时,优化器可能会选择基于该列执行,从而导致性能下降。
查询逻辑的常见误区
实际上,这类查询语句在逻辑上往往存在问题。开发人员常未能意识到,数据库检索的语义与实际业务需求并不完全对等。
例如,某个查询条件为“时间小于 10 分钟前”,本意是每 10 分钟轮询一次新增数据。然而,开发者未考虑到“1900 年”同样满足“小于 10 分钟前”这一条件。正确的逻辑应该是查询“从上一次轮询时间点到当前时刻”的新数据。
类似逻辑缺陷在各行业、各类数据库中屡见不鲜,已从传统关系型数据库蔓延到 NoSQL 系统中。如果缺乏对查询质量的关注,这类问题很难在开发阶段被发现。
临时解决方案
鉴于无法立即从根本上重构查询逻辑,我们采取了折中方案:新建一个集合,仅将近期数据迁移至其中,从而大幅减少排序操作涉及的数据量,缓解查询压力。
小结
本次问题的根本原因在于:
- 对数据库适用场景理解不足;
- 索引设计未能支撑实际查询模式;
- 查询语句存在逻辑缺陷,导致扫描数据范围过大。
从临时措施(新建集合、迁移近期数据)的效果来看,系统压力已暂时缓解。这也说明, 问题与信创环境并无必然关联,反而印证了:只要避免大范围数据扫描和排序,即使在信创环境下,MongoDB 仍可稳定运行。
反思
数据库选型与使用是一门需要持续积累的学问。明确各类数据库的优势场景、设计合理的索引、编写高效的查询语句,是保障系统稳定性的基础。在技术架构快速演进的今天,这一点尤其值得每一位开发者重视。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号