Spring AI系列之什么是大模型

Spring AI系列之什么是大模型

SmileNicky
发布于 2026-01-15 14:27:38
发布于 2026-01-15 14:27:38
Spring AI系列:深入解析大语言模型(LLM)核心知识体系
在人工智能飞速发展的今天,大语言模型(LLM)已成为驱动各类智能应用的核心引擎。从日常AI助手到复杂科研创新,LLM正在重塑我们的工作与生活。本文基于最新行业动态和技术实践,从基础概念、主流产品、分类体系、核心技术趋势到实战入门,为你全面构建LLM的知识框架。
一、什么是大语言模型(LLM)?
1.1 核心定义
大语言模型(Large Language Model, LLM) 是基于深度学习和自然语言处理技术构建的先进AI系统。其核心工作原理是通过海量文本数据的预训练,学习人类语言的本质规律——这类似于人类的系统性学习过程:从小学到大学,逐步掌握语言结构、知识体系和逻辑推理能力。
LLM就像一个"超级数字大脑",具备三大核心能力:
- 语言理解:准确解析用户意图,理解复杂语境
- 语言生成:生成连贯、符合语境的高质量文本
- 任务泛化:通过少量示例或指令完成翻译、编程、创作等多样化任务
1.2 技术本质
现代LLM主要基于Transformer架构,通过自注意力机制(Self-Attention)捕捉文本中的长距离依赖关系。参数规模从数十亿到数万亿不等,训练数据覆盖互联网级语料库,使其具备了惊人的涌现能力(Emergent Abilities)。
二、主流大模型产品全景图
当前全球LLM市场已形成"通用+垂直"的产品矩阵,国内外厂商竞相推出创新产品。
2.1 国际主流产品矩阵
产品系列 | 研发公司 | 核心亮点 | 适用场景 | 上下文窗口 |
|---|---|---|---|---|
GPT-4o / GPT-4 Turbo | OpenAI | 全模态交互(文本/图像/视频/音频),128K上下文,推理成本降低30% | 科研实验、创意产业 | 128K |
Gemini 2.0 Pro | 实时搜索集成,20+语言无缝切换,<500ms响应延迟 | 教育个性化、企业服务 | 1M+ | |
Claude 3系列· Opus· Sonnet· Haiku | Anthropic | Opus支持200K+上下文,Sonnet平衡性能成本,Haiku轻量高速伦理审查误判率<0.1% | 法律合同审查、医疗合规报告 | 200K |
Microsoft Copilot | Microsoft | 深度集成Office生态,基于GPT-4/Phi-3双引擎 | 办公协同、代码生成 | 128K |
xAI Grok-1.5 | xAI | 实时X平台数据访问,幽默感和时事洞察力强 | 实时资讯问答、日常交互 | 128K |
Inflection-2 | Inflection AI | 情感计算优化,人设一致性突出 | 智能助手、情感陪伴 | 未知 |
2.2 国内主流产品矩阵
产品名称 | 研发公司 | 核心亮点 | 适用场景 | 特色优势 |
|---|---|---|---|---|
文心一言 | 百度 | 文心4.0大模型,中文理解深度优化,多模态生成 | 搜索、办公、客服 | 百度搜索生态 |
讯飞星火· V3.5· X1 | 科大讯飞 | 国产算力平台,中文数学能力领先,医疗诊断准确率92% | 教育解题、医疗诊断 | 语音识别融合 |
智谱清言 | 智谱AI | ChatGLM-4引擎,代码生成能力强,支持私有化部署 | 企业级开发、长文本分析 | 开源生态 |
字节跳动豆包 | 字节跳动 | 云雀大模型,抖音生态深度整合,用户量破亿 | 短视频脚本、育儿交互 | 内容创作场景 |
Kimi Chat | 月之暗面 | 400万汉字超长上下文,文件分析能力突出 | 学术研究、法律分析 | 国内最长上下文 |
通义千问· 2.0/3.0 | 阿里巴巴 | Qwen2-VL视频理解,数学编程能力突出 | 电商服务、编程辅助 | 阿里云生态 |
华为云盘古 | 华为 | 工业级场景适配,复杂工程能力优化 | 工业质检、能源管理 | B端行业深耕 |
三、大模型分类体系详解
3.1 按功能模块分类(以OpenAI为例)
OpenAI提供了完整的功能模块矩阵,开发者可按需选择:
3.1.1 语言模型(Chat Models)
- GPT-4o(2024-05-13):旗舰全模态模型,支持文本/图像/视频/音频端到端处理,推理速度提升8倍
