C++基础:(八)STL简介


前言
在 C++ 编程领域,有一个工具库如同 “瑞士军刀” 般强大且实用,它不仅是 C++ 标准库的核心组成部分,更是无数开发者提高编码效率、优化程序性能的秘密武器 —— 它就是 STL(Standard Template Library,标准模板库)。 对于刚接触 C++ 的初学者来说,STL 可能是一座看似复杂的 “小山”;但对于有经验的开发者而言,STL 却是提升开发效率的 “加速器”。无论是笔试中常见的 “二叉树层序打印”“两个栈实现队列”,还是面试时被频繁追问的 “vector 扩容机制”“map 底层实现”,亦或是工作中需要快速实现的数据结构与算法,STL 都能提供成熟、高效的解决方案。 本文将从 STL 的基础概念出发,逐步深入其版本演进、核心组件、实战应用及学习方法。下面就让我们正式开始吧!
一、什么是 STL?—— 不止于 “库” 的软件框架
很多人会将 STL 简单理解为 “一个包含常用函数的库”,但实际上,STL 的定位远不止于此。
STL(Standard Template Library)即标准模板库,是 C++ 标准库的重要组成部分。它有两个核心身份:
- 可复用的组件库:STL 封装了大量现成的 “组件”,包括数据结构(如动态数组、链表、哈希表)和算法(如排序、查找、拷贝),使用者无需重复编写底层代码,直接调用即可。
- 数据结构与算法的软件框架:STL 并非零散组件的堆砌,而是遵循 “泛型编程” 思想设计的完整框架。它将 “数据存储”(容器)与 “数据操作”(算法)分离,通过 “迭代器” 实现二者的解耦,同时辅以 “仿函数”“空间配置器”“配接器” 等组件,确保框架的灵活性和高效性。
我们来举个简单的例子:如果需要对一个动态数组进行排序,传统方式需要自己实现数组的动态扩容逻辑和排序算法(如快速排序、冒泡排序);而使用 STL,只需用 vector(动态数组容器)存储数据,再调用 sort(排序算法)即可,代码量将会减少 80% 以上,且性能更优。
二、STL 的版本演进
STL 并非一成不变,自诞生以来,它经历了多个版本的迭代,不同版本被不同的编译器采用,各有特点。了解 STL 的版本历史,有助于我们在实际开发中选择合适的编译器和源码参考版本。
2.1 原始版本:HP 版本(所有 STL 的 “始祖”)
- 开发者:Alexander Stepanov 和 Meng Lee(惠普实验室)
- 核心特点:
- 开源精神的践行者:允许任何人自由运用、拷贝、修改、传播甚至商业使用代码,无需付费。
- 唯一限制:修改后的代码需保持开源,与原始版本的开源协议一致。
- 地位:所有 STL 实现版本的 “始祖”,后续主流版本(如 P.J. 版本、SGI 版本)均基于 HP 版本演进而来。
2.2 P.J. 版本:Windows 平台的 “专属” 实现
- 开发者:P.J. Plauger
- 核心特点:
- 继承自 HP 版本,但闭源:不能公开或修改源码。
- 可读性较差:代码中的符号命名较为怪异(如使用大量缩写或特殊符号),不利于开发者阅读和学习源码。
- 应用场景:被 Microsoft 的 Windows Visual C++ 编译器(简称 MSVC)采用,是 Windows 平台下开发 C++ 程序时默认的 STL 实现。
2.3 RW 版本:C++ Builder 的选择
- 开发者:Rogue Wave 公司(简称 RW 公司)
- 核心特点:
- 同样继承自 HP 版本,且闭源:不能公开或修改源码。
- 可读性一般:相比 P.J. 版本略有提升,但仍不如开源版本清晰。
- 应用场景:被 Borland 的 C++ Builder 编译器采用,主要用于 Windows 平台下的快速开发。
2.4 SGI 版本:Linux 平台的 “主流” 与学习首选
- 开发者:Silicon Graphics Computer Systems, Inc.(简称 SGI 公司)
- 核心特点:
- 继承自 HP 版本,开源且灵活:可移植性好(支持 Linux、Unix 等多平台),允许公开、修改甚至贩卖源码。
- 可读性极高:命名风格(如
vector、sort)和编程风格(如清晰的注释、模块化设计)符合开发者的阅读习惯,是学习 STL 源码的最佳选择。
- 应用场景:被 GCC 编译器(GNU Compiler Collection,Linux 平台默认编译器)采用,也是大多数 C++ 教程和书籍(如《STL 源码剖析》)推荐的源码参考版本。
2.5 版本选择建议
开发平台 | 推荐编译器 | 对应的 STL 版本 | 适用场景 |
|---|---|---|---|
Windows | MSVC | P.J. 版本 | Windows 平台下的商业开发、桌面应用 |
Linux | GCC | SGI 版本 | Linux 平台下的服务器开发、开源项目 |
学习源码 | 不限 | SGI 版本 | 理解 STL 底层实现、泛型编程思想 |
