强化学习|近端策略优化 PPO


近端策略优化PPO(Proximal Policy Optimization)针对策略梯度PG(Policy Gradient)中 “策略更新幅度过大导致不稳定” 的问题,通过 “剪辑(Clip)” 或 “KL 散度约束” 限制新策略与旧策略的差异,使得每次更新在安全范围内,确保强化学习的训练过程高效且稳定。本文主要围绕PPO介绍以下内容:
1)同策略,异策略以及重要性采样的基本概念。 2)重要性权重如何影响PPO参数更新的过程。 3)PPO如何通过裁剪和KL散度策略构建“信任域”。
关注“AI老马” —【获取资源】&【进群交流】
1,重要性采样介绍
1.1,同策略和异策略
梯度策略PG参数更新的基本公式 (1)和 (2):
实际计算中需要从环境中采样很多条的轨迹,然后按照公式 (1)和 (2) 对策略函数参数 进行更新。由于轨迹从概率分布 中采样得到,一旦策略函数参数更新,轨迹的概率分布就会发生变化,之前采样过的轨迹就不能再次利用,所以策略梯度方法需要不断的从与环境的交互中学习,而不能利用历史数据,因此训练效率极低。
- • 同策略(On-Policy)
简而言之,“自己学,自己练”。在策略梯度中,负责与环境交互的演员与负责学习的演员是相同的,即用当前正在优化的策略 收集数据,收集完数据后,用这些数据更新策略 ,然后丢弃旧数据,再用新策略重新收集数据。
优点:数据和策略 “匹配”,更新逻辑简单;
缺点:效率低,每次更新都要重新收集数据,且容易因更新幅度过大导致策略 “突变”,训练不稳定,比如旧策略收集的数据对新策略已不适用。
- • 异策略(Off-Policy)
简而言之,“别人练,自己学”。将两个演员分离,固定一个演员与环境交互而不去更新它,将交互得到的轨迹交由另外一个负责学习的演员训练。
优点:数据可以重复使用,无需每次更新都重新收集,提高训练效率,但依赖于重要性采样。
缺点:数据和策略 “不匹配”,直接用新策略的数据分析旧策略会有偏差,需要校正。
小结: 同策略与异策略的本质区别是,谁来 “收集数据”!数据的收集者直接决定了策略的类型。近端策略优化PPO就是采用了异步策略。
1.2,重要性采样
异策略的核心问题是:用分布q 收集的轨迹(s,a),不能直接代表分布 p 的选择偏好。比如 q 喜欢选动作 A,而 p 喜欢选动作 B,直接用 A 的轨迹优化策略函数会误导模型。
重要性采样 IS(Importance Sampling) 它的核心思想是,通过重要性权重纠正偏差,即给分布 q 收集的每个(s,a)样本加一个 “权重”,这个权重反映了 “ 分布 q 选择 a 的概率” 相对于 “分布 p 选择 a 的概率” 的比例,从而让样本更贴合分布 p 的偏好。
- • 期望计算公式
假设随机变量 x 服从概率分布 p, 如果需要计算函数 的期望,可以从分布 p 中采样得到多条数据,使用公式近似计算:
若采样条数 N 足够大,公式 (3) 的结果就可以无限趋近于分布的真实期望。
- • 重要性权重修正
如果无法从分布 p 中进行采样,只能从分布q 中采样 ,这样就不能直接利用公式 (3)计算期望,需要进行转换。
从q 中每采样一个 并计算 都需要乘上一个重要性权重 修正这两个分布的差异,因此这种方法叫做重要性采样。这样就可以实现从分布 q 中采样,计算当前 x 服从分布 p 时的期望,其中 q 可以是任何分布。
- • 两分布保持一致