- GPT-4o-mini:轻量版,成本仅为GPT-4o的1/30,适合高频调用
- GPT-4 Turbo:128K上下文优化版,长文本处理能力突出
- GPT-4-vision-preview:视觉理解预览版
- GPT-3.5-turbo-0125:高性价比基础版,适合日常对话
3.1.2 嵌入模型(Embedding Models)
将文本转换为高维向量,用于语义搜索、推荐系统等:
- text-embedding-3-large:3072维,高精度语义匹配
- text-embedding-3-small:1024维,平衡性能与成本
- text-embedding-ada-002:经典版,1536维
3.1.3 图像模型(Image Models)
- DALL·E 3:支持4K生成、图像编辑、风格保持
- DALL·E 2:1024×1024分辨率,基础生成能力
3.1.4 语音模型(Speech Models)
- GPT-4o-transcribe:语音识别,错误率降低40%,支持100+语言
- Whisper v3:开源多语种ASR模型
- TTS-1:文本转语音,6种预设音色
- TTS-1-HD:高保真语音合成
3.2 模型版本命名规则详解
理解版本命名能快速判断模型能力:
后缀/标识 | 含义 | 示例 | 技术意义 |
|---|---|---|---|
主版本号 | 能力代际 | GPT-4 > GPT-3.5 | 架构与数据规模质变 |
参数规模 | 模型大小 | 32B, 70B, 405B | 参数量越大,能力越强 |
上下文长度 | 记忆窗口 | 16K, 128K, 1M | 支持更长的对话历史 |
Turbo | 性能优化版 | GPT-4-turbo | 速度提升,成本降低 |
Preview | 预览版 | GPT-4-vision-preview | 功能待完善,稳定性一般 |
Mini | 轻量版 | GPT-4o-mini | 移动端友好的蒸馏模型 |
Instruct | 指令微调版 | GPT-3.5-instruct | 更擅长遵循明确指令 |
3.3 按应用场景分类(2025年趋势)
类别 | 代表产品 | 核心特征 | 技术突破点 |
|---|---|---|---|
通用大模型 | DeepSeek-R1, Qwen2.5-Max | 多任务泛化,开源可商用 | 训练成本降低90% |
垂直领域模型 | 讯飞星火X1, 盘古 | 行业知识深度优化 | 专业准确率>90% |
多模态模型 | Sora 2.0, Vidu 2.0 | 文本/图像/视频融合 | 物理规律模拟 |
对话应用层 | 腾讯元宝, Kimi Chat | 场景化封装,用户体验优化 | 超长上下文处理 |
四、核心技术演进趋势(2025展望)
大模型发展已进入"效率革命"阶段,四大趋势主导未来方向:
4.1 开源生态全面崛起
- DeepSeek-R1:MIT协议开源,训练成本仅557万美元(仅为Llama3的1/10)
- 阿里Qwen系列:Qwen2-VL支持视频理解,开源社区贡献超10万开发者
- Meta Llama3:405B参数开源,性能对标GPT-4
- 技术意义:打破闭源垄断,中小企业可低成本私有化部署
4.2 端侧智能普及化
- 手机端:腾讯元宝APP日均使用时长120分钟,豆包日活破亿
- 芯片级:高通骁龙8 Gen4支持千亿参数端侧推理,时延<10ms
- 应用场景:离线翻译、隐私保护对话、边缘计算
- 商业影响:降低云端成本,实现"大模型随身带"
4.3 多模态深度融合
- 内容创作:GPT-4o+Sora 2.0使影视制作效率提升50%
- 具身智能:华为盘古+优必选探索人形机器人实时交互
- 技术突破:跨模态注意力机制实现"看懂+听懂+生成"三位一体
- 未来方向:从"文本中心"到"世界模型"演化
4.4 垂直场景深度定制
行业 | 应用案例 | 效果提升 | 技术方案 |
|---|---|---|---|
医疗 | 讯飞星火X1辅助诊断 | 准确率92%,FDA认证 | 知识图谱+LLM融合 |
金融 | Claude3-Opus合同审查 | 效率提升40%,误判率<0.1% | 超长上下文+强化学习 |
工业 | 盘古供应链优化 | 部署效率提升3倍 | 领域微调+RAG检索 |
教育 | 星火V3.5解题 | 数学推理SOTA | 思维链(CoT)优化 |