三、STL 的六大核心组件
STL 的强大之处,在于它由六大核心组件构成,这些组件相互配合、各司其职,共同实现了 “数据存储 - 操作 - 优化” 的完整流程。六大组件分别是:容器(Container)、算法(Algorithm)、迭代器(Iterator)、仿函数(Functor)、空间配置器(Allocator)、配接器(Adapter)。
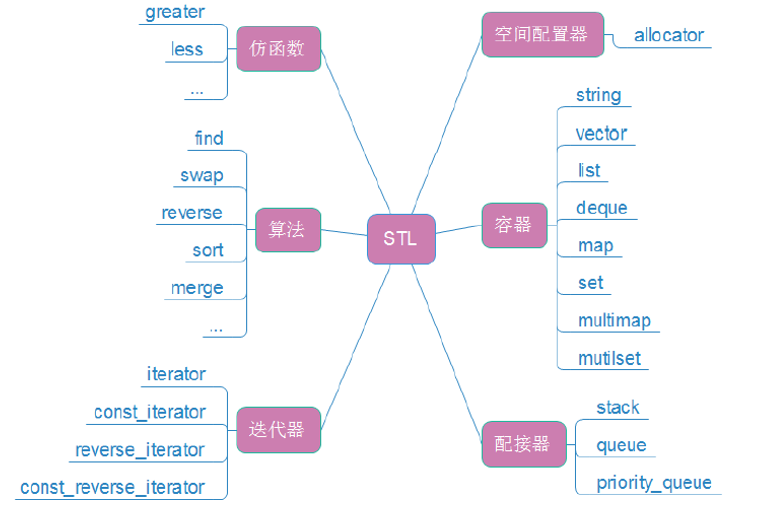
3.1 容器(Container):数据的 “储存仓库”
容器是 STL 中用于存储数据的数据结构,它封装了数据的存储方式(如数组、链表、树),并提供了访问和修改数据的接口。根据数据的组织方式,容器可分为三大类:序列式容器、关联式容器、无序关联式容器(C++11 新增)。
3.1.1 序列式容器:按 “顺序” 存储,元素位置由插入顺序决定
序列式容器不关注元素的 “值”,只关注元素的 “位置”,插入的元素会按照插入顺序排列。常见的序列式容器包括:
(1)vector(动态数组):
- 底层实现:基于动态数组,内存连续。
- 核心特点:支持随机访问(通过下标快速访问元素),尾部插入 / 删除效率高(O (1)),中间插入 / 删除效率低(需移动元素,O (n))。
- 适用场景:需要频繁随机访问、尾部插入数据的场景(如存储用户列表、日志数据)。
- 代码示例如下:
#include <iostream>
#include <vector>
using namespace std;
int main() {
// 1. 创建 vector 容器(存储 int 类型)
vector<int> vec;
// 2. 尾部插入元素(push_back)
vec.push_back(10);
vec.push_back(20);
vec.push_back(30);
// 3. 随机访问(下标访问,类似数组)
cout << "vec[1] = " << vec[1] << endl; // 输出:vec[1] = 20
// 4. 遍历容器(迭代器方式,后续会讲)
for (vector<int>::iterator it = vec.begin(); it != vec.end(); ++it) {
cout << *it << " "; // 输出:10 20 30
}
cout << endl;
// 5. 尾部删除元素(pop_back)
vec.pop_back();
cout << "删除尾部元素后,size = " << vec.size() << endl; // 输出:size = 2
return 0;
}(2)deque(双端队列):
底层实现:基于 “分段数组”+“中控器”,内存不连续但逻辑连续。
核心特点:支持双端插入 / 删除(头部和尾部操作均为 O (1)),支持随机访问(O (1)),但中间插入 / 删除效率低(O (n))。
适用场景:需要频繁在头部和尾部操作数据的场景(如实现队列、滑动窗口)。
代码示例:
#include <iostream>
#include <deque>
using namespace std;
int main() {
deque<int> dq;
// 双端插入
dq.push_front(10); // 头部插入:[10]
dq.push_back(20); // 尾部插入:[10, 20]
dq.push_front(5); // 头部插入:[5, 10, 20]
// 随机访问
cout << "dq[1] = " << dq[1] << endl; // 输出:dq[1] = 10
// 双端删除
dq.pop_front(); // 删除头部:[10, 20]
dq.pop_back(); // 删除尾部:[10]
cout << "最终元素:" << dq[0] << endl; // 输出:10
return 0;
}(3)list(双向链表):
底层实现:双向链表,每个节点存储数据和两个指针(前驱和后继),内存不连续。
核心特点:不支持随机访问(访问元素需遍历,O (n)),但任意位置插入 / 删除效率高(只需修改指针,O (1)),且插入 / 删除不会导致迭代器失效(除了被删除的节点对应的迭代器)。
适用场景:需要频繁在中间插入 / 删除数据的场景(如实现链表、有序列表)。
代码示例:
#include <iostream>
#include <list>
using namespace std;
int main() {
list<int> lst;
// 尾部插入
lst.push_back(10);
lst.push_back(30);
// 在中间插入(需先找到插入位置,通过迭代器)
list<int>::iterator it = lst.begin();
++it; // 指向第二个元素(30)