在实际中采样次数是有限的,分布 q 和分布 p 的不能差距太大,否则结果可能差距很大。
2,PPO梯度更新
将重要性采样运用到策略函数更新,可以把同策略换成异策略。假设负责学习的智能体策略为 (重要性采样中的分布 p),负责采样的智能体策略为 (重要性采样中的分布 q)。在梯度策略优化公式 (1) 中,加入重要性权重修正结果。
此策略梯度只更新 ,而不更新 ,这样才能不断的从分布 q 中采样轨迹,使得参数可以不断被更新。在此基础上,将已有的优化策略,精细化奖励和优势函数加入,得到:
优势函数从 变到 ,因为是利用 进行采样。继续拆解,利用
假定状态仅和环境有关,与具体策略无关,即 ,因为这部分无法直接计算,而条件概率可以,进一步简化为:
从公式 (8) 的梯度形式反推回目标函数:
其中 为要优化的目标函数,代表使用 与环境交互, 代表要优化的参数。
重要性采样的一个重要的稳定性保证就是分布 p 和分布 q 不能相差太大,可以KL散度来约束,使之尽可能的相似:
公式 (10) 的目的是要保证两个分布的表现相似,即动作概率的相似。公式 (11) 的大括号中有两部分组成,第一项重要性权重 ρ,通过两个独立的 “状态→动作” 的概率分布计算得到,第二项优势函数 A,一般通过 GAE 广义优势函数进行估计。
注意以上公式中的 与 是两个独立的分布,二者均是 “状态→动作” 的概率分布,但二者存在明确的 “更新继承关系”, 是 的 “历史版本”(即 在上一次数据收集阶段的分布状态),并非同一分布的两次实时更新。
参数更新过程:
实际工程中, 和需要分别的初始化两个神经网络,在每次数据收集前,将当前优化的的参数复制给,之后保持固定,仅负责与环境交互收集数据;而则基于这些数据进行多步更新,逐渐形成与 有差异但可控的新分布。
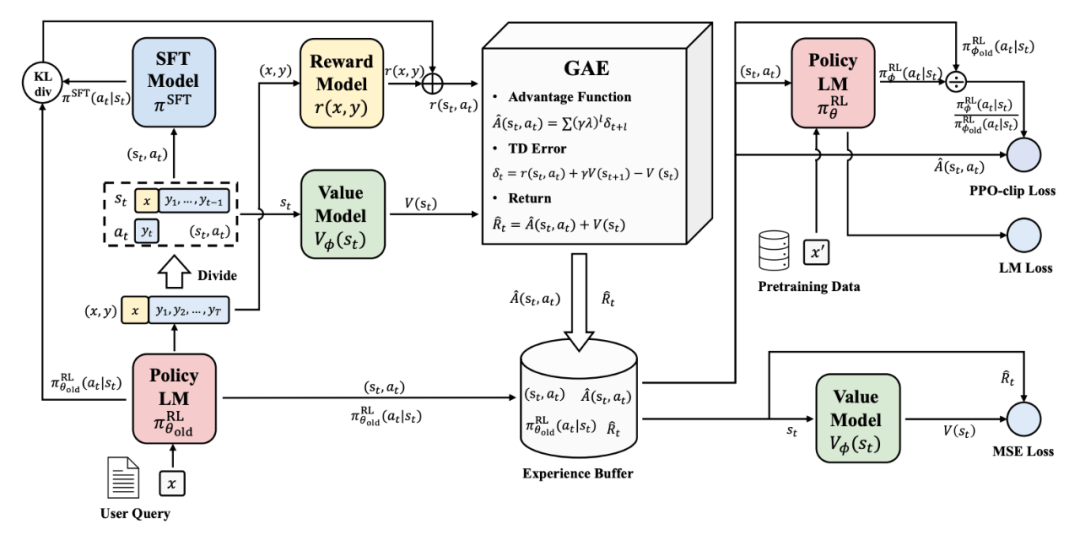
图2,PPO 参数更新流程图。
但新问题来了:策略更新幅度过大
异策略虽然高效,但如果目标策略 中的参数 更新太快,会导致 与 的差异过大,即此时重要性权重会变得极大或极小,校正效果失效,甚至让梯度估计出现严重偏差,最终导致训练发散,比如智能体突然开始乱选动作。
这就是 PPO 要解决的核心矛盾:如何在异策略高效更新的同时,限制策略 与 的差异,确保训练稳定。
3,PPO信任域约束
PPO 的本质是:在异策略的基础上,增加一个 “信任域(Trust Region)” 约束,强制新策略不能和旧策略差太远。这个约束通过两种主流方式实现:裁剪和KL 散度惩罚,对应的算法分别是 PPO-Clip 和 PPO-Penalty。
先统一目标函数框架,PPO 的目标是最大化 “带约束的策略收益”,目标函数的核心形式为:
公式中 L 是 “优势加权的策略改进项”,两种实现方式的差异在于 L 的定义。
3.1,近端策略优化-裁剪
PPO-Clip 的核心思想是:不直接使用原始的重要性权重 ρ,而是对 ρ 进行 “裁剪(Clip)”,强制其在 [1-ε, 1+ε] 范围内(ε 通常取 0.2),从而限制 与 的差异。裁剪后的目标函数为:
拆解这个公式:
- • 第一项:ρ・A(原始异策略的改进项)
- • 第二项:clip (ρ, 1-ε, 1+ε)・A(裁剪后的改进项)
- • min 操作:取两者中较小的那个,相当于 “保守更新”,即只保留对策略改进有正向作用的部分,避免因 ρ 过大 / 过小导致的过度更新。