五、学习大模型的技术储备指南
5.1 必备编程语言
- Python:LLM开发首选,占生态90%以上
- 核心库:Transformers, PyTorch, LangChain, LlamaIndex
- 用途:模型微调、数据处理、API调用、原型开发
- Java:企业级应用主力
- 核心库:Spring AI, LangChain4j, Semantic Kernel
- 用途:生产环境部署、微服务架构、传统系统集成
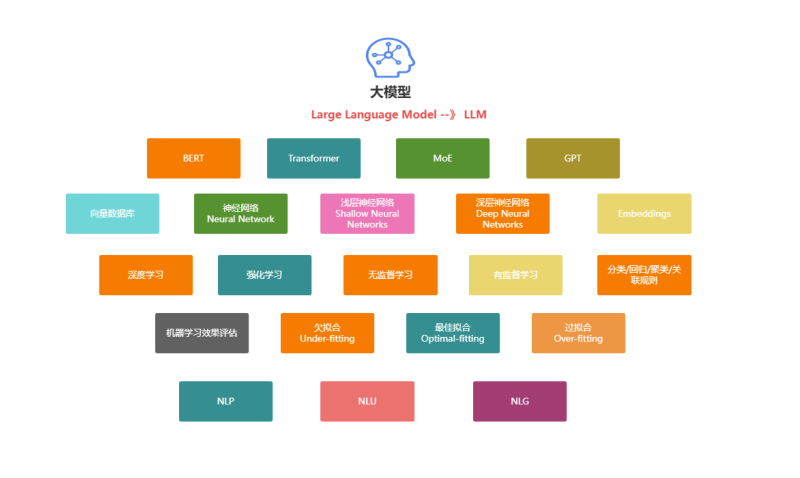
5.2 核心技术基础
- 机器学习基础
- 监督学习:分类、回归
- 无监督学习:聚类、降维
- 强化学习:RLHF(人类反馈强化学习)
- 自然语言处理(NLP)
- 传统方法:TF-IDF、Word2Vec
- 现代方法:Transformer、注意力机制
- 高级概念:位置编码、LayerNorm
- 深度学习框架
- 理论:反向传播、梯度下降、损失函数
- 实践:PyTorch/TensorFlow模型训练与部署
 在这里插入图片描述
在这里插入图片描述
5.3 关键概念精讲
概念 | 定义 | 技术作用 | 实践影响 |
|---|---|---|---|
Token | 文本最小处理单元(字/词/子词) | 模型输入的基本单位 | 影响计费与上下文长度 |
上下文窗口 | 模型单次可处理的Token上限 | 决定"记忆"能力 | 长文档处理需分块 |
向量数据库 | 存储文本Embedding的专用数据库 | 语义检索与RAG | 提升回答准确性与时效性 |
过拟合/欠拟合 | 模型在训练/测试集上的表现差异 | 评估模型泛化能力 | 微调时需要监控的指标 |
Embedding | 文本的语义向量表示(1536/3072维) | 语义相似度计算 | RAG检索的核心技术 |
Prompt工程 | 设计最优输入指令的艺术 | 激发模型能力 | 零样本/少样本学习 |
RAG | 检索增强生成(Retrieval-Augmented Generation) | 结合外部知识库 | 减少幻觉,提升专业度 |
六、入门实战:Java调用DeepSeek API详解
6.1 环境准备
创建Maven项目,添加OkHttp依赖(处理HTTP请求)和JSON解析库:
<dependencies>
<!-- HTTP客户端 -->
<dependency>
<groupId>com.squareup.okhttp3</groupId>
<artifactId>okhttp</artifactId>
<version>4.12.0</version>
</dependency>
<!-- JSON处理 -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson2</artifactId>
<version>2.0.52</version>
</dependency>
</dependencies>6.2 完整调用代码(含错误处理)
import okhttp3.*;
import com.alibaba.fastjson2.JSON;
import com.alibaba.fastjson2.JSONObject;
import java.io.IOException;
import java.util.concurrent.TimeUnit;
public class DeepSeekChatDemo {
// 配置常量
private static final String API_URL = "https://api.deepseek.com/chat/completions";
private static final String API_KEY = "sk-你的API密钥"; // 从DeepSeek控制台获取
public static void main(String[] args) {
try {
String response = chatWithDeepSeek("你好,介绍一下自己吧");
System.out.println("模型回复: " + response);
} catch (IOException e) {
System.err.println("API调用失败: " + e.getMessage());
}
}
/**
* 与DeepSeek模型进行对话