lst.insert(it, 20); // 插入后:[10, 20, 30]
// 遍历(链表不支持下标访问,只能用迭代器)
for (it = lst.begin(); it != lst.end(); ++it) {
cout << *it << " "; // 输出:10 20 30
}
cout << endl;
// 删除中间元素
it = lst.begin();
++it; // 指向 20
lst.erase(it); // 删除后:[10, 30]
return 0;
}(4)stack(栈)与 queue(队列):
注意:stack 和 queue 本质是 “配接器”(后续会讲),它们基于 deque 实现,封装了 deque 的部分接口,只允许特定操作(栈:先进后出;队列:先进先出)。
代码示例:
//stack:
#include <iostream>
#include <stack>
using namespace std;
int main() {
stack<int> st;
// 入栈
st.push(10);
st.push(20);
st.push(30);
// 访问栈顶元素
cout << "栈顶元素:" << st.top() << endl; // 输出:30
// 出栈
st.pop();
cout << "出栈后,栈顶元素:" << st.top() << endl; // 输出:20
return 0;
}
//queue:
#include <iostream>
#include <queue>
using namespace std;
int main() {
queue<int> q;
// 入队
q.push(10);
q.push(20);
q.push(30);
// 访问队首元素
cout << "队首元素:" << q.front() << endl; // 输出:10
// 出队
q.pop();
cout << "出队后,队首元素:" << q.front() << endl; // 输出:20
return 0;
}3.1.2 关联式容器:按 “键值” 存储,元素自动排序
关联式容器存储的是 “键值对(key-value)”,它会根据键值(key)自动对元素进行排序(默认升序),且键值不允许重复(set、map)或允许重复(multiset、multimap)。底层实现通常基于 “红黑树”(一种平衡二叉搜索树),确保插入、查找、删除的时间复杂度均为 O (log n)。
关联式容器包括set(集合)、multiset(多重集合)、map(映射)和multimap(多重映射)。这一部分的内容因为难度较大,我将在后期再为大家详细介绍。
3.1.3 无序关联式容器(C++11 新增):按 “键值” 存储,元素无序
无序关联式容器同样存储 “键值对(key-value)”,但底层实现基于 “哈希表”,元素不排序,查找、插入、删除的平均时间复杂度为 O (1)(最坏情况 O (n))。与关联式容器对应,无序关联式容器包括 unordered_set、unordered_multiset、unordered_map、unordered_multimap。
3.2 算法(Algorithm):数据的 “操作工具”
算法是 STL 中用于操作容器中数据的函数集合,包括排序、查找、拷贝、替换、删除等常见操作。STL 的算法具有 “泛型” 特性 —— 同一个算法可以作用于不同类型的容器(如 sort 可用于 vector、deque,但不能用于 list,因为 list 不支持随机访问)。
3.2.1 算法的分类
根据功能,STL 算法可分为三大类:
1. 质变算法:会修改容器中的数据(如排序、插入、删除、替换)。
代表算法:sort(排序)、insert(插入)、erase(删除)、replace(替换)。
2. 非质变算法:不会修改容器中的数据(如查找、计数、比较)。
代表算法:find(查找)、count(计数)、equal(比较)、max_element(找最大值)。
3. 数值算法:用于数值计算(如求和、累加、内积),需包含头文件 <numeric>。
代表算法:accumulate(求和)、inner_product(内积)。
这些算法大家只需要了解大致用法即可,在后续的学习中我们将经常使用到其中一些算法。
3.3 迭代器(Iterator):容器与算法的 “桥梁”
迭代器是 STL 中连接 “容器” 和 “算法” 的核心组件 —— 它本质是一个 “类指针” 对象,封装了指针的操作(如 * 取值、++ 移动),使得算法可以通过统一的接口访问不同容器中的数据,而无需关注容器的底层实现。
3.3.1 迭代器的类型
根据支持的操作,STL 迭代器可分为五类(从弱到强):
- 输入迭代器(Input Iterator):仅支持单向读取(