比如你在学习打篮球( 是你的当前技术), 是你上周的技术。教练允许你每周进步,但不能进步太快,不能从 “不会运球” 直接变成 “扣篮”:
- • 如果你上周命中率 30%( ),这周练到 35%(ρ≈1.17 < 1.2):正常进步,教练认可;
- • 如果你这周突然练到 50%(ρ≈1.67 > 1.2):进步太快,教练会 “裁剪” 你的目标,让你先稳定在 42%(1.2×35%),避免动作变形;
- • 如果你这周命中率降到 20%(ρ≈0.67 < 0.8):退步太多,教练会让你至少保持 24%(0.8×30%),避免越练越差。
3.2,近端策略优化-惩罚
PPO-Penalty 的核心思想是:不裁剪权重,而是在目标函数中加入一个 “KL 散度惩罚项”,直接惩罚 与 的差异。KL 散度(Kullback-Leibler Divergence)是衡量两个概率分布差异的指标,KL 越大差异越大。
- • 第一项:ρ・A(原始改进项,鼓励策略优化)
- • 第二项:β・KL (...)(惩罚项,β 是惩罚系数,KL 越大,惩罚越重)
- • 核心逻辑:在 “优化策略收益” 和 “限制策略差异” 之间找平衡,即如果 与 差异太大,惩罚项会抵消一部分收益,从而阻止过度更新。
动态调整 β(自适应惩罚)为了让惩罚更灵活,PPO-Penalty 会动态调整 β:
- • 如果当前 KL 散度 > 目标 KL(比如目标 KL=0.01):说明差异太大,增大 β,加强惩罚;
- • 如果当前 KL 散度 < 目标 KL:说明差异太小,学习太慢,减小 β,减弱惩罚。
4,PPO 的完整训练流程
这里梳理 PPO-Clip 的核心训练步骤:
初始化:随机初始化目标策略 、价值网络 ,用于估计优势函数 A;
收集数据:用当前策略 与环境交互,收集一批轨迹 ;
计算优势函数 A:用价值网络 计算每个 的优势 ,常用 GAE 方法,更平滑;
更新策略 : 固定 即固定当前 θ 作为旧参数。用收集的数据,通过最大化 L_clip 目标函数,迭代更新 θ,通常迭代 3-10 次,即 “多步更新”,提高数据效率。
更新价值网络 V:最小化价值网络的预测误差,可以使用MSE 损失,让 V更准确估计状态价值;
重复步骤以上:直到策略 收敛,总收益不再提升。
关键细节,步骤 “多步更新” 是 PPO 高效的关键,异策略让数据可以重复使用,无需每次更新都重新收集,大大提升了训练效率。
总结
PPO 的核心目标:解决传统策略梯度 “更新幅度过大导致不稳定” 的问题,兼顾效率与稳定性;
核心思想:异策略 + 重要性采样(高效利用数据)+ 信任域约束(限制策略差异);
两种实现:PPO-Clip:裁剪重要性权重,简单高效,首选;PPO-Penalty:KL 散度惩罚,动态调整,适合平滑更新需求;
通俗理解:让智能体 “稳步进步”,不允许 “一口吃成胖子”,既保证学习效率,又避免走偏。
PPO 之所以成为强化学习的 “万能算法”,正是因为它在稳定性和效率之间找到了极佳的平衡,既不用像传统 PG 那样 “慢且不稳定”,也不用像 DQN 那样依赖值函数逼近的技巧,因此被广泛应用于游戏、机器人、NLP 等多个领域。
参考:arxiv 2307.04964
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-11-28,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号