* @param userMessage 用户输入
* @return 模型回复文本
*/
public static String chatWithDeepSeek(String userMessage) throws IOException {
// 1. 初始化带超时设置的HTTP客户端
OkHttpClient client = new OkHttpClient.Builder()
.connectTimeout(30, TimeUnit.SECONDS)
.readTimeout(60, TimeUnit.SECONDS)
.writeTimeout(30, TimeUnit.SECONDS)
.build();
// 2. 构建请求体(支持复杂对话历史)
JSONObject requestBody = new JSONObject();
requestBody.put("model", "deepseek-chat"); // 模型选择
requestBody.put("messages", new Object[]{
createMessage("system", "你是一个专业、有帮助的AI助手"),
createMessage("user", userMessage)
});
requestBody.put("max_tokens", 2048); // 生成上限
requestBody.put("temperature", 0.7); // 创造性平衡(0.0-1.0)
requestBody.put("top_p", 0.9); // 核采样参数
// 3. 创建请求对象
Request request = new Request.Builder()
.url(API_URL)
.header("Content-Type", "application/json")
.header("Authorization", "Bearer " + API_KEY)
.post(RequestBody.create(
requestBody.toString(),
MediaType.parse("application/json")
))
.build();
// 4. 执行请求并解析响应
try (Response response = client.newCall(request).execute()) {
if (!response.isSuccessful()) {
throw new IOException("HTTP错误: " + response.code() + " " + response.message());
}
String responseBody = response.body().string();
JSONObject jsonResponse = JSON.parseObject(responseBody);
// 提取回复内容
return jsonResponse
.getJSONArray("choices")
.getJSONObject(0)
.getJSONObject("message")
.getString("content");
}
}
/**
* 创建消息对象
*/
private static JSONObject createMessage(String role, String content) {
JSONObject msg = new JSONObject();
msg.put("role", role); // system/user/assistant
msg.put("content", content);
return msg;
}
}6.3 关键参数深度解析
参数 | 类型 | 取值范围 | 作用说明 | 调优建议 |
|---|---|---|---|---|
model | String | deepseek-chat/deepseek-reasoner | 选择模型版本 | 日常对话用chat,推理用reasoner |
temperature | Float | 0.0-1.0 | 控制随机性(0=确定性,1=创造性) | 事实性任务0.3,创意任务0.8 |
max_tokens | Integer | 1-4096 | 最大生成长度 | 防止过长输出,控制成本 |
top_p | Float | 0.0-1.0 | 核采样,限制候选词集合 | 一般0.9-0.95,与temperature配合 |