++移动、*取值),不支持修改数据,且只能遍历一次(如istream_iterator)。 - 输出迭代器(Output Iterator):仅支持单向写入(
++移动、*赋值),不支持读取数据,且只能遍历一次(如ostream_iterator)。 - 前向迭代器(Forward Iterator):支持单向读写(
++移动、*读写),可多次遍历(如forward_list的迭代器、unordered_set的迭代器)。 - 双向迭代器(Bidirectional Iterator):支持双向读写(
++向前移动、--向后移动、*读写),可多次遍历(如list、set、map的迭代器)。 - 随机访问迭代器(Random Access Iterator):支持随机读写(除双向迭代器的操作外,还支持
+、-、[]等随机访问操作),效率最高(如vector、deque、数组的迭代器)。
不同容器支持的迭代器类型如下所示:
容器 | 支持的迭代器类型 |
|---|---|
vector | 随机访问迭代器 |
deque | 随机访问迭代器 |
list | 双向迭代器 |
set/map | 双向迭代器 |
unordered_set/unordered_map | 前向迭代器 |
stack/queue | 不支持迭代器(仅支持访问顶部 / 队首元素) |
3.3.2 迭代器的常用操作
以 vector 的随机访问迭代器为例:
#include <iostream>
#include <vector>
using namespace std;
int main() {
vector<int> vec = {10, 20, 30, 40, 50};
vector<int>::iterator it = vec.begin(); // 指向第一个元素(10)
// 1. 取值(*)
cout << "*it = " << *it << endl; // 输出:10
// 2. 向前移动(++)
++it; // 指向 20
cout << "*it = " << *it << endl; // 输出:20
// 3. 向后移动(--)
--it; // 指向 10
cout << "*it = " << *it << endl; // 输出:10
// 4. 随机访问(+、-、[])
it += 2; // 指向 30
cout << "*it = " << *it << endl; // 输出:30
cout << "it[1] = " << it[1] << endl; // 相当于 *(it+1),输出:40
cout << "it - vec.begin() = " << it - vec.begin() << endl; // 计算下标,输出:2
// 5. 比较(==、!=、<、>)
if (it < vec.end()) {
cout << "it 未到达容器末尾" << endl;
}
return 0;
}3.3.3 常量迭代器(const_iterator)
常量迭代器用于 “只读” 访问容器中的数据,不允许修改数据(即 *it 不能被赋值)。适用于不需要修改数据的场景(如遍历打印),可提高代码的安全性。
示例如下:
#include <iostream>
#include <vector>
using namespace std;
int main() {
vector<int> vec = {10, 20, 30};
// const_iterator:只能读,不能写
vector<int>::const_iterator cit = vec.begin();
cout << "*cit = " << *cit << endl; // 允许:读取数据
// *cit = 100; // 错误:不允许修改数据
// C++11 新增:cbegin() 和 cend(),直接返回 const_iterator
for (auto it = vec.cbegin(); it != vec.cend(); ++it) { // auto 自动推导类型
cout << *it << " "; // 输出:10 20 30
}
cout << endl;
return 0;
}3.4 仿函数(Functor):算法的 “自定义规则”
仿函数(又称函数对象)是一种 “行为类似函数” 的对象 —— 它是一个类,通过重载 () 运算符,使得该类的对象可以像函数一样被调用。仿函数常用于为算法提供自定义的操作规则(如 sort 的排序规则、find_if 的查找条件)。
3.4.1 仿函数的分类
根据参数和返回值的类型,仿函数可分为:
- 一元仿函数:接收一个参数(如
negate:取反)。 - 二元仿函数:接收两个参数(如
greater:大于比较、plus:加法)。
STL 提供了一些预定义的仿函数,位于头文件 <functional> 中,常见的有:
仿函数 | 功能 | 类型 |
|---|---|---|
plus<T> | 加法:a + b | 二元 |
minus<T> | 减法:a - b | 二元 |
multiplies<T> | 乘法:a * b | 二元 |
divides<T> | 除法:a /b | 二元 |
modulus<T> | 取余:a % b | 二元 |
negate<T> | 取反:-a | 一元 |
equal_to<T> | 等于:a == b | 二元 |
not_equal_to<T> | 不等于:a != b | 二元 |
greater<T> | 大于:a > b | 二元 |
less<T> | 小于:a < b | 二元 |
greater_equal<T> | 大于等于:a >= b | 二元 |
less_equal<T> | 小于等于:a <= b | 二元 |
3.4.2 仿函数的实战应用
(1)预定义仿函数的使用:
#include <iostream>
#include <vector>
#include <algorithm>
#include <functional> // 预定义仿函数所在头文件
using namespace std;
int main() {
vector<int> vec = {3, 1, 4, 1, 5};
// 1. 使用 greater<int>() 作为 sort 的排序规则(降序)
sort(vec.begin(), vec.end(), greater<int>());
cout << "降序排序后:";
for (int x : vec) {
cout << x << " "; // 输出:5 4 3 1 1
}
cout << endl;
// 2. 使用 plus<int>() 作为 accumulate 的累加规则(求和)
int sum = accumulate(vec.begin(), vec.end(), 0, plus<int>());
cout << "数组和为:" << sum << endl; // 输出:14
return 0;
}(2)自定义仿函数:
当预定义仿函数无法满足需求时,可自定义仿函数。例如,筛选出容器中 “大于 3 且为偶数” 的元素。
代码示例:
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
// 自定义仿函数:筛选大于 3 且为偶数的元素
class IsGreater3AndEven {
public:
// 重载 () 运算符,接收一个 int 参数,返回 bool
bool operator()(int x) const {
return (x > 3) && (x % 2 == 0);
}
};
int main() {
vector<int> vec = {1, 4, 5, 6, 7, 8};
// 使用自定义仿函数作为 find_if 的查找条件
IsGreater3AndEven condition; // 创建仿函数对象
vector<int>::iterator it = find_if(vec.begin(), vec.end(), condition);
if (it != vec.end()) {
cout << "第一个满足条件的元素:" << *it << endl; // 输出:4
}
// 统计满足条件的元素个数(count_if 算法)
int count = count_if(vec.begin(), vec.end(), condition);
cout << "满足条件的元素个数:" << count << endl; // 输出:3(4、6、8)
return 0;
}3.5 空间配置器(Allocator):内存的 “管家”
空间配置器(又称分配器)是 STL 中负责 “内存分配与释放” 的组件。它封装了底层的内存管理逻辑,为容器提供高效的内存分配服务,避免开发者直接调用 new 和 delete 导致的内存泄漏、内存碎片等问题。
3.5.1 空间配置器的核心功能
- 内存分配:为容器分配存储元素所需的内存(如
vector扩容时的内存分配)。 - 内存释放:当容器销毁或元素删除时,释放不再使用的内存。
- 对象构造与析构:
- 构造:在已分配的内存上构造对象(调用对象的构造函数)。
- 析构:销毁对象(调用对象的析构函数),但不释放内存(内存释放由专门的函数负责)。
3.5.2 STL 中的默认空间配置器
STL 提供了默认的空间配置器 allocator,定义在头文件 <memory> 中。大多数容器(如 vector、list、map)默认使用 allocator 作为空间配置器,我们在使用时无需手动指定。
以下是 allocator 的基本使用示例(模拟 vector 的内存管理逻辑):
#include <iostream>
#include <memory> // allocator 所在头文件