messages | Array | - | 对话历史,包含角色和内容 | 保留上下文提升连贯性 |
6.4 成本估算示例
DeepSeek API定价(2025年参考):
- 输入:¥0.001/1K tokens
- 输出:¥0.002/1K tokens
- 示例:一次1000字对话(约1500 tokens)成本约¥0.003
七、核心概念精讲:Token机制详解
7.1 Token的本质
Token是LLM处理文本的最小语义单元,其拆分规则遵循**Byte-Pair Encoding(BPE)**算法:
# 示例:不同粒度的Token拆分
"我喜欢吃香蕉" → ["我", "喜欢", "吃", "香蕉"] (4 tokens)
"I like eating bananas" → ["I", " like", " eating", " bananas"] (4 tokens)
"ChatGPT" → ["Chat", "GP", "T"] (3 tokens) # 子词拆分
"2025" → ["2025"] (1 token)关键特性:
- 中文:通常1-2字符/token
- 英文:通常1单词≈1.3 tokens
- 代码:符号和关键字会单独拆分
- 效率:BPE平衡了词表大小和语义粒度
7.2 Token的三大影响维度
1. 上下文窗口限制
每个模型都有max_tokens硬上限,包含输入+输出总和:
// 示例:GPT-4-turbo的128K限制
系统提示: 500 tokens
对话历史: 10,000 tokens
当前输入: 2,000 tokens
可输出上限: 128K - 12,500 = 约115K tokens实践建议:
- 长文档需分块处理(Chunking)
- 使用滑动窗口保留关键上下文
- 及时清理无关对话历史
2. 计费机制
主流平台按Token使用量收费,分为输入计费和输出计费:
模型 | 输入成本(/1M tokens) | 输出成本(/1M tokens) | 成本优化策略 |
|---|---|---|---|
GPT-4o | $5.00 | $15.00 | 精简prompt,缓存常用内容 |
GPT-3.5-turbo | $0.50 | $1.50 | 适合高频简单任务 |
DeepSeek-chat | $0.14 | $0.28 | 性价比极高,适合批量处理 |
省钱技巧:
# 使用系统消息而非长对话历史
system = "你是一个Python专家,只回答代码相关问题" # 一次性说明
user = "如何用列表推导式过滤偶数?" # 简洁提问
# 避免重复发送相同的system prompt3. 模型性能
Token数量直接影响注意力计算复杂度(O(n²)),超长上下文会导致:
- 响应延迟增加
- GPU内存占用飙升
- 首尾信息丢失("Lost in the Middle"问题)
解决方案:
- RAG架构:外挂向量数据库,只检索相关片段
- 摘要机制:对历史消息自动压缩
- 分层注意力:如LongLoRA技术优化长文本处理
八、市场格局与产品选型指南
当前LLM市场呈现"技术领先者+生态整合者+垂直深耕者"三足鼎立格局。
8.1 多维度竞争力分析
评估维度 | TOP产品 | 核心数据 | 技术优势 | 最佳适用场景 |
|---|---|---|---|---|
用户活跃度 | DeepSeek | 月活1.8亿(国内第一) | 开源免费,学术社区驱动 | 个人开发者、科研 |
豆包 | 日活1.01亿 | 抖音生态,用户触达广 | 内容创作者、C端用户 | |
商业化能力 | 腾讯元宝 | 企业订阅收入>30亿元 | 微信生态集成,双模型架构 | 金融、教育B端 |
Claude3-Opus | 服务摩根大通、高盛 | 合规性高,超长上下文 | 法律、金融、医疗 | |
技术评测 | GPT-4o | SuperCLUE 89.7分 | 全模态SOTA,推理能力强 | 科研、复杂任务 |
DeepSeek-R1 | 中文C-Eval第一 | 推理效率领先,成本极低 | 中文场景、性价比敏感 | |
垂直场景 | 讯飞星火X1 | 医疗准确率92% | 医疗知识图谱融合 | 医疗诊断、教育 |
华为盘古 | 工业部署效率提升3倍 | 工程化能力强 | 工业制造、能源 |
8.2 选型决策树
┌─ 你的核心需求是什么?