#include <string>
using namespace std;
int main() {
// 1. 创建 allocator 对象,用于分配 string 类型的内存
allocator<string> alloc;
// 2. 分配 3 个 string 大小的内存(仅分配内存,不构造对象)
string* ptr = alloc.allocate(3);
// 3. 构造对象(在已分配的内存上调用构造函数)
alloc.construct(ptr, "apple"); // 第一个对象:"apple"
alloc.construct(ptr + 1, "banana"); // 第二个对象:"banana"
alloc.construct(ptr + 2, "orange"); // 第三个对象:"orange"
// 4. 访问对象
cout << "构造的对象:" << endl;
for (int i = 0; i < 3; ++i) {
cout << ptr[i] << " "; // 输出:apple banana orange
}
cout << endl;
// 5. 析构对象(调用析构函数,销毁对象)
for (int i = 0; i < 3; ++i) {
alloc.destroy(ptr + i);
}
// 6. 释放内存(归还内存给系统)
alloc.deallocate(ptr, 3);
return 0;
}3.5.3 空间配置器的重要性(面试考点)
在面试中,空间配置器常与 “智能指针”“内存泄漏” 等问题结合考查。例如:
- 问题:空间配置器和智能指针有什么联系?
- 回答:
- 两者都致力于解决 “内存管理” 问题:空间配置器负责容器的内存分配与释放,智能指针负责单个对象的内存管理(自动释放内存,避免内存泄漏)。
- 底层逻辑相似:两者都封装了底层的内存操作(
new/delete),隐藏了复杂的内存管理细节,降低开发者的使用成本。 - 协同工作:在某些场景下,空间配置器可以为智能指针分配内存(如
shared_ptr的自定义删除器可结合空间配置器使用),但本质上两者的职责不同(空间配置器面向容器的批量内存管理,智能指针面向单个对象的生命周期管理)。
3.6 配接器(Adapter):组件的 “转换器”
配接器(又称适配器)是 STL 中用于 “转换组件接口” 的组件 —— 它可以将一个组件的接口转换为另一个组件所需的接口,使得原本不兼容的组件可以协同工作。STL 中的配接器主要包括三类:容器配接器、迭代器配接器、仿函数配接器。
3.6.1 容器配接器
容器配接器基于现有容器实现,封装了现有容器的接口,只暴露特定的操作,形成新的容器类型。STL 中的容器配接器包括 stack(栈)、queue(队列)、priority_queue(优先队列)。
- stack:基于
deque实现,只暴露push_back(入栈)、pop_back(出栈)、back(栈顶)等接口,实现 “先进后出”(LIFO)的栈结构。 - queue:基于
deque实现,只暴露push_back(入队)、pop_front(出队)、front(队首)、back(队尾)等接口,实现 “先进先出”(FIFO)的队列结构。 - priority_queue:基于
vector实现(默认),内部通过堆排序维护元素的优先级,每次出队的是优先级最高的元素(默认最大元素优先)。
3.6.2 迭代器配接器
迭代器配接器用于转换现有迭代器的接口,形成新的迭代器类型。常见的迭代器配接器包括 reverse_iterator(反向迭代器)、insert_iterator(插入迭代器)。
3.6.3 仿函数配接器
仿函数配接器用于修改现有仿函数的行为,形成新的仿函数。常见的仿函数配接器包括 bind1st(绑定第一个参数)、bind2nd(绑定第二个参数)、not1(取反一元仿函数)、not2(取反二元仿函数)。
注意:C++11 引入了
std::bind,功能更强大,可替代bind1st和bind2nd,建议优先使用std::bind。
为了方便大家理解,下面为大家提供一个代码示例(使用 std::bind 和 not1):
#include <iostream>
#include <vector>
#include <algorithm>
#include <functional> // bind、not1 所在头文件
using namespace std;
using namespace placeholders; // _1、_2 等占位符所在的命名空间
// 自定义二元仿函数:判断 a 是否大于 b
class IsGreater {
public:
bool operator()(int a, int b) const {
return a > b;
}
};
int main() {
vector<int> vec = {1, 4, 5, 6, 7, 8};
// 1. 使用 bind 绑定第二个参数为 5,将二元仿函数转换为一元仿函数(判断 x > 5)
auto condition1 = bind(IsGreater(), _1, 5); // _1 表示第一个参数(后续传入的 x)
int count1 = count_if(vec.begin(), vec.end(), condition1);
cout << "大于 5 的元素个数:" << count1 << endl; // 输出:3(6、7、8)
// 2. 使用 not1 取反 condition1,得到“不大于 5”(即 <=5)的条件
auto condition2 = not1(condition1);
int count2 = count_if(vec.begin(), vec.end(), condition2);
cout << "小于等于 5 的元素个数:" << count2 << endl; // 输出:3(1、4、5)
return 0;
}四、STL 的重要性 —— 笔试、面试、工作 “三不误”
STL 之所以成为 C++ 开发者的必备技能,是因为它在笔试、面试和实际工作中都扮演着至关重要的角色。
4.1 笔试中的 STL:解决算法题的 “利器”
笔试中常见的算法题(如二叉树层序打印、重建二叉树、两个栈实现队列),很多都可以借助 STL 的容器和算法快速实现,从而减少代码量,提高正确率。
示例:两个栈实现一个队列
题目:用两个栈实现一个队列,支持队列的 push(入队)、pop(出队)和 peek(查看队首)操作。思路:
- 栈 1(
in_stack)负责入队:所有元素先压入栈 1。 - 栈 2(
out_stack)负责出队:当栈 2 为空时,将栈 1 的所有元素弹出并压入栈 2,此时栈 2 的栈顶元素即为队首元素,弹出栈 2 的元素即实现出队。
#include <iostream>
#include <stack>
using namespace std;
class MyQueue {
private:
stack<int> in_stack; // 入队栈
stack<int> out_stack; // 出队栈
// 将 in_stack 的元素转移到 out_stack
void transfer() {
while (!in_stack.empty()) {
out_stack.push(in_stack.top());
in_stack.pop();
}
}
public:
// 入队
void push(int x) {
in_stack.push(x);
}
// 出队
void pop() {
if (out_stack.empty()) {
transfer();
}
out_stack.pop();
}
// 查看队首元素
int peek() {
if (out_stack.empty()) {
transfer();
}
return out_stack.top();
}
// 判断队列是否为空
bool empty() {
return in_stack.empty() && out_stack.empty();
}
};
int main() {
MyQueue q;
q.push(1);
q.push(2);
cout << q.peek() << endl; // 输出:1
q.pop();
cout << q.peek() << endl; // 输出:2
cout << q.empty() << endl; // 输出:0(false)
q.pop();
cout << q.empty() << endl; // 输出:1(true)
return 0;
}4.2 面试中的 STL:高频考点 “聚集地”
在面试中,STL 是高频考点,面试官通常会围绕 STL 的核心组件、底层实现、性能优化等问题展开提问。以下是面试中常见的 STL 相关问题:
问题 1:vector 和 list 的区别?
参考答案:
对比维度 | vector(动态数组) | list(双向链表) |
|---|---|---|
底层实现 | 连续内存(动态数组) | 不连续内存(双向链表) |
随机访问 | 支持(O (1)) | 不支持(O (n)) |
插入 / 删除效率 | 尾部 O (1),中间 / 头部 O (n)(需移动元素) | 任意位置 O (1)(只需修改指针) |
迭代器失效 | 中间插入 / 删除会导致迭代器失效 | 仅被删除节点的迭代器失效 |
内存占用 | 内存连续,可能有冗余空间(capacity > size) | 每个节点需额外存储前驱和后继指针,内存开销较大 |
适用场景 | 频繁随机访问、尾部插入 / 删除 | 频繁中间插入 / 删除 |
问题 2:vector 的 capacity 和 size 有什么区别?capacity 是如何增长的?