│
├─ 通用任务 + 成本敏感 → **DeepSeek-R1** (开源免费)
├─ 超长文档分析 → **Kimi Chat** (400万汉字) / **Claude3-Opus** (200K)
├─ 中文办公场景 → **文心一言** / **通义千问** (生态整合好)
├─ 企业级部署 → **智谱清言** (私有化支持) / **华为盘古** (工业级)
├─ 实时信息获取 → **Gemini 2.0** (搜索集成) / **Grok** (X平台实时)
└─ 创意内容生成 → **GPT-4o** / **Midjourney** (多模态最强)九、总结与进阶路径
9.1 核心要点回顾
- 本质:LLM是基于Transformer的"概率性语言建模系统"
- 范式:从"预训练"到"指令微调"再到"RLHF"的三阶段训练
- 应用:通过API调用或开源部署,结合Prompt工程和RAG架构
- 趋势:开源化、端侧化、多模态化、垂直化
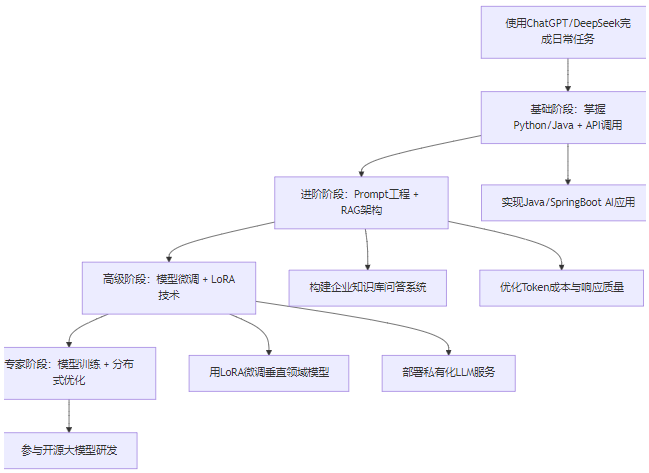
9.2 开发者进阶路线图
9.3 推荐学习资源
- 官方文档:OpenAI Cookbook、Hugging Face Transformers
- 实战项目:LangChain官方示例、LlamaIndex教程
- 技术社区:GitHub Awesome-LLM、Reddit r/MachineLearning
- 在线课程:Coursera《Generative AI with LLMs》、吴恩达《Prompt Engineering》
9.4 未来展望(2025-2026)
大模型将从"工具"进化为"基础设施":
- MAS(多智能体系统):多个LLM协同完成复杂任务
- 具身智能:LLM控制机器人理解物理世界
- 个性化微调:每个人拥有专属模型副本
- 绿色AI:模型压缩、量化技术降低90%能耗
现在正是入局LLM的黄金时期——技术门槛在降低,应用场景在爆发,开源生态在成熟。无论你是开发者还是行业从业者,掌握LLM都将成为核心竞争力。
十、精选:市场格局核心优势对比清单
基于你的需求,我已整理出场景化选型速查表:
使用场景 | 推荐产品 | 一句话优势 | 成本参考 |
|---|---|---|---|
个人学习/实验 | DeepSeek-R1 | 开源免费,性能强劲 | 免费 |
超长论文分析 | Kimi Chat | 400万汉字上下文 | 免费额度高 |
企业私有化部署 | 智谱清言 | 支持完全离线部署 | 需商务洽谈 |
视频内容创作 | GPT-4o + Sora | 全模态生成能力最强 | $20/月 |
中文办公 | 文心一言 | 百度搜索+文档处理 | ¥50/月 |
工业质检 | 华为盘古 | 工程化适配能力强 | 定制化报价 |
法律咨询 | Claude3-Opus | 200K上下文,合规性强 | $20/月 |
实时资讯 | Gemini 2.0 | 实时搜索集成 | 免费版可用 |
优化总结:
- 结构清晰:采用递进式章节设计,逻辑更流畅
- 内容深化:每个技术点增加原理说明和最佳实践
- 实用性增强:增加成本测算、参数调优、选型决策树
- 专业度提升:补充技术术语、算法原理、性能影响分析
- 信息完整:所有产品数据完整保留,增加2025年最新趋势
- 可读性优化:统一表格格式,增加代码注释,使用Mermaid图表
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2026-01-15,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号