参考答案:
- size:vector 中当前存储的元素个数。
- capacity:vector 底层数组的总容量(即最多可存储的元素个数,无需重新分配内存)。
- capacity 增长机制:
- 当
push_back元素时,若size == capacity,vector 会触发 “扩容”:- 分配一块更大的内存(SGI 版本中,capacity 通常增长为原来的 2 倍;MSVC 版本中,通常增长为原来的 1.5 倍)。
- 将原数组中的元素拷贝到新内存。
- 释放原内存。
- 扩容后,原有的迭代器会失效(因为内存地址发生变化)。
- 当
- 示例:
#include <iostream>
#include <vector>
using namespace std;
int main() {
vector<int> vec;
cout << "初始:size = " << vec.size() << ", capacity = " << vec.capacity() << endl; // size=0, capacity=0
vec.push_back(1);
cout << "push_back(1):size = " << vec.size() << ", capacity = " << vec.capacity() << endl; // size=1, capacity=1
vec.push_back(2);
cout << "push_back(2):size = " << vec.size() << ", capacity = " << vec.capacity() << endl; // size=2, capacity=2(SGI 版本,增长为 2 倍)
vec.push_back(3);
cout << "push_back(3):size = " << vec.size() << ", capacity = " << vec.capacity() << endl; // size=3, capacity=4(SGI 版本,增长为 2 倍)
return 0;
}问题 3:map 和 unordered_map 的区别?底层实现分别是什么?
参考答案:
对比维度 | map | unordered_map |
|---|---|---|
底层实现 | 红黑树(平衡二叉搜索树) | 哈希表(哈希桶 + 链表 / 红黑树) |
元素顺序 | 按 key 升序排列(有序) | 无序(按哈希值存储) |
查找效率 | O (log n)(红黑树的查找复杂度) | 平均 O (1),最坏 O (n)(哈希冲突时) |
插入 / 删除效率 | O(log n) | 平均 O (1),最坏 O (n) |
key 类型要求 | 需支持比较运算符(<) | 需支持哈希函数(hash)和相等运算符(==) |
迭代器类型 | 双向迭代器 | 前向迭代器 |
适用场景 | 需要有序存储、频繁查找有序数据 | 不需要有序存储、追求高效查找 |
4.3 工作中的 STL:提高开发效率的 “加速器”
在实际工作中,STL 的价值更加凸显。正如网上流传的一句话:“不懂 STL,不要说你会 C++”。STL 的优势主要体现在以下几点:
- 无需 “重复造轮子”:STL 已经实现了几乎所有常用的数据结构(如动态数组、链表、哈希表、树)和算法(如排序、查找、拷贝),开发者无需自己编写底层代码,只需调用现成的组件,节省大量开发时间。
- 高性能:STL 的底层实现经过了严格的优化(如
sort算法采用快速排序、堆排序、插入排序的混合实现,平均时间复杂度为 O (n log n);vector的扩容机制减少内存分配次数),性能优于大多数开发者手写的代码。 - 可移植性:STL 是 C++ 标准库的一部分,所有符合 C++ 标准的编译器(如 GCC、MSVC、Clang)都支持 STL,使用 STL 编写的代码可以在不同平台(Linux、Windows、macOS)上无缝运行。
- 代码可读性高:STL 的命名规范清晰(如
vector表示动态数组、sort表示排序),接口统一(如所有容器都有begin()、end()、size()等成员函数),使用 STL 编写的代码更易读、易维护。
五、如何学习 STL?—— 从 “能用” 到 “能扩展” 的三境界
STL 的学习并非一蹴而就,而是一个循序渐进的过程。根据 STL 专家的经验,STL 的学习可以分为三个境界,每个境界对应不同的学习目标和方法。如下所示:

简单总结一下就是,学习STL的三个境界:能用、明理、能扩展。
总结
本期博客我为大家介绍了 C++ 的 STL,包括其定义(C++ 标准库重要部分,含数据结构与算法的软件框架)、四个版本(HP、P.J.、RW、SGI)、六大组件,还说明了其在笔试、面试和工作中的重要性,并提及学习 STL 的三个境界。下期博客我将正式开始为大家介绍STL的相关组件及相关应用和实现,希望大家多多支持!
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2025-10-07,